9月1日目标检测学习笔记——文本检测
文章目录
- 前言
- 一、类型
- 1、Top-Down
- 2、Bottom-up
- 二、基于深度学习的文本检测模型
- 1、CTPN
- 2、RRPN
- 3、FTSN
- 4、DMPNet
- 5、EAST
- 6、SegLink
- 7、PixelLink
- 8、Textboxes
- 9、Textboxes++
- 三、常见数据集
- 1、ICIAR
- 2、Chinese Text in the Wild(CTW)
- 3、Reading Chinese Text in the Wild(RCTW-17)
- 4、ICPR MWI 2018
- 5、Total-text
- 6、Google FSNS 谷歌街景文本数据集
- 7、COCO-TEXT
前言
本文为9月1日目标检测学习笔记——文本检测,分为三个章节:
- 类型;
- 基于深度学习的文本检测模型;
- 常见数据集。
定位文字所在区域。
一、类型
1、Top-Down
先检测文本区域,再找出文本线。
- 缺点:
- 不考虑上下文;
- 不够鲁棒;
- 太多子模块。
2、Bottom-up
先检测字符,再串成文本线。
二、基于深度学习的文本检测模型
1、CTPN
-
可检测水平或微斜的文本行;
-
文本行可被看成一个字符序列,文本字符间上下文;
-
数据后处理阶段:合并相邻的小文字块为文本行。
-
网络结构:
VGG16 + BLSTM + FC ⇒ 文字块坐标值和分类结果概率分布。
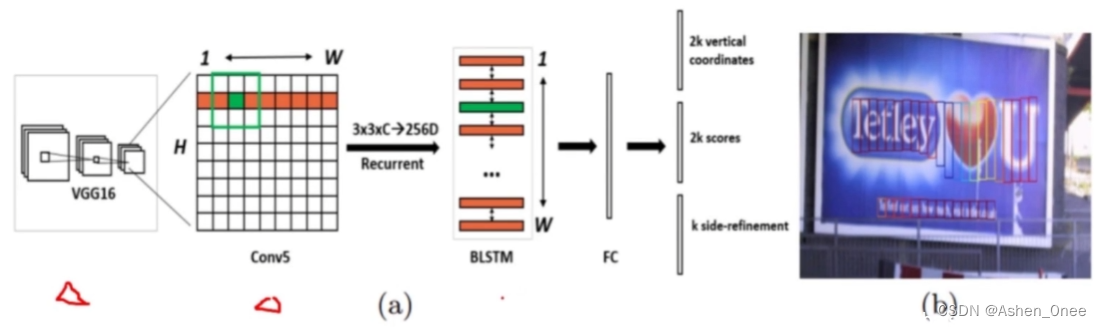
- 步骤:

2、RRPN
-
基于旋转区域候选网络的方案;
-
BBox ( x , y , h , w , θ ) (x, y, h, w, \theta) (x,y,h,w,θ),h 为短边,w 为长边,方向是长边的方向:
