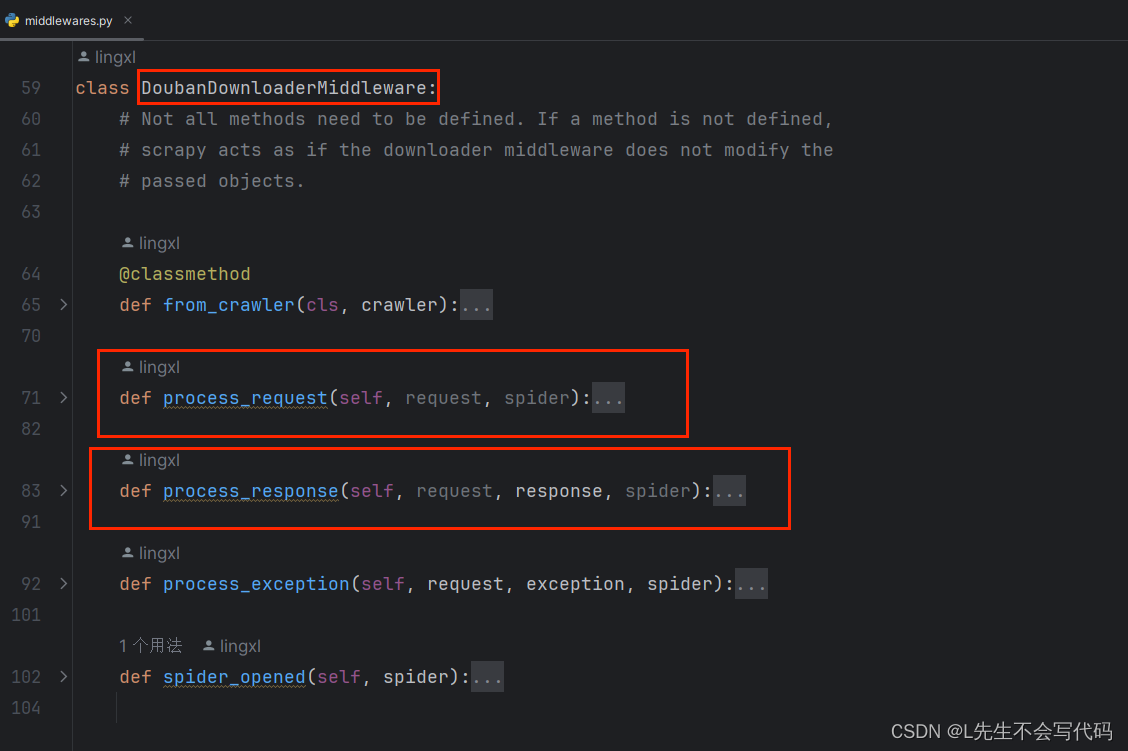
scrapy的基本使用介绍
创建项目
### 1. 创建虚拟环境
conda create -n spiderScrapy python=3.9
### 2. 安装scrapy
pip install scrapy==2.8.0 -i https://pypi.tuna.tsinghua.edu.cn/simple### 3. 生成一个框架
scrapy startproject my_spider### 4. 生成项目
scrapy genspider baidu https://www.baidu.com/### 5. 重新安装Twisted指定版本
pip install Twisted==22.10.0### 6. 启动项目
scrapy crawl baidu
项目框架如下
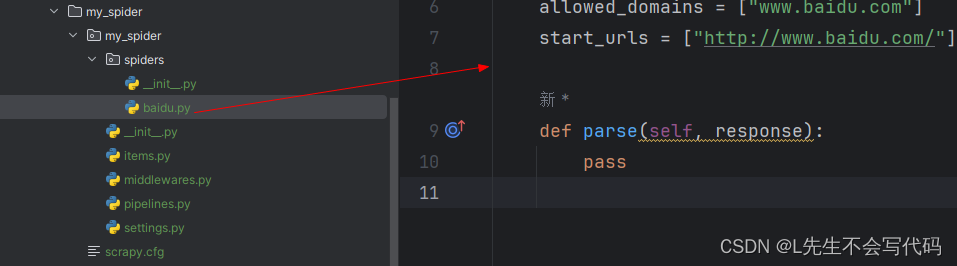
这里创建了一个百度爬虫的项目
- parse:解析响应数据
- pipelines:存储parse方法返回的解析好的数据- setting: 配置文件- middlewares: 中间件
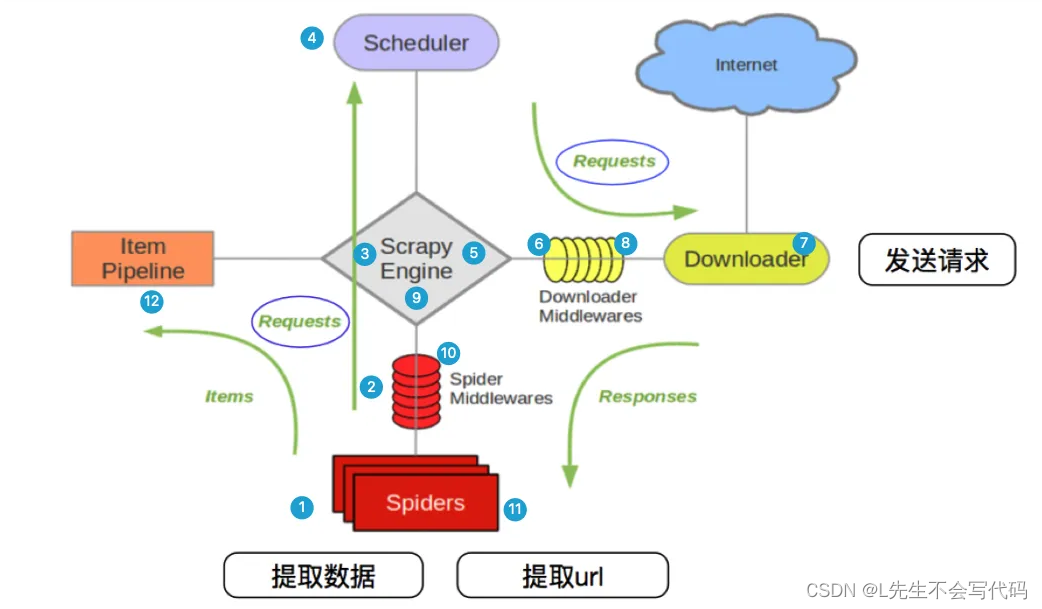
中间件的介绍
这里只介绍下载中间件,后期也是重点使用下载中间件