textcnn, textrnn, textrcnn, textrnn_att, dpcnn, transformer介绍
目录
1 textcnn
2 textrnn
3 textrcnn
4 textrnn_att
5 DPCNN
6 Transformer
1 textcnn
Text-CNN 和传统的 CNN 结构类似,具有词嵌入层、卷积层、池化层和全连接层的四层结构。
论文链接:https://arxiv.org/pdf/1408.5882.pdf
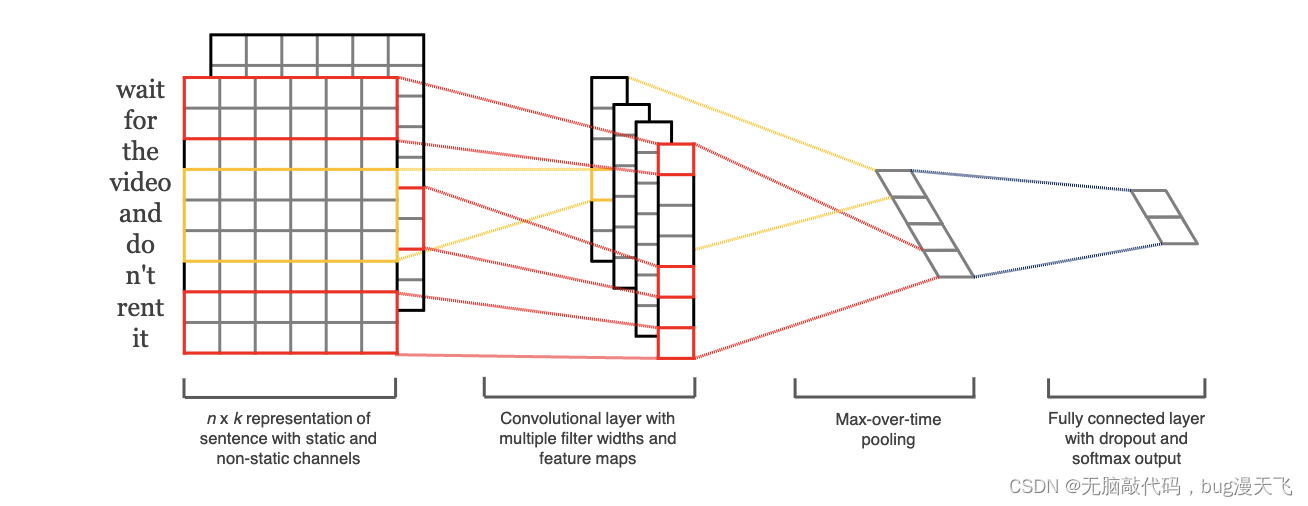
词嵌入层:使用二维矩阵来表示长文本,词嵌入方法有多种: Bert、word2vec等;
经过词嵌入,每个单词具有相同长度的词向量表示。将各个词语的向量表示连起来便可以得到二维矩阵。
[batch_size,sentence_length,embedding_size]
文本使用卷积channels = 1;
对上方输入进行扩维度:[batch_size,sentence_length,embedding_size,1],因为进行卷积操作需要的维度是4维的,对应上图第一部分。
卷积层: 卷积核的宽度等于词向量的维度,经卷积后可以提取文本的特征向量;
textcnn也可以设置多个卷积核,用来提取文本的多层特征,长度为N的卷积核可以提取文中的N-gram特征;
设卷积核size为n,卷积核的shape是[n,embedding_size,1,num_filter],num_filter表示卷积核的数量;
以步长为1 进行卷积,会得到size_len*num_filter个列向量,其中size_len是size的种类数(比如size为(2,3,4));
该层产生维度(size_len*num_filter)个[(sentence_length-size+1)*1],对应上图第二部分。
池化层:一般采用最大池化,从而判断词嵌入中是否含N-gram;
将列向量中最大值取出来,对输入补0做过滤;
池化操作是对上述卷积层得到的整个列向量;
池化的shape是[1,sentence_length-size+1,1,1],其中sentence_length-size+1是上文提到的经过卷积处理后得到的列向量长度.;
经过池化操作后得到size_len*num_filter个元素,合并在一起形成一个size_len*num_filter维的向量;
该层产生维度为[(size_len*num_filter)*1],对应上图第三部分。
全连接层:采用Dropout算法防止过拟合(也可以加一个l2正则,),通过soft Max输出各类别概率。
网络结构简单导致参数数目少, 计算量少, 训练速度快。
CNN具有一个缺点就是CNN有一个固定的窗口大小,很难完全采集到文本的所有信息。
小窗口大小可能导致一些关键信息的丢失,而大的窗口会导致巨大的参数空间(这可能很难训练)
2 textrnn
textRNN指的是利用RNN循环神经网络解决文本分类问题,通常使用LSTM和GRU这种变形的RNN。
模型输入准备:一般会进行固定长度的文本输入,不够长度则进行填充,过长则进行截断;得到文本中每个词的嵌入表示(embedding size固定)
RNN:在RNN的每一个时间步长上输入文本中一个单词的向量表示;计算当前时间步长上的隐藏状态,用于该时间步的输出以及下一个时间步的输入;下一个时间步的输入和下一个单词的词向量一起作为RNN单元输入;再计算下一个时间步长上RNN的隐藏状态,以此类推...
