《算法系列》之设计
简介
为啥要把设计类型题放到最后来讲呢,因为我们见识了常见的数据类型与算法后,我们还是需要回到编程的本质:解决问题。自己设计需求,解决需求的行为,也许看上去很酷,但其实行为多少有点蠢,我们需要落到实地去解决我们的问题。这类题也是面试常考类型之一,因为更加开放,更加具有不确定性,能更好测出面试者的水平。这里有个小技巧,我们一般做设计题时,用一个数据结构能简单做出来的题,最多是中等题,一般需要算法加数据结构一起才能完成的设计题才是困难类的。
理论基础
设计这个标签里的问题,是需要我们结合问题的场景,利用我们已经学习过的数据结构组装成一个新的,适用于当前问题场景的数据结构。如果非要说什么理论基础的话,那数据结构很重要,其次就是之前涉及的大多数算法。因为出题者的可操作型太大了,今天设计一个限流的,明天设计一个负载的,能找出什么规律和模板吗?找不到的,重点就是,之前学习的所有内容都是重点,再一点就是实现能力,有时我们知道怎么实现,但考察的范围实在太广,刚好考到自己的薄弱处,就完不成了,所以我们还是需要熟悉书写各类代码才行。
leetcode上的所有题,包括设计题都有一个缺点,太直白了。有时从题目都能看出,我们需要用什么知识去解决我们的题目。这其实就像学术派一样,或像公式题一样,而我们面试或工作时大概率面临的是应用题,需要抽象后根据题目,去选择合适的数据结构与算法。这就需要,我们要有一定的抽象能力,在leetcode上面可能这项能力,得不到很好的锻炼,但我们自己下来学习的时候也需要注意这方向的一个发展。
解题心得
- 设计类型题很考综合能力,尤其特别需要熟知各种数据结构。
- 有时需要一定的抽象能力,并选择合适的数据结构去解决问题。
- 看过某些源码,对设计类相当有帮助,你会发现,原来自己实现的就是简易版的源码。
- 设计类的题,比较考代码熟练能力。
- 普意上的设计题,需要我们有一定的抽象能力与解决问题的能力。
算法题目
146. LRU 缓存
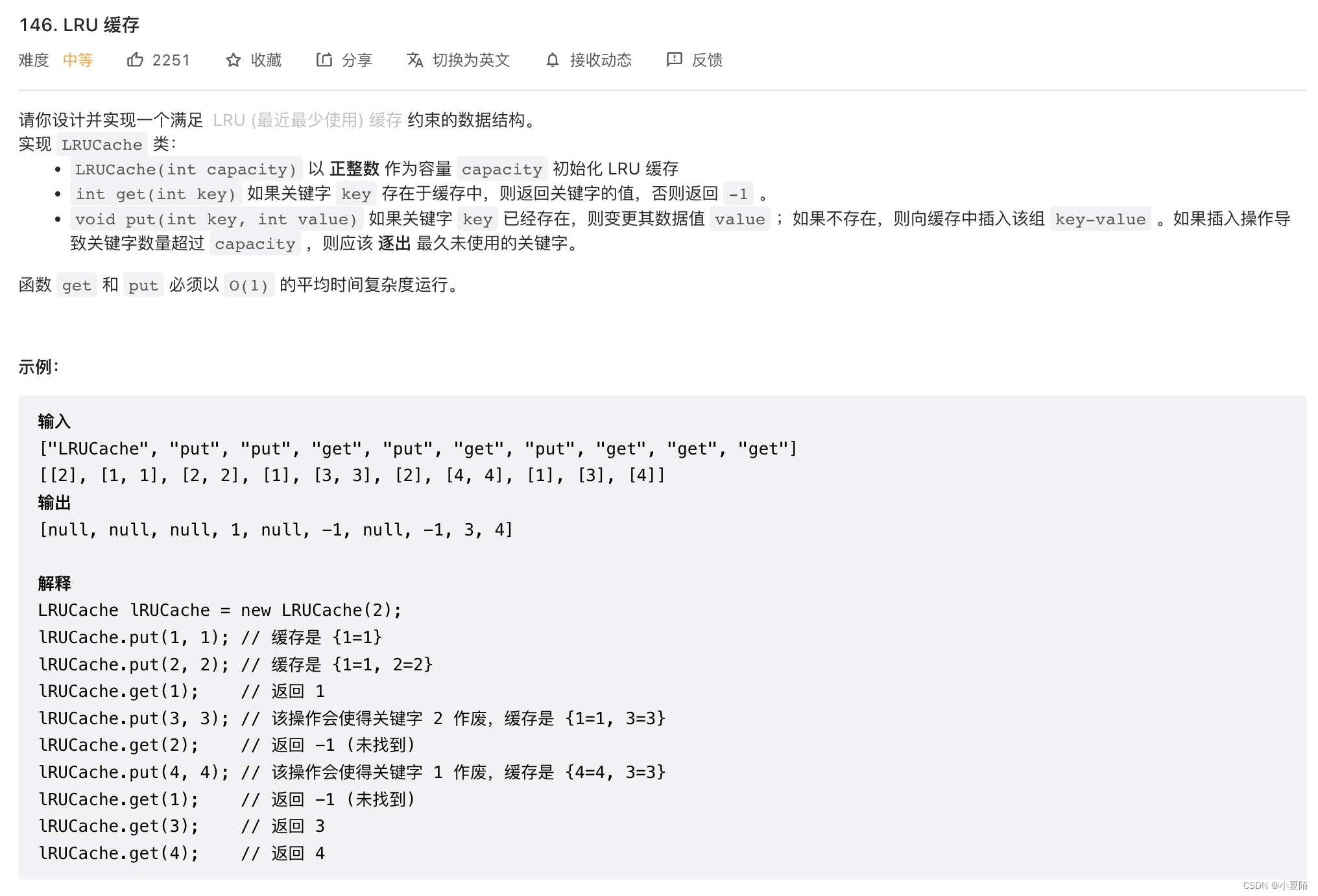
题目解析:这是一道面试常考题,借助哈希表赋予了链表快速查找的特性,然后使用链表,可以快速实现LRU(最近最少使用)缓存算法。
代码如下:
/**
* 哈希表、双向链表
*
*/
class LRUCache{
