2019独角兽企业重金招聘Python工程师标准>>> 
一、spark三种运行方式
1、local单机模式:
./bin/spark-submit --class org.apache.spark.examples.SparkPi --master local[1] ./lib/spark-examples-1.3.1-hadoop2.4.0.jar 100
运行结果可以在xshell看见:如图所示

2、standalone集群模式:
需要的配置项
1, slaves文件 指定从节点的ip
# A Spark Worker will be started on each of the machines listed below.
#localhost
node22
node33
2, 在spark-env.sh中添加如下信息
export JAVA_HOME=/usr/local/java/jdk
export SPARK_MASTER_IP=node11 #指定主节点的ip
export SPARK_MASTER_PORT=7077
export SPARK_WORKER_CORES=1
export SPARK_WORKER_INSTANCES=1
export SPARK_WORKER_MEMORY=1g
3、把配置好的spark-1.3.1-bin-hadoop2.4文件复制到其他两台机器上
scp -r spark-1.3.1-bin-hadoop2.4/ node22:/usr/local/java/
scp -r spark-1.3.1-bin-hadoop2.4/ node33:/usr/local/java/
4、启动spark 在 /usr/local/java/spark-1.3.1-bin-hadoop2.4/sbin文件下执行
命令 [root@node11 sbin]# ./start-all.sh
在浏览器中输入 http://node11:8080/index.htm 出现如下界面表示启动成功
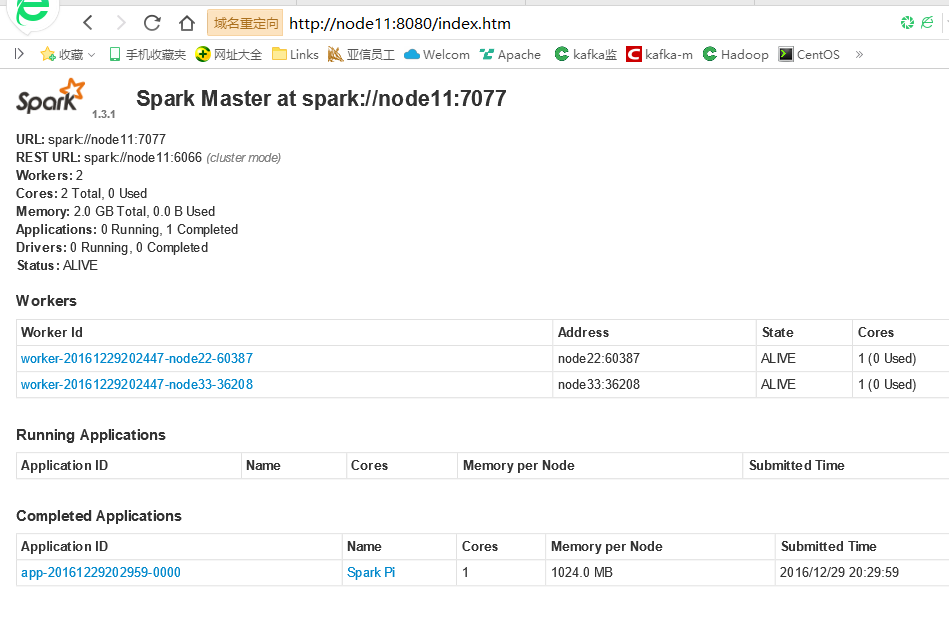
standalone集群模式:
之client模式:
./bin/spark-submit --class org.apache.spark.examples.SparkPi --master spark://node11:7077 --executor-memory 1G --total-executor-cores 1 ./lib/spark-examples-1.3.1-hadoop2.4.0.jar 100
运行结果可以在xshell看见:如图所示

standalone集群模式:
之cluster模式:
结果node11:8080里面可见!
./bin/spark-submit --class org.apache.spark.examples.SparkPi --master spark://node11:7077 --deploy-mode cluster --supervise --executor-memory 1G --total-executor-cores 1 ./lib/spark-examples-1.3.1-hadoop2.4.0.jar 100
3、Yarn集群模式:
需要的配置项
1, spark-env.sh
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
export SPARK_HOME=/usr/local/java/spark-1.3.1-bin-hadoop2.4
export SPARK_JAR=/usr/local/java/spark-1.3.1-bin-hadoop2.4/lib/spark-assembly-1.3.1-hadoop2.4.0.jar
export PATH=$SPARK_HOME/bin:$PATH
2, ~/.bash_profile
配置好hadoop环境变量
3、启动zookeeper集群 zookeeper集群安装参考 https://my.oschina.net/xiaozhou18/blog/787132
4、启动hadoop集群 hadoop安装 参考 https://my.oschina.net/xiaozhou18/blog/787902
Yarn集群模式:
client模式:
./bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn-client --executor-memory 1G --num-executors 1 ./lib/spark-examples-1.3.1-hadoop2.4.0.jar 100
运行结果可以在xshell看见:如图所示

Yarn集群模式:
cluster模式:
结果spark001:8088里面可见!
./bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn-cluster --executor-memory 1G --num-executors 1 ./lib/spark-examples-1.3.1-hadoop2.4.0.jar 100
二、在xshell中写第一个spark的wordcount程序
1、启动spark xshell
[root@node11 bin]# ./spark-shell --master yarn-client
2、读取文件里的数据 (这个文件要保证在每台节点上都有)
scala> var lines = sc.textFile("file:///usr/local/java/spark-1.3.1-bin-hadoop2.4/README.md")
3、按空格分隔数据
scala> var words=lines.flatMap(_.split(" "))
4、把每个单词作为key value是1 后面用来做统计单词数量用
scala> var pairs=words.map((_,1))
5、把每个单词计数相加
scala> var result=pairs.reduceByKey(_+_)
//如果想按照单词出现的次数进行排序
//用sortByKey
//result.map(x=>x._2->x._1)
//scala>result.sortByKey(false).map(x=>x._2->x._1).collect()
//sortByKey(false)按照key进行升序进行排序
//map(x=>x._2->x._1) 把map中的key,value颠倒位置
//用sortBy
//result.sortBy(_._2,false).collect() 第一个_表示集合中的每个元素 _2表示每个集合中的第二个元素也就是value false表示按value的升序排序
6、提交job作业 把结果存到hdfs上
scala> result.saveAsTextFile("hdfs://hadoopservice/spark.txt")
7、spark rdd例子
http://homepage.cs.latrobe.edu.au/zhe/ZhenHeSparkRDDAPIExamples.html
三、spark常用算子
#常用Transformation(即转换,延迟加载)
#通过并行化scala集合创建RDD
val rdd1 = sc.parallelize(Array(1,2,3,4,5,6,7,8))
#查看该rdd的分区数量
rdd1.partitions.length
val rdd1 = sc.parallelize(List(5,6,4,7,3,8,2,9,1,10))
val rdd2 = sc.parallelize(List(5,6,4,7,3,8,2,9,1,10)).map(_*2).sortBy(x=>x,true)
val rdd3 = rdd2.filter(_>10)
val rdd2 = sc.parallelize(List(5,6,4,7,3,8,2,9,1,10)).map(_*2).sortBy(x=>x+"",true)
val rdd2 = sc.parallelize(List(5,6,4,7,3,8,2,9,1,10)).map(_*2).sortBy(x=>x.toString,true)
val rdd4 = sc.parallelize(Array("a b c", "d e f", "h i j"))
rdd4.flatMap(_.split(' ')).collect
val rdd5 = sc.parallelize(List(List("a b c", "a b b"),List("e f g", "a f g"), List("h i j", "a a b")))
rdd5.flatMap(_.flatMap(_.split(" "))).collect
#union求并集,注意类型要一致
val rdd6 = sc.parallelize(List(5,6,4,7))
val rdd7 = sc.parallelize(List(1,2,3,4))
val rdd8 = rdd6.union(rdd7)
rdd8.distinct.sortBy(x=>x).collect
#intersection求交集
val rdd9 = rdd6.intersection(rdd7)
val rdd1 = sc.parallelize(List(("tom", 1), ("jerry", 2), ("kitty", 3)))
val rdd2 = sc.parallelize(List(("jerry", 9), ("tom", 8), ("shuke", 7)))
#join
val rdd3 = rdd1.join(rdd2)
val rdd3 = rdd1.leftOuterJoin(rdd2)
val rdd3 = rdd1.rightOuterJoin(rdd2)
#groupByKey
val rdd3 = rdd1 union rdd2
rdd3.groupByKey
rdd3.groupByKey.map(x=>(x._1,x._2.sum))
#WordCount, 第二个效率低
sc.textFile("/root/words.txt").flatMap(x=>x.split(" ")).map((_,1)).reduceByKey(_+_).sortBy(_._2,false).collect
sc.textFile("/root/words.txt").flatMap(x=>x.split(" ")).map((_,1)).groupByKey.map(t=>(t._1, t._2.sum)).collect
#cogroup
val rdd1 = sc.parallelize(List(("tom", 1), ("tom", 2), ("jerry", 3), ("kitty", 2)))
val rdd2 = sc.parallelize(List(("jerry", 2), ("tom", 1), ("shuke", 2)))
val rdd3 = rdd1.cogroup(rdd2)
val rdd4 = rdd3.map(t=>(t._1, t._2._1.sum + t._2._2.sum))
#cartesian笛卡尔积
val rdd1 = sc.parallelize(List("tom", "jerry"))
val rdd2 = sc.parallelize(List("tom", "kitty", "shuke"))
val rdd3 = rdd1.cartesian(rdd2)
###################################################################################################
#spark action
val rdd1 = sc.parallelize(List(1,2,3,4,5), 2)
#collect
rdd1.collect
#reduce
val rdd2 = rdd1.reduce(_+_)
#count
rdd1.count
#top 按升序后取前两个
rdd1.top(2)
#take 取前两个
rdd1.take(2)
#first(similer to take(1)) 取第一个
rdd1.first
#takeOrdered 按照某个规则排序后取前三个
rdd1.takeOrdered(3)
四、高级算子
http://homepage.cs.latrobe.edu.au/zhe/ZhenHeSparkRDDAPIExamples.html
map是对每个元素操作, mapPartitions是对其中的每个partition操作
-------------------------------------------------------------------------------------------
-------------------------------------------------------------------------------------------
mapPartitionsWithIndex : 把每个partition中的分区号和对应的值拿出来
val func = (index: Int, iter: Iterator[(Int)]) => {