TextRNN的结构非常灵活,可以任意改变。比如把LSTM单元替换为GRU单元,把双向改为单向,添加dropout或BatchNormalization以及再多堆叠一层等等。
TextRNN在文本分类任务上的效果非常好,与TextCNN不相上下,但RNN不能并行运算,训练速度相对偏慢,一般2层就已经足够多了。
RNN是一个有偏倚的模型,在这个模型中,后面的单词比先前的单词更具优势。因此,当它被用于捕获整个文档的语义时,它可能会降低效率,因为关键组件可能出现在文档中的任何地方,而不是最后。
3 textrcnn
一个双向的循环结构,与传统的基于窗口的卷积神经网络相比,它可以大大减少噪声,从而最大程度地捕捉上下文信息。
在学习文本表示时可以保留更大范围的词序;
使用了一个可以自动判断哪些特性在文本分类中扮演关键角色的池化层(max-pooling),以捕获文本中的关键组件;
论文链接:http://www.nlpr.ia.ac.cn/cip/~liukang/liukangPageFile/Recurrent%20Convolutional%20Neural%20Networks%20for%20Text%20Classification.pdf
一般的 CNN 网络,都是卷积层 + 池化层。textrcnn是将卷积层换成了双向 RNN,所以结果是,双向 RNN + 池化层。
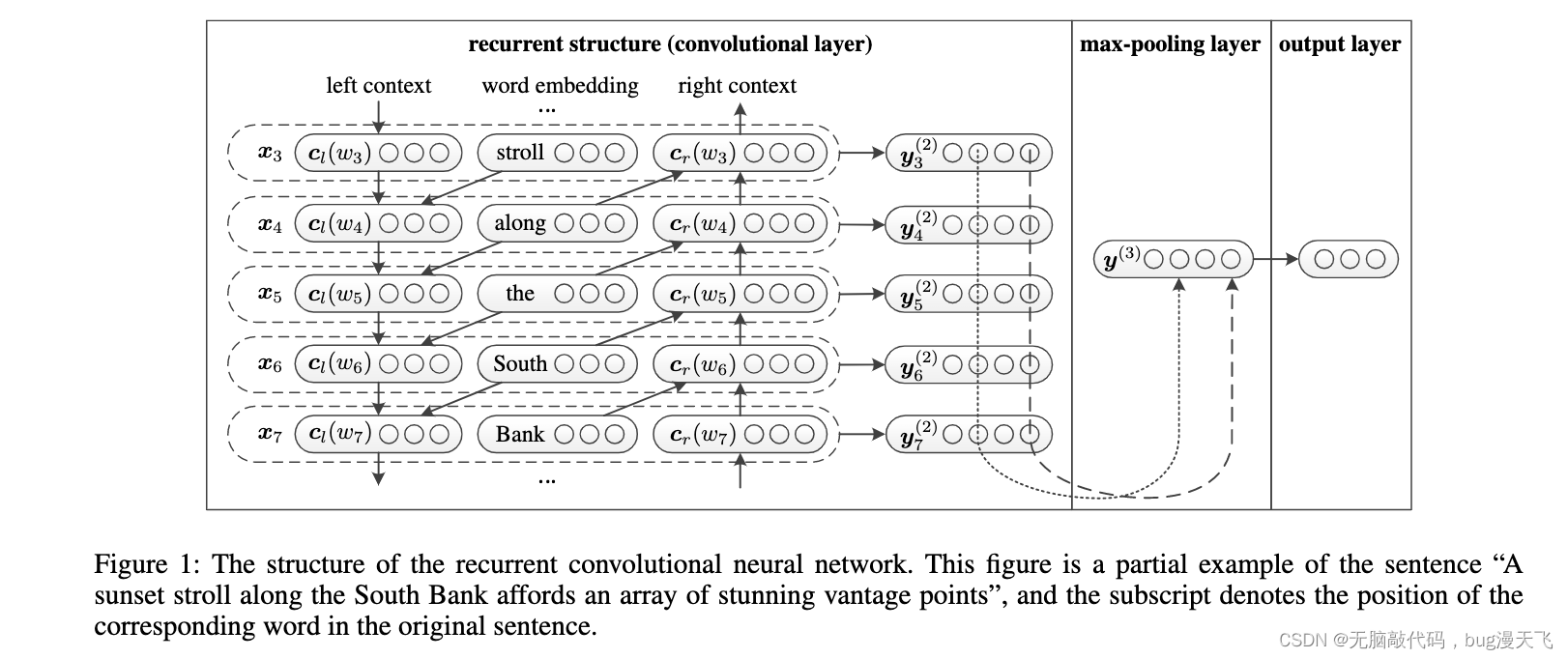
模型分为三部分R-CNN结构,池化层和输出层;
R-CNN部分是一个双向的循环神经网络,输入是单词的embedding;
