【Java面试】二、Redis篇(中)
文章目录
- 1、Redis持久化
- 1.1 RDB
- 1.2 AOF
- 1.3 RDB与AOF的对比
- 2、数据过期策略(删除策略)
- 2.1 惰性删除
- 2.2 定期删除
- 3、数据淘汰策略
- 4、主从复制
- 4.1 主从全量同步
- 4.2 增量同步
- 5、哨兵模式
- 5.1 服务状态监控
- 5.2 哨兵选主规则
- 5.3 哨兵模式下,Redis集群的脑裂
- 6、分片集群
- 7、Redis快的原因(IO多路复用 + Redis网络模型)
- 7.1 用户空间和内核空间
- 7.2 阻塞IO模型
- 7.3 非阻塞IO模型
- 7.4 IO多路复用
- 8、面试
1、Redis持久化
1.1 RDB
RDB,即Redis Database Backup file,导出数据快照到磁盘。如果Redis实例宕机,也可读取快照文件,恢复数据,一般bgsave,以防文件过大时,阻塞其他请求
也可根据配置触发RDB:redis.conf

RDB的执行原理:bgsave开始时,fork主进程得到一个子进程(类似克隆,把存有映射关系的页表拷贝给了子进程),页表中存了分配给进程的内存(虚拟地址)和物理内存(物理地址) 的映射关系。子进程根据页表去读取数据,并写入RDB文件,主进程则继续回去处理客户端请求。
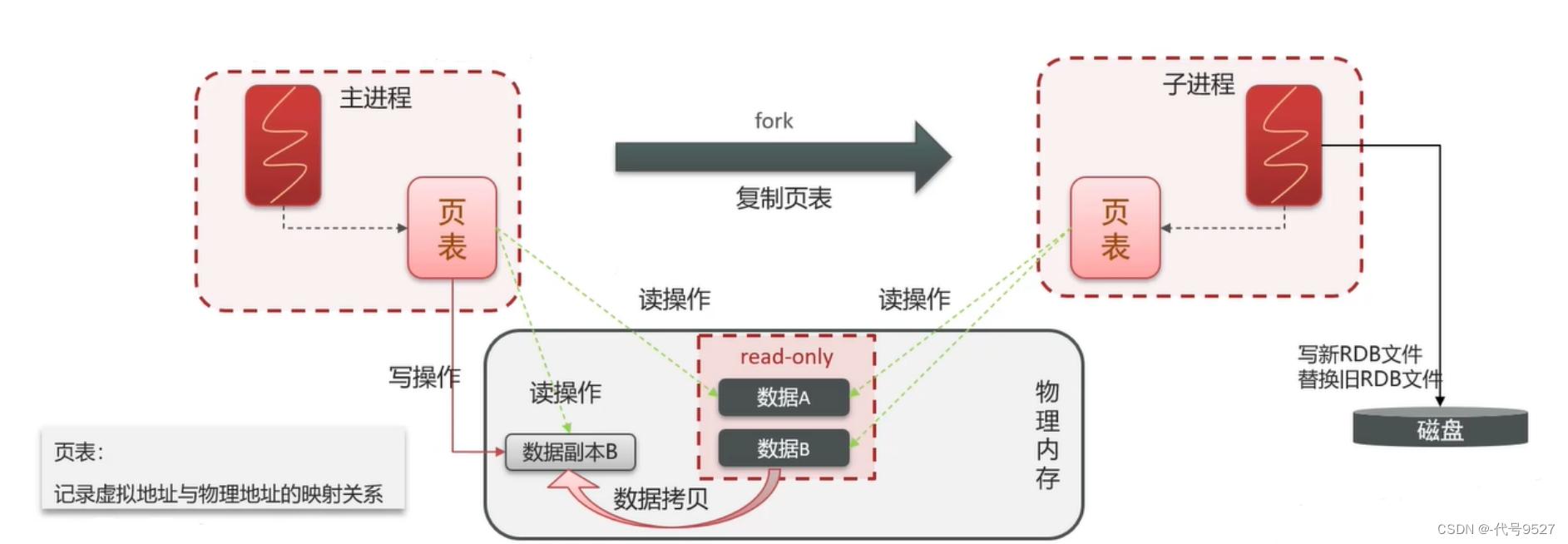
主进程和子进程之间会使用写时复制(copy-on-write)机制,此时,原内存空间为read-only,主进程如果要进行写操作,会拷贝一份数据,进行写操作,且后面读操作也是基于拷贝的副本去读,因此,basave期间,进行更新的那部分数据,不会同步到快照文件中。
