云计算实验(二)Hadoop 练习
1、实验目的
搭建 Hadoop 运行环境,了解其基本操作。
2、实验内容
一、搭建 Hadoop
在个人电脑上搭建 Hadoop,操作系统 Linux/Windows 都可以,可使用虚拟机,单节点(如果时间充裕,可以搭建多节点)。
参考:
http://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/SingleCluster.html
https://wiki.apache.org/hadoop/Hadoop2OnWindows
网上还有很多中文资料,可自行搜索。
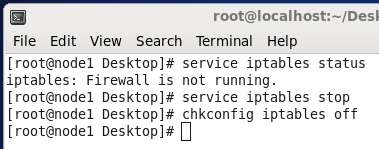
1、为了实验的方便起见,彻底关闭防火墙
2、更改了计算机名为node1 node2 node3,方便操作。
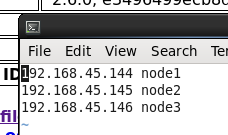
3、三者的ip地址



4、更改三者的hosts文件(名称和ip对应),这里是因为hadoop规定必须要有名称
vi /etc/hosts
5、如果为了方便起见,可以直接安装openjdk,如果是生产环境可能考虑要手动安装。

我之前已经安装了jdk1.8,位置在/usr/bin/java(注意这只是个程序)安装命令是
yum install java-1.8.0-openjdk-devel.x86_64
我这里不是直接安装的,而是手动安装的jdk1.7,复制解压配置path即可,比较简单,不再赘述,位置在/usr/java/jdk1.7.0_80,程序jdk版本和hadoop使用的jdk版本不要搞错了,否则运行的时候报错。
6、SSH协议配置
SSH全称secure shell ,默认22端口,通俗的来讲是用来连接远程linux服务器的,使用了非对称加密算法, 熟悉RSA的人应该对此很了解,而且它主要有两个作用,正向和逆向能用来加密或验证。在每个用户下的.ssh文件夹里有四个文件authorized_keys id_rsa id_rsa.pub known_hosts,分别是存放的公钥、私钥、公钥和已知的客户端,已知的客户端主要是为了防范中间人攻击的,存放的公钥是用来保存可以登录的主机地公钥,因为只有对应私钥加密的内容才能被公钥解密,所以可以用来验证客户端身份。所以我们只用每个服务器生成一对公钥和私钥,再把3个公钥放到一个文本文档里authorized_keys,再复制到另外两个客户端里即可。
7、测试登录,由于三者都一样,故不再赘述。
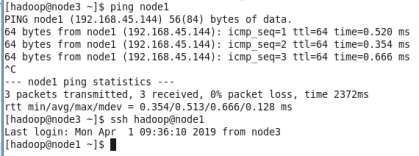
用这种方式登录的好处是不需要再输入密码,一次设置,永远安全。同时这也是hadoop的必须达到的要求,因为它需要主机之间自由的通信和操作。
8、下载hadoop-2.6.0.tar.gz,解压,这里我解压过了就不再运行了
x是解压的意思,z是对应tar.gz文件的意思(tar是将多个文件合并为一个文件,gz是一种压缩格式),v是verbose (啰嗦)就是在页面上打印调试信息,f指定文件,一定要写在所有可选选项的最后。

9、配置java位置

都加入一句话

为你安装java的位置
10、编写配置文件



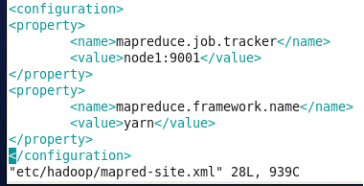
11、只有master才需要编写slaves文件
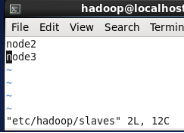
12、格式化
-
NameNode 格式化
bin/hdfs namenode -format – 产生一个Cluster ID -
指定Cluster ID
bin/hdfs namenode -format -clusterid yarn-cluster
13、启动各项服务
-
启动NameNode
sbin/hadoop-daemon.sh start namenode -
启动DataNode
sbin/hadoop-daemon.sh start datanode -
启动SecondaryNameNode
sbin/hadoop-daemon.sh start secondarynamenode
。。。。。。
14、全部启动成功后查看JPS
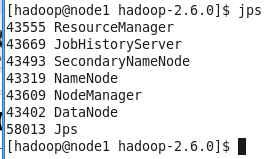
至此说明安装并启动成功。
15、安装成功,面板上Live Npdes显示3个节点都已经启动,其中node1是主节点,node2 node3是从节点