第i个位置的隐藏状态受到他的左右两边的上下文的影响, 那么第i个位置的隐藏状态我们可以根据他的左边的上下文和右边的上下文分别描述:

将R-CNN部分获得的隐层输出和词向量拼接[forward Output, word Embedding, backward Output];
将拼接后的向量非线性映射到低维;
向量中的每一个位置的值都取所有时序上的最大值,得到最终的特征向量,该过程类似于max-pooling;
softmax分类。
RNN因为当前的状态会受到上下文的影响,因此模型在学习的时候自然会考虑到文本的上下文的影响,而且影响的范围大于CNN的卷积核,因此RNN的效果可能会优于CNN的效果。
4 textrnn_att
基于注意力机制的双向LSTM网络(AttBLSTM)来捕获句子中的最重要语义信息用于关系分类;
论文链接:https://aclanthology.org/P16-2034.pdf
模型架构:
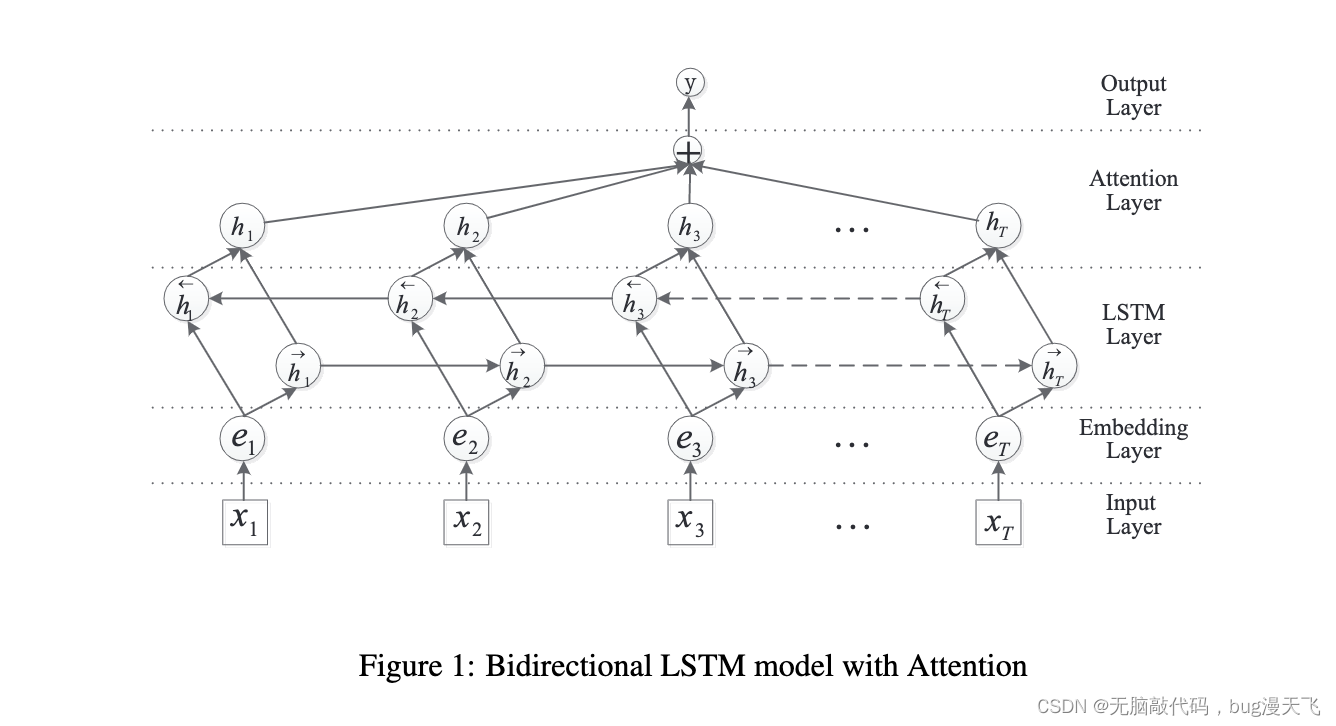
词嵌入层:将每个词映射到低维向量;
LSTM层:使用BiLSTM提取特征;
注意力层:通过与权重向量加权求和,将词级别的特征合并到句子级别的特征;

输出层:将句子层级的特征用于关系分类。
参考:textRNN-Attention - 知乎
5 DPCNN
ACL2017 年中,腾讯 AI-lab 提出了Deep Pyramid Convolutional Neural Networks for Text Categorization(DPCNN)