1.2 AOF
Append Only File(追加文件),类似日志文件,记录每一个写命令
相关配置:redis.conf

记录写命令到AOF文件,有不同的策略(即刷盘策略)


everysec策略适用场景最多。此外,多次set同一个key,没必要重复记录,记录最后一次即可,可用bgrewriteaof命令,让AOF重写,降低文件大小。

关于触发重写的阈值配置:

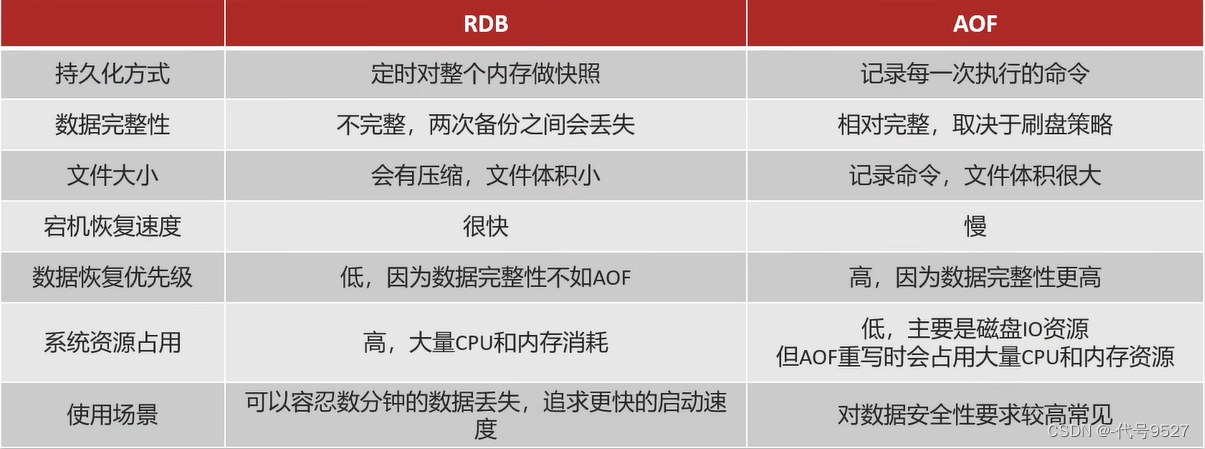
1.3 RDB与AOF的对比
2、数据过期策略(删除策略)
即数据过期后,何时从内存中删除。
- 惰性删除
- 定期删除
2.1 惰性删除
key过期后,不管,直到下次get key,发现过期就删除,否则正常返回

- 优点:不多占用CPU
- 缺点:如果有key过期,但后面没被get过,则这块空间一直得不到释放
2.2 定期删除
每隔一段时间,对一定数量的key进行检查,删除过期的key。有两种模式:
- SLOW模式:定时任务,执行频率默认10hz,即每个执行周期100ms,每次不超过25ms,可在redis.conf调整
- FAST模式:频率不固定,但两次间隔不低于2ms,每次耗时不超过1ms
Redis的过期策略是惰性删除 + 定期删除配合。
3、数据淘汰策略
如果缓存过多,内存沾满了,如何处理 ⇒ 根据配置的策略删除一定的数据 ⇒ 数据淘汰策略
- noeviction:不淘汰,内存满了就不允许写,抛错,是默认的策略
