“一万字”动静图生动结合详解:快速排序
动静图生动结合——快速排序

每博一文案
小时候,摔倒了,要看看周围有没有人,有人就哭,没人就爬起来,
长大后,摔倒了也要看周围有没有人,有人就爬起来,没人才敢哭。
有人说,成年人的世界都已开启了精英模式,很少会听见他们抱怨
生活的苦难。小时候有父母遮风挡雨,长大后,突然肩负了,太多
的责任和期待。前有父母,不敢喊累,后有孩子,不能逃避。
每个成年人都有无法诉说的心酸和苦恼,总是把苦,藏在心底。
选择一个人,硬抗,有太多的时候,心里已经很苦,很累了。却还是
装出一副云淡风轻的样子,明明已经坚持不住了,却还是逞强要求自己再坚持一会儿。
有太多时候,处在崩溃的边缘,也想要痛痛快快的大哭一场,害怕自己之前的坚持,
都会白费。
没有谁的生活能够一帆风顺,即便再光鲜的背后,也有不为人知的苦楚,
每个人都在和这个残酷的世界交手,我们无需过分压抑自己,想哭的时候就哭
,想笑的时候就放声大笑,一辈子就那么长,别总是让自己硬抗。
我们都是肉体凡胎,最普通的平常人,不用无所不能,愿你无论何时,懂得
心痛自己,给自己最温柔的呵护。
在坚定的力量,走在人生的弯路,也能欣赏路上的风景。
凡心所向,素履所往,生如逆旅,一苇以航
—————— 一禅心灵庙语
快速排序介绍
取待排序元素序列中的某个元素作为 基准值, 通过一趟排序将要排序的数据 分割成独立的两个部分左右序列 ,左序列中的所有数据比 基准值 都要小,另外 右序列中所有的数据比 基准值 都要大,然后再按如上的方法对这两部分数据**(左右序列)** , 分别进行快速排序,排序过程可以递归进行,以此达到整个数据变成有序序列。
-
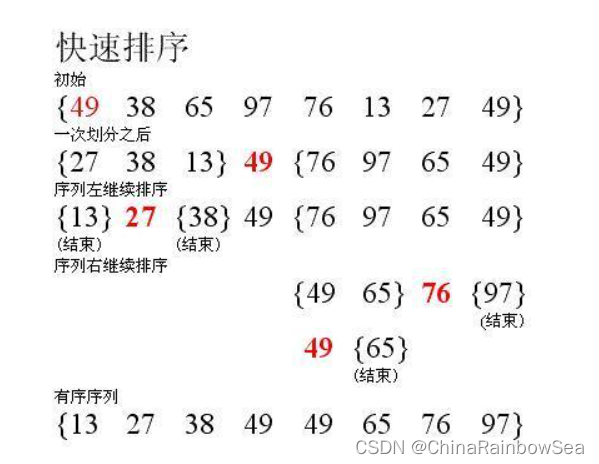
上图以 第一个元素的值 作为基准
-
比 基准值 小的,排在左侧,比基准值大的排在右侧
-
然后再以分好的部分重复以上操作,直到每个部分中只有一个数据时,就排序好了,有序了
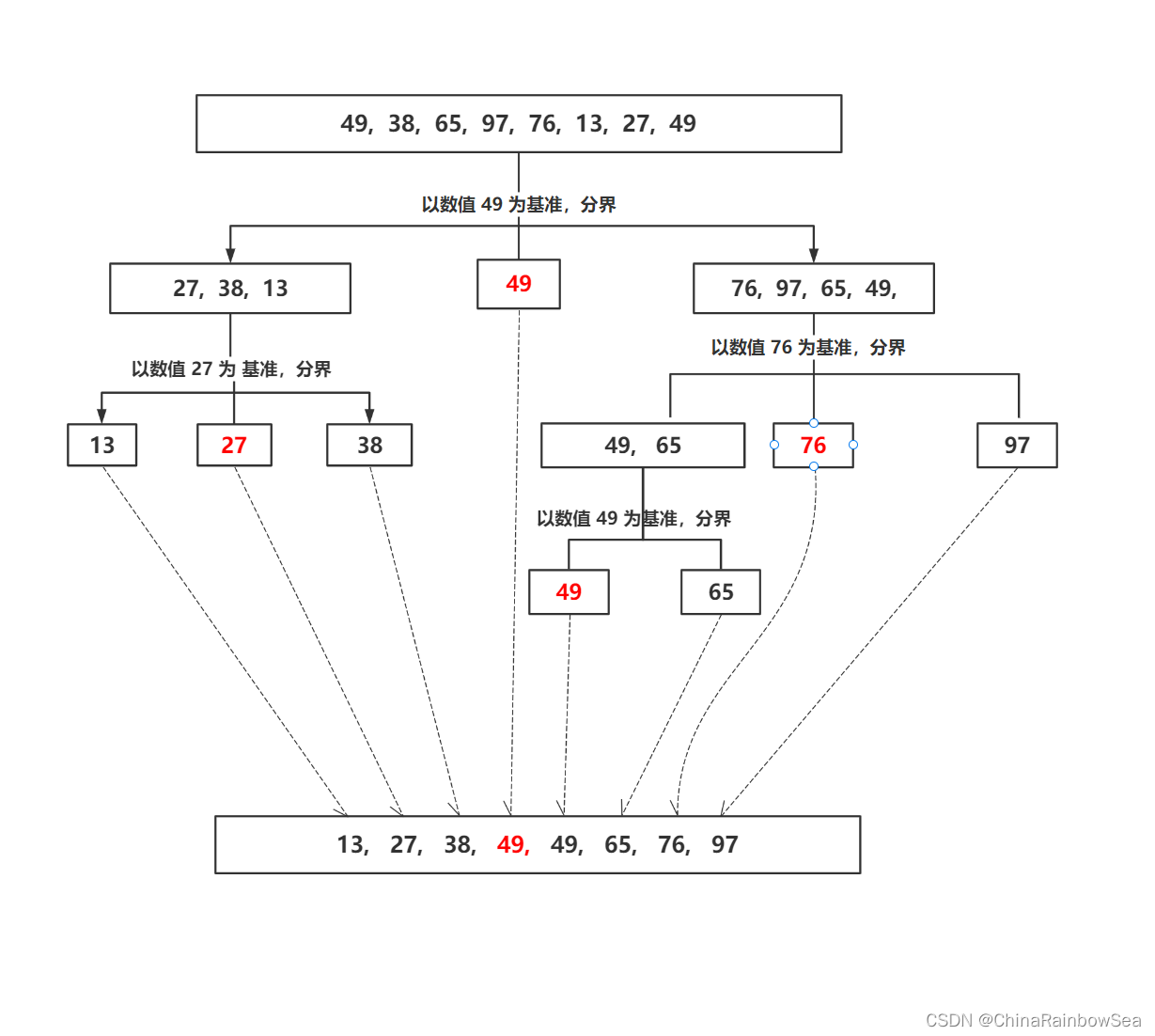
- 上图是以 最后一个元素的值 作为分界基准
- 比 基准值 小的,排在左侧,比基准值大的排在右侧
- 然后再以分好的部分重复以上操作,直到每个部分中只有一个数据时,就排序好了,有序了
挖坑法,快速排序 升序
挖坑法的基本思想,以升序为例
- 从待排序元素序列中的某个元素作为
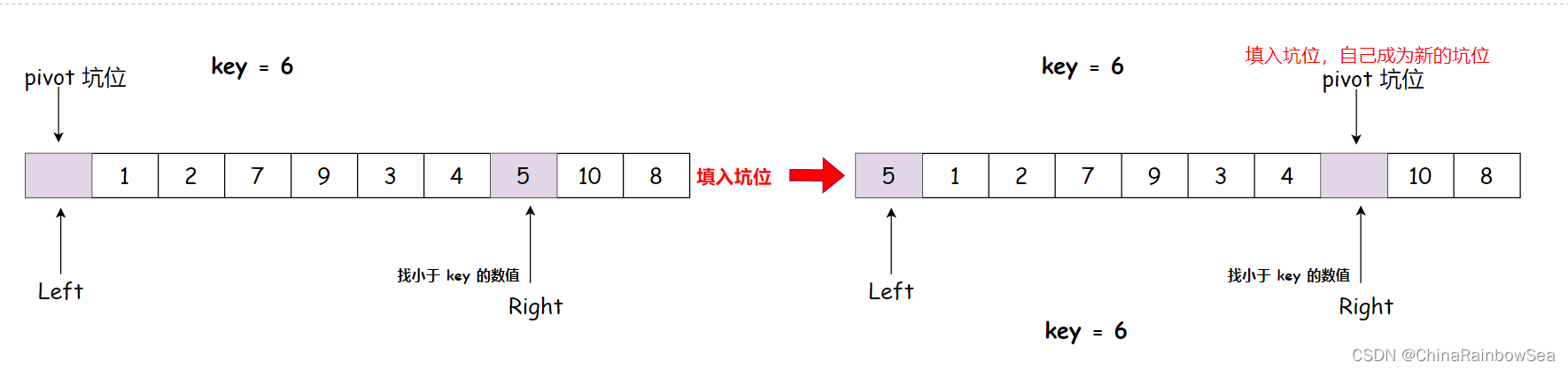
基准值(一般是序列中的第一个元素或者是最后一个元素) ,将该基准值存放到key中,并在该数据下标位置创建一个坑位,坑位: 该位置下标的数值,可以被覆盖,因为已经被保存到了key中了 - 定义一个
L和一个R,L 从序列的首元素下标开始,左向右走,R 从序列最后一个下标位置开始,右向左走。注意 **(若坑位最开始是在最左边,则需要 **R右边先走,从右向左先走),(若坑位是最开始在右边,则需要L左边先走,从左向右先走) ,如果不这么做的话,是无法进行key的数值分界的。具体说明,大家可以往后看下去,会说明详细的 - 在走的过程中,这里是以 升序为例 ,
R向前先走,当R遇到小于key的数值,则将该数值,填入到左边的坑位中,同时把自己的下标位置作为新的坑位使用,这时后再L向后走,当L遇到 大于key的数值,则将该数值,填入到右边的坑位中,同时把自己的下标位置作为新的坑位使用。 - 如此循环下去,直到
L和R相遇,把它们相遇的下标点作为新的坑位使用,再把key关键值,填入该相遇点坑位,经过这样的一次单趟排序,也是把key排序到了,正确的位置中,并且也使得key左边的数据全部小于key,key右边的数据全部都大于key。 - 然后,分而治之,将
key左序列 和 右序列 的数据进行上述方式的 单趟排序 ,如此反复递归操作下去,当左右序列都有序了,整体也就有序了,递归结束条件 :左右序列只有一个数据,或者左右序列不存在时,该部分数据就已经有序了,停止递归,返回
如下是:单趟排序的动图
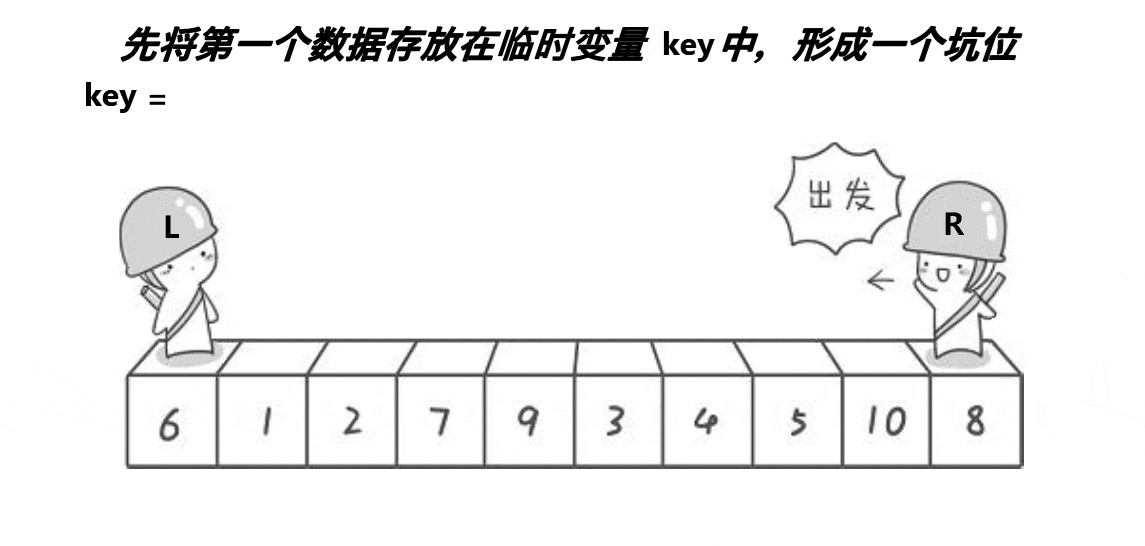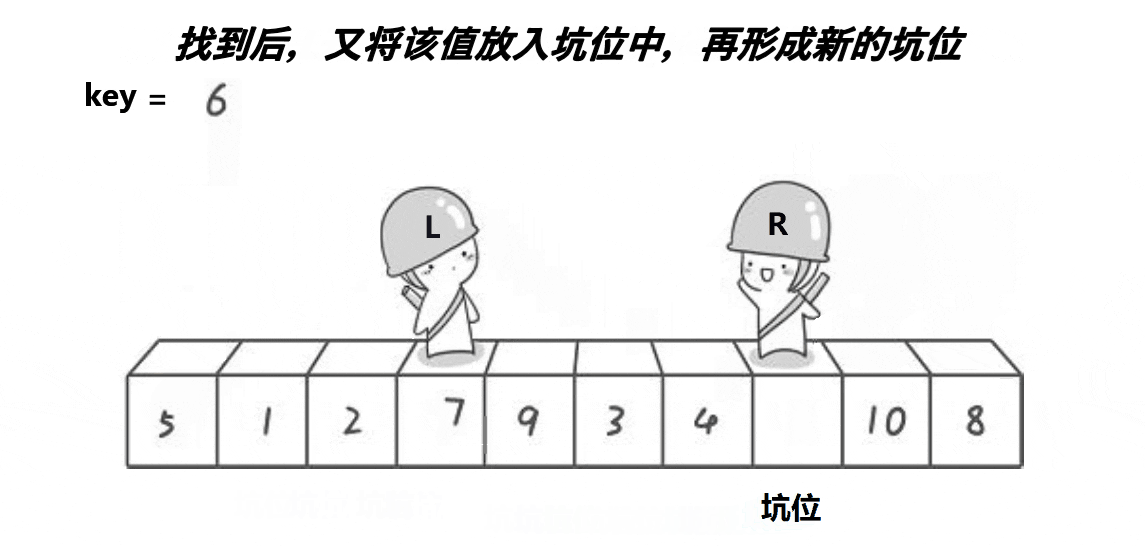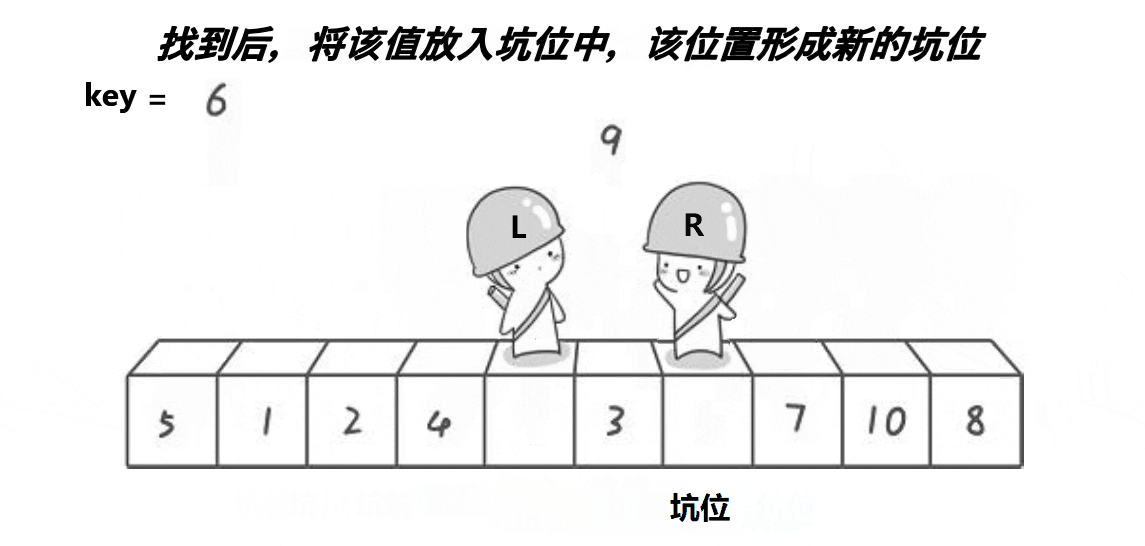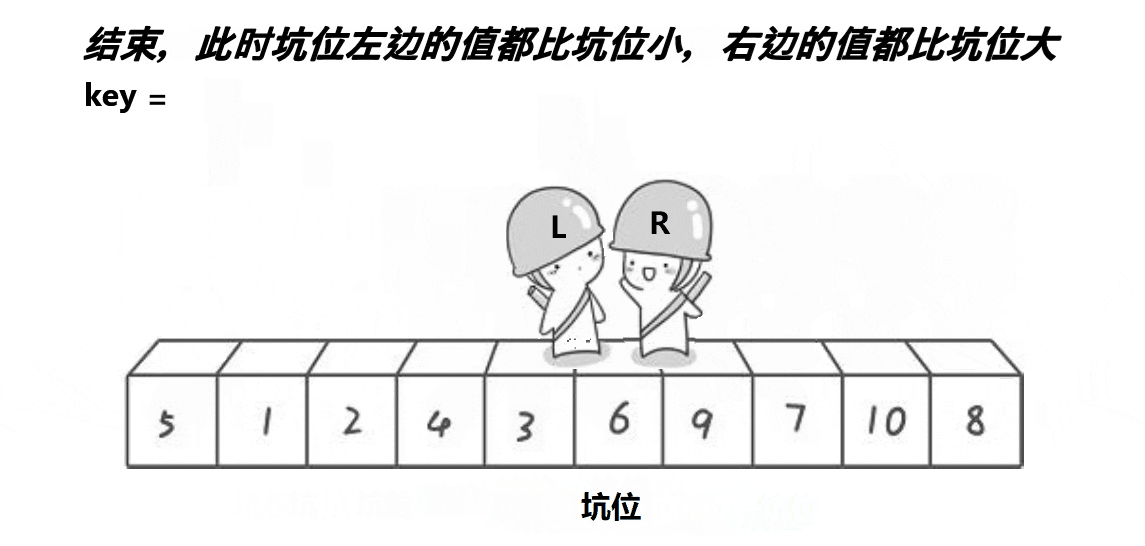
静图单趟排序步骤如下,这里以升序为例
- 首先准备一个无序的数组

- 这里将数组下标
0作为 坑位和key数值分界
坑位在左边,右边的 Right 先走,升序,找小于 key 的数值,找到 5,填入坑位
注意 坑位上的数值,并没有消失,只是可以被覆盖。
- 再
Left向前走,找大于key的数值,
找到 7 比 key 大,填入右边的坑位中
注意 坑位上的数值,并没有消失,只是可以被覆盖
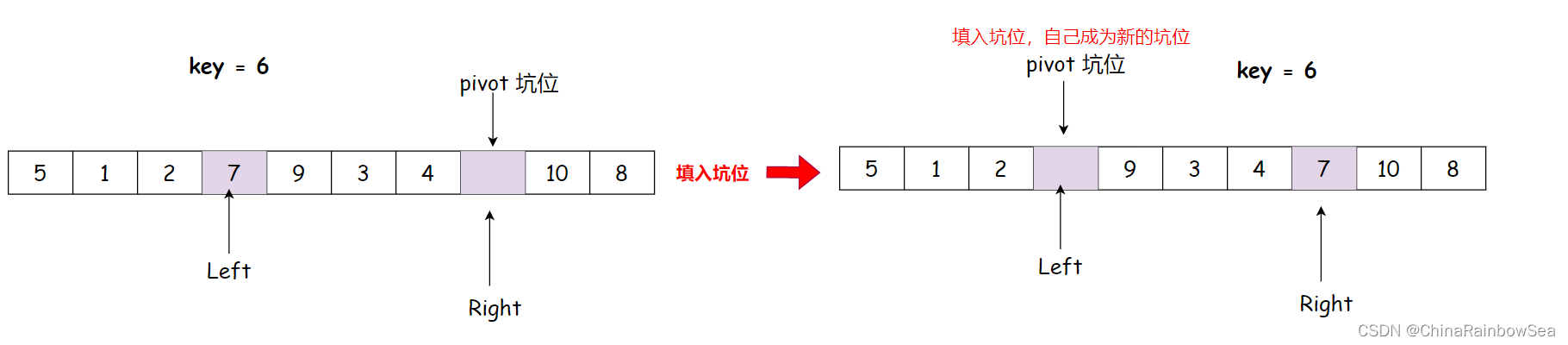
Right向前走,找小于key的数值
找到 4 比 key 小,填入左边的坑位中
注意 坑位上的数值,并没有消失,只是可以被覆盖
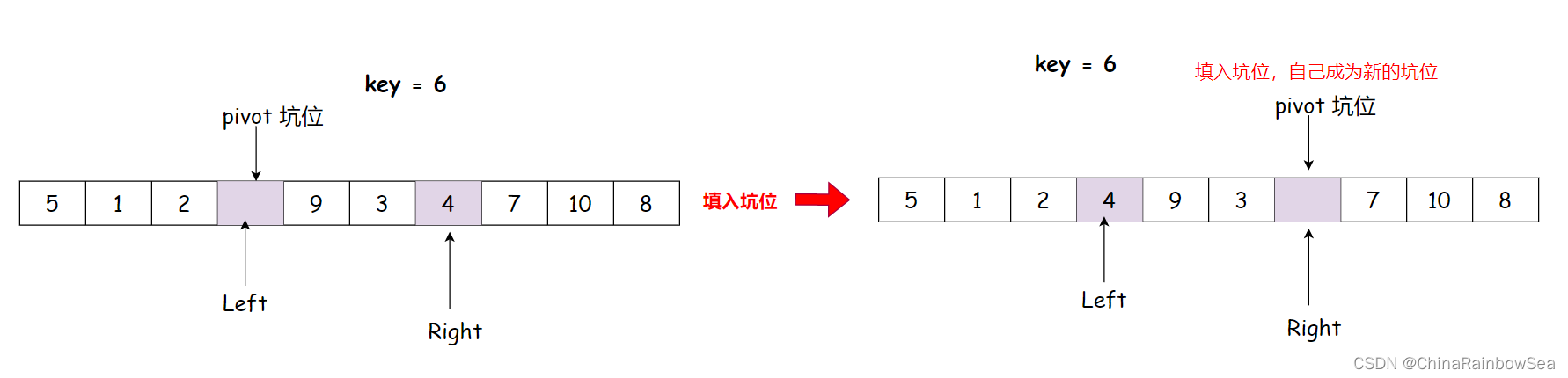
Left向后走,找大于key的数值
找到 9 比 key 大,填入右边的坑位中
注意 坑位上的数值,并没有消失,只是可以被覆盖
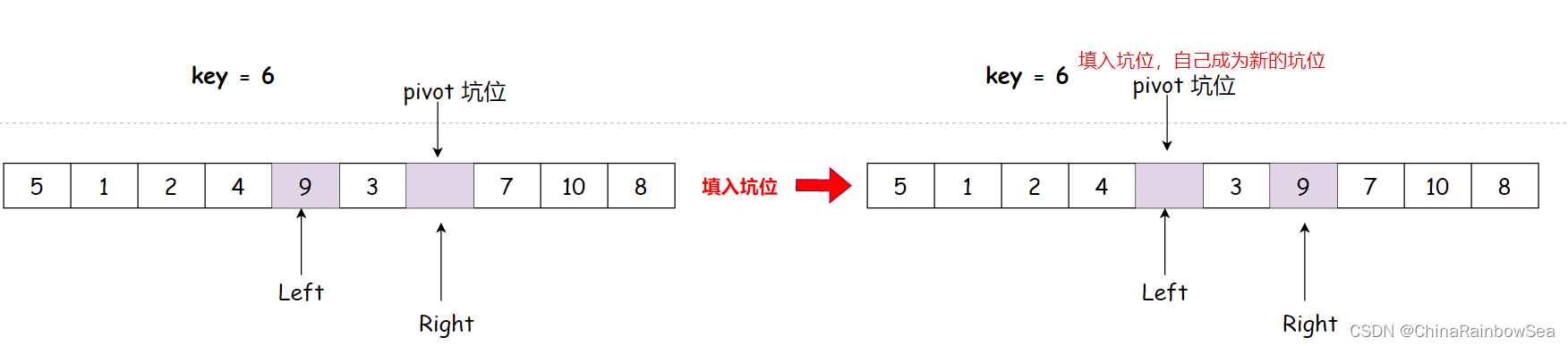
Right向前走,找小于key的数值
找到 3 比 key 小,填入左边的坑位中
注意 坑位上的数值,并没有消失,只是可以被覆盖
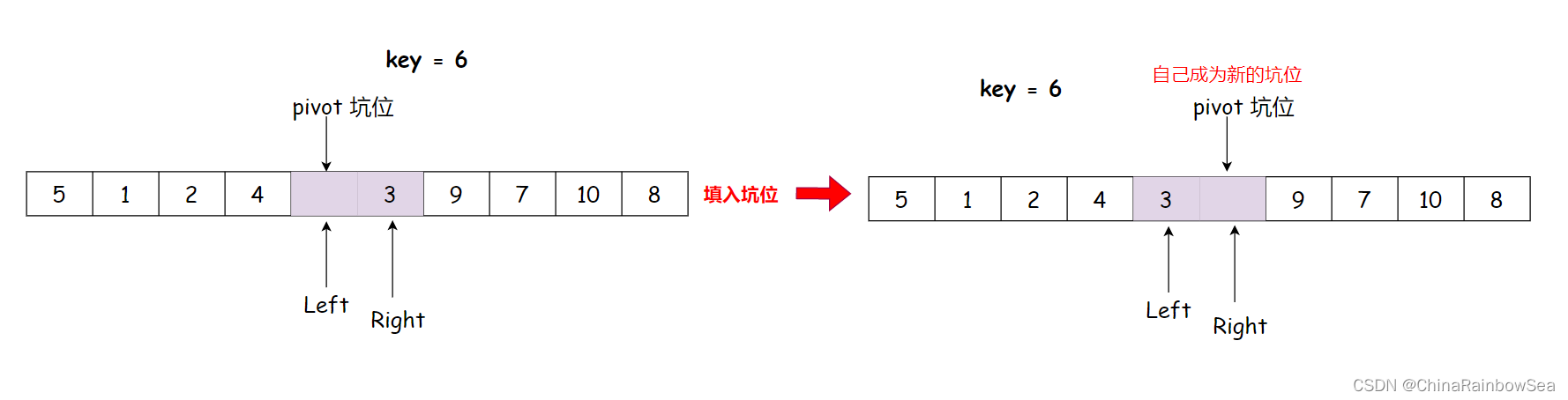
- 再
Left向后走,找大于key的数值,但是与Right相遇了
将相遇点,作为坑位,将 key 数值,填入到坑位中,该 key 就有序了
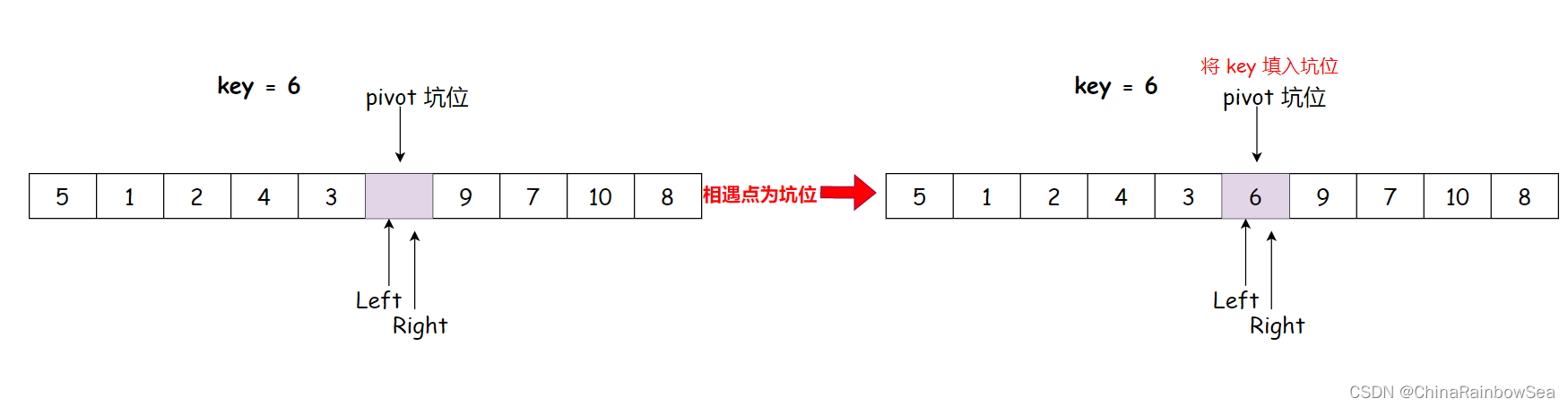
- 单趟排序完,比
key数值小的全部在 左边,比key数值大的全部在右边,key排序好了,不要动了

- 后面,再通过分而治之,递归的上述同样的方式,将
key左右序列,排序成有序,整体就有序了,
递归结束条件为 ,当 左右序列只有一个数据时或者序列不存在,则说明该部分已经有序了,不用在排序了,返回。
为什么,当 key 和 坑位 在左边的时候,右边先走,当 key 和 坑位 在 右边的时候,左边先走 ??? 这里以升序为例
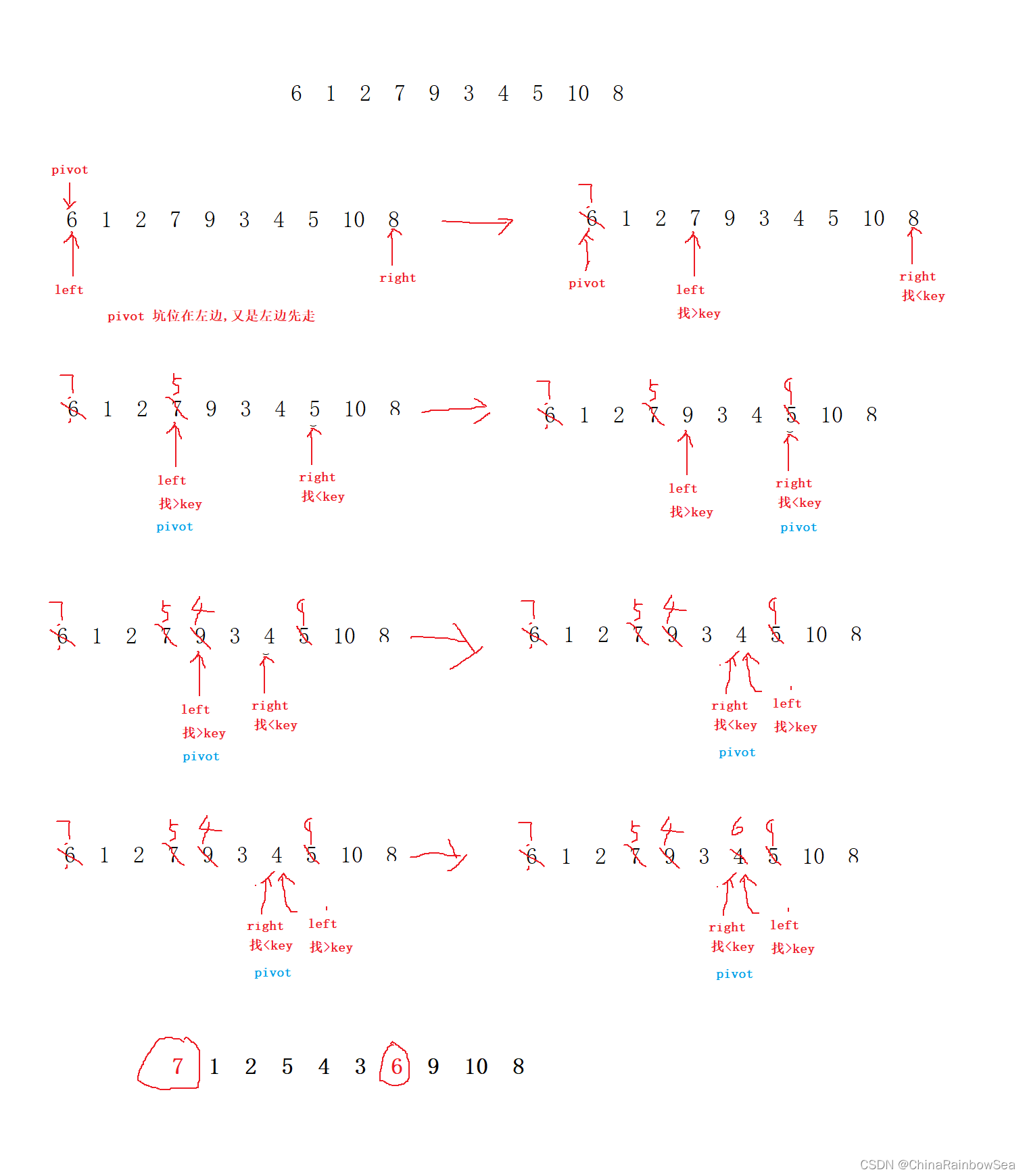
从上述的过程演示中: 我们可以发现如果 key 是在左边,而又是左边先走的话,其 与数值 分界值 key 作为坑位的 6 左边第一个坑位,会首先被 left 找 大于 key 的数值,填入坑位,导致第一个左边坑位上的数值是 大于 key 的,而坑位又被移动了,就无法实现 key 分界了,小于 key 的全部在左边,大于 key 的全部在右边是无法做到的,
而如果反过来,key 在左边,右边right 先走的话,right 找小于 key 的数值,然后填入到第一个左边 key 坑位中去,其值是小于 key 的,没有问题,小于 key 全部在左边。
同理:当 key 和 坑位 在 右边的时候,左边先走 是同一个道理。
都是为了防止,第一坑位上的数值,出现数值大小问题。
具体代码,实现如下:
// 打印数组
void playPrint(int* arr, int n)
{
for (int i = 0; i < n; i++)
{
printf("%d ", arr[i]);
}
printf("\n");
}
// 快速排序,升序
quickSortAsc(int* arr, int begin, int end)
{
if (begin >= end) // 当左右序列只有一个数值或 begin > end 不存在序列时,
{ // 该部分数据已经有序了,不用在递归排序下去
return;
}
int left = begin;
int right = end;
int pivot = left; // 默认坑位是,数组中下标 0 的位置
int key = arr[pivot]; // 分界值
while (left < right) // 相遇跳出
{
// 坑位,在左边,先从右边开始找小于 key 的数值下标
while (left < right && arr[right] >= key) // left < right防止在该内部循环就已经相遇了,退出循环
{ // >= 需要 = ,如果 没有 等于 当 arr[right] == key,不会执行 right --
right--; // 而是停留在 等于的位置,left 与 right 就不会相遇了,死循环
}
// 跳出循环,找到了小于 key 的数值的下标位置
arr[pivot] = arr[right]; // 填入坑位中,
pivot = right; // 自己成为新的坑位
// 左边找,大于 key 的数值下标
while (left < right && arr[left] <= key) // left < right 和上面同理
{ // <= 和上面同理
left++;
}
// 跳出循环,找到了大于 key 的数值下标位置
arr[pivot] = arr[left]; // 填入坑位
pivot = left; // 自己成为新的坑位
}
// 跳出循环,相遇了
pivot = left; // 相遇点作为新的坑位, left 和 right 是相等的
arr[pivot] = key; // 将 key 填入到,相遇点坑位中,排序好,
// [begin, pivot-1] pivot [pivot +1 , end] pivot 下标位置的数值,排序好了,不要动
quickSortAsc(arr, begin, pivot - 1); // 左区间,递归排序
quickSortAsc(arr, pivot + 1, end); // 右区间,递归排序
}
上述代码解析,及其注意事项
默认数组中的第一个下标位置作为 坑位,以及 key 分界值
int pivot = left;int key = arr[pivot];,它存在一定的缺陷,具体的大家可以,往下看 三数取中 的内容上有说明递归结束条件
if (begin >= end)当
begin = end表示: 它们相等,左右序列只剩下一个数值(该数值就是它们相等的数值),同时表示该部分数据已经排序好了,因为只有一个数据了,还需要排序吗,自身就是一个排序好了的表现。返回。
当
begin > end表示:该序列不存在了,因为 左边怎么可以大于 右边的序列,这时不存在的,该现象同样表明了,该部分序列已经排序好了,返回。
注意 **(若坑位最开始是在最左边,则需要 **
R右边先走,从右向左先走),(若坑位是最开始在右边,则需要L左边先走,从左向右先走)
while (left < right && arr[right] >= key)
内循环中附加left < right是为了,防止该内循环中就 已经出现了 left 与 right 相遇的下标点了,而没有跳出,导致出错
arr[right] >= key必须要有=,如果没有 等于 的话,当arr[right] = key时,是不会执行循环中的
right--;向前移动的,就会导致right一直停留在arr[right] = key的下标位置, 再导致
right与left不会相遇,从而死循环。