论文链接:https://aclanthology.org/P17-1052.pdf
实验证明在不增加太多计算成本的情况下,增加网络深度就可以获得最佳的准确率。
网络结构
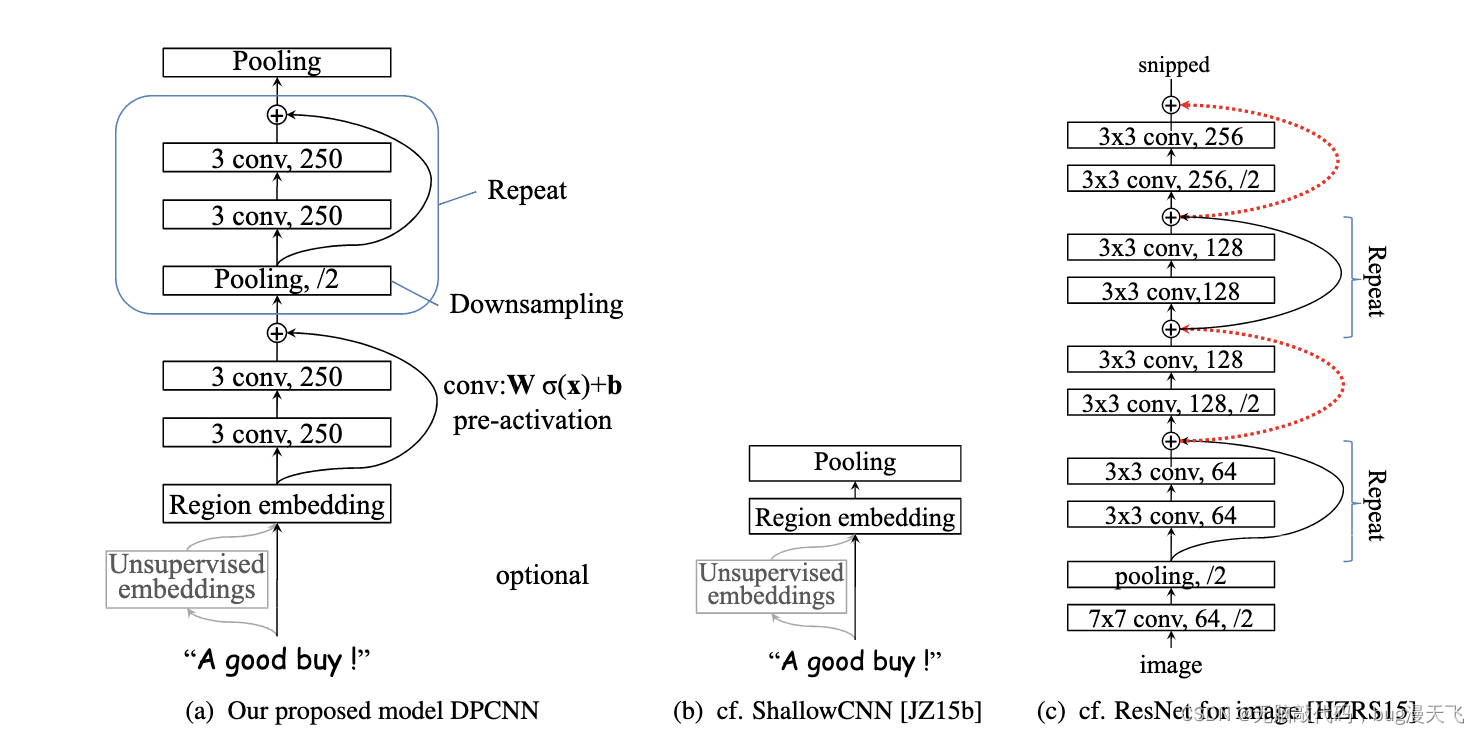
想要克服TextCNN的缺点,捕获长距离模式,显然就要用到深层CNN,更大的感受野。
堆叠卷积形式:
假设输入的序列长度为n,卷积核大小为m,步长(stride)为s,输入序列两端各填补p个零(zero padding):
则卷积层输出的序列为(n-m+2p)/s + 1
(1)窄卷积:步长s=1,两端不补0,即p=0,卷积后输出长度为n-m+1;
(2)宽卷积:步长s=1,两端补零p= m -1,卷积后输出长度为 n + m -1;
(3) 等长卷积:步长s = 1,两端补零 p = (m-1)/2,卷积后输出长度为n;
如上图首先堆叠了两层等长卷积;
池化:
选用两层等长卷积来提高embdding 的丰富性,然后接下来就是downsampling(池化)
再每一个卷积块(两层的等长卷积)后,使用一个 size=3 和 stride=2 进行 maxpooling 进行池化。
序列的长度就被压缩成了原来的一半,其能够感知到的文本片段就比之前长了一倍。
实验发现增加 feature map 的数量只会大大增加计算时间,而没有提高精度。
残差连接:
DPCNN里的Block里加上了shortcut connection
每个block的输入在初始阶段容易是0而无法激活,那么直接用一条线把region embedding层连接到每个block的输入乃至最终的池化层/输出层。