- volatile-ttl:TTL越小,越先被淘汰
- allkeys-randon:全体key,随机淘汰
- volatile-random:设置了TTL的key,随机淘汰
- allkeys-lru:全体key,按LRU算法淘汰
- volatile-lru:设置了TTL的key,按LRU淘汰
- allkeys-lfu:全体key,按LFU算法淘汰
- volatile-lfu:设置了TTL的key,按LFU淘汰

数据库有 1000 万数据 ,Redis 只能缓存 20w 数据,如何保证 Redis 中的数据都是热点数据?
⇒ allkeys-lru策略,挑选最近没怎么使用的数据淘汰,留下热点数据。且如果有指定的需求,可以用volatile-lru + 置顶数据不设置过期时间,以保证这些数据永不被删除
4、主从复制
Redis的三种模式:
- 单机模式
- 集群模式
- 哨兵模式
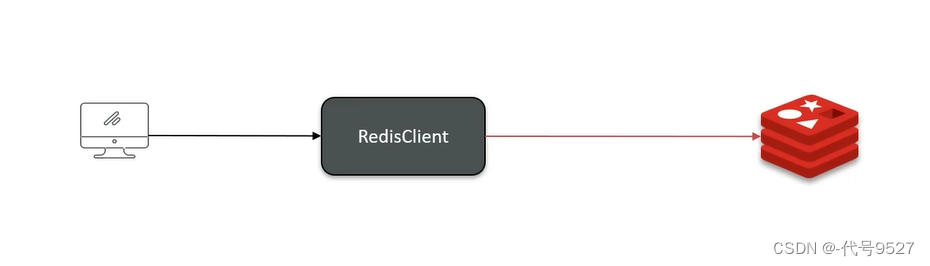
单节点的Redis并发能力有上限,切为Redis主从集群,实现读写分离,提高并发能力(如下,一台服务器又查又写,并为一台写两台查,查的并发上限翻倍):
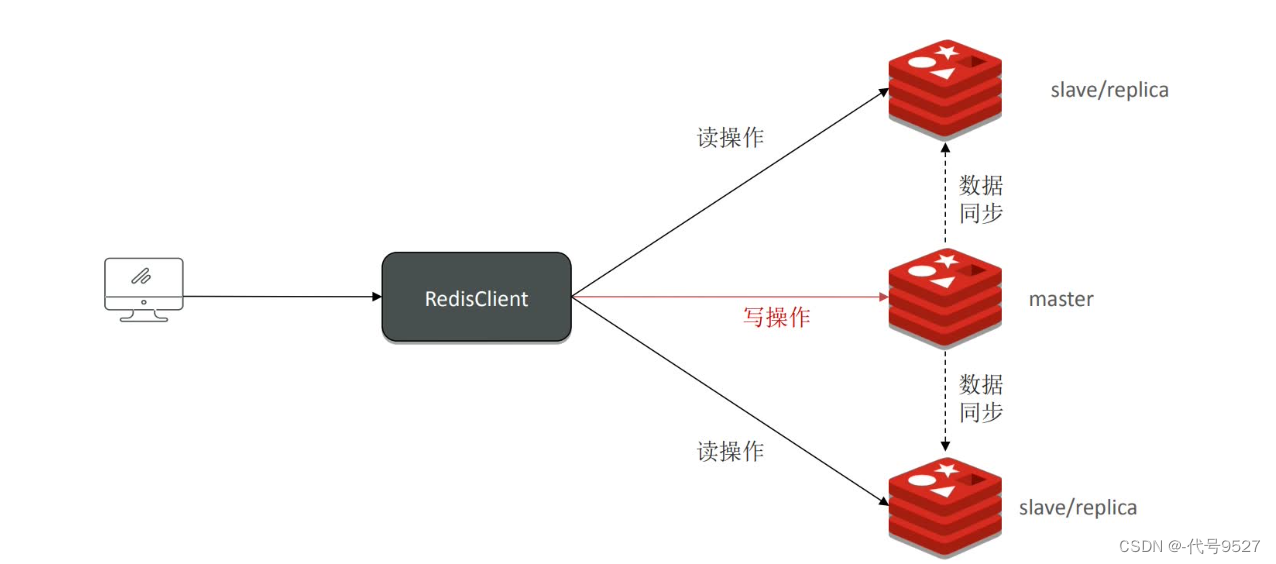
读写分离后,数据的同步方案:
4.1 主从全量同步
-
Replication Id:即replid,数据集的标记,该ID相同则说明对应的数据集是同一个,每个master有唯一的replid,slave会继承master的replid。
-
