【翻译】Style-Aware Normalized Loss for Improving Arbitrary Style Transfer

用于改进任意风格迁移的风格感知归一化损失
文章目录
- Abstract
- 1. Introduction
- 2. Related Work
- 3. AST Style Loss 分析
- 3.1. AST Training Loss
- 3.2. 分析
- 4. A New Blalanced AST Style Loss
- 4.1. 识别AST损失的真正问题
- 4.2. A New Balanced AST Style Loss
- 4.3. 效果的分析和验证
- 5. 实验评估
- 5.1. 实验设置
- 5.2. 定性评估
- 5.3. 量化评估
- 6. 结论
Abstract
神经风格转换(NST)已经从单一风格迅速发展到无限风格模型,也被称为任意风格转换(AST)。尽管吸引人的结果在文献中被广泛报道,但我们对四种著名的AST方法(GoogleMagenta[14]、AdaIN[19]、LinearTransfer[29]和SANet[37])的实证研究表明,超过50%的时间,AST风格化的图像不能被人类用户接受,通常是因为风格化不足或过度。我们系统地研究了这种不平衡的风格转移性(IST)的原因,并提出了一个简单而有效的解决方案来缓解这个问题。我们的研究表明,IST问题与传统的AST风格损失有关,并揭示了其根本原因是训练样本的权重相等,而不考虑其相应风格图像的适当性,这使模型偏向于某些风格。通过对AST风格损失的理论界限的研究,我们提出了一种新的损失,在很大程度上克服了IST。理论分析和实验结果验证了我们的损失的有效性,在风格欺骗率方面有超过80%的相对改善,在人类评价方面有98%的相对较高的偏好。
1. Introduction
神经风格转移(NST)指的是通过神经网络从两幅图像C和S中生成一个模仿图像P,其中P与C共享内容,但具有S的风格。虽然Gatys[13]的原始NST方法为每一对C和S优化转移模型,但近年来该领域已经迅速发展,开发出支持任意风格的模型,开箱即用。因此,NST模型可以根据其风格化能力分为:为
(1)C和S的单一组合训练的模型[13,23,28,32,39]
(2)一个S[21,27,47,48]
(3)多个固定S[2, 9, 24, 30, 42, 55]
(4)无限(任意)S[4, 14, 15, 17, 19, 20, 25, 29, 31, 37, 43, 44]
直观地说,任意风格转移(AST)的类别(4)是最有优势的,因为它对S是不可知的,允许训练的模型被用于不同的新风格,而不需要重新训练。
尽管在概念上很优越,但目前的AST模型被不平衡的风格转移性(IST)问题所困扰,即模型输出的风格化强度在不同的风格S之间有很大差异。更重要的是,除了以前的工作[14,19,29,37]中显示的不错的结果外,大量的风格化图像因各种S而遭受欠风格化(例如,只有主要颜色被转移)或过度风格化(即内容几乎不可见),使得它们在视觉上不受欢迎(见图1的样本)。我们在第3.2节中描述的用户研究证明了这一点,超过50%的风格化图像被认为是不可接受的,与所使用的AST模型无关。因此,我们离AST的目标还很远——成功地将风格从一个任意的图像转移到另一个。这促使我们系统地研究IST的根本原因,并找到潜在的解决方案来进一步提高AST的性能,以便为不同的风格生成更好的风格化图像。

