分布式链路追踪技术
1、分布式链路追踪技术适用场景(问题场景)
场景描述
为了支撑日益增长的庞大业务量,我们会使用微服务架构设计我们的系统,使得我们的系统不仅能够通过集群部署抵挡流量的冲击,有能根据业务进行灵活的扩展。那么,在微服务架构下,一次请求少则经过三四次服务调用完成,多则跨越几十个甚至是上百个服务节点。那么问题接踵而来:
- 如何动态展示服务的调用链路?(比如A服务调用了哪些其他的服务---依赖关系)
- 如何分析服务调用链路中的瓶颈节点并对其进行调优?(比如A—>B—>C,C服务处理时间特别长)
- 如何快速进行服务链路的故障发现?
这就是分布式链路追踪技术存在的目的和意义
分布式链路追踪技术
如果我们在一个请求的调用处理过程中,在各个链路节点都能够记录下日志,并最终将日志进行集中可视化展示,那么我们想监控调用链路中的一些指标就有希望了~~~比如,请求到达哪个服务实例?请求被处理的状态怎样?处理耗时怎样?这些都能够分析出来了...
分布式环境下基于这种想法实现的监控技术就是就是分布式链路追踪(全链路追踪)。
市场上的分布式链路追踪方案
分布式链路追踪技术已然成熟,产品也不少,国内外都有,比如:
- Spring Cloud Sleuth + Twitter Zipkin
- 阿里巴巴的“鹰眼”
- 大众点评的“CAT”
- 美团的“Mtrace”
- 京东的“Hydra”
- 新浪的“Watchman”
- 另外还有最近也被提到很多的Apache Skywalking。
2、分布式链路追踪技术核心思想
本质:记录日志,作为一个完整的技术,分布式链路追踪也有自己的理论和概念
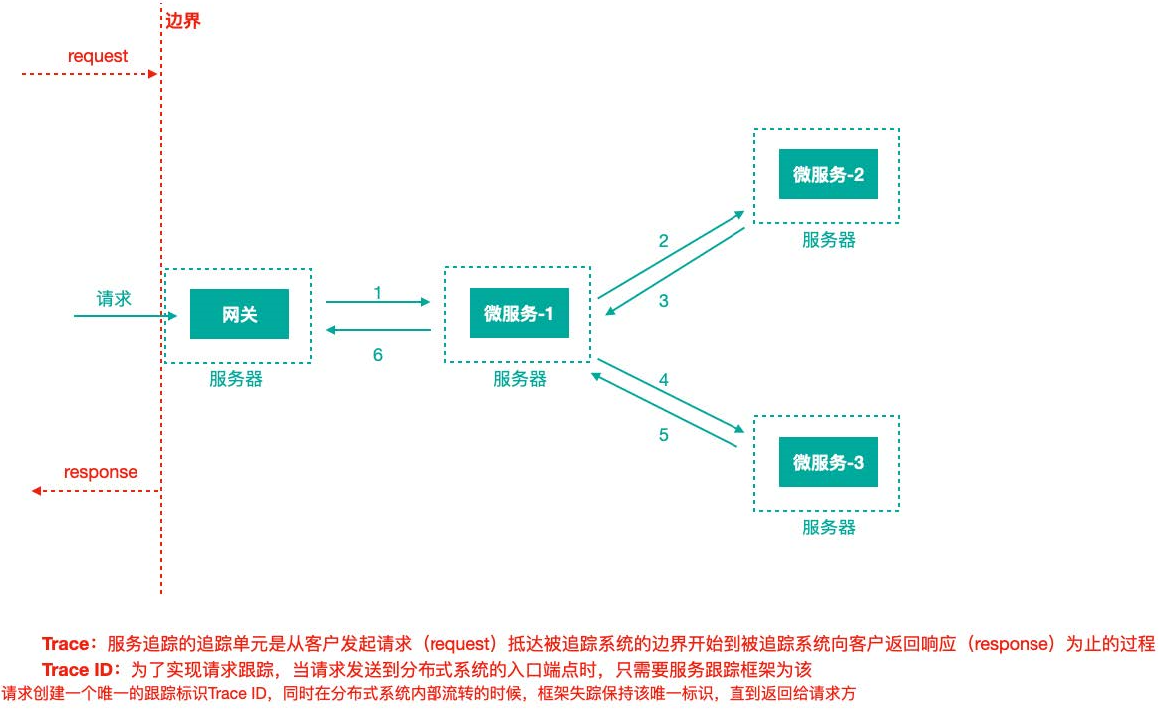
微服务架构中,针对请求处理的调用链可以展现为一棵树,示意如下:

上图描述了一个常见的调用场景,一个请求通过网关服务路由到下游的微服务-1,然后微服务-1调用微服务-2,拿到结果后再调用微服务-3,最后组合微服务-2和微服务-3的结果,通过网关返回给用户 。
为了追踪整个调用链路,肯定需要记录日志,日志记录是基础,在此之上肯定有一些理论概念,当下主流的的分布式链路追踪技术/系统所基于的理念都来自于Google的⼀篇论文《Dapper, a Large-Scale Distributed Systems TracingInfrastructure》,这里面涉及到的核心理念是什么,我们来看下,还以前面的服务调用来说。
上图标识一个请求链路,一条链路通过TraceId唯一标识,span标识发起的请求信息,各span通过parrentId关联起来。