- 生成带有文本方向角的倾斜候选框;
- 在边框回归中学习文本方向角。
-
网络结构:
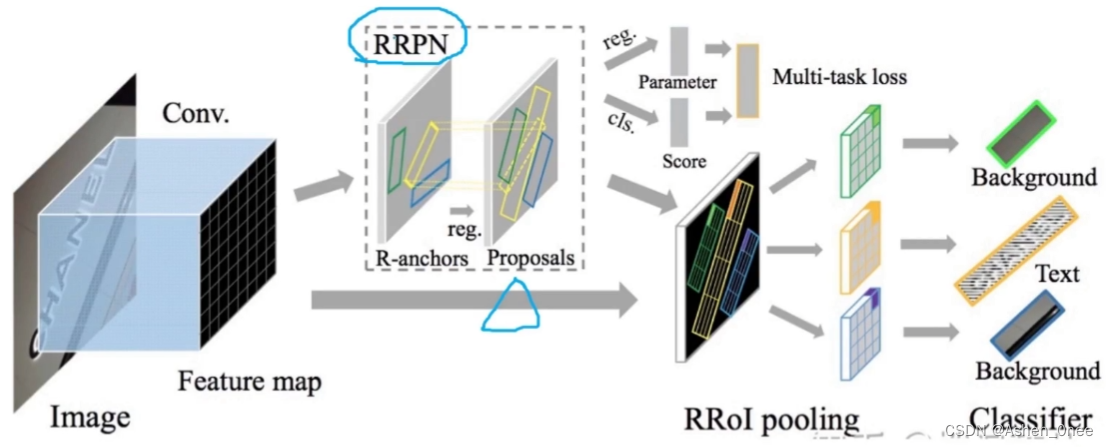
- VGG 16;
- 多任务网络:交叉熵 + smooth L1;
- 五元组 ( x , y , h , w , θ ) (x, y, h, w, \theta) (x,y,h,w,θ);
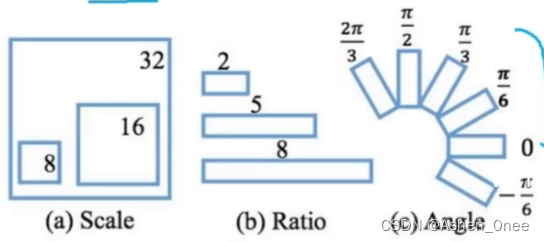
- 改进 anchor:
- 6个方向角: − π 6 : 2 π 3 : π 6 -\frac{\pi}{6} : \frac{2\pi}{3} : \frac{\pi}{6} −6π:32π:6π;
- 文本框形状比例:1:2、1:5、1:8;
- 54个R型锚点;
- 分类层有 108个(2×54)个输出值,回归层有 270个(5×54)个输出值;
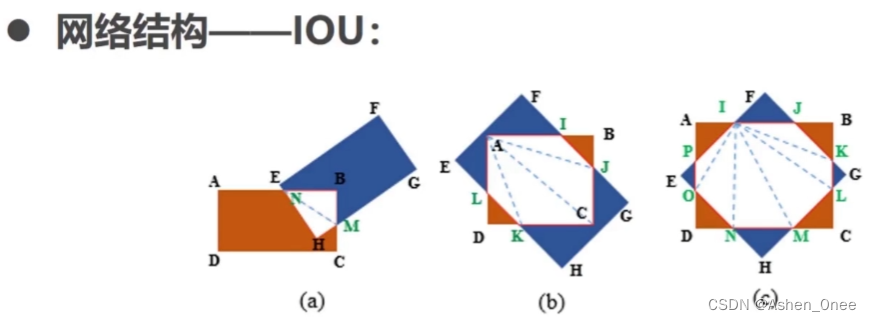
- 锚点对应的 box 与 GT 的 IoU 值最大,标记为正样本;
- 锚点对应的 box 与 GT 的 IoU 值>0.7,标记为正样本;
- 锚点对应的 box 与 GT 的 夹角< π 12 \frac{\pi}{12} 12π,标记为正样本;
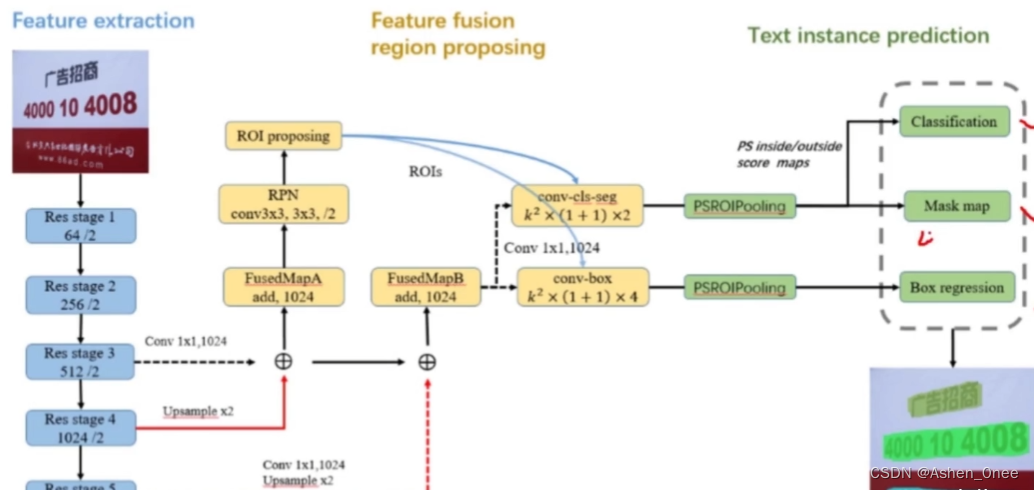
3、FTSN
- 分割网络 + 倾斜文本检测 ⇒ 多任务;
- Mask-NMS 代替传统 BBOX 的 NMS 算法过滤候选框;
- ResNet-101 作基础网络;
- 多尺度融合的特征图;
网络结构:
4、DMPNet
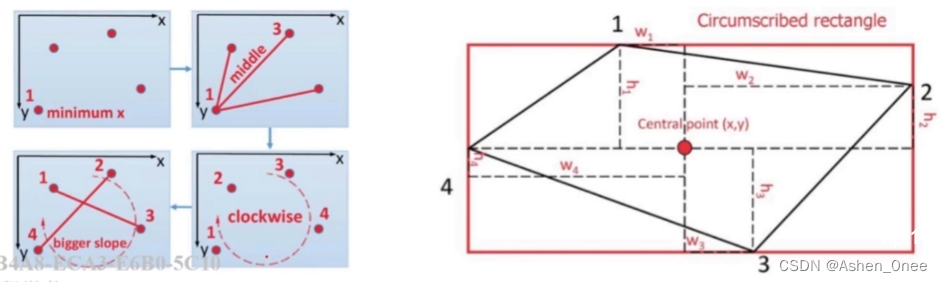
- 使用四边形更紧凑地标注文本区域边界;
