深入理解单元测试
荐语
本文要介绍的是 2020 年 O’Reilly 出版的书籍 Unit Testing Principles, Practices, and Patterns,一本在豆瓣评分高达 9.9 的好书。

作为一名软件开发工程师,你应该对单元测试(unit test)很熟悉,但单元测试的目的、Mock 的正确用法、单元测试和集成测试的区别等等,你真的懂吗?书中对这些内容都做了深入的介绍,并通过实际案例教你如何写出好的单元测试。读完这本书,你一定会有醍醐灌顶的感觉,原来单元测试要这么写!
书中的另一个重要观点认为,单元测试和代码架构是息息相关的,写不出好的单元测试,极有可能是代码架构设计得不好。为了写出好的单元测试,需要不断对代码架构的优化,它们相辅相成,从而让软件能够持续演进。
内容概览
文章目录
- 荐语
- 内容概览
- 为什么要写单元测试?
- 单元测试的目的
- 单元测试也分好坏
- 什么是单元测试
- 测试金字塔
- 单元测试中的依赖和测试替身
- 单元测试的定义
- 经典学派和伦敦学派之争
- 更准确的定义
- 集成测试与端到端测试
- 单元测试的结构
- 用例的命名
- 测试代码的组织
- 测试代码的重用
- 评判单元测试的四个标准
- 标准一:避免漏报
- 标准二:避免误报
- 漏报和误报的关系
- 标准三:快速反馈
- 标准四:可维护性
- 理想的单元测试
- mock 的正确用法
- 测试替身的分类
- 可观测行为与实现细节
- mock 可观测行为
- 单元测试的三种风格
- 通过重构来更好地完成单元测试
- 代码的分类
- 重构实战
- 单元测试的反模式
- 对私有方法进行测试
- 为了可测试性而扩大 public API 范围
- 将领域逻辑泄漏到单元测试中
- 代码污染
- 对实现类进行 mock
- 与时间耦合
- 最后
- 文章配图
- 参考
为什么要写单元测试?
单元测试的目的
如今,在软件开发活动中,单元测试已经成为企业级软件不可或缺的一环,是代码门禁的必选项。
如果突然有人问你,“为什么要写单元测试?”,你很容易会想到这样的答案,1)为了找到代码中已有的 Bug;2)为了防止引入新的 Bug;3)让代码架构变得更好;甚至是 4)满足代码门禁中覆盖率的要求。

但这些都不是我们写单元测试的根本目的,它们只是“写单元测试”这一活动所带来的副产品。
书中认为,单元测试的目的是实现软件项目的可持续增长。
企业级软件应用通常都有着业务逻辑复杂度高和生命周期长的特点。随着产品的不断迭代,代码会变得越来越复杂乱,每次修改代码也会变得越来越难,这就是软件的熵增定律。而单元测试的目的就是降低熵增的加速度,使得重构代码或新增功能变得更加的容易。

单元测试也分好坏
代码并非资产,而是一种负债,单元测试代码也是如此。
然而,我们往往会将生产代码和测试代码区分对待,忽略了对测试代码的维护,久而久之,测试代码变得冗余、复杂,甚至出现误报的情况。这样的单元测试,只会让系统的演进更加难。

如何评判单元测试的好坏?最常用的方法是代码覆盖率,也即测试用例执行了多少源代码。其中,又可分为行覆盖率和分支覆盖率。
行覆盖率计算执行了多少代码行,比如下面的例子,return true 的代码行无法覆盖,因此代码行覆盖率为 4/5=80%:
// C#
public static bool IsStringLong(string input)
{if (input.Length > 5)// 无法执行return true;return false;}public void Test()
{bool result = IsStringLong("abc");Assert.Equal(false, result);
}
但是,某些时候行覆盖率并不能放映真实的覆盖情况,比如将上述的 IsStringLong 使用三目运算符进行重构,行覆盖率 3/3=100% 了,但实际情况并未改善。
// C#
public static bool IsStringLong(string input)
{return input.Length > 5 ? true : false;
}public void Test()
{bool result = IsStringLong("abc");Assert.Equal(false, result);
}
分支覆盖率情况会好一些,IsStringLong 重构前后的分支覆盖率都是 1/2=50%:

但是,如果代码中涉及调用第三方库的代码,分支覆盖率也无法反映真实的情况:
public static int Parse(string input)
{// int.Parse为第三方库中的方法return int.Parse(input);
}public void Test()
{int result = Parse("5");Assert.Equal(5, result);
}上述例子中,看似分支覆盖率也 100% 了,但 int.Parse 方法的实现并未考虑到:

另外,一些代码并未包含核心的业务逻辑,比如枚举类的声明,专门写单元测试来覆盖它们,除了得到更高的代码覆盖率之外,实际并不会带来价值。
// C#
// 稳定、不包含业务逻辑
public enum InputType {SOCKET,HTTP,HTTPS,WEBSOCKET
}
所以,代码覆盖率低的单元测试,可以认为是不好的;但代码覆盖率高的单元测试,却不见得是好的。
那么,怎样的单元测试才是好的呢?
书中认为,好的单元测试应该包含如下几个特点:
- 被集成到开发周期中。单元测试应该被集成到 CICD 流程,每次代码的更改都能够自动执行。
- 仅针对代码中最重要的部分。单元测试代码也是一种负债,不能为了追求代码覆盖率而写出大量的冗余用例。
- 以最低的维护成本提供最大的价值。这是书中的重点,也是后文要详细介绍的内容。
什么是单元测试
测试金字塔
如果有人问你,“什么是单元测试?”,你可能会想到测试金字塔:

