ReverseEngineering#1.Basic knowledge
文章为整合而成。有删改。本节不涉及技术细节和工具。
1.单元、位和字节
·BIT(位)电脑数据量的最小单元,可以是0或者1。
例:00000001 = 1;00000010 = 2;00000011 = 3
·BYTE(字节) 一个字节包含8个位,所以一个字节最大值是255(0-255)。为了方便阅读,我们通常使用16进制来表示。
·WORD(字) 一个字由两个字节组成,共有16位。一个字的最大值是0FFFFh (或者是 65535d) (h代表16进制,d代表10进制)。
·DOUBLE WORD(双字DWORD) - 一个双字包含两个字,共有32位。最大值为0FFFFFFFF (或者是 4294967295d)。
·KILOBYTE(千字) - 千字节并不是1000个字节,而是1024 (32*32) 个字节。
·MEGABYTE - 兆字节同样也不是一兆个字节,而是1024*1024=1,048,576 个字节
2.寄存器
寄存器是中央处理器内的组成部分。寄存器是有限存贮容量的高速存贮部件,它们可用来暂存指令、数据和地址。在中央处理器的控制部件中,包含的寄存器有指令寄存器(IR)和程序计数器(PC)。在中央处理器的算术及逻辑部件中,存器有累加器(ACC)。
EAX: 累加器
EBX: 基址寄存器
ECX: 计数器
EDX: 数据寄存器
ESI: 源变址寄存器
EDI: 目的变址寄存器
EBP: 扩展基址指针寄存器
ESP: 栈指针寄存器
EIP: 指令指针寄存器
…
通常来说寄存器大小都是32位 (四个字节) 。它们可以储存值为从0-FFFFFFFF (无符号)的数据。起初大部分寄存器的名字都暗示了它们的功能,比如ECX=计数,但是现在你可以使用任意寄存器进行计数 (只有在一些自定义的部分,计数才必须用到ECX)。
EBP: EBP在栈中运用最广,刚开始没有什么需要特别注意的 ;)
ESP: ESP指向栈区域的栈顶位置。栈是一个存放即将会被用到的数据的地方,你可以去搜索一下push/pop 指令了解更多栈知识。
EIP: EIP指向下一个将会被执行的指令。
还有一件值得注意的事:有一些寄存器是16位甚至8位的,它们是不能直接寻址的。
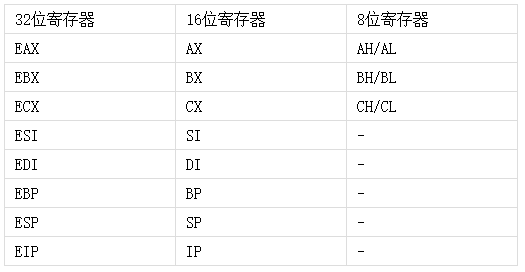
EAX是这个32位寄存器的名字,EAX的低16位部分被称作AX,AX又分为高8位的AH和低8位的AL两个独立寄存器。
单字节(8位)寄存器: 顾名思义,这些寄存器都是一个字节 (8位) :
AL and AH
BL and BH
CL and CH
DL and DH
ii. 单字(16位)寄存器: 这些寄存器大小为一个字 (=2 字节 = 16 位)。一个单字寄存器包含两个单字节寄存器。我们通常根据它们的功能来区分它们。
- 通用寄存器:
AX (单字=16位) = AH + AL -> 其中‘+’号并不代表把它们代数相加。AH和AL寄存器是相互独立的,只不过都是AX寄存器的一部分,所以你改变AH或AL (或者都改变) ,AX寄存器也会被改变。
-> ‘accumulator’(累加器):用于进行数学运算
BX -> ‘base’(基址寄存器):用来连接栈(之后会说明)
CX -> ‘counter’(计数器):
DX -> ‘data’(数据寄存器):大多数情况下用来存放数据
DI -> ‘destination index’(目的变址寄存器): 例如将一个字符串拷贝到DI
SI -> ‘source index’(源变址寄存器): 例如将一个字符串从SI拷贝
2. 索引寄存器(指针寄存器):
BP -> ‘base pointer’(基址指针寄存器):表示栈区域的基地址
SP -> ‘stack pointer’(栈指针寄存器):表示栈区域的栈顶地址
3. 段寄存器:
CS -> ‘code segment’(代码段寄存器):用于存放应用程序代码所在段的段基址(之后会说明)
DS -> ‘data segment’(数据段寄存器):用于存放数据段的段基址(以后会说明)
ES -> ‘extra segment’(附加段寄存器):用于存放程序使用的附加数据段的基地址
