Redis数据库知识点
Redis
set get del keys
redis中有哪些数据类型
string
最大512m
key层级
redis的key允许有多个单词形成层级结构,多个单词之间用‘:’隔开
set get del keys
hash
本身在redis中存储方式就为key-value, 而hash数据结构中value又是一对key-value
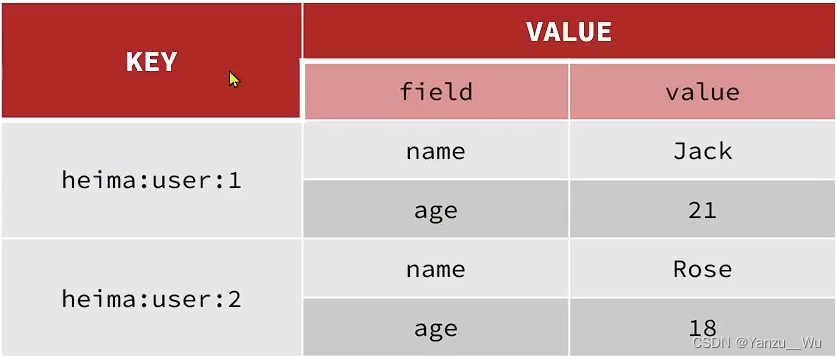
hset key field value
hget key field
hdel
hkeys
list
双向链表,元素可重复
lpush key element
lpop key
rpush key element
rpop key
lrange key start end
set
底层是hash表
无序,不可重复
查找快,支持交际并集差集等集合操作
SADD key member
SREM key member
SISMEMBER
SMEMBERS
SINTER key1 key2 交集
SDIFF key1 key2 差集
SUNION key1 key2 并集
sorted set
底层是跳表+hash表
sorted中每个元素都带score属性,根据score属性排序
特点:可排序,元素不可重复,查询速度快
ZADD key score member
ZREM ket member
ZDIFF,ZINTER,ZUNION:求差集,交集,并集
持久化是什么,持久化aof和rdb
redis是基于内存的,因此如果遭遇断电的情况,会导致数据丢失,这对一个数据库而言是致命的
持久化就是指将Redis服务器中的数据保存到磁盘上,以防止数据在服务器重启或宕机时丢失。
redis有两种方式保障数据,一个是rdb(redis database),另一个是aof(Append only file)
rdb是每隔一定的时间间隔,对数据库进行一次快照,并保存至磁盘中
aof是在执行写命令是,不仅会将数据写入到内存中,还会将写操作追加到aof文件中,它会以日志的形式来记录每一个写操作,在redis重启后,通过重新执行aof文件中的命令,来恢复数据
缓存穿透,缓存击穿,缓存雪崩
缓存穿透、缓存击穿和缓存雪崩是三种常见的缓存相关问题,它们有着不同的特点和原因:
1、缓存穿透是指,客户端查询到了根本不存在的数据,使得这个请求直达存储层,导致负载过大造成数据库宕机。2、缓存击穿主要是指一个非常大的热点数据缓存失效导致所有请求直达存储层,导致服务崩溃。3、缓存雪崩是指某一时刻缓存层无法继续提供服务,导致所有请求直达存储层,造成数据库宕机。
-
缓存穿透(Cache Penetration):
- 定义:缓存穿透是指恶意用户或者非法请求频繁访问缓存中不存在的数据,导致这些请求直接穿透缓存层,直接访问后端存储系统。
- 原因:通常是因为用户查询了不存在的数据,或者攻击者故意发起恶意请求。这种情况下,每次请求都会直接访问后端存储系统,造成系统资源浪费和性能下降。
- 解决方案:可以通过在缓存层增加布隆过滤器等机制来过滤掉不存在的请求,或者在后端存储系统中添加空值缓存来防止穿透。
-
缓存击穿(Cache Breakdown):
- 定义:缓存击穿是指某一个热点数据突然失效或者被删除,导致大量的请求直接访问后端存储系统,造成后端存储系统负载剧增和性能下降的情况。