offset:偏移量,repl_baklog文件记录的数据越多,offset越大
全量同步时,如果master和slave的replid不相等,则master执行basave生成快照给slave去同步。根据前面的写时复制机制,basave期间,master接收到的写请求不会同步到快照文件中,因此,slave加载完快照文件后,还要执行从master收到的repl_baklog文件,该文件记录了basave期间,master额外收到的写指令。

如果replid相等,但master的offset为80,slave的offset为50,则slave把repl_baklog文件50-80的这一段命令再执行一下
4.2 增量同步
常用于slave节点重启后。slave发送自己的replid和offset到master,如果replid不一致,则是第一次同步,后续同全量。

如果replid一致,则不是第一次同步。根据offset发送对应片段的repl_baklog的命令到slave

5、哨兵模式
上面的主从集群,并不能实现高可用,master一挂,丧失写的能力 ⇒ 引入哨兵机制实现主从集群自动故障恢复。哨兵做为Redis集群的一个节点,其作用:
- 节点状态监控:不断检查master、各个slave的健康状况
- 自动故障恢复:如果master故障,则从slave中提升一个出来当master,即使后面master再恢复,也以新的master为主节点
- 通知:集群故障转移后,将新的master、slave信息推到Redis客户端
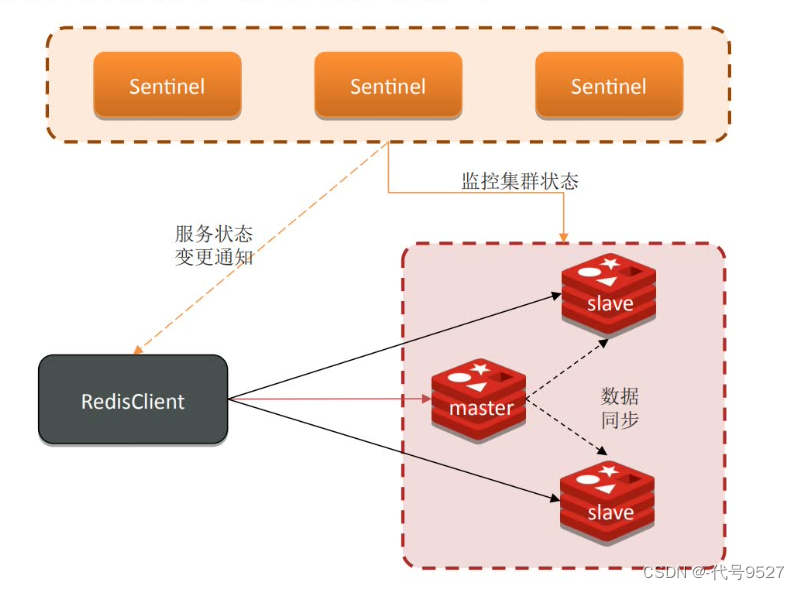