SS -> ‘stack segment’(栈段寄存器):用于存放栈段的段基址(以后会说明)
4. 指令指针寄存器:
IP -> ‘instruction pointer’(指令指针寄存器):指向下一个指令 ;)
iii. 双字(32位)寄存器:
2 字= 4 字节= 32 位, EAX、EBX、ECX、EDX、EDI……
如果16位寄存器前面加了‘E’,就代表它们是32位寄存器。例如,AX=16位,EAX=32位。
III. 标志寄存器
标志寄存器代表某种状态。在32位CPU中有32个不同的标志寄存器,不过不用担心,我们只关心其中的3个:ZF、OF、CF。在逆向工程中,你了解了标志寄存器就能知道程序在这一步是否会跳转,标志寄存器就是一个标志,只能是0或者1,它们决定了是否要执行某个指令。
Z-Flag(零标志):
ZF是破解中用得最多的寄存器(通常情况下占了90%),它可以设成0或者1。若上一个运算结果为0,则其值为1,否则其值为0。(你可能会问为什么‘CMP’可以操作ZF寄存器,这是因为该指令在做比较操作(等于、不等于),那什么时候结果是0什么时候是1呢?待会再说)
The O-Flag(溢出标志):
OF寄存器在逆向工程中大概占了4%,当上一步操作改变了某寄存器的最高有效位时,OF寄存器会被设置成1。例如:EAX的值为7FFFFFFFF,如果你此时再给EAX加1,OF寄存器就会被设置成1,因为此时EAX寄存器的最高有效位改变了(你可以使用电脑自带计算器将这个16进制转化成2进制看看)。还有当上一步操作产生溢出时(即算术运算超出了有符号数的表示范围),OF寄存器也会被设置成1。
The C-Flag(进位标志):
进位寄存器的使用大概占了1%,如果产生了溢出,就会被设置成1。例,假如某寄存器值为FFFFFFFF,再加上1就会产生溢出,你可以用电脑自带的计算器尝试。
IV. 段偏移
内存中的一个段储存了指令(CS)、数据(DS)、堆栈(SS)或者其他段(ES)。每个段都有一个偏移量,在32位应用程序下,这些偏移量由 00000000 到 FFFFFFFF。段和偏移量的标准形式如下:
段:偏移量 = 把它们放在一起就是内存中一个具体的地址。
可以这样看:
一个段是一本书的某一页:偏移量是一页的某一行
栈
栈是内存里可以存放稍后会用到的东西的地方。可以把它看作一个箱子里的一摞书,最后一本放进去的永远是最先出来的。或者把栈看作一个放纸的盒子,盒子是栈,而每一张纸就代表了一个内存地址。总之记住这个规则:最后放的纸最先被拿出来。’push’命令就是向栈中压入数据,‘pop’命令就是从栈中取出最后放入的数据并且把它存进具体的寄存器中。
3.汇编指令 (字母表排序)
请注意,所有的值通常是以16进制形式储存的。
大部分指令有两个操作符 (例如:add EAX, EBX),有些是一个操作符 (例如:not EAX),还有一些是三个操作符 (例如:IMUL EAX、EDX、64)。如果你使用 “DWORD PTR [XXX]”就表示使用了内存中偏移量为[XXX]的的数据。注意:字节在内存中储存方式是倒过来的(Win+Intel的电脑上大部分采用”小端法”, WORD PTR XXX和 BYTE PTR XXX也都遵循这一规定)。
大部分有两个操作符的指令都是以下这些形式(以add指令举例):
add eax,ebx ;; 寄存器, 寄存器
add eax,123 ;; 寄存器, 数值
add eax,dword ptr [404000] ;; 寄存器, Dword 指针 [数值]
add eax,dword ptr [eax] ;; 寄存器, Dword 指针 [寄存器值]
add eax,dword ptr [eax+00404000] ;; 寄存器, Dword 指针 [寄存器值+数值]
add dword ptr [404000],eax ;; Dword 指针[数值], 寄存器
add dword ptr [404000],123 ;; Dword 指针[数值], 数值
add dword ptr [eax],eax ;; Dword 指针[寄存器值], 寄存器
add dword ptr [eax],123 ;; Dword 指针[寄存器值], 数值
add dword ptr [eax+404000],eax ;; Dword 指针[寄存器值+数值], 寄存器