测试金字塔从下往上分别是单元测试、集成测试和端到端测试,单元测试通常是面向类或方法级别的测试方法;集成测试则面向服务或模块级别;端到端测试是从最终用户的角度进行测试,测试对象为整个系统。
在一个设计良好的系统中,这三类测试的占比就像它们在金字塔中的面积,越往下越高;测试执行速度越往下越快。
测试金字塔所表达的意思是,单元测试的执行效率更高,因此我们应依靠大量的单元测试、辅助以少量的集成测试和端到端测试,来保证系统的功能正确。
那么,怎样的测试才算是单元测试呢?
单元测试中的依赖和测试替身
在给单元测试下定义之前,先介绍单元测试中的依赖,它是区分不同学派的单元测试,以及测试金字塔中不同测试类别的关键。
书中将单元测试的依赖分成两类,共享依赖和私有依赖,其中私有依赖又可分为可变依赖和不可变依赖。

- 共享依赖指测试之间共享的依赖项,比如可变的静态全局变量(进程内)和数据库(进程外)。
- 私有依赖则是非共享的依赖项:
- 可变依赖,普通对象、无状态的静态方法都属于可变依赖,比如前面例子中
Parse方法所依赖的int.Parse方法。 - 不可变依赖,又称值对象,比如前面例子的
InputType枚举类。
- 可变依赖,普通对象、无状态的静态方法都属于可变依赖,比如前面例子中

写单元测试的过程中,总会存在某些依赖项无法在测试环境中集成,这时须要使用测试替身(test double)进行替换。
测试替身是一个看起来跟实际依赖对象行为一致、实际是简化版实现的对象,有助于提升单元测试的可测试性。

我们常用到的 Mock 属于测试替身的一种,能够用于校验被测对象和依赖项之间的交互行为。
单元测试的定义
单元测试的定义很多,提取关键点可总结出这样的定义,单元测试是一种自动化测试方法,它具备如下特点:
- 验证一小段代码(也即,代码单元)。
- 执行速度很快。
- 并以相互隔离的方式来执行。
经典学派和伦敦学派之争
上述的定义延伸出两种学派的单元测试,经典学派(Classical School)和伦敦学派(London School)。

它们分歧点主要在定义的第 1 点和第 3 点,以及选择使用测试替身的时机:
| 被测对象 | 隔离对象 | 使用测试替身的依赖 | |
|---|---|---|---|
| 经典学派 | 一个或多个类 | 测试用例 | 共享依赖 |
| 伦敦学派 | 一个类 | 被测对象 | 除不可变依赖的其他依赖 |

支持伦敦学派的人通常持有如下观点:
- 观点一:伦敦学派拥有更细的测试粒度,一个用例只测试一个类,符合单一职责原则。
- 观点二:在依赖关系复杂的代码工程里,更易编写单元测试。
- 观点三:如果测试失败,很容易找到问题点。
而作者却更偏好经典学派,认为它能够写出更高质量的单元测试,因此也更能满足单元测试目标的要求。针对上述的几个观点,作者给出如下的反驳:
-
观点一:被测对象不应该是一个类,而应该是一个行为。也即单元测试应该站在用户的角度去验证系统的行为,至于该行为需要一个或是多个类来实现,这些都是实现细节,并不重要!
单元测试应该是讲述一个你的代码如何解决业务问题的故事,书中举了一个很形象的例子,面向行为的单元测试就像下述故事一样,凝练、目标清晰:
当我呼唤我的狗时,它从右边向我走来。
而面向实现细节的单元测试则像这样,冗长、目标不明确:
当我呼唤我的狗时,它首先迈开它的左前腿,然后是有前腿,接着转过头来,并开始摇尾巴…
-
观点二:代码的依赖关系复杂,通常都是代码架构设计的问题,使用测试替身只是隐藏了问题,并不能从根本上解决。
-
观点三:单元测试通常会被集成到 CICD 流程上,因此每次修改代码都会触发测试执行,因此,经典学派在问题定位上也不会很难。
更准确的定义
因此,书中认为,单元测试更准确的定义应该是,它是一种自动化测试方法,具备如下特点:
- 验证一个行为单元。
- 执行速度很快。
- 执行时与其他测试用例相隔离。
集成测试与端到端测试
书中对集成测试(integration test)的定义为不满足单元测试这三个特点的测试,比如如下的情形:
- 测试用例验证了多个行为(表现为用例中有多个 Assert 断言语句)。
- 测试用例中需要调用数据库、远程 API 服务等,考虑网络时延等,用例执行耗时可能来到秒级。
- 测试用例需要访问共享数据库,因此无法与其他用例隔离开。
端到端测试(end-to-end tests)属于集成测试的子集。它们的区别是,集成测试会使用测试替身来替代部分依赖,比如远程 API 服务;而端到端测试则不会,因此结果也更可靠。