图1:流行的任意风格转移方法由于在训练期间不平衡的风格转移性而受到欠风格化和过度风格化的影响。我们新的平衡损失可以缓解这些欠风格和过度风格的问题。
在本文中,我们做出了以下贡献:
- 首先,我们系统地研究了AST中的IST问题,发现AST的风格损失是有问题的,因为它不能反映人类的评价分数。
- 第二,我们研究了AST的风格损失函数,发现IST的核心原因是样本风格损失被聚合成一个批次损失的方式。
- 第三,我们推导出样本风格损失的理论期望值及其界限,并利用它提出一种新的风格损失,使不同风格的训练更加平衡。
- 最后,我们进行了广泛的AST基准实验以及人工评估来验证所提出的解决方案的有效性。结果表明,对于所有测试过的AST方法来说,通过纳入所提出的风格损失,IST问题确实得到了极大的缓解。
本文的其余部分组织如下。第2节简要回顾了相关的AST工作。第3节讨论了两个与AST风格损失相关的研究,并表明IST与损失有关联。第4节指出训练损失聚合中的风格无关的样本加权是真正的罪魁祸首,得出我们新的风格感知损失,并通过重复上述两项研究来验证其有效性。第5节提供了在四种著名的AST方法中应用所提出的损失的进一步结果,并表明IST问题在所有的方法中都被克服了。最后,第6节提供了结论性意见。
2. Related Work
任意的风格转移方法可以分为非参数方法[10, 11, 15, 26, 31, 50, 51, 54]和参数方法[14,19,20,25,29,37,43,44,46,49]。非参数方法在内容和风格图像之间找到相似的斑块,并根据匹配的斑块来转移风格。早期的方法流行进行纹理合成[10, 11, 26, 51]。然而,神经风格转移(NST)方法自从在[13]中诞生以来已经成为主流。NST框架的改进包括对VGG[45]特征的多级美白和着色[31],以及基于补丁的特征相似性的特征重构[15]。
参数化AST[14, 19, 20, 25, 29, 37, 43, 44, 46, 49, 52]涉及优化一个目标函数,该函数反映了(1)内容与风格化图像之间的视觉相似性,以及(2)风格与风格化图像之间的风格相似性。这类AST方法[14, 19, 20, 29, 37, 43]通常使用基于格拉姆矩阵的VGG知觉损失[13, 21],并对训练程序做一些修改 。AdaIN[19]在图像图像上应用了一个自适应实例归一化层。在GoogleMagenta[14]和[43]中,元学习被用于学习风格描述。LinearTransfer[29]从内容和风格特征中学习了一个线性变换函数,用于风格化。在SANet[37]和其他作品[46, 52]中,注意力机制也已经与内容和风格特征融合在一起。轻量级的高效风格转换已经通过实例规范化和动态卷积进行了探索[20]。基于格拉姆矩阵的损失也被广泛用于任意视频风格转换[1, 3, 18, 29, 40, 41]。没有基于格拉姆矩阵的损失的方法使用对抗性[25]或重建[44]目标。本文研究了参数化的AST方法,包括表1所列的基于格拉姆矩阵的损失。

