生成式AI的GPU网络技术架构

生成式AI的GPU网络
引言:超大规模企业竞相部署拥有64K+ GPU的大型集群,以支撑各种生成式AI训练需求。尽管庞大Transformer模型与数据集需数千GPU,但实现GPU间任意非阻塞连接或显冗余。如何高效利用资源,成为业界关注焦点。
张量并行
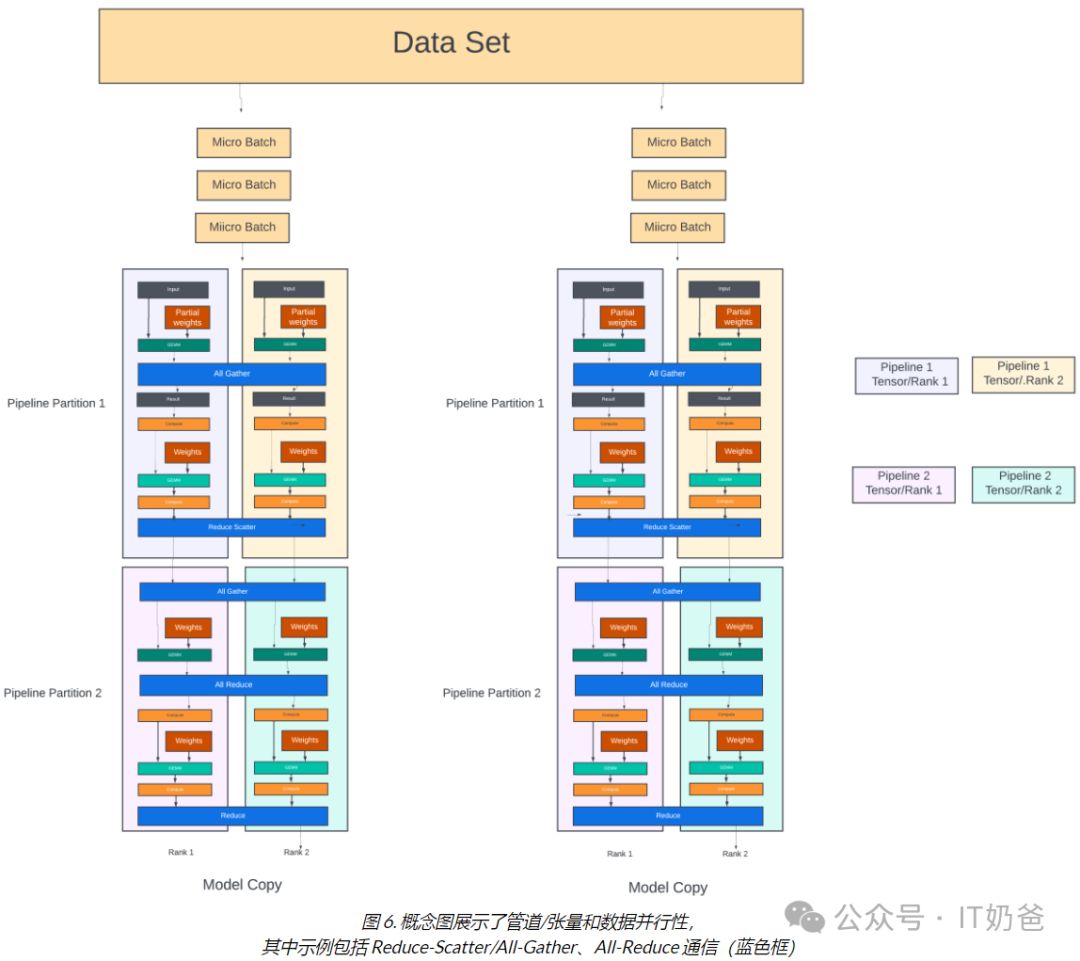
流水线阶段的GEMM操作可跨多GPU分布。张量并行采用2D模型并行(流水线+张量),显著减少流水线深度,从而缩短训练时间。
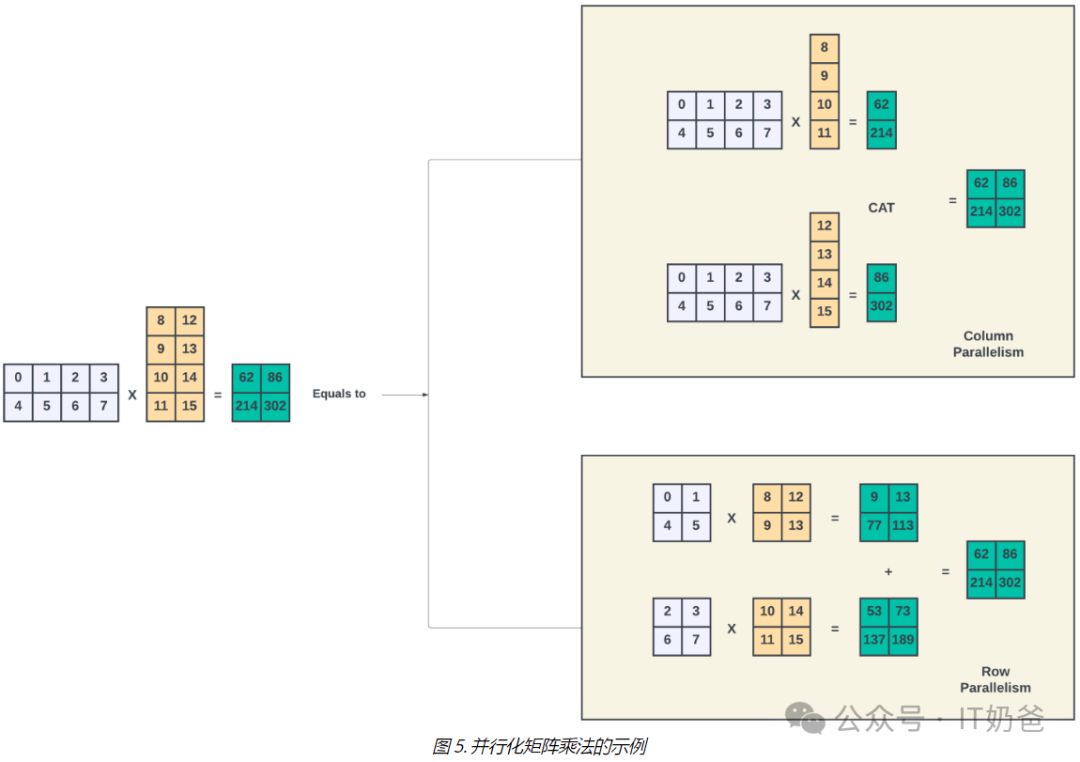
矩阵乘法并行化极为简便。输入矩阵(X)与权重矩阵(Y)相乘时,可轻松拆分为Nt个独立部分,如图5所示,Nt可设为2,显著提升计算效率。
通过张量并行技术,将Nt个部分矩阵乘法高效分配给Nt个离散GPU,需将输入X广播至所有GPU,确保高效并行处理。
GPU间协同工作,通过乘法运算获取结果Zt。张量并行GPU间需共享部分结果,通过列并行连接或行并行加法,汇总得出最终结果Z。这一成果将无缝衔接至后续计算流程,确保高效的数据处理与运算。
每个微批次的Nt GPU之间的all-to-all通信需要高带宽。通信的大小取决于微批次大小和隐藏层(矩阵乘法中使用的权重)的大小。由于高带宽要求,每个流水线中参与张量并行的 GPU 数量通常仅限于 GPU 服务器或节点内的 GPU 数量。这些服务器内 GPU 通过高速 NVlink 和 NVSwitches 连接。
回想一下,当两个 GPU 在服务器内时, H100服务器中的 GPU 到 GPU 带宽是它们在两个不同的服务器上时的 9 倍。
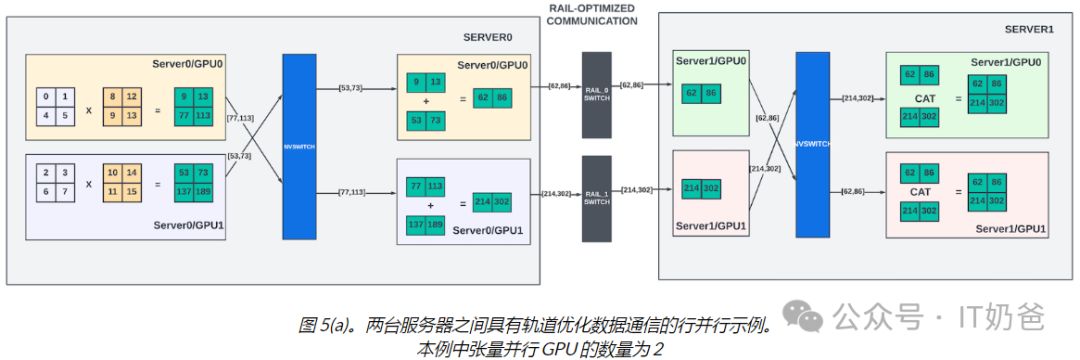
如图6所示,流水线阶段间的GPU交换中间结果时,相邻两个阶段的张量并行组需进行全对全(all-to-all)通信,确保数据高效传递,优化整体计算效率。
在上面的矩阵示例中,如果下一个流水线阶段的 GPU 位于不同的服务器中,Nvidia 不会将最终结果Z广播到下一个流水线阶段的所有张量并行组,而是提供像分散-聚集(scatter-gather)这样的集合,如 Megatron-LM 论文中所述。结果可以在发送端分成大小相等的块,每个 GPU 通过叶交换机将一个块发送到下一个流水线阶段中相同张量等级(轨道)的 GPU(图 5.a)。
因此,如果每个流水线阶段有八个张量并行 GPU,数据通信量可以减少八分之一。使用此方案,在接收端,每个张量并行 GPU 都可以通过 NVlinks 执行所有聚集以获取所有块并计算最终结果Z,然后再将其用于进一步的矩阵乘法。
