代码随想录算法day16 | 二叉树part06 | 654.最大二叉树,617.合并二叉树,700.二叉搜索树中的搜索,98.验证二叉搜索树
654.最大二叉树
力扣题目地址(opens new window)
给定一个不含重复元素的整数数组。一个以此数组构建的最大二叉树定义如下:
- 二叉树的根是数组中的最大元素。
- 左子树是通过数组中最大值左边部分构造出的最大二叉树。
- 右子树是通过数组中最大值右边部分构造出的最大二叉树。
通过给定的数组构建最大二叉树,并且输出这个树的根节点。
示例 :
提示:
给定的数组的大小在 [1, 1000] 之间。

构造树一般采用的是前序遍历,因为先构造中间节点,然后递归构造左子树和右子树。
确定递归函数的参数和返回值
参数传入的是存放元素的数组,返回该数组构造的二叉树的头结点。
代码如下:
public TreeNode constructMaximumBinaryTree(int[] nums)确定终止条件
题目中说了输入的数组大小一定是大于等于1的,所以我们不用考虑小于1的情况,那么当递归遍历的时候,如果传入的数组大小为1,说明遍历到了叶子节点了。
那么应该定义一个新的节点,并把这个数组的数值赋给新的节点,然后返回这个节点。 这表示一个数组大小是1的时候,构造了一个新的节点,并返回。
代码如下:
TreeNode node = new TreeNode();
if (nums.size() == 1) {node.val = nums[0];return node;
}
确定单层递归的逻辑
这里有三步工作
-
先要找到数组中最大的值和对应的下标, 最大的值构造根节点,下标用来下一步分割数组
-
最大值所在的下标左区间构造左子树
-
最大值所在的下标右区间构造右子树
由此分析之后,稍加优化在整体代码如下所示:
将每次都要创建新数组改成了通过下标索引直接在原数组上进行操作
优化后在代码允许空数组进入递归,所以结束条件也要对应增加判断空数组在返回情况
class Solution {public TreeNode constructMaximumBinaryTree(int[] nums) {return constructMaximumBinaryTree1(nums, 0, nums.length);}public TreeNode constructMaximumBinaryTree1(int[] nums, int leftIndex, int rightIndex) {if (rightIndex - leftIndex < 1) {// 没有元素了return null;}if (rightIndex - leftIndex == 1) {// 只有一个元素return new TreeNode(nums[leftIndex]);}int maxIndex = leftIndex;// 最大值所在位置int maxVal = nums[maxIndex];// 最大值for (int i = leftIndex + 1; i < rightIndex; i++) {if (nums[i] > maxVal){maxVal = nums[i];maxIndex = i;}}TreeNode root = new TreeNode(maxVal);// 根据maxIndex划分左右子树root.left = constructMaximumBinaryTree1(nums, leftIndex, maxIndex);root.right = constructMaximumBinaryTree1(nums, maxIndex + 1, rightIndex);return root;}
}总结
注意类似用数组构造二叉树的题目,每次分隔尽量不要定义新的数组,而是通过下标索引直接在原数组上操作,这样可以节约时间和空间上的开销。
可能会疑惑,什么时候递归函数前面加if,什么时候不加if,这个问题我在最后也给出了解释。
其实就是不同代码风格的实现,一般情况来说:如果让空节点(空指针)进入递归,就不加if,如果不让空节点进入递归,就加if限制一下, 终止条件也会相应的调整。
617.合并二叉树
优先掌握递归
力扣题目链接(opens new window)
给定两个二叉树,想象当你将它们中的一个覆盖到另一个上时,两个二叉树的一些节点便会重叠。
你需要将他们合并为一个新的二叉树。合并的规则是如果两个节点重叠,那么将他们的值相加作为节点合并后的新值,否则不为 NULL 的节点将直接作为新二叉树的节点。
示例 1:

注意: 合并必须从两个树的根节点开始。
递归
二叉树使用递归,就要想使用前中后哪种遍历方式?
本题使用哪种遍历都是可以的!