add dword ptr [eax+404000],123 ;; Dword 指针[寄存器值+数值], 数值
ADD (加)语法: ADD 被加数, 加数
加法指令将一个数值加在一个寄存器上或者一个内存地址上。
add eax,123 = eax=eax+123;
加法指令对ZF、OF、CF都会有影响。
AND (逻辑与)
语法: AND 目标数, 原数
AND运算对两个数进行逻辑与运算。
AND指令会清空OF,CF标记,设置ZF标记。
为了更好地理解AND,这里有两个二进制数:
1001010110
0101001101
如果对它们进行AND运算,结果是0001000100
即同真为真(1),否则为假(0),你可以用计算器验证。
CALL (调用)
语法:CALL something
CALL指令将当前的相对地址(IP)压入栈中,并且调用CALL 后的子程序
CALL 可以这样使用:
CALL 404000 ;; 最常见: CALL 地址
CALL EAX ;; CALL 寄存器 - 如果寄存器存的值为404000,那就等同于第一种情况
CALL DWORD PTR [EAX] ;; CALL [EAX]偏移量所指向的地址
CALL DWORD PTR [EAX+5] ;; CALL [EAX+5]偏移量所指向的地址CDQ
Syntax: CDQ
CDQ指令第一次出现时通常不好理解。它通常出现在除法前面,作用是将EDX的所有位变成EAX最高位的值,
比如当EAX>=80000000h时,其二进制最高位为1,则EDX被32位全赋值为1,即FFFFFFFF
若EAX<80000000,则其二进制最高位为0,EDX为00000000。
然后将EDX:EAX组成新数(64位):FFFFFFFF 80000000
CMP (比较)
语法: CMP 目标数, 原数
CMP指令比较两个值并且标记CF、OF、ZF:
CMP EAX, EBX ;; 比较eax和ebx是否相等,如果相等就设置ZF为1
CMP EAX,[404000] ;; 比较eax和偏移量为[404000]的值是否相等
CMP [404000],EAX ;; 比较[404000]是否与eax相等DEC (自减)
语法: DEC something
dec用来自减1,相当于c中的–
dec可以有以下使用方式:
dec eax ;; eax自减1
dec [eax] ;; 偏移量为eax的值自减1
dec [401000] ;; 偏移量为401000的值自减1
dec [eax+401000] ;; 偏移量为eax+401000的值自减1
dec指令可以标记ZF、OFDIV (除)
语法: DIV 除数
DIV指令用来将EAX除以除数(无符号除法),被除数通常是EAX,结果也储存在EAX中,而被除数对除数取的模存在除数中。
例:
mov eax,64 ;; EAX = 64h = 100
mov ecx,9 ;; ECX = 9
div ecx ;; EAX除以ECX在除法之后 EAX = 100/9 = 0B(十进制:11) 并且 ECX = 100 MOD 9 = 1
div指令可以标记CF、OF、ZF
IDIV (整除)
语法: IDIV 除数
IDIV执行方式同div一样,不过IDIV是有符号的除法
idiv指令可以标记CF、OC、ZF
IMUL (整乘)
语法:IMUL 数值
IMUL 目标寄存器、数值、数值
IMUL 目标寄存器、数值
IMUL指令可以把让EAX乘上一个数(INUL 数值)或者让两个数值相乘并把乘积放在目标寄存器中(IMUL 目标寄存器, 数值,数值)或者将目标寄存器乘上某数值(IMUL 目标寄存器, 数值)
如果乘积太大目标寄存器装不下,那OF、CF都会被标记,ZF也会被标记
INC (自加)
语法: INC something
INC同DEC相反,它是将值加1
INC指令可以标记ZF、OF
INT
语法: int 目标数
INT 的目标数必须是产生一个整数(例如:int 21h),类似于call调用函数,INT指令是调用程序对硬件控制,不同的值对应着不同的功能。
具体参照硬件说明书。
JUMPS
这些都是最重要的跳转指令和触发条件(重要用标记,最重要用*标记):
指令 条件 条件