pivot = left;arr[pivot] = key;跳出循环,相遇点作为新坑位,将key填入坑位中,
key就已经是排序好了,不用动了当
key左右序列都有序了,整体才有序,
[begin, pivot-1] pivot [pivot +1 , end];
quickSortAsc(arr, begin, pivot - 1);左区间递归排序,[begin, pivot-1]是左区间的下标位置的范围,
begin表示: 数组的起始位置下标,pivot - 1表示:排序好的key前一个下标位置
quickSortAsc(arr, pivot + 1, end);右区间递归排序,[pivot +1 , end]是右区间的下标位置的范围,
pivot + 1表示:排序好的key后一个下标位置,end表示:数组的最后下标位置
注意,
quickSortAsc(int* arr, int begin, int end)的参数是 (数组的地址,数组起始位置下标数组最后一个位置的下标(不是数组的大小注意了)),不然就会发生越界的可能。
quickSortAsc(arr, 0, sizeof(arr) / sizeof(int) - 1)
sizeof(arr) / sizeof(int) - 1表示数组最后一个下标的位置,
sizeof(arr)表示数组所占空间的大小,单位字节
sizeof(int) - 1表示数组元素类型所占空间的大小,单位字节
挖坑法,快速排序,降序
方式原理是一样的,只是把 大于key 的数值放到左边,小于 key的数值放到右边。
我们只需要改变一下 Left 找小于的 key 的数值,Right 找大于 key 的数值,就可以了
具体代码实现如下:
// 打印数组
void playPrint(int* arr, int n)
{
for (int i = 0; i < n; i++)
{
printf("%d ", arr[i]);
}
printf("\n");
}
// 挖坑法,快速排序,降序
void quickSortDesc(int* arr, int begin, int end)
{
if (begin >= end) // 左右使用一个数值或序列不存在,说明该部分数据已经有序了,返回
{
return;
}
int left = begin;
int right = end;
int pivot = left; // 默认数组 0下标坑位
int key = arr[pivot]; // 分界数值
while (left < right)
{
// 坑位在左边,右边坑位先走,找大于key 的数值下标
while (left < right && arr[right] <= key) // left < right / <= 和上面升序是一样的
{
right--;
}
// 跳出循环找到了
arr[pivot] = arr[right]; // 填入坑位
pivot = right; // 自己成为新的坑位
// 左边找小于 key 的数值下标
while (left < right && arr[left] >= key) // left < right / >= 原理一样
{
left++;
}
// 跳出循环找到了
arr[pivot] = arr[left]; // 填入坑位
pivot = left; // 自己成为坑位
}
// 相遇点成为新的坑位
pivot = left;
arr[pivot] = key; // key 填入坑位,排序好
// key 左右序列有序,递归,分而治之
// [begin, pivot -1] pivot [pivot+1, right] pivot 排序好了,不要动了
quickSortDesc(arr, begin, pivot - 1); // 左区间递归排序
quickSortDesc(arr, pivot + 1, right); // 右区间递归排序
}

左右指针,快速排序,升序
左右指针的基本思想,以升序为例
- 从待排序元素序列中的某个元素作为
基准值(一般是序列中的第一个元素或者是最后一个元素) ,将该基准值存放到key中,以它key作为分界值 - 定义一个
L和一个R,L 序列的首元素下标开始,从左向右走,R从序列最后一个下标位置开始,从右向左走。注意(若key分界下标在左边,则右边先走,从左向右,若key分界下标在右边,则左边先走,从左往右 ) 具体说明,大家可以向后继续查看,会有介绍说明原因。 - 在执行的过程中,这里是以升序为例 ,
R走,从右向左走,当R遇到小于key的数值,记住该数值的下标位置,再L走,从左向右走,当L遇到大于key的数值,记住该数值的下标位置, - 当
R和L都找到了,对应的数值下标位置后,交换。们之间的数值(注意: 形参的改变想要影响实参需要传地址) - 如此执行下去,直到
L和R两个下标相遇,把相遇点的下标的数值与key数值交换,此时就实现了,把全部小于key的数值放到了key的左边,全部大于key的数值放到了key的右边。此时的key也是排序到了,它正确的位置中去了。 - 最后,同样分而治之,将
key左序列 和 右序列 的数据进行上述方式的 单趟排序 ,如此反复递归操作下入,当左右序列都有序了,整体也就有序了,递归结束条件:左右序列只有一个数据,或者左右序列不存在时,该部分数据就已经排序好,有序了,停止递归,开始返回了。
有关的动图如下:
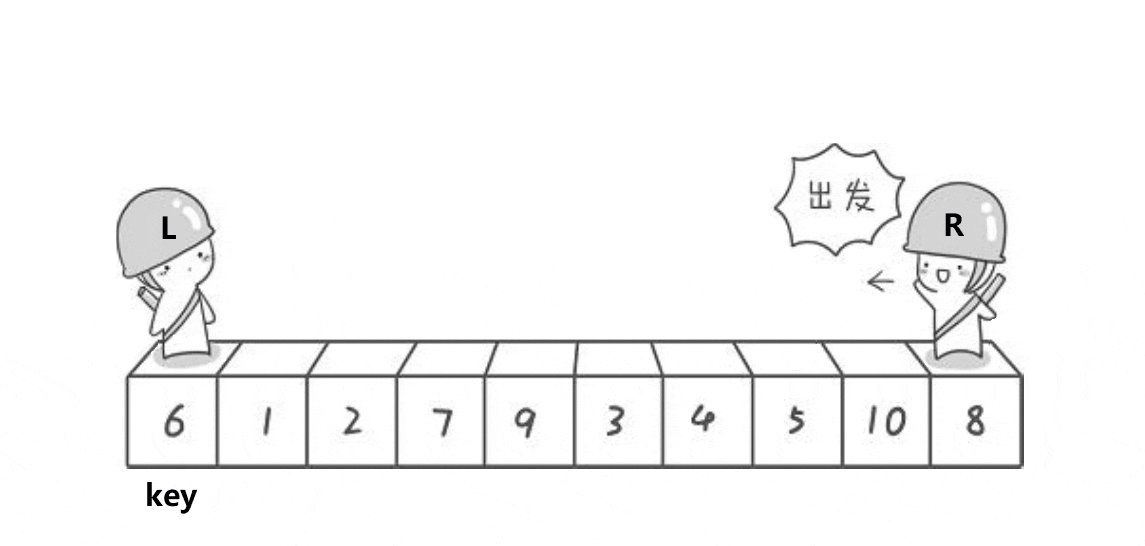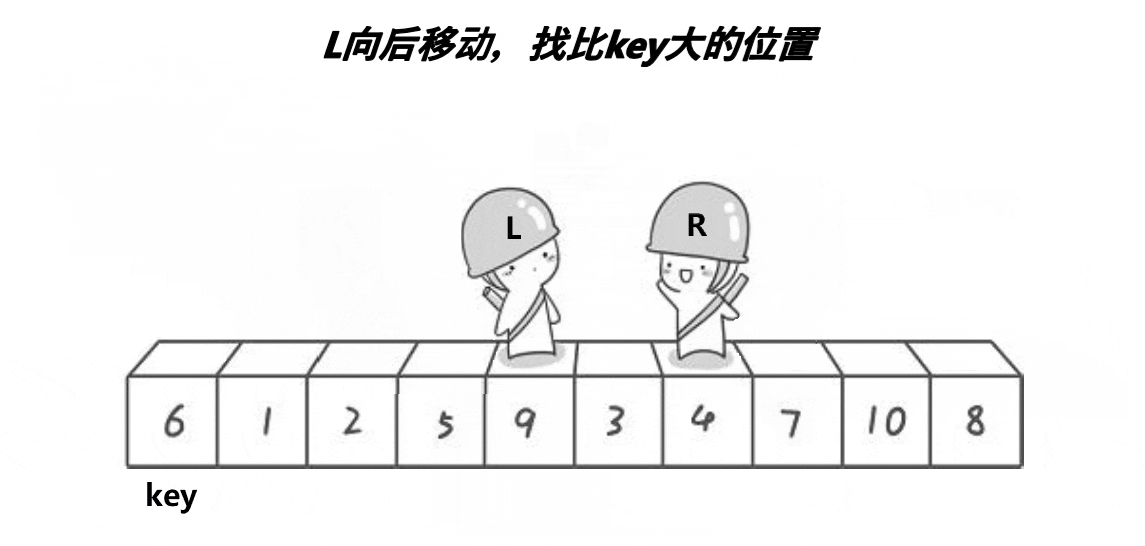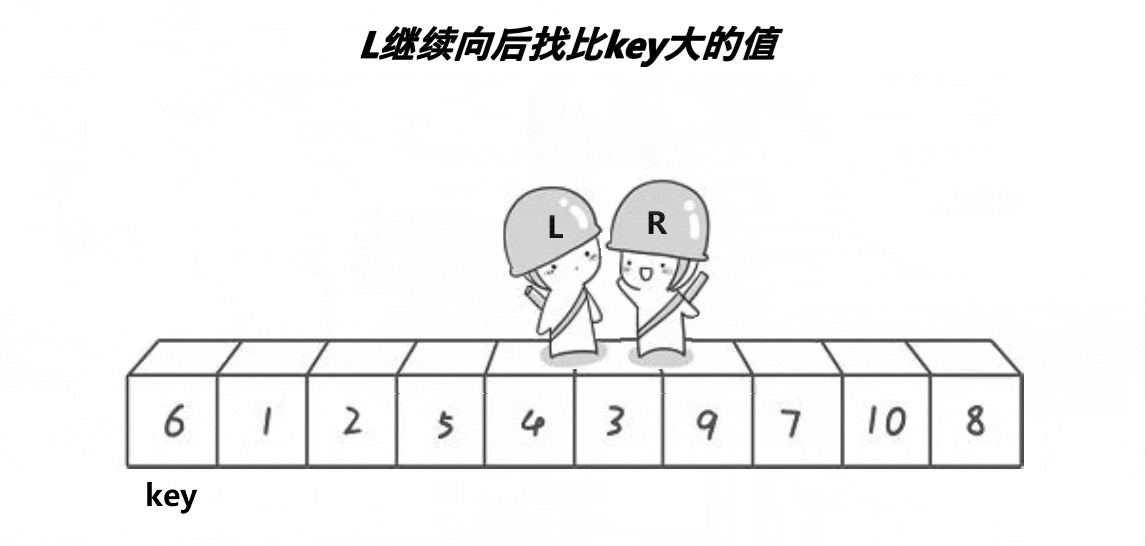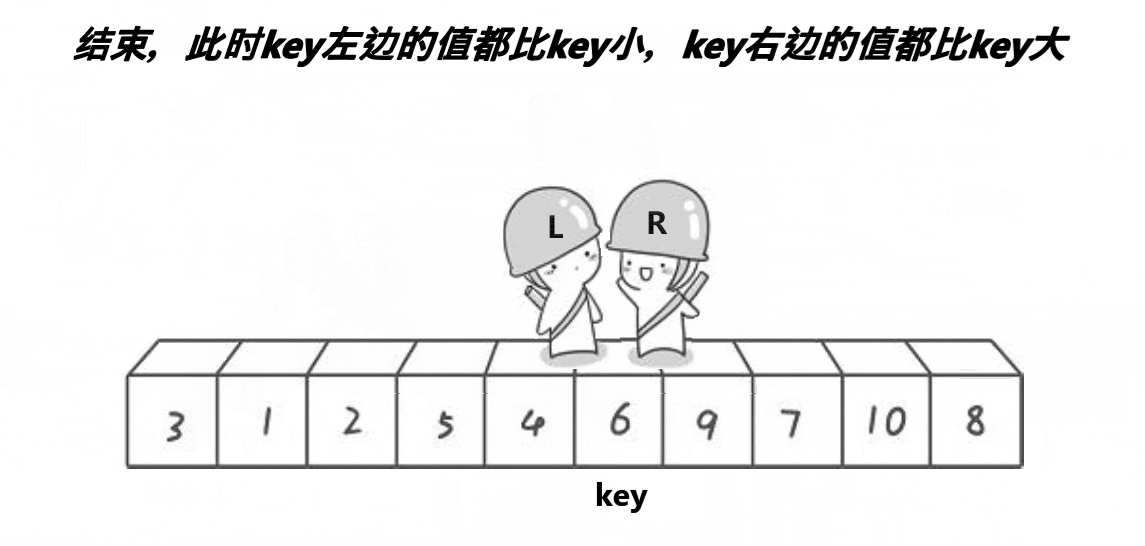
有关的静态图运行图如下:
- 首先来一个无序的数组如下:
将数组下标为 0 的位置作为 Left ,数组的最后一个下标位置作为 Right,默认 数组下标0的数值是 Key 分界值
Right找小于key的数值,Left找大于key的数值,然后交换数值
注意: 因为 key分界值,取的是左边的,所以需要左边先走,Left 找到 7,Right 找到 5, 交换
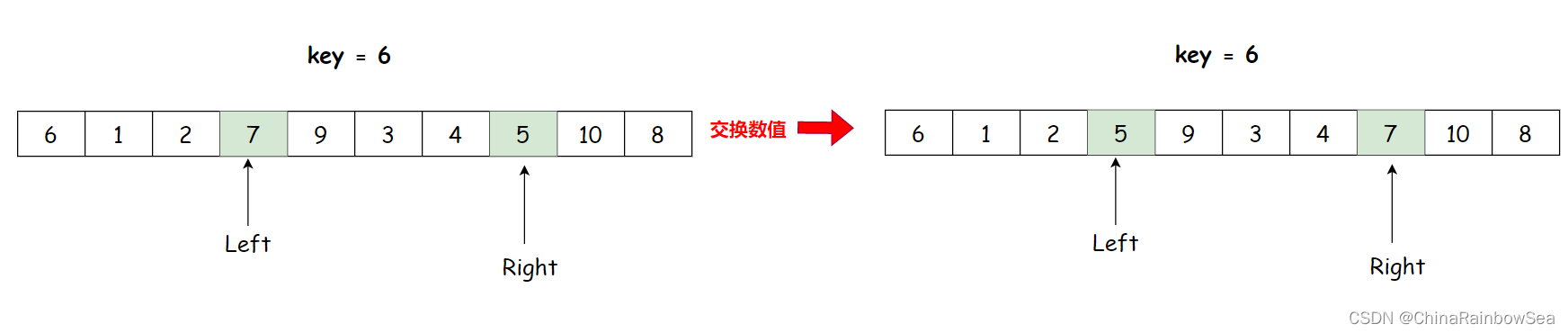
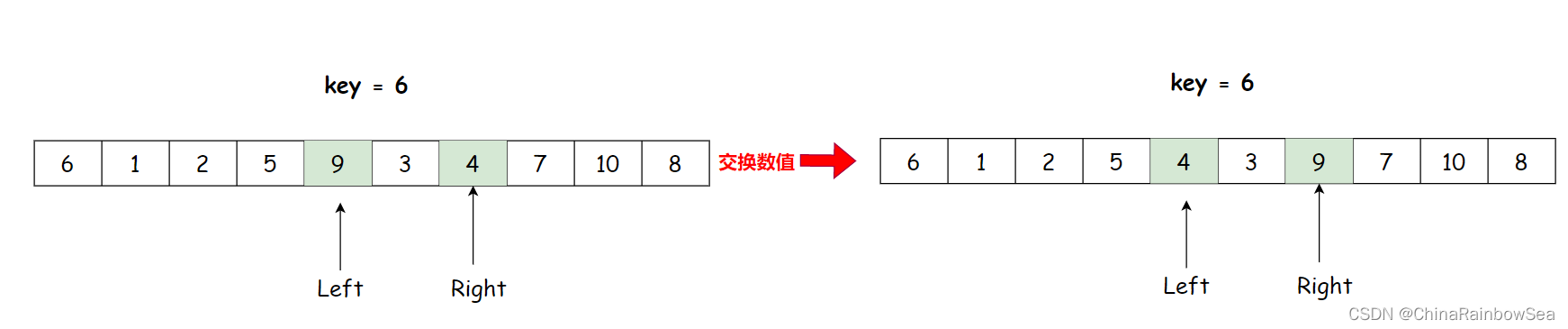
Right再找小于key的数值,Left找大于key的数值,然后交换数值
Right 找到 4, Left 找到 9 ,交换数值
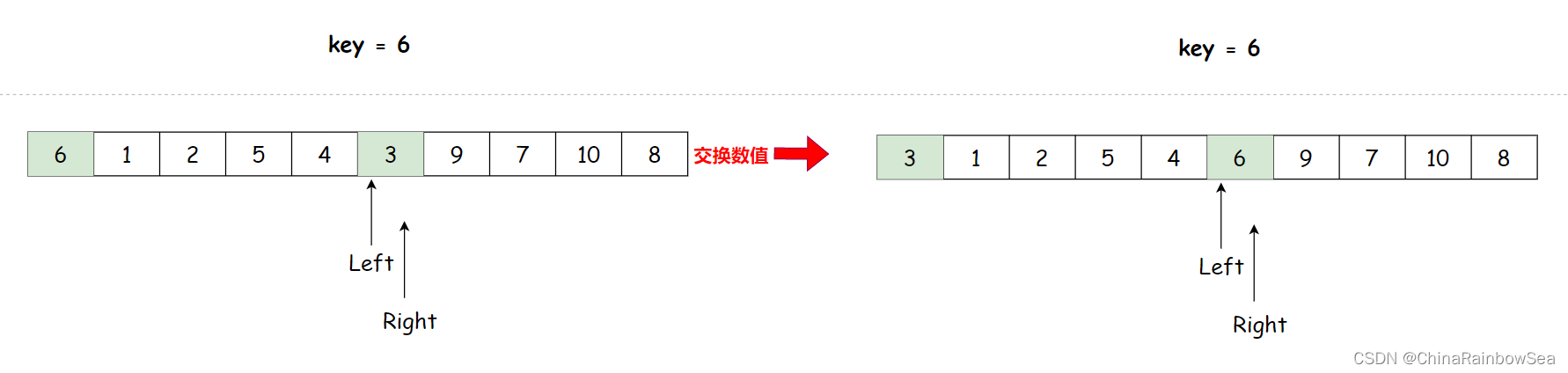
- 再走,相遇了,将
key与相遇点的下标数值交换
Left 和 Right 在 数值3 的位置相遇了,与 key下标下的数值交换
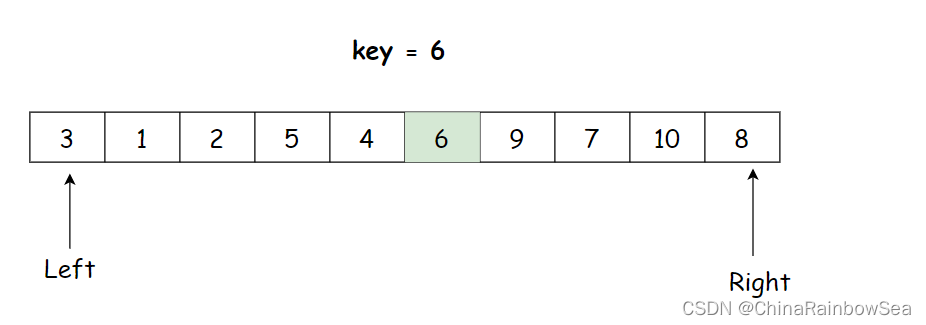
- 单趟排序完,比
key数值小的全部在 左边,比key数值大的全部在右边,key排序好了,不要动了
- 后面,再通过分而治之,递归的上述同样的方式,将
key左右序列,排序成有序,整体就有序了,
递归结束条件为 ,当 左右序列只有一个数据时或者序列不存在,则说明该部分已经有序了,不用在排序了,返回。
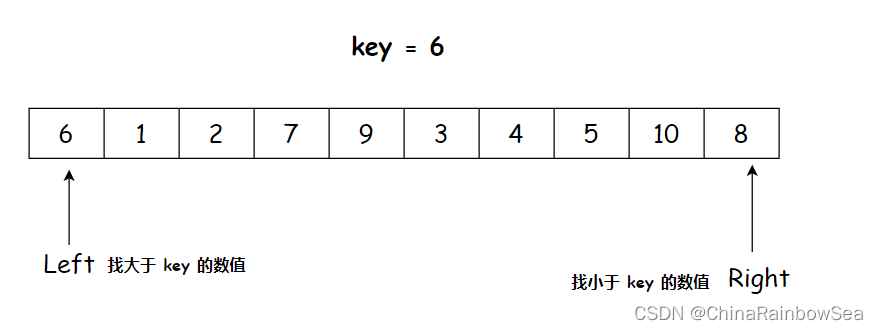
为什么,当 key 在左边的时候,右边先走,当 key 在 右边的时候,左边先走 ???这里以升序为例
大家看下图
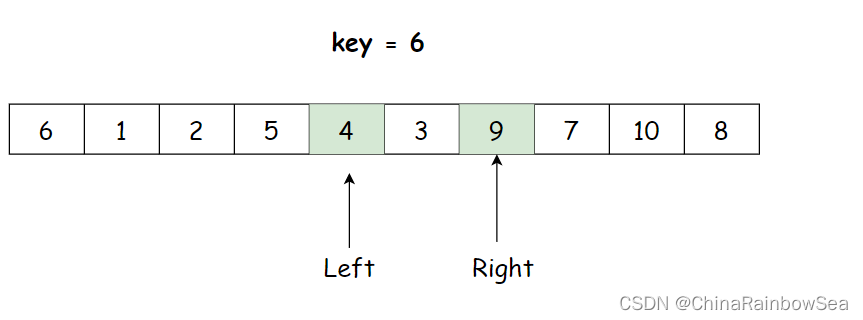
如上图所示,key 的数值取的是左边的,如果 Left 先走找到大于 key 的数值 9 ,也是它们 Left 和 Right 相遇点,既然是相遇点, key 数值 6 与 相遇点的数值9就需要进行交换。就会变成如下图所示的结果:
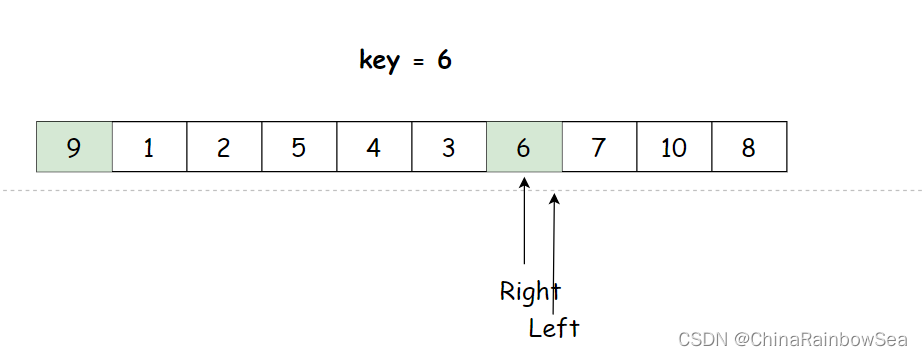
把 大于 key 的数值 9 放到了,以数组 0 下标的位 key 的位置,这样就不符合 小于 key 的数值全部在左边,大于 key 的数值全部在右边的,要求了。因为 Right 本身就是为了找到小于 key 的数值然后,把大于 key 的数值交换到自己这里来,当 left 先走,是 left 遇到 Right ,而这时的 Right 下标位置停留的数值还是之前通过交换得到的大于 key 的数值。再与 key 以交换,自然就把大于 key 给换到前面去了。
而如果是反过来,当key 是在左边,右边的Right 先走,找小于 key 的数值,是 Right 找到 3 小于 key ,再,Left 走与 Right 相遇,这时候,因为是 Right 先走的,找到的是 小于 key 的数值 3 ,以交换,就把小于 key 的数值换到前面了。
同理:当 key 在 右边的时候,左边先走 也是一样的道理。防止把数值放到了,不正确的位置上。
具体代码实现如下,升序
// 交换数值
void swap(int* p1, int* p2)
{
int tmp = *p1;
*p1 = *p2;
*p2 = tmp;
}
// 左右指针法,快速排序,升序
void quickSortLeftRightAsc(int* arr, int begin, int end)
{
if (begin >= end) // 当左右序列只有一个数值时或序列不存在,表示该部分序列已经有序了,返回
{
return;
}
int left = begin;
int right = end;
int keyi = left; // 分界值下标,保存
while (left < right)
{
// 因为 keyi 分界值是在左边,所以右边right找 小于 keyi 分界值的数值下标 先走
while (left < right && arr[right] >= arr[keyi]) // left < right 防止在该内循环中,就已经相遇了,而没有跳出循环
{ // >= 需要 = ,如果没有 等于的话,当 arr[left]= arr[keyi] 的分界数值的时候,是不会执行left++
right--; // 导致left 停留在相等的下标位置,导致 left 与 right 无法相遇,而死循环
}
// 左边left找 大于 keyi 分界值的数值下标
while (left < right && arr[left] <= arr[keyi]) // left < right / <= 同理
{
left++;
}
// 走到这,表示: 左右都找到了,对应数值的下标位置,则交换,或者,相遇了(就是自己和自己交换)
swap(&arr[left], &arr[right]); // 交换
}
//相遇了, 跳出循环, 将 keyi 分界值的数值与相遇点交换
int meet = left; // 保留相遇点
swap(&arr[meet], &arr[keyi]); // 交换,keyi 的数值有序了
// [begin meet-1] meet [meet+1, end] meet 有序了不要动
quickSortLeftRightAsc(arr, begin, meet - 1); // 左区间,递归排序
quickSortLeftRightAsc(arr, meet + 1, end); // 右区间,递归排序
}
上述代码解析及其注意事项
默认数组中的第一个 0 下标位置作为,
key分界数值,它存在一定的缺陷,具体的大家可以,往下看 三数取中 的内容上有说明
