matlab中k-means算法_OpenCV图像处理-KMeans 图像处理
KMeans 数据分类
概述
- KMeans算法的作者是MacQueen, KMeans的算法是对数据进行分类的算法,采用的硬分类方式,是属于非监督学习的算法;
- 对于给定的样本集,按照样本之间的距离大小,将样本划分为K个簇,让簇内的点尽量紧密的连接在一起,而让簇间的距离尽量的大。
KMeans算法
输入:训练数据集
过程:函数
1:从 D 中随机选择 k 个样本作为初始“簇中心”向量:
2:repeat
3: 令
4: for
5: 计算样本
6: 根据距离最近的“簇中心”向量确定
7: 将样本
8: end for
9: for
10: 计算新“簇中心”向量:
11: if
12: 将当前“簇中心”向量
13: else
14: 保持当前均值向量不变
15: end if
16: end for
17: else
18:until 当前“簇中心”向量均未更新
输出:簇划分
备注:
kmeans算法由于初始“簇中心”点是随机选取的,因此最终求得的簇的划分与随机选取的“簇中心”有关,也就是说,可能会造成多种 k 个簇的划分情况。
这是因为kmeans算法收敛到了局部最小值,而非全局最小值。
二分KMeans
- 基于kmeans算法容易使得结果为局部最小值而非全局最小值这一缺陷,对算法加以改进。
- 使用一种用于度量聚类效果的指标SSE(Sum of Squared Error),即对于第 i 个簇,其SSE为各个样本点到“簇中心”点的距离的平方的和,SSE值越小表示数据点越接近于它们的“簇中心”点,聚类效果也就越好,以此作为划分簇的标准。
算法思想: 先将整个样本集作为一个簇,该“簇中心”点向量为所有样本点的均值,计算此时的SSE。若此时簇个数小于 k ,对每一个簇进行kmeans聚类(k=2) ,计算将每一个簇一分为二后的总误差SSE,选择SSE最小的那个簇进行划分操作。
输入: 训练数据集
k ;
过程: 函数
1: 将所有点看做一个簇,计算此时“簇中心”向量:
2:while
3: for
4: 将第
5: 计算划分后的误差平方和
6: 比较
7: 更新簇的分配结果
8: 添加新的“簇中心”
9:until 当前“簇中心”个数达到
输出: 簇划分
Opnecv 函数
OpenCV中KMeans数据分类的API为:
cv2.kmeans(
InputArray data,
int K,
InputOutputArray bestLabels,
TermCriteria criteria,
int attempts,
int flags,
OutputArray centers = noArray()
)输入:
- data表示输入的样本数据,必须是按行组织样本,每一行为一个样本数据,列表示样本的维度;
- K表示最终的分类数目;
- bestLabels 表示最终分类每个样本的标签;
- criteria 表示KMeans分割的停止条件;
- attempts 表示采样不同初始化标签尝试次数;
- flag表示中心初始化方法:
- KMEANS_RANDOM_CENTERS
- KMEANS_PP_CENTERS
- KMEANS_USE_INITIAL_LABELS
- centers表示最终分割以后的每个cluster的中心位置。
代码示例
import numpy as np
import cv2
from matplotlib import pyplot as plt
# 读取数据
def loadDataSet(fileName):
data = []
with open(fileName) as f:
for line in f.readlines():
curLine = line.strip().split("t")
fltLine = list(map(float, curLine)) # 转换为float
data.append(fltLine)
return np.array(data, dtype=np.float32)
# 导入数据
data = loadDataSet('testSet2.txt')
# 定义停止条件
criteria = (cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER, 10, 1.0)
# kmeans计算
ret,label,center=cv2.kmeans(data, 3, None, criteria, 2, cv2.KMEANS_RANDOM_CENTERS)
print(len(label))
print(center)
# 获取不同标签的点
A = data[label.ravel()==0]
B = data[label.ravel()==1]
C = data[label.ravel()==2]
# 可视化
plt.scatter(A[:,0],A[:,1])
plt.scatter(B[:,0],B[:,1],c = 'r')
plt.scatter(C[:,0],C[:,1],c = 'purple')
plt.scatter(center[:,0],center[:,1],s = 80,c = 'black', marker = '*')
plt.xlabel('Height'),plt.ylabel('Weight')
plt.show()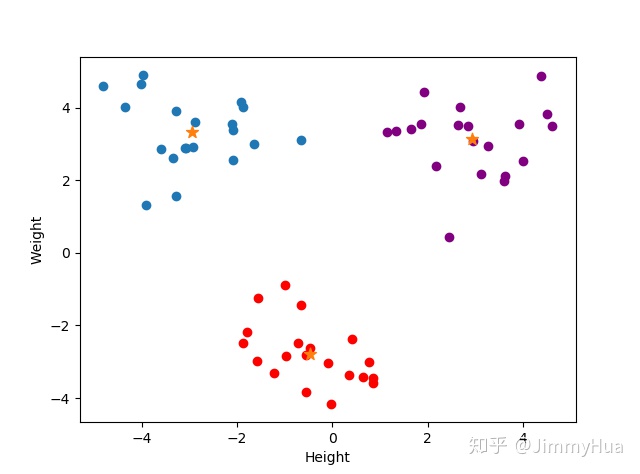
Kmeans图像分割
✔️ 在一张图片中,每一个像素点对应位置坐标和色彩坐标,用k-means算法对图像聚类不是聚类位置信息,而是对其色彩进行聚类。
✔️ kmeans能够实现简单的分割,当然效果不是非常好,需要经过一些后处理调整,才能得到高精度的分割图。
颜色空间分割
这里我们选取一个半身像,针对图片的颜色进行kmeans分割。
import numpy as np
import cv2 as cv
image = cv.imread('people.jpg')
# 构建图像数据
data = image.reshape((-1,3))
data = np.float32(data)
# MAX_ITER最大迭代次数,EPS最高精度
criteria = (cv.TERM_CRITERIA_EPS + cv.TERM_CRITERIA_MAX_ITER, 10, 1.0)
num_clusters = 4
ret,label,center=cv.kmeans(data, num_clusters, None, criteria, num_clusters, cv.KMEANS_RANDOM_CENTERS)
center = np.uint8(center)
# 颜色label
color = np.uint8([[255, 0, 0],