class Node {
int value;
Node prev;
Node next;
public Node() {
}
public Node(int _value) {
value = _value;
}
}
int cap;
int size;
// 用数组优化HashMap,因为值范围固定,且数组更快
// 索引为key,值为value的hashMap
Node[] map = new Node[10001];
// 双向链表,两个方向
Node head;
Node tail;
public LRUCache(int capacity) {
cap = capacity;
size = capacity;
head = new Node();
tail = new Node();
head.next = tail;
tail.prev = head;
size = 0;
}
public int get(int key) {
Node node = map[key];
if (node == null || node.value == -1) return -1;
// 被查找后,删除,再添加,相当于更新为最新位置
remove(node);
addHead(node);
return node.value;
}
public void put(int key, int value) {
// 为空添加后,如果超长,需要删除旧的
if (map[key] == null || map[key].value == -1) {
Node node = new Node(value);
addHead(node);
if (size == cap) removeTail();
else ++size;
map[key] = node;
// 若已存在,更新为最新值,和最新位置
} else {
map[key].value = value;
remove(map[key]);
addHead(map[key]);
}
}
public void remove(Node node) {
node.prev.next = node.next;
node.next.prev = node.prev;
}
public void addHead(Node node) {
node.next = head.next;
node.prev = head;
head.next.prev = node;
head.next = node;
}
public void removeTail() {
Node last = tail.prev.prev;
last.next.value = -1;
last.next = tail;
tail.prev = last;
}
}
/**
* Your LRUCache object will be instantiated and called as such:
* LRUCache obj = new LRUCache(capacity);
* int param_1 = obj.get(key);
* obj.put(key,value);
*/
155. 最小栈
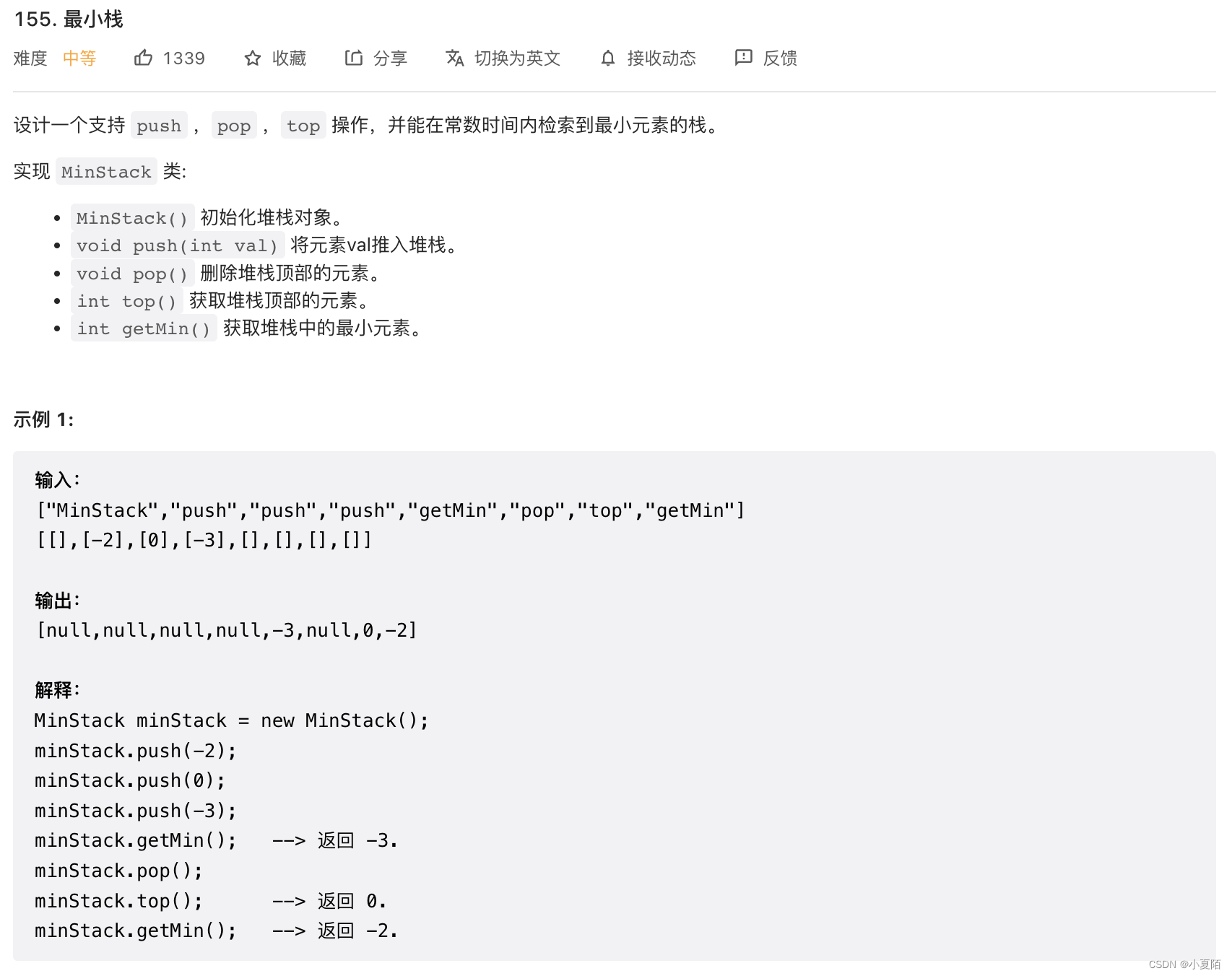
题目解析:用链表,每个节点存储时,把该节点情况下最小值也存进去即可。
代码如下:
/**
* 链表
*/
class MinStack {
private Node head;
public void push(int x) {
if(head == null)
head = new Node(x, x);
else
head = new Node(x, Math.min(x, head.min), head);
}
public void pop() {
head = head.next;
}
public int top() {
return head.val;
}
public int getMin() {
return head.min;
}
private class Node {
int val;
int min;
Node next;
private Node(int val, int min) {
this(val, min, null);
}
private Node(int val, int min, Node next) {
this.val = val;
this.min = min;
this.next = next;
}
}
}
/**
