Elasticsearch:调整近似 kNN 搜索
在我之前的文章 “Elasticsearch:调整搜索速度”,我详细地描述了如何调整正常的 BM25 的搜索速度。在今天的文章里,我们来进一步探讨如何提高近似 kNN 的搜索速度。希望对广大的向量搜索开发者有一些启示。
Elasticsearch 支持近似 k 最近邻搜索,以有效查找与查询向量最接近的 k 个向量。 由于近似 kNN 搜索的工作方式与其他查询不同,因此对其性能有特殊的考虑。其中许多建议有助于提高搜索速度。 使用近似 kNN,索引算法在底层运行搜索以创建向量索引结构。 因此,这些相同的建议也有助于提高索引速度。
减少向量内存占用
默认的 element_type是 float。 但这可以通过 quantization 在索引时间时自动进行标量量化。具体的介绍可以详细阅读文章 “Elasticsearch:dense vector 数据类型及标量量化”。 量化会将所需的内存减少 4 倍,但也会降低向量的精度并增加该字段的磁盘使用量(最多增加 25%)。 磁盘使用量增加是 Elasticsearch 存储量化向量和未量化向量的结果。 例如,当量化 40GB 浮点向量时,将为量化向量存储额外的 10GB 数据。 总磁盘使用量为50GB,但快速搜索的内存使用量将减少到10GB。
对于 dim 大于或等于 384 的浮点向量,强烈建议使用量化索引。
降低向量维数
kNN 搜索的速度与向量维数成线性关系,因为每个相似度计算都会考虑两个向量中的每个元素。 只要有可能,最好使用维度较低的向量。 一些嵌入模型有不同的维度大小,有更低和更高维度的选项。 你还可以尝试使用 PCA 等降维技术。 在尝试不同的方法时,衡量对相关性的影响非常重要,以确保搜索质量仍然可以接受。
从 _source 中排除向量字段
Elasticsearch 将在索引时传递的原始 JSON 文档存储在 _source 字段中。 默认情况下,搜索结果中的每个命中都包含完整文档 _source。 当文档包含 dense_vector 字段时,_source 可能非常大且加载成本昂贵。 这可能会显着降低 kNN 搜索的速度。
你可以通过 excludes 映射参数禁用在 _source 中存储 dense_vector 字段。 这可以防止在搜索期间加载和返回大向量,并且还可以减少索引大小。 _source 中省略的向量仍然可以在 kNN 搜索中使用,因为它依赖于单独的数据结构来执行搜索。 在使用 excludes 参数之前,请确保查看从 _source 中省略字段的缺点。
另一种选择是使用 synthetic_source(如果所有索引字段都支持)。
确保数据节点有足够的内存
Elasticsearch 使用 HNSW 算法进行近似 kNN 搜索。 HNSW 是一种基于图的算法,只有当大多数向量数据保存在内存中时才能有效地工作。 你应该确保数据节点至少有足够的 RAM 来保存向量数据和索引结构。 要检查向量数据的大小,你可以使用分析索引磁盘使用情况 API。 作为一个宽松的经验法则,并假设默认的 HNSW 选项,使用的字节将为 num_vectors * 4 * (num_dimensions + 12)。 当使用字节 element_type 时,所需的空间将更接近 num_vectors * (num_dimensions + 12)。 请注意,所需的 RAM 用于文件系统缓存,它与 Java 堆分开。