- 使用共享蒙特卡洛方法精确计算多边形面积;
- 基于一种序贯协议(定义点的顺序)确定四边形四个点的顺序:
- Smooth L n L_n Ln loss;
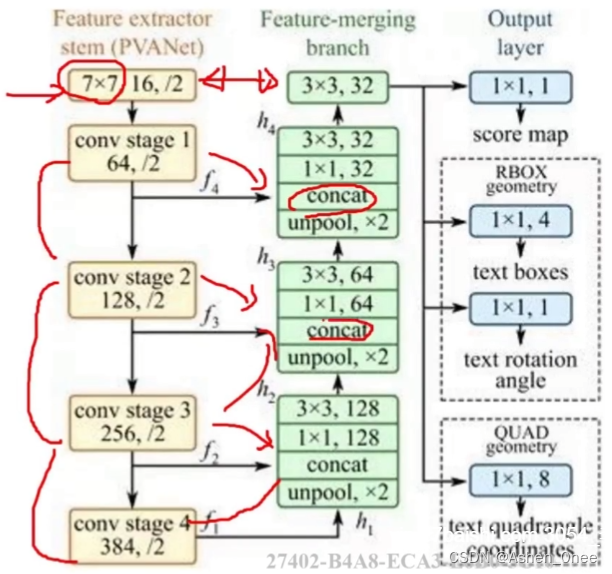
5、EAST
- 使用 FCN 生成多尺度融合的特征图,进行像素级的文本块预测;
- 支持旋转矩形框、任意四边形两种文本区域标注形式;
- 提供了方向信息,可检测各方向的文本;
- 特征提取层:PVANet;
- 特征融合层:上采样 + concat;
- 输出层:1个 score map + 4个回归的框 + 1个角度信息。
6、SegLink
- 改进版的 SSD,解决多方向的文字检测问题;
- Segements + Link:可得到最后的文本行的 box ( x , y , w , h , θ ) (x, y, w, h, \theta) (x,y,w,h,θ);
- Loss 函数: L ( y s , c s , y l , c l , s ^ , s ) = 1 N s L c o n f ( y s , c s ) + λ 1 1 N s L l o c ( s ^ , s ) + λ 2 1 N i L c o n f ( y l , c l ) L(y_s, c_s, y_l, c_l, \hat{s}, s ) = \frac{1}{N_s} L_{conf(y_s, c_s)} + \lambda_1 \frac{1}{N_s}L_{loc}(\hat{s}, s) + \lambda_2 \frac{1}{N_i}L_{conf}(y_l, c_l) L(ys,cs,yl,cl,s^,s)=Ns1Lconf(ys,cs)+λ1Ns1Lloc(s^,s)+λ2Ni1Lconf(yl,cl).