* Your MinStack object will be instantiated and called as such:
* MinStack obj = new MinStack();
* obj.push(val);
* obj.pop();
* int param_3 = obj.top();
* int param_4 = obj.getMin();
*/
173. 二叉搜索树迭代器

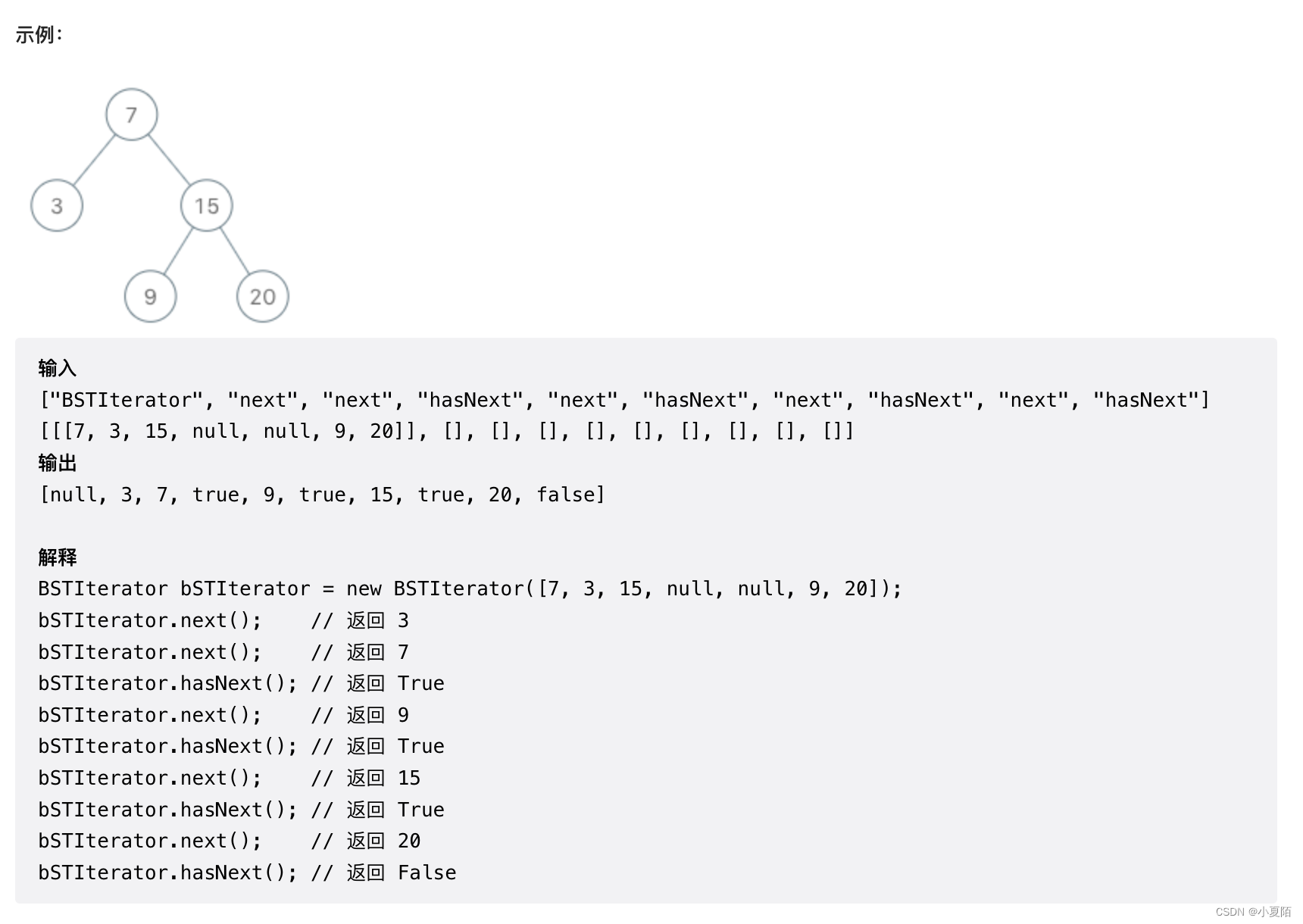
题目解析:用栈做中序迭代。
代码如下:
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode() {}
* TreeNode(int val) { this.val = val; }
* TreeNode(int val, TreeNode left, TreeNode right) {
* this.val = val;
* this.left = left;
* this.right = right;
* }
* }
*/
/**
* 二叉树
*/
class BSTIterator {
Deque<TreeNode> stack;
// 思路:因为要中序遍历,所以把根节点先入栈然后入栈左孩子,每当输出一个节点后把那个节点的右孩子以及右孩子的所有左边的孩子加入进栈(想象递归的思想,空间复杂度O(h):因为最多存入树的高度个节点)
public BSTIterator(TreeNode root) {
stack = new LinkedList<>();
TreeNode t = root;
while(t!=null){ // 初始化栈:把根节点和根节点的所有左孩子及左孩子的左孩子加入进栈
stack.addLast(t);
t = t.left;
}
}
public int next() {
TreeNode t = stack.pollLast();
int res = t.val;
if(t.right!=null){ // 把取出节点的右孩子和右孩子的所有左孩子及左孩子的左孩子加入进栈
stack.addLast(t.right);
t = t.right.left;
while(t!=null){
