PostgreSQL回滚TRUNCATE操作的原理
下午大家在讨论pg可以回滚truncate操作,好奇原理是怎么样的,搜到的大部分文章只提到了“事务DDL”的概念,没有详细介绍。后来找到两篇文章,整理并测试了一下主要内容。
一、 回滚原理
在 Oracle中,多个表和索引存储在由一个或多个数据文件组成的表空间中,但在 PostgreSQL 中,通常将每个对象存储为一个 OS 上的文件,例如表或索引。
在 PostgreSQL 中执行 TRUNCATE 时,会为目标表创建一个新的物理文件,之后该事务会话引用这个新的物理文件,而其他会话引用旧文件(查询对应表会被阻塞)。旧物理文件通过pendingDeletes机制一直保留到执行TRUNCATE 的事务提交(实际是在提交的一段时间之后)。如果执行回滚,则改回引用旧文件,此时便可快速回滚truncate操作。
二、 实验测试
创建测试表
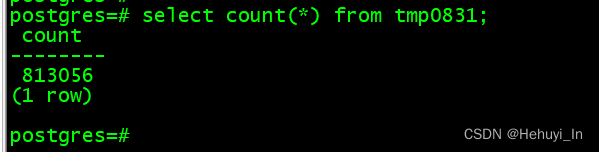
查看表的OID及relfilenode
select oid,relfilenode from pg_class where relname = 'tmp0831';
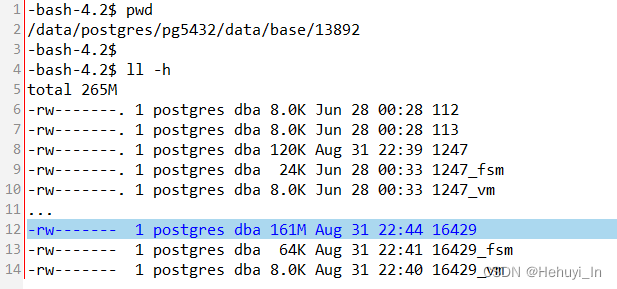
![]() 对应物理文件
对应物理文件
1. 回滚测试
从另一个会话(会话 2)启动事务,并truncate表。
begin;
truncate table tmp0831;
select count(*) from tmp0831;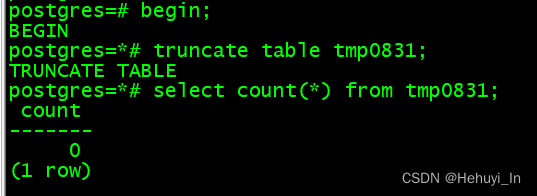
![]()
查询relfilenode,发现已经变了

说明对应的物理文件已经变了

会话1查询tmp0831表行数,发现被阻塞

查询relfilenode,还是旧的

会话2回滚truncate操作,再查relfilenode,发现变回来了

2. 自动提交测试
关闭事务,会话2再次 truncate,此时会自动提交

可以看到这次会话1的也跟着变了

查看物理文件,会发现之前的16429和16435都没有了,只有最新的16438,tmp0831表目前就引用该文件。

符合前面提到的原理
参考
https://dev.classmethod.jp/articles/postgresql-internal-truncate/
http://www.nminoru.jp/~nminoru/postgresql/pg-table-and-block-structure.html#relation-file-node