iter.toList.map(x => "[partID:" + index + ", val: " + x + "]").iterator
}
val rdd1 = sc.parallelize(List(1,2,3,4,5,6,7,8,9), 2)
rdd1.mapPartitionsWithIndex(func).collect
-------------------------------------------------------------------------------------------
-------------------------------------------------------------------------------------------
aggregate 先把分区里的数据聚合后 在把每个分区聚合后的数据 在聚合
def func1(index: Int, iter: Iterator[(Int)]) : Iterator[String] = {
iter.toList.map(x => "[partID:" + index + ", val: " + x + "]").iterator
}
val rdd1 = sc.parallelize(List(1,2,3,4,5,6,7,8,9), 2)
rdd1.mapPartitionsWithIndex(func1).collect
###是action操作, 第一个参数是初始值, 二:是2个函数[每个函数都是2个参数(第一个参数:先对个个分区进行合并, 第二个:对个个分区合并后的结果再进行合并), 输出一个参数]
###0 + (0+1+2+3+4 + 0+5+6+7+8+9)
rdd1.aggregate(0)(_+_, _+_)
rdd1.aggregate(0)(math.max(_, _), _ + _)
###5和1比, 得5再和234比得5 --> 5和6789比,得9 --> 5 + (5+9)
rdd1.aggregate(5)(math.max(_, _), _ + _)
val rdd2 = sc.parallelize(List("a","b","c","d","e","f"),2)
def func2(index: Int, iter: Iterator[(String)]) : Iterator[String] = {
iter.toList.map(x => "[partID:" + index + ", val: " + x + "]").iterator
}
rdd2.aggregate("")(_ + _, _ + _)
rdd2.aggregate("=")(_ + _, _ + _)
val rdd3 = sc.parallelize(List("12","23","345","4567"),2)
rdd3.aggregate("")((x,y) => math.max(x.length, y.length).toString, (x,y) => x + y)
val rdd4 = sc.parallelize(List("12","23","345",""),2)
rdd4.aggregate("")((x,y) => math.min(x.length, y.length).toString, (x,y) => x + y)
val rdd5 = sc.parallelize(List("12","23","","345"),2)
rdd5.aggregate("")((x,y) => math.min(x.length, y.length).toString, (x,y) => x + y)
-------------------------------------------------------------------------------------------
-------------------------------------------------------------------------------------------
aggregateByKey
val pairRDD = sc.parallelize(List( ("cat",2), ("cat", 5), ("mouse", 4),("cat", 12), ("dog", 12), ("mouse", 2)), 2)
def func2(index: Int, iter: Iterator[(String, Int)]) : Iterator[String] = {
iter.toList.map(x => "[partID:" + index + ", val: " + x + "]").iterator
}
pairRDD.mapPartitionsWithIndex(func2).collect
pairRDD.aggregateByKey(0)(math.max(_, _), _ + _).collect
pairRDD.aggregateByKey(100)(math.max(_, _), _ + _).collect
-------------------------------------------------------------------------------------------
-------------------------------------------------------------------------------------------
checkpoint
sc.setCheckpointDir("hdfs://node-1.itcast.cn:9000/ck")
val rdd = sc.textFile("hdfs://node-1.itcast.cn:9000/wc").flatMap(_.split(" ")).map((_, 1)).reduceByKey(_+_)
rdd.checkpoint
rdd.isCheckpointed
rdd.count
rdd.isCheckpointed
rdd.getCheckpointFile
-------------------------------------------------------------------------------------------
-------------------------------------------------------------------------------------------
coalesce, repartition
val rdd1 = sc.parallelize(1 to 10, 10)
val rdd2 = rdd1.coalesce(2, false)
rdd2.partitions.length
-------------------------------------------------------------------------------------------
-------------------------------------------------------------------------------------------
collectAsMap : Map(b -> 2, a -> 1)
val rdd = sc.parallelize(List(("a", 1), ("b", 2)))
rdd.collectAsMap
-------------------------------------------------------------------------------------------
-------------------------------------------------------------------------------------------
combineByKey : 和reduceByKey是相同的效果
###第一个参数x:原封不动取出来, 第二个参数:是函数, 局部运算, 第三个:是函数, 对局部运算后的结果再做运算
###每个分区中每个key中value中的第一个值, (hello,1)(hello,1)(good,1)-->(hello(1,1),good(1))-->x就相当于hello的第一个1, good中的1
val rdd1 = sc.textFile("hdfs://master:9000/wordcount/input/").flatMap(_.split(" ")).map((_, 1))