数据节点还应该为其他需要 RAM 的方式留下缓冲区。 例如,你的索引可能还包括文本字段和数字,这也受益于使用文件系统缓存。 建议使用你的特定数据集运行基准测试,以确保有足够的内存来提供良好的搜索性能。 你可以在这里和这里找到我们用于夜间基准测试的一些数据集和配置示例。
预热文件系统缓存
如果运行 Elasticsearch 的机器重新启动,文件系统缓存将为空,因此操作系统需要一些时间才能将索引的热区域加载到内存中,以便搜索操作快速。 你可以使用 index.store.preload 设置显式告诉操作系统哪些文件应根据文件扩展名立即加载到内存中。
警告:如果文件系统缓存不够大,无法容纳所有数据,则在太多索引或太多文件上急切地将数据加载到文件系统缓存中将使搜索速度变慢。 谨慎使用。
以下文件扩展名用于近似 kNN 搜索:
- 向量值的 vec 和 veq
- HNSW 图的 vex
- 用于元数据的 vem、vemf 和 vemq
减少索引段的数量
Elasticsearch 分片由段(segment)组成,段是索引中的内部存储元素。 对于近似 kNN 搜索,Elasticsearch 将每个段的向量值存储为单独的 HNSW 图,因此 kNN 搜索必须检查每个段。 最近的 kNN 搜索并行化使得跨多个片段的搜索速度大大加快,但如果片段较少,kNN 搜索的速度仍然可以提高数倍。 默认情况下,Elasticsearch 通过后台合并过程定期将较小的段合并为较大的段。 如果这还不够,你可以采取明确的步骤来减少索引段的数量。
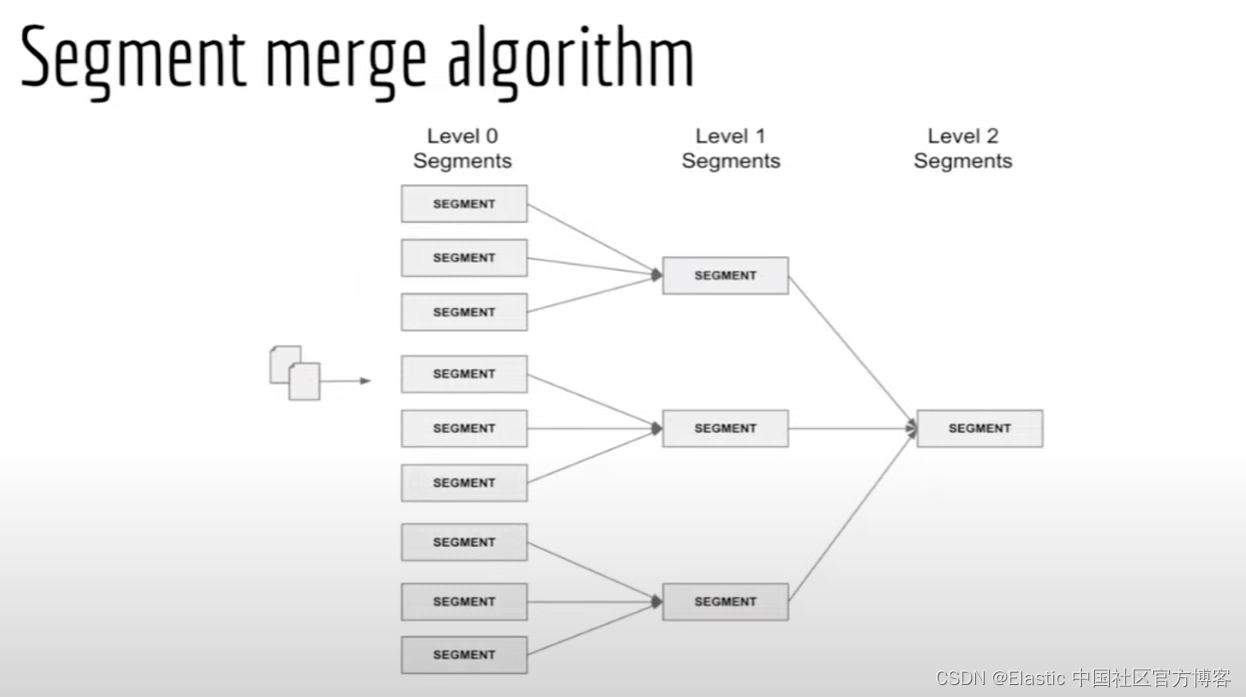
Lucene 合并,同时索引所有维基百科(英文)
强制合并到一个段
Force merge 操作强制进行索引合并。 如果强制合并到一个段,kNN 搜索只需要检查一个包含所有内容的 HNSW 图。 强制合并 dense_vector 字段是一项昂贵的操作,可能需要大量时间才能完成。
警告:我们建议仅强制合并只读索引(意味着索引不再接收写入)。 当文档被更新或删除时,旧版本不会立即删除,而是软删除并标记为 “墓碑”。 这些软删除文档会在定期段合并期间自动清除。 但强制合并可能会导致生成非常大(> 5GB)的段,这些段不符合常规合并的条件。 因此,软删除文档的数量会迅速增长,从而导致更高的磁盘使用率和更差的搜索性能。 如果你定期强制合并接收写入的索引,这也会使快照更加昂贵,因为新文档无法增量备份。
在批量索引期间创建大段
常见的模式是首先执行初始批量上传,然后使索引可用于搜索。 你可以调整索引设置以鼓励 Elasticsearch 创建更大的初始段,而不是强制合并:
- 确保批量上传期间没有搜索,并通过将其设置为 -1 来禁用 index.refresh_interval。 这可以防止刷新操作并避免创建额外的段。
- 为 Elasticsearch 提供一个较大的索引缓冲区,以便它可以在刷新之前接受更多文档。 默认情况下,indices.memory.index_buffer_size 设置为堆大小的 10%。 对于像 32GB 这样的大堆大小,这通常就足够了。 为了允许使用完整的索引缓冲区,你还应该增加限制 index.translog.flush_threshold_size。
避免在搜索过程中建立大量索引
积极地索引文档可能会对近似 kNN 搜索性能产生负面影响,因为索引线程会窃取搜索的计算资源。 当同时索引和搜索时,Elasticsearch 也会频繁刷新,这会创建几个小段。 这也会损害搜索性能,因为当分段较多时,近似 kNN 搜索速度会变慢。
如果可能,最好在近似 kNN 搜索期间避免大量索引。 如果你需要重新索引所有数据,可能是因为向量嵌入模型发生了变化,那么最好将新文档重新索引到单独的索引中,而不是就地更新它们。 这有助于避免上述速度减慢,并防止由于频繁的文档更新而导致昂贵的合并操作。
在 Linux 上使用适度的预读值来避免页面缓存抖动
搜索可能会导致大量随机读取 I/O。 当底层块设备具有较高的预读值时,可能会执行大量不必要的读取 I/O,特别是当使用内存映射访问文件时(请参阅存储类型)。
大多数 Linux 发行版对单个普通设备使用 128KiB 的合理预读值,但是,当使用软件 raid、LVM 或 dm-crypt 时,生成的块设备(支持 Elasticsearch path.data)最终可能会具有非常大的预读值(在 几个 MiB 的范围)。 这通常会导致严重的页面(文件系统)缓存抖动,从而对搜索(或更新)性能产生不利影响。
你可以使用 lsblk -o NAME,RA,MOUNTPOINT,TYPE,SIZE 检查当前值(以 KiB 为单位)。 有关如何更改此值的信息,请参阅发行版的文档(例如,使用 udev 规则在重新启动后保持不变,或通过 blockdev --setra 作为瞬态设置)。 我们建议预读值为 128KiB。
在 Linux 上使用适度的预读值 (readahead) 来避免页面缓存抖动
搜索可能会导致大量随机读取 I/O。 当底层块设备具有较高的预读值时,可能会执行大量不必要的读取 I/O,特别是当使用内存映射访问文件时(请参阅存储类型)。
大多数 Linux 发行版对单个普通设备使用 128KiB 的合理预读值,但是,当使用软件 raid、LVM 或 dm-crypt 时,生成的块设备(支持 Elasticsearch path.data)最终可能会具有非常大的预读值(在 几个 MiB 的范围)。 这通常会导致严重的页面(文件系统)缓存抖动,从而对搜索(或更新)性能产生不利影响。
你可以使用 lsblk -o NAME,RA,MOUNTPOINT,TYPE,SIZE 检查当前值(以 KiB 为单位)。 有关如何更改此值的信息,请参阅发行版的文档(例如,使用 udev 规则在重新启动后保持不变,或通过 blockdev --setra 作为瞬态设置)。 我们建议预读值为 128KiB。
警告:blockdev 期望值以 512 字节扇区为单位,而 lsblk 报告值以 KiB 为单位。 例如,要将 /dev/nvme0n1 的预读临时设置为 128KiB,请指定 blockdev --setra 256 /dev/nvme0n1。