单元测试的结构
前面提到,好的单元测试应该要以最低的维护成本提供最大的价值。要降低维护成本,就要为它设计出好的代码结构。
用例的命名
好的命名能够极大提升单元测试代码的可读性,当前,被提及最多的命名方式如下:
[MethodUnderTest]_[Scenario]_[ExpectedResult]
其中:
- MethodUnderTest 表示被测试的方法。
- Scenario 表示测试场景。
- ExpectedResult 表示测试的预期结果。
// C#
// [Fact]表示该方法为一个单元测试用例
[Fact]
public void IsDeliveryValid_InvalidDate_ReturnsFalse()
{DeliveryService sut = new DeliveryService();DateTime pastDate = DateTime.Now.AddDays(-1);Delivery delivery = new Delivery{Date = pastDate};bool isValid = sut.IsDeliveryValid(delivery);Assert.False(isValid);
}
上述例子中,从用例名 IsDeliveryValid_InvalidDate_ReturnsFalse 可以看出,被测的方法为 IsDeliveryValid,场景是非法日期(Invalid Date),预期结果是方法返回 False。
前文提到,我们应该**面向代码行为来编写单元测试,**而 IsDeliveryValid_InvalidDate_ReturnsFalse 这种命名方式却暴露了实现细节(被测方法)。
更好的方法是,站在用户的角度命名测试用例:
public void Delivery_with_invalid_date_should_be_considered_invalid()
在该版本中,被测方法 IsDeliveryValid 从命名中被删除,命名已非常接近于人类语言,这样即使是非开发人员也能看懂。
我们还能将进一步明确测试场景(delivery with past date):
public void Delivery_with_past_date_should_be_considered_invalid()
到这里,命名已经很清晰,但还能更简洁,去掉没意义的 considered:
public void Delivery_with_past_date_should_be_invalid()
另外,我们应该在用例命名中使用肯定的语气,也即将 should be 替换为 is:
public void Delivery_with_past_date_is_invalid()
最后,我们没必要删减基本的英语语法,它能够让非开放人员更好地看懂用例,将 a 添加到命名中:
public void Delivery_with_a_past_date_is_invalid()
测试代码的组织
书中推荐按照 AAA 模式组织测试代码,AAA 模式将测试分成 3 部分:Arrange、Act 和 Assert。
- Arrange 部分负责初始化被测系统(System Under Test,SUT)和相关依赖的初始化。
- Act 部分则调用 SUT 的被测方法,向其传递依赖,如果有返回值,则保存它。
- Assert 部分校验 Act 部分的返回值,或系统的某个状态,或相关的交互动作等。
Given-When-Then 模式可能更常见,它跟 AAA 模式类似,Given 对应 Arrange,When 对应 Act,Then 对应 Assert。
前面的 Delivery_with_a_past_date_is_invalid 例子就是按照 AAA 的模式来组织:
// C#
[Fact]
public void Delivery_with_a_past_date_is_invalid()
{// ArrangeDeliveryService sut = new DeliveryService();DateTime pastDate = DateTime.Now.AddDays(-1);Delivery delivery = new Delivery{Date = pastDate};// Actbool isValid = sut.IsDeliveryValid(delivery);// AssertAssert.False(isValid);
}
按 AAA 模式组织代码时,有以下几个注意点:
-
应始终将被测对象命名为
sut,这样可读性更高,比如上述例子中的DeliveryService。 -
应避免在用例中包含
if语句,如果必须,通常表明该用例测试的内容太多,需要拆分。 -
Act 部分应避免有多行,如果必须,通常表明代码设计不合理,缺少封装,需要重构。比如下述例子中,因缺少封装导致需要两次调用才能完成一次购买业务。更好的方法是将
store.RemoveInventory封装到customer.Purchase里面,否则过度依赖调用方,容易产生数据不一致的问题。// C# // 缺少封装,导致Act需要2行 [Fact] public void Purchase_succeeds_when_enough_inventory() {// Arrangevar store = new Store();store.AddInventory(Product.Shampoo, 10);var customer = new Customer();// Actbool success = customer.Purchase(store, Product.Shampoo, 5);store.RemoveInventory(success, Product.Shampoo, 5);// AssertAssert.True(success);Assert.Equal(5, store.GetInventory(Product.Shampoo)); }// 合理的封装下,Act只需1行 [Fact] public void Purchase_succeeds_when_enough_inventory() {// Arrangevar store = new Store();store.AddInventory(Product.Shampoo, 10);var customer = new Customer();// Actbool success = customer.Purchase(store, Product.Shampoo, 5);// AssertAssert.True(success);Assert.Equal(5, store.GetInventory(Product.Shampoo)); }
测试代码的重用
测试用例之间往往会存在可重用的初始化代码,它们出现在 Arrange 部分。很多人的会选择通过将初始化代码抽取到构造函数中:
// C#
public class CustomerTests
{ // 将被测对象和依赖提取成为成员变量private final Store _store; private final Customer _sut;// 在构造函数中进行初始化public CustomerTests() {_store = new Store();_store.AddInventory(Product.Shampoo, 10);_sut = new Customer();}// 用例1[Fact]public void Purchase_succeeds_when_enough_inventory(){bool success = _sut.Purchase(_store, Product.Shampoo, 5);Assert.True(success);Assert.Equal(5, _store.GetInventory(Product.Shampoo));}// 用例2[Fact]public void Purchase_fails_when_not_enough_inventory(){bool success = _sut.Purchase(_store, Product.Shampoo, 15);Assert.False(success);Assert.Equal(10, _store.GetInventory(Product.Shampoo));}
}然而这种做法有两个明显的缺点:
- 导致测试用例之间耦合加深。上述例子中,两个用例都依赖了相同的
_sut和_store实例。 - 降低了测试代码的可读性。上述例子中,阅读每个用例时,都必须跳转到构造函数查看
_sut和_store的声明。
更好的方法是将初始化代码提取到私有工厂方法中,一方面消除了用例间的耦合,另一方面可读性也更好:
// C#
public class CustomerTests
{// 用例1[Fact]public void Purchase_succeeds_when_enough_inventory(){Store store = CreateStoreWithInventory(Product.Shampoo, 10);Customer sut = CreateCustomer();bool success = sut.Purchase(store, Product.Shampoo, 5);Assert.True(success);Assert.Equal(5, store.GetInventory(Product.Shampoo));}// 用例2[Fact]public void Purchase_fails_when_not_enough_inventory(){Store store = CreateStoreWithInventory(Product.Shampoo, 10);Customer sut = CreateCustomer();bool success = sut.Purchase(store, Product.Shampoo, 15);Assert.False(success);Assert.Equal(10, store.GetInventory(Product.Shampoo));}// 初始化工厂方法1private Store CreateStoreWithInventory(Product product, int quantity){Store store = new Store();store.AddInventory(product, quantity);return store;}// 初始化工厂方法2private static Customer CreateCustomer(){return new Customer();}
}
评判单元测试的四个标准
只有好的结构,还不足以称为好的单元测试,理想的单元测试应该要做到四个标准:
-
避免漏报。
-
避免误报。
-
快速反馈。
-
可维护性高。
书中这四个标准的英文原文如下,本文按照个人理解进行了类似语义的翻译:
- Protection against regressions(避免漏报)
- Resistance to refactoring(避免误报)
- Fast feedback(快速反馈)
- Maintainability(可维护性)
标准一:避免漏报
好的单元测试应该尽量避免 Bug 漏报。
代码是一项负债,代码越多,出错的概率也就越大。所以,单元测试覆盖的代码量越大,发现代码 Bug 的概率也就越大,漏报率越低。
然而,高代码覆盖率只是好的单元测试的必要条件,我们不能一昧追求覆盖所有代码。有些代码的测试价值很低,比如枚举类、getter 和 setter 方法等,它们出错的概率很低,对它们做测试,收益并不大。
因此,我们更应该关注如下两类代码:
- 复杂的代码。代码越复杂,出现 Bug 的概率越大。
- 关键业务代码。关键业务代码一旦出现 Bug,影响通常会很大,理应花更多的精力进行测试。

