2019独角兽企业重金招聘Python工程师标准>>> 
对所有的技术人员来说,业务可靠性提升是一个系统工程,涉及网络管理、IDC管理、服务器管理、交付管理、变更管理、故障管理、监控管理、预案管理、根因分析、容量规划、容灾演练、标准化建设、集成测试、泛操作管理、权限管理、数据安全管理等方方面面,随着先进技术的应用、业务云化、微服务化等,业务架构变得更加复杂,任何一个环节出现问题,哪怕是一个小问题都可能演变成大故障,我们更加迫切需要一种新的方式提升业务可靠性。
业界做法和阿里云的探索
先跟大家聊聊业界是怎么多的?诸如Netflix探索通过异常注入的方式提升其视频服务的可靠性[1],已经演进成独立的“混沌自动化平台”(ChAP,Chaos Automation Platform);Microsoft Azure 在Netflix之后也研发了自己的异常注入平台;Google通过研发自动化平台来替代传统模型中的人工操作,在业务可靠性提升的重要方向都有对应的平台实现,参考《Site. Reliability. Engineering》;在阿里云已经有了Monkey King 平台,实现系统级别诸如宕机、磁盘掉盘、网卡丢包等异常注入。Netflix ChAP关注的是业务自身可靠性提升,不太适合专有云以及公共云这种模式;Google很多平台基于其强大的研发能力,在产品内部实现大量可靠性设计与代码嵌入,我们现在还比较难直接照搬;Monkey King已经能很好的实现异常注入的功能,但该注入哪些异常,该如何评估云产品的可靠性还在探索中。结合综上实践和思考,我们在业界经验的基础上,结合云特点正在探索通过混沌工程理念[2]提升系统可靠性。
混沌工程理念:指在系统可靠性设计范围内实践一些可在系统(对专有云是在仿真系统)内引发失效的实验,在进行每个实验之前工程师会提出一个导致系统失效的假设场景,进而设计一个实验去引发或模拟该场景,并以受控、自动化的方式开展实验。通过观测系统的反馈,对不符合预期的结果进行深入分析并持续改进。在我们的实践中重点关注系统可靠性提升的三个问题:
1. 该如何降低故障频度、重复故障比例、提升监控有效性与故障处理效率
- 该如何量化评估云产品的可靠性,是否存在隐患,优化建议是什么
- 该如何帮助云用户提升其业务可靠性
通过混沌工程提升可靠性包括如下图示几大部分:

1、SSRD设计
和对应产品的负责人一起确定用哪些指标来描述服务的稳定状态,常见的指标可以参考服务的SLA、SLO设计。这些指标主要用来描述系统的可靠性设计以及衡量的指标。在这个过程中,我们会和云产品的负责人一起通过历史故障分析讨论我们的云产品可靠性该如何设计,是否需要增加进而逐渐完善云产品的可靠性体系。