二、运行第一个 Hadoop 实例wordcount
Wordcount 是 Hadoop 中的 HelloWorld 的程序。尝试正确运行 Wordcount。
1、创建输入和输出文件夹,存放所有的输入文件和输出,本次实验输入文件夹为/data/wordcount/ 输出文件夹为 /output 注意输出文件夹必须不存在,由程序自行创建,不能手动创建,这是hadoop的规定,没有为什么。
1.[hadoop@node1 mapreduce]$ /home/hadoop/hadoop-2.6.0/bin/hadoop fs -mkdir -p /data/wordcount
2.19/04/28 09:03:58 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform… using builtin-java classes where applicable
3.[hadoop@node1 mapreduce]$ /home/hadoop/hadoop-2.6.0/bin/hadoop fs -ls /
4.19/04/28 09:04:21 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform… using builtin-java classes where applicable
5.Found 5 items
6.drwxr-xr-x - hadoop supergroup 0 2019-04-28 09:04 /data
7.drwxr-xr-x - hadoop supergroup 0 2019-04-02 01:47 /output
8.drwxr-xr-x - hadoop supergroup 0 2019-04-02 01:27 /people
9.drwxr-xr-x - hadoop supergroup 0 2019-04-21 23:55 /tmp
10.drwxr-xr-x - hadoop supergroup 0 2019-04-02 01:37 /user
11.[hadoop@node1 mapreduce]$ /home/hadoop/hadoop-2.6.0/bin/hadoop fs -rm -r /output
12.19/04/28 09:04:44 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform… using builtin-java classes where applicable
13.19/04/28 09:04:45 INFO fs.TrashPolicyDefault: Namenode trash configuration: Deletion interval = 0 minutes, Emptier interval = 0 minutes.
14.Deleted /output
2、创建一个文本文本用来做词频统计
15.[hadoop@node1 mapreduce]$ cat > myword.txt
16.leaf yyh
17.yyh xpleaf
18.katy ling
19.yeyonghao leaf
20.xpleaf katy
3、上传该文本到hdfs
21.[hadoop@node1 mapreduce]$ /home/hadoop/hadoop-2.6.0/bin/hadoop fs -put myword.txt /data/wordcount
22.19/04/28 09:05:47 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform… using builtin-java classes where applicable
23.[hadoop@node1 mapreduce]$ /home/hadoop/hadoop-2.6.0/bin/hadoop fs -ls /data/wordcount
24.19/04/28 09:06:09 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform… using builtin-java classes where applicable
25.Found 1 items
26.-rw-r–r-- 2 hadoop supergroup 57 2019-04-28 09:05 /data/wordcount/myword.txt
27.[hadoop@node1 mapreduce]$ /home/hadoop/hadoop-2.6.0/bin/hadoop fs -cat /data/wordcount
28.19/04/28 09:06:24 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform… using builtin-java classes where applicable
29.cat: `/data/wordcount’: Is a directory
4、打印已上传到hdfs的文本文档
30.[hadoop@node1 mapreduce]$ /home/hadoop/hadoop-2.6.0/bin/hadoop fs -cat /data/wordcount/myword.txt
31.19/04/28 09:06:39 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform… using builtin-java classes where applicable
32.leaf yyh
33.yyh xpleaf
34.katy ling
35.yeyonghao leaf
36.xpleaf katy
5、运行自带的wordcount程序
37.[hadoop@node1 mapreduce]$ /home/hadoop/hadoop-2.6.0/bin/hadoop jar hadoop-mapreduce-examples-2.6.0.jar wordcount /data/wordcount /output
38.19/04/28 09:08:23 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform… using builtin-java classes where applicable
39.19/04/28 09:08:26 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032
40.19/04/28 09:08:30 INFO input.FileInputFormat: Total input paths to process : 1