网络结构:
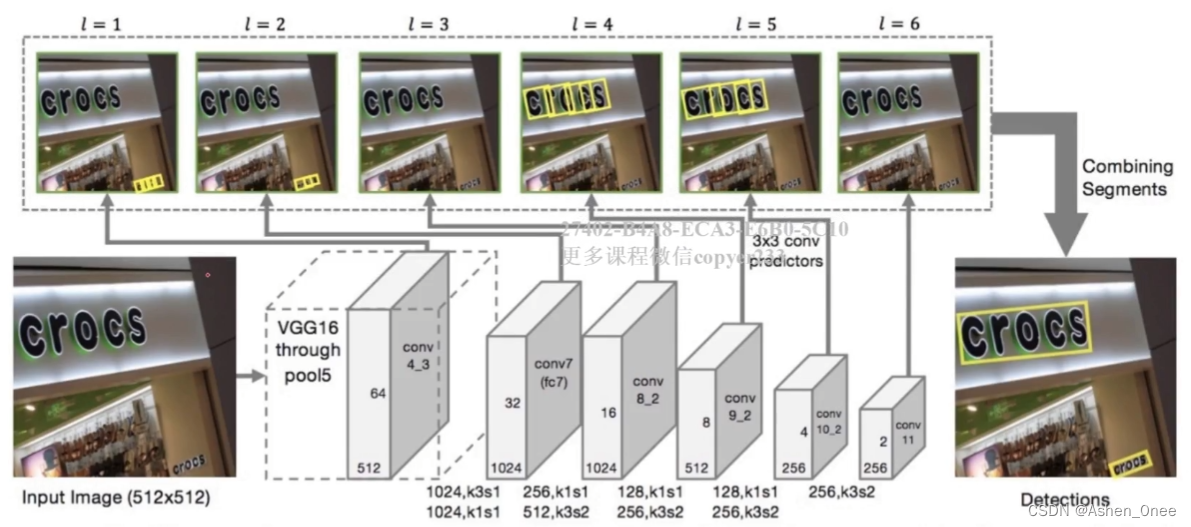
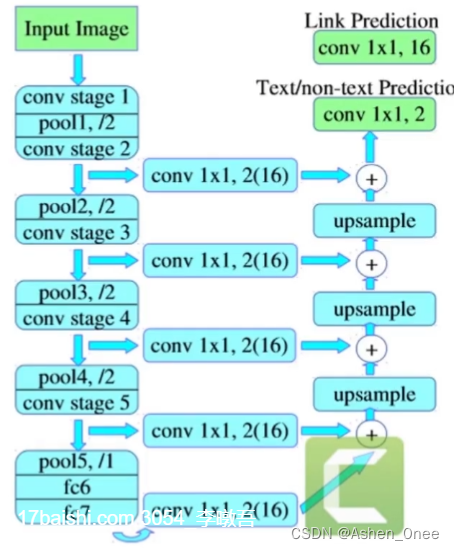
7、PixelLink
- 基于实例分割的文本检测模型:自然场景图像中,一组文字块经常紧挨在一起,通过语义分割方法难以将它们识别开来。
流程:
- 特征提取:VGG16 基础上构建的 FCN 网络:
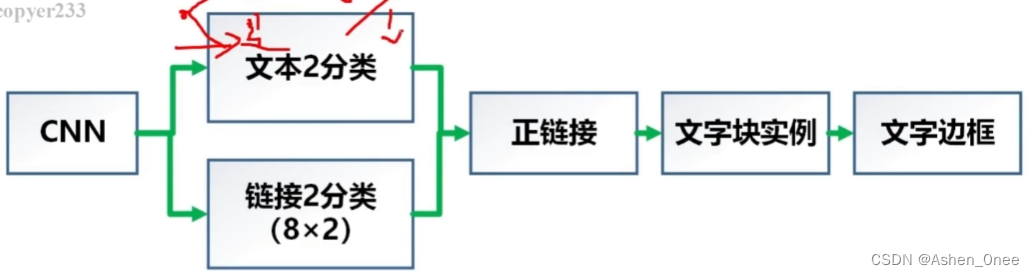
核心结构:
- VGG16 + FPN;
- 下采样:1/2,1/4;
- 连接像素提取文本框;
- 后处理去除噪声;
- 损失函数:
L p i x e l = 1 ( 1 + r ) S W L p i x e l _ C E L l i n k _ p o s = W p o s _ l i n k L l i n k _ C E L l i n k _ n e g = W n e g _ l i n k L l i n k _ C E L l i n k = L l i n k _ p o s ( r s u m ( W p o s _ l i n k ) + L l i n k _ n e g ( r s u m ( W n e g _ l i n k ) L_{pixel} = \frac{1}{(1+r)S} WL_{pixel\_CE} \\ L_{link\_pos} = W_{pos\_link} L_{link\_CE}\\ L_{link\_neg} = W_{neg\_link} L_{link\_CE}\\ L_{link} = \frac{L_{link\_pos}}{(rsum(W_{pos\_link})} + \frac{L_{link\_neg}}{(rsum(W_{neg\_link})} Lpixel=(1+r)S1WLpixel_CELlink_pos=Wpos_linkLlink_CELlink_neg=Wneg_linkLlink_CELlink=(rsum(Wpos_link)Llink_pos+(rsum(Wneg_link)Llink_neg

8、Textboxes
- 改进的 SSD 算法:
- 端到端训练;
- 检测 + OCR;
网络结构:
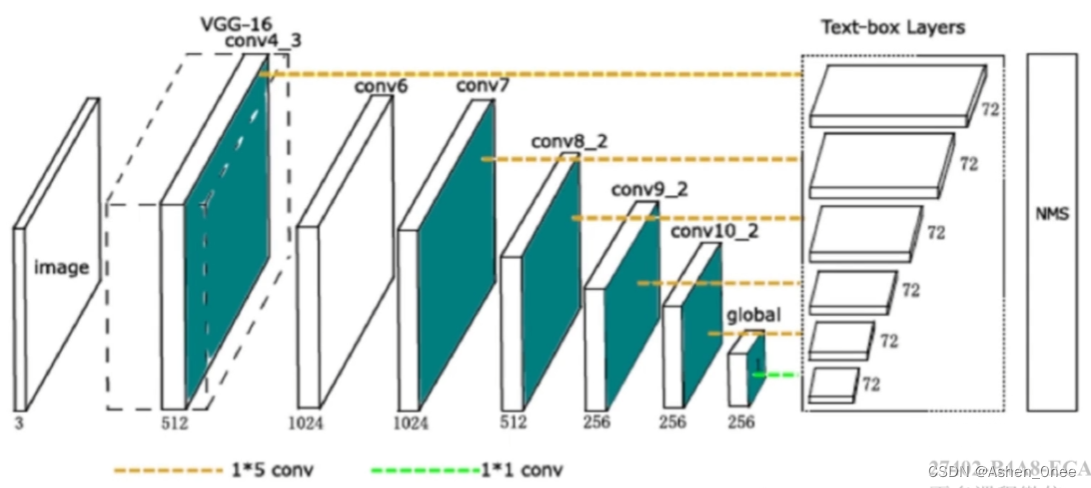
- 主干网络:VGG + 6个卷积层特征层;
- Text-box layer:
- 预测 72 维向量;
- 12 个 default boxes;
- 预测 4个偏差坐标值。
- NMS;
- Default box 的长宽比改为 1,2,3,5,7,10;
- 1×5 滤波器代替 3×3 滤波器;
- 仅包含文本行一种分类;
- 多个比例图片输入;