我们下面以前序遍历为例。
动画如下:

那么我们来按照递归三部曲来解决:
确定递归函数的参数和返回值
首先要合入两个二叉树,那么参数至少是要传入两个二叉树的根节点,返回值就是合并之后二叉树的根节点。
代码如下:
public TreeNode mergeTrees(TreeNode t1, TreeNode t2)
确定终止条件
因为是传入了两个树,那么就有两个树遍历的节点 t1 和 t2,如果 t1 == NULL 了,两个树合并就应该是 t2 了(如果 t2 也为NULL也无所谓,合并之后就是NULL)。
反过来如果 t2 == NULL,那么两个数合并就是 t1(如果t1也为NULL也无所谓,合并之后就是NULL)。
代码如下:
if (t1 == null) return t2; // 如果t1为空,合并之后就应该是t2
if (t2 == null) return t1; // 如果t2为空,合并之后就应该是t1
确定单层递归的逻辑
单层递归的逻辑就比较好写了,这里我们重复利用一下 t1 这个树,t1 就是合并之后树的根节点(就是修改了原来树的结构)。
那么单层递归中,就要把两棵树的元素加到一起。
t1.val += t2.val;
接下来 t1 的左子树是:合并 t1 左子树 t2 左子树之后的左子树。
t1 的右子树:是 合并 t1 右子树 t2 右子树之后的右子树。
最终t1就是合并之后的根节点。
代码如下:
t1.left = mergeTrees(t1.left, t2.left);
t1.right = mergeTrees(t1.right, t2.right);
return t1;
此时前序遍历,完整代码就写出来了,如下:
class Solution {// 递归public TreeNode mergeTrees(TreeNode root1, TreeNode root2) {if (root1 == null) return root2;if (root2 == null) return root1;root1.val += root2.val;root1.left = mergeTrees(root1.left,root2.left);root1.right = mergeTrees(root1.right,root2.right);return root1;}
}但是前序遍历是最好理解的,我建议大家用前序遍历来做就OK。
如上的方法修改了t1的结构,当然也可以不修改t1和t2的结构,重新定义一个树。
class Solution {public TreeNode mergeTrees(TreeNode t1, TreeNode t2) {if (t1 == NULL) return t2;if (t2 == NULL) return t1;// 重新定义新的节点,不修改原有两个树的结构TreeNode root = new TreeNode();root.val = t1.val + t2.val;root.left = mergeTrees(t1.left, t2.left);root.right = mergeTrees(t1.right, t2.right);return root;}
}迭代法
使用迭代法,如何同时处理两棵树呢?
本题使用队列,模拟的层序遍历,代码如下:
class Solution {// 使用队列迭代public TreeNode mergeTrees(TreeNode root1, TreeNode root2) {if (root1 == null) return root2;if (root2 == null) return root1;Queue<TreeNode> queue = new LinkedList<>();queue.offer(root1);queue.offer(root2);while (!queue.isEmpty()) {TreeNode node1 = queue.poll();TreeNode node2 = queue.poll();// 此时两个节点一定不为空,val相加node1.val = node1.val + node2.val;// 如果两棵树左节点都不为空,加入队列if (node1.left != null && node2.left != null) {queue.offer(node1.left);queue.offer(node2.left);}// 如果两棵树右节点都不为空,加入队列if (node1.right != null && node2.right != null) {queue.offer(node1.right);queue.offer(node2.right);}// 若node1的左节点为空,直接赋值.root2为空时不需要对root1做改变,所以不需要进行判断if (node1.left == null && node2.left != null) {node1.left = node2.left;}// 若node1的右节点为空,直接赋值if (node1.right == null && node2.right != null) {node1.right = node2.right;}}return root1;}
}同样也可以使用栈来解决这道题
注意这里用栈就要关注进栈的顺序问题:右节点比左节点更先入栈;push顺序要和poll顺序相反
其他与队的解法一模一样
