并发编程——并发容器
并发编程——并发容器
本文总结下Java中的并发容器。
Java中的容器主要分为四个大类:List、Map、Set、Queue。我们常用的ArrayList、HashMap并不是并发安全的,在JDK1.5之前,其实JDK有提供线程安全的容器——Collections类中的synchronized系列,synchronizedList、SynchronizedMap、SynchronizedSet,它们被称为同步容器。
它们的实现也非常的简单粗暴:
下面截取部分synchronizedList的源码:
public int hashCode() {
synchronized (mutex) {return list.hashCode();}
}
public E get(int index) {
synchronized (mutex) {return list.get(index);}
}
public E set(int index, E element) {
synchronized (mutex) {return list.set(index, element);}
}
public void add(int index, E element) {
synchronized (mutex) {list.add(index, element);}
}
public E remove(int index) {
synchronized (mutex) {return list.remove(index);}
}
直接在add、get、remove、set等方法上加synchronized关键字,保证每个方法的原子性。这个思路其实就是前面讲过的,将线程安全的容器封装在对象内部,然后控制好访问方法。这里也要注意个坑,每个方法都是原子性并不保证一组操作都是原子性,同步容器有个很明显的坑就是迭代操作:
List list = Collections.synchronizedList(new ArrayList());
Iterator i = list.iterator();
while (i.hasNext())
foo(i.next());
但是同步容器类有很显著的缺点——所有的方法都用synchronized来保证原子性,串行度太高,性能太差了。因此JDK1.5以后的版本提供了性能更高的并发容器,也就是今天要看到重点。
并发容器大概可以分为这几种:
List
list的并发安全类只有一个——CopyOnWriteArrayList,从名字就可以看出来,这个类保证并发安全的手段就是通过我们之前讲的CopyOnWrite,写时复制。读的时候完全无锁,写的时候将list复制一份出来,在copy的副本上修改,修改完之后再替换掉原来的list。
我们先看下它的类图大概了解下它有什么能力:
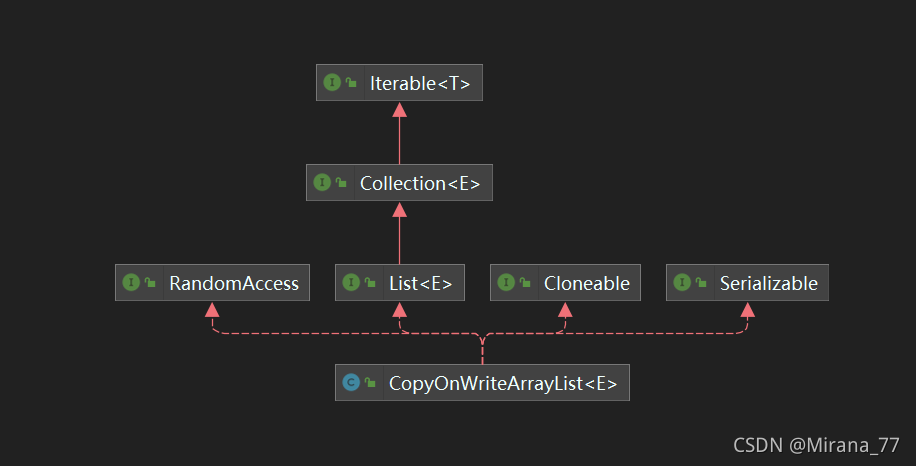
源码解析
成员变量
final transient ReentrantLock lock = new ReentrantLock();
private transient volatile Object[] array;
CopyOnWriteArrayList内部维护了个可重入锁与临时的数组array。这里为什么说是临时呢,首先因为修饰它的关键字transient,表明这个属性在序列化的时候就会被忽略;而且CopyOnWriteArrayList的list只要被改变,array就会被改变,不如说它是快照更恰当一点。
主要方法
这里只看了开发中常用到的:构造参数为数组的构造方法、set、和iterator方法