- 原因:通常是因为某一个热点数据的缓存失效了,或者缓存设置了较短的过期时间。当大量请求同时到达时,会直接访问后端存储系统,造成击穿现象。
- 解决方案:延长热点数据缓存时间:针对热点数据,可以将其缓存设置为永久有效,或者设置一个较长的过期时间,以减少因缓存失效而导致的击穿问题。 加锁:在缓存失效时,可以使用分布式锁等机制来避免同时访问后端存储系统,从而降低因击穿而导致的请求压力。
-
缓存雪崩(Cache Avalanche):
- 定义:缓存雪崩是指缓存中的大量数据同时失效,导致大量请求直接访问后端存储系统,造成后端存储系统负载剧增和性能下降的情况。
- 原因:通常是因为缓存中的数据过期时间设置过于集中,或者缓存服务器故障等原因导致大量缓存同时失效。当大量请求同时到达时,会直接访问后端存储系统,造成雪崩现象。
- 解决方案:随机过期时间:对缓存中的数据设置随机的过期时间,可以避免大量缓存同时失效,从而减少缓存雪崩的发生。 热点数据预热:在缓存中预先加载热点数据,可以避免因缓存失效而导致的大量请求直接访问后端存储系统。可以通过定时任务或者手动触发的方式进行热点数据的预热。
redis 为什么读取速度那么块
Redis 读取速度快的主要原因有以下几点:
-
内存存储:Redis 将数据存储在内存中,读取数据时直接从内存中获取,而不需要像传统数据库一样进行磁盘 I/O 操作,因此读取速度非常快。
-
单线程模型:Redis 使用单线程模型来处理客户端请求,避免了多线程之间的上下文切换和锁竞争,提高了读取速度。
-
非阻塞 I/O:Redis 使用非阻塞 I/O 处理网络请求,当客户端发起读取请求时,Redis 会立即返回数据,而不需要等待数据读取完成,进一步提高了读取速度。
-
高效的数据结构:Redis 提供了丰富而高效的数据结构,如字符串、哈希、列表、集合、有序集合等,这些数据结构的实现都经过了优化,能够在内存中高效存储和访问数据。
-
事件驱动:Redis 使用事件驱动模型处理客户端请求,采用事件循环机制监听和处理事件,避免了线程阻塞和等待,提高了系统的并发处理能力和读取速度。
-
预编译指令:Redis 采用了预编译的方式处理客户端请求,将一些常用的操作编译成底层的指令,减少了解析和执行的时间,提高了读取速度。
为什么redis6.0要引入多线程
Redis 6.0引入多线程主要是为了提高性能和利用多核处理器的能力。在传统的Redis版本中,采用单线程的事件循环模型,这意味着无法充分利用多核处理器的优势
通过引入多线程,Redis可以将工作负载分布到多个线程上,从而更好地利用多核处理器的能力。这样可以提高Redis在多核处理器上的并发性能和吞吐量,使其更适合处理大规模的并发请求。
在Redis 6.0中,引入了多线程处理网络 I/O 操作,但主要的数据处理仍然是在单线程中完成的。这种设计被称为“多线程非阻塞 I/O”。
在这种模型下,Redis的主线程仍然负责执行命令的解析、执行以及数据处理等核心任务,而多个 I/O 线程负责处理网络 I/O 操作,如接受新的客户端连接、读取和写入数据等。这样可以在一定程度上提高网络 I/O 的并发处理能力,减少了主线程在等待 I/O 完成时的空闲时间,从而提升了整体的性能表现。
采用多线程处理网络 I/O 操作的好处在于可以更充分地利用多核处理器的优势,提高了 Redis 在处理大量并发连接时的性能表现。同时,这种设计也避免了传统多线程模型中因线程切换而带来的额外开销和复杂性。