5.1 服务状态监控
哨兵Sentinel基于心跳机制监测节点状态,每1秒向集群每个节点发送ping命令:
- 主观下线:某一个Sentienl发现某节点在规定时间未响应回pong到Sentinel,认为该节点主观下线
- 客观下线:指定数量(常设为Sentienl数量的一半)的Sentintl都认为这个节点主观下线,则该节点客观下线
5.2 哨兵选主规则
- 排除不在线的、响应慢的
- 排除与主节点断开时间长的(断开时间长,读写分离下,数据不全)
- 根据优先级、offset。若slave-prority一样,offset越大,优先级越高
- 看运行ID,越小优先级越高
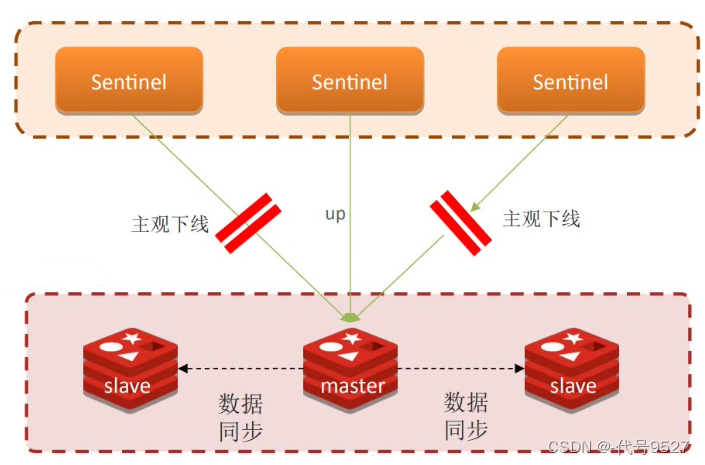
5.3 哨兵模式下,Redis集群的脑裂
下面是一个正常的哨兵模式架构:
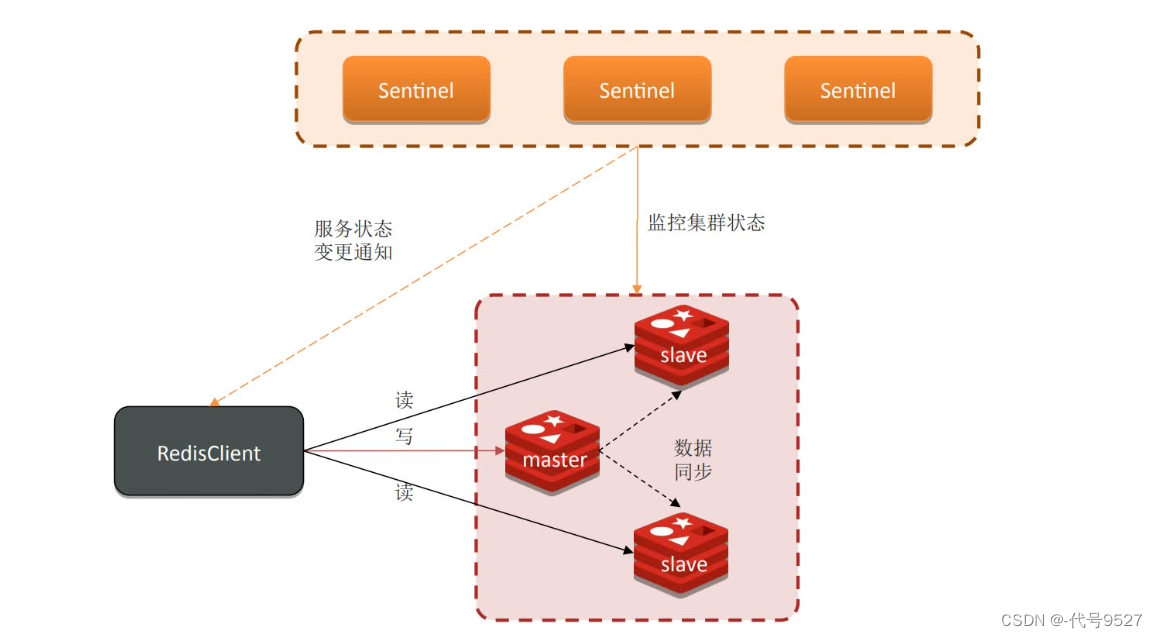
如下,假如Sentinel、master、slave处于不同的网络环境,当Sentinel因网络原因连不上master时,其会去重新选举出一个master。但原来的master客户端是可以连接通的,此时就出现了两个master,即发生了脑裂。
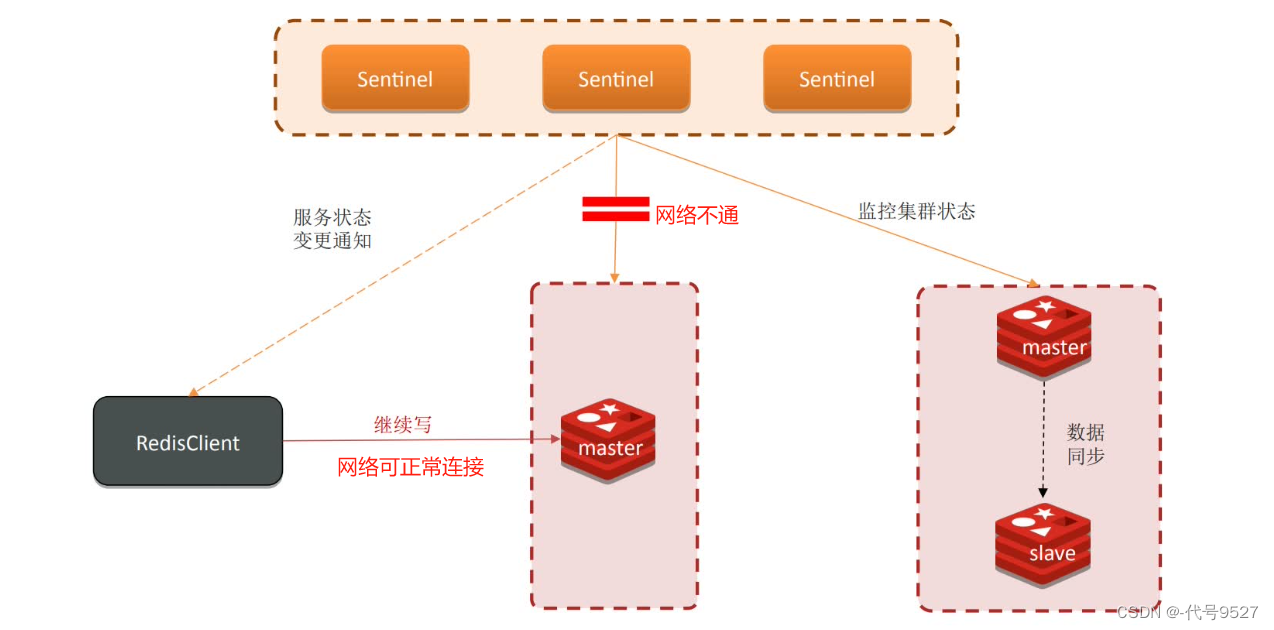
再到后来,网络恢复,原来的master会被降为slave(前面提到的,恢复后,以新master为主节点),并从新的master去同步数据。即清空自己的数据,导入新master的快照文件,如此,脑裂期间,客户端写到master的数据就会丢失。