public CopyOnWriteArrayList(E[] toCopyIn) {
setArray(Arrays.copyOf(toCopyIn, toCopyIn.length, Object[].class));
}
public E set(int index, E element) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] elements = getArray();
E oldValue = get(elements, index);
if (oldValue != element) {
int len = elements.length;
Object[] newElements = Arrays.copyOf(elements, len);
newElements[index] = element;
setArray(newElements);
} else {
// Not quite a no-op; ensures volatile write semantics
setArray(elements);
}
return oldValue;
} finally {
lock.unlock();
}
}
public Iterator<E> iterator() {
return new COWIterator<E>(getArray(), 0);
}
从这三个方法我们可以看出:
CopyOnWriteArrayList在set的时候会先获取锁;然后判断list位置index的元素是否是element,如果不是就会去赋值一个新的数组,然后把值塞进去再做替换
iterator每次迭代的时候,都会对当前的arry创建一个快照
那我们再看下迭代器COWIterator的结构:
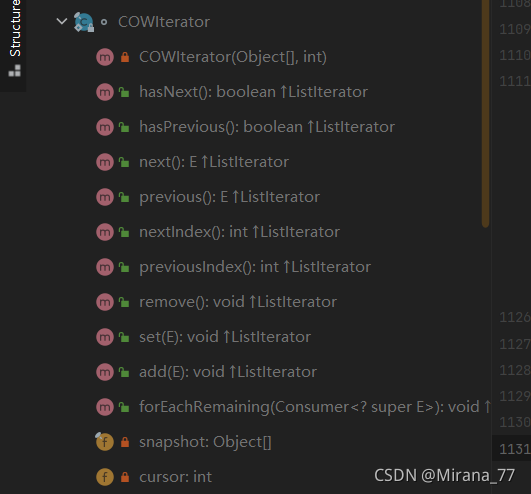
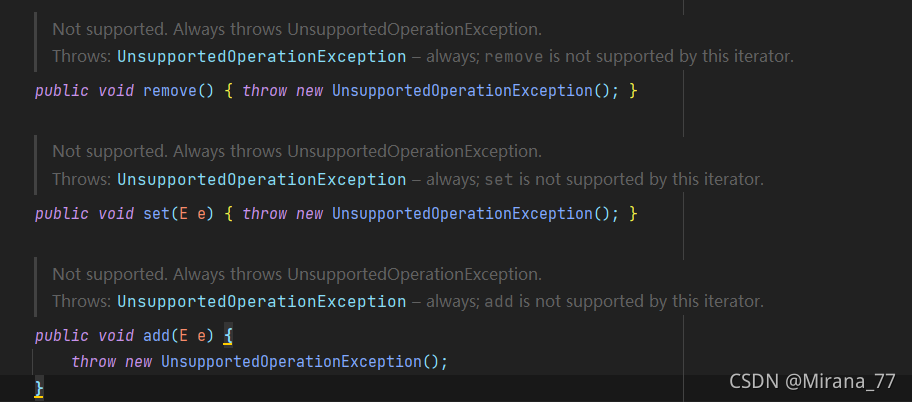
可以看到,它是只读的,进行增删改操作都会抛出UnsupportedOperationException异常
总结
- CopyOnWriteArrayList确实可以保证线程安全,但是它并不适合频繁修改的场景;只适合写操作非常少,并且每次写都会复制当前的list,浪费内存;
- 使用iterator迭代器进行迭代时,迭代的list是获取迭代器那一刻的副本,所以需要允许短暂的不一致;
- CopyOnWriteArrayList的迭代器是只读的,增删改都会抛出UnsupportedOperationException异常,其实也很好理解。因为迭代器遍历的仅仅是一个快照,对它增删改也没有意义,如果强行增删改还要想办法保证数据一致性,不如干脆不能增删改;
Map
JDK中提供的并发安全Map类有两个:ConcurrentHashMap与ConcurrentSkipListMap。
我们看下类图:
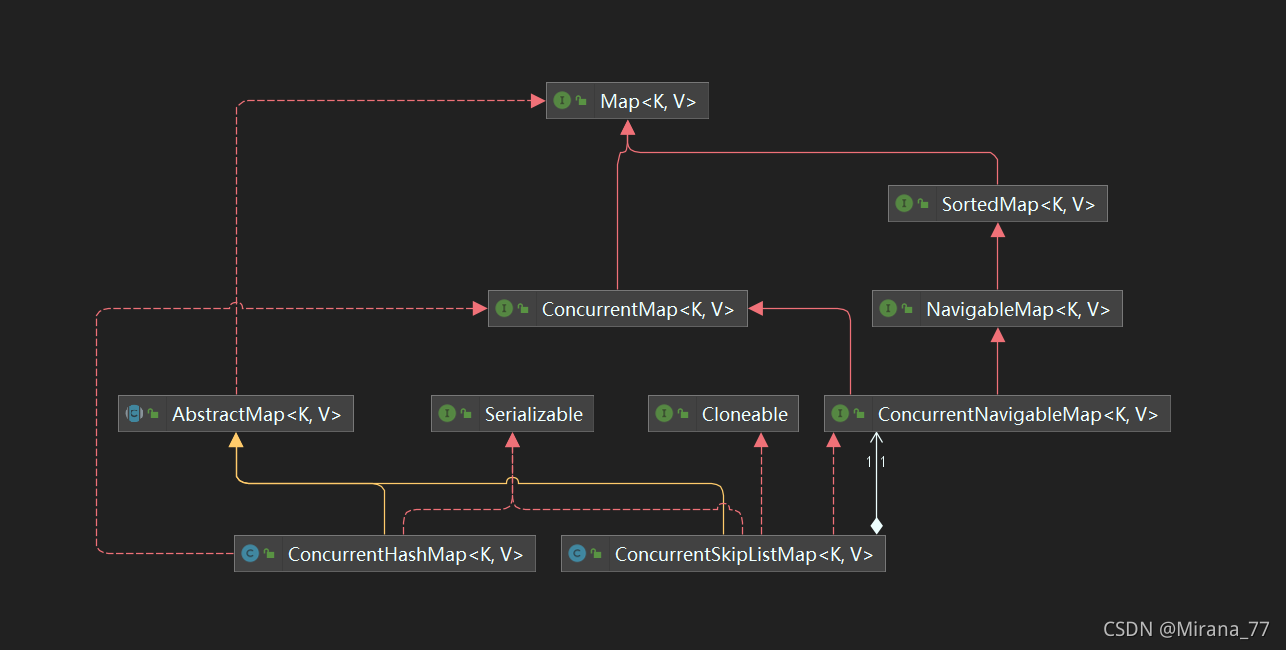
从它们的UML图就知道它们两个的区别:
ConcurrentSkipListMap实现了ConcurrentNavigableMap,它的key是有序的
ConcurrentHashMap
ConcurrentHashMap在1.7跟1.8的实现上有很大的不同,总结一下大概是:
| 1.7 | 1.8 | |
|---|---|---|
| 每个节点的数据结构 | Segment(固定16个Segment,不可扩容) | Node(无限制,可扩容) |
| 哈希冲突 | 链表 | 阈值小于8是链表,大于8转为红黑树 |