JA* - 如果大于就跳转(无符号) - CF=0 and ZF=0
JAE - 如果大于或等于就跳转(无符号)- CF=0
JB* - 如果小于就跳转(无符号) - CF=1
JBE - 如果小于或等于就跳转(无符号)- CF=1 or ZF=1
JC - 如果CF被标记就了跳转 - CF=1
JCXZ - 如果CX等于0就跳转 - CX=0
JE** - 如果相等就跳转 - ZF=1
JECXZ - 如果ECX等于0就跳转 - ECX=0
JG* - 如果大于就跳转(有符号) - ZF=0 and SF=OF (SF = Sign Flag)
JGE* - 如果大于或等于就跳转(有符号) - SF=OF
JL* - 如果小于就跳转(有符号) - SF != OF (!= is not)
JLE* - 如果小于或等于就跳转(有符号 - ZF=1 and OF != OF
JMP** - 跳转 - 强制跳转
JNA - 如果不大于就跳转(无符号) - CF=1 or ZF=1
JNAE - 如果不大于等于就跳转(无符号) - CF=1
JNB - 如果不小于就跳转(无符号) - CF=0
JNBE - 如果不小于等于就跳转(无符号) - CF=0 and ZF=0
JNC - 如果CF未被标记就跳转 - CF=0
JNE** - 如果不等于就跳转 - ZF=0
JNG - 如果不大于就跳转(有符号) - ZF=1 or SF!=OF
JNGE - 如果不大于等于就跳转(有符号) - SF!=OF
JNL - 如果不小于就跳转(有符号) - SF=OF
JNLE - 如果不小于等于就跳转(有符号) - ZF=0 and SF=OF
JNO - 如果OF未被标记就跳转 - OF=0
JNP - 如果PF未被标记就跳转 - PF=0
JNS - 如果SF未被标记就跳转 - SF=0
JNZ - 如果不等于0就跳转 - ZF=0
JO - 如果OF被标记就跳转 - OF=1
JP - 如果PF被标记就跳转 - PF=1
JPE - 如果是偶数就跳转 - PF=1
JPO - 如果是奇数就跳转 - PF=0
JS - 如果SF被标记就跳转 - SF=1
JZ - 如果等于0就跳转 - ZF=1LEA (有效地址传送)
语法:LEA 目的数、源数
LEA可以看成和MOV差不多的指令LEA ,它本身的功能并没有被太广泛的使用,反而广泛运用在快速乘法中:
lea eax,dword ptr [4*ecx+ebx]将eax赋值为 4*ecx+ebx
MOV (传送)
语法: MOV 目的数,源数
这是一个很简单的指令,MOV指令将源数赋值给目的数,并且源数值保持不变
这里有一些MOV的变形:
MOVS/MOVSB/MOVSW/MOVSD EDI, ESI:这些变形能将ESI指向的内容传送到EDI指向的内容中去
MOVSX:MOVSX指令将单字或者单字节扩展为双字或者双字节传送,原符号不变
MOVZX:MOVZX扩展单字节或单字为双字节或双字并且用0填充剩余部分(通俗来说就是将源数取出置于目的数,其他位用0填充)
MUL (乘法)
语法:MUL 数值
这个指令同IMUL一样,不过MUL可以乘无符号数。
NOP (无操作)
语法:NOP
这个指令说明不做任何事
所以它在逆向中运用范围最广
OR (逻辑或)
语法:OR 目的数,源数
OR指令对两个值进行逻辑或运算
这个指令会清空OF、CF标记,设置ZF标记
为了更好的理解OR,思考下面二进制串:
1001010110
0101001101
如果对它们进行逻辑与运算,结果将是1101011111。
只有当两边同为0时其结果为0,否则就为1。你可以用计算器尝试计算。希望你能理解为什么,最好自己动手算一算
POP
语法:POP 目的地址
POP指令将栈顶第一个字传送到目的地址。 每次POP后,ESP(栈指针寄存器)都会增加以指向新栈顶
PUSH
语法:PUSH 值
PUSH是POP的相反操作,它将一个值压入栈并且减小栈顶指针值以指向新栈顶。
REP/REPE/REPZ/REPNE/REPNZ
语法: REP/REPE/REPZ/REPNE/REPNZ ins
重复上面的指令:直到CX=0。ins必须是一个操作符,比如CMPS、INS、LODS、MOVS、OUTS、SCAS 或 STOS
RET (返回)