表1:四个研究的AST方法与模型的联系
3. AST Style Loss 分析
3.1. AST Training Loss
最近提出了一些用于AST训练的损失函数,例如,基于判别器的逆向损失[25]和基于重建的损失项[44]。然而,最初的[13]NST损失LNST仍然是最普遍采用的[14, 19, 20, 29, 37, 43]。如公式(1)所述,它由两个项组成。LNSTc (C, P )用于从C中学习内容,LNSTs (S, P )用于从S中得出风格,并有一个权衡系数β。

我们通常需要一个ImageNet[8]预训练的VGG[45]网络F来提取C、S和P的特征。 接下来,通过比较P和C的特征来计算内容损失,通过比较P和S的特征的Gram矩阵来计算风格项,因为已知G能有效得出风格信息[13, 32]。在实践中,风格和内容项是针对几个层的特征计算的,并使用加权和(权重wl通常设置为1)跨层汇总。下面的公式总结了损失计算,其中MSE是平均平方误差。
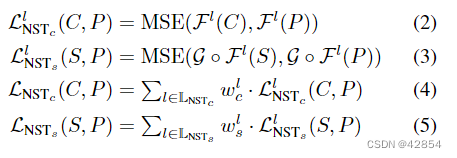
3.2. 分析
IST问题可以直观地归因于与其他风格相比,某些风格转移的难度 “自然更高”。为了系统地研究IST,我们计算了20,000张随机抽样的ImageNet[8]图像的内容和风格损失,这些图像的风格来自Describable Textures Dataset(DTD)[7]和表1中列出的预训练模式。理想情况下,欠风格化和过度风格化的P分别是那些具有低内容和低风格损失的图像。然而,在对样本进行分析时,我们发现前者的关系是有效的,但后者却不是——过度风格化的P通常比欠风格化的样本达到(有时明显)更高的风格损失。在下面的研究中,我们研究了风格损失的分布以及它与风格化质量的视觉感知的关联性。

表 1:四种研究的 AST 方法与模型链接。
研究一:AST风格损失分布(Study I: AST Style Loss Distribution)。我们计算了表1中所列模型的风格损失的经验分布,并检查了属于分布中不同部分的风格化样本–低、中、高风格损失。我们使用在ImageNet上预训练的VGG-16模型作为特征提取器,并使用传统风格层集[21]LASTs = {Fr2b1 , Fr2b2 , Fr3b3 , Fr4b4 }中的层Fl计算风格损失(见公式(5)),其中Frj bi表示VGG-16的第i个卷积块的第j个ReLU层。因此,AST风格的损失被重述如下:
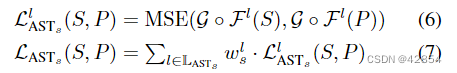
图2总结了我们的发现。尽管被测试的方法之间有很大的差异,(1)它们的LASTs分布是相似的,(2)LASTs并不反映风格化的质量:风格化不足的样本比风格化过度的样本获得的损失值更低。对于基于VGG-19的LASTs也可以得出类似的结论,如补充材料所示。
