一、大白话MapReduce
1.什么是Map/Reduce,看下面的各种解释:
(1)MapReduce是hadoop的核心组件之一,hadoop要分布式包括两部分,一是分布式文件系统hdfs,一部是分布式计算框,就是mapreduce,缺一不可,也就是说,可以通过mapreduce很容易在hadoop平台上进行分布式的计算编程。
(2)Mapreduce是一种编程模型,是一种编程方法,抽象理论。
(3)下面是一个关于一个程序员是如何个妻子讲解什么是MapReduce?文章很长请耐心的看。
我问妻子:“你真的想要弄懂什么是MapReduce?” 她很坚定的回答说“是的”。 因此我问道:
我: 你是如何准备洋葱辣椒酱的?(以下并非准确食谱,请勿在家尝试)
妻子: 我会取一个洋葱,把它切碎,然后拌入盐和水,最后放进混合研磨机里研磨。这样就能得到洋葱辣椒酱了。
妻子: 但这和MapReduce有什么关系?
我: 你等一下。让我来编一个完整的情节,这样你肯定可以在15分钟内弄懂MapReduce.
妻子: 好吧。
我:现在,假设你想用薄荷、洋葱、番茄、辣椒、大蒜弄一瓶混合辣椒酱。你会怎么做呢?
妻子: 我会取薄荷叶一撮,洋葱一个,番茄一个,辣椒一根,大蒜一根,切碎后加入适量的盐和水,再放入混合研磨机里研磨,这样你就可以得到一瓶混合辣椒酱了。
我: 没错,让我们把MapReduce的概念应用到食谱上。Map和Reduce其实是两种操作,我来给你详细讲解下。
Map(映射): 把洋葱、番茄、辣椒和大蒜切碎,是各自作用在这些物体上的一个Map操作。所以你给Map一个洋葱,Map就会把洋葱切碎。 同样的,你把辣椒,大蒜和番茄一一地拿给Map,你也会得到各种碎块。 所以,当你在切像洋葱这样的蔬菜时,你执行就是一个Map操作。 Map操作适用于每一种蔬菜,它会相应地生产出一种或多种碎块,在我们的例子中生产的是蔬菜块。在Map操作中可能会出现有个洋葱坏掉了的情况,你只要把坏洋葱丢了就行了。所以,如果出现坏洋葱了,Map操作就会过滤掉坏洋葱而不会生产出任何的坏洋葱块。
Reduce(化简):在这一阶段,你将各种蔬菜碎都放入研磨机里进行研磨,你就可以得到一瓶辣椒酱了。这意味要制成一瓶辣椒酱,你得研磨所有的原料。因此,研磨机通常将map操作的蔬菜碎聚集在了一起。
妻子: 所以,这就是MapReduce?
我: 你可以说是,也可以说不是。 其实这只是MapReduce的一部分,MapReduce的强大在于分布式计算。
妻子: 分布式计算? 那是什么?请给我解释下吧。
我: 没问题。
我: 假设你参加了一个辣椒酱比赛并且你的食谱赢得了最佳辣椒酱奖。得奖之后,辣椒酱食谱大受欢迎,于是你想要开始出售自制品牌的辣椒酱。假设你每天需要生产10000瓶辣椒酱,你会怎么办呢?
妻子: 我会找一个能为我大量提供原料的供应商。
我:是的..就是那样的。那你能否独自完成制作呢?也就是说,独自将原料都切碎? 仅仅一部研磨机又是否能满足需要?而且现在,我们还需要供应不同种类的辣椒酱,像洋葱辣椒酱、青椒辣椒酱、番茄辣椒酱等等。
妻子: 当然不能了,我会雇佣更多的工人来切蔬菜。我还需要更多的研磨机,这样我就可以更快地生产辣椒酱了。
我:没错,所以现在你就不得不分配工作了,你将需要几个人一起切蔬菜。每个人都要处理满满一袋的蔬菜,而每一个人都相当于在执行一个简单的Map操作。每一个人都将不断的从袋子里拿出蔬菜来,并且每次只对一种蔬菜进行处理,也就是将它们切碎,直到袋子空了为止。
这样,当所有的工人都切完以后,工作台(每个人工作的地方)上就有了洋葱块、番茄块、和蒜蓉等等。
妻子:但是我怎么会制造出不同种类的番茄酱呢?