stack.addLast(t);
t = t.left;
}
}
return res;
}
public boolean hasNext() {
return !stack.isEmpty();
}
}
/**
* Your BSTIterator object will be instantiated and called as such:
* BSTIterator obj = new BSTIterator(root);
* int param_1 = obj.next();
* boolean param_2 = obj.hasNext();
*/
208. 实现 Trie (前缀树)
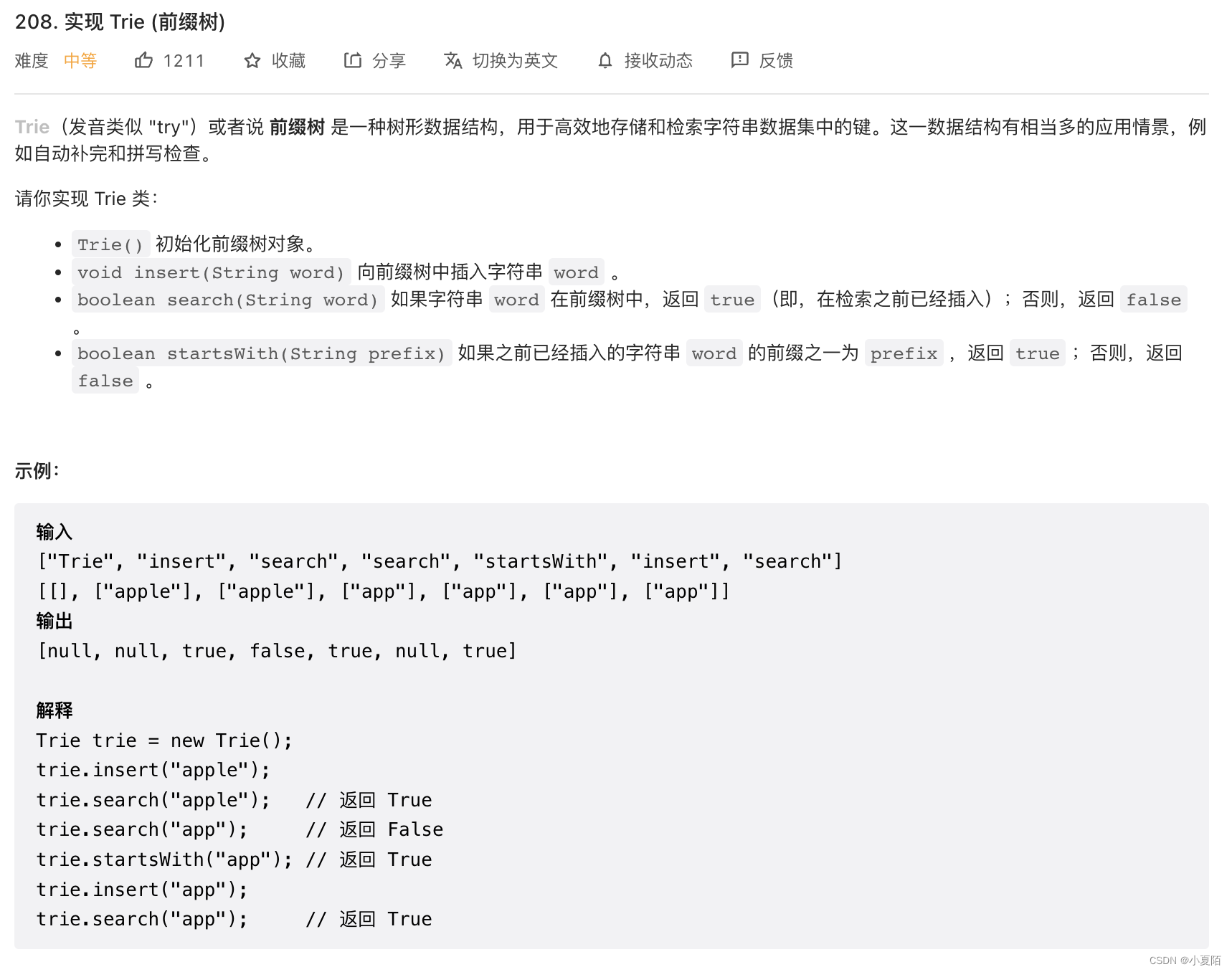
题目解析:用数组实现字典树。
代码如下:
/**
* 设计
*/
class Trie {
private class TrieNode { // 每个节点最多有26个不同的小写字母
private boolean isEnd;
private TrieNode[] next;
public TrieNode() {
isEnd = false;
next = new TrieNode[26];
}
}
private TrieNode root;
/** Initialize your data structure here. */
public Trie() {
root = new TrieNode();
}
/** Inserts a word into the trie. */
public void insert(String word) {
TrieNode cur = root;
for (int i = 0, len = word.length(), ch; i < len; i++) {
ch = word.charAt(i) - 'a';
if (cur.next[ch] == null)
cur.next[ch] = new TrieNode();
cur = cur.next[ch];
}
cur.isEnd = true; // 加上一个标记,表示为一个单词
}
/** Returns if the word is in the trie. */
public boolean search(String word) {
TrieNode cur = root;
for (int i = 0, len = word.length(), ch; i < len; i++) {
ch = word.charAt(i) - 'a';
if (cur.next[ch] == null)
return false;
cur = cur.next[ch];
}
return cur.isEnd;
}
/**
* Returns if there is any word in the trie that starts with the given prefix.
*/
public boolean startsWith(String prefix) {
TrieNode cur = root;
for (int i = 0, len = prefix.length(), ch; i < len; i++) {
ch = prefix.charAt(i) - 'a';
if (cur.next[ch] == null)
return false; // 若还没遍历完给定的前缀子串,则直接返回false
cur = cur.next[ch];
}
return true; // 直接返回true
}
}
/**
* Your Trie object will be instantiated and called as such:
* Trie obj = new Trie();
* obj.insert(word);
* boolean param_2 = obj.search(word);
* boolean param_3 = obj.startsWith(prefix);
*/
211. 添加与搜索单词 - 数据结构设计
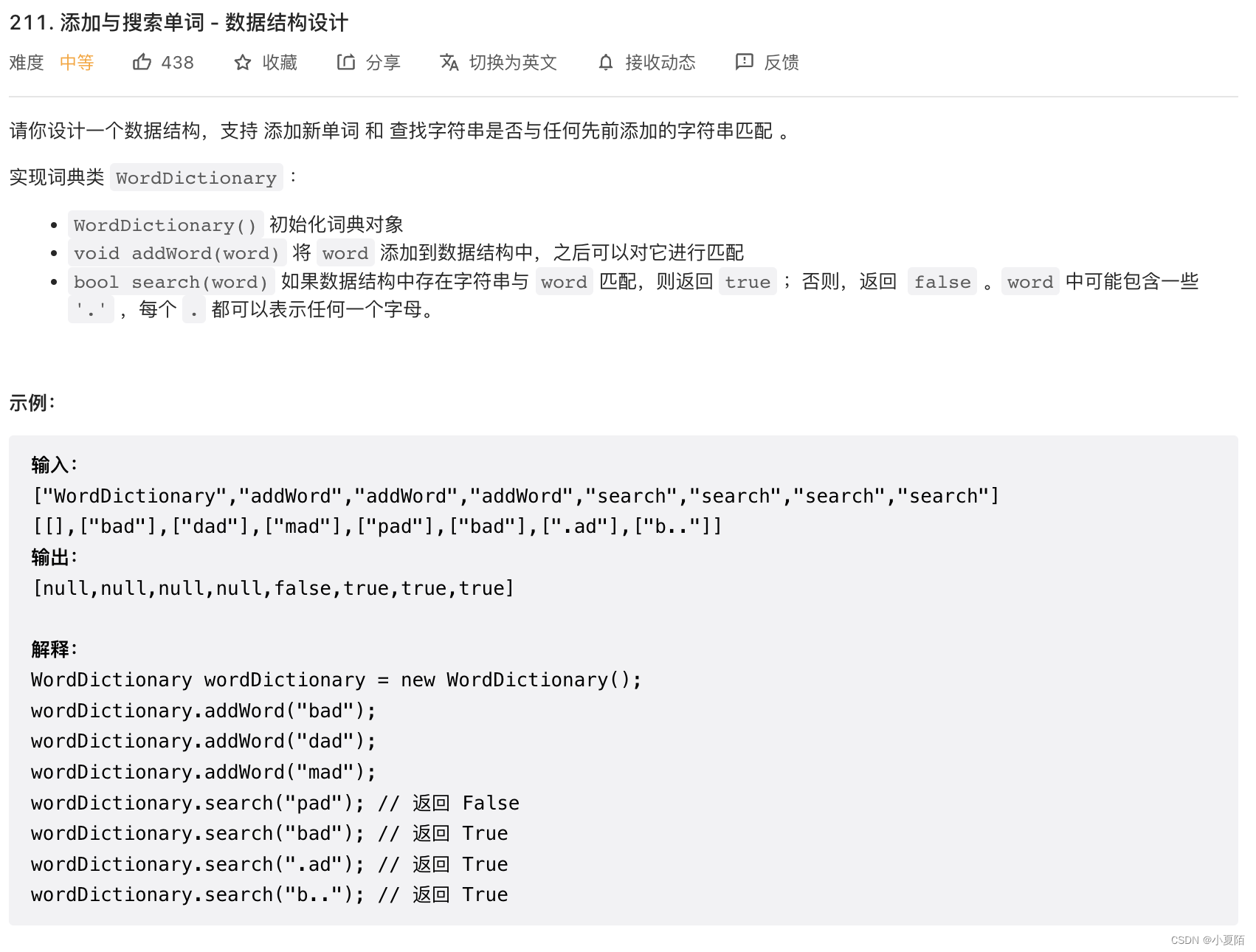
题目解析:字典树与208.实现 Trie (前缀树)大同小异,只需要对.单独处理就可以了。
代码如下:
/**
* 设计
*/
class WordDictionary {
private WordDictionary[] items;
boolean isEnd;
public WordDictionary() {
items = new WordDictionary[26];
}
public void addWord(String word) {
WordDictionary curr = this;
int n = word.length();
for(int i = 0; i < n; i++){
int index = word.charAt(i) - 'a';
if(curr.items[index] == null)
curr.items[index] = new WordDictionary();
curr = curr.items[index];
}
curr.isEnd = true;
}
public boolean search(String word) {
return search(this, word, 0);
}
private boolean search(WordDictionary curr, String word, int start){
int n = word.length();
if(start == n)
return curr.isEnd;
char c = word.charAt(start);
if(c != '.'){
WordDictionary item = curr.items[c - 'a'];
return item != null && search(item, word, start + 1);
}
for(int j = 0; j < 26; j++){
if(curr.items[j] != null && search(curr.items[j], word, start + 1))
return true;
}
return false;
}
}
/**
* Your WordDictionary object will be instantiated and called as such:
* WordDictionary obj = new WordDictionary();
* obj.addWord(word);
* boolean param_2 = obj.search(word);
*/
225. 用队列实现栈