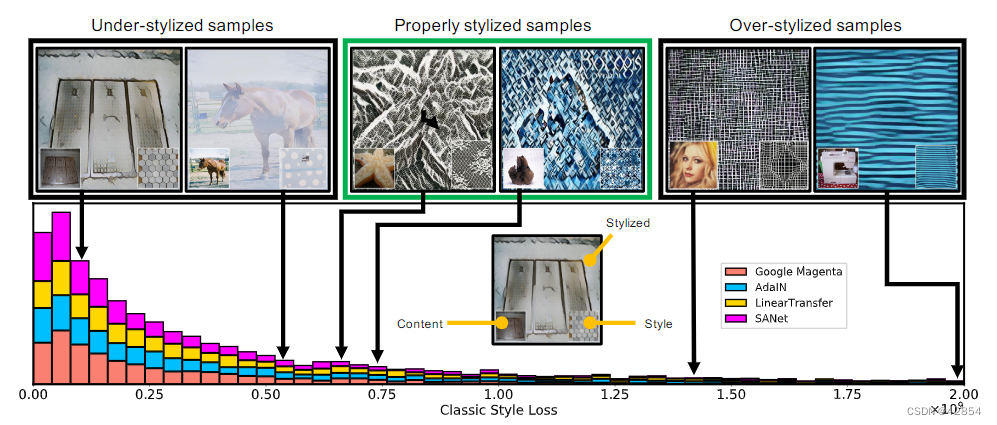
图2:四种AST方法[14,19,29,37]的基于经典格拉姆矩阵的风格损失的分布。较小的损失并不能保证更好的风格转移(左边两幅图),而高质量的转移图像可能有较大的风格损失(中间两幅图),过度风格化的图像反倒获得了最大的损失。放大以获得更好的视觉效果
研究二:传统AST风格损失与人类得分的关系(Study II: Classic AST Style Loss versus Human Score)。研究一揭示了风格转移质量和传统AST风格损失之间缺乏反直觉的关系。在这项研究中,我们进一步调查了这个问题,通过对人类的研究来评估LAST和人类感知之间的相关性。具体来说,我们要求五名志愿者对AST样本进行手工注释,将研究一中产生的样本分成五个随机不相交的子集。每个样本都是一个(S, P)的元组,必须按照风格化质量的递减顺序被注释为 “好”(-1)、“好”(0)或 “坏”(1)。注释者没有得到额外的指示,他们被告知要根据自己的感觉对样本进行分类。
图3显示了收集到的注释的统计数据。我们计算了人类得分和相应的风格损失之间的皮尔逊相关性。表2总结了结果,表明传统的风格损失不仅不能反映人类的感知,而且是负相关的。因此,LASTs(如公式(7)中的定义)不适合AST任务。此外,负相关关系表明,这种风格损失对过度风格化的样本的惩罚比对不足风格化的样本的惩罚更大–这与人们对一个好的AST风格损失的期望相反。
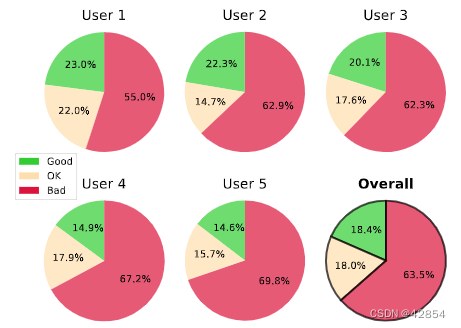
图3:研究II中评估的人类对风格化质量的感知统计。
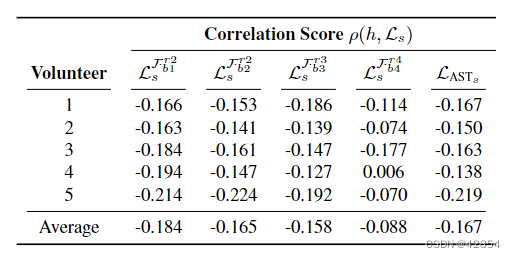
表2:经典AST风格损失(LASTs )和人类得分(h)之间的皮尔逊相关性。Frj bi表示VGG-16的第i个卷积块中的第j个ReLU层。
4. A New Blalanced AST Style Loss
方程(7)中定义的传统AST风格损失重用了经典的NST风格损失,这在以前的一些工作中已经被证明是可行的[14, 19, 29, 37,43]。然而,研究一和研究二的结果显示,这种AST风格损失是有问题的:训练过的模型部分地工作,但受到不平衡风格转移性(IST )的影响,即各种风格的风格化不足或过度,损失值不能反映风格化质量。在这一节中,我们首先通过从多任务学习的角度来看AST,来确定AST风格损失的核心问题。然后,我们提出一个简单而有效的解决方案来缓解这个问题。
4.1. 识别AST损失的真正问题
研究一和研究二中使用的传统AST风格的损失(也是经典的NST风格的损失)是一种样本式的损失。然而,为了确定上述问题的原因,重要的是检查它在训练中是如何使用的——它需要被汇总成一个批量的损失
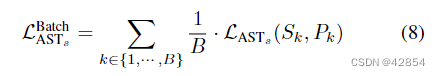
其中B是批次大小。虽然以这种方式将样品的损失平均化为批次损失是很典型的,但这种协议不适合于AST。这是因为AST的学习设置类似于多任务学习,每个批次有B个任务——每个输入样式一个。整体的多任务损失可写为