我:现在你会看到MapReduce遗漏的阶段—搅拌阶段。MapReduce将所有输出的蔬菜碎都搅拌在了一起,这些蔬菜碎都是在以key为基础的 map操作下产生的。搅拌将自动完成,你可以假设key是一种原料的名字,就像洋葱一样。 所以全部的洋葱keys都会搅拌在一起,并转移到研磨洋葱的研磨器里。这样,你就能得到洋葱辣椒酱了。同样地,所有的番茄也会被转移到标记着番茄的研磨器里,并制造出番茄辣椒酱。
上面都是从理论上来说明什么是MapReduce,那么咱们在MapReduce产生的过程和代码的角度来理解这个问题。
问题:如果想统计下过去10年计算机论文出现最多的几个单词,看看大家都在研究些什么,那收集好论文后,该怎么办呢?
方法一:
我可以写一个小程序,把所有论文按顺序遍历一遍,统计每一个遇到的单词的出现次数,最后就可以知道哪几个单词最热门了。 这种方法在数据集比较小时,是非常有效的,而且实现最简单,用来解决这个问题很合适。
方法二:
写一个多线程程序,并发遍历论文。
这个问题理论上是可以高度并发的,因为统计一个文件时不会影响统计另一个文件。当我们的机器是多核或者多处理器,方法二肯定比方法一高效。但是写一个多线程程序要比方法一困难多了,我们必须自己同步共享数据,比如要防止两个线程重复统计文件。
方法三:
把作业交给多个计算机去完成。
我们可以使用方法一的程序,部署到N台机器上去,然后把论文集分成N份,一台机器跑一个作业。这个方法跑得足够快,但是部署起来很麻烦,我们要人工把程序copy到别的机器,要人工把论文集分开,最痛苦的是还要把N个运行结果进行整合(当然我们也可以再写一个程序)。
方法四:
让MapReduce来帮帮我们吧!
MapReduce本质上就是方法三,但是如何拆分文件集,如何copy程序,如何整合结果这些都是框架定义好的。我们只要定义好这个任务(用户程序),其它都交给MapReduce。
map函数和reduce函数
map函数和reduce函数是交给用户实现的,这两个函数定义了任务本身。
map函数:接受一个键值对(key-value pair),产生一组中间键值对。MapReduce框架会将map函数产生的中间键值对里键相同的值传递给一个reduce函数。
reduce函数:接受一个键,以及相关的一组值,将这组值进行合并产生一组规模更小的值(通常只有一个或零个值)
二 MapReduce实现wordcount
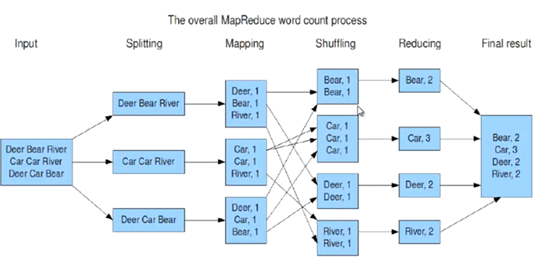
编程实现wordcount


/*
* KEYIN:输入kv数据对中key的数据类型
* VALUEIN:输入kv数据对中value的数据类型
* KEYOUT:输出kv数据对中key的数据类型
* VALUEOUT:输出kv数据对中value的数据类型
*/
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable>{
/*
* map方法是提供给map task进程来调用的,map task进程是每读取一行文本来调用一次我们自定义的map方法
* map task在调用map方法时,传递的参数:
* 一行的起始偏移量LongWritable作为key
* 一行的文本内容Text作为value
*/
@Override
protected void map(LongWritable key, Text value,Context context) throws IOException, InterruptedException {
//拿到一行文本内容,转换成String 类型
String line = value.toString();
//将这行文本切分成单词
String[] words=line.split(" ");
//输出<单词,1>
for(String word:words){
context.write(new Text(word), new IntWritable(1));
}
}
}
/*
* KEYIN:对应mapper阶段输出的key类型
* VALUEIN:对应mapper阶段输出的value类型
* KEYOUT:reduce处理完之后输出的结果kv对中key的类型
* VALUEOUT:reduce处理完之后输出的结果kv对中value的类型
*/
public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable>{
@Override
/*
* reduce方法提供给reduce task进程来调用
*
* reduce task会将shuffle阶段分发过来的大量kv数据对进行聚合,聚合的机制是相同key的kv对聚合为一组