标准二:避免误报
好的单元测试应该尽量避免 Bug 误报。
随着软件的不断演进,代码重构不可避免。重构就是在不改变可观测行为的基础上,对代码的实现进行修改,以降低它的复杂性。修改代码,就意味着可能引入 Bug,而单元测试作为防护网,能够有效阻止 Bug 的发生。
重构,最怕遇到的就是单元测试的误报,也即测试报错但业务行为正常的情况。误报会加大重构的代价,久而久之,会影响开发人员重构的积极性。
考虑如下代码,MessageRenderer 负责将消息 Message 渲染成 HTML 页面:
// C#
public class Message
{public string Header { get; set; }public string Body { get; set; }public string Footer { get; set; }
}
// 渲染接口
public interface IRenderer
{string Render(Message message);
}public class MessageRenderer : IRenderer
{public IReadOnlyList<IRenderer> SubRenderers { get; }public MessageRenderer(){SubRenderers = new List<IRenderer>{new HeaderRenderer(),new BodyRenderer()};}// 将消息渲染成HTML页面,属于可观测的行为public string Render(Message message){return SubRenderers.Select(x => x.Render(message)).Aggregate("", (str1, str2) => str1 + str2);}
}
考虑有如下的单元测试,用于验证 MessageRenderer 具备正确的结构:
// C#
[Fact]
public void MessageRenderer_uses_correct_sub_renderers()
{var sut = new MessageRenderer();IReadOnlyList<IRenderer> renderers = sut.SubRenderers;Assert.Equal(2, renderers.Count);Assert.IsAssignableFrom<HeaderRenderer>(renderers[0]);Assert.IsAssignableFrom<BodyRenderer>(renderers[1]);
}
但该用例并未针对用户可观测的行为,也即 MessageRenderer.Render 方法,进行测试,而是陷入到具体的实现细节中。一旦我们对MessageRenderer 进行重构,可能就会出现误报。比如,从 BodyRenderer 拆分出 FooterRenderer:
// C#
public class MessageRenderer : IRenderer
{public IReadOnlyList<IRenderer> SubRenderers { get; }public MessageRenderer(){SubRenderers = new List<IRenderer>{new HeaderRenderer(),new BodyRenderer(),// 重构点:拆分出FooterRenderernew FooterRenderer()};}// 将消息渲染成HTML页面,属于可观测的行为public string Render(Message message) {...}
}
那么,原有单元测试将会报错,但实际上,MessageRenderer.Render 的结果并未受影响。
// C#
[Fact]
public void MessageRenderer_uses_correct_sub_renderers()
{...// 报错,重构后的renderers.Count为3Assert.Equal(2, renderers.Count);...
}
更好的做法是只对可观测行为 MessageRenderer.Render 进行测试:
[Fact]
public void Rendering_a_message()
{var sut = new MessageRenderer();var message = new Message{Header = "h",Body = "b",Footer = "f"};string html = sut.Render(message);Assert.Equal("<h1>h</h1><b>b</b><i>f</i>", html);
}
所以,防止误报的最有效做法是,针对可观测行为进行测试!

漏报和误报的关系
把测试是否成功与功能是否正常放在一起,可得出如下表格:

- 真阴性。功能正常,且测试成功。正常情况下,单元测试都应该处于该情况。
- 真阳性。功能异常,且测试失败。这是单元测试存在的意义,当功能异常时,测试能够执行失败,以作提示。
- 假阴性。功能异常,但测试正常。测试漏报,表明 代码中存在未被发现的 Bug。此情况影响最大,可能导致生产问题。可通过覆盖高价值代码降低该情况出现概率。
- 假阳性。功能正常,但测试失败。测试误报,可通过面向行为的测试降低该情况出现概率。
标准三:快速反馈
好的单元测试应该能够给开发人员快速反馈 Bug。
快速执行是单元测试的基本属性,测试执行得越快,单位时间内执行的用例数量就越多,也就能缩短 Bug 反馈周期。一旦你引入 Bug,测试用例就能及时提示相关错误信息,避免出现更严重的影响。
标准四:可维护性
好的单元测试应该有足够高的可维护性。
可维护性由以下两方面组成:
- 理解测试用例的难度。测试代码越少,可读性越高,理解的难度越低。
- 运行测试用例的难度。测试依赖越少,运行难度越低。
理想的单元测试
能同时做到上述四点的即为理想的单元测试。然而,现实中却不存在这样的单元测试,除可维护性特征之外,其他三个特征会有所冲突,三者只能取其二,有点像 CAP 理论。

-
端到端测试能够同时做到避免误报和避免漏报,但无法做到快速反馈。
-
脆弱的测试,也即面向实现细节的测试,能够做到避免漏报和快速反馈,但很难避免误报。最极端的情况是针对源码本身做验证,一旦有修改代码的行为,立即报错,绝不会漏报,但极有可能是误报。比如:
// C# [Fact] public void MessageRenderer_is_implemented_correctly() {string sourceCode = File.ReadAllText(@"[path]\MessageRenderer.cs");Assert.Equal(@" public class MessageRenderer : IRenderer {public IReadOnlyList<<IRenderer> SubRenderers { get; }public MessageRenderer(){SubRenderers = new List<<IRenderer>{new HeaderRenderer(),new BodyRenderer(),new FooterRenderer()};}public string Render(Message message) { /* ... */ } }", sourceCode); } -
低价值的测试,比如针对 getter 和 setter 的测试,能够做到避免误报和快速反馈,但很难发现 Bug,导致漏报。
既然无法同时完美做到这四个标准,那么只能退而求其次,做权衡。
通常来说,可维护性相对独立,通过组织良好的测试结构,能够达到很好的可维护性;而避免误报、消除测试的脆弱性,是构建测试系统/套件首要任务。因此,我们通常会在避免漏报和快速反馈之间做权衡:

避免漏报和快速反馈之间的权衡,也可以对应到测试金字塔中各类测试的选择,端到端测试能避免漏报,单元测试能快速反馈,而集成测试则是折中选择:

mock 的正确用法
测试替身的分类
前文提到,mock 是测试替身(test double)的一种,剩余的还有 spy 、stub、dummy 和 fake。实际上,它们又可以归成两类,Mock 和 Stub。其中 mock 和 spy 属于前者,dummy、stub 和 fake 属于后者。

-
Mock 是针对被测系统外发(outcoming)、有副作用的交互进行模拟和校验,如调用 SMPT 服务进行邮件发送。mock 和 spy 的主要区别在于,前者的替换对象是通过 mock 框架自动生成;而后者则是手动编写而成。
// c# // mock和spy的区别 // 这是mock,使用了Mock框架的能力 var mock = new Mock<IEmailGateway>(); mock.Setup(x => x.SendGreetingsEmail(“user@email.com”)).Returns(true);public class EmailGatewayMock : IEmailGateway {...public bool SendGreetingsEmail(string email) {if (email == “user@email.com”) {return ture;}...} } // 这是spy,自定义一个测试替身类EmailGatewayMock var mock = new EmailGatewayMock()var sut = new Controller(mock); sut.GreetUser("user@email.com"); // Mock需要校验交互行为,这里为校验SendGreetingsEmail被调用一次 mock.Verify(x => x.SendGreetingsEmail("user@email.com"),Times.Once); -
Stub 是针对被测系统传入(incoming)、无副作用的交互进行模拟,但无发进行校验,如调用数据库进行数据查询。其中,dummy 主要是一些简单的硬编码常量,比如 NULL,一般作为占位符用于填充函数参数列表,并不会被使用;stub 则更复杂一些,需要根据不同的测试条件来预设不同的返回值;fake 则是实际依赖的裁剪版实现,它有实际的业务逻辑,但因经过简化而无法用到生产环境上,比如单元测试用的内存数据库。
用的比较多的是 stub,我们可以通过 mock 框架来生成 stub:
// c# [Fact] public void Creating_a_report() {// 这是Stub,只模拟传入行为var stub = new Mock<IDatabase>();stub.Setup(x => x.GetNumberOfUsers()).Returns(10);var sut = new Controller(stub.Object);Report report = sut.CreateReport();// Stub不需要校验交互行为,校验读取结果即可Assert.Equal(10, report.NumberOfUsers); }

可观测行为与实现细节
书中把系统的可观测行为定义为能够帮助客户端达成其目标的方法或状态,不满足这个定义的,都是实现细节。我们很容易将 public API 和可观测行为划上等号,但它们并不完全一样。
在理想的情况下,public API 与可观测行为一致,实现细节都被包含在 private API 中。但大多数人在系统设计时,都会把部分实现细节泄露到 public API 里。

比如,在下面的例子中,客户端主要使用 UserController.RenameUser 方法,用于给用户执行重命名操作:
// C#
public class User
{public string Name { get; set; }public string NormalizeName(string name){string result = (name ?? "").Trim();if (result.Length > 50)return result.Substring(0, 50);return result;}
}public class UserController
{public void RenameUser(int userId, string newName){User user = GetUserFromDatabase(userId);string normalizedName = user.NormalizeName(newName);user.Name = normalizedName;SaveUserToDatabase(user);}
}
User 类提供了 2 个 public API,Name 属性和 NormalizeName 方法,但从“重命名”这个目标来看,NormalizeName 不应该是 UserController 可见的,它存在的意义是为了满足 User 的命名规则,因此,它属于 User 的实现细节。更好的设计是将它改为 private API:
// C#
public class User
{private string _name;public string Name{get => _name;set => _name = NormalizeName(value);}private string NormalizeName(string name){string result = (name ?? "").Trim();if (result.Length > 50)return result.Substring(0, 50);return result;}
}public class UserController
{public void RenameUser(int userId, string newName){User user = GetUserFromDatabase(userId);user.Name = newName;SaveUserToDatabase(user);}
}

理解可观测行为和实现细节的另一个途径是通过六边形架构(Hexagonal Architecture),它是领域驱动设计中推荐的架构,分成领域层和应用层,其中领域层实现业务逻辑,应用层负责与外部交互(比如消息总线、数据库等)。那么,在领域层内部的交互为实现细节,应用层与外部的交互为可观测行为。

mock 可观测行为
从前文可知,针对实现细节进行测试往往会导致测试套变得脆弱,这对 mock 同样适用,mock 的对象应该只有可观测行为,而非实现细节。所以,不要尝试寻找对 private API 进行 mock 的方法!