val rdd2 = rdd1.combineByKey(x => x, (a: Int, b: Int) => a + b, (m: Int, n: Int) => m + n)
rdd1.collect
rdd2.collect
###当input下有3个文件时(有3个block块, 不是有3个文件就有3个block, ), 每个会多加3个10
val rdd3 = rdd1.combineByKey(x => x + 10, (a: Int, b: Int) => a + b, (m: Int, n: Int) => m + n)
rdd3.collect
val rdd4 = sc.parallelize(List("dog","cat","gnu","salmon","rabbit","turkey","wolf","bear","bee"), 3)
val rdd5 = sc.parallelize(List(1,1,2,2,2,1,2,2,2), 3)
val rdd6 = rdd5.zip(rdd4)
val rdd7 = rdd6.combineByKey(List(_), (x: List[String], y: String) => x :+ y, (m: List[String], n: List[String]) => m ++ n)
-------------------------------------------------------------------------------------------
-------------------------------------------------------------------------------------------
countByKey
val rdd1 = sc.parallelize(List(("a", 1), ("b", 2), ("b", 2), ("c", 2), ("c", 1)))
rdd1.countByKey
rdd1.countByValue
-------------------------------------------------------------------------------------------
-------------------------------------------------------------------------------------------
filterByRange
val rdd1 = sc.parallelize(List(("e", 5), ("c", 3), ("d", 4), ("c", 2), ("a", 1)))
val rdd2 = rdd1.filterByRange("b", "d")
rdd2.collect
-------------------------------------------------------------------------------------------
-------------------------------------------------------------------------------------------
flatMapValues : Array((a,1), (a,2), (b,3), (b,4))
val rdd3 = sc.parallelize(List(("a", "1 2"), ("b", "3 4")))
val rdd4 = rdd3.flatMapValues(_.split(" "))
rdd4.collect
-------------------------------------------------------------------------------------------
-------------------------------------------------------------------------------------------
foldByKey
val rdd1 = sc.parallelize(List("dog", "wolf", "cat", "bear"), 2)
val rdd2 = rdd1.map(x => (x.length, x))
val rdd3 = rdd2.foldByKey("")(_+_)
val rdd = sc.textFile("hdfs://node-1.itcast.cn:9000/wc").flatMap(_.split(" ")).map((_, 1))
rdd.foldByKey(0)(_+_)
-------------------------------------------------------------------------------------------
-------------------------------------------------------------------------------------------
foreachPartition 分别对每个分区下的数据进行操作
val rdd1 = sc.parallelize(List(1, 2, 3, 4, 5, 6, 7, 8, 9), 3)
rdd1.foreachPartition(x => println(x.reduce(_ + _)))
-------------------------------------------------------------------------------------------
-------------------------------------------------------------------------------------------
keyBy : 以传入的参数做key
val rdd1 = sc.parallelize(List("dog", "salmon", "salmon", "rat", "elephant"), 3)
val rdd2 = rdd1.keyBy(_.length)
rdd2.collect
-------------------------------------------------------------------------------------------
-------------------------------------------------------------------------------------------
keys拿到所有的key values 拿到所有的value
val rdd1 = sc.parallelize(List("dog", "tiger", "lion", "cat", "panther", "eagle"), 2)
val rdd2 = rdd1.map(x => (x.length, x))
rdd2.keys.collect
rdd2.values.collect
-------------------------------------------------------------------------------------------
-------------------------------------------------------------------------------------------
五、分区
写一个类 继承 Partitioner 重写 以下两个方法
//总共分几个区
override def numPartitions: Int = 0
//将对应的key分到哪个分区里
override def getPartition(key: Any): Int = 0
分区应用demo
oobject UrlCountPartitioner {
def main(args: Array[String]): Unit = {
val config=new SparkConf().setAppName("urlcount").setMaster("local");
val sc=new SparkContext(config);
val logfile=sc.textFile("E:\\BaiduYunDownload\\day29\\itcast.log").map(
x=>{
val message=x.split("\t")(1);
//("www.java.com",1),("www.net.com",1),("www.php.com",1).....