* 然后reduce task对每一组聚合kv调用一次我们自定义的reduce方法
* 比如:<hello,1><hello,1><hello,1><tom,1><tom,1><tom,1>
* hello组会调用一次reduce方法进行处理,tom组也会调用一次reduce方法进行处理
* 调用时传递的参数:
* key:一组kv中的key
* values:一组kv中所有value的迭代器
*/
protected void reduce(Text key, Iterable<IntWritable> values,Context context) throws IOException, InterruptedException {
//定义一个计数器
int count = 0;
//通过value这个迭代器,遍历这一组kv中所有的value,进行累加
for(IntWritable value:values){
count+=value.get();
}
//输出这个单词的统计结果
context.write(key, new IntWritable(count));
}
}
public class WordCountJobSubmitter {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
Job wordCountJob = Job.getInstance(conf);
//重要:指定本job所在的jar包
wordCountJob.setJarByClass(WordCountJobSubmitter.class);
//设置wordCountJob所用的mapper逻辑类为哪个类
wordCountJob.setMapperClass(WordCountMapper.class);
//设置wordCountJob所用的reducer逻辑类为哪个类
wordCountJob.setReducerClass(WordCountReducer.class);
//设置map阶段输出的kv数据类型
wordCountJob.setMapOutputKeyClass(Text.class);
wordCountJob.setMapOutputValueClass(IntWritable.class);
//设置最终输出的kv数据类型
wordCountJob.setOutputKeyClass(Text.class);
wordCountJob.setOutputValueClass(IntWritable.class);
//设置要处理的文本数据所存放的路径
FileInputFormat.setInputPaths(wordCountJob, "hdfs://192.168.77.70:9000/wordcount/srcdata/");
FileOutputFormat.setOutputPath(wordCountJob, new Path("hdfs://192.168.77.70:9000/wordcount/output/"));
//提交job给hadoop集群
wordCountJob.waitForCompletion(true);
}
}
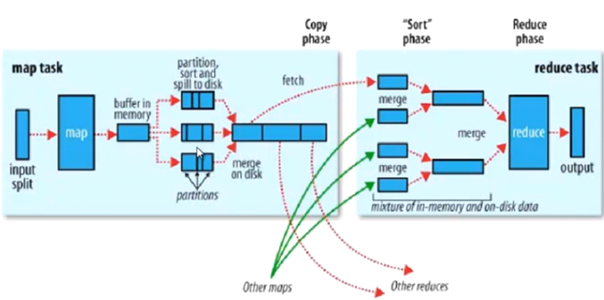
三、 MapReduce过程详解
MapReduce过程:
Input --》 Map --》 shuffle --》 Reduce --》 Output
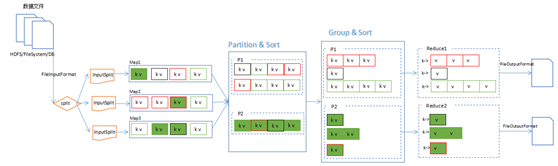
MapReduce中,分片、分区、排序和分组(Group)的关系图:
分片大小
对于HDFS中存储的一个文件,要进行Map处理前,需要将它切分成多个块,才能分配给不同的MapTask去执行。 分片的数量等于启动的MapTask的数量。默认情况下,分片的大小就是HDFS的blockSize。
Map阶段的对数据文件的切片,使用如下判断逻辑:
protected long computeSplitSize(long blockSize, long minSize,
long maxSize) {
return Math.max(minSize, Math.min(maxSize, blockSize));
}
blockSize:默认大小是128M(dfs.blocksize)
minSize:默认是1byte(mapreduce.input.fileinputformat.split.minsize):
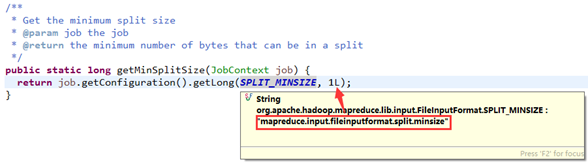
maxSize:默认值是Long.MaxValue(mapreduce.input.fileinputformat.split.minsize)