2、FMEA分析
针对云产品的特性、所运行的环境、强弱依赖分析、故障频次、发生后影响、历史故障等因素建立故障关联模型,诸如系统是否可冗余单点异常、发生频率是什么、如果发生对用户影响有多大等等。
3、ACP(Apsara Chaos Platform)
实现基础异常注入、复杂任务编排以及异常任务自动调度功能
本文将重点介绍FMEA分析以及ACP平台
FMEA分析和ACP平台介绍
为了发现业务存在的隐患,我们首先需要想清楚需要构建哪些异常,为此我们从公共云以及专有云海量故障入手,通过对这些故障的分析、聚类,我们抽取了第一版云平台下的105种故障模式,通过这些基础故障及其组合我们可以构建超万种异常场景。
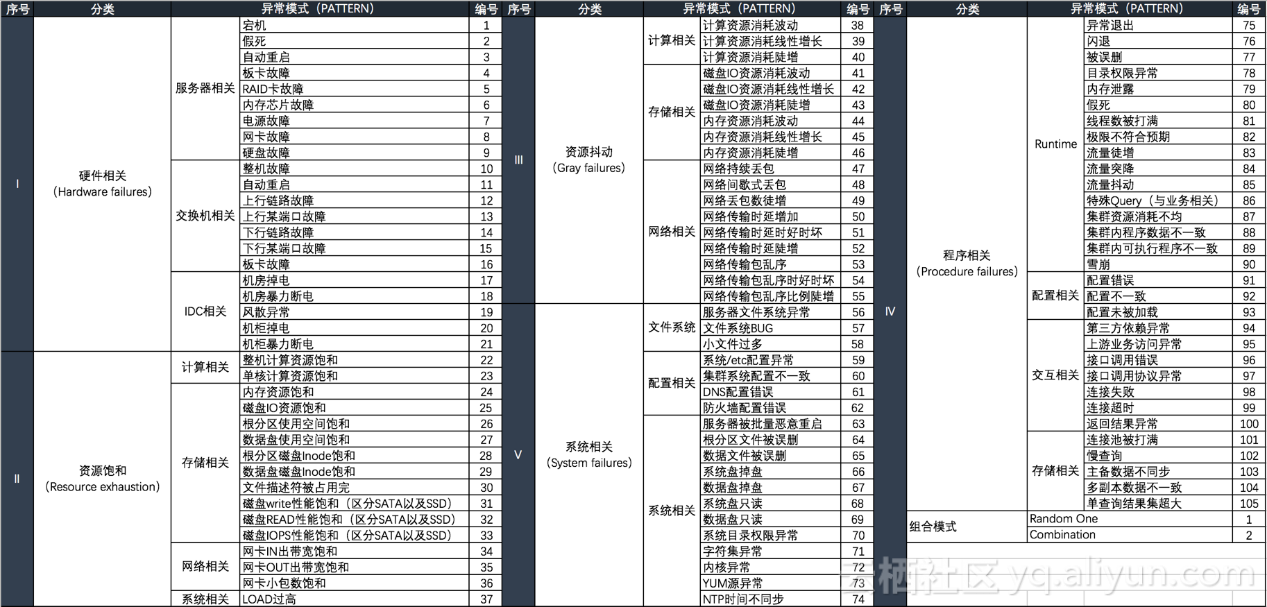
另外20%左右故障基于现有技术无法有效的模拟,比如第三方依赖引入的问题、程序BUG以及特殊机型硬件等异常。
回顾这些基于上千种CASE抽取的故障模式,感慨万深,每一次故障都是血的教训,我们努力的避免并预防故障的发生。而如今恰恰也是这些宝贵的经验与知识再一次指引我们未来的方向。在一期我们还是大量依靠人工来分析和提炼这些异常模式,难免有遗漏和不准确,目前在进行中的二期我们正探索通过AI方式抽取更复杂的故障模式进而覆盖更广的异常场景,未来有了新成果也会和各位读者共同探讨
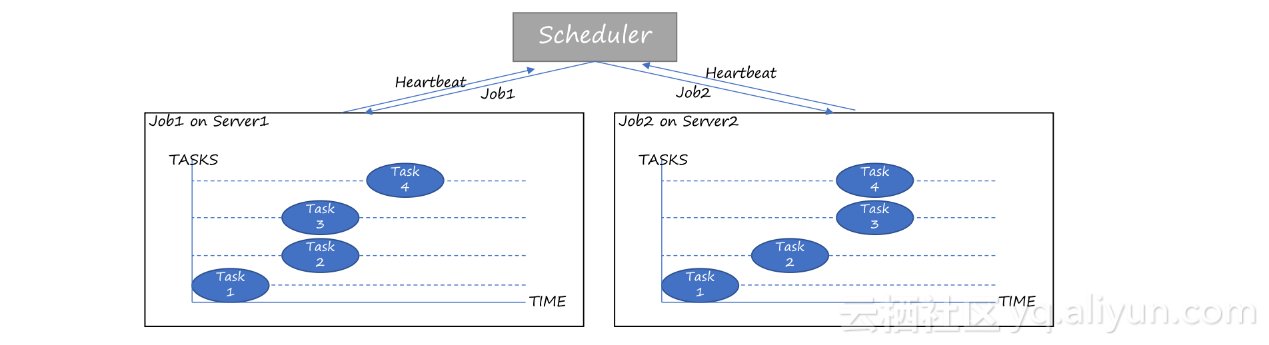
在ACP设计中,Scene用来描述异常场景,每个异常Pattern可以创建一个单一的异常场景。也可以由一个或几个基础异常组合而成,组合的方式见下文异常立方体模型。任务调度引擎实现对Scene的调度,每次异常注入对应一个JOB(任务),当前系统为了保证Scene不会被反复调度,全局控制保证一个Scene只能被调度一次。每个JOB提供若干操作原语(CREATE、DELETE、START、STOP、SUSPEND)提供人工干预接口。同步后台会有Service Check模块,主动关注SSRD中涉及的核心指标,如果发现异常会自动触发JOB暂停。我们尝试进行一场场景的仿真,比如 Gray failures异常,它是诸如服务器假死、网络抖动、IO hang、某个硬件设备单核CPU被打满、流量陡增等异常。这些看似小问题系统稍微处理不当便可能演变成大故障。
如下图我们预期随着业务量增涨资源消耗是线性增涨,但实际上可能是业务量增涨到某个节点,资源还没有达到瓶颈的时候,性能确急剧下降而出现严重的雪崩点。如果我们不能及时发现这些隐患点,那么在生产系统高峰期发生的时候会是非常可怕的。