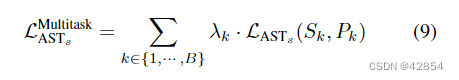
其中λk通常是一个特定任务的贡献因子。比较公式(8)和(9),很明显,当λk=1/B时,AST风格的损失是多任务损失的一个特例。然而,这种等任务权重的设置在多任务学习中是有问题的,除非所有的任务损失都在类似的动态范围内[6,22]。
在AST的情况下,对于随机初始化和完全训练的AST模型,不同风格图像的风格损失可以相差1000倍以上。因此,动态损失范围小或大的风格分别被低估或过度风格化。尽管λk=1/B对某些风格图像有效,为它们产生了很好的风格化结果,但这种设置不适合一般的AST问题,是风格化质量和损失值之间差异的根本原因。因此,我们既不应该简单地将样本的损失汇总成一个批次的损失,也不应该直接比较不同风格的损失。
4.2. A New Balanced AST Style Loss
上一节讨论的多任务观点意味着,IST问题可以通过给一批中的每个风格转移任务分配 "正确的 "任务权重来解决。因此,我们试图制定一个平衡的AST风格损失:
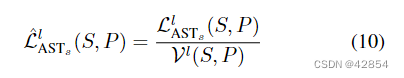
其中Vl(S, P )是需要确定的适当的任务相关的归一化项(其中λk = 1/Vl(S, P ))。一个直观的方法是采用多任务文献[6, 16, 22, 34]中的自动任务损失权重调整方法来实现这一点。然而,这些方法需要在多次迭代中估计所有任务的统计数据(如梯度规范)(如果不是连续的),这对AST来说是不可行的,因为任务在不同批次中变化,(S,P)组合的数量可能是有限的。因此,权重调整的方法不适合AST。此外,Vl(S, P)的选择仅限于在没有历史数据的情况下可以计算的东西。
我们首先推导出经典AST层式损失(等式(6))的理论上的上界和下界,分别如等式(11)和(12)所示。
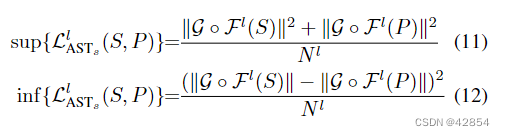
其中N l是一个常数,等于l层特征张量的空间维度的乘积。 详细的推导可以在补充材料中找到。
为了减轻不平衡的风格转移性,我们提出了一个新的风格平衡的损失ˆLlASTs,通过将每个AST任务的风格损失与它的最高值归一化为:
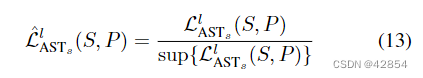
4.3. 效果的分析和验证
我们进行了三项研究来分析和验证我们的新损失(公式(13))的正确性和有效性。
研究三:LlASTs (S, P )与sup{LlASTs (S, P )}之间的关系。建立这种关系很重要,以确保sup{LlASTs (S, P )}是一个合适的规范化术语。具体来说,这种关系必须接近于线性,以平衡所有的训练任务,确保所有的训练任务具有相同的上界1。
我们从Painter by Numbers(PBN)数据集中随机抽取200,000对图像[36]。对于每一对图像,我们使用VGG-16风格层集[21](公式(7))和它的上界(公式(11))计算经典的分层风格损失LlASTs(S,P)。图4提供了这两个项的散点图,其中每个点是一个样本,红线是所有样本的线性拟合,显示LlASTs (S, P )和sup{LlASTs (S, P )}是强烈相关的。
