前端遍历导致查询数据时间过长_「干货」一文搞懂为什么图数据库比关系型数据库查询更快...
随着数据形式的变化,面向不同场景的数据库也应运而生,主要包括关系型数据库(如Oracle、Mysql、SQLite)和非关系型数据库NoSQL(如内存数据库Redis、文档数据库MogoDB、列式数据库HBase、图数据库Neo4j)两大类。在NoSQL中,以Neo4j为代表的图数据库解决了海量关联数据存储和查询的问题。

都说在处理关联型数据上,图数据库表现得比传统关系型数据库优异,但优异在哪里呢?特别是,为什么图数据库查询关系数据更快呢?本文将以一个具体的例子进行解读。
图数据库VS关系型数据库
相对于关系型数据库来说,图数据库因其存储结构的特点相较于关系型数据库有天然的优势,总结起来有如下几点:
- 更好的性能表现:对于高度关联的数据来说,会产生较多的join操作,当join层次过多的时候,关系型数据库的性能会显著低于图数据库。
- 灵活性:图数据库具有更好的灵活性,不强制把图数据存储到结构一定的数据表中,属性值的新增和删除都很方便,对于NULL值很多的数据集、非结构化数据等非常有用。
- 便于数据模型:因为没有预先设定的结构,使得数据建模非常方便,可按需调整。
- SQL查询痛点:随着Join的操作,SQL语句会变得非常复杂。
对于上述四点优势,2-4理解起来没什么难度,第一点虽然字面意思能理解,但一直搞不懂是为什么?join的层数变多会让关系型数据库查询性能下降能够理解,但为什么图数据库不会呢?
案例场景
场景:有三张表分别是部门表D(部门ID、部门名称)、员工表E(员工编号、员工姓名、所属部门)、支出表P(支出编号、员工、金额),现在想查询的是部门d1的总支出金额。
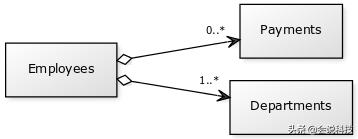
关系型数据库
先来看一下传统关系型数据库是怎么解决场景中提出的问题,通过对需求的分析,SQL可以写成如下形式:
select sum(P.money)from Dleft join Eon D.id = E.didleft join Pon E.id = P.eidwhere D.id = 'd1'上述查询语句会怎么执行呢,大致可分为如下几步:
- 遍历D表,定位部门编号id为d1的部门,即要把D表的每一个值都访问一遍,时间复杂度是|D|。
- 遍历E表,判断每一行数据的部门编号did字段是否为d1,即定位所属部门编号为d1的员工,假设最终定位到d1部门中有m位员工,时间复杂度是|E|。
- 遍历P表,判断每一行数据的员工编号是否与第2步中得到的m位员工编号相同,进而得到支出金额,时间复杂度为5*|P|。
- 汇总支出金额。
上述的按步分析可知,传统关系型数据库在解决这样一个问题时会多次遍历多张表,总的时间消耗是|D|+|E|+m*|P|。这还是在只探查一个部门的简化情况下,如果分析所有部门,时间复杂度可达到|D|*|E|*|P|,一般D表数据量不大,但E和P表的数据量(特别是P表)的数据量都很大,这样消耗的时间就很长了。
可能会有人说为什么不做索引,确实通过索引能够改善查询性能,假设D、E、P表的索引分别建在部门编号、员工编号、支出编号上,那么上面场景的时间消耗是多少呢?
- 因为D表中的部门编号有索引,所以定位部门d1的时间为常数时间,记为1。
- 员工表E的索引不在部门编号上,因此查询部门员工的操作仍然需要遍历全表,耗时为|E|。
- 支出表P的员工编号也没有做索引,查询部门员工支出仍然需要遍历全表,耗时为|P|。
- 那么,总耗时是1+|E|+m*|P|。在E表和P表都很大的情况下,耗时仍然过长。
随着D表、E表、P表规模的扩大,上述场景的耗时会越来越大。如果再增加一个支出明细表PI(产品编号、产品名称、产品数量、产品单价、支出编号),想要查询每个部门的具体支出明细,上面的SQL代码就更复杂了,耗时也就更长,最坏情况下是|D|*|E|*|P|*|PI|。
也就是说,即使使用索引,传统关系型数据库还是会随着查询层次的加深、数据量的加大,查询性能会逐渐恶化,这还不算索引本身的维护成本。
图数据库
相较于传统的关系型数据库,图数据库(以Neo4j为例)并不是把数据存在一张一张表里,然后通过外键进行关联,而是在存储结构上直接把节点及其关联节点连接在一起。这样,当需要查询一个节点的关联节点时,直接从节点循着链接出发去寻找就可以了,而不需要遍历所有节点,大大节省了查询时间。
对于上述场景中的部门、员工、支出,图数据库将其视为实体,员工和部门之间通过“属于”的关系链接在一起,支出和员工通过“实施”关系链接在一起,如下图所示:
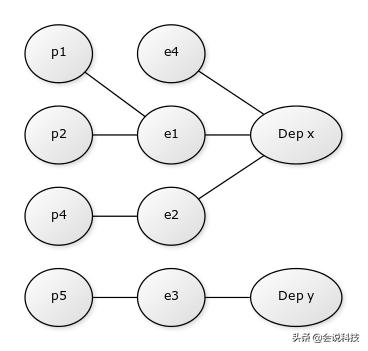
那么,如何查询部门d1的支出情况呢,步骤如下:
- 通过索引技术快速定位编号为d1的部门,耗时为1。
- d1为图数据库中的一个节点,直接遍历通过“属于”关系与该节点联结的节点(员工),耗时为m,m为部门d1的员工数。
- 围绕m个员工节点,遍历通过“实施”关系与这些节点联结的节点(支出)。假设有n个支出事件与部门d1的m个员工相关,那么耗时为n。
- 这样,总的耗时时间为1+m+n。
这里,m和n都远小于|E|和|P|,因此耗时远小于传统关系型数据库的耗时。
即使是查询所有部门的支出情况,耗时为|D|+|E|+|P|,耗时也远比|D|*|E|*|P|少。
还有就是上面提到的,增加一个支出详情表PI,其实对于图数据库来说,并不会有多大影响。单一部门的时间变成1+m+n+c,远小于|D|+|E|+|P|+|PI|;全部部门的时间是|D|+|E|+|P|+|PI|,耗时也远比|D|*|E|*|P|*|PI|少。
总结一下
通过上面的例子可以看出,使用图数据库查询时,查询工作量仅与被查询的节点关系数有关(即一个子图),而与全局节点数无关,这样当全局节点数变多、图变大时,子图的查询工作量不会有太大变化。另外,即使是查询层次变深,对于图数据库来说,只是多查了一层子图,逻辑比较清晰,不会像传统关系型数据库那样增加SQL的复杂度和表的遍历工作量。
这就是为什么在关联数据查询的场景下,图数据库的效率要比传统关系型数据库高的原因。
PS:本文内容多翻译自《Why Graph Databases Outperform RDBMS on Connected Data》,原文有更多解读,如果您感兴趣,可自行阅读。
如果有更好的理解,欢迎评论区留言讨论。
我是会说科技,关注我,一起聊聊数据、科技、IT、安全、金融那些琐事。