递归结束条件:
if (begin >= end)当
begin = end就是表示,该部分的左右序列中只剩下一个数据(就是它们相等的数值)了,一个数据自然就是有序的了,因为一个数值还需要比较排序吗,递归结束返回,当
begin > end该序列情况是不存在的,左边的下标位置怎么可以大于右边的下标位置,递归结束,返回
- 注意: 如
key分界值的取值是在左边,则右边先走,从右往左,若key分界值取值是在右边,则左边先走,从左往右 防止数据交换的位置错误。while (left < right && arr[right] >= arr[keyi])
left < right防止在内循环中left与right就已经相遇了,而没有退出。
arr[right] >= arr[keyi]需要=,如果没有 等于 的话,如果没有 等于 的话,当
arr[right] = key时,是不会执行循环中的right--;向前移动的,就会导致
right一直停留在arr[right] = key的下标位置, 再导致right与left不会相遇,从而死循环。
- 交换传地址,形参的改变想要影响实参就需要传地址。
[begin meet-1] meet [meet+1, end]meet 相遇点,该位置的数值排序好了,不要动
quickSortLeftRightAsc(arr, begin, meet - 1)左区间递归排序,[begin, meet-1]表示的是: 左区间的范围 ,
begin是数组的起始下标位置。meet-1是排序好的数值的前一个下标位置。同理
quickSortLeftRightAsc(arr, meet + 1, end)右区间递归排序,[meet+1,end]表示的是:右区间的范围,
meet+1表示的是排序好的数值后一个下标位置,end表示的是数组最后一个下标位置,( 不是数组的大小)。
quickSortLeftRightAsc(arr, 0, sizeof(arr) / sizeof(int) - 1)注意传的参数是:(数组的地址,数组起始位置下标数组最后一个位置的下标(不是数组的大小注意了)),不然就会发生越界的可能。
sizeof(arr) / sizeof(int) - 1表示数组最后一个下标的位置,
sizeof(arr)表示数组所占空间的大小,单位字节
sizeof(int) - 1表示数组元素类型所占空间的大小,单位字节
左右指针,快速排序,降序
方式原理是一样的,只是把 大于key 的数值放到左边,小于 key的数值放到右边。
我们只需要改变一下 Left 找小于的 key 的数值,Right 找大于 key 的数值,就可以了
具体代码实现如下:
// 交换数值
void swap(int* p1, int* p2)
{
int tmp = *p1;
*p1 = *p2;
*p2 = tmp;
}
//快速排序 左右指针,降序
void quickSortLeftRightDesc(int* arr, int begin, int end)
{
if (begin >= end) // 递归结束条件: 只有一个数值或该数组不存在,递归结束,返回
{
return;
}
int left = begin;
int right = end;
int keyi = left; // 分界值,下标
while (left < right)
{
// key 分界值是在左边,右边先走,降序找大于 key 的数值下标
while (left < right && arr[right] <= arr[keyi])
{
right--;
}
// 左边走,找小于 key 的数值下标
while (left < right && arr[left] >= arr[keyi])
{
left++;
}
// 跳出循环,left 和 right 都找到了对应的数值下标位置
swap(&arr[left], &arr[right]); // 交换
}
// 跳出循环,left 与 right 相遇了
int meet = left; //相遇点,保留
swap(&arr[meet], &arr[keyi]); // key数值与相遇点交换数值
// [begin, meet-1] meet [meet +1, end] meet 排序好了下标位置,不要动了
quickSortLeftRightDesc(arr, begin, meet - 1); // 左区间,递归排序
quickSortLeftRightDesc(arr, meet + 1, end); // 右区间,递归排序
}

前后指针,快速排序,升序
前后指针的基本思想,这里以升序为例
- 从待排序元素序列中的某个元素作为
基准值(一般是序列中的第一个元素或者是最后一个元素) ,将该基准值存放到key中,以它key作为分界值 - 定义两个指针,
prev指向数组的起始位置下标为0的位置作为前指针 ,以及cur指向prev +1后一个下标位置作为后指针 cur一直向前走,当cur下标对应的数值 小于key分界值时,则prev++向后移动一位,同时将该prev下标的数值 与cur下标的数值交换,同时cur++继续走,如果cur下标的数值大于key分界值,cur++继续走- 按照上述方式执行下去,直到
cur达到数组的最后位置,此时,将key数值和prev下标的数值交换。 - 这样就实现了,把全部小于
key的数值放到了key的左边,全部大于key的数值放到了key的右边。此时的key也是排序到了,它正确的位置中去了。 - 最后,同样分而治之,将
key左序列 和 右序列 的数据进行上述方式的 单趟排序 ,如此反复递归操作下入,当左右序列都有序了,整体也就有序了,递归结束条件:左右序列只有一个数据,或者左右序列不存在时,该部分数据就已经排序好,有序了,停止递归,开始返回了
具体操作动图如下:
静态操作图如下:
- 首先我们需要一个无序的数组如下:
首元素作为 key 分界值,将下标为 0 的位置作为 prev(前指针), 将 prev +1 作为 cur(后指针)
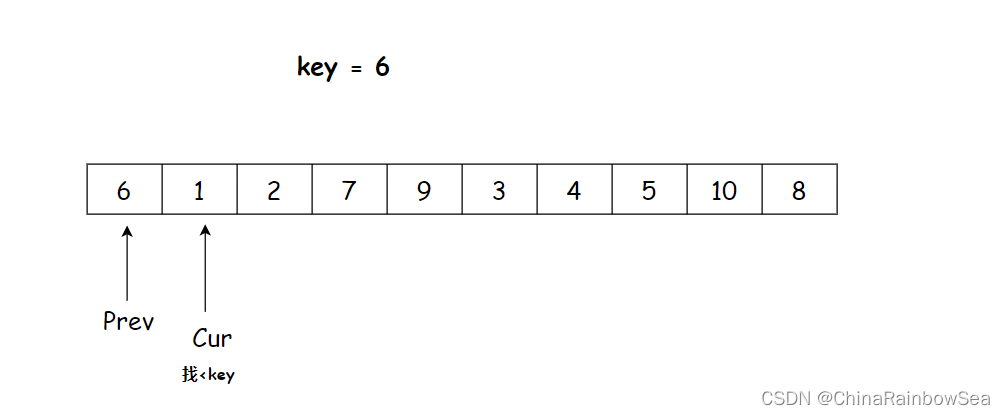
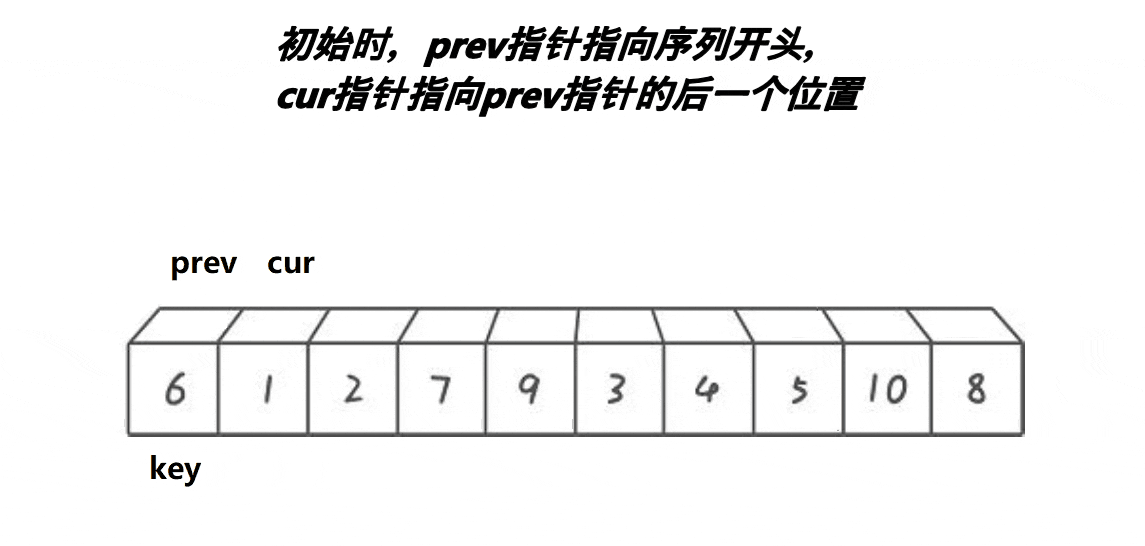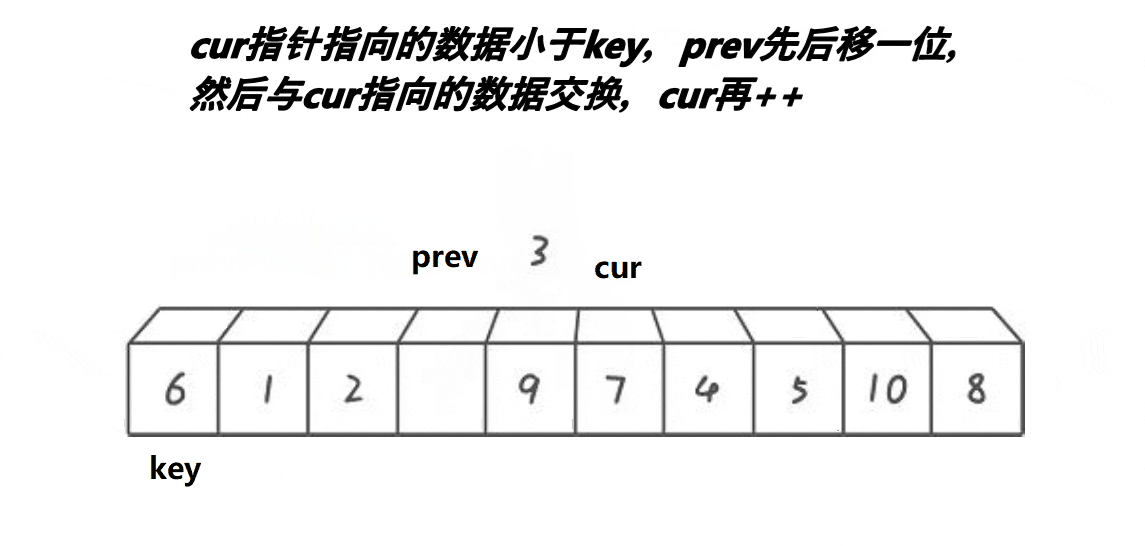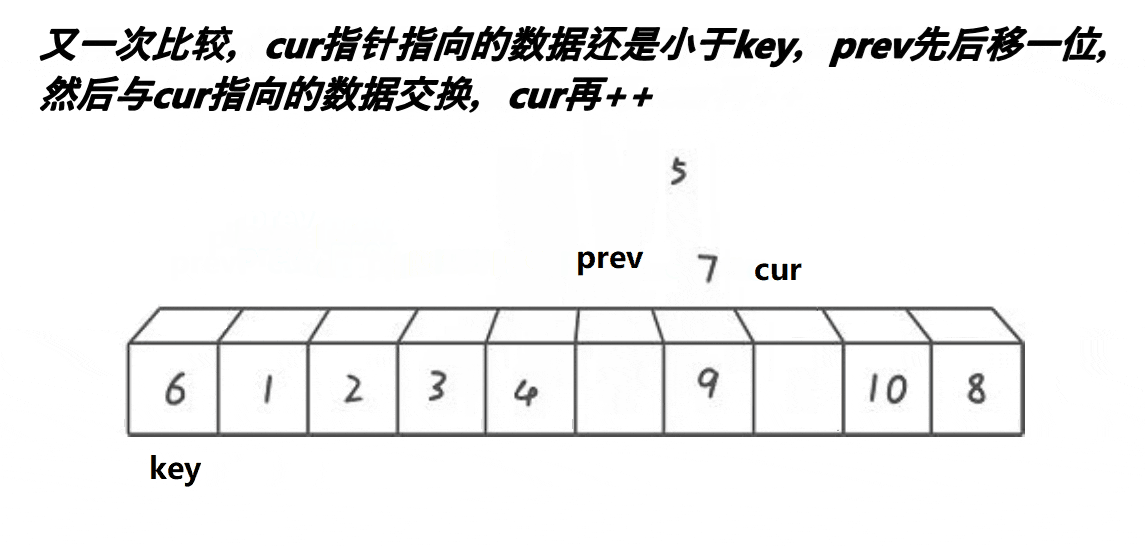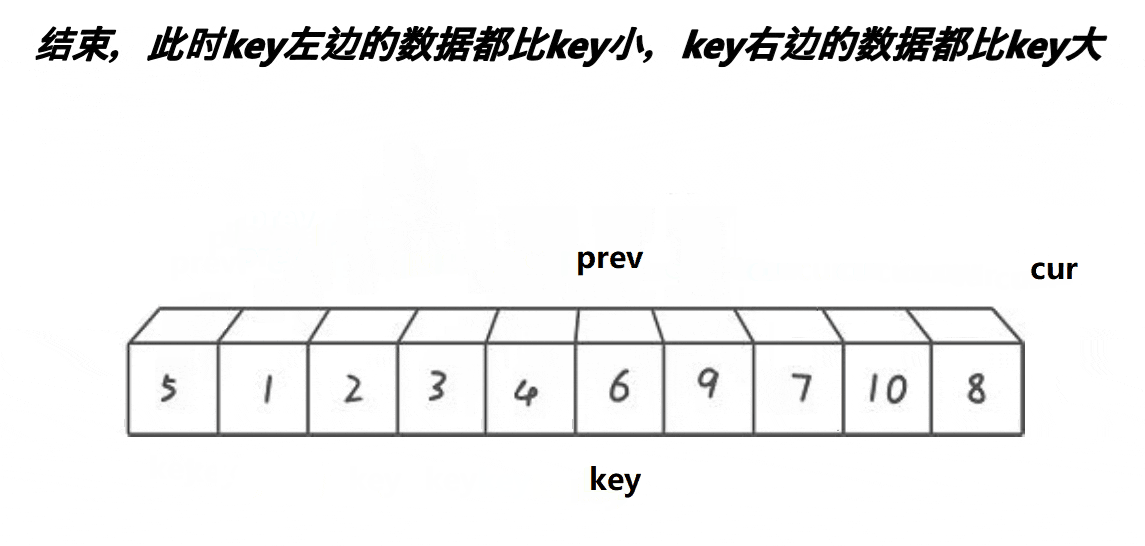
cur++找小于key的数值,交换
cur 找到 1 比 key 小,与 prev++ 后,arr[prev] 与 arr[cur] 交换数值,就是自己和自己交换
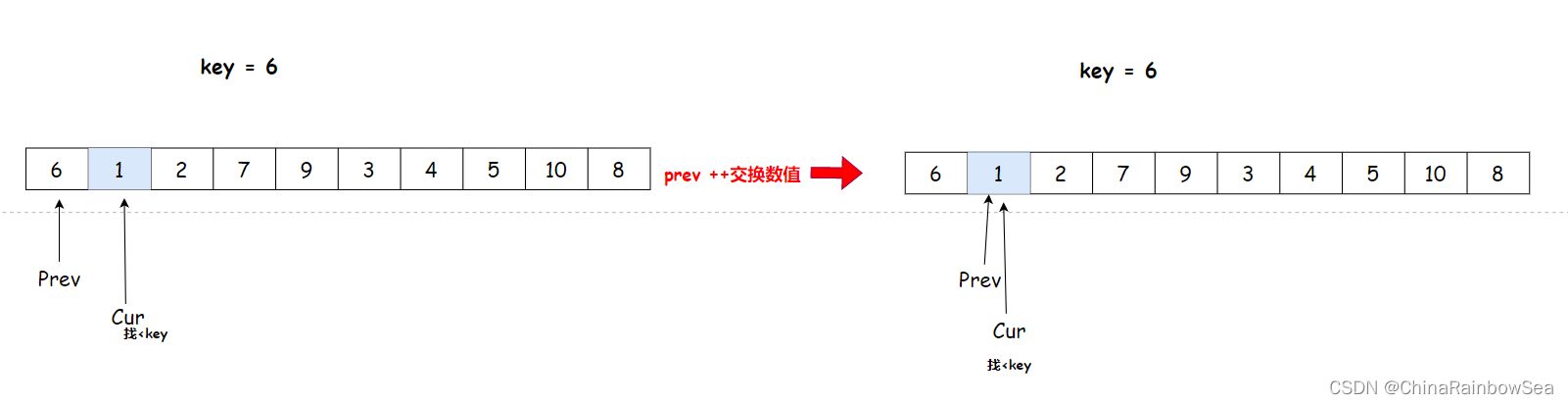
cur++找小于key的数值,交换
cur 找到 2 比 key 小,与 prev++ 后,arr[prev] 与 arr[cur] 交换数值,就是自己和自己交换
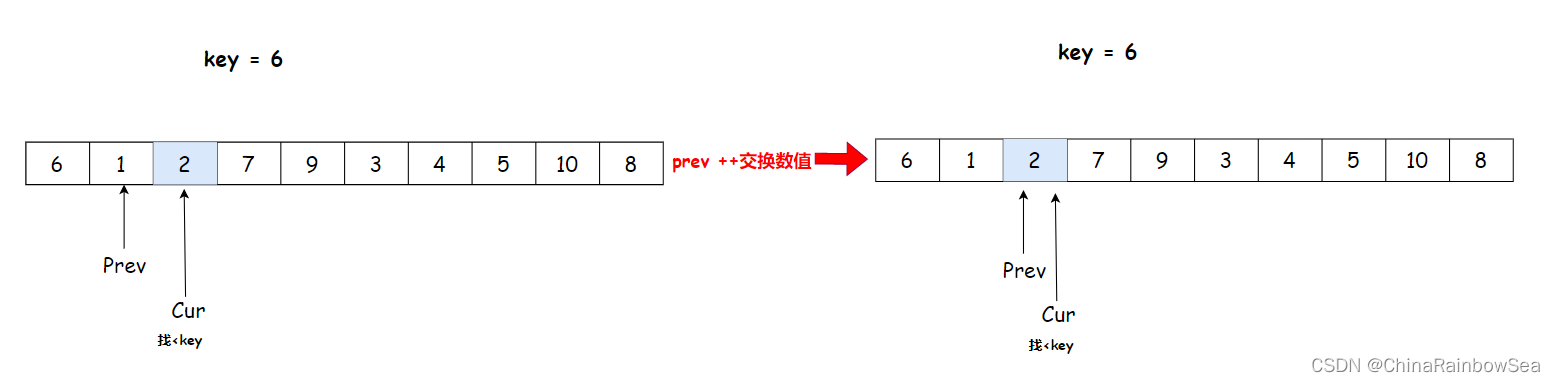
cur++找小于key的数值,交换,cur下标数值大于key的数值,不交换,继续cur++,但是prev不动
cur 找到 3 比 key 6 小,与 prev++ 后,arr[prev] 与 arr[cur] 交换数值
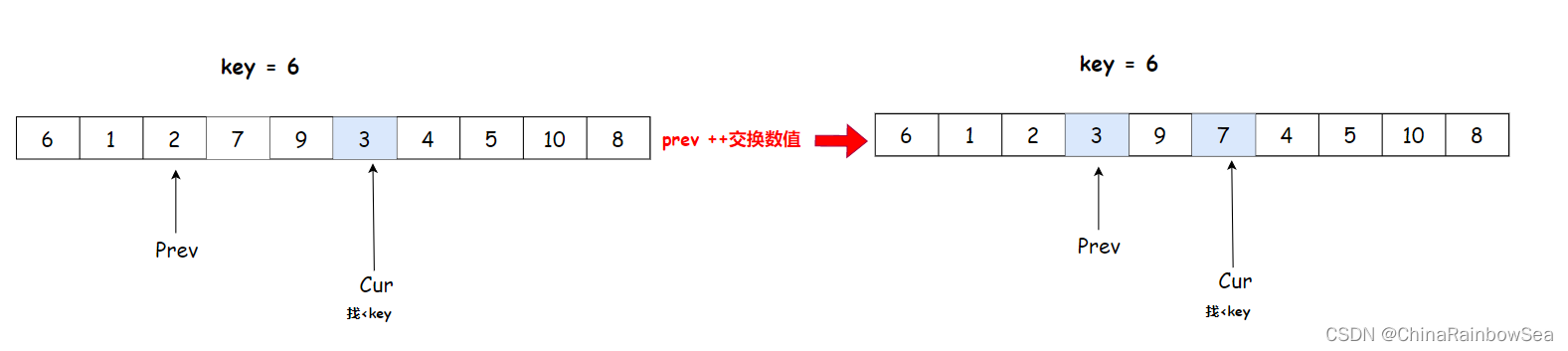
cur++找小于key的数值,交换,cur下标数值大于key的数值,不交换,继续cur++,但是prev不动
cur 找到 4 比 key 6 小,与 prev++ 后,arr[prev] 与 arr[cur] 交换数值
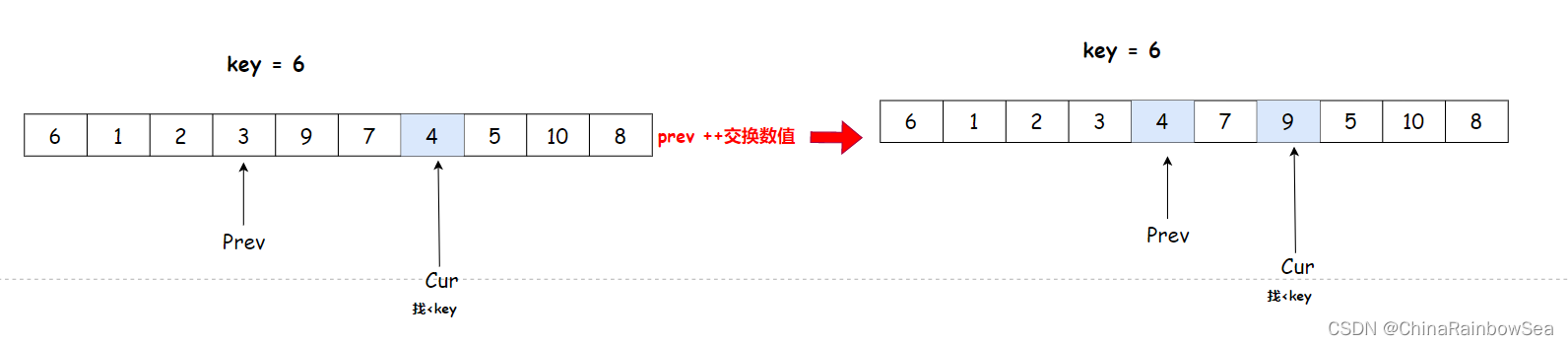
cur++找小于key的数值,交换,cur下标数值大于key的数值,不交换,继续cur++,但是prev不动
cur 找到 5 比 key 6 小,与 prev++ 后,arr[prev] 与 arr[cur] 交换数值
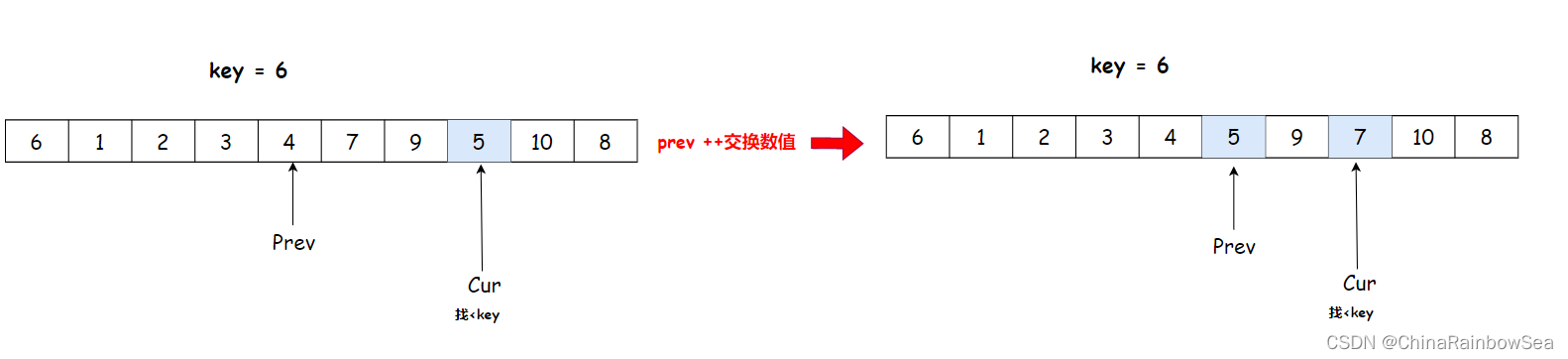
- 一直
cur++下去,直到cur达到数组最后一个下标位置,停止,此时将key的数值,与prev下标的数值交换
key 6 与 prev 下标的数值交换,prev 不用 ++
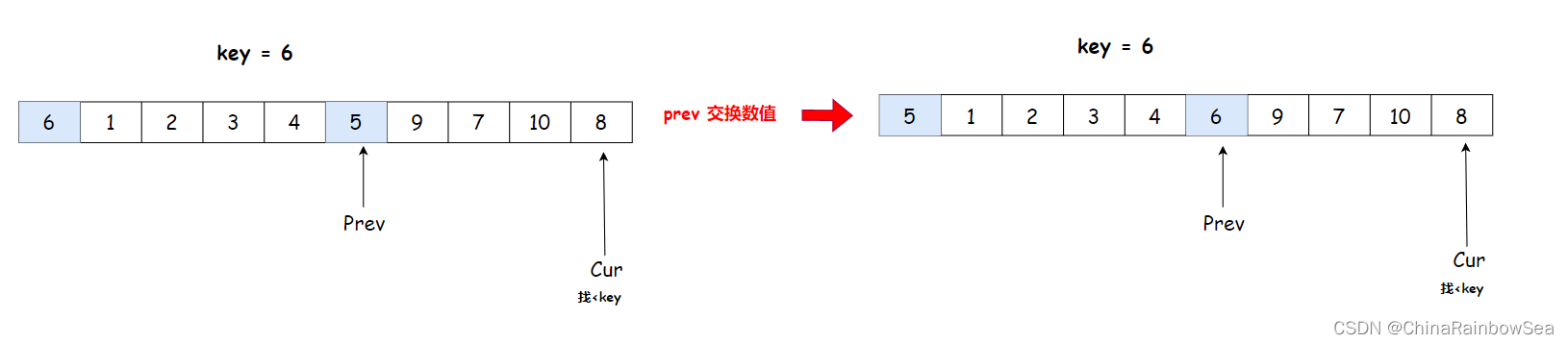
- 单趟排序完,比
key数值小的全部在 左边,比key数值大的全部在右边,key排序好了,不要动了
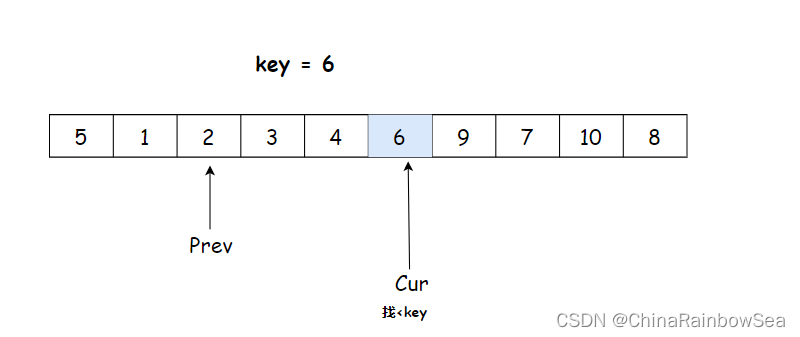
- 后面,再通过分而治之,递归的上述同样的方式,将
key左右序列,排序成有序,整体就有序了,
递归结束条件为 ,当 左右序列只有一个数据时或者序列不存在,则说明该部分已经有序了,不用在排序了,返回。
具体代码实现如下,升序
// 交换数值
void swap(int* p1, int* p2)
{
int tmp = *p1;
*p1 = *p2;
*p2 = tmp;
}
// 前后指针,快速排序,升序
void quickSortPrevCurAsc(int* arr, int begin, int end)
{
if (begin >= end) // 递归结束条件:左右序列只有一个数值(begin == end),左右序列不存在,begin > end
{
return;
}
int prev = begin; // 后指针下标
int cur = prev + 1; // 前指针下标
int keyi = begin; // 分界值,下标保留
while (cur <= end) // 防止越界
{
// 当 cur 下标数值小于 key 关键值,与 prev++ 后的下标值,交换
if (arr[cur] < arr[keyi])
{
prev++;
swap(&arr[prev], &arr[cur]);
}
cur++; // >< = cur 前指针都要继续走,
}
// cur 达到数组最后位置,key 关键值 与 prev 下标的数值交换
swap(&arr[prev], &arr[keyi]);
// [begin, prev-1] prev [prev+1, end] prev 已经排序好了,不要动了
quickSortPrevCurAsc(arr, begin, prev - 1); // 左区间,递归排序
quickSortPrevCurAsc(arr, prev + 1, end); // 右区间,递归排序
}

上述代码解析及其注意事项
默认数组中的第一个 0 下标位置作为,
key分界数值,它存在一定的缺陷,具体的大家可以,往下看 三数取中 的内容上有说明
while (cur <= end),循环条件,=因为传的参数中end是数组最后一个下标位置,防止越界递归结束条件:
if (begin >= end)当
begin = end就是表示,该部分的左右序列中只剩下一个数据(就是它们相等的数值)了,一个数据自然就是有序的了,因为一个数值还需要比较排序吗,递归结束返回,当
begin > end该序列情况是不存在的,左边的下标位置怎么可以大于右边的下标位置,递归结束,返回
交换传地址,形参的改变想要影响实参就需要传地址
cur++无论是arr[cur] > < = key 分界值都要继续cur向后移动找,小于key的数值当