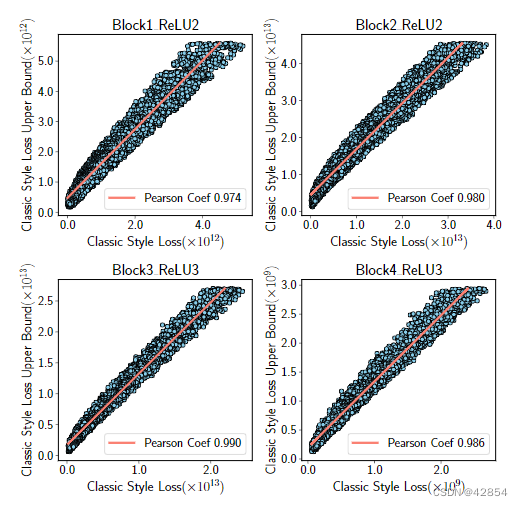
图4:经典AST风格损失LlASTs (S, P )和sup{LlASTs (S, P )}之间的关系。这些子图与分析中使用的四个VGG-16风格层相关。
研究四:新平衡 AST 风格的分布(Study IV: Distribution of the New Balanced AST Style)
损失(Loss)。正如之前在研究一中所指出的,在经典的AST风格的损失中,不够稳定的样本通常比过度稳定的样本获得更低的损失值。在这里我们验证了我们新的AST风格损失是否解决了这个问题。我们重新使用研究一中的数据来测试四种AST方法(见表1),并计算相应的新风格损失分布,如图5所示。结果显示,在新的AST风格损失ˆLASTs下,过度风格化的样本现在获得的损失值比风格化不足的样本低。
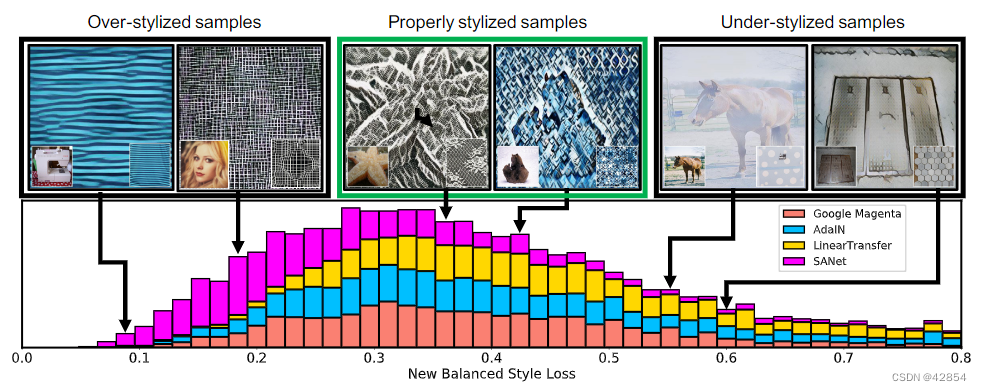
图5:我们对四种AST方法[14, 19, 29, 37]的风格平衡损失的分布。小的损失值表示过度风格化,而大的损失值则对应于风格化不足,适当风格化的样本处于中间,正如预期的那样。
研究五:新的AST风格损失与人类分数(Study V: New AST Style Loss vs. Human Score)。我们研究了我们新的平衡AST风格损失ˆLASTs和研究II中产生的样本的人类分数之间的关系。这些结果在表3中列出。与经典AST风格损失和人类分数之间的负相关关系不同(见表2),新的平衡AST风格损失与人类分数呈正相关关系。尽管在人类研究分析中把 "OK "注释作为零分处理,但这有力地表明,所提出的新的AST风格损失与人类分数的一致性要比经典AST风格损失好得多。
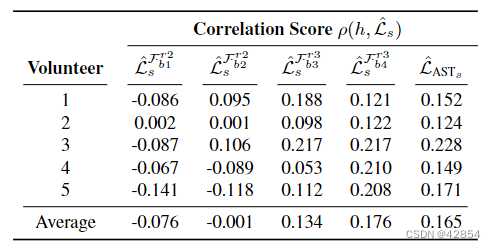
表3:新的AST风格损失(ˆLASTs)和人类分数(h)之间的皮尔逊相关性。Frj bi表示VGG-16的第i个卷积块中的第j个ReLU层。
5. 实验评估
在这一节中,我们提供了对所提出的新损失的定性和定量评估,以及它与传统的AST风格的损失相比较的好处。
5.1. 实验设置
我们重新使用表1中列出的预训练模型,并用经典或新式损失训练其他模型,以验证后者带来的改进的普遍性。这些模型列于表4。我们使用MS-COCO[33]的内容图像和Painter by Numbers[36]的风格图像来训练这些模型。在研究I-V中使用的ImageNet训练的VGG-16模型的四个层(LASTs = {Fr2b1 , Fr2b2 , Fr3b3 , Fr4b4 })在这里被用来计算训练的风格损失。按照以前的研究[13, 21],Fr3b3层被重新用于计算内容损失。为了对模型进行公平的比较,我们在总体损失中挑选了风格与内容的权重β(公式(1)),以确保风格和内容损失的大小相似。我们使用的优化器与文献中报道的四个模型的作者所使用的优化器相同。我们使用 "1P "模型进行经典的AST风格损失相关的比较。我们不通过分母反向传播梯度,以获得更稳定的训练和更好的结果。