当我们回头再次审视单元测试的伦敦学派和经典学派之争时,经典学派应当是获胜的一方。主要的原因是,伦敦学派鼓励在不可变依赖之外的所有依赖项都使用 mock,而不区分可观察行为和实现细节,这会导致单元测试变得脆弱!
单元测试的三种风格
现在,我们从另一个维度来审视单元测试的分类,基于输出的测试(output-based testing)、基于状态的测试(state-based testing)、基于通信的测试(communication-based testing)。
-
基于输出的测试,只校验 SUT 的输出结果,只适用于无副作用的方法,比如函数式编程。比如下面的例子:
// C# public class PriceEngine {public decimal CalculateDiscount(params Product[] products){decimal discount = products.Length * 0.01m;return Math.Min(discount, 0.2m);} }[Fact] public void Discount_of_two_products() {var product1 = new Product("Hand wash");var product2 = new Product("Shampoo");var sut = new PriceEngine();decimal discount = sut.CalculateDiscount(product1, product2);Assert.Equal(0.02m, discount); }
-
基于状态的测试,需要校验系统状态,包含 SUT 本身及其依赖项的状态,比如下面的例子中:
// C# public class Order {private readonly List<Product> _products = new List<Product>();public IReadOnlyList<Product> Products => _products.ToList();public void AddProduct(Product product){_products.Add(product);} }[Fact] public void Adding_a_product_to_an_order() {var product = new Product("Hand wash");var sut = new Order();sut.AddProduct(product);Assert.Equal(1, sut.Products.Count);Assert.Equal(product, sut.Products[0]); }
-
基于交互的测试,则校验 SUT 与依赖对象的交互行为,其中依赖对象通常会被 mock 替代,比如下面的例子:
[Fact] public void Sending_a_greetings_email() {var emailGatewayMock = new Mock<IEmailGateway>();var sut = new Controller(emailGatewayMock.Object);sut.GreetUser("user@email.com");emailGatewayMock.Verify(x => x.SendGreetingsEmail("user@email.com"),Times.Once); }
下面,我们使用前文提到的四个标准来评判这三类风格的单元测试:
- 避免漏报。该标准与具体的测试风格相关性不大,主要与测试执行的代码量、代码的复杂性、代码的价值相关。
- 避免误报。基于输出的测试表现最好,因为测试用例只依赖 SUT 本身;基于状态的测试表现次之;基于交互的测试最易受到误报的影响,只针对可观测行为进行校验可降低误报影响。
- 快速反馈。只要没有进程外的依赖对象,三种风格的测试都能做到很快。
- 可维护性。基于输出的测试只依赖 SUT 本身,可维护性最好,其他两者相当。

所以,我们应当尽可能地使用基于输出的测试风格来编写单元测试,但它的适用场景决定了这很不容易,我们可以把系统设计成函数式架构(Functional Architecture)来达到这个目的。
函数式架构与六边形架构类似,也分成两层,Functional Core 层和 Mutable Shell 层。Functional Core 层使用函数式编程风格来编写业务逻辑,核心是数据的不变性,根据系统输入,计算得出结果,无其他副作用;Mutable Shell 层一方面负责给 Functional Core 层输入,一方面负责将 Functional Core 层的输出转换成副作用,比如系统状态变更。

函数式架构下,我们应该尽可能地增加 Functional Core 层的代码,而减少 Mutable Shell 层的代码。书中通过一个实际例子,详细介绍了如何将代码重构成函数式架构,本文不再展开。
通过重构来更好地完成单元测试
代码的分类
我们可以从代码的复杂度(业务价值)和外部依赖的数量两个维度,将代码分成 4 类:

- 左上角通常为领域层代码,比如领域模型或核心算法,它们一般具备很高的业务价值和代码复杂度,但只有很少的外部依赖,通过单元测试覆盖。
- 右下角通常为应用层代码,比如控制器,它们一般没有业务逻辑,负责与外部依赖进行交互,通过集成测试覆盖。
- 左下角为低价值代码,比如常量定义,它们没有业务逻辑,也没有外部依赖,测试价值很低。
- 右上角为“大泥球”代码,既有复杂的业务逻辑,又有很多的外部依赖,我们很难对它进行单元测试。它是我们重点重构的对象,通常会将它拆分成领域层和应用层。
重构实战
考虑一个用户管理模块,当前只有一个业务,更改用户邮件,代码如下:
// C#
// 用户管理模块
public class User
{public int UserId { get; private set; }public string Email { get; private set; }public UserType Type { get; private set; }// 当前只支持用户邮件更改业务public void ChangeEmail(int userId, string newEmail){// 从数据库中查询用户的邮件和用户类型object[] data = Database.GetUserById(userId);UserId = userId;Email = (string)data[1];Type = (UserType)data[2];if (Email == newEmail)return;// 从数据库中查询公司邮箱域名和员工数量object[] companyData = Database.GetCompany();string companyDomainName = (string)companyData[0];int numberOfEmployees = (int)companyData[1];// 如果用户的新邮箱域名为公司域名,则该用户为员工,否则为客户string emailDomain = newEmail.Split('@')[1];bool isEmailCorporate = emailDomain == companyDomainName;UserType newType = isEmailCorporate? UserType.Employee: UserType.Customer;// 若存在用户类型变更,则更新数据库中员工数量if (Type != newType){int delta = newType == UserType.Employee ? 1 : -1;int newNumber = numberOfEmployees + delta;Database.SaveCompany(newNumber);}Email = newEmail;Type = newType;// 保存当前用户信息,并向消息总线发送消息变更消息Database.SaveUser(this);MessageBus.SendEmailChangedMessage(UserId, newEmail);}
}
上述代码中,User.ChangeEmail 既包含了业务逻辑,又与包含了与 Database 和 MessageBus 外部依赖的交互,是个“大泥球”!
接下来,我们对代码进行重构。
-
第一步:将外部依赖显式化。提高可测试性的常用手段是将隐式的依赖显式化,通常会通过依赖注入的方法实现。
// C# // 用户管理模块 public class User {// 显式化外部依赖private readonly Database _database = new Database();private readonly MessageBus _messageBus = new MessageBus();public int UserId { get; private set; }public string Email { get; private set; }public UserType Type { get; private set; }// 当前只支持用户邮件更改业务public void ChangeEmail(int userId, string newEmail){// 从数据库中查询用户的邮件和用户类型object[] data = _database.GetUserById(userId);..._messageBus.SendEmailChangedMessage(UserId, newEmail);} } -
第二步:引入应用层。将与外部依赖交互的逻辑剥离到应用层中,通常会通过 Controller 实现:
// C# // 用户管理应用层 public class UserController {private readonly Database _database = new Database();private readonly MessageBus _messageBus = new MessageBus();// 与外部依赖交互的逻辑,实际的业务执行调用领域层user.ChangeEmail方法public void ChangeEmail(int userId, string newEmail){object[] data = _database.GetUserById(userId);string email = (string)data[1];UserType type = (UserType)data[2];var user = new User(userId, email, type);object[] companyData = _database.GetCompany();string companyDomainName = (string)companyData[0];int numberOfEmployees = (int)companyData[1];int newNumberOfEmployees = user.ChangeEmail(newEmail, companyDomainName, numberOfEmployees);_database.SaveCompany(newNumberOfEmployees);_database.SaveUser(user);_messageBus.SendEmailChangedMessage(userId, newEmail);} }// 用户管理领域层 public class User {public int UserId { get; private set; }public string Email { get; private set; }public UserType Type { get; private set; }// 函数式的方法,不涉及外部依赖public int ChangeEmail(string newEmail, string companyDomainName, int numberOfEmployees){if (Email == newEmail)return numberOfEmployees;string emailDomain = newEmail.Split('@')[1];bool isEmailCorporate = emailDomain == companyDomainName;UserType newType = isEmailCorporate? UserType.Employee: UserType.Customer;if (Type != newType){int delta = newType == UserType.Employee ? 1 : -1;int newNumber = numberOfEmployees + delta;numberOfEmployees = newNumber;}Email = newEmail;Type = newType;return numberOfEmployees;} } -
第三步:消除应用层的复杂性。应用层应该尽可能地简单:
// C# public class UserController {private readonly Database _database = new Database();private readonly MessageBus _messageBus = new MessageBus();public void ChangeEmail(int userId, string newEmail){object[] userData = _database.GetUserById(userId);User user = UserFactory.Create(userData);object[] companyData = _database.GetCompany();Company company = CompanyFactory.Create(companyData);user.ChangeEmail(newEmail, company);_database.SaveCompany(company);_database.SaveUser(user);_messageBus.SendEmailChangedMessage(userId, newEmail);} }// UserFactory封装User实例化逻辑 public class UserFactory {public static User Create(object[] data){Precondition.Requires(data.Length >= 3);int id = (int)data[0];string email = (string)data[1];UserType type = (UserType)data[2];return new User(id, email, type);} }// CompanyFactory封装Company实例化逻辑 public class CompanyFactory {...