| 保证并发安全 | 分段锁,Segment又继承自ReentrantLock | CAS+synchronized |
| 查询时间复杂度 | O(n) | O(n),如果已经转为红黑树则是O(logn) |
1.8源码分析
这里主要看下比较重要的put和get方法(因put方法实际上内部调用了putVal,所以只看putVal):
final V putVal(K key, V value, boolean onlyIfAbsent) {
//如果key为空或者value为空,就抛出空指针异常
if (key == null || value == null) throw new NullPointerException();
//计算自己的哈希值
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
//如果table还没有初始化就对它进行初始化工作
if (tab == null || (n = tab.length) == 0)
tab = initTable();
//如果这个哈希节点是空的直接cas插入
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
//如果这个哈希节点正在扩容,就帮助进行扩容
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else {
V oldVal = null;
synchronized (f) {
//这块是链表的操作
if (tabAt(tab, i) == f) {
if (fh >= 0) {
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
//如果当前节点有值,查看onlyIfAbsent,如果是false就把新的值替换旧的值返回
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
//如果不存在就直接new个新的节点,插入到链表最后面
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
//如果是红黑树
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
//判断是否需要把链表转成树
if (binCount != 0) {
//TREEIFY_THRESHOLD就是阈值8
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
addCount(1L, binCount);
return null;
}
public V get(Object key) {
Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek;
int h = spread(key.hashCode());
//如果table或者tab为空就直接返回null
if ((tab = table) != null && (n = tab.length) > 0 &&
(e = tabAt(tab, (n - 1) & h)) != null) {
//如果第一个节点的哈希值符合,就直接把第一个节点的值返回
if ((eh = e.hash) == h) {
if ((ek = e.key) == key || (ek != null && key.equals(ek)))
return e.val;
}
//如果eh<0说明是红黑树或者是转移节点,就用find方法去找对应到value
else if (eh < 0)