cur到达数组的最后位置的时候,prev不用++了,其下标数值和keyi下标 数值交换
[begin, prev-1] prev [prev+1, end]prev 已经排序好了,不要动了
quickSortPrevCurAsc(arr, begin, prev - 1);左区间,递归排序,
[begin, prev-1]:表示的是左区间的范围,begin表示数组的起始位置下标,
prev-1表示排序好数值前一个下标
quickSortPrevCurAsc(arr, prev + 1, end)右区间,递归排序,
[prev+1, end]表示右区间,递归排序,prev+1表示排序好的数值的后一个下标
end:表示数组最后一个数值的下标位置。
前后指针,快速排序,降序
方式原理是一样的,只是把 大于key 的数值放到左边,小于 key的数值放到右边。
我们只需要改变一下 把其中的if (arr[cur] < arr[keyi]) 改为 if (arr[cur] > arr[keyi]) 就可以了
具体代码实现如下:
// 前后指针,降序
void quickSortPrevCurDesc(int* arr, int begin, int end)
{
if (begin >= end) // 递归结束条件: 左右序列只有一个数值,或数值不存在,
{
return;
}
int prev = begin;
int cur = prev + 1;
int keyi = prev;
while (cur <= end)
{
// 降序 cur 大于 key 分界值,交换数值
if (arr[cur] >= arr[keyi])
{
prev++;
swap(&arr[prev], &arr[cur]);
}
cur++;
}
// 跳出循环,到达数组最后一个下标位置.
swap(&arr[prev], &arr[keyi]); // 交换
//[begin, prev-1] prev [prev+1, end]
quickSortPrevCurDesc(arr, begin, prev - 1); // 左区间,递归排序
quickSortLeftRightDesc(arr, prev + 1, end); // 右区间,递归排序
}

优化
上述所将的快速排序还是又不少可以改进的地方,我们来看看一些优化的方案吧
这里我介绍两种优化方案:
- 三数取中
- 小区间优化,消除递归
三数取中
如果我们选取的 key 的数值就是处于整个序列中的中间位置的话,那么我们就可以将整个序列分成 小数集合 和 大数集合 了,但是注意了,我刚才说的是 如果…是中间的 ,那么假如我们选的不是 中间的数值 ,而是最大的或最小的数值呢,结果又是如何。如下图所示在有序的情况下,选取数组下标为 0 的作为 key 分界值:第一趟的时间复杂度是 O(n)
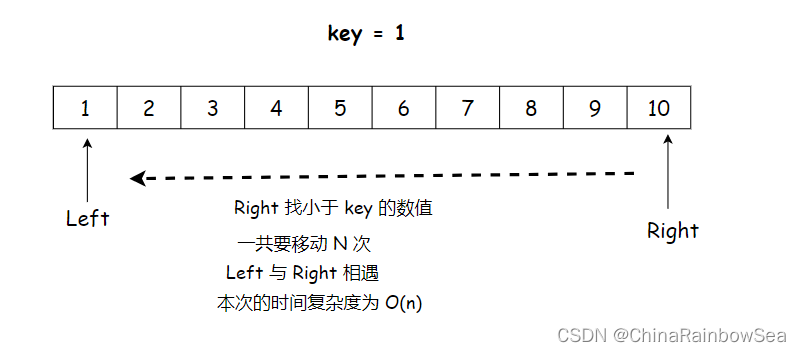
第二趟,时间复杂度为 O(n-1)
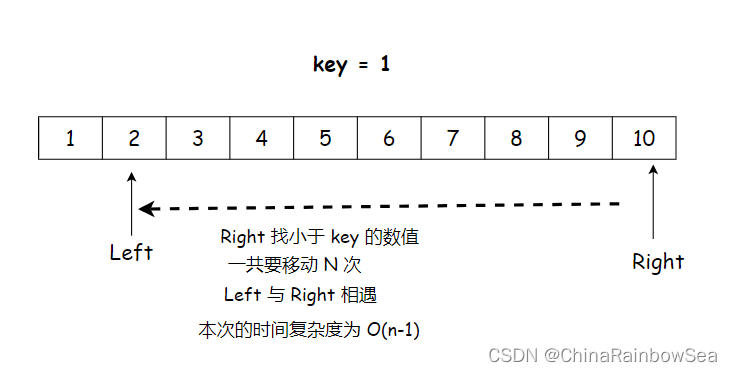
依次类推,第三趟为 O(n - 2), 第四趟为 O(n-3) ,这样的话快速排序时间复杂度为 O(N*N) ,变得不再快速了,
也就是说,在最优的情况下(key 为中间数值)的时间复杂度为O(nlogn) ,
在最坏的情况下,待排序的序列为正序或者是逆序 ,key 值选取的是 最大值 或者是 最小值 ,每次划分只得到一个比上次划分少一个记录的子序列。此时需要执行 n-1 次递归调用,且第i 次划分需要经过 n-i 次分界值key 的比较才能找到第 i 个记录,也就是中枢(分界)的位置,最终的时间复杂度为 O(n*n)
这是快速排序的一大缺陷,但是这个缺陷,并非无法,弥补。
通过上述的分析,我们可以知道 key 分界值的取值会对快速排序的效率,影响十分巨大,
如当 key 选取的数值是 中间值或者靠近中间值 ,时间复杂度为O(nlogn) ,当key 选取的数值是 最大值或者是最小值 ,时间复杂度为O(n*n)
所以我们可以通过改变 key 的取值,提高效率,不求 key 的取值是 中间值 ,这要靠近中间值,或者是,远离最大值和最小值就可以大大提高不小的效率。
三数取中 :三数 分别是:序列中最后面的数,最前面的数,和中间位置的数。
三数取中 就是取这 三数 当中数值大小居中的,那个数作为该 趟排序中的 key 分界值,这就可以确保,我们所选取的数值,不会是序列中的最大值或者是最小值了。大大提高的快速排序的效率。

具体代码实现如下:
通过不断的比较判断找到中间大小的数值。找到返回该数值的下标位置。
// 三数取中
int getMidIndex(int* arr, int left, int right)
{
int mid = (left + right) >> 1; // >> 向右移动 /2
if (arr[left] < arr[mid])
{
if (arr[mid] < arr[right])
{ // arr[left] < arr[mid] < arr[right]
return mid; // 中间值的下标位置
}
else if (arr[right] < arr[left])
{ // arr[right] < arr[left] < arr[mid]
return left;
}
else // arr[right] > arr[left], arr[mid] > arr[right]
{ // arr[left] < arr[right] < arr[mid]
return right;
}
}
else // arr[left] > arr[mid]
{
if (arr[mid] > arr[right])
{ // arr[left] > arr[mid] > arr[right]
return mid;
}
else if (arr[right] > arr[left])
{ // arr[right] > arr[left] > arr[mid]
return left;
}
else // arr[left] > arr[right], arr[right] > arr[mid]
{ // arr[left] > arr[right] > arr[mid]
return right;
}
}
}
int main()
{
int arr[] = { 6,1,2,7,9,3,4,5,10,8 };
playPrint(arr, sizeof(arr) / sizeof(int));
printf("%d\n", getMidIndex(arr, 0, sizeof(arr) / sizeof(int) - 1));
}
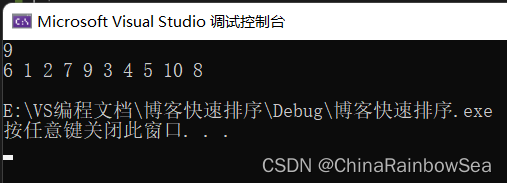
0 + 9 / 2 = 4 , arr[4] = 9 , arr[0] = 6 ,arr[9] = 8; arr[0] < arr[9] < arr[4]
是下标为 9 的数值在这个三数中具中
我们将其添加到,快速排序中去:思想:
我们原先的代码快速排序中,key 默认是取序列中下标为 0 的数值,我们只需要将我们找到三数取中 的数值,与下标为 0 的数值交换一下,就可以了,这样我们key 默认是取序列中下标为 0 的数值就是取(三数取中的数值),后面的代码也就无序改变了。
具体代码实现如下,以升序为例:
// 交换数值
void swap(int* p1, int* p2)
{
int tmp = *p1;
*p1 = *p2;
*p2 = tmp;
}
// 三数取中
int getMidIndex(int* arr, int left, int right)
{
int mid = (left + right) >> 1; // >> 向右移动 /2
if (arr[left] < arr[mid])
{
if (arr[mid] < arr[right])
{ // arr[left] < arr[mid] < arr[right]
return mid; // 中间值的下标位置
}
else if (arr[right] < arr[left])
{ // arr[right] < arr[left] < arr[mid]
return left;
}
else // arr[right] > arr[left], arr[mid] > arr[right]
{ // arr[left] < arr[right] < arr[mid]
return right;
}
}
else // arr[left] > arr[mid]
{
if (arr[mid] > arr[right])
{ // arr[left] > arr[mid] > arr[right]
return mid;
}
else if (arr[right] > arr[left])
{ // arr[right] > arr[left] > arr[mid]
return left;
}
else // arr[left] > arr[right], arr[right] > arr[mid]
{ // arr[left] > arr[right] > arr[mid]
return right;
}
}
}
// 经过了三数取中的优化
void quickSort(int* arr, int begin, int end)
{
if (begin >= end) // 当左右序列只有一个数值或 begin > end 不存在序列时,
{ // 该部分数据已经有序了,不用在递归排序下去
return;
}
int index = getMidIndex(arr, begin, end); // 三数取中的数值下标位置,
swap(&arr[index], &arr[begin]); // 三数取中的数值 与下标为0 的数值交换一下
int left = begin;
int right = end;
int pivot = left; // 默认坑位是,数组中下标 0 的位置
int key = arr[pivot]; // 分界值
while (left < right) // 相遇跳出
{
// 坑位,在左边,先从右边开始找小于 key 的数值下标
while (left < right && arr[right] >= key) // left < right防止在该内部循环就已经相遇了,退出循环
{ // >= 需要 = ,如果 没有 等于 当 arr[right] == key,不会执行 right --
right--; // 而是停留在 等于的位置,left 与 right 就不会相遇了,死循环
}
// 跳出循环,找到了小于 key 的数值的下标位置
arr[pivot] = arr[right]; // 填入坑位中,
pivot = right; // 自己成为新的坑位
// 左边找,大于 key 的数值下标
while (left < right && arr[left] <= key) // left < right 和上面同理
{ // <= 和上面同理
left++;
}
// 跳出循环,找到了大于 key 的数值下标位置
arr[pivot] = arr[left]; // 填入坑位
pivot = left; // 自己成为新的坑位
}
// 跳出循环,相遇了