梯度聚合流量
梯度聚合高效集成各模型副本参数梯度,实现全面优化。所有GPU协同工作,同rank/流水线内的GPU共同参与,确保每模型副本内Nm个GPU在每次迭代中并行执行Nm个梯度聚合线程,每线程含Nd个GPU,显著提升训练效率。
传统上,Ring-All-Reduce 方案以环形模式传递梯度,但速度受限。该方案下,每个GPU依次聚合从上一个GPU接收的梯度与本地计算的梯度,再发送给下一个GPU。这种顺序聚合与传播导致效率低下。为提升性能,需寻求更高效的梯度同步方法。
Nvidia创新推出双二叉树机制,实现梯度聚合的全带宽与对数延迟,大幅提升深度学习训练效率。如需深入了解此技术,请访问:[链接地址],获取详尽的论文解析。掌握前沿科技,引领深度学习新纪元。
二叉树梯度聚合中,各模型副本同阶段GPU形成树状结构。叶节点梯度上传至父节点,并与兄弟节点梯度相加。此过程递归进行,直至根节点完成梯度聚合,实现高效协同计算,优化模型训练效率。
根节点汇总所有梯度后,需逐层向下发送至树中所有节点,以更新模型参数的本地副本。梯度首先由根节点传递至其子节点,随后逐层下传,直至所有节点同步更新完毕。
在双二叉树方法中,使用跨数据并行组的同等级 GPU 构建两个二叉树。第一棵树的叶节点是另一棵树的中间节点。每棵树聚合一半的梯度。如论文所述,在双二叉树中,每个 GPU 最多可以有两个父 GPU 和两个子 GPU,并且性能(训练时间)远优于大型集群中的环形拓扑。对于大型集群,如果仅使用叶交换机即可访问子 GPU 和父 GPU,则部分梯度聚合可以使用叶交换机进行。但梯度聚合(或数据并行流量)还需要使用主干/聚合交换机来聚合所有无法通过叶交换机访问的数据并行 GPU 等级。
树形结构虽延迟低,但易在网络中产生2对1和1对2流量模式,可能引发短暂拥塞。相比之下,Ring-all-reduce的1对1流量模式更受超大规模网络运营商青睐,有效减少主干-叶子流量,保持网络高效流畅。
GPU 内存优化
GPU内存高效存储流水线/张量分区的参数、梯度、优化器状态、中间激活及输入数据,同时提供临时空间支持高效计算。
混合精度训练中,参数、梯度和优化器状态存储需求约(4*P + 12*P),采用Adam优化器时。对于拥有1万亿参数的模型,其存储空间需求高达24TB,展现了显著的存储挑战。
中间激活在反向传递中占用额外空间,与批大小和隐藏层大小成正比。通过重新计算激活,虽减少内存需求但增加计算量。对于输入激活,需1-2TB内存存储。然而,内存碎片等问题导致暂存空间增加和效率低下,需优化内存管理策略以提升性能。
