算法图解笔记(整合)
文章目录
- 第一章 算法简介
- 1.二分查找
- 2.大O表示法
- 第二章 选择排序
- 1.数组和链表
- 2.排序
- 第三章 递归
- 1.栈和队列
- 2.递归
- 基线条件和递归条件
- 调用栈
- 递归调用栈
- 尾递归
- 分而治之D&C
- 第五章 散列表
- 散列函数、散列表
- 冲突
- 第六章 图搜索算法
- 图
- 广度优先搜索
- 狄克斯特拉算法
- 贝尔曼-福德算法
- 第八章 贪婪算法
- 例子1:集合覆盖
- 动态规划
- 例子2:偷东西
- 最长公共子串
- 最长公共子序列
- 第十章 K临近算法
第一章 算法简介
1.二分查找
适用于有序列表,速度O(logn).
二分查找就是,设定一个low值,一个high值,当low<=high,每次比较target和中间的值,如果中间的值大,就调整high值,如果中间的值小就调整low值。直到找到target,返回他的位置。
2.大O表示法
不是以s为单位,O(n)n表示操作数,这个值衡量了算法运行时间的增速,也就是当n增加的时候运算时间增加多少。他表示的是最糟情况。
常量是一个算法需要的固定时间,一般来说如果操作数不同,常量可以忽略,但有时常量也有很大影响。二分查找的常量大于简单查找,但是因为操作数小的多所以在数据很大的时候二分查找速度快。
第二章 选择排序
1.数组和链表
内存工作原理:就像在抽屉里存东西,地址是抽屉,数据是物品。
数组存放数据地址必须相连,如果东西放的太多现有的空位放不下了就得换位置。
解决方法是预留空位,即使只带了两样东西也留出十个位置,这样浪费内存;放满了以后再转移到有20个空位的位置。
好处是可以随时读取。数组的元素类型必须相同(存东西的时候,不同尺寸的东西不能放在同一组抽屉里)
链表地址无需相连,在每个地址中都存放了下一个数据的地址,像解谜一样打开一个抽屉能看到下一个抽屉的位置。但是这样就不能随时访问,要找一个东西就得挨个找。优点:插入和删除很快
2.排序
选择排序:遍历所有元素,找出最大值放在以一个,然后再遍历找出剩下的最大值…O(nn)
快速排序:一种D&C方法。随机选一个元素a,遍历所有元素,比a小的放在less子序列里,比a大的放在greater子序列里。然后再对子序列快速排序。经过2的n次幂操作能把序列分完,每次操作都要遍历一次n,所以O(nlogn)。基线条件是,子序列长度为0或1。
第三章 递归
1.栈和队列
栈 只有两种操作:压入和弹出。先进后出
队列 只有两种操作:入队和出队。先进先出
"""
创建双端队列
"""
from collections import deque
search_queue = deque()
search_queue += list #向队列中添加列表中的元素
2.递归
基线条件和递归条件
为了防止无限循环,必须要有基线条件。if 基线条件:return,else:调用自己。
调用栈
程序调用函数就是调用栈,调用栈是一个这样的结构:读到一个函数就压入这个函数,然后运行,读到下一个函数就压入这个函数,然后运行,运行完一个函数就弹出这个函数,没有别的事做再弹出之前的函数。
递归调用栈
类比:从大盒子里找小盒子。
函数调用信息一直存储在栈里,占用大量内存,尾递归可以解决这个问题
尾递归
待学习!!!!!
分而治之D&C
这是一种递归思路,而不是方法:一个复杂的问题,不断分解直到满足基线条件。例如分土地,基线条件是一条边是另一条边的两倍。
基线条件往往是数组为空或只包含一个元素。
第五章 散列表
散列函数、散列表
散列函数将不同的数据映射成不同的数字,相同的数据映射成相同的数字。好的标准:均匀分布,没有冲突。
散列表:给一个数组,给一些数据(键),用散列函数生成一系列数字(存储位置),把键对应的值存到数组里,索引是散列函数生成的数字。在python中字典就是散列表。查找插入删除都很快,适用于创建映射、缓存数据、检查数据是否存在。
冲突
冲突:散列函数给两个键分配的存储位置相同。
解决方法:在冲突的索引处存一个链表。链表短的话查找速度还行,长的话查找速度又慢了。
填装因子:散列表存的数据数/位置总数,这个值越大说明散列表越被充分利用。
填装因子>1以后需要换位置(同数组),一般来说填装因子>0.7就换位置。
第六章 图搜索算法
图
图模拟了数据的依赖关系,无向图就是环。邻居关系可以用散列表实现。一个节点为键,他的所有邻居组成的列表为值。
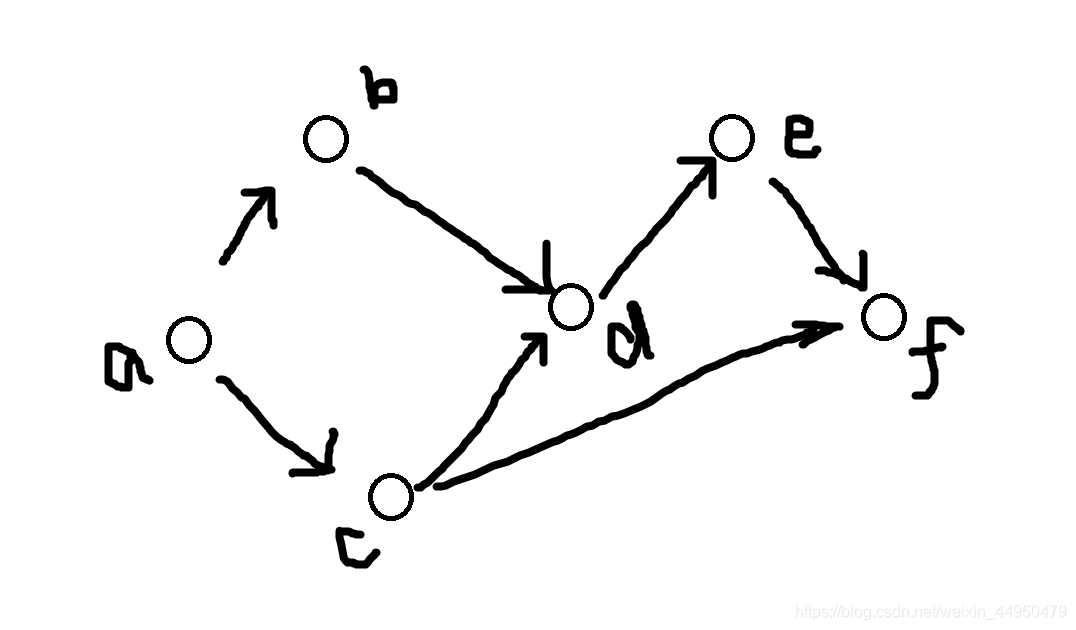
"""
用散列表(字典)实现无权图
"""
graph = {} #散列表
graph["a"] = ["b","c"] #值是邻居组成的列表
graph["b"] = ["d"]
graph["c"] = ["d","f"]
graph["d"] = ["e"]
graph["e"] = ["f"]