语法:RET
RET digit
RET指令的功能是从一个代码区域中退出到调用CALL的指令处。
RET digit在返回前会清理栈
SUB (减)
语法:SUB 目的数,源数
SUB与ADD相反,它将源数减去目的数,并将结果储存在目的数中
SUB可以标记ZF、OF、CF
TEST
语法:TEST 操作符、操作符
这个指令99%都是用于”TEST EAX, EAX”,它执行与AND相同的功能,但是并不储存数据。如果EAX=0就会标记ZF,如果EAX不是0,就会清空ZF
XOR
语法:XOR 目的数,源数
XOR指令对两个数进行异或操作
这个指令清空OF、CF,但会标记ZF
为了更好的理解,思考下面的二进制串:
1001010110
0101001101
如果异或它们,结果将是1100011011
如果两个值相等,则结果为0,否则为1,你可以使用计算器验算。
很多情况下我们会使用”XOR EAX, EAX”,这个操作是将EAX赋值为0,因为当一个值异或其自身,就过都是0。你最好自己动手尝试下,这样可以帮助你理解得更好。
4.PE(Portable Executable)文件简介
PE(Portable Executable)文件是Windows操作系统下使用的可执行文件格式。它是微软在UNIX平台的COFF(通用对象文件格式)基础上制作而成。最初设计用来提高程序在不同操作系统上的移植性,但实际上这种文件格式仅用在Windows系列操作系统下。
PE文件是指32位可执行文件,也称为PE32。64位的可执行文件称为PE+或PE32+,是PE(PE32)的一种扩展形式(请注意不是PE64)。
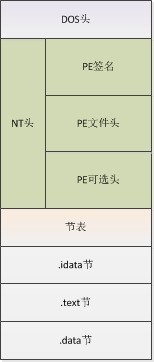
PE文件结构一般如上图所示。
当一个PE文件被执行时,PE装载器首先检查DOS header里的PE header的偏移量。如果找到,则直接跳转到PE header的位置。
当PE装载器跳转到PE header后,第二步要做的就是检查PE header是否有效。如果该PE header有效,就跳转到PE header的尾部。
紧跟PE header尾部的是节表。PE装载器执行完第二步后开始读取节表中的节段信息,并采用文件映射(在执行一个PE文件的时候,Windows并不在一开始就将整个文件读入内存,而是采用与内存映射的机制,也就是说,Windows装载器在装载的时候仅仅建立好虚拟地址和PE文件之间的映射关系,只有真正执行到某个内存页中的指令或者访问某一页中的数据时,这个页面才会被从磁盘提交到物理内存,这种机制使文件装入的速度和文件大小没有太大的关系)的方法将这些节段映射到内存,同时附上节表里指定节段的读写属性。
PE文件映射入内存后,PE装载器将继续处理PE文件中类似 import table (输入表)的逻辑部分
这四个步骤便是PE文件的执行顺序,具体细节读者可以参考相关文档。
Ref:http://www.freebuf.com/articles/system/86596.html
5.壳
壳的定义:在一些计算机软件里也有一段专门负责保护软件不被非法修改或反编译的程序。它们一般都是先于程序运行,拿到控制权,然后完成它们保护软件的任务。由于这段程序和自然界的壳在功能上有很多相同的地方,基于命名的规则,大家就把这样的程序称为“壳”了,无非是保护、隐蔽壳内的东西。而从技术的角度出发,壳是一段执行于原始程序前的代码。原始程序的代码在加壳的过程中可能被压缩、加密……。当加壳后的文件执行时,壳-这段代码先于原始程序运行,他把压缩、加密后的代码还原成原始程序代码,然后再把执行权交还给原始代码。 软件的壳分为加密壳、压缩壳、伪装壳、多层壳等类,目的都是为了隐藏程序真正的OEP(入口点,防止被破解)。
壳的加载过程:首先是保存现场 ==》获取壳程序自己所需要的函数(请记住这几个函数) ==》解密数据 ==》初始化IAT ==》跳到OEP ==》进行脱壳、修复
ref:http://www.2cto.com/article/201212/172850.html
6.OEP查找
PUSHAD (压栈) 代表程序的入口点, POPAD (出栈) 代表程序的出口点,与PUSHAD相对应,一般找到这个,OEP就在附近。
方法一:
1.用OD载入,不分析代码!