GPT-4模型以1.5万亿参数傲视群雄,其32TB内存展现卓越性能,效率高达75%。若每个GPU拥有80GB容量,则400个GPU即可承载其一个模型副本,彰显强大算力。
针对Nd模型副本,优化内存的有效方法是仅在每个副本中存储部分参数、梯度和优化器状态。通过GPU间动态获取参数/状态,即“分片”技术,虽增加通信开销,但显著降低内存占用和所需GPU数量。微软研究显示,100B参数模型已通过分片优化。对于GPT-4等万亿参数模型,分片对GPU规模的影响尚待探究。
GPU-GPU 流量要点
- 流水线分区的张量并行GPU通信需高带宽,模型分区框架应优先保持其于同一服务器节点内,确保高效通信。
- 分散-聚集法大幅减少张量并行GPU在不同服务器间流水线阶段的通信量。通过轨道优化拓扑连接,GPU服务器实现高效流水线并行流量传输。特别地,各服务器中第N个GPU能经第N个叶交换机(轨道交换机)以无阻带宽互通,显著提升通信效率。
- 数据并行流量实现梯度聚合,通过所有并行组中的GPU间进行。这种分层树聚合形成了多种2对1或1对2的流量模式,传输量随GPU等级中存储参数量递增,高效处理大数据量。
- 集群GPU的数据/张量及模型并行划分后,每次训练迭代均重复通信模式。次优分区导致的拥塞、长尾延迟等问题会在迭代中累积,影响作业完成时间。
- 分片参数于所有数据并行GPU上,可大幅减少集群GPU数量,虽增数据并行通信,但显著缩小集群规模,提升效率。
状态空间/划分方法
决定张量、管道和数据并行 GPU 的最佳组合的状态空间很大,并且取决于许多因素。
- GPU组过多导致梯度聚合通信量剧增,影响迭代效率,流水线停顿降低GPU利用率。针对特定批次大小,过多数据并行组会缩减小批次和微批次大小,进而无法充分利用GPU计算资源,因为计算量与微批次大小直接相关。优化并行组配置,提高GPU资源利用率至关重要。
- 增大微批量(Bu)数量可显著减少流水线刷新停滞影响,但同时微批量大小会相应减小,可能引发GPU计算利用率不足。在优化时需权衡两者,确保高效利用资源。
- 当张量并行组GPU超过8个时,需依赖低带宽连接与叶交换机传输高带宽流量,导致性能瓶颈。为避免此问题,多数模型分区方法均致力于将GPU数量控制在每台服务器的可用范围内。
- Nvidia的Super POD震撼发布,搭载高达256个GPU,通过NV交换机GH200的层次结构高效互联。此系统强大到支持超过八个张量并行GPU,引领计算性能新纪元。
- 模型状态分片虽使GPU间通信量增1.5倍,但显著减少所需GPU总数,整体优化训练时间与成本,提升效率。