pivot = left; // 相遇点作为新的坑位, left 和 right 是相等的
arr[pivot] = key; // 将 key 填入到,相遇点坑位中,排序好,
// [begin, pivot-1] pivot [pivot +1 , end] pivot 下标位置的数值,排序好了,不要动
quickSortAsc(arr, begin, pivot - 1); // 左区间,递归排序
quickSortAsc(arr, pivot + 1, end); // 右区间,递归排序
}

小区间优化,消除递归
我们可以看到,就算是上面理想状态下的快速排序,也不能避免随着递归的深入,每一层的递归次数会以 2 倍的形式快速增长。
为了减少递归树的最后几层递归,我们可以设置一个判断语句,当序列的长度小于某个数的时候,就不再进行快速排序了,转而使用其他的种类的排序(这里我们使用插入排序)。关于插入排序的内容大家可以移动到🔜🔜🔜 图文并茂 —— 插入排序,希尔排序_ChinaRainbowSea的博客-CSDN博客小区间优化若是使用得当的话,会在一定程度上加快,快速排序的效率,而且待排序的长度越长,该效果越明显。
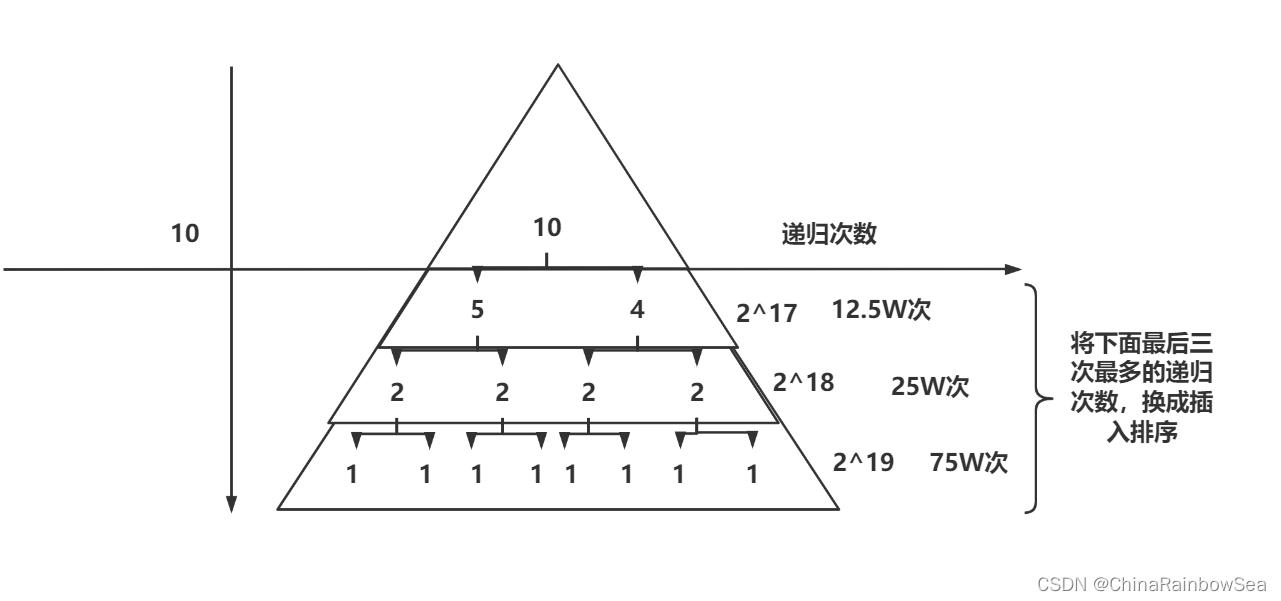
区间范围内的数值量多时:继续使用递归的方式,快速排序
当区间范围内的数值量少时:使用插入排序,将剩下的数值排序好。
具体代码实现如下:
// 交换数值
void swap(int* p1, int* p2)
{
int tmp = *p1;
*p1 = *p2;
*p2 = tmp;
}
// 插入排序,升序
void insertSort(int* arr, int n)
{
for (int i = 0; i < n - 1; i++)
{
int end = i;
int tmp = arr[end + 1];
while (end >= 0)
{
if(tmp < arr[end])
{
arr[end + 1] = arr[end]; // 后移动,覆盖
end--;
}
else
{
break;
}
}
arr[end + 1] = tmp;
}
}
// 经过了三数取中 和 小区间的优化
void quickSort(int* arr, int begin, int end)
{
if (begin >= end) // 当左右序列只有一个数值或 begin > end 不存在序列时,
{ // 该部分数据已经有序了,不用在递归排序下去
return;
}
int index = getMidIndex(arr, begin, end); // 三数取中的数值下标位置,
swap(&arr[index], &arr[begin]); // 三数取中的数值 与下标为0 的数值交换一下
int left = begin;
int right = end;
int pivot = left; // 默认坑位是,数组中下标 0 的位置
int key = arr[pivot]; // 分界值
while (left < right) // 相遇跳出
{
// 坑位,在左边,先从右边开始找小于 key 的数值下标
while (left < right && arr[right] >= key) // left < right防止在该内部循环就已经相遇了,退出循环
{ // >= 需要 = ,如果 没有 等于 当 arr[right] == key,不会执行 right --
right--; // 而是停留在 等于的位置,left 与 right 就不会相遇了,死循环
}
// 跳出循环,找到了小于 key 的数值的下标位置
arr[pivot] = arr[right]; // 填入坑位中,
pivot = right; // 自己成为新的坑位
// 左边找,大于 key 的数值下标
while (left < right && arr[left] <= key) // left < right 和上面同理
{ // <= 和上面同理
left++;
}
// 跳出循环,找到了大于 key 的数值下标位置
arr[pivot] = arr[left]; // 填入坑位
pivot = left; // 自己成为新的坑位
}
// 跳出循环,相遇了
pivot = left; // 相遇点作为新的坑位, left 和 right 是相等的
arr[pivot] = key; // 将 key 填入到,相遇点坑位中,排序好,
// [begin, pivot-1] pivot [pivot +1 , end] pivot 下标位置的数值,排序好了,不要动
/*
quickSortAsc(arr, begin, pivot - 1); // 左区间,递归排序
quickSortAsc(arr, pivot + 1, end); // 右区间,递归排序
修改为 小区间优化
*/
// 小区间优化,清除递归,换用插入排序
if (pivot - 1 - begin > 10) // 如果左区间的数值量 大于 10 继续使用递归排序
{
quickSort(arr, begin, pivot - 1); // 左区间递归排序
}
else // 如果左区间上的数值量 小于 10 则使用插入排序,将剩下的数值排序好
{
insertSort(arr + begin, pivot - 1 - begin + 1); // 左区间,插入排序
}
if (end - (pivot + 1) > 10) // 如果右区间上的数值量 大于 10 继续使用递归 排序
{
quickSort(arr, pivot + 1, end); // 右区间递归排序
}
else // 如果右区间上的数值量 小于 10 ,则使用插入排序,将剩下的数值排序好
{
insertSort(arr + (pivot + 1), end - (pivot + 1) + 1); // 右区间,插入排序
}
}

上述代码解析及其注意事项
- 小区间优化:
[begin, pivot-1] pivot [pivot +1 , end] pivot 下标位置的数值,排序好了,不要动, ``[begin, pivot-1]
表示左区间;[prev+1, end]` 表示右区间,。
if (pivot - 1 - begin > 10): 表示左区间的数值量是否大于 10
insertSort(arr + begin, pivot - 1 - begin + 1);表示插入排序
arr + begin表示:插入排序的起始位置,注意是需要+begin的因为前面的是排序好了的,不要再排序,浪费时间了。
pivot - 1 - begin + 1表示的是左区间数组的大小,不是最后一个下标位置,pivot - 1 - begin联系这里的第2 段话,这里表示的是左区间的范围,不是数组的大小,需要多+ 1,就像[0~9]数组一共有9-0+1 = 10个数值因为插入排序的参数是
insertSort(数组地址,数组的大小)
if (end - (pivot + 1) > 10):表示右区间的数值量是否大于 10
insertSort(arr + (pivot + 1), end - (pivot + 1) + 1)表示:插入排序
arr+(pivot + 1)表示:插入排序的起始位置,注意是需要+(pivot + 1)的,因为前面的是排序好了的,就不要动了
end - (pivot + 1) + 1)表示的是右区间数组的大小,不是最后一个下标位置,end - (pivot + 1)联系这里的第2 段话 表示的是右区间的范围,不是数组的大小,需要多
+ 1,就像
[0~9]数组一共有9-0+1 = 10个数值 因为插入排序的参数是insertSort(数组地址,数组的大小)
非递归实现,快速排序
递归深度太深,程序是没错的,但是栈的空间不够用
递归的缺陷:栈帧深度太深,栈空间不够用,可能会溢出。
递归改非递归的方式有两种:
- 直接改循环,如(斐波那契额数列)
- 借助自己或库中的栈,模拟递归的过程,入栈出栈
这里我们使用的方式是:第二种:自己创建栈,模拟递归的过程,入栈出栈。
快速排序非递归实现的基本思想:
- 我们需要自己创建一个
栈,大家可以移步到🔜🔜🔜 图文并茂 ,栈的实现 —— C语言_ChinaRainbowSea的博客-CSDN博客 将其中 栈 的实现的代码复制过来。 - 先将数组最后一个元素的下标入栈,其次是数组中的第一个元素的下标入栈,因为先前的后出来
- 取栈顶元素,读取栈中的数据信息(数组下标),(依次读取一个左边
L的下标,右边R的下标),获得该下标后,调用某一个版本的(挖坑法,左右指针法,前后指针) 的单趟排序,这里我们使用挖坑法 - 排序完后,获得排序好的
key数值下标位置,不要动了,因为已经排序好了。然后在判断key左序列和右序列是否还存在没有排序好的数值,如果还有将对应的序列下标入栈,如果没有需要排序(只有一个元素或者是不存在这里的序列) ,就不需要将该序列的信息下标入栈了。 - 反复执行上述
3,4序号的步骤,直到栈为空为止。
快速排序非递归实现,升序代码
// 交换数值
void swap(int* p1, int* p2)
{
int tmp = *p1;
*p1 = *p2;
*p2 = tmp;
}
// 三数取中
int getMidIndex(int* arr, int left, int right)
{
int mid = (left + right) >> 1; // >> 向右移动 /2
if (arr[left] < arr[mid])
{
if (arr[mid] < arr[right])
{ // arr[left] < arr[mid] < arr[right]
return mid; // 中间值的下标位置
}
else if (arr[right] < arr[left])
{ // arr[right] < arr[left] < arr[mid]
return left;
}
else // arr[right] > arr[left], arr[mid] > arr[right]
{ // arr[left] < arr[right] < arr[mid]
return right;
}
}
else // arr[left] > arr[mid]
{
if (arr[mid] > arr[right])
{ // arr[left] > arr[mid] > arr[right]
return mid;
}
else if (arr[right] > arr[left])
{ // arr[right] > arr[left] > arr[mid]
return left;
}
else // arr[left] > arr[right], arr[right] > arr[mid]
{ // arr[left] > arr[right] > arr[mid]
return right;
}
}
}
// 求单趟排序好的数值下标位置,挖坑法
int parSort(int* arr, int begin, int end)
{
int index = getMidIndex(arr, begin, end); // 三数取中的数值下标位置,
swap(&arr[index], &arr[begin]); // 三数取中的数值 与下标为0 的数值交换一下
int left = begin;
int right = end;
