分布式主键
目录
1.分布式主键的基本需求
2.常见的分布式主键生成策略
2.1UUID(128位)
2.2MySQL
2.2.1自增主键
2.2.2区间号段
2.3Redis
2.4SnowFlake雪花算法(64位)
1.分布式主键的基本需求
全局唯一:不管什么主键,都需要全局唯一。
高性能高可用:分布式主键服务本身就是一个底层的服务,很多服务都依赖于这个服务,如果底层服务都不稳定,那么上游的服务就更谈不上稳定。
递增:大部分数据存储使用MySQL存储数据,为了快速存储和检索,分布式主键生成策略总趋势要求是递增的。
2.常见的分布式主键生成策略
2.1UUID(128位)
在Java中自带的UUID就具有唯一性。如下面代码所示。生成的结果不是数字,是字符串。
UUID 是由128位二进制数组成,通常表示为32个十六进制字符。
public static void main(String[] args) {String uuid = UUID.randomUUID().toString().replaceAll("-","");System.out.println(uuid);//e48126eb0e6646638b043fca85f38818
}优点:简单,没有网络消耗。
缺点:
- 不保证大趋势递增,不利于检索,对索引的构建和维护成本比较大。
- 长度过长,不利于存储。
- 没有具体的业务含义。
2.2MySQL
2.2.1自增主键
基于数据库的自增主键充当分布式ID服务器。
具体实现:
1)创建一个SEQUENCE_ID表(id,value)
2)每次请求该分布式主键服务时 向SEQUENCE_ID 插入一条数据,并返回自增主键作为分布式主键。
优点:实现简单,自增有序;
缺点:DB单点存在宕机风险,扛不住高并发场景。
对于MySQL集群,单点数据库方式不可取,那对上边的方式做一些高可用优化,换成主从模式集群。害怕一个主节点挂掉没法用,那就做双主模式集群,也就是两个Mysql实例都能单独的生产自增ID。(起始值+自增步长)