高效利用GPU集群是一大挑战,手动划分模型至多GPU以满足内存限制并最大化计算能力极为困难。Nvidia的开源框架(Alpa/Ray)能自动执行状态空间搜索,并考虑集群拓扑,实现智能优化。
NVIDIA Collective Communications Library(NCCL)针对特定集体操作,构建了高效跨GPU和节点的环或树结构,旨在减少争用、最大化吞吐量。其拓扑和通信模式专为集体操作优化,确保计算性能卓越。
服务器间流量
训练期间,服务器间流量利用GPU Direct RDMA技术,高效传输数据(中间结果、梯度等)于不同GPU内存间。GPU Direct RDMA是RDMA技术的进阶版,突破性地实现了GPU内存与远程设备间的直接数据交换,无需主机CPU介入,极大提升了数据传输效率。
以太网广泛普及,交换机/路由器生态系统丰富,超大规模企业和公共数据中心纷纷投资构建以太网架构。其中,RoCEv2(基于融合以太网/IP的RDMA)承载服务器间流量,其交换/路由方式与常规IP流量无异,为数据中心带来高效、稳定的网络体验。
RDMA 写入涉及以下步骤
优化后内容:在GPU/流间建立队列对(QP),通过带外通信共享QP信息,整个训练期间仅需一次设置,高效便捷。
2 - 将 QP 转换为准备状态以发送/接收交易
3 - 准备 RDMA 进行写入(发送方/接收方内存地址、传输大小)
RDMA网络接口卡(NIC)在发送服务器上接管,从特定GPU内存中读取数据,并高效地通过网络传输至目标服务器。其独特地利用GPU结构的MTU大小,将数据传输优化为网络上的多个高效事务。
QP中,每个RDMA操作(写入/读取/发送/接收)均由发送方分配唯一序列号,确保接收方精准检测丢失操作。传统RDMA NIC中,数据包不重排,序列号缺失即触发接收方暂停接收,并请求发送方从断点重传全部数据包,即回退N次重传。此法效率低下,既耗带宽又增延迟。
一些 NIC 支持选择性 NACK,它们请求仅重新传输丢失的数据包。一些 NIC(如 Nvidia 的 ConnectX NIC)允许网络对数据包进行重新排序(有限重新排序)。在此模式下,NIC 将操作无序(OOO)直接写入 GPU 内存,而不会触发向发送方的重新传输。NIC 内部的硬件可以使用位图跟踪最多 N 个操作(N 对应于带宽延迟乘积或 RTT),并按顺序将元数据传送给 GPU。此机制巧妙地使用 GPU 内存来存储 OOO 数据包,并且可以在不占用 NIC 内存空间的情况下实现。
-对此,您有什么看法见解?-
-欢迎在评论区留言探讨和分享。-