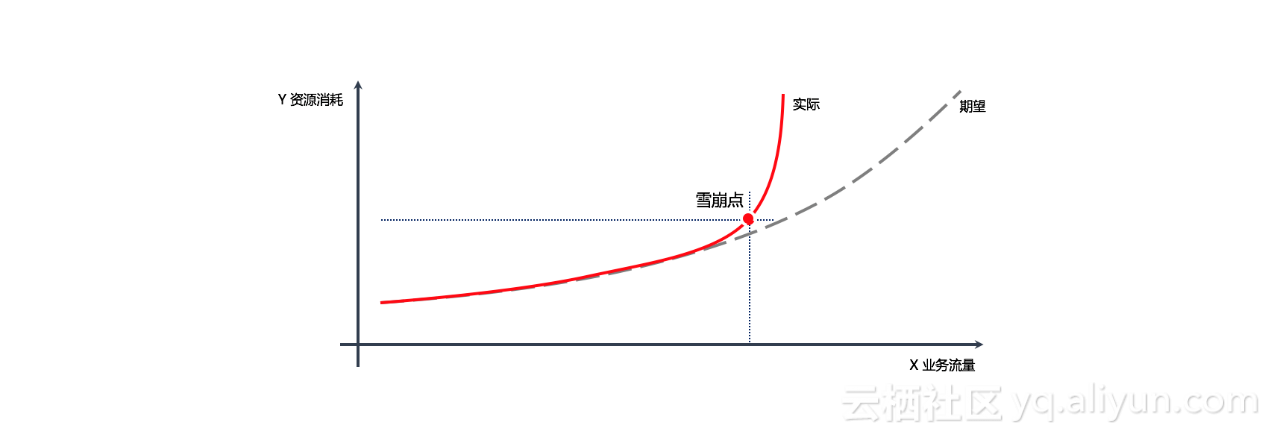
因此在ACP平台上,我们在集成集团Monkey King平台第一、二大类异常仿真的基础上开发了Gray failures异常仿真引擎,支持诸如通过线性方式模拟CPU消耗自然增长、通过正弦方式模拟网络抖动式丢包、通过高斯方式模拟流量陡增等异常仿真,如下图所示:

为了能支持更复杂的组合类异常场景,我们调研了Airflow[3]以及Jenkins[4]等工作流引擎,都能满足需求,但Jenkins偏重,每次流创建和生成都需要分钟以上,难以满足时效性要求。Airflow依赖第三方库非常多,会偶尔出现流夯住的问题,虽然是开源的,但代码量巨大,出现问题定位和修复成本非常高。为此我们实现了类似Airflow一样的轻量级流编排引擎,可以满足简单任务的编排需求。但从长期来看,我们更倾向于切换到Airflow进而支持更高并发量、更复杂的流描述能力。
除此之外,为了能支撑超万种异常场景自动调度,我们自研了分布式任务调度框架,消除单点隐患以及解决未来高吞吐场景的需求。当前在任务调度引擎中已经引入优先级的概念,支持三种任务级别,同级别中的任务无优先级,采用FIFO的方式调度,支持并发度控制。
ACP 交互界面展示分享
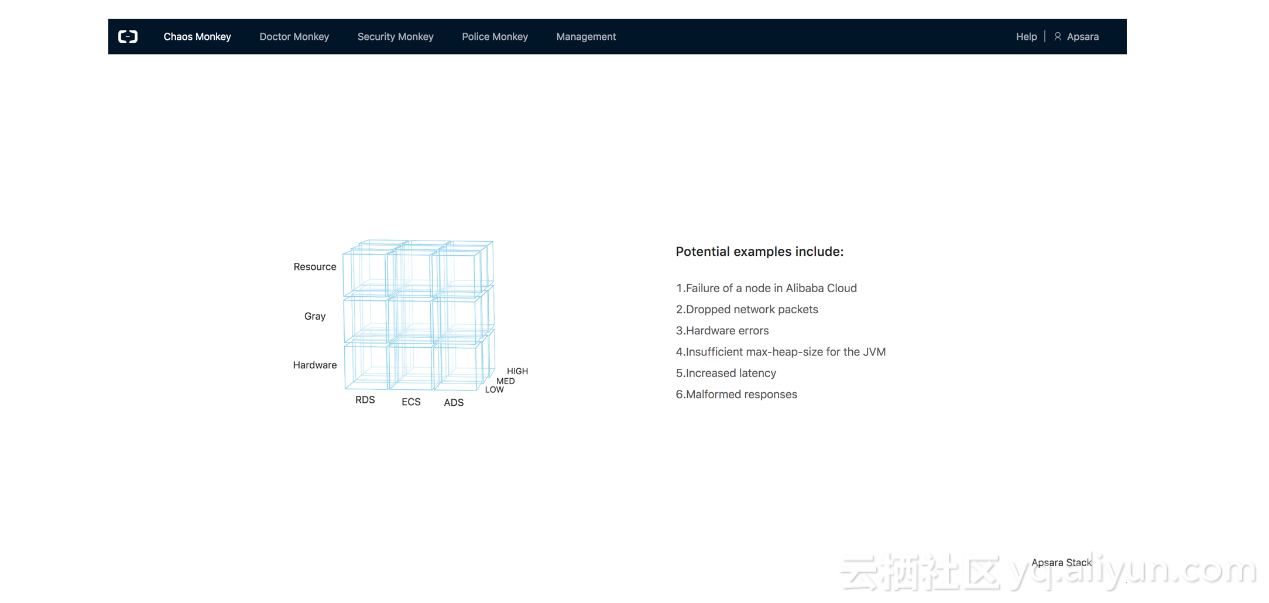
为了更好管理异常组合,我们引入了数据立方体概念,每个小方块代表一类基础异常,对于数据立方体,我们可以通过切片、切块、上卷(roll-up)、下钻(drill-down)等方式生成更复杂的组合类异常。异常立方体中我们会对异常进行分级:
Low级别:系统对于这些异常可以优雅自动恢复无需人工干预;
Medium级别:系统可以从这些异常中优雅恢复,但可能会导致一些业务降级或者服务可靠性的影响;
High级别:这个级别的异常注入对服务可靠性存在较大的影响,需要较多的人工干预才能恢复。
样例:对任意一个异常事件 Ae =F(X=1,Y=1,Z=1) 表示RDS的Low程度的Hardware Failure(Low级别诸如宕机故障)
ACP任务创建PORTAL

通过如下多种随机模式可以覆盖尽可能多的异常模拟
Mode:Single:指定异常注入对象;Random One:随机选择一个操作对象;Sequence:顺序选择所有操作对象
Device:Single:指定操作设备;Random One:随机选择一个操作设备;
Pattern:Linear:线性模拟;Sine:正弦模拟;Gaussian:高斯模拟