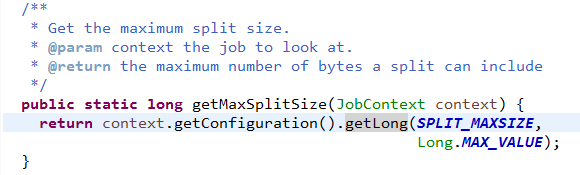
由此可以看出两个可以自定义的值(minSize和maxSize)与blockSize之间的关系如下:
当blockSize位于minSize和maxSize 之间时,认blockSize:
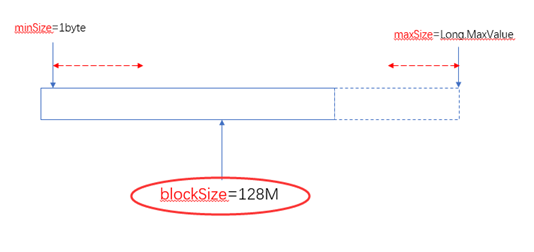
当maxSize小于blockSize时,认maxSize:
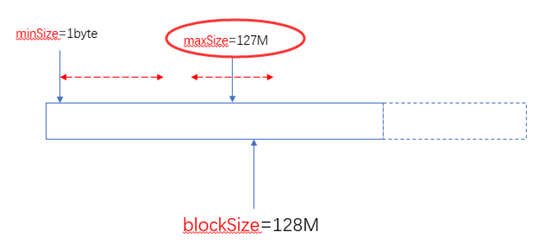
当minSize大于blockSize时,认minSize:
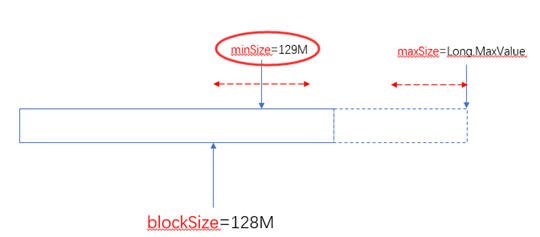
另外一个极端的情况,maxSize小于minSize时,认minsize,可以理解为minSize的优先级比maxSize大:
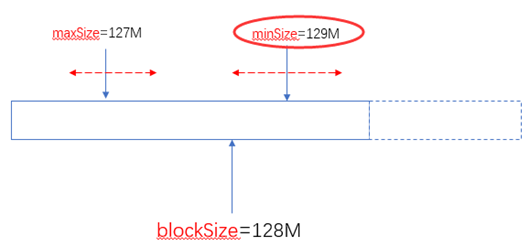
实际使用中,建议不要去修改maxSize,通过调整minSize(使他大于blockSize)就可以设定分片(Split)的大小了。
总之通过minSize和maxSize的来设置切片大小,使之在blockSize的上下自由调整。
什么时候需要调整分片的大小
首先要明白,HDFS的分块其实是指HDFS在存储文件时的一个参数。而这里分片的大小是为了业务逻辑用的。分片的大小直接影响到MapTask的数量,你可以根据实际的业务需求来调整分片的大小。
分区
在Reduce过程中,可以根据实际需求(比如按某个维度进行归档,类似于数据库的分组),把Map完的数据Reduce到不同的文件中。分区的设置需要与ReduceTaskNum配合使用。比如想要得到5个分区的数据结果。那么就得设置5个ReduceTask。
自定义Partitioner:
public class URLResponseTimePartitioner extends Partitioner<Text, LongWritable>{
@Override
public int getPartition(Text key, LongWritable value, int numPartitions) {
String accessPath = key.toString();
if(accessPath.endsWith(".do")) {
return 0;
}
return 1;
}
}
然后可以在job中设置partitioner:
job.setPartitionerClass(URLResponseTimePartitioner.class);
//URLResponseTimePartitioner returns 1 or 0,so num of reduce task must be 2
job.setNumReduceTasks(2);
两个分区会产生两个最终结果文件:
[root@centos01 ~]# hadoop fs -ls /access/log/response-time17/12/19 14:53:55 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Found 3 items-rw-r--r-- 2 root supergroup 0 2017-12-19 14:49 /access/log/response-time/_SUCCESS-rw-r--r-- 2 root supergroup 7769 2017-12-19 14:49 /access/log/response-time/part-r-00000
-rw-r--r-- 2 root supergroup 18183 2017-12-19 14:49 /access/log/response-time/part-r-00001
其中00000中存放着.do的统计结果,00001则存放其他访问路径的统计结果。
[root@centos01 ~]# hadoop fs -cat /access/log/response-time/part-r-00001 |more17/12/19 14:55:41 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable//MyAdmin/scripts/setup.php 3857//css/console.css 356//css/result_html.css 628//images/male.png 268//js/tooltipster/css/plugins/tooltipster/sideTip/themes/tooltipster-sideTip-borderless.min.css 1806//js/tooltipster/css/tooltipster.bundle.min.css 6495//myadmin/scripts/setup.php 3857//phpMyAdmin/scripts/setup.php 3857//phpmyadmin/scripts/setup.php 3857//pma/scripts/setup.php 3857