return (p = e.find(h, key)) != null ? p.val : null;
//如果第一个节点不是要找的节点也不是红黑树,说明是个链表,就用while循环遍历去寻找
while ((e = e.next) != null) {
if (e.hash == h &&
((ek = e.key) == key || (ek != null && key.equals(ek))))
return e.val;
}
}
return null;
}
FAQ
Q:为什么ConcurrentHashMapz在1.8中,当哈希冲突阈值超过8会转为红黑树?
A:当哈希冲突小于8时,使用链表就算时间复杂度是O(n),也是可以接受的并且链表所占的内存空间较小,红黑树虽然查找时间复杂度是O(logn),但是它占用的内存也是链表的两倍,所以需要在链表与红黑树之间找到一个平衡点,而8就是这个平衡点:8这个阈值其实是作者经过泊松分布计算,为8的概率已经很小了,基本上微乎其微,为了保证在这种情况下也能有较高的查询效率,所以就让它在>8的时候转为红黑树
ConcurrentSkipListMap
在Redis支持的数据类型的底层实现数据结构中,我们知道Redis的Set的底层实现方式之一就是SkipList。
跳表是种有序的数据结构,它的设计思想就是在纵向上二分查找,所以我们就知道虽然它的查找时间复杂度是O(logn),但是这种数据结构需要额外的空间存储。
Set
Set接口的并发安全实现类是CopyOnWriteArraySet和ConcurrentSkipListSet,跟Map差不多就不再多说了。
Queue
队列是种先进先出(FIFO )的数据结构,它可以从两个维度去分类:
阻塞非阻塞:阻塞指的是当队列已满,入队操作阻塞;当队列已空,出队操作阻塞
单端双端:单端指的是只能队尾入队队首出队;双端则是队尾队首都可以入队出队
Java并发包中,阻塞队列使用Blocking标识,单端队列使用Queue标识,双端队列使用Deque标识。
如果按照有界无界来分的话,只有 ArrayBlockingQueue 和 LinkedBlockingQueue 是支持有界的。
那么两两组合,队列可以分为:
单端阻塞队列
ArrayBlockingQueue、LinkedBlockingQueue、SynchronousQueue、LinkedTransferQueue、PriorityBlockingQueue 和 DelayQueue都是单端阻塞队列的实现。内部一般会持有一个队列,这个队列可以是数组(其实现是 ArrayBlockingQueue)也可以是链表(其实现是 LinkedBlockingQueue);甚至还可以不持有队列(其实现是 SynchronousQueue),此时生产者线程的入队操作必须等待消费者线程的出队操作。而 LinkedTransferQueue 融合 LinkedBlockingQueue 和 SynchronousQueue 的功能,性能比 LinkedBlockingQueue 更好;PriorityBlockingQueue 支持按照优先级出队;DelayQueue 支持延时出队。
我们来看下比较有代表性的LinkedBlockingQueue的源码实现(其实我们在前面自己也用ReentrantLock+Condition实现了一个阻塞队列,原理基本上都差不多)
LinkedBlockingQueue的源码分析
成员变量
private final int capacity; //链表容量
private final AtomicInteger count = new AtomicInteger(); //链表元素数量
