从0到1的混沌之旅

下面,我将开始分享自己在这个旅程中的学到一切,从应用程序、云到平台Keiko on K8s。
这是一场从0到1的混沌之旅,未来还有很多东西需要学习和实现。
初识混沌
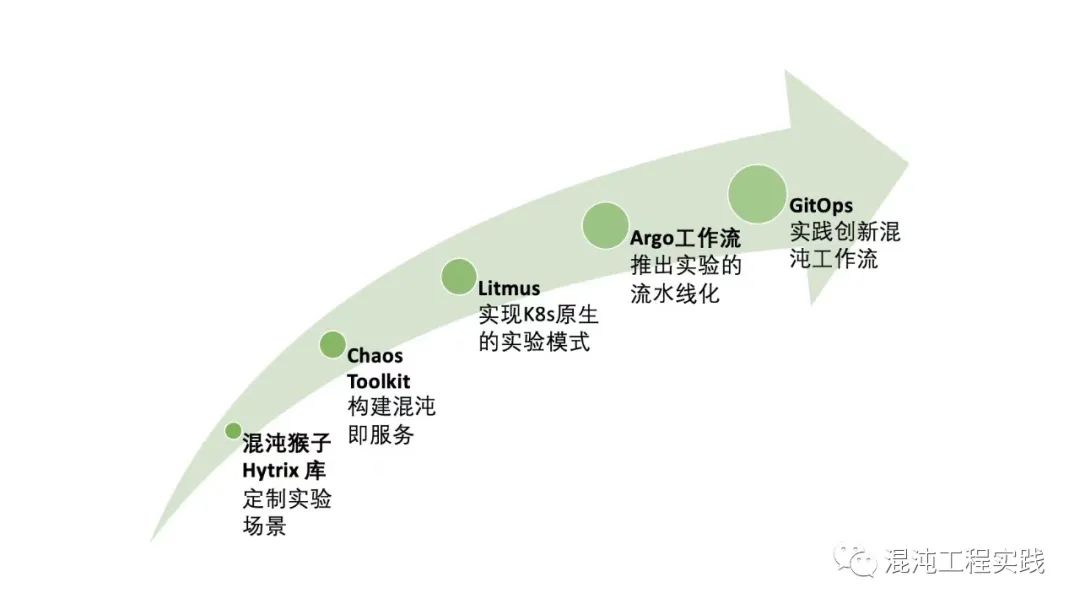
五年前,我们曾经在 AWS 上运行 Netflix 的混沌猴子和猿猴军团的解决方案。主要重点是提升应用程序的韧性并实践Hystrix。
Hystrix是Netflix开源的容错库,旨在隔离对远程系统、服务和第三库的访问,停止级联故障并在故障不可避免的复杂分布式系统中启用韧性。
后来,我们开发了更多的工具来模拟新的故障场景。逐渐地,我们发现,采用一种单一的解决方案满足不了实际应用的韧性需求。

同时,我们在混沌实验上做了很多POC,并尝试了各种开源和商业工具。我们发现使用市面上的商业解决方案都无法满足我们的需求。
我们一直在寻找一个强大的解决方案,利用其核心功能,并根据我们的需求并定制新的场景和功能行为。
混沌聚会和GameDay
因此,我们举办了一场混沌聚会。

本次聚会,我们收获了Chaos Toolkit这个工具,它是一个开源解决方案,并且支持高度可定制。
Chaos Toolkit遵循混沌工程原理,最初的 POC 发现它很有用,高度可定制的方式满足我们的需求。随后我们便开始与团队进行小规模合作,以采用此解决方案。
在这个阶段,我们在Kafka可靠性方面实践了一次GameDay。

其中,流量由Gatling生成,Chaos Toolkit混沌框架结合多个插件和扩展,实现混沌实验的能力。
混沌框架和定制
当我们开始研究支持插件和扩展的Chaos Toolkit框架时,发现我们仍需要自定义不少的插件和扩展的编写。
实际中,我们在框架更新和新插件支持方面投入资源,使用了7-8个插件,添加了4-5个新插件,主要是为了增强 K8s 和 AWS 插件以满足需求。

随着PoC的深入,我们开始关注更多的用户需求。
混沌转折点
第一个转折点是在2018年的公司创新日,我们提出了混沌工程的实践,并获得了第二名。
第二个转折点出现在2019年,Intuit 正在构建下一代 K8s 平台;K8s 集群上开始引入大量的产品团队。
在这个时候,我们遇到了生产事件,由于这是一个核心平台,可靠性的呼声到了顶点。
我们在作战室,花了将近 2 周的时间,构建了所有可能的用例,并验证了我们的平台Keiko on K8s
同时,我们向更多的团队分享了混沌方案的想法和经验。
混沌开始在整个公司中,变得越来越重要。
混沌即服务
在作战室期间,我们提出了一个新的问题:
验证 K8s 的混沌用例时,如何将这些混沌用例自动化,成为验证平台的执行组件?
为此,我们提出了混沌即服务。
我们做了一个POC,并构建了一个基于Python的部署服务,它在容器中运行这个混沌框架Chaos Toolkit,以及应用程序。