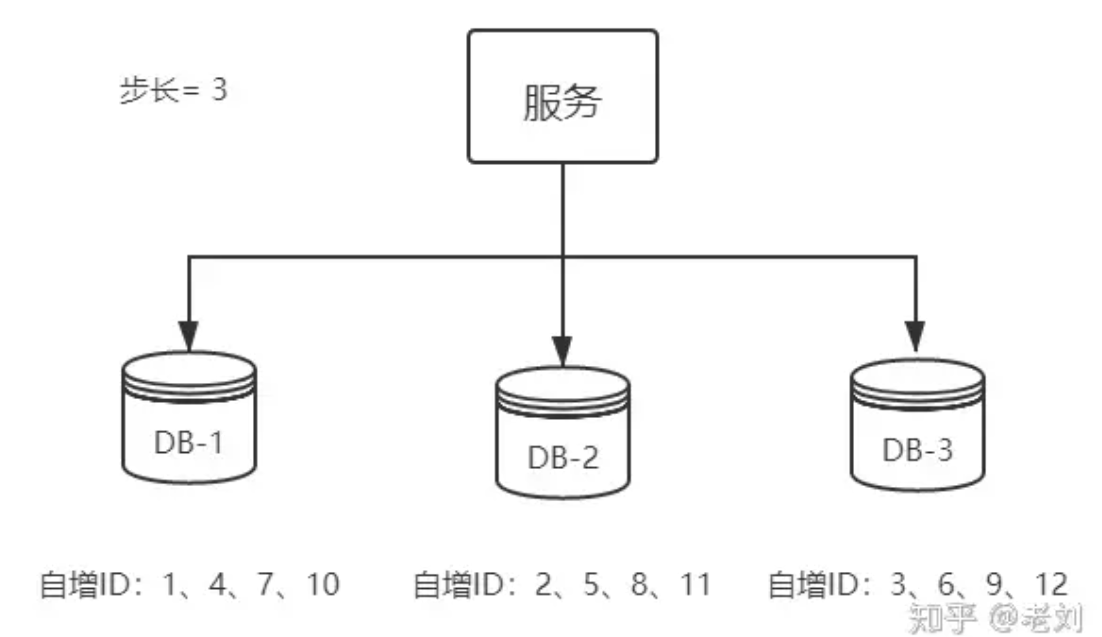
2.2.2区间号段
以单节点为例,在数据库中维护一个SEQUENCE_ID表。表中定义的是一个order主键生成规则和user主键生成规则。简单对表做一下解释,biz_code表示一种主键,max_id表示已经分配的最大ID,step表示步长,用于每次生成一批主键。
| biz_code | max_id | step | desc | update_time |
| order | 11000 | 1000 | 订单表 | 2022-09-06 |
| user | 1000 | 100 | 用户表 | 2022-09-09 |
在上面数据库的原始数据之上,此时上线了3个节点的订单服务。当用户创建订单时,Order_Node1节点会请求主键服务器生成一批主键,此时数据库表记录为
| biz_code | max_id | step | desc | update_time |
| order | 11000 | 1000 | 订单表 | 2022-09-06 |
[max_id + 1 , max_id + step]这批主键会返回给Order_Node1,即[11001,12000],此时会更新表的数据为
| biz_code | max_id | step | desc | update_time |
| order | 12000 | 1000 | 订单表 | 2022-09-07 |
每个节点的内存中存的是一批主键ID,当时候完毕后再去申请一批数据,效率极高。
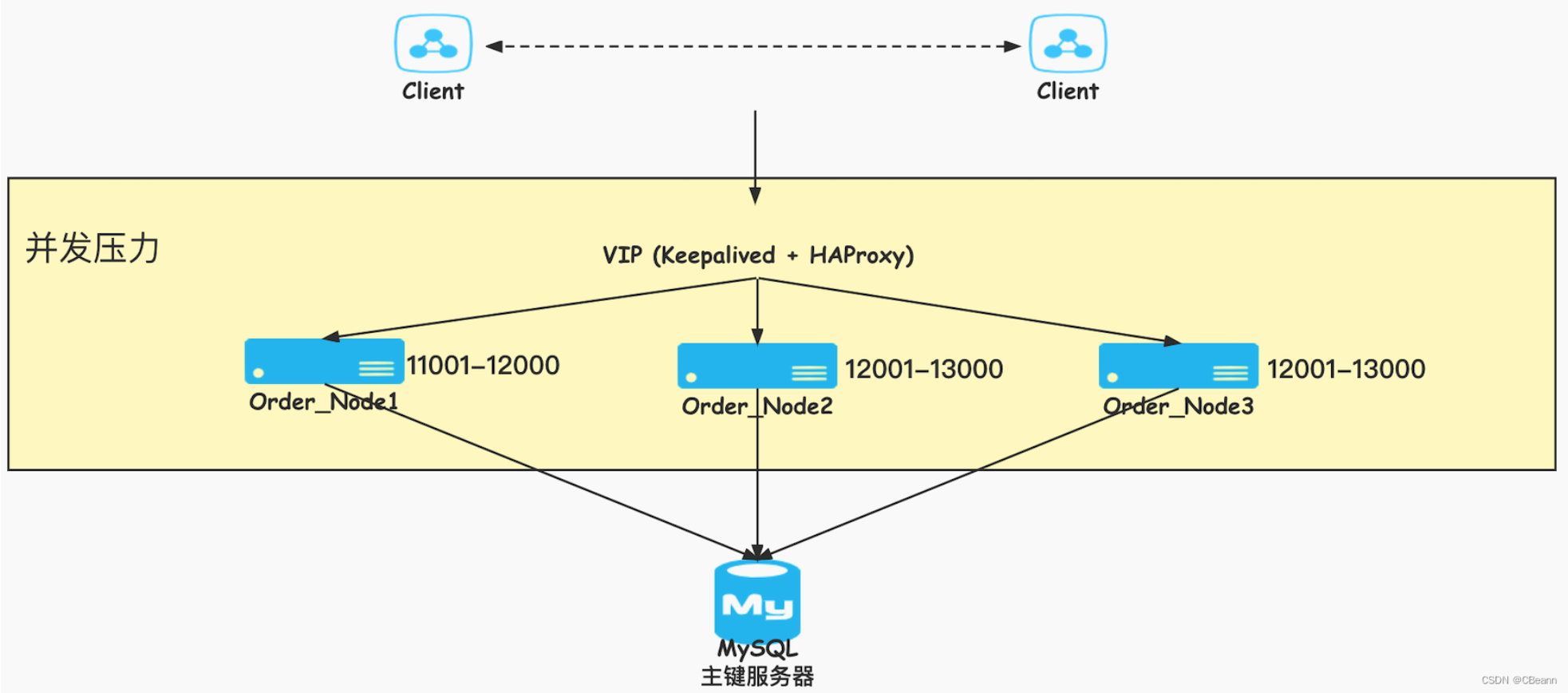
优点:
- 并发压力不会再MySQL主键服务器侧。
- 容灾性好,我一次给你一批,即使主键服务器挂了,Node内存中的主键可以继续使用,Node不应该order_node对外提供服务。