private final ReentrantLock takeLock = new ReentrantLock(); //入队的可重入锁
private final Condition notEmpty = takeLock.newCondition(); //队列不为空的条件
private final ReentrantLock putLock = new ReentrantLock(); //出队的的可重入锁
private final Condition notFull = putLock.newCondition(); //队列不满的条件
//linkedBlockingQueue的队列是链表实现的,这里为做展示
主要方法
void put(E e) throws InterruptedException //入队,如果队列满就等待被唤醒
boolean offer(E e) //入队,如果队列满就返回false
boolean add(E e) //入队,如果队列满就抛出IllegalStateException异常
E poll(long timeout, TimeUnit unit) throws InterruptedException //出队,如果队列空就返回null
E take() throws InterruptedException //出队,如果队列空就等待被唤醒
LinkedBlockingQueue与ArrayBlockingQueue的实现有个有意思的东西,ArrayBlockingQueue只有一把ReentrantLock,而LinkedBlockingQueue则是有入队和出队两把ReentrantLock。
为什么这么设计呢,个人查找了下网上的相关问答:
https://stackoverflow.com/questions/11015571/arrayblockingqueue-uses-a-single-lock-for-insertion-and-removal-but-linkedblocki
个人是更倾向于这个答案的:
ArrayBlockingQueue has to avoid overwriting entries so that it needs to know where the start and the end is. A LinkedBlockQueue doesn’t need to know this as it lets the GC worry about cleaning up Nodes in the queue.
ArrayBlockingQueue内部的队列是数组实现的,并且是个循环的,在入队出队的方法中都能看到这段:
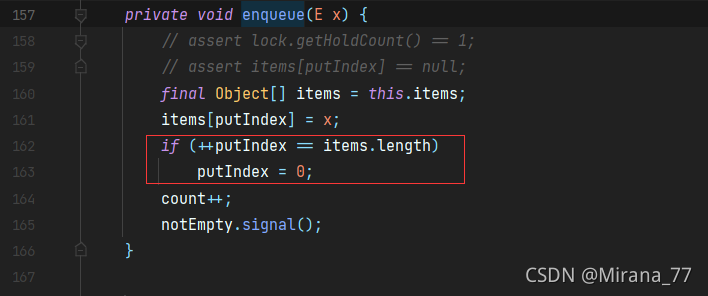
也就是说,如果它的入队出队是两把锁的话,那么就要做更多的操作维护队列的起点跟终点,防止队首的数组下标恰巧就是队尾的数组下标——个人理解
但是不管原因是什么,我们都知道一件事,那就是LinkedBlockingQueue的读写上是不同的锁,队列的性能也就更好。
双端阻塞队列
LinkedBlockingDeque
单端非阻塞队列
ConcurrentLinkedQueue
双端非阻塞队列
ConcurrentLinkedDeque
队列小结
队列是种先进先出(FIFO )的数据结构。
队列可以按照阻塞非阻塞、单端双端划分为四个维度:单端阻塞队列、双端阻塞队列、单端非阻塞队列、双端非阻塞队列。
在队列的使用中,有界无界也是个重要的衡量指标,LinkedBlockingQueue与ArrayBlockingQueue都是有界的阻塞队列。