(message,1)
}).reduceByKe
val aa=logfile.map(x=>{
val host=new URL(x._1).getHost;
(host,(x._1,x._2));
});
//获取所有学院的数量 后面分区用 不同学院分到不同分区
val bb=aa.map(_._1).distinct().collect();
//创建一个自定义分区
val mypartion=new MyPartitioner(bb);
//应用自定义分区 mapPartitions对分区里的数据进去操作
aa.partitionBy(mypartion).mapPartitions(it=>{
it.toList.sortBy(_._2._2).reverse.iterator
}).saveAsTextFile("d://out6")
sc.stop();
}
class MyPartitioner(partion:Array[String]) extends Partitioner{
val map=new mutable.HashMap[String,Int]();
var count=0;
for(i <-partion){
map +=(i -> count);
count +=1;
}
override def numPartitions: Int = partion.length;
override def getPartition(key: Any): Int ={
println("key==="+key.toString)
map.getOrElse(key.toString,0);
};
}
}
六、自定义排序
自定义个一个类 继承Ordered 重写compare方法
object OrderContext {
implicit val girlOrdering = new Ordering[Girl] {
override def compare(x: Girl, y: Girl): Int = {
if(x.faceValue > y.faceValue) 1
else if (x.faceValue == y.faceValue) {
if(x.age > y.age) -1 else 1
} else -1
}
}
}
/**
* Created by root on 2016/5/18.
*/
//sort =>规则 先按faveValue,比较年龄
//name,faveValue,age
object CustomSort {
def main(args: Array[String]) {
val conf = new SparkConf().setAppName("CustomSort").setMaster("local[2]")
val sc = new SparkContext(conf)
val rdd1 = sc.parallelize(List(("yuihatano", 90, 28, 1), ("angelababy", 90, 27, 2),("JuJingYi", 95, 22, 3)))
import OrderContext._
val rdd2 = rdd1.sortBy(x => Girl(x._2, x._3), false)
println(rdd2.collect().toBuffer)
sc.stop()
}
}
/**
* 第一种方式
* @param faceValue
* @param age
case class Girl(val faceValue: Int, val age: Int) extends Ordered[Girl] with Serializable {
override def compare(that: Girl): Int = {
if(this.faceValue == that.faceValue) {
that.age - this.age
} else {
this.faceValue -that.faceValue
}
}
}
*/
/**
* 第二种,通过隐式转换完成排序
* @param faceValue
* @param age
*/
case class Girl(faceValue: Int, age: Int) extends Serializable
七、缓存
//把读出来的数据缓存到内存
val result1=sc.textFile("D:\\word.txt").cache()
//释放内存
result1.unpersist(true)
spark 缓存级别
val NONE = new StorageLevel(false, false, false, false)
val DISK_ONLY = new StorageLevel(true, false, false, false)
val DISK_ONLY_2 = new StorageLevel(true, false, false, false, 2)
val MEMORY_ONLY = new StorageLevel(false, true, false, true)
val MEMORY_ONLY_2 = new StorageLevel(false, true, false, true, 2)
val MEMORY_ONLY_SER = new StorageLevel(false, true, false, false)
val MEMORY_ONLY_SER_2 = new StorageLevel(false, true, false, false, 2)
val MEMORY_AND_DISK = new StorageLevel(true, true, false, true)
val MEMORY_AND_DISK_2 = new StorageLevel(true, true, false, true, 2)
val MEMORY_AND_DISK_SER = new StorageLevel(true, true, false, false)
val MEMORY_AND_DISK_SER_2 = new StorageLevel(true, true, false, false, 2)
val OFF_HEAP = new StorageLevel(false, false, true, false)
spark checkpoint 数据保存点
spark 会先从内存中读取数据 如果内存没有会从checkpoint 设置的报存目录读取数据
//设置数据保存的地方
sc.setCheckpointDir("hdfs://node11:9000/")
//给result1 rdd的数据内容保存起来
val result1=sc.textFile("D:\\word.txt").checkpoint()
八、SparkSql
1、spark-shell 编写sparksql步骤
//1.读取数据,将每一行的数据使用列分隔符分割
val lineRDD = sc.textFile("hdfs://node1.itcast.cn:9000/person.txt", 1).map(_.split(" "))
//2.定义case class(相当于表的schema)
case class Person(id:Int, name:String, age:Int)
//3.导入隐式转换,在当前版本中可以不用导入
import sqlContext.implicits._
//4.将lineRDD转换成personRDD
val personRDD = lineRDD.map(x => Person(x(0).toInt, x(1), x(2).toInt))
//5.将personRDD转换成DataFrame
val personDF = personRDD.toDF
6.对personDF进行处理
#(SQL风格语法)
personDF.registerTempTable("t_person")
sqlContext.sql("select * from t_person order by age desc limit 2").show
sqlContext.sql("desc t_person").show
val result = sqlContext.sql("select * from t_person order by age desc")
7.保存结果