缺点:每当请求主键服务器申请一批主键时,TP 999数据会偶尔出现尖刺。因为当Clinet大量的请求到Order_Node时因没有主键去申请主键时会导致这一批的请求时间会hang住。
双Buffer优化
针对 区间号段 中出现尖刺的情况,使用双Buffer进行优化。
首先申请一批主键,当使用到该批次的10%时,后台起一个线程申请下一批主键,这样一种预加载的情况可以时主键串联起来,有效解决上面的请求RT抖动情况。

2.3Redis
原理就是利用redis的incr命令实现ID的原子性自增。
127.0.0.1:6379>set seq_id 1 // 初始化自增ID为1
OK
127.0.0.1:6379> incr seq_id // 增加1,并返回递增后的数值
(integer)2优点:
- 极大降低了主键服务器MySQL的流量
缺点:
- Redis如果使用RDB进行持久化,那么数据会存在丢失的风险。即 incr 后的数据丢失,则再次生成的主键会重复
- 依赖第三方服务,系统的复杂性会增加
2.4SnowFlake雪花算法(64位)
(雪花算法的基本思想是采用一个8字节的二进制序列来生成一个主键。为什么用8个字节呢?因为8个字节正好是一个Long类型的变量。既保持足够的区分度,又能比较自然的与业务结合。)
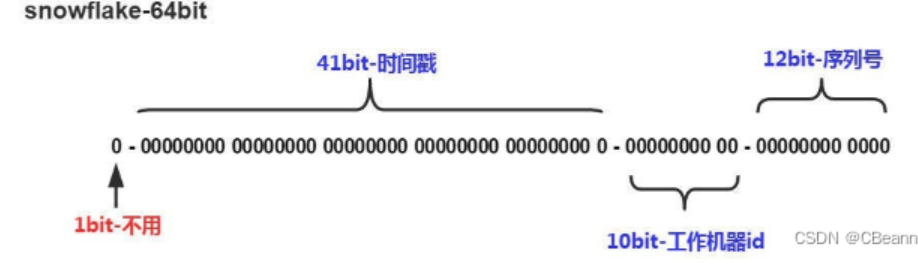
- 第一个bit位(1bit):一般生成ID都为正数,所以默认为0。
- 时间戳部分(41bit):毫秒级的时间,不建议存当前时间戳,而是用(当前时间戳 - 固定开始时间戳)的差值,可以使产生的ID从更小的值开始;41位的时间戳可以使用69年,(1L << 41) / (1000L * 60 * 60 * 24 * 365) = 69年
- 工作机器id(10bit):也被叫做workId,这个可以灵活配置,机房或者机器号组合都可以。
- 序列号部分(12bit),自增值支持同一毫秒内同一个节点可以生成4096个ID
核心思想:
多种唯一的值 进行拼接,使其更唯一。
Snowflake的第二部分是时间戳,时间戳是唯一的,但是如果多个节点同时生产则会参数相同的时间戳,那怎么办?接着加唯一的值,工作机器的ID唯一呀。那么就出现了第三部分的值。但是如果在一个进程中可能两个线程同时请求,那么会产生相同的(时间戳+工作机器ID),那就继续加唯一值,在加上最后的序列号,从而保证全局唯一。
- 第一个bit位(1bit):一般生成ID都为正数,所以默认为0。
- 时间戳部分(41bit):保证单节点下请求唯一,但是多节点内请求会生成相同的时间戳。
- 工作机器id(10bit):时间戳 + 工作机器 保证多节点同同时请求可以生成不同的主键ID。但是多节点下多线程还是存在重复。
- 序列号部分(12bit),解决多节点下多线程生成ID重复的问题。
优点:
- 高性能,生成的主键贼多
缺点
- 生成的主键之间跨度大,不密集,比如我想看一天的订单量,那么根据主键ID相减就没办法
- 该算法强依赖时间,存在时钟回拨问题
时钟回拨问题常见的解决方案
其实很多大厂基于雪花算法开源的分布式ID解决方案一方面偏重于64的设计,另一方面偏重于时钟回拨出现后的解决方案优化。
- 回拨时间很短(<100ms)
当请求系统时如果发现这个时钟回拨的时间段很小,则可以使其睡一会而到达之前最新的时间节点而继续往下执行。 - 回拨时间适中(>100ms && < 1s)
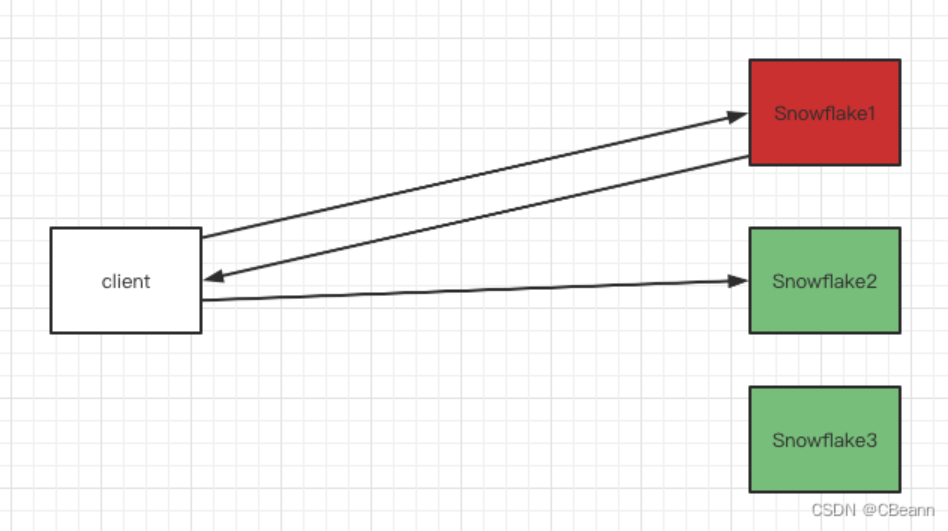
维护最近的一秒(1000毫秒)每毫秒请求的最大值到Redis中(time,maxId),如果发生时钟回拨则取该毫秒的最大值+1。 - 回拨时间较长(>1s && < 5s)
当请求Snowflake1时发现时钟回拨,则可以抛一个异常给客户端,客户端则进行其他节点的访问,负载均衡去实现。
- 回拨时间很长(>5s )
直接报警下线吧,都不能用了
参考:
分布式主键生成设计策略_分布式主键生成策略-CSDN博客