int pivot = left; // 默认坑位是,数组中下标 0 的位置
int key = arr[pivot]; // 分界值
while (left < right) // 相遇跳出
{
// 坑位,在左边,先从右边开始找小于 key 的数值下标
while (left < right && arr[right] >= key) // left < right防止在该内部循环就已经相遇了,退出循环
{ // >= 需要 = ,如果 没有 等于 当 arr[right] == key,不会执行 right --
right--; // 而是停留在 等于的位置,left 与 right 就不会相遇了,死循环
}
// 跳出循环,找到了小于 key 的数值的下标位置
arr[pivot] = arr[right]; // 填入坑位中,
pivot = right; // 自己成为新的坑位
// 左边找,大于 key 的数值下标
while (left < right && arr[left] <= key) // left < right 和上面同理
{ // <= 和上面同理
left++;
}
// 跳出循环,找到了大于 key 的数值下标位置
arr[pivot] = arr[left]; // 填入坑位
pivot = left; // 自己成为新的坑位
}
// 跳出循环,相遇了
pivot = left; // 相遇点作为新的坑位, left 和 right 是相等的
arr[pivot] = key; // 将 key 填入到,相遇点坑位中,排序好,
// [begin, pivot-1] pivot [pivot+1, end]
return pivot; // 返回排序好的数值下标位置。
}
// 快速排序,非递归实现
void quickSortNonR(int* arr, int n)
{
ST st; // 定义栈
StackInit(&st); // 初始化栈
StackPush(&st, n - 1); // 右边最后一个数值下标入栈
StackPush(&st, 0); // 左边数组 0 下标入栈
while (!StackEmpty(&st)) // 栈不为空
{
int left = StackTop(&st); // 取栈顶元素
StackPop(&st); // 出栈
int right = StackTop(&st); // 取栈顶元素
StackPop(&st); // 出栈
int keyIndex = parSort(arr, left, right); // 单趟排序好的数值下标位置
// [left, keyIndex -1] keyIndex [keyIndex+1, right]
if (keyIndex + 1 < right) // 右区间还有数值没有排序好,继续出栈排序
{
StackPush(&st, right); // 右区间的右区间入栈
StackPush(&st, keyIndex + 1); // 右区间的左区间入栈
}
if (left < keyIndex - 1) // 左区间还有数值没有排序好,继续出栈排序
{
StackPush(&st, keyIndex - 1); // 左区间的右区间入栈
StackPush(&st, left); // 左区间中的左区间入栈
}
}
StackDestory(&st); // 销毁栈
}
上述代码解析及其注意事项:
StackInit(&st);初始化栈- 我们根据上面的
挖坑法知道,当 **若坑位最开始是在最左边,则需要 **R右边先走,从右向左先走),(若坑位是最开始在右边,则需要
L左边先走,从左向右先走 ,所以,先将数组中最后一个下标位置入栈,其次是数组起始 0 下标位置入栈。先进后出栈 的特点。
int left = StackTop(&st)取栈顶元素下标,就是左边L的下标位置,保存起来,因为:我们先入栈的是右边的数组最后一个下标位置,其次是 左边数组的起始位置下标。所以我们第一次取栈顶,取的就是
左边的下标位置。注意取了栈顶元素后,需要和出栈
StackPop(&st);配合不然你无法取到栈后面的数据的。
int right = StackTop(&st);同理取栈顶元素下标,这里就是右边R的下标位置了[left, keyIndex -1] keyIndex [keyIndex+1, right]if (keyIndex + 1 < right)右区间判断是否还有没有排序好的数值(如果只有一个数值keyIndex = right) 就不用排序了,或者keyIndex + 1 > right序列不存在 , 因为左边L的下标 怎么可以大于R右边的下标呢是不存在的。如果存在
keyIndex +1 < right右区间还有没有排序好的数值下标,左右区间入栈,继续单趟(挖坑法)排序
StackPush(&st, right);右区间的右区间入栈,StackPush(&st, keyIndex + 1)右区间的左区间入栈。
- 同理
if (left < keyIndex - 1)左区间判断是否还有没有排序好的数值。- 最后不要忘记了,需要销毁栈
StackDestory(&st);,释放空间。
性能测试
利用排序前后的时间差,来计算出排序的效率
这里我们比较 非递归实现 和 递归实现 的快速排序的效率
// 性能测试
void testTop()
{
srand(time(0));
const int N = 1000000; // 100W
// 动态(堆区)上开辟空间
int* arr1 = (int*)malloc(sizeof(int) * N);
int* arr2 = (int*)malloc(sizeof(int) * N);
if (NULL == arr1 || NULL == arr2)
{
perror("malloc error"); // 错误提醒
exit(-1); // 非正常退出程序
}
for (int i = 0; i < N; i++)
{
arr1[i] = rand(); // 生成随机值
arr2[i] = arr1[i]; // 控制变量
}
int begin1 = clock(); // 递归快速排序开始前的时间点,单位 毫秒
quickSort(arr1, 0, N - 1); // 递归快速排序,升序
int end1 = clock(); // 递归快速排序结束后的时间点, 单位 毫秒
int begin2 = clock(); // 非递归快速排序开始前的时间点,单位 毫秒
quickSortNonR(arr2, N); // 非递归快速排序,升序
int end2 = clock(); // 非递归快速排序结束后的时间点, 单位 毫秒
/* 排序效率的计算
* 排序效率 = 排序结束后的时间 end - 排序开始前的时间 begin
*/
printf("递归快速排序: %d\n", end1 - begin1);
printf("非递归快速排序:%d\n", end2 - begin2);
}

快速排序,总结
- 快速排序中的单趟排序
挖坑法,左右指针法,需要 注意当key分界值在左边时,右边先走,从右往左,当key分界值在右边时,左边先走,从左往右,不然无法实现分界 - 无论是那种方式的单趟排序
挖坑法,左右指针法,前后指针法其目的都是一样的,将序列 以key分界值,对序列进行一个 分组划分,如升序:小于key的全部在 key 的左边,大于key的全部在 key 的右边。 - 多种单趟排序的方式
挖坑法,左右指针法,前后指针法是因为有些OJ题的不同的单趟排序方式,排序到的数值顺序是不同的,有时其中的某种方式,无法跑过。 - 对于 快速排序中存在的优化方案,主要掌握
三数取中的方式,因为key的取值关系的影响,有序序列(顺序,逆序)当key为最大值或最小值 时。时间复杂度为O(n*n),通过三数取中的方式,让key接近于序列中的 中间值 ,或者远离 序列中的最大值或最小值 ,提高排序效率 - 注意数组访问的范围,防止数组的越界,导致错误
快速排序,完整代码实现
下面是,有关快速排序的完整内容的代码实现。除了栈的 非递归实现快速排序的那一块内容,大家需要从这里 🔜🔜 🔜 图文并茂 ,栈的实现 —— C语言_ChinaRainbowSea的博客-CSDN博客 复制代码以外,其中所有的代码大家都可以直接 粘贴复制直接运行使用 大家可以运行体验看看
#define _CRT_SECURE_NO_WARNINGS 1
#include"Stack.h"
#include<time.h>
// 打印数组
void playPrint(int* arr, int n)
{
for (int i = 0; i < n; i++)
{
printf("%d ", arr[i]);
}
printf("\n");
}
// 交换数值
void swap(int* p1, int* p2)
{
int tmp = *p1;
*p1 = *p2;
*p2 = tmp;
}
// 插入排序,升序
void insertSort(int* arr, int n)
{
for (int i = 0; i < n - 1; i++)
{
int end = i;
int tmp = arr[end + 1];
while (end >= 0)
{
if(tmp < arr[end])
{
arr[end + 1] = arr[end]; // 后移动,覆盖
end--;
}
else
{
break;
}
}
arr[end + 1] = tmp;
}
}
// 三数取中
int getMidIndex(int* arr, int left, int right)
{
int mid = (left + right) >> 1; // >> 向右移动 /2
if (arr[left] < arr[mid])
{
if (arr[mid] < arr[right])
{ // arr[left] < arr[mid] < arr[right]
return mid; // 中间值的下标位置
}
else if (arr[right] < arr[left])
{ // arr[right] < arr[left] < arr[mid]
return left;
}
else // arr[right] > arr[left], arr[mid] > arr[right]
{ // arr[left] < arr[right] < arr[mid]
return right;
}
}
else // arr[left] > arr[mid]
{
if (arr[mid] > arr[right])
{ // arr[left] > arr[mid] > arr[right]
return mid;
}
else if (arr[right] > arr[left])
{ // arr[right] > arr[left] > arr[mid]
return left;
}
else // arr[left] > arr[right], arr[right] > arr[mid]
{ // arr[left] > arr[right] > arr[mid]
return right;
}
}
}
// 挖坑法,快速排序,升序
void quickSortAsc(int* arr, int begin, int end)
{