}// Company封装公司领域逻辑 public class Company {public string DomainName { get; private set; }public int NumberOfEmployees { get; private set; }public void ChangeNumberOfEmployees(int delta){Precondition.Requires(NumberOfEmployees + delta >= 0);NumberOfEmployees += delta;}public bool IsEmailCorporate(string email){string emailDomain = email.Split('@')[1];return emailDomain == DomainName;} }// User封装用户领域逻辑 public class User {public int UserId { get; private set; }public string Email { get; private set; }public UserType Type { get; private set; }public void ChangeEmail(string newEmail, Company company){if (Email == newEmail)return;UserType newType = company.IsEmailCorporate(newEmail)? UserType.Employee: UserType.Customer;if (Type != newType){int delta = newType == UserType.Employee ? 1 : -1;company.ChangeNumberOfEmployees(delta);}Email = newEmail;Type = newType;} }
至此,我们成功将“大泥球” User 重构成领域层的 User、Company、UserFactory 和 CompanyFactory,应用层 UserController。
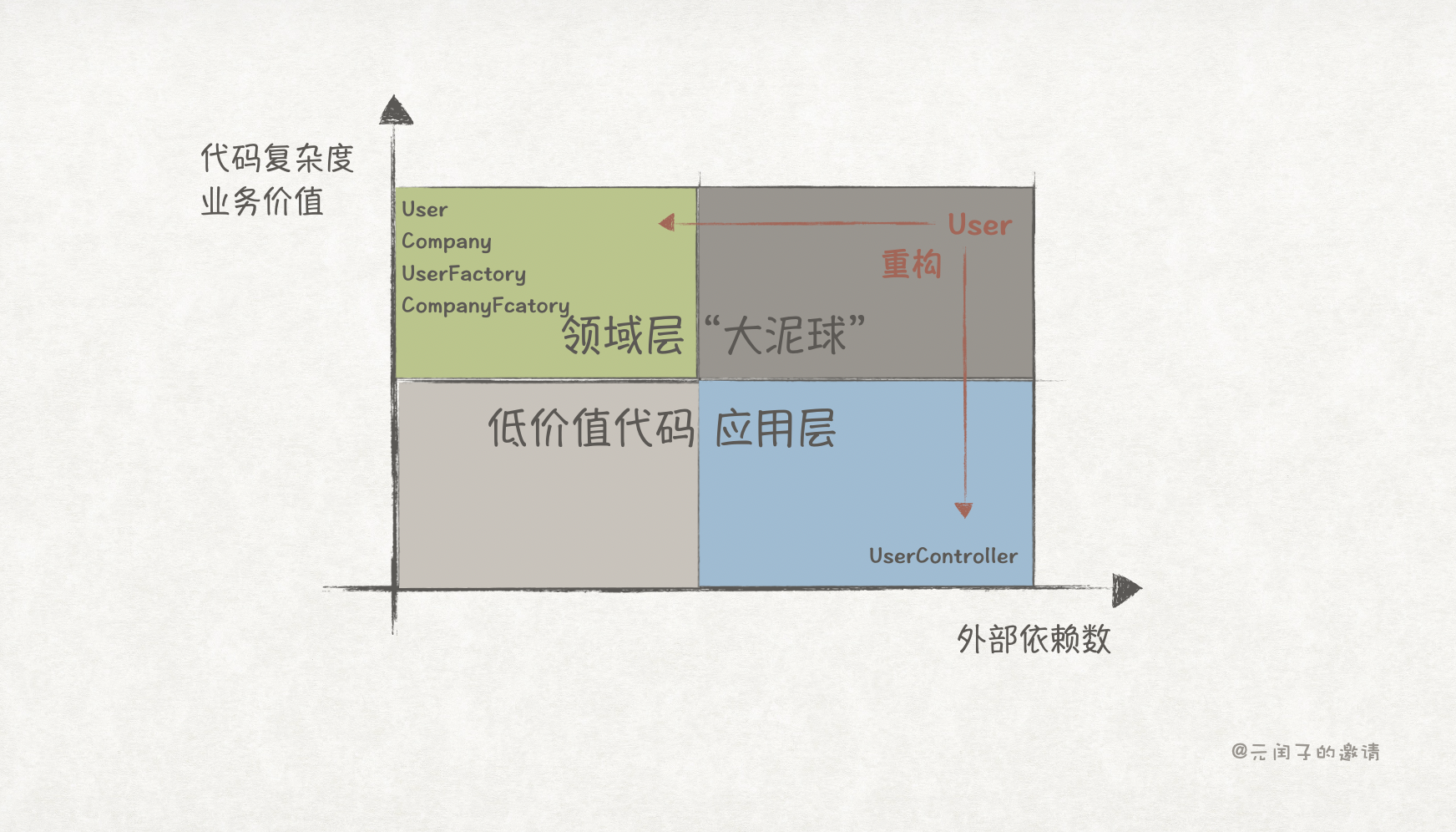
这样,我们就能很方便地对 User 进行单元测试了:
// C#
[Fact]
public void Changing_email_from_non_corporate_to_corporate()
{var company = new Company("mycorp.com", 1);var sut = new User(1, "user@gmail.com", UserType.Customer);sut.ChangeEmail("new@mycorp.com", company);Assert.Equal(2, company.NumberOfEmployees);Assert.Equal("new@mycorp.com", sut.Email);Assert.Equal(UserType.Employee, sut.Type);
}
单元测试的反模式
对私有方法进行测试
对私有方法进行测试,是最常见的单元测试反模式。由前文可知,私有方法或实现细节往往是不稳定的,对它们进行测试会导致用例变得脆弱,更容易出现误报。
如果测试用例在覆盖所有的可观测行为之后,仍然存在部分私有方法未覆盖,原因要么是这部分代码是冗余代码,要么是缺少合理的抽象。比如下面的例子中,Order.GetPrice 是一个具有独立且复杂逻辑的私有方法,理应有独立的单元测试对其进行覆盖:
// C#
public class Order
{private Customer _customer;private List<Product> _products;public string GenerateDescription(){return $"Customer name: {_customer.Name}, " +$"total number of products: {_products.Count}, " +$"total price: {GetPrice()}"; 1}private decimal GetPrice() 2{decimal basePrice = /* Calculate based on _products */;decimal discounts = /* Calculate based on _customer */;decimal taxes = /* Calculate based on _products */;return basePrice - discounts + taxes;}
}
更好的实现是将 Order.GetPrice 抽象成单独的类 PriceCalculator,提供公开接口 Calculate:
// C#
public class Order
{private Customer _customer;private List<Product> _products;public string GenerateDescription(){var calc = new PriceCalculator();return $"Customer name: {_customer.Name}, " +$"total number of products: {_products.Count}, " +$"total price: {calc.Calculate(_customer, _products)}";}
}public class PriceCalculator
{public decimal Calculate(Customer customer, List<Product> products){decimal basePrice = /* Calculate based on products */;decimal discounts = /* Calculate based on customer */;decimal taxes = /* Calculate based on products */;return basePrice - discounts + taxes;}
}
为了可测试性而扩大 public API 范围
为了可测试性而扩大 public API 范围是我们常犯的另一个反模式,考虑下面的例子,Customer._status 是一个私有属性,其中 Promote 方法对其进行了更新:
// C#
public class Customer
{private CustomerStatus _status =CustomerStatus.Regular;public void Promote(){_status = CustomerStatus.Preferred;}public decimal GetDiscount(){return _status == CustomerStatus.Preferred ? 0.05m : 0m;}
}
为了测试 Promote 方法,很多人可能会将 _status 改成公有属性,便于在测试用例中校验正确性,这也是一种反模式!
将领域逻辑泄漏到单元测试中
我们常常会无意中将领域逻辑泄漏到单元测试中,考虑下面的例子:
// C#
public static class Calculator
{public static int Add(int value1, int value2){return value1 + value2;}
}public class CalculatorTests
{[Fact]public void Adding_two_numbers(){int value1 = 1;int value2 = 3;// 领域逻辑的泄漏!int expected = value1 + value2; 1int actual = Calculator.Add(value1, value2);Assert.Equal(expected, actual);}
}
上述的测试用例看起来没问题,但 int expected = value1 + value2; 相当于在测试用例中重新实现了一遍领域逻辑,若后续重构,很容易导致误报。更好的方法是,直接针对值进行断言:
public class CalculatorTests
{[Fact]public void Adding_two_numbers(){int value1 = 1;int value2 = 3;int actual = Calculator.Add(value1, value2);// 直接针对值进行断言Assert.Equal(4, actual);}
}
代码污染
代码污染指的是在业务代码中增加仅用于单元测试的代码,这也是常见的反模式,比如下面的例子:
// C#
public class Logger
{// 用于判断是否为测试环境private readonly bool _isTestEnvironment;public Logger(bool isTestEnvironment) 1{_isTestEnvironment = isTestEnvironment;}public void Log(string text){if (_isTestEnvironment) 1return;/* Log the text */}
}
对实现类进行 mock
我们一般只对接口进行 mock,mock 具体的实现类是一种反模式!
与时间耦合
很多程序的实现逻辑需要访问当前时间,也即调用 DateTime.Now() 方法,因为方法与当前时间强耦合,不同的时间执行方法,结果可能会不一样。更好的方法是,将 DateTime 对象作为依赖注入到方法中。
最后
本文花了很长的篇幅把 Unit Testing Principles, Practices, and Patterns 书中的主要内容列举了出来,书中有着更多的代码示例,能够让读者更深地理解作者的用意,建议大家直接读原书。
总的来说,这不仅是一本介绍单元测试的书,更是一本介绍软件设计的书,非常值得一读!
文章配图
可以在 用Keynote画出手绘风格的配图 中找到文章的绘图方法。
参考
[1] Unit Testing Principles, Practices, and Patterns , Vladimir Khorikov
更多文章请关注微信公众号:元闰子的邀请