graph["f"] = [] #最后一个节点也要有
"""
用散列表(字典)实现加权图
"""
graph = {} #散列表
graph["a"] = {} #值是散列表
graph["b"] = {}
graph["c"] = {}
graph["d"] = {}
graph["e"] = {}
graph["f"] = {}
graph["a"]["b"] = [1] #值是权重
graph["a"]["c"] = [2]
graph["b"]["d"] = [3]
graph["c"]["d"] = [2]
graph["c"]["f"] = [1]
......
广度优先搜索
是一种与图有关的查找方法,解决是否有路径,找段数最少的路径问题
,搜索需要按顺序,所以用队列。
为了防止有环导致无限循环,检查完一个节点要把它标记为已检查。过程:只要搜索队列不空,就取出队列的第一个节点检查,如果这个节点没有检查过就检查,如果不满足,将他的邻居们加入到队列,并且将这个节点记为检查过。直到找出节点或队列空掉。
def search(name):
searched = []
while search_queue:
node = search_queue.popleft
if not node in searched:
if not jianchatiaojain(node):
search_queue += graph[node]
searched.append(node)
else:
return True
return False
狄克斯特拉算法
找用最短的路径,也就是加权图,适用于有向无环图。不适用于负权边。
过程:有三个散列表:graph,costs,parents。取出未检查的cost最小的节点,只要这个节点存在,就取出他的邻居,计算所有邻居的cost并于原来的cost比较,如果新的cost小就同步更新cost以及父节点,并且将这个节点记为检查过。直到找出节点或队列空掉。
def find_less_cost(costs):
infinity = float("inf" ) #表示无穷大
less_cost = infinity
less_cost_node = None
for node in costs:
if costs[node] < less_cost and node not in searched:
less_cost = costs[i]
less_cost_node = i
return less_cost_node
def dijkstra():
#是一个字典
node = find_less_cost(costs)
while node is not None:
cost = costs[node]
neibors = graph[node]
for n in neibors.keys():
n_cost = cost + neibors[n]
if n_cost < costs[n]:
costs[n] = n_cost
parents[n] = code
searched.append(node)
node = find_less_cost()
贝尔曼-福德算法
适用于负权边。
待学习!!!!!!!!
第八章 贪婪算法
思想:每步都选择局部最优解,最后就会得到全局最优解,这是一个大致的最优解。广度优先搜索,狄克斯特拉算法就是一种贪婪算法。
例子1:集合覆盖
用最少的广播台覆盖需要的州。每次找一个能覆盖【还未覆盖的州】最多州的电台,直到全部覆盖。
def find_best_station(stations,states_needed):
best_station = None
best_covered = set()
for station in stations and station not in station_set:
covered = stations[station] & states_needed
if len(covered) > len(best_covered):
best_covered = covered
best_station = station
return best_station,best_covered
states_needed = set([州的列表])
stations = {"广播站":set([覆盖的州])}
station_set = set()
while states_needed:
best_station,best_covered = find_best_station(stations,states_needed)
station_set.add(station)
states_needed -= best_covered
print(station_set)
动态规划
只适用于没有依赖关系的问题