41.19/04/28 09:08:30 INFO mapreduce.JobSubmitter: number of splits:1
42.19/04/28 09:08:31 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1554212690488_0004
43.19/04/28 09:08:32 INFO impl.YarnClientImpl: Submitted application application_1554212690488_0004
44.19/04/28 09:08:33 INFO mapreduce.Job: The url to track the job: http://node1:8088/proxy/application_1554212690488_0004/
45.19/04/28 09:08:33 INFO mapreduce.Job: Running job: job_1554212690488_0004
46.19/04/28 09:08:59 INFO mapreduce.Job: Job job_1554212690488_0004 running in uber mode : false
47.19/04/28 09:08:59 INFO mapreduce.Job: map 0% reduce 0%
48.19/04/28 09:09:17 INFO mapreduce.Job: map 100% reduce 0%
49.19/04/28 09:09:36 INFO mapreduce.Job: map 100% reduce 100%
50.19/04/28 09:09:37 INFO mapreduce.Job: Job job_1554212690488_0004 completed successfully
51.19/04/28 09:09:38 INFO mapreduce.Job: Counters: 49
52. File System Counters
53. FILE: Number of bytes read=78
54. FILE: Number of bytes written=212117
55. FILE: Number of read operations=0
56. FILE: Number of large read operations=0
57. FILE: Number of write operations=0
58. HDFS: Number of bytes read=165
59. HDFS: Number of bytes written=48
60. HDFS: Number of read operations=6
61. HDFS: Number of large read operations=0
62. HDFS: Number of write operations=2
63. Job Counters
64. Launched map tasks=1
65. Launched reduce tasks=1
66. Data-local map tasks=1
67. Total time spent by all maps in occupied slots (ms)=14647
68. Total time spent by all reduces in occupied slots (ms)=15235
69. Total time spent by all map tasks (ms)=14647
70. Total time spent by all reduce tasks (ms)=15235
71. Total vcore-seconds taken by all map tasks=14647
72. Total vcore-seconds taken by all reduce tasks=15235
73. Total megabyte-seconds taken by all map tasks=14998528
74. Total megabyte-seconds taken by all reduce tasks=15600640
75. Map-Reduce Framework
76. Map input records=5
77. Map output records=10
78. Map output bytes=97
79. Map output materialized bytes=78
80. Input split bytes=108
81. Combine input records=10
82. Combine output records=6
83. Reduce input groups=6
84. Reduce shuffle bytes=78
85. Reduce input records=6
86. Reduce output records=6
87. Spilled Records=12
88. Shuffled Maps =1
89. Failed Shuffles=0
90. Merged Map outputs=1
91. GC time elapsed (ms)=321
92. CPU time spent (ms)=3430
93. Physical memory (bytes) snapshot=283787264
94. Virtual memory (bytes) snapshot=1680564224
95. Total committed heap usage (bytes)=136056832
96. Shuffle Errors
97. BAD_ID=0
98. CONNECTION=0
99. IO_ERROR=0
100. WRONG_LENGTH=0
101. WRONG_MAP=0
102. WRONG_REDUCE=0
103. File Input Format Counters
104. Bytes Read=57
105. File Output Format Counters
106. Bytes Written=48
6、实验结果
107.[hadoop@node1 mapreduce]$ /home/hadoop/hadoop-2.6.0/bin/hadoop fs -cat /output/part-r-00000
108.19/04/28 09:12:59 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform… using builtin-java classes where applicable
109.katy 2
110.leaf 2
111.ling 1
112.xpleaf 2
113.yeyonghao 1
114.yyh 2
115.[hadoop@node1 mapreduce]$
7、结果截图

