2019独角兽企业重金招聘Python工程师标准>>> 
为了使决策树最优,哪一个属性将在树的根节点被测试?分类能力最好的属性被选作树的根结点的测试。采用不同测试属性及其先后顺序将会生成不同的决策树。
定义一个统计属性,称为“信息增益”(information gain),用来衡量给定的属性区分训练样例的能力。度量信息增益的标准为“熵”(entropy)。信息量就是不确定性的多少,熵越大,信息的不确定性越大
熵代表一个系统的杂乱程度,熵越大,系统越杂乱。对一个数据集中数据的分类就是使得该数据集熵减小的过程。
决策树算法就是一个划分数据集的过程。划分数据集的原则就是:将无序的数据变得更加有序。我们假设得到的数据是有用的信息,处理信息的一种有效的方法就是利用信息论。
信息增益:划分数据集前后信息的变化成为信息增益,获得信息增益最高的特征就是最好的选择。那么如何计算信息增益?集合信息的度量方式称为熵。
“ 如果看不明白什么是信息增益和熵,请不要着急——它们自诞生的那一天起,就注定会令世人十分费解。克劳德香农写信息论之后,约翰冯诺依曼建议使用“熵”这个术语,因为大家都不知道它是什么意思。 ”
熵定义为信息的期望值,在明晰这个概念之前,先来看看信息的定义。如果待分类的事务可能划分在多个分类之中,则符号 的信息定义为:
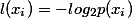
其中 是选择该分类的概率。
所有类别所有可能值包含的信息期望值,即是计算所得的熵:
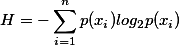
三、一个简单的例子
下表包含5个海洋动物,特征包括:不浮出水面是否可以生存,以及是否有脚蹼。将这些动物分为两类:鱼类和非鱼类。要研究的问题就是依据第一个特征还是第二个特征划分数据。
| 不浮出水面是否可以生存 | 是否又脚蹼 | 属于鱼类 | |
| 1 | 是 | 是 | 是 |
| 2 | 是 | 是 | 是 |
| 3 | 是 | 否 | 否 |
| 4 | 否 | 是 | 否 |
| 5 | 否 | 是 | 否 |
先给出计算香农熵的python代码,以备后续使用(一下所有代码均是python写的)
1 def calcShannonEnt(dataSet):
2 numEntries = len(dataSet)
3 labelCounts = {}
4 for featVec in dataSet:
5 currentLabel = featVec[-1]
6 if currentLabel not in labelCounts.keys(): labelCounts[currentLabel] = 0
7 labelCounts[currentLabel] += 1
8 shannonEnt = 0.0
9 for key in labelCounts:
10 prob = float(labelCounts[key])/numEntries
11 shannonEnt -= prob * log(prob, 2)
12 return shannonEnt
如果了解python,代码还是比较简单的,不过要事先说明一下dataSet是什么样的数据,怎样的数据结构。这就引出了下面的代码,用来生成dataSet,这样你就能更好地了解代码中“currentLabel = featVec[-1]”是怎么回事了。
1 def createDataSet(): 2 dataSet = [[1, 1, 'yes'], 3 [1, 1, 'yes'], 4 [1, 0, 'no'], 5 [0, 1, 'no'], 6 [0, 1, 'no']] 7 labels = ['no surfacing', 'flippers'] 8 return dataSet, labels
我们所处理的数据是形如dataSet这样的数据集,每个数据是list类型,数据的最后一项是数据的标签。看一下效果:
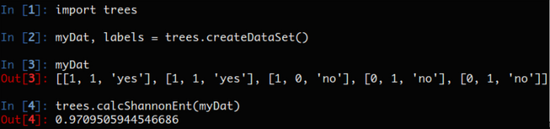
熵越高,说明数据的混合度越高,增加数据类别可以观察熵的变化。
接下来做些什么?别忘了初衷:依据第一个特征还是第二个特征划分数据?这个问题的回答就在于哪种特征的划分熵更小一些。我们将对每个特征划分数据集的结果计算一次信息熵,然后判断按照哪个特征划分数据集是最好的划分方式。
首先编写一个函数用于按照给定特征划分数据集:
1 def splitDataSet(dataSet, axis, value): 2 retDataSet = [] 3 for featVec in dataSet: 4 if featVec[axis] == value: 5 reducedFeatVec = featVec[:axis] 6 reducedFeatVec.extend(featVec[axis+1:]) 7 retDataSet.append(reducedFeatVec) 8 return retDataSet
代码中使用了python中自带的两个方法:extend()、append(),这两个方法功能类似,但是在处理多个列表时,这两个方法是完全不同的,这个大家就自行百度一下。代码比较好理解,一下子没有理解也没事,慢慢来,先看看运行的效果,感性认识一下吧:
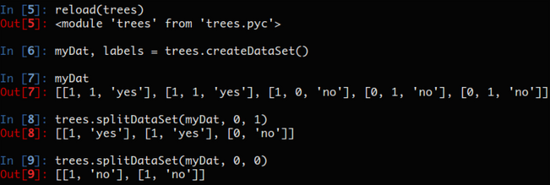
最后一个函数就是用于对每个特征划分数据集的结果计算一次信息熵,然后判断按照哪个特征划分数据集是最好的划分方式:
1 def chooseBestFeatureToSplit(dataSet): 2 numFeatures = len(dataSet[0]) - 1 3 baseEntropy = calcShannonEnt(dataSet) 4 bestInfoGain = 0.0; bestFeature = -1 5 for i in range(numFeatures): 6 featList = [example[i] for example in dataSet] 7 uniqueVals = set(featList) 8 newEntropy = 0.0 9 for value in uniqueVals: 10 subDataSet = splitDataSet(dataSet, i, value) 11 prob = len(subDataSet) / float(len(dataSet)) 12 newEntropy += prob * calcShannonEnt(subDataSet) 13 infoGain = baseEntropy - newEntropy 14 if(infoGain > bestInfoGain): 15 bestInfoGain = infoGain 16 bestFeature = i 17 return bestFeature

看得出,按照第一个特征划分获得的是最好的划分,熵最小。