if (begin >= end) // 当左右序列只有一个数值或 begin > end 不存在序列时,
{ // 该部分数据已经有序了,不用在递归排序下去
return;
}
int left = begin;
int right = end;
int pivot = left; // 默认坑位是,数组中下标 0 的位置
int key = arr[pivot]; // 分界值
while (left < right) // 相遇跳出
{
// 坑位,在左边,先从右边开始找小于 key 的数值下标
while (left < right && arr[right] >= key) // left < right防止在该内部循环就已经相遇了,退出循环
{ // >= 需要 = ,如果 没有 等于 当 arr[right] == key,不会执行 right --
right--; // 而是停留在 等于的位置,left 与 right 就不会相遇了,死循环
}
// 跳出循环,找到了小于 key 的数值的下标位置
arr[pivot] = arr[right]; // 填入坑位中,
pivot = right; // 自己成为新的坑位
// 左边找,大于 key 的数值下标
while (left < right && arr[left] <= key) // left < right 和上面同理
{ // <= 和上面同理
left++;
}
// 跳出循环,找到了大于 key 的数值下标位置
arr[pivot] = arr[left]; // 填入坑位
pivot = left; // 自己成为新的坑位
}
// 跳出循环,相遇了
pivot = left; // 相遇点作为新的坑位, left 和 right 是相等的
arr[pivot] = key; // 将 key 填入到,相遇点坑位中,排序好,
// [begin, pivot-1] pivot [pivot +1 , end] pivot 下标位置的数值,排序好了,不要动
quickSortAsc(arr, begin, pivot - 1); // 左区间,递归排序
quickSortAsc(arr, pivot + 1, end); // 右区间,递归排序
}
// 挖坑法,快速排序,降序
void quickSortDesc(int* arr, int begin, int end)
{
if (begin >= end) // 左右使用一个数值或序列不存在,说明该部分数据已经有序了,返回
{
return;
}
int left = begin;
int right = end;
int pivot = left; // 默认数组 0下标坑位
int key = arr[pivot]; // 分界数值
while (left < right)
{
// 坑位在左边,右边坑位先走,找大于key 的数值下标
while (left < right && arr[right] <= key) // left < right / <= 和上面升序是一样的
{
right--;
}
// 跳出循环找到了
arr[pivot] = arr[right]; // 填入坑位
pivot = right; // 自己成为新的坑位
// 左边找小于 key 的数值下标
while (left < right && arr[left] >= key) // left < right / >= 原理一样
{
left++;
}
// 跳出循环找到了
arr[pivot] = arr[left]; // 填入坑位
pivot = left; // 自己成为坑位
}
// 相遇点成为新的坑位
pivot = left;
arr[pivot] = key; // key 填入坑位,排序好
// key 左右序列有序,递归,分而治之
// [begin, pivot -1] pivot [pivot+1, right] pivot 排序好了,不要动了
quickSortDesc(arr, begin, pivot - 1); // 左区间递归排序
quickSortDesc(arr, pivot + 1, right); // 右区间递归排序
}
// 左右指针法,快速排序,升序
void quickSortLeftRightAsc(int* arr, int begin, int end)
{
if (begin >= end) // 当左右序列只有一个数值时或序列不存在,表示该部分序列已经有序了,返回
{
return;
}
int left = begin;
int right = end;
int keyi = left; // 分界值下标,保存
while (left < right)
{
// 因为 keyi 分界值是在左边,所以右边right找 小于 keyi 分界值的数值下标 先走
while (left < right && arr[right] >= arr[keyi]) // left < right 防止在该内循环中,就已经相遇了,而没有跳出循环
{ // >= 需要 = ,如果没有 等于的话,当 arr[left]= arr[keyi] 的分界数值的时候,是不会执行left++
right--; // 导致left 停留在相等的下标位置,导致 left 与 right 无法相遇,而死循环
}
// 左边left找 大于 keyi 分界值的数值下标
while (left < right && arr[left] <= arr[keyi]) // left < right / <= 同理
{
left++;
}
// 走到这,表示: 左右都找到了,对应数值的下标位置,则交换,或者,相遇了(就是自己和自己交换)
swap(&arr[left], &arr[right]); // 交换
}
//相遇了, 跳出循环, 将 keyi 分界值的数值与相遇点交换
int meet = left; // 保留相遇点
swap(&arr[meet], &arr[keyi]); // 交换,keyi 的数值有序了
// [begin meet-1] meet [meet+1, end] meet 有序了不要动
quickSortLeftRightAsc(arr, begin, meet - 1); // 左区间,递归排序
quickSortLeftRightAsc(arr, meet + 1, end); // 右区间,递归排序
}
//快速排序 左右指针,降序
void quickSortLeftRightDesc(int* arr, int begin, int end)
{
if (begin >= end) // 递归结束条件: 只有一个数值或该数组不存在,递归结束,返回
{
return;
}
int left = begin;
int right = end;
int keyi = left; // 分界值,下标
while (left < right)
{
// key 分界值是在左边,右边先走,降序找大于 key 的数值下标
while (left < right && arr[right] <= arr[keyi])
{
right--;
}
// 左边走,找小于 key 的数值下标
while (left < right && arr[left] >= arr[keyi])
{
left++;
}
// 跳出循环,left 和 right 都找到了对应的数值下标位置
swap(&arr[left], &arr[right]); // 交换
}
// 跳出循环,left 与 right 相遇了
int meet = left; //相遇点,保留
swap(&arr[meet], &arr[keyi]); // key数值与相遇点交换数值
// [begin, meet-1] meet [meet +1, end] meet 排序好了下标位置,不要动了
quickSortLeftRightDesc(arr, begin, meet - 1); // 左区间,递归排序
quickSortLeftRightDesc(arr, meet + 1, end); // 右区间,递归排序
}
// 前后指针,快速排序,升序
void quickSortPrevCurAsc(int* arr, int begin, int end)
{
if (begin >= end) // 递归结束条件:左右序列只有一个数值(begin == end),左右序列不存在,begin > end
{
return;
}
int prev = begin; // 后指针下标
int cur = prev + 1; // 前指针下标
int keyi = begin; // 分界值,下标保留
while (cur <= end) // 防止越界
{
// 当 cur 下标数值小于 key 关键值,与 prev++ 后的下标值,交换
if (arr[cur] < arr[keyi])
{
prev++;
swap(&arr[prev], &arr[cur]);
}
cur++; // >< = cur 前指针都要继续走,
}
// cur 达到数组最后位置,key 关键值 与 prev 下标的数值交换
swap(&arr[prev], &arr[keyi]);
// [begin, prev-1] prev [prev+1, end] prev 已经排序好了,不要动了
quickSortPrevCurAsc(arr, begin, prev - 1); // 左区间,递归排序
quickSortPrevCurAsc(arr, prev + 1, end); // 右区间,递归排序
}
// 前后指针,降序
void quickSortPrevCurDesc(int* arr, int begin, int end)
{
if (begin >= end) // 递归结束条件: 左右序列只有一个数值,或数值不存在,
{
return;
}
int prev = begin;
int cur = prev + 1;
int keyi = prev;
while (cur <= end)
{
// 降序 cur 大于 key 分界值,交换数值
if (arr[cur] >= arr[keyi])
{
prev++;
swap(&arr[prev], &arr[cur]);
}
cur++;
}
// 跳出循环,到达数组最后一个下标位置.
swap(&arr[prev], &arr[keyi]); // 交换
//[begin, prev-1] prev [prev+1, end]
quickSortPrevCurDesc(arr, begin, prev - 1); // 左区间,递归排序
quickSortLeftRightDesc(arr, prev + 1, end); // 右区间,递归排序
}
// 经过了三数取中 和 小区间的优化
void quickSort(int* arr, int begin, int end)
{
if (begin >= end) // 当左右序列只有一个数值或 begin > end 不存在序列时,
{ // 该部分数据已经有序了,不用在递归排序下去
return;
}
int index = getMidIndex(arr, begin, end); // 三数取中的数值下标位置,