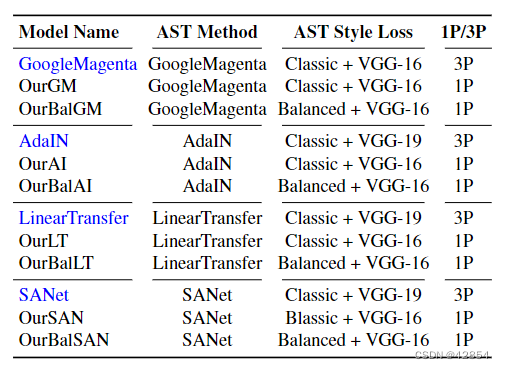
表4:实验评估中使用的AST模型。"3P "表示公开可用的预训练模型,而 "1P "表示我们实验中使用的设置。为了保持一致性,我们使用基于VGG-16的损失来训练所有模型。
5.2. 定性评估
与经典损失的比较。图6显示了一些使用我们新的平衡风格损失训练模型的欠佳和过度僵化的例子。显而易见,我们的损失在这两种情况下都是有效的,而且在所有测试的AST模型中都是通用的,在内容和风格之间提供了一个更好的权衡。风格化样本的结果表明,我们的损失有助于捕捉全局和低层次纹理相关的风格信息,而用传统损失训练的模型只包含风格颜色。结果还表明,我们的损失在过度僵化的情况下可以保留更多的内容。虽然由于经典损失,在过度风格化的图像中,内容是完全不可识别的,但我们的损失同时产生了可见的内容和适当的风格化。更多结果见补充材料。

图6:由于经典损失而导致的不足或过度风格化的情况下的改进。在前一种情况下,当我们使用新的损失时,风格化图像的局部和整体纹理更接近于风格化图像,例如,Google Magenta的第(3)和(4)列。在后一种情况下,使用我们的损失时,原始内容在风格化图像中更明显,例如AdaI的第(1)列。
与风格插值的比较。风格插值是一种常见的融合风格的方法,即在解码前结合不同图像的风格特征[14, 19, 29, 43]。通常,一个插值系数被用来控制不同风格的贡献。由于过度风格化主要是指转移过多的风格,一个合理的补救措施是在风格和内容之间应用风格插值(即把内容图像作为一个新的风格)。然而,如图7所示,这不是很有效。相比之下,使用我们的平衡损失的风格化(图7©)提供了更好的结果,在适当转移风格的同时更好地保留了内容。最后但并非最不重要的是,找到一个 "好的 "插值系数并不是一个简单的任务,因为它对于不同的风格是不同的。

图7:与使用GoogleMagenta解决方案的经典风格插值方法相比,我们新的平衡风格损失能更有效地缓解过度风格化问题。风格插值系数用大括号表示。
5.3. 量化评估
AST风格损失比较。我们计算了每个AST模型的所有测试样本的经典和新的平衡AST风格损失。结果显示在图表5中。显而易见,我们用新的平衡损失训练的模型总是能达到明显较低的总体损失值。这是因为新的损失允许更多的任务((S, C)组合)被公平地训练,对于相同的内容和风格图像对,实现更低的经典风格损失。
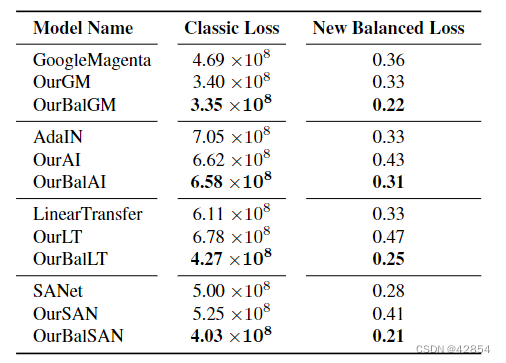
表5:用传统损失训练的模型和用我们的新损失训练的模型之间的损失比较。用我们的损失训练的模型总是能获得较低的总体损失值。
欺骗率(Deception Rate)。Sanakoyeu等人[42]引入了欺骗率作为评价风格转移质量的指标。它被定义为风格化图像欺骗艺术家分类模型的成功率,从而使风格化图像和风格化图像都被预测为同一艺术家。