Trace:服务追踪的追踪单元是从客户发起请求(request)抵达被追踪系统的边界开始,到被追踪系统向客户返回响应(response)为止的过程
Trace ID:为了实现请求跟踪,当请求发送到分布式系统的入口端点时,只需要服务跟踪框架为该请求创建一个唯一的跟踪标识Trace ID,同时在分布式系统内部流转的时候,框架失踪保持该唯一标识,直到返回给请求方。
一个Trace由一个或者多个Span组成,每一个Span都有一个SpanId,Span中会记录TraceId,同时还有一个叫做ParentId,指向了另外一个Span的SpanId,表明父子关系,其实本质表达了依赖关系。
Span ID:为了统计各处理单元的时间延迟,当请求到达各个服务组件时,也是通过一个唯一标识Span ID来标记它的开始,具体过程以及结束。对每一个Span来说,它必须有开始和结束两个节点,通过记录开始Span和结束Span的时间戳,就能统计出该Span的时间延迟,除了时间戳记录之外,它还可以包含⼀些其他元数据,比如时间名称、请求信息等。
每一个Span都会有一个唯一跟踪标识 Span ID,若干个有序的 span 就组成了一个trace。
Span可以认为是一个日志数据结构,在一些特殊的时机点会记录了一些日志信息,比如有时间戳、spanId、TraceId,parentIde等,Span中也抽象出了另外一个概念,叫做事件,核心事件如下:
- CS :client send/start 客户端/消费者发出一个请求,描述的是一个span开始
- SR: server received/start 服务端/生产者接收请求 SR-CS属于请求发送的网络延迟
- SS: server send/finish 服务端/生产者发送应答 SS-SR属于服务端消耗时间
- CR:client received/finished 客户端/消费者接收应答 CR-SS表示回复需要的时间(响应的网络延迟)
Spring Cloud Sleuth (追踪服务框架)可以追踪服务之间的调用,Sleuth可以记录一个服务请求经过哪些服务、服务处理时长等,根据这些,我们能够理清各微服务间的调用关系及进行问题追踪分析。
- 耗时分析:通过 Sleuth 了解采样请求的耗时,分析服务性能问题(哪些服务调用比较耗时)
- 链路优化:发现频繁调用的服务,针对性优化等
- Sleuth就是通过记录日志的方式来记录踪迹数据的
注意:我们往往把Spring Cloud Sleuth 和 Zipkin 一起使用,把 Sleuth 的数据信息发送给Zipkin 进行聚合,利用 Zipkin 存储并展示数据。