2.单步向下跟踪F8,是向下跳的让它实现
3.遇到程序往回跳的(包括循环),我们在下一句代码处按F4(或者右健单击代码,选择断点——运行到所选)
4.绿色线条表示跳转没实现,不用理会,红色线条表示跳转已经实现!
5.如果刚载入程序,在附近就有一个CALL的,我们就F7跟进去,这样很快就能到程序的OEP
6.在跟踪的时候,如果运行到某个CALL程序就运行的,就在这个CALL中F7进入
7.一般有很大的跳转,比如 jmp XXXXXX 或者 JE XXXXXX 或者有RETE的一般很快就会到程序的OEP。
方法二:
ESP定理脱壳(ESP在OD的寄存器中,我们只要在命令行下ESP的硬件访问断点,就会一下来到程序的OEP了!)
1.开始就点F8,注意观察OD右上角的寄存器中ESP有没出现。
2.在命令行下:dd 0012FFA4(指在当前代码中的ESP地址),按回车!
3.选种下断的地址,下硬件访问WORD断点。
4.按一下F9运行程序,直接来到了跳转处,按下F8,到达程序OEP,脱壳
方法三:
内存跟踪:
1:用OD打开软件!
2:点击选项——调试选项——异常,把里面的忽略全部√上!CTRL+F2重载下程序!
3:按ALT+M,DA 打开内存镜象,找到第一个。rsrc.按F2下断点,
然后按SHIFT+F9运行到断点,接着再按ALT+M,DA 打开内存镜象,找到。RSRC上面的CODE,按
F2下断点!然后按SHIFT+F9,直接到达程序OEP,脱壳!
方法四:
一步到达OEP(前辈们总结的经验)
1.开始按Ctrl+F,输入:popad(只适合少数壳,包括ASPACK壳),然后按下F2,F9运行到此处
2.来到大跳转处,点下F8,脱壳之!
方法五:
1:用OD打开软件!
2:点击选项——调试选项——异常,把里面的√全部去掉!CTRL+F2重载下程序!
3:一开是程序就是一个跳转,在这里我们按SHIFT+F9,直到程序运行,记下从开始按F9到程序
运行的次数!
4:CTRL+F2重载程序,按SHIFT+F9(次数为程序运行的次数-1次
5:在OD的右下角我们看见有一个SE 句柄,这时我们按CTRL+G,输入SE 句柄前的地址!
6:按F2下断点!然后按SHIFT+F9来到断点处!
7:去掉断点,按F8慢慢向下走!
8:到达程序的OEP,脱壳!
Reference
[1]http://www.2cto.com/article/201212/172850.html
[2]http://blog.csdn.net/secondwatch/article/details/7823654
[3]VillanCh http://www.freebuf.com/news/others/86147.html
[4]http://baike.baidu.com/link?url=15J-2DYBVDA4EvUMFYTHm45U8OIXkkvioU35egSK3aEuq6JzNLYfSv7n9iXUn2gaRJLty4y6gpxN6hUMWXe7zuxfxHqLDTI_s2wZji6zXs-gzt9gvlzHngAYnGfHkraD
[5]VillanCh http://www.freebuf.com/articles/system/86596.html