我们为每个AST模型生成5,000张风格化图片,内容图片来自ImageNet测试集,风格图片来自Painter by Numbers(PBN)测试集,以确保本实验中使用的图片和风格不与训练数据集重叠。此外,我们排除了在训练数据中出现过的艺术家的风格图像,或者在测试集中有少于30幅画。这导致了来自34位艺术家的1,798幅风格图像(绘画)。内容-风格对被随机抽样,以生成用于评估的风格化图像。
我们使用PBN挑战赛的获胜方案(https://github.com/inejc/painters)来计算欺骗率。首先,我们使用该模型为所有的风格图像生成2,048维的特征。接下来,对于每个风格化的图像,我们使用相同的模型提取其特征,并使用L2距离找到其最近的风格图像。对于一个成功的欺骗,最近的邻居的艺术家必须与用于生成风格化样本的风格图像相匹配。
表6总结了结果,显示采用我们的新损失后,欺骗率有了很大的提高。改进的范围从SANet的83%的最小相对改进到LinearTransfer的111%(或2.1倍)。
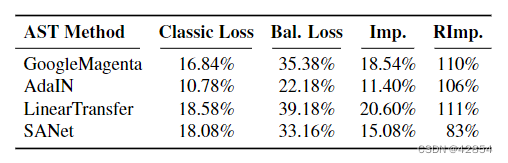
表6: 欺骗率(%),分别显示在 "经典损失 "和 "平衡损失 "两栏。损失 "这一栏中分别显示。"Imp. "和 "RImp. "分别表示绝对和相对的改进。
人类评价。我们通过人类评估进一步量化由于我们的新损失而带来的风格化质量的改善。我们随机抽取了5000个内容风格对,其中内容图像来自ImageNet测试集,风格图像来自PBN[36]和Describable Textures Dataset(DTD)[7]的测试集。对于每一对图像和四种AST方法中的每一种(表1),我们生成两个风格化的图像:一个使用用传统损失训练的模型,另一个使用用我们的新损失训练的模型。然后由注释者对随机的图像子集进行投票,注释者被要求根据他们对风格化质量的偏好,为每对图像选择两个风格化的图像中的一个。在total中,收集了2,200个注释,结果显示,28.2%的投票者更喜欢用经典损失训练的模型的风格化图像,而更多的人喜欢用我们新的平衡损失训练的模型,其中15.8%认为它们的质量相似。图8提供了每个模型的分类,显示出用我们的损失训练的模型产生的结果更受人类感知的青睐。
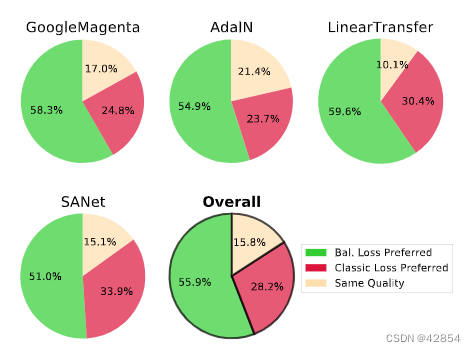
图8:人类评价结果。在所有的方法中,用户更喜欢用我们的损失模型训练出来的风格化的图像。
6. 结论
在这项工作中,我们系统地研究了经典AST风格损失和人类对风格化质量的感知之间的差异。我们确定了这种差异的根本原因是在训练过程中对样本损失的风格不了解,并得出了风格损失的理论界限,以设计一种新的具有风格意识的标准化的风格平衡损失。我们表明,与传统的损失不同,我们的新损失与人类的感知正相关。最后,实验结果显示,欺骗率和人类偏好的相关改进分别达到111%和98%。未来的工作可以在相关问题中采用我们的新损失,例如,视频[1, 3, 5, 12, 18, 29, 40, 41]和照片[29, 35, 38, 53]风格化,纹理合成[10, 11, 26,51]等。未来的工作还可以为风格损失推导出更严格的界限,以提高风格感知的规范化程度。