/404/search_children.js 3827
/Dashboard.action 3877
/Homepage.action 3877
/My97DatePicker/WdatePicker.js 9371
/My97DatePicker/calendar.js 22044
/My97DatePicker/lang/zh-cn.js 1089
/My97DatePicker/skin/WdatePicker.css 158
/My97DatePicker/skin/default/datepicker.css 3486
/My97DatePicker/skin/default/img.gif 475
排序
要想最终结果中按某个特性排序,则需要在Map阶段,通过Key的排序来实现。
例如,想让上述平均响应时间的统计结果按降序排列,实现如下:
关键就在于这个用于OUTKey的Bean。它实现了Comparable接口,所以输出的结果就是按compareTo的结果有序。
由于这个类会作为Key,所以它的equals方法很重要,会作为,需要按实际情况重写。这里重写的逻辑是url相等则表示是同一个Key。(虽然Key相同的情况其实没有,因为之前的responseTime统计结果已经把url做了group,但是这里还是要注意有这么个逻辑。)
排序并不是依赖于key的equals!
public class URLResponseTime implements WritableComparable<URLResponseTime>{
String url;
long avgResponseTime;
publicvoid write(DataOutput out) throws IOException {
out.writeUTF(url);
out.writeLong(avgResponseTime);
}
publicvoid readFields(DataInput in) throws IOException {
this.url = in.readUTF();
this.avgResponseTime = in.readLong();
}
publicint compareTo(URLResponseTime urt) {
returnthis.avgResponseTime > urt.avgResponseTime ? -1 : 1;
}
public String getUrl() {
return url;
}
publicvoid setUrl(String url) {
this.url = url;
}
publiclong getAvgResponseTime() {
return avgResponseTime;
}
publicvoid setAvgResponseTime(long avgResponseTime) {
this.avgResponseTime = avgResponseTime;
}
@Override
publicint hashCode() {
finalint prime = 31;
int result = 1;
result = prime * result + ((url == null) ? 0 : url.hashCode());
return result;
}
@Override
publicboolean equals(Object obj) {
if (this == obj)
returntrue;
if (obj == null)
returnfalse;
if (getClass() != obj.getClass())
returnfalse;
URLResponseTime other = (URLResponseTime) obj;
if (url == null) {
if (other.url != null)
returnfalse;
} elseif (!url.equals(other.url))
returnfalse;
returntrue;
}
@Override
public String toString() {
return url;
}
}
然后就简单了,在Map和Reduce分别执行简单的写和读操作就行了,没有更多的处理,依赖于Hadoop MapReduce框架自身的特点就实现了排序:
MapReduce排序分组
https://www.cnblogs.com/sunddenly/p/4009751.html
四、Mapreduce 项目实战
需求:
用户行为日志清洗,分析出用户行为链。
实现方式:根据用户曝光页面时间排序。(粗略)
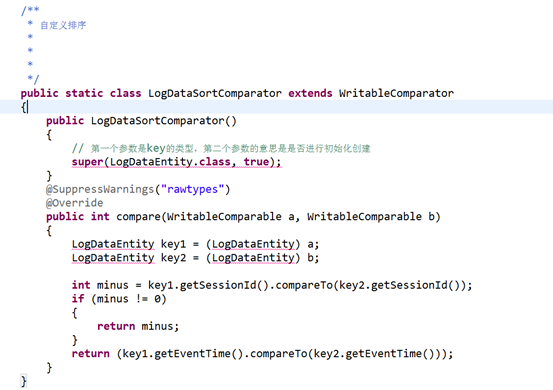
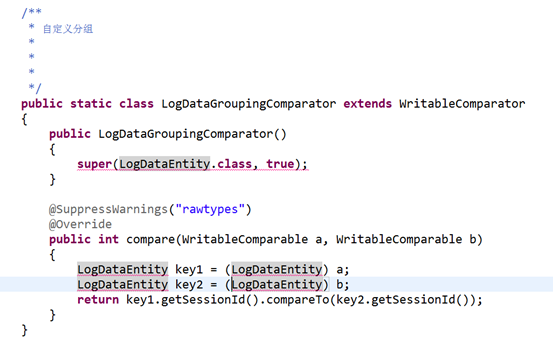
自定义分区,分组,排序
job.setSortComparatorClass(LogDataSortComparator.class);
job.setGroupingComparatorClass(LogDataGroupingComparator.class);
job.setPartitionerClass(LogDataPartitioner.class); //自定义分区

五、Hive 设置map 和 reduce 的个数
Hive 设置map 和 reduce 的个数
https://www.cnblogs.com/1130136248wlxk/articles/5352154.html
Hive 设置map 和 reduce 的个数
一、 控制hive任务中的map数:
1. 通常情况下,作业会通过input的目录产生一个或者多个map任务。
主要的决定因素有: input的文件总个数,input的文件大小,集群设置的文件块大小(目前为128M, 可在hive中通过set dfs.block.size;命令查看到,该参数不能自定义修改);
2. 举例:
a) 假设input目录下有1个文件a,大小为780M,那么hadoop会将该文件a分隔成7个块(6个128m的块和1个12m的块),从而产生7个map数
b) 假设input目录下有3个文件a,b,c,大小分别为10m,20m,130m,那么hadoop会分隔成4个块(10m,20m,128m,2m),从而产生4个map数
即,如果文件大于块大小(128m),那么会拆分,如果小于块大小,则把该文件当成一个块。
3. 是不是map数越多越好?
答案是否定的。如果一个任务有很多小文件(远远小于块大小128m),则每个小文件也会被当做一个块,用一个map任务来完成,
而一个map任务启动和初始化的时间远远大于逻辑处理的时间,就会造成很大的资源浪费。
而且,同时可执行的map数是受限的。
4. 是不是保证每个map处理接近128m的文件块,就高枕无忧了?
答案也是不一定。比如有一个127m的文件,正常会用一个map去完成,但这个文件只有一个或者两个小字段,却有几千万的记录,
如果map处理的逻辑比较复杂,用一个map任务去做,肯定也比较耗时。
针对上面的问题3和4,我们需要采取两种方式来解决:即减少map数和增加map数;
如何合并小文件,减少map数?
假设一个SQL任务:
Select count(1) from popt_tbaccountcopy_mes where pt = ‘2012-07-04’;
该任务的inputdir /group/p_sdo_data/p_sdo_data_etl/pt/popt_tbaccountcopy_mes/pt=2012-07-04
共有194个文件,其中很多是远远小于128m的小文件,总大小9G,正常执行会用194个map任务。
Map总共消耗的计算资源: SLOTS_MILLIS_MAPS= 623,020
我通过以下方法来在map执行前合并小文件,减少map数:
set mapred.max.split.size=100000000;
set mapred.min.split.size.per.node=100000000;
set mapred.min.split.size.per.rack=100000000;
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;
再执行上面的语句,用了74个map任务,map消耗的计算资源:SLOTS_MILLIS_MAPS= 333,500
对于这个简单SQL任务,执行时间上可能差不多,但节省了一半的计算资源。
大概解释一下,100000000表示100M, set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;这个参数表示执行前进行小文件合并,
前面三个参数确定合并文件块的大小,大于文件块大小128m的,按照128m来分隔,小于128m,大于100m的,按照100m来分隔,把那些小于100m的(包括小文件和分隔大文件剩下的),
进行合并,最终生成了74个块。
如何适当的增加map数?