[0, 0, 255],
[128, 128, 128],
[0, 255, 0]])
res = color[label.flatten()]
print(res.shape)
# 显示
result = res.reshape((image.shape))
cv.imshow('kmeans-image-demo',result)
cv.waitKey(0)
cv.destroyAllWindows()
背景替换
✔️ KMeans可以实现简单的证件照片的背景分割提取与替换,大致可以分为如下几步实现:
- 读入图像建立KMenas样本;
- 使用KMeans图像分割,指定指定分类数目;
- 取左上角的label得到背景cluster index;
- 生成alpha图,然后选取新背景进行合成。
import numpy as np
import cv2 as cv
image = cv.imread('people.jpg')
cv.imshow("input", image)
h, w ,ch = image.shape
# 构建图像数据
data = image.reshape((-1,3))
data = np.float32(data)
# 图像分割
criteria = (cv.TERM_CRITERIA_EPS + cv.TERM_CRITERIA_MAX_ITER, 10, 1.0)
num_clusters = 4
ret,label,center=cv.kmeans(data, num_clusters, None, criteria, num_clusters, cv.KMEANS_RANDOM_CENTERS)
# 生成mask区域
index = label[0][0]
center = np.uint8(center)
color = center[0]
mask = np.ones((h, w), dtype=np.uint8)*255.
label = np.reshape(label, (h, w))
# alpha图
mask[label == index] = 0
# 高斯模糊
se = cv.getStructuringElement(cv.MORPH_RECT, (3, 3))
# 膨胀,防止背景出现
cv.erode(mask, se, mask)
#边缘模糊
mask = cv.GaussianBlur(mask, (5, 5), 0)
cv.imshow('alpha-image',mask)
# 白色背景
bg = np.ones(image.shape, dtype=np.float)*255.
# 粉丝背景
purle = np.array([255, 0, 255])
bg_color = np.tile(purle, (image.shape[0], image.shape[1], 1))
alpha = mask.astype(np.float32) / 255.
fg = alpha[..., None] * image
new_image = fg + (1 - alpha[..., None])*bg
new_image_purle = fg + (1 - alpha[..., None])*bg_color
cv.imwrite("white.jpg", np.hstack((image, new_image.astype(np.uint8))))
cv.imwrite("purle.jpg", np.hstack((image, new_image_purle.astype(np.uint8))))
cv.waitKey(0)
cv.destroyAllWindows()

主色彩提取
✔️ KMeans分割会计算出每个聚类的像素平均值,根据这个可以得到图像的主色彩RGB分布成分多少,得到各种色彩在图像中的比重,绘制出图像对应的取色卡!
这个方面在纺织与填色方面特别有用!主要步骤显示如下:
- 读入图像建立KMenas样本
- 使用KMeans图像分割,指定分类数目
- 统计各个聚类占总像素比率,根据比率建立色卡!
import numpy as np
import cv2 as cv
image = cv.imread('yuner.jpg')
cv.imshow("input", image)
h, w ,ch = image.shape
# 构建图像数据
data = image.reshape((-1,3))
data = np.float32(data)
# 图像分割
criteria = (cv.TERM_CRITERIA_EPS + cv.TERM_CRITERIA_MAX_ITER, 10, 1.0)
num_clusters = 5
ret,label,center=cv.kmeans(data, num_clusters, None, criteria, num_clusters, cv.KMEANS_RANDOM_CENTERS)
print(label[300])
# 生成主色彩条形卡片
card = np.zeros((50, w, 3), dtype=np.uint8)
clusters = np.zeros([5], dtype=np.int32)
# 统计每一类的数目
for i in range(len(label)):
clusters[label[i]] += 1
# 比重
clusters = np.float32(clusters) / float(h*w)
center = np.int32(center)
x_offset = 0
# 绘制色卡
for c in range(num_clusters):
dx = np.int(clusters[c] * w)
b = center[c][0]
g = center[c][1]
r = center[c][2]
cv.rectangle(card, (x_offset, 0), (x_offset+dx, 50), (int(b), int(g), int(r)), -1)
x_offset += dx
cv.imshow("color table", card)
cv.waitKey(0)
cv.destroyAllWindows()

------------------------------------------可爱の分割线------------------------------------------
更多Opencv教程可以 Follow github的opencv教程,中文&English 欢迎Star❤️❤️❤️
JimmyHHua/opencv_tutorialsgithub.com
参考
- kmeans算法理解及代码实现