class Solution {// 使用栈迭代public TreeNode mergeTrees(TreeNode root1, TreeNode root2) {if (root1 == null) {return root2;}if (root2 == null) {return root1;}Stack<TreeNode> stack = new Stack<>();stack.push(root2);stack.push(root1);while (!stack.isEmpty()) {TreeNode node1 = stack.pop();TreeNode node2 = stack.pop();node1.val += node2.val;if (node2.right != null && node1.right != null) {stack.push(node2.right);stack.push(node1.right);} else {if (node1.right == null) {node1.right = node2.right;}}if (node2.left != null && node1.left != null) {stack.push(node2.left);stack.push(node1.left);} else {if (node1.left == null) {node1.left = node2.left;}}}return root1;}
}总结
合并二叉树,也是二叉树操作的经典题目,如果没有接触过的话,其实并不简单,因为我们习惯了操作一个二叉树,一起操作两个二叉树,还会有点懵懵的。
这不是我们第一次操作两棵二叉树了,在101.对称二叉树中也一起操作了两棵二叉树。
迭代法中,一般一起操作两个树都是使用队列模拟类似层序遍历,同时处理两个树的节点,这种方式最好理解,如果用模拟递归的思路的话,要复杂一些。
700.二叉搜索树中的搜索
力扣题目地址(opens new window)
给定二叉搜索树(BST)的根节点和一个值。 你需要在BST中找到节点值等于给定值的节点。 返回以该节点为根的子树。 如果节点不存在,则返回 NULL。
例如,
在上述示例中,如果要找的值是 5,但因为没有节点值为 5,我们应该返回 NULL。

之前讲的都是普通二叉树,那么接下来看看二叉搜索树。
二叉搜索树是一个有序树:
- 若它的左子树不空,则左子树上所有结点的值均小于它的根结点的值;
- 若它的右子树不空,则右子树上所有结点的值均大于它的根结点的值;
- 它的左、右子树也分别为二叉搜索树
这就决定了,二叉搜索树,递归遍历和迭代遍历和普通二叉树都不一样。
本题,其实就是在二叉搜索树中搜索一个节点。那么我们来看看应该如何遍历。
递归法
确定递归函数的参数和返回值
递归函数的参数传入的就是根节点和要搜索的数值,返回的就是以这个搜索数值所在的节点。
代码如下:
public TreeNode searchBST(TreeNode root, int val)
1
- 确定终止条件
如果root为空,或者找到这个数值了,就返回root节点。
if (root == NULL || root->val == val) return root;
确定单层递归的逻辑
看看二叉搜索树的单层递归逻辑有何不同。
因为二叉搜索树的节点是有序的,所以可以有方向的去搜索。
如果root.val > val,搜索左子树,如果root.val < val,就搜索右子树,最后如果都没有搜索到,就返回NULL。
代码如下:
TreeNode result = NULL;
if (root.val > val) result = searchBST(root.left, val);
if (root.val < val) result = searchBST(root.right, val);
return result;
很多人写递归函数的时候习惯直接写 searchBST(root.left, val),却忘了递归函数还有返回值。
递归函数的返回值是什么?
左子树如果搜索到了val,要将该节点返回。 如果不用一个变量将其接住,那么返回值不就没了。
所以要 result = searchBST(root.left, val)
所以完整代码如下:
class Solution {// 递归,利用二叉搜索树特点,优化public TreeNode searchBST(TreeNode root, int val) {if (root == null || root.val == val) {return root;}if (val < root.val) {return searchBST(root.left, val);} else {return searchBST(root.right, val);}}
}迭代法
一提到二叉树遍历的迭代法,可能立刻想起使用栈来模拟深度遍历,使用队列来模拟广度遍历。
对于二叉搜索树可就不一样了,因为二叉搜索树的特殊性,也就是节点的有序性,可以不使用辅助栈或者队列就可以写出迭代法。
对于一般二叉树,递归过程中还有回溯的过程,例如走一个左方向的分支走到头了,那么要调头,在走右分支。
而对于二叉搜索树,不需要回溯的过程,因为节点的有序性就帮我们确定了搜索的方向。
例如要搜索元素为3的节点,我们不需要搜索其他节点,也不需要做回溯,查找的路径已经规划好了。
中间节点如果大于3就向左走,如果小于3就向右走,如图:
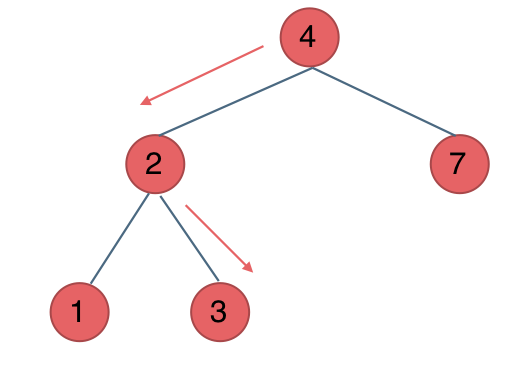
所以迭代法代码如下:
第一次看到了如此简单的迭代法,是不是感动的痛哭流涕,哭一会~
总结
本题我们介绍了二叉搜索树的遍历方式,因为二叉搜索树的有序性,遍历的时候要比普通二叉树简单很多。
但是一些同学很容易忽略二叉搜索树的特性,所以写出遍历的代码就未必真的简单了。
所以针对二叉搜索树的题目,一样要利用其特性。
递归和迭代两种方式,写法都非常简单,就是利用了二叉搜索树有序的特点。
98.验证二叉搜索树
力扣题目链接(opens new window)
给定一个二叉树,判断其是否是一个有效的二叉搜索树。
假设一个二叉搜索树具有如下特征:
- 节点的左子树只包含小于当前节点的数。
- 节点的右子树只包含大于当前节点的数。
- 所有左子树和右子树自身必须也是二叉搜索树。

要知道中序遍历下,输出的二叉搜索树节点的数值是有序序列。
有了这个特性,验证二叉搜索树,就相当于变成了判断一个序列是不是递增的了。
递归法
可以递归中序遍历将二叉搜索树转变成一个数组
然后只要比较一下,这个数组是否是有序的,注意二叉搜索树中不能有重复元素
以上思路中,我们把二叉树转变为数组来判断,是最直观的,但其实不用转变成数组,可以在递归遍历的过程中直接判断是否有序。
这道题目比较容易陷入两个陷阱:
- 陷阱1
不能单纯的比较左节点小于中间节点,右节点大于中间节点就完事了。
写出了类似这样的代码:
if (root.val > root.left.val && root.val < root.right.val) {return true;
} else {return false;
}
我们要比较的是 左子树所有节点小于中间节点,右子树所有节点大于中间节点。所以以上代码的判断逻辑是错误的。
例如: [10,5,15,null,null,6,20] 这个case:
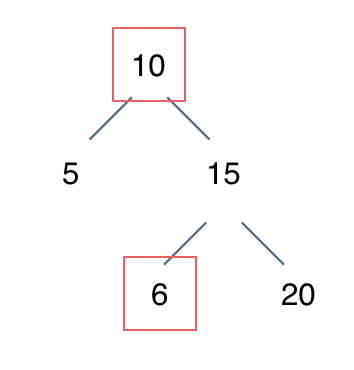
节点10大于左节点5,小于右节点15,但右子树里出现了一个6 这就不符合了!
- 陷阱2
样例中最小节点可能是 int 的最小值,如果这样使用最小的 int 来比较也是不行的。
此时可以初始化比较元素为 long 的最小值。
了解这些陷阱之后我们来看一下代码应该怎么写:
递归三部曲:
- 确定递归函数,返回值以及参数
要定义一个 long 的全局变量,用来比较遍历的节点是否有序,因为后台测试数据中有 int 最小值,所以定义为 long 的类型,初始化为 long 最小值。
注意递归函数要有bool类型的返回值, 只有寻找某一条边(或者一个节点)的时候,递归函数会有bool类型的返回值。
我们在寻找一个不符合条件的节点,如果没有找到这个节点就遍历了整个树,如果找到不符合的节点了,立刻返回。
代码如下:
ong maxVal = LONG.MIN_VALUE; // 因为后台测试数据中有int最小值
public bool isValidBST(TreeNode root)
- 确定终止条件
如果是空节点是不是二叉搜索树呢?
是!二叉搜索树也可以为空!
代码如下:
if (root == null) return true;
- 确定单层递归的逻辑
中序遍历,一直更新maxVal,一旦发现maxVal >= root.val,就返回false,注意元素相同时候也要返回false。
代码如下:
bool left = isValidBST(root.left); // 左// 中序遍历,验证遍历的元素是不是从小到大
if (maxVal < root.val) maxVal = root.val; // 中
else return false;bool right = isValidBST(root.right); // 右
return left && right;最后我们再优化一下这段代码,结果如下:
class Solution {public boolean isValidBST(TreeNode root) {return validBST(Long.MIN_VALUE, Long.MAX_VALUE, root);}boolean validBST(long lower, long upper, TreeNode root) {if (root == null) return true;if (root.val <= lower || root.val >= upper) return false;return validBST(lower, root.val, root.left) && validBST(root.val, upper, root.right);}
}迭代法
可以用迭代法模拟二叉树中序遍历
迭代法中序遍历稍加改动就可以了,代码如下:
class Solution {// 迭代public boolean isValidBST(TreeNode root) {if (root == null) {return true;}Stack<TreeNode> stack = new Stack<>();TreeNode pre = null;while (root != null || !stack.isEmpty()) {while (root != null) {stack.push(root);root = root.left;// 左}// 中,处理TreeNode pop = stack.pop();if (pre != null && pop.val <= pre.val) {return false;}pre = pop;root = pop.right;// 右}return true;}
}