当input的文件都很大,任务逻辑复杂,map执行非常慢的时候,可以考虑增加Map数,来使得每个map处理的数据量减少,从而提高任务的执行效率。
假设有这样一个任务:
Select data_desc,
count(1),
count(distinct id),
sum(case when …),
sum(case when ...),
sum(…)
from a group by data_desc
如果表a只有一个文件,大小为120M,但包含几千万的记录,如果用1个map去完成这个任务,肯定是比较耗时的,这种情况下,我们要考虑将这一个文件合理的拆分成多个,
这样就可以用多个map任务去完成。
set mapred.reduce.tasks=10;
create table a_1 as
select * from a
distribute by rand(123);
这样会将a表的记录,随机的分散到包含10个文件的a_1表中,再用a_1代替上面sql中的a表,则会用10个map任务去完成。
每个map任务处理大于12M(几百万记录)的数据,效率肯定会好很多。
看上去,貌似这两种有些矛盾,一个是要合并小文件,一个是要把大文件拆成小文件,这点正是重点需要关注的地方,
根据实际情况,控制map数量需要遵循两个原则:使大数据量利用合适的map数;使单个map任务处理合适的数据量;
二、 控制hive任务的reduce数:
1. Hive自己如何确定reduce数:
reduce个数的设定极大影响任务执行效率,不指定reduce个数的情况下,Hive会猜测确定一个reduce个数,基于以下两个设定:
hive.exec.reducers.bytes.per.reducer(每个reduce任务处理的数据量,默认为1000^3=1G)
hive.exec.reducers.max(每个任务最大的reduce数,默认为999)
计算reducer数的公式很简单N=min(参数2,总输入数据量/参数1)
即,如果reduce的输入(map的输出)总大小不超过1G,那么只会有一个reduce任务;
如:select pt,count(1) from popt_tbaccountcopy_mes where pt = '2012-07-04' group by pt;
/group/p_sdo_data/p_sdo_data_etl/pt/popt_tbaccountcopy_mes/pt=2012-07-04 总大小为9G多,因此这句有10个reduce
2. 调整reduce个数方法一:
调整hive.exec.reducers.bytes.per.reducer参数的值;
set hive.exec.reducers.bytes.per.reducer=500000000; (500M)
select pt,count(1) from popt_tbaccountcopy_mes where pt = '2012-07-04' group by pt; 这次有20个reduce
3. 调整reduce个数方法二;
set mapred.reduce.tasks = 15;
select pt,count(1) from popt_tbaccountcopy_mes where pt = '2012-07-04' group by pt;这次有15个reduce
4. reduce个数并不是越多越好;
同map一样,启动和初始化reduce也会消耗时间和资源;
另外,有多少个reduce,就会有多少个输出文件,如果生成了很多个小文件,那么如果这些小文件作为下一个任务的输入,则也会出现小文件过多的问题;
5. 什么情况下只有一个reduce;
很多时候你会发现任务中不管数据量多大,不管你有没有设置调整reduce个数的参数,任务中一直都只有一个reduce任务;
其实只有一个reduce任务的情况,除了数据量小于hive.exec.reducers.bytes.per.reducer参数值的情况外,还有以下原因:
a) 没有group by的汇总,比如把select pt,count(1) from popt_tbaccountcopy_mes where pt = '2012-07-04' group by pt; 写成 select count(1) from popt_tbaccountcopy_mes where pt = '2012-07-04';
这点非常常见,希望大家尽量改写。
b) 用了Order by
c) 有笛卡尔积
通常这些情况下,除了找办法来变通和避免,我暂时没有什么好的办法,因为这些操作都是全局的,所以hadoop不得不用一个reduce去完成;
同样的,在设置reduce个数的时候也需要考虑这两个原则:使大数据量利用合适的reduce数;使单个reduce任务处理合适的数据量;