result.save("hdfs://hadoop.itcast.cn:9000/sql/res1")
result.save("hdfs://hadoop.itcast.cn:9000/sql/res2", "json")
#以JSON文件格式覆写HDFS上的JSON文件
import org.apache.spark.sql.SaveMode._
result.save("hdfs://hadoop.itcast.cn:9000/sql/res2", "json" , Overwrite)
8.重新加载以前的处理结果(可选)
sqlContext.load("hdfs://hadoop.itcast.cn:9000/sql/res1")
sqlContext.load("hdfs://hadoop.itcast.cn:9000/sql/res2", "json")
2、代码方式编写sparksql
package cn.itcast.spark.sql import org.apache.spark.{SparkConf, SparkContext} import org.apache.spark.sql.SQLContext object InferringSchema { def main(args: Array[String]) { //创建SparkConf()并设置App名称 val conf = new SparkConf().setAppName("SQL-1") //SQLContext要依赖SparkContext val sc = new SparkContext(conf) //创建SQLContext val sqlContext = new SQLContext(sc) //从指定的地址创建RDD //文件内容 1,zhangsan,10 //2,lisi,20 val lineRDD = sc.textFile(args(0)).map(_.split(" ")) //创建case class //将RDD和case class关联 val personRDD = lineRDD.map(x => Person(x(0).toInt, x(1), x(2).toInt)) //导入隐式转换,如果不导入无法将RDD转换成DataFrame //将RDD转换成DataFrame import sqlContext.implicits._ val personDF = personRDD.toDF //注册表 personDF.registerTempTable("t_person") //传入SQL val df = sqlContext.sql("select * from t_person order by age desc limit 2") //将结果以JSON的方式存储到指定位置 df.write.json(args(1)) //df.show() 显示结果 //停止Spark Context sc.stop() } } //case class一定要放到外面 case class Person(id: Int, name: String, age: Int)
3 从MySQL中加载数据(Spark Shell方式)
1.启动Spark Shell,必须指定mysql连接驱动jar包
/usr/local/spark-1.5.2-bin-hadoop2.6/bin/spark-shell \
--master spark://node1.itcast.cn:7077 \
--jars /usr/local/spark-1.5.2-bin-hadoop2.6/mysql-connector-java-5.1.35-bin.jar \
--driver-class-path /usr/local/spark-1.5.2-bin-hadoop2.6/mysql-connector-java-5.1.35-bin.jar
2.从mysql中加载数据
val jdbcDF = sqlContext.read.format("jdbc").options(Map("url" -> "jdbc:mysql://192.168.10.1:3306/bigdata", "driver" -> "com.mysql.jdbc.Driver", "dbtable" -> "person", "user" -> "root", "password" -> "123456")).load()
3.执行查询
jdbcDF.show()
4 将数据写入到MySQL中(打jar包方式)
package cn.itcast.spark.sql
import java.util.Properties
import org.apache.spark.sql.{SQLContext, Row}
import org.apache.spark.sql.types.{StringType, IntegerType, StructField, StructType}
import org.apache.spark.{SparkConf, SparkContext}
object JdbcRDD {
def main(args: Array[String]) {
val conf = new SparkConf().setAppName("MySQL-Demo")
val sc = new SparkContext(conf)
val sqlContext = new SQLContext(sc)
//通过并行化创建RDD val personRDD = sc.parallelize(Array("1 tom 5", "2 jerry 3", "3 kitty 6")).map(_.split(" "))
//通过StructType直接指定每个字段的schema val schema = StructType(
List(
StructField("id", IntegerType, true),
StructField("name", StringType, true),
StructField("age", IntegerType, true)
)
)
//将RDD映射到rowRDD val rowRDD = personRDD.map(p => Row(p(0).toInt, p(1).trim, p(2).toInt))
//将schema信息应用到rowRDD上 val personDataFrame = sqlContext.createDataFrame(rowRDD, schema)
//创建Properties存储数据库相关属性 val prop = new Properties()
prop.put("user", "root")
prop.put("password", "123456")
//将数据追加到数据库 personDataFrame.write.mode("append").jdbc("jdbc:mysql://192.168.10.1:3306/bigdata", "bigdata.person", prop)
//停止SparkContext sc.stop()
}
}
|
1.用maven将程序打包
2.将Jar包提交到spark集群
/usr/local/spark-1.5.2-bin-hadoop2.6/bin/spark-submit \
--class cn.itcast.spark.sql.JdbcRDD \
--master spark://node1.itcast.cn:7077 \
--jars /usr/local/spark-1.5.2-bin-hadoop2.6/mysql-connector-java-5.1.35-bin.jar \
--driver-class-path /usr/local/spark-1.5.2-bin-hadoop2.6/mysql-connector-java-5.1.35-bin.jar \
/root/spark-mvn-1.0-SNAPSHOT.jar
九、sparksql和hive结合
1、创建hive的元数据的表 修改hive表的编码
alter database hive character set latin1;
ALTER TABLE hive.* DEFAULT CHARACTER SET latin1;
2.安装hive
忽略
3.将配置好的hive-site.xml,hdfs-site.xml,core-site.xml 放入$SPARK-HOME/conf目录下