swap(&arr[index], &arr[begin]); // 三数取中的数值 与下标为0 的数值交换一下
int left = begin;
int right = end;
int pivot = left; // 默认坑位是,数组中下标 0 的位置
int key = arr[pivot]; // 分界值
while (left < right) // 相遇跳出
{
// 坑位,在左边,先从右边开始找小于 key 的数值下标
while (left < right && arr[right] >= key) // left < right防止在该内部循环就已经相遇了,退出循环
{ // >= 需要 = ,如果 没有 等于 当 arr[right] == key,不会执行 right --
right--; // 而是停留在 等于的位置,left 与 right 就不会相遇了,死循环
}
// 跳出循环,找到了小于 key 的数值的下标位置
arr[pivot] = arr[right]; // 填入坑位中,
pivot = right; // 自己成为新的坑位
// 左边找,大于 key 的数值下标
while (left < right && arr[left] <= key) // left < right 和上面同理
{ // <= 和上面同理
left++;
}
// 跳出循环,找到了大于 key 的数值下标位置
arr[pivot] = arr[left]; // 填入坑位
pivot = left; // 自己成为新的坑位
}
// 跳出循环,相遇了
pivot = left; // 相遇点作为新的坑位, left 和 right 是相等的
arr[pivot] = key; // 将 key 填入到,相遇点坑位中,排序好,
// [begin, pivot-1] pivot [pivot +1 , end] pivot 下标位置的数值,排序好了,不要动
/*
quickSortAsc(arr, begin, pivot - 1); // 左区间,递归排序
quickSortAsc(arr, pivot + 1, end); // 右区间,递归排序
修改为 小区间优化
*/
// 小区间优化,清除递归,换用插入排序
if (pivot - 1 - begin > 10) // 如果左区间的数值量 大于 10 继续使用递归排序
{
quickSort(arr, begin, pivot - 1); // 左区间递归排序
}
else // 如果左区间上的数值量 小于 10 则使用插入排序,将剩下的数值排序好
{
insertSort(arr + begin, pivot - 1 - begin + 1); // 左区间,插入排序
}
if (end - (pivot + 1) > 10) // 如果右区间上的数值量 大于 10 继续使用递归 排序
{
quickSort(arr, pivot + 1, end); // 右区间递归排序
}
else // 如果右区间上的数值量 小于 10 ,则使用插入排序,将剩下的数值排序好
{
insertSort(arr + (pivot + 1), end - (pivot + 1) + 1); // 右区间,插入排序
}
}
// 求单趟排序好的数值下标位置,挖坑法
int parSort(int* arr, int begin, int end)
{
int index = getMidIndex(arr, begin, end); // 三数取中的数值下标位置,
swap(&arr[index], &arr[begin]); // 三数取中的数值 与下标为0 的数值交换一下
int left = begin;
int right = end;
int pivot = left; // 默认坑位是,数组中下标 0 的位置
int key = arr[pivot]; // 分界值
while (left < right) // 相遇跳出
{
// 坑位,在左边,先从右边开始找小于 key 的数值下标
while (left < right && arr[right] >= key) // left < right防止在该内部循环就已经相遇了,退出循环
{ // >= 需要 = ,如果 没有 等于 当 arr[right] == key,不会执行 right --
right--; // 而是停留在 等于的位置,left 与 right 就不会相遇了,死循环
}
// 跳出循环,找到了小于 key 的数值的下标位置
arr[pivot] = arr[right]; // 填入坑位中,
pivot = right; // 自己成为新的坑位
// 左边找,大于 key 的数值下标
while (left < right && arr[left] <= key) // left < right 和上面同理
{ // <= 和上面同理
left++;
}
// 跳出循环,找到了大于 key 的数值下标位置
arr[pivot] = arr[left]; // 填入坑位
pivot = left; // 自己成为新的坑位
}
// 跳出循环,相遇了
pivot = left; // 相遇点作为新的坑位, left 和 right 是相等的
arr[pivot] = key; // 将 key 填入到,相遇点坑位中,排序好,
// [begin, pivot-1] pivot [pivot+1, end]
return pivot; // 返回排序好的数值下标位置。
}
// 快速排序,非递归实现
void quickSortNonR(int* arr, int n)
{
ST st; // 定义栈
StackInit(&st); // 初始化栈
StackPush(&st, n - 1); // 右边最后一个数值下标入栈
StackPush(&st, 0); // 左边数组 0 下标入栈
while (!StackEmpty(&st)) // 栈不为空
{
int left = StackTop(&st); // 取栈顶元素
StackPop(&st); // 出栈
int right = StackTop(&st); // 取栈顶元素
StackPop(&st); // 出栈
int keyIndex = parSort(arr, left, right); // 单趟排序好的数值下标位置
// [left, keyIndex -1] keyIndex [keyIndex+1, right]
if (keyIndex + 1 < right) // 右区间还有数值没有排序好,继续出栈排序
{
StackPush(&st, right); // 右区间的右区间入栈
StackPush(&st, keyIndex + 1); // 右区间的左区间入栈
}
if (left < keyIndex - 1) // 左区间还有数值没有排序好,继续出栈排序
{
StackPush(&st, keyIndex - 1); // 左区间的右区间入栈
StackPush(&st, left); // 左区间中的左区间入栈
}
}
StackDestory(&st); // 销毁栈
}
// 性能测试
void testTop()
{
srand(time(0));
const int N = 1000000; // 100W
// 动态(堆区)上开辟空间
int* arr1 = (int*)malloc(sizeof(int) * N);
int* arr2 = (int*)malloc(sizeof(int) * N);
if (NULL == arr1 || NULL == arr2)
{
perror("malloc error"); // 错误提醒
exit(-1); // 非正常退出程序
}
for (int i = 0; i < N; i++)
{
arr1[i] = rand(); // 生成随机值
arr2[i] = arr1[i]; // 控制变量
}
int begin1 = clock(); // 递归快速排序开始前的时间点,单位 毫秒
quickSort(arr1, 0, N - 1); // 递归快速排序,升序
int end1 = clock(); // 递归快速排序结束后的时间点, 单位 毫秒
int begin2 = clock(); // 非递归快速排序开始前的时间点,单位 毫秒
quickSortNonR(arr2, N); // 非递归快速排序,升序
int end2 = clock(); // 非递归快速排序结束后的时间点, 单位 毫秒
/* 排序效率的计算
* 排序效率 = 排序结束后的时间 end - 排序开始前的时间 begin
*/
printf("递归快速排序: %d\n", end1 - begin1);
printf("非递归快速排序:%d\n", end2 - begin2);
}
// 测试
void test()
{
int arr[] = { 6,1,2,7,9,3,4,5,10,8 };
quickSortNonR(arr, sizeof(arr) / sizeof(int)); // 快速排序,非递归排序
// insertSort(arr, sizeof(arr) / sizeof(int)); 插入排序,升序
// quickSort(arr, 0, sizeof(arr) / sizeof(int) - 1); // 快速排序:升序:三数取中,小区间优化
// quickSortPrevCurDesc(arr, 0, sizeof(arr) / sizeof(int) - 1); // 前后指针,快速排序,降序
//quickSortPrevCurAsc(arr, 0, sizeof(arr) / sizeof(int) - 1); // 前后指针,快速排序,升序
// quickSortLeftRightDesc(arr, 0, sizeof(arr) / sizeof(int) - 1); // 左右指针,快速排序,降序
//quickSortLeftRightAsc(arr, 0, sizeof(arr) / sizeof(int) - 1); // 左右指针,快速排序,升序
//
//quickSortDesc(arr, 0, sizeof(arr) / sizeof(int) - 1); // 挖坑法,快速排序,降序
//
//quickSortAsc(arr, 0, sizeof(arr) / sizeof(int) - 1); // 挖坑法,快速排序,升序
// printf("%d\n", getMidIndex(arr, 0, sizeof(arr) / sizeof(int) - 1)); // 三数取中
playPrint(arr, sizeof(arr) / sizeof(int));
/*
* sizeof(arr) / sizeof(int) - 1 表示数组最后一个下标的位置,
sizeof(arr) 表示数组所占空间的大小,单位字节
sizeof(int) - 1 表示数组元素类型所占空间的大小,单位字节
*/
}
int main()
{
// test(); // 快速排序测试
testTop(); // 非递归 和 递归 快速排序效率测试
return 0;
}

最后:
限于自身水平,其中存在的错误,希望大家给予指教,韩信点兵——多多益善,谢谢大家,后会有期,江湖再见 !!!