三、拓展:自己编写wordcount
项目结构
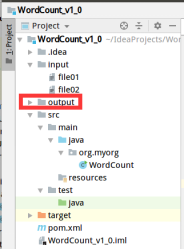
- 本地测试的时候要删除output文件夹(hadoop的规定)。
pom依赖
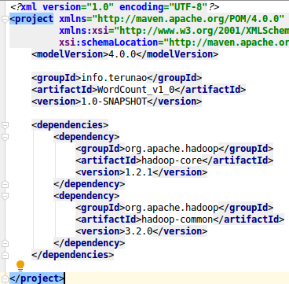
代码

本地测试
main函数的参数设置 输入文件夹input 输出文件夹output

输入文件夹input下的两个文件
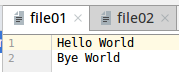
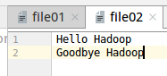
本地测试运行结果

手动上传到云端测试
使用maven工具或命令打包成jar

复制jar手动上传到服务器

检查了权限发现的确属于hadoop用户和组
运行
发现了jdk版本不符的错误

改变jdk版本再打包
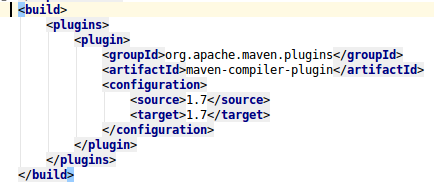
还是报错,仔细检查了之后发现是我习惯不好,在mvn packging之前应该先clean一下,否则会影响打包好的jar。
1.[hadoop@node1 ~]$ /home/hadoop/hadoop-2.6.0/bin/hadoop jar WordCount_v1_0-1.0-SNAPSHOT.jar org.myorg.WordCount /data/wordcount /output
2.19/04/29 01:15:43 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform… using builtin-java classes where applicable
3.19/04/29 01:15:44 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032
4.19/04/29 01:15:44 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032
5.19/04/29 01:15:45 WARN mapreduce.JobSubmitter: Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this.
6.19/04/29 01:15:45 INFO mapred.FileInputFormat: Total input paths to process : 1
7.19/04/29 01:15:45 INFO mapreduce.JobSubmitter: number of splits:2
8.19/04/29 01:15:46 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1554212690488_0005
9.19/04/29 01:15:46 INFO impl.YarnClientImpl: Submitted application application_1554212690488_0005
10.19/04/29 01:15:46 INFO mapreduce.Job: The url to track the job: http://node1:8088/proxy/application_1554212690488_0005/
11.19/04/29 01:15:46 INFO mapreduce.Job: Running job: job_1554212690488_0005
12.19/04/29 01:15:55 INFO mapreduce.Job: Job job_1554212690488_0005 running in uber mode : false
13.19/04/29 01:15:55 INFO mapreduce.Job: map 0% reduce 0%
14.19/04/29 01:16:09 INFO mapreduce.Job: map 100% reduce 0%
15.19/04/29 01:16:17 INFO mapreduce.Job: map 100% reduce 100%
16.19/04/29 01:16:18 INFO mapreduce.Job: Job job_1554212690488_0005 completed successfully
17.19/04/29 01:16:18 INFO mapreduce.Job: Counters: 49
18. File System Counters
19. FILE: Number of bytes read=113
20. FILE: Number of bytes written=318501
21. FILE: Number of read operations=0
22. FILE: Number of large read operations=0
23. FILE: Number of write operations=0
24. HDFS: Number of bytes read=276
25. HDFS: Number of bytes written=48
26. HDFS: Number of read operations=9
27. HDFS: Number of large read operations=0
28. HDFS: Number of write operations=2
29. Job Counters
30. Launched map tasks=2
31. Launched reduce tasks=1
32. Data-local map tasks=2
33. Total time spent by all maps in occupied slots (ms)=20922
34. Total time spent by all reduces in occupied slots (ms)=5634
35. Total time spent by all map tasks (ms)=20922
36. Total time spent by all reduce tasks (ms)=5634
37. Total vcore-seconds taken by all map tasks=20922
38. Total vcore-seconds taken by all reduce tasks=5634
39. Total megabyte-seconds taken by all map tasks=21424128
40. Total megabyte-seconds taken by all reduce tasks=5769216
41. Map-Reduce Framework
42. Map input records=5
43. Map output records=10
44. Map output bytes=97
45. Map output materialized bytes=119
46. Input split bytes=190
47. Combine input records=10
48. Combine output records=9
49. Reduce input groups=6
50. Reduce shuffle bytes=119
51. Reduce input records=9
52. Reduce output records=6
53. Spilled Records=18
54. Shuffled Maps =2
55. Failed Shuffles=0
56. Merged Map outputs=2
57. GC time elapsed (ms)=261
58. CPU time spent (ms)=2330
59. Physical memory (bytes) snapshot=470757376
60. Virtual memory (bytes) snapshot=2517786624
61. Total committed heap usage (bytes)=256581632
62. Shuffle Errors
63. BAD_ID=0
64. CONNECTION=0
65. IO_ERROR=0
66. WRONG_LENGTH=0
67. WRONG_MAP=0
68. WRONG_REDUCE=0
69. File Input Format Counters
70. Bytes Read=86
71. File Output Format Counters
72. Bytes Written=48
73.[hadoop@node1 ~]$ /home/hadoop/hadoop-2.6.0/bin/hadoop fs -cat /output/part-00000
74.19/04/29 01:25:13 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform… using builtin-java classes where applicable
75.katy 2
76.leaf 2
77.ling 1
78.xpleaf 2
79.yeyonghao 1
80.yyh 2
81.[hadoop@node1 hadoop-2.6.0]$
由于结果一致,故不再赘述。
手动上传还是很麻烦,可以考虑用eclipse的hadoop插件,自己编写hdfs代码上传等方式