- Loss: L ( x , c , l , g ) = 1 N ( L c o n f ( x , c ) + α L l o c ( x , l , g ) ) L(x, c, l, g) = \frac{1}{N}(L_{conf}(x, c) + \alpha L_{loc} (x, l, g)) L(x,c,l,g)=N1(Lconf(x,c)+αLloc(x,l,g));
9、Textboxes++
- 多方向文本;
- 端到端。
网络结构:
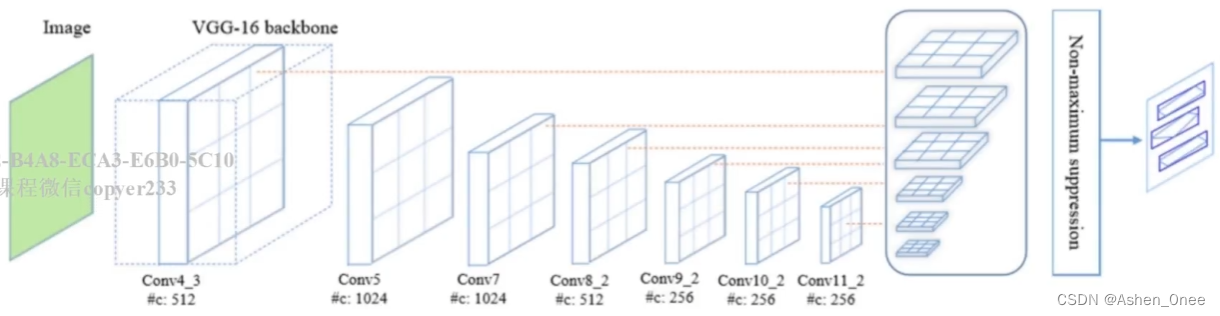
-
VGG16(conv1_1 ~ conv5_3);
-
最后两层用卷积层替换全连接层;
-
额外加 8 个卷积层;
-
NMS 后处理;
-
不同尺度的输入;
-
文本框表示:四边形或矩形(8个值表示):
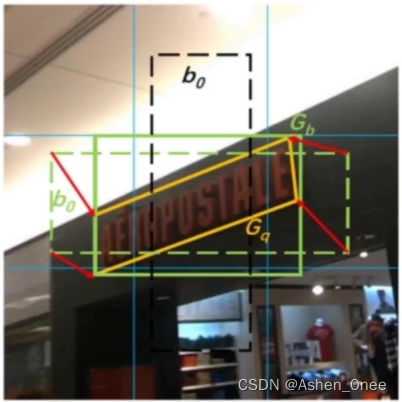
-
default boxes 设置上下偏置;
-
卷积核:3×3 ⇒ 3×5;
-
多任务:CRNN 做 OCR;
-
6 个不同的尺度上做 NMS。
-
特殊处理:
- 真值表示:多边形 + 角度;
- 在线难例挖掘;
- 数据增强;
- 多尺度训练;
- 级联的 NMS;
- 多任务网络。
三、常见数据集
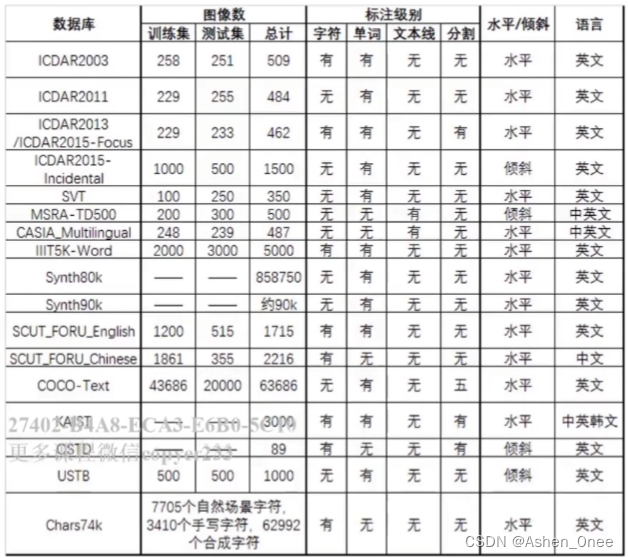
1、ICIAR
https://www.icdar.org/
2、Chinese Text in the Wild(CTW)
https://ctwdataset.github.io/