4.启动spark-shell时指定mysql连接驱动位置
bin/spark-shell \
--master spark://node11:7077 \
--executor-memory 1g \
--total-executor-cores 2 \
--driver-class-path /usr/local/apache-hive-0.13.1-bin/lib/mysql-connector-java-5.1.35-bin.jar
5.使用sqlContext.sql调用HQL
sqlContext.sql("select * from spark.person limit 2")
或使用org.apache.spark.sql.hive.HiveContext
import org.apache.spark.sql.hive.HiveContext
val hiveContext = new HiveContext(sc)
hiveContext.sql("select * from spark.person")
十、SparkStreaming
1、第一sparkStreaming wordcount 处理每一批次的数据 处理局部数据
object StreamingWordCount {
def main(args: Array[String]) {
val conf = new SparkConf().setAppName("StreamingWordCount").setMaster("local[2]")
val sc = new SparkContext(conf)
//每隔5秒 处理一次数据
val ssc = new StreamingContext(sc, Seconds(5))
//接收数据监听 172.16.0.11:8888 (数据来源)
val ds = ssc.socketTextStream("172.16.0.11", 8888)
//DStream是一个特殊的RDD
//hello tom hello jerry
val result = ds.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_+_)
//打印结果
result.print()
ssc.start()
ssc.awaitTermination()
}
}
2、sparkStreaming 处理全局变量 wordcount累加
object StateFulWordCount {
//String 某个单词
//Seq这个批次某个单词的次数
//Option[Int]:以前的结果
//分好组的数据
val updateFunc = (iter: Iterator[(String, Seq[Int], Option[Int])]) => {
//iter.flatMap(it=>Some(it._2.sum + it._3.getOrElse(0)).map(x=>(it._1,x)))
//iter.map{case(x,y,z)=>Some(y.sum + z.getOrElse(0)).map(m=>(x, m))}
//iter.map(t => (t._1, t._2.sum + t._3.getOrElse(0)))
iter.map{case(word, current_count, history_count) => (word, current_count.sum + history_count.getOrElse(0)) }
}
def main(args: Array[String]) {
val conf = new SparkConf().setAppName("StateFulWordCount").setMaster("local[2]")
val sc = new SparkContext(conf)
//updateStateByKey必须设置setCheckpointDir
sc.setCheckpointDir("c://ck")
val ssc = new StreamingContext(sc, Seconds(5))
val ds = ssc.socketTextStream("172.16.0.11", 8888)
//hello tom hello jerry
val result = ds.flatMap(_.split(" ")).map((_, 1)).updateStateByKey(updateFunc, new HashPartitioner(sc.defaultParallelism), true)
result.print()
ssc.start()
ssc.awaitTermination()
}
}
3、SparkStreaming 和flume结合 fluem版本要和SparkStreaming对应 这里都是采用1.6.1
(1)、flume向SparkStreaming push数据 这种方式用的不多 数据只能交给一台SparkStreaming处理
SparkStreaming代码
object FlumePushWordCount {
def main(args: Array[String]) {
val host = “192.168.1.105”
val port = 8888
val conf = new SparkConf().setAppName("FlumeWordCount").setMaster("local[2]")
val ssc = new StreamingContext(conf, Seconds(5))
//推送方式: flume向spark发送数据 flume配置文件中sink 配置的ip和端口
val flumeStream = FlumeUtils.createStream(ssc, host, port)
//flume中的数据通过event.getBody()才能拿到真正的内容
val words = flumeStream.flatMap(x => new String(x.event.getBody().array()).split(" ")).map((_, 1))
val results = words.reduceByKey(_ + _)
results.print()
ssc.start()
ssc.awaitTermination()
}
}
编写一个flume agent的配置文件 flume-push.conf 内容如下
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# source
a1.sources.r1.type = spooldir
#监控该目录下的文件
a1.sources.r1.spoolDir = /usr/local/java/log
a1.sources.r1.fileHeader = true
# sink
a1.sinks.k1.type = avro
#这是接收方 运行sparkStreaming 机器ip
a1.sinks.k1.hostname = 192.168.1.105
# 运行sparkStreaming 机器端口
a1.sinks.k1.port = 8888
# memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
先启动sparkstreaming再启动 flume
bin/flume-ng agent -n a1 -c conf -f conf/flume-push.conf
(2)、SparkStreaming 从flume中 pull数据 可以由多台SparkStreamming处理数据
把如下三个jar包放到 flume_home/lib下
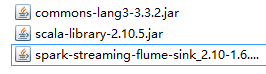
编写一个flume agent的配置文件 flume-poll.conf 内容如下
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# source
a1.sources.r1.type = spooldir
a1.sources.r1.spoolDir = /usr/local/java/log
a1.sources.r1.fileHeader = true
# Describe the sink 用SparkStreaming提供的 sink
a1.sinks.k1.type = org.apache.spark.streaming.flume.sink.SparkSink