详细讲解请看链接:DPCNN 模型详解 - 知乎
6 Transformer
Transformer,这是一个摒弃递归的模型架构,而完全依靠注意力机制来得出输入和输出之间的全局依赖关系。Transformer显著提高了模型的并行化程度。
编码器+解码器模型
编码器是由6个相同的层堆叠而成的(2个子层,Multi-head attention 和Feed Forward Network)。
每层有两个子层。第一层是一个多头自注意力机制,第二层是一个简单的全连接前馈神经网络。并且两个子层都采用了残差连接,并进行层的归一化。
解码器也是由6个相同层的堆叠而成(3个子层,Multi-head attention ,cross-attention和Feed Forward Network)。
除了编码器层的两个子层之外,解码器还插入了第三个子层,它对编码器隐层的输出采用多头注意力机制。与编码器类似,在每个子层都采用残差连接,然后进行层的归一化(LayerNorm)。
论文解码器中的第一个子层为多头自注意力层(使用了mask机制,用该技术实现并行操作),以防止解码时关注后面位置的单词。
并且在模型训练时,在解码端使用错位输入与输出(比如总共需要预测n个单词,将该预测句子加入开始符和结束符,长度变为n+2,向解码器端输入前n+1个单词,解码器端预测输出后n+1个单词),采用这种这种屏蔽和错位机制,确保对位置i的预测只取决于小于i的位置的已知输出。
解码器的第二个子层交叉注意力层(cross-attention)解码端的每一层与编码端的最后输出层做cross-attention.