ACP异常模式四象限
用来描述这些异常PATTERN对用户的潜在影响,目标不断通过技术、管理、流程等手段将第一象限中高风险、高影响的隐患优化到第三象限(更低的风险以及更小的影响)

云产品可靠性设计与隐患消除
专有云有它的特殊性,故障在专有云的环境下往往影响更大,一个单一的故障在几百朵云内可能就是几百次故障.....更需要我们在产品设计过程中消除隐患,而这个过程可行方式之一就是启动SSRD设计,在产品构建之初启动可靠性设计并通过FMEA分析以及ACP不断挖掘潜在隐患并打磨故障处理的整个闭环,如下图:

在整个实验过程中,我们不断观测并采集系统的核心指标:
1、监控是否能及时发现,是否有报警
2、出现的故障,全链路监控是否能及时发现
3、对应的预案是否生效
4、系统的自愈能力是否符合设计预期
5、如果系统没有达到预期,该如何优化
对任何环节存在缺失或者不完善的隐患,持续推动优化
云产品的可靠性量化评估一直比较棘手,传统方式更多依靠经验来评估。有了ACP以及不断积累的异常场景知识库,我们便可以在仿真环境下验证并给出量化的评估结果,而这些不但可以提早帮云产品发现潜在的隐患而且可以给出优化的建议和方向。有一个很重要的场景就是业务上云以后其所在的运行环境已经发生了巨变,而用户的业务需要提早适应新的环境以及应对新的挑战,最有效的方式之一就是通过容灾演练在业务无流量或仿真环境下模拟异常发生并观测业务的应激能力,对发现的问题及早推动改进和优化,提前消除隐患。
现在还有一个难点就是针对不同的云产品我们该建立哪些异常场景?这还需要继续实践。非常欢迎各位云产品的负责人和技术同学一起参与进来共建,一同携手提升产品的可靠性。
附录:
[1]. https://blog.codecentric.de/en/2018/07/chaos-engineering/
[2]. 混沌(Chaos theory)一词原指宇宙未形成之前的混沌状态,混沌现象起因于物体不断以某种规则复制前一阶段的运动状态而产生无法预测的随机效果,易发生于变动的系统中,该系统在行动之初极为单纯,但经过一定时间连续变动之后却产生始料未及的后果,也就是混沌状态。
[3]. Airflow:http://airflow.incubator.apache.org/
[4]. Jenkins: https://jenkins.io/
了解更多“云产品持续拥有稳定性的实践”尽在阿里云总监课第五期,戳链接了解详情:https://yq.aliyun.com/promotion/689&tlog=out_aiticai_zongjianke_20181206
原文链接