#flume 的ip地址 sparkstreaming会从这个ip上的flume拉去数据
a1.sinks.k1.hostname = 192.168.52.138
a1.sinks.k1.port = 8888
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
启动flume
bin/flume-ng agent -n a1 -c conf -f conf/flume-poll.conf
sparkStreamming 代码
object StreamingFlumePull {
val func=(it:Iterator[(String, Seq[Int], Option[Int])]) => {
it.map(x=>(x._1,x._2.sum+x._3.getOrElse(0)))
}
def main(args: Array[String]): Unit = {
val conf=new SparkConf().setAppName("StreamingFlumePull").setMaster("local[2]");
val sc=new SparkContext(conf);
sc.setCheckpointDir("c://ck")
val ssc=new StreamingContext(sc,Seconds(5));
//可以有多台sparkStreaming来处理flume产生的数据 下面是flume的ip和端口
val address = Seq(new InetSocketAddress("192.168.52.138", 8888))
val flumeData=FlumeUtils.createPollingStream(ssc,address,StorageLevel.MEMORY_AND_DISK);
val words=flumeData.flatMap(x=>{
new String(x.event.getBody.array()).split(" ")
}).map((_,1))
val result=words.updateStateByKey(func,new HashPartitioner(sc.defaultParallelism),true)
result.print();
ssc.start();
ssc.awaitTermination();
}
}
4、sparkstreaming 和kafka结合 非直连方式 通过receviver方式从kafka 的broker中消费数据 此方式 会一直从broker中消费数据 会产生在这一段时间内拉取得数据量大于work的内存
(1)、启动kafka
/bin/kafka-server-start.sh /usr/local/java/kafka/config/server.properties &
(2)、创建topic
bin/kafka-topics.sh --create --zookeeper node22:2181,node33:2181,node44:2181 --replication-factor 1 --partitions 1 --topic sparkstreaming
(3)、生产数据
bin/kafka-console-producer.sh --broker-list node11:9092,node22:9092,node33:9092 --sync --topic sparkstreaming
(5)、sparkstreaming代码
object KafkaWordCount {
val updateFunc = (iter: Iterator[(String, Seq[Int], Option[Int])]) => {
//iter.flatMap(it=>Some(it._2.sum + it._3.getOrElse(0)).map(x=>(it._1,x)))
iter.flatMap { case (x, y, z) => Some(y.sum + z.getOrElse(0)).map(i => (x, i)) }
}
def main(args: Array[String]) {
//zookeeper地址
val zkQuorm="node22:2181,node33:2181,node44:2181";
//消费组
val groupId="sparkgroup";
//消费主题
val topics="sparkstreaming";
val sparkConf = new SparkConf().setAppName("KafkaWordCount").setMaster("local[2]")
val ssc = new StreamingContext(sparkConf, Seconds(5))
ssc.checkpoint("c://ck2")
//"alog-2016-04-16,alog-2016-04-17,alog-2016-04-18"
//"Array((alog-2016-04-16, 2), (alog-2016-04-17, 2), (alog-2016-04-18, 2))"
//numThreads 表示有几个线程来消费topic里的数据
val topicMap = topics.split(",").map((_, numThreads.toInt)).toMap
val data = KafkaUtils.createStream(ssc, zkQuorum, group, topicMap, StorageLevel.MEMORY_AND_DISK_SER)
//kafka过来的数据是key value的形式 只取value做处理(_._2)
val words = data.map(_._2).flatMap(_.split(" "))
val wordCounts = words.map((_, 1)).updateStateByKey(updateFunc, new HashPartitioner(ssc.sparkContext.defaultParallelism), true)
ssc.start()
ssc.awaitTermination()
}
}
十一、sparkstreaming窗口函数 用于计算某段时间的数据
object WindowOpts {
def main(args: Array[String]) {
val conf = new SparkConf().setAppName("WindowOpts").setMaster("local[2]")
val ssc = new StreamingContext(conf, Milliseconds(5000))
val lines = ssc.socketTextStream("172.16.0.11", 9999)
val pairs = lines.flatMap(_.split(" ")).map((_, 1))
//reduceByKeyAndWindow 方法中的三个参数
//(a:Int,b:Int) => (a + b) 对数据进行相加操作
//Seconds(15) 计算15秒内的数据 这个时间必须是 产生批次时间的整数倍 (上面的Milliseconds(5000))
//Seconds(10)) 每隔10秒计算一次
val windowedWordCounts = pairs.reduceByKeyAndWindow((a:Int,b:Int) => (a + b), Seconds(15), Seconds(10))
//Map((hello, 5), (jerry, 2), (kitty, 3))
windowedWordCounts.print()
// val a = windowedWordCounts.map(_._2).reduce(_+_)
// a.foreachRDD(rdd => {
// println(rdd.take(0))
// })
// a.print()
// //windowedWordCounts.map(t => (t._1, t._2.toDouble / a.toD))
// windowedWordCounts.print()
// //result.print()
ssc.start()
ssc.awaitTermination()
}