关于集群脑裂问题的解决,可配置这两个参数:
//最少的slave节点为1个
min-replicas-to-write 1
//数据复制和同步的延迟不能超过5秒
min-replicas-max-lag 5
如此,脑裂时,往旧的master写数据,因其slave数量为0,就会写入失败。且网络恢复后,数据同步也会因延迟过大而报错。
6、分片集群
主从(主写从读)集群和哨兵,解决了高可用、高并发读的问题,但存在两个问题:
- 海量数据的存储问题
- 高并发
写的问题
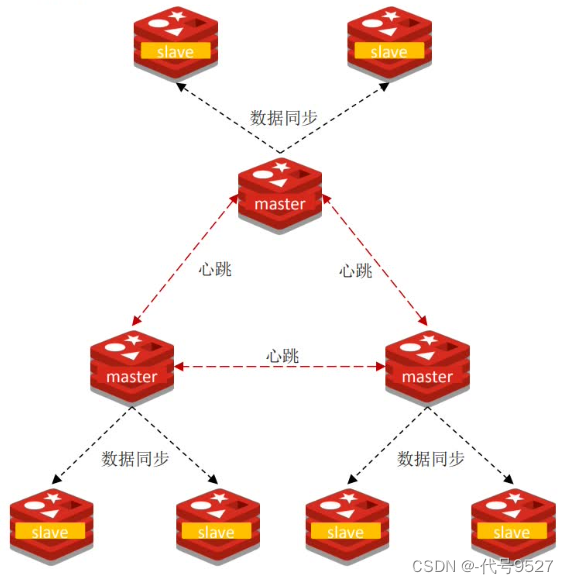
由此 ⇒ Redis分片集群,特点:
- 集群中有多个master,每个master保存不同的数据,由此,每加一个master,并发写的能力就加一段(如从2n到3n)⇒ 解决高并发写
- 每个master有多个slave ⇒ 解决高并发读
- master之间互相ping,以检测健康状态,起到了哨兵的作用。如果多个master都认为某个master挂了,那这个master客观下线 ⇒ 类似哨兵
- 客户端可请求访问集群的任意节点,最终都会被转发到正确的节点上去查写
至于客户端的请求会被转发到正确的节点上去,是通过哈希槽实现。Redis集群引入哈希槽的概念,整个集群有16384个哈希槽。
set或者get某个key ⇒ 这个key通过CRC16校验后,对16384取模来决定放哪个槽 ⇒ 集群每个master负责一定范围的槽
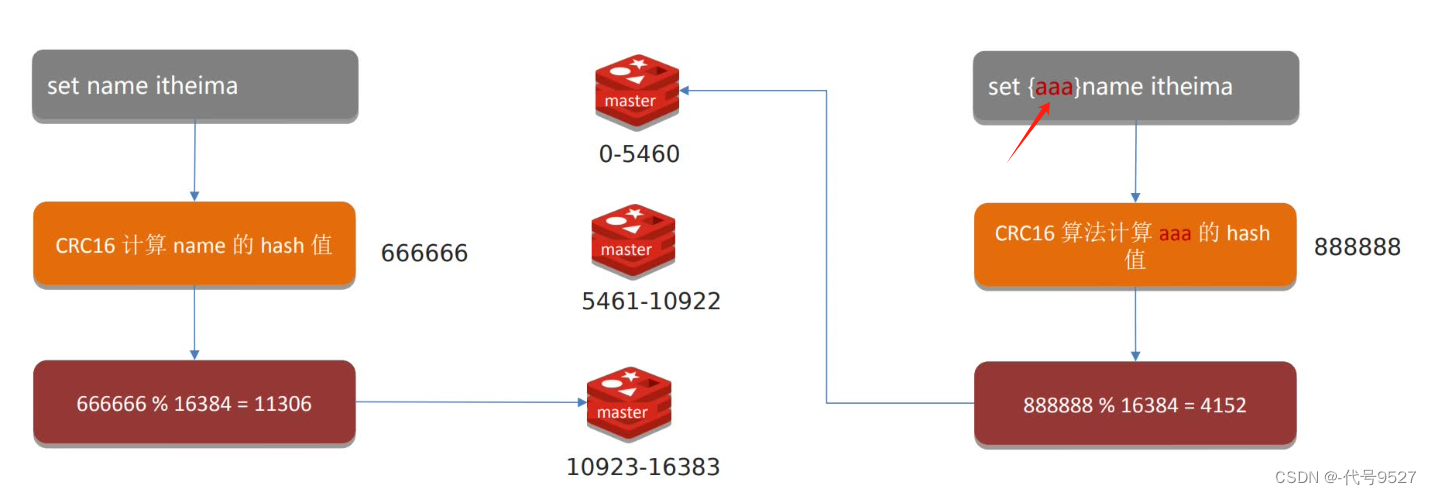
除了key去决定放哪个槽,也可以在key前加个{有效部分},如上面{aaa},如此,这些key就都可以被分到同一个master节点
7、Redis快的原因(IO多路复用 + Redis网络模型)
Redis是单线程的,但为什么还那么快?
- 纯内存操作,执行速度快
- 单线程下,避免了上下文切换,以及线程安全问题的考虑和实现
- 使用了I/O多路复用模型,是非阻塞IO
7.1 用户空间和内核空间
Linux系统中一个进程使用的内存有两部分:
- 用户空间:权限低,不能直接调用系统资源(只能通过内核提供的接口来调用)
- 内核空间:可调用一切系统资源
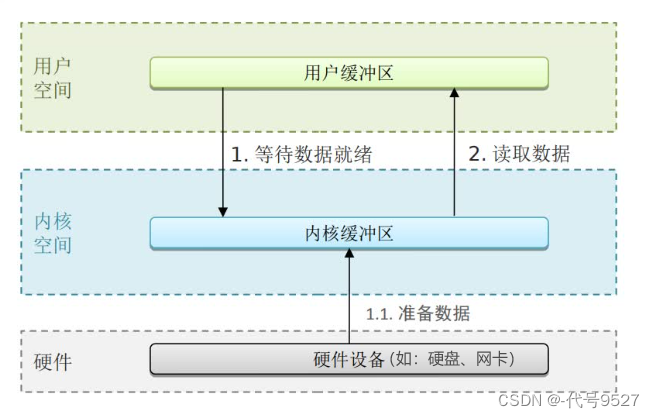
关于以上空间的理解:用户A打开微信给其好友B,发生了一条消息message1。启动微信,即开了一个进程,编辑信息message1,相当于在服务器的用户空间,想发送message1,就要过网卡然后发给用户B。
而用户空间不能直接调用系统资源(硬件网卡),因此整个流程为:把用户缓冲区数据拷贝到内核缓冲区 ⇒ 写入硬件设备。用户B给A回复后,读数据则是:从网卡设备读到内核缓冲区,再拷贝到用户缓冲区。
以上,影响性能的有两个点:
- 用户空间读数据时,要等待内核空间给它,内核空间数据未就绪,就一直空等
- 数据来回拷贝
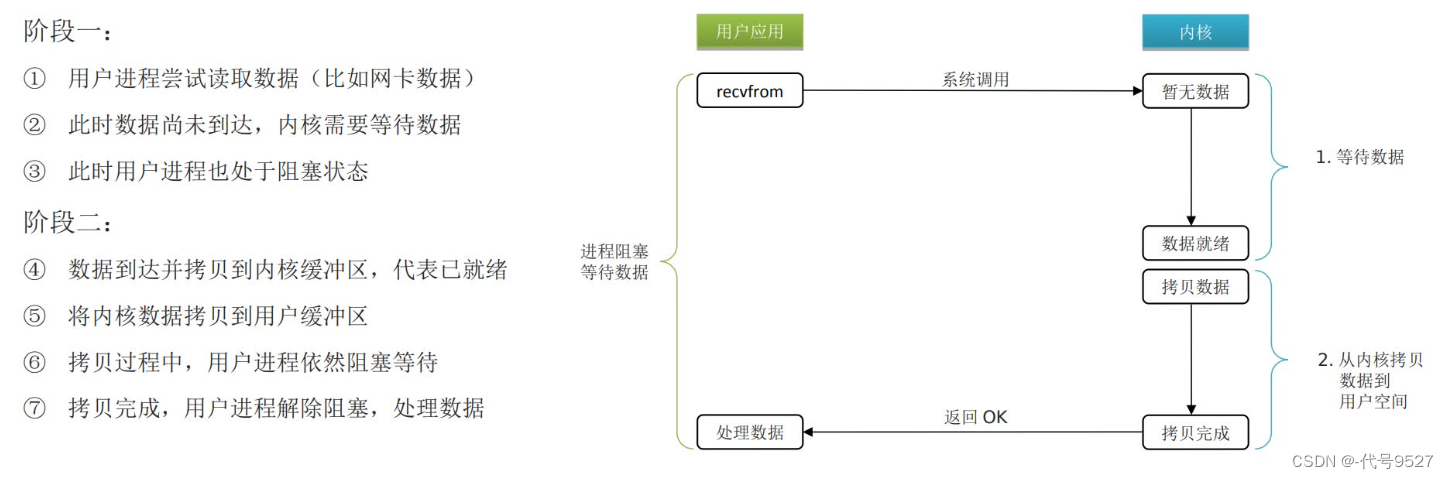
7.2 阻塞IO模型
用户进程在以下两个阶段都被阻塞:
- 阶段1:等待内核从系统硬件资源中去准备数据
- 阶段2:数据从内核空间拷贝到用户空间
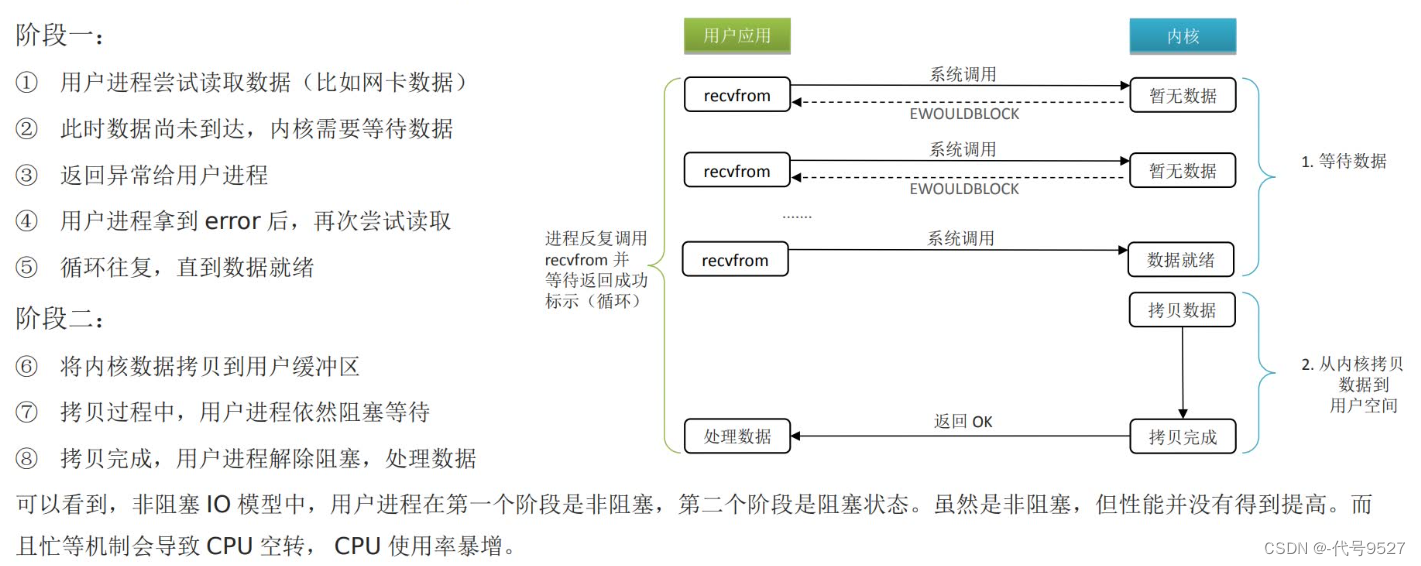
7.3 非阻塞IO模型
用户进程,在阶段一不会被阻塞,如果内核空间没数据,会返回一个异常给用户进程,用户进程可以过会儿再去读。但阶段二,从内核空间拷贝到用户空间的时候,依然阻塞
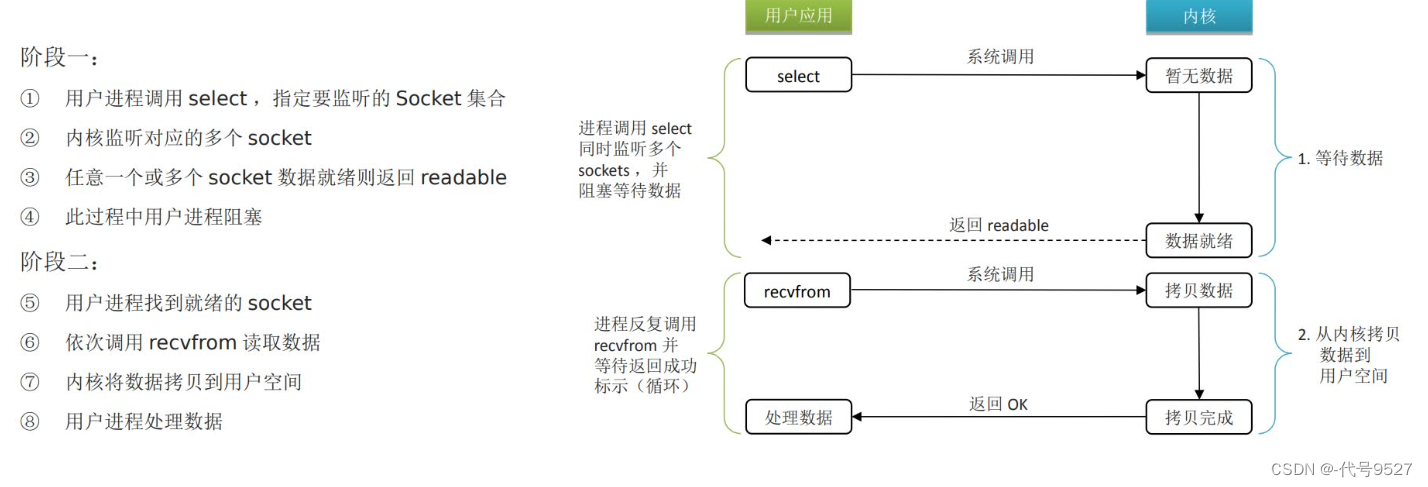
7.4 IO多路复用
单个线程去监听多个Socket,监听的过程,用户线程是阻塞的,但只要出现一个Socket可读或可写,用户线程就会收到通知去干活儿
IO多路复用,监听Socket有多种实现:
- select
- poll
- epoll
以点餐为例,select和poll就像:吧台有一盏灯,底下一群顾客,人手一个按钮,想好吃什么时,按下按钮,吧台灯亮。但此时吧台显示不出具体是哪个顾客要点餐,只是知道有人要点餐了。服务员就得挨个去问,是不是你要点餐?
epoll则是:顾客的按钮不再控制吧台的灯,而是控制吧台的计算机屏幕,顾客按一下,屏幕显示顾客桌号
select 和 poll 只会通知用户进程有 Socket 就绪,但不确定具体是哪个Socket ,需要用户进程逐个遍历 Socket 来确认
epoll 则会在通知用户进程 Socket 就绪的同时,把已就绪的 Socket 写入用户空间
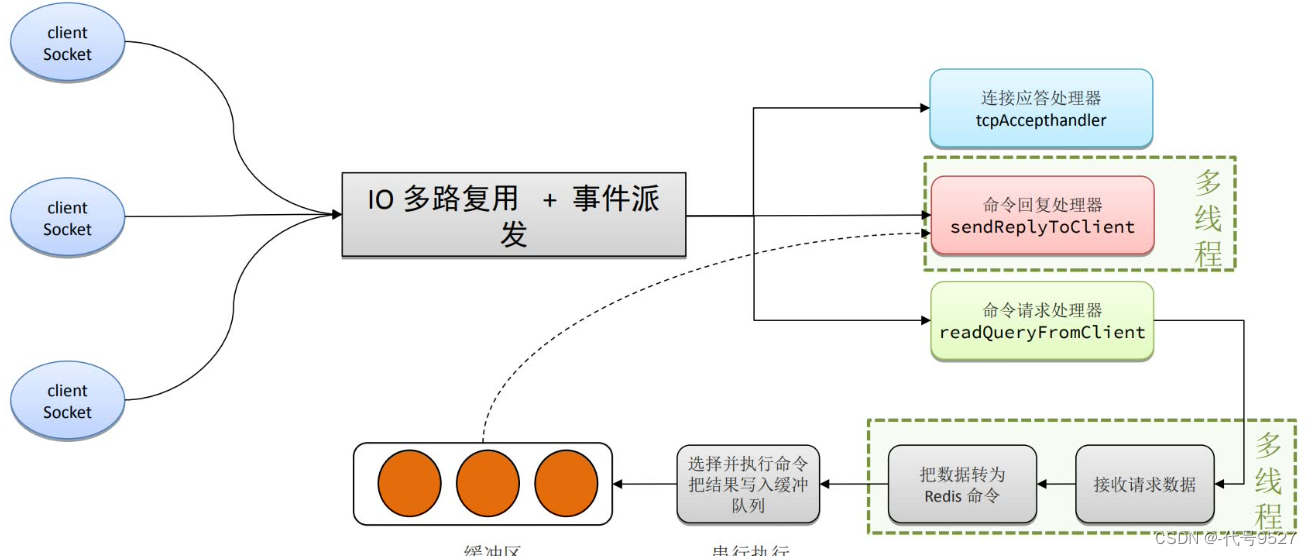
最后,Redis的网络模型,有IO多路复用,用来监听客户端的连接Socket,但每个Socket下做的事可能不一样,有读请求、写请求,因此,Redis再用事件派发机制,转发到对应的处理器
8、面试