这个混沌即服务与 Rest API 交互,并使用集群角色来执行混沌操作。
后来,我们又创建了一个基于 nodejs 的 UI,以便团队可以快速体验,吃自己的狗粮,同时也推动产品团队试用并验证。
不少团队在他们的预生产环境中试用了这个解决方案,效果不错,一直在使用。
K8s和云上的混沌
实践证明,混沌即服务运行良好。
产品经理的新需求来了,由于跨集群的产品方案,希望借助混沌获得其应用和服务的可靠性。
接下来,与安全团队一起审查了混沌即服务的方案,发现了合规性和部署方面的挑战。
通过服务设置访问权限存在安全性和合规性问题
如何在 100 个集群中实现跨集群的混沌即服务
于是我们开始在 K8s 空间寻找新的解决方案。
最初,我们为 AWS 和 K8s 构建了两个解决方案,但问题又来了
如何移植我们当前已有的混沌框架和混沌用例?
最终,我们选择再次探索开源的混沌实践Litmus,并做了很多 POC。

K8s 混沌架构
经过了技术和用例的可行性分析,我们决定使用Litmus,这个具有插件架构、社区支撑和 K8s 原生支持的混沌工具。
更重要的是,Litmus是开源的,现在已经成为 CNCF 的一个沙箱项目。
我们的第一个 POC 是希望移植我们当前的工作,50 多个混沌用例,期望尽量减少工作量。
所以,我们仔细研究了Litmus的插件结构和CRD混沌模式,以及学会了如何创建自定义资源。
针对集群进行混沌实验

针对应用进行混沌实验

几周后,我们使用Litmus运行了第一个 K8s 的混沌用例。
之后的每一个月,我们都会在Litmus社区中展示并分享我们的进展。
使用 CRD 混沌模式
当我们开始研究Litmus时,希望混沌用例以 K8s 原生的方式执行,因此必须构建一个容器原生方案,利用自定义资源和CRD,将我们的混沌代码以容器的方式运行。

这需要我们将原来的混沌即服务层次重新编排,使用litmus runner和operator来执行这个容器。
在这次整合过程中,我们发现了许多挑战,在社区的帮助下,这些挑战得到了解决。
自定义注释、覆盖自定义资源权限、为 AWS 传递 IAM 角色,是我们为Litmus所做的一些贡献,以支持我们的自定义用例。
现在有了这些更改,我们可以执行 K8s 实验以及 AWS 实验。
混沌用例的角色和分类
我们将用户角色分为集群管理员和服务所有者。
集群管理员对集群级的混沌实验拥有更多权限
服务所有者仅对其命名空间拥有有限的权限
这些角色会在平台Keiko on K8s、应用程序和云上执行混沌实验,根据平台健康状况和服务正常运行时间来运行 K8s、应用程序和云基础的混沌。
我们有三类用例来满足应用程序、平台Keiko on K8s和云(AWS)的需求,再根据可行性和执行频率划分了不同优先级的测试用例。
混沌工作流
我们正在使用Argo工作流来执行测试基础架构。
我们内部构建了基于Argo工作流的混沌实验,并在Argo社区上进行了分享。

这个方案帮助我们,自动化了混沌实验,并提供了一种基础设施即代码的方法。
我们扩展并添加其作为混沌工作流程的一部分,也为开源做了一点贡献。

上图就是我们如何使用声明式流水线并通过Jenkins执行的展示。
混沌与性能工程
我们非常重视服务交互过程中的失败因素,因为这是引起服务中断的重要原因。
当我们开始做混沌实验时,大部分混沌实验都是有状态的,以此验证服务的正常运行时间和可用性。
当 Pod 或应用程序关闭时,没有无状态的方法可以继续检查服务的正常运行时间。
虽然使用HPA(水平Pod自动缩放器),但我们期望在Pod停机期间,验证服务的正常运行时间。
因此,我们在混沌工程中引入了性能测试。

我们利用现有的性能测试方案,使用Argo工作流将其置入在混沌工作流中。
现在我们可以在性能测试基础上运行混沌实验。

该方案基于开源构建,并在Argo工作流社区进行过分享。
混沌报告
如果不能衡量混沌实验的结果,我们就不会看到持续的进步和改进。
当然,每个团队/公司都有自己的报告方式。Chaos Toolkit会给我们一个报告,Litmus也会给出混沌实验的结果,尽管都很有用,但我们有特定的报告要求。
我们从第一天起,就在框架中构建了报告要求;并将所有数据推送到基于Kafka的数据湖。
最新地,我们将所有混沌结果移至集中式数据湖,并通过Kibana构建自定义仪表板,提供有关混沌执行的信息。
混沌与GitOps
基于GitOps的混沌实验是我们最新的实践方向。
我们正在使用ArgoCD遵循GitOps进行应用程序部署。

推荐阅读
《混沌工程:复杂系统韧性实现之道》

[美]Casey Rosenthal,Nora Jones 著
混沌工程开创者撰写,通过谷歌、微软等行业专家的真实故事,
系统阐释混沌工程的核心实践,提供实践建议
推荐理由:随着越来越多的公司转向构建微服务及其他形式的分布式系统,这些系统的复杂性也与日俱增。虽然无法消除复杂性,但通过实践混沌工程,可以发现系统中的漏洞,并防患于未然。本书向工程师展示了如何在优化系统满足业务目标的同时应对复杂的系统。


扫码关注【华章计算机】视频号
每天来听华章哥讲书

更多精彩回顾
书讯 | 9月书讯 | 秋天的第一本书,来了
资讯 | DB-Engines 9月数据库排名:SnowFlake坐上了火箭
书单 | 送你一份入门前端学习路线图
干货 | 人工智能、机器学习领域13个常见概念
收藏 | 这40个Python可视化图表案例,强烈建议收藏!
上新 | 【新书速递】Julia设计模式
赠书 | 【第73期】全面拥抱 Go 语言!
