性能分析-CPU知识
目录
CPU知识
cpu组成
查看cpu信息:
top命令中 cpu相关:
top命令看到系统负载: CPU负载 + IO负载
上下文: CPU的寄存器和程序计数器----在cpu的控制器中
实战演示分析
top命令分析
arthas工具
进程上下文切换高的问题分析
stress-ng 工具定位
分析
top
vmstat
pidstat -w 1
线程上下文切换的问题分析
stress-ng 工具定位
分析
top
vmstat
pidstat -w 1
IO密集型导致服务器负载高
stress-ng 工具定位
分析
top
vmstat 1
iostat -dx 1
监控平台
grafana + promethues 监控模板界面不显示数据
CPU知识
选择: 架构、核、主频
cpu组成
控制单元 、计算单元、存储单元



查看cpu信息:
- top
- lscpu
- cat /proc/cpuinfo


top命令中 cpu相关:
- top命令中的 进程列表中,是根据cpu的使用率从高到低。所以使用top进行性能分析时,如果 cpu使用率高,可以首先分析top命令中进程列表中 cpu使用率最高的第一个进程。
- us\sy 非内核态(用户态)\内核态(系统态)
- us: 逻辑运算
- sy: 底层计算
- 如果现在 top命令中,cpu使用率高的第1个进程,是一个 应用程序。此时再看 us、sy。
- us高: 应该是 应用程序的 逻辑运算 频繁 ------代码有问题
- 如果 现在top命令中,cpu使用率高的第1个进程是一个数据库程序。此时再看 us、sy。
- us高: sql语句执行逻辑很复杂 -----sql有问题
- sy高: 读写磁盘操作
top命令看到系统负载: CPU负载 + IO负载

- sys高, =====> 怀疑===>上下文切换高 ======>pidstat====>自愿上下文切换高------可能是获取不 到足够的资源,----内存不足
- sys高 =====》怀疑 =====》上下文切换=====》pidstat=====》非自愿上下文切换高 -----cpu不够用
- us高 ====》业务逻辑有关 -----实现上存在、FGC、 CPU密集计算
- si高 ====》 抢占资源 wa高 ===》 等资源 -----可能是内存,也可能是网络资源、外设资源、磁盘资源太慢


上下文: CPU的寄存器和程序计数器----在cpu的控制器中
- 上下文切换发生在cpu的控制器中。 其实就是 cpu控制器中的指令的切换。
CPU上下文的切换,先保存前一个指令的资源到内核中,然后加载新的指令的资源,执行新的指 令
- 这个过程有保存老的, 加载新的,所以它会占用CPU的时间。如果占用的总时间长,到cpu的 用 与计算的时间就少了。所以cpu运算速度就变慢,处理的 响应时间就变长了。
切换的指令,可以是同一个进程的,也可以是不同进程的
- 同一个进程中上下文切换。
- 进程是资源的拥有者。
- 同一个进程中, 不同线程之间的切换。 只需要保存线程的私有的资源即可
- 不同进程之间,上下文切换。
- 保存 前一个进程的资源, 然后打开新进程的资源。
实战演示分析
现在讲的CPU,cpu是硬件设备。要进行性能分析可以使用性能分析命令,也可以使用监控平台。
- 先用 命令分析
- 再用 监控平台来分析
把xxxxx项目启动
对 获取验证码 接口 进行性能测试

top命令分析
- top进程列表中, cpu使用率最高的java进程
- 知道 java进行的 pid
- ps -ef |grep pid 找 找到 具体java进程 -----判断出,到底是哪个java进程,导致的cpu使用

- cpu的总的使用率数据中,显示 总和 接近100%, us态是最高的
- 代码逻辑有问题
- 结论: xxxxx项目,在获取验证码接口上,存在性能问题,代码逻辑可能有问题。
arthas工具
是阿里开源的 java项目的性能分析工具。
- 定位:
- arthas: 下载到 xxxx项目机器上 curl -O https://arthas.aliyun.com/arthas-boot.jar
- 使用 java -jar arthas-boot.jar 启动arthas
- 显示出,所有的java进程列表
- 选择你要分析的java进程的id的 序号 回车, 就自动连接到 你要连接到java进程

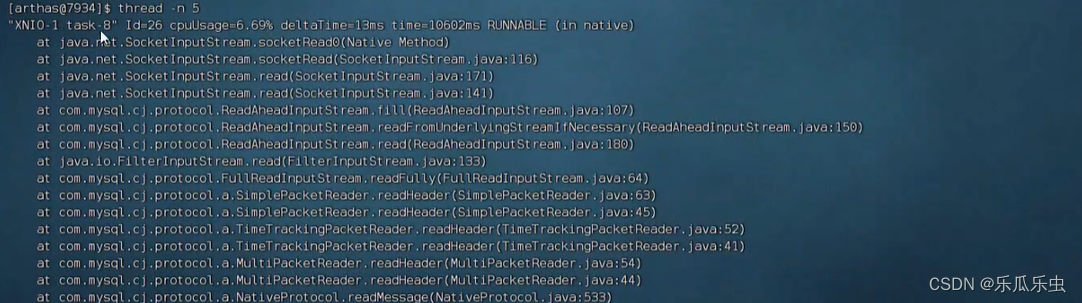
- 查看帮助信息thread --help

- thread -n 数字 ------获取到了 cpu使用率最高的几个线程栈信息
- 如果你看不懂, 你把这个线程栈信息,给 java开发人员,让他们定位。
- 自己看线程栈信息,找到 项目工程的 代码类和行
- at
- com.lemon.lemon_erp.controller.CodeController.getCode(CodeController.j ava:67)
进程上下文切换高的问题分析
stress-ng 工具定位
进程: 在一台机器上 有多个进程
使用 stress-ng 工具,来模拟产生大量的 进程,然后相互竞争,造成性能现象,模拟在企业服 务器中 多进程的情况。
yum install epel-release.noarch
yum update -y
yum install stress-ng -y

命令 nproc 获取系统cpu的数量
((proc_cnt = `nproc`*10)); stress-ng --cpu $proc_cnt --pthread 1 --timeout 120s分析
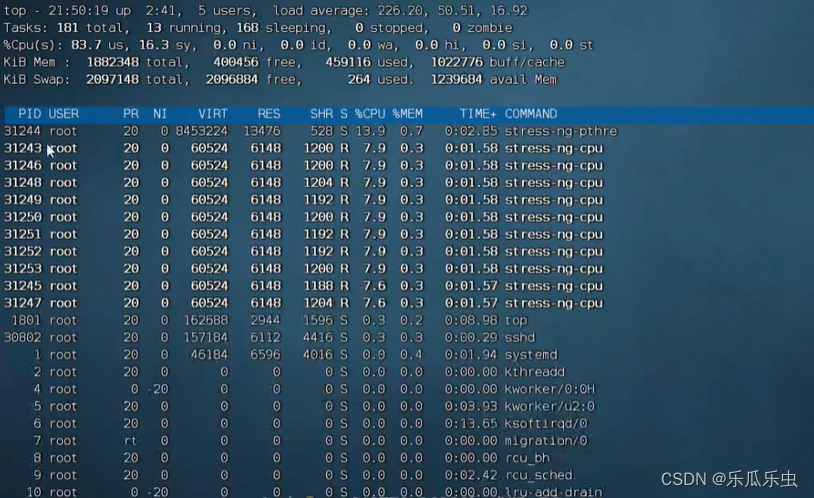
top
- 进程列表中,cpu使用率最高的一些进程的名称相同; cpu的 us态值最高 sy也有增大; loadaverage 非常大。
- 进程名称相同,怀疑是在抢cpu资源----想到 vmstat
vmstat
- procs中r队列的值,有明显的数据变化。
- 有大量的进程在抢占cpu资源。 -------cpu不够,是性能瓶颈。
- 内存中,free有稍微变少,cache有变大,buff基本没变
- bi bo si so 没有明显的变化
- system中的 in 变化比较小, cs变化非常大。-----上下文切换非常大。

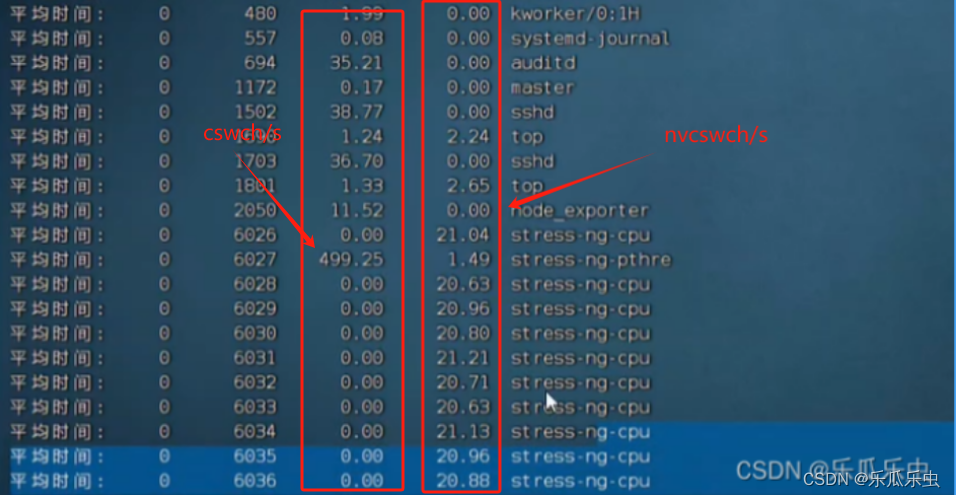
pidstat -w 1
- cswch/s 自愿上下文切换要大一些 nvcswch/s 也有明显的数,相对来说小一些。
当系统出现 了进程上下文过多导致的性能问题,通过top命令和vmstat命令和pidstat命令,看到现象就如上。
这个问题,怎么解决?
- 加cpu,但是实际中,加cpu数量,是不方便。
- 减少进程(迁移一些进程到另外的服务器上、或者调整项目代码配置,减少启动的进程数量)
线程上下文切换的问题分析
一个进程: 就是一个程序、一个服务、一个项目, 进程是资源的拥有者。
线程: 是进程的工作者。 一个进程是可以有多个线程的。
线程上下文切换:
同一个进程中,多个线程之间的切换
不同进程间,线程的切换 ------类似 进程切换
stress-ng 工具定位
stress-ng --cpu `nproc` --pthread 10 --timeout 120
分析
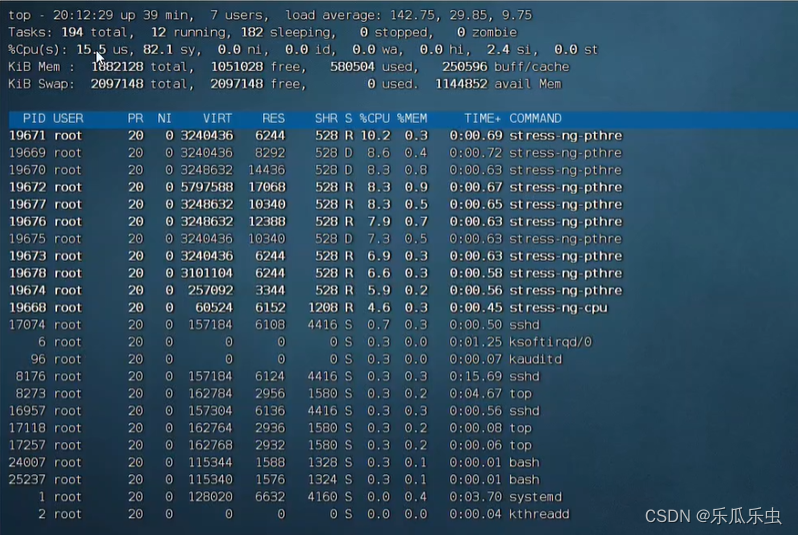
top
系统负载升高、CPU的使用情况中 us和sy都有值、si也有值,sy要比us大。进程列表中先了 多个项目的名称。
vmstat
proc中 r列有明显的数据变化,b列没有变化,free有变小,cache变大,in、cs有数据变化, 但是 cs变化的很明显(上下文切换)。
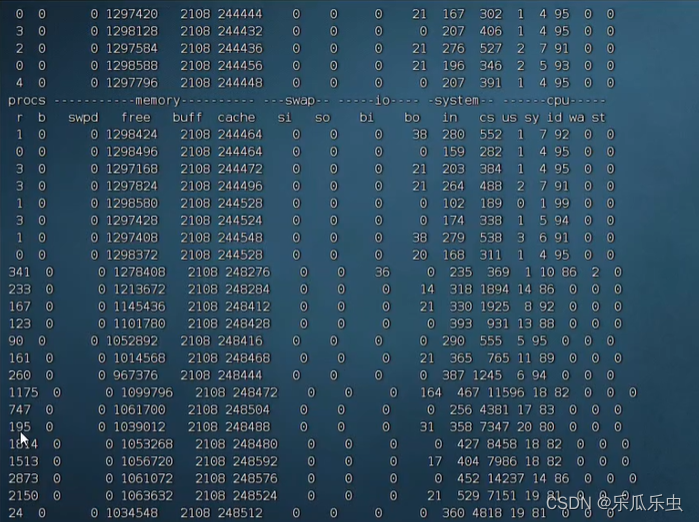
pidstat -w 1
看到每一个线程的 cswch/s 自愿上下文切换的数据都比较大, 每个线程的非自愿nvcswch/s上下文切换数据比较小的。

| 进程上下文切换 | 线程上下文切换 | |
| top | us大,sy小 | us小,sy大 |
| vamstat 1 | proc列的r数据大 、cs数据大 | proc列的r数据大、cs数据大 |
| pidstat -w 1 , | 总的进程的自愿上下文大,每个进程的自愿上下文小,每个进程的非自愿上下文切换大。 | 每个线程的自愿上下文切换是 大的,非自愿上下文切换小 |
这种问题怎么解决?
- 少启动一些线程:
- 修改进程中,启动的线程数的配置 ------ 最大值,由服务所在的机器或容器的CPU核数来定
- 在服务器上,少启用一些服务\进程,迁移一些进程到其他服务器上面。
IO密集型导致服务器负载高
- 系统负载高,由两部分组成: CPU负载高、 IO负载高 io负载高,
- top命令看得时候,cpu的使用率中 wa 值
- 如果 CPU使用率中wa值比较大,这种情况大概率就是 IO性能问题
- io负载: 磁盘负载 、 网络负载、外设负载
- 如果是网络负载慢: 可能就是网卡或者是带宽
- 网卡: 一般情况下 都是千兆网卡 ------一般情况下,网卡速度不会成为瓶颈
- 外设:
- 磁盘: 读写使用率 IOPS 模拟,系统IO使用率高,导致的性能瓶颈的分析
- 如果是网络负载慢: 可能就是网卡或者是带宽
- 模拟,系统IO使用率高,导致的性能瓶颈的分析
- 什么现象,说明磁盘的io成为了性能瓶颈?

stress-ng 工具定位
stress-ng -i 6 --hdd 1 --timeout 120分析
top
sy、wa、si 这三个值,跳跃性的成为最大值。
- sy cpu的内核进程计算 读写磁盘是发生在内核中
- wa 等待数据
- si 软中断

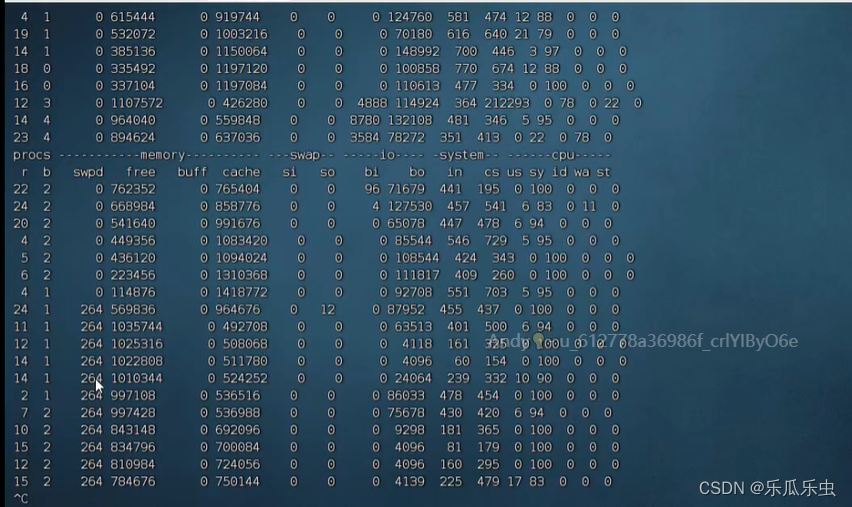
vmstat 1
proc的r队列有变化不明显; free表小,cache 变大了, bi、bo有明显的数据
bi bo 是磁盘操作-----怀疑是磁盘瓶颈
iostat -dx 1
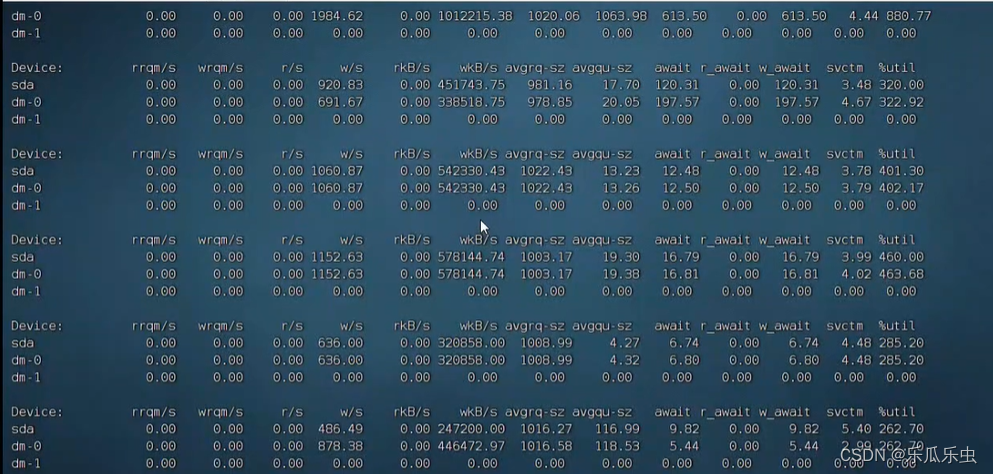
await有明显的数据,说明有明显的磁盘等待。
使用这个命令不要过于频繁或时间过长。执行这个命令很明显的等待,操作会很卡,持续操作的话,可能导致 机器宕机。
问题解决办法
- 磁盘成为了瓶颈
- 换磁盘: 应用服务器换固态硬盘
- 减少IO操作: 应用服务器,写日志,是应用服务最常见的磁盘操作
- 减少日志: 提高日志级别,日志级别越高,日志量越少。
- 日志文件拆解:如 根据日志文件大小拆解
- 数据库服务器的磁盘瓶颈
监控平台
监控服务器硬件资源: grafana + Prometheus + node_exporter
- grafana
- prometheus 时序数据
- node_exporter: Prometheus收集硬件资源的收集器
- 如果你想要收集信息,就选择用不同的
- exporter exporter不同,就可以收集不同的资源(硬件资源、服务资源)
grafana、Prometheus,不会安装在被监控服务器上。 exporter 会安装到 被监控的机器上。要收集多 个机器,每个机器上都放置 exporter
node_exporter的 默认端口: 浏览器http协议可以访问端口 9100
- 启动 ./node_exporter
Prometheus可浏览器http协议访问的端口: 9090
- 配置文件 prometheus.yml 要注意格式
- job_name: 'node_exporter'
static_configs:
- targets: ['192.168.130.133:9100']- ./prometheus
启动grafana: systemctl restart grafana-server
http://grafana的ip:3000 admin admin
选择添加 Prometheus数据源
- 注意: 数据源添加url: http://prometheus的ip:9090
引入模板: import 12884
- 注意: 数据源,要选择你上面添加的 数据源的名称
grafana + promethues 监控模板界面不显示数据
- Prometheus 与 node_exporter机器 网络不通
- Prometheus的机器的 时间 与 node_expoter机器的时间 相差特别大
- 隔8小时 把grafana的模板界面右上角的时间 拉长8小时以上--出现数据
- 界面模板的界面 左上角 信息没有出来 ---可以手动填,不是所有的都会带出来

- 有修改 hosts文件(系统名未改,大部分公司已经改了的)
- /etc/hosts文件中
- 没有填写主机名网络请求时,有的会要读取这个文件中主机名,读不到会导致网络延迟非常大。
- /etc/hosts文件中
搭建环境详见:Linux集群监控部署: prometheus 普罗米修斯 + Grafana(超详细)_监控 普罗米修斯和gra-CSDN博客文章浏览阅读1.1w次,点赞12次,收藏130次。前言之前我们有用到top、free、iostat等等命令,去监控服务器的性能,但是这些命令,我们只针对单台服务器进行监控,通常我们线上都是一个集群的项目,难道我们需要每一台服务器都去敲命令监控吗?这样显然不是符合逻辑的,Linux中就提供了一个集群监控工具 – prometheus。..._监控 普罗米修斯和grahttps://blog.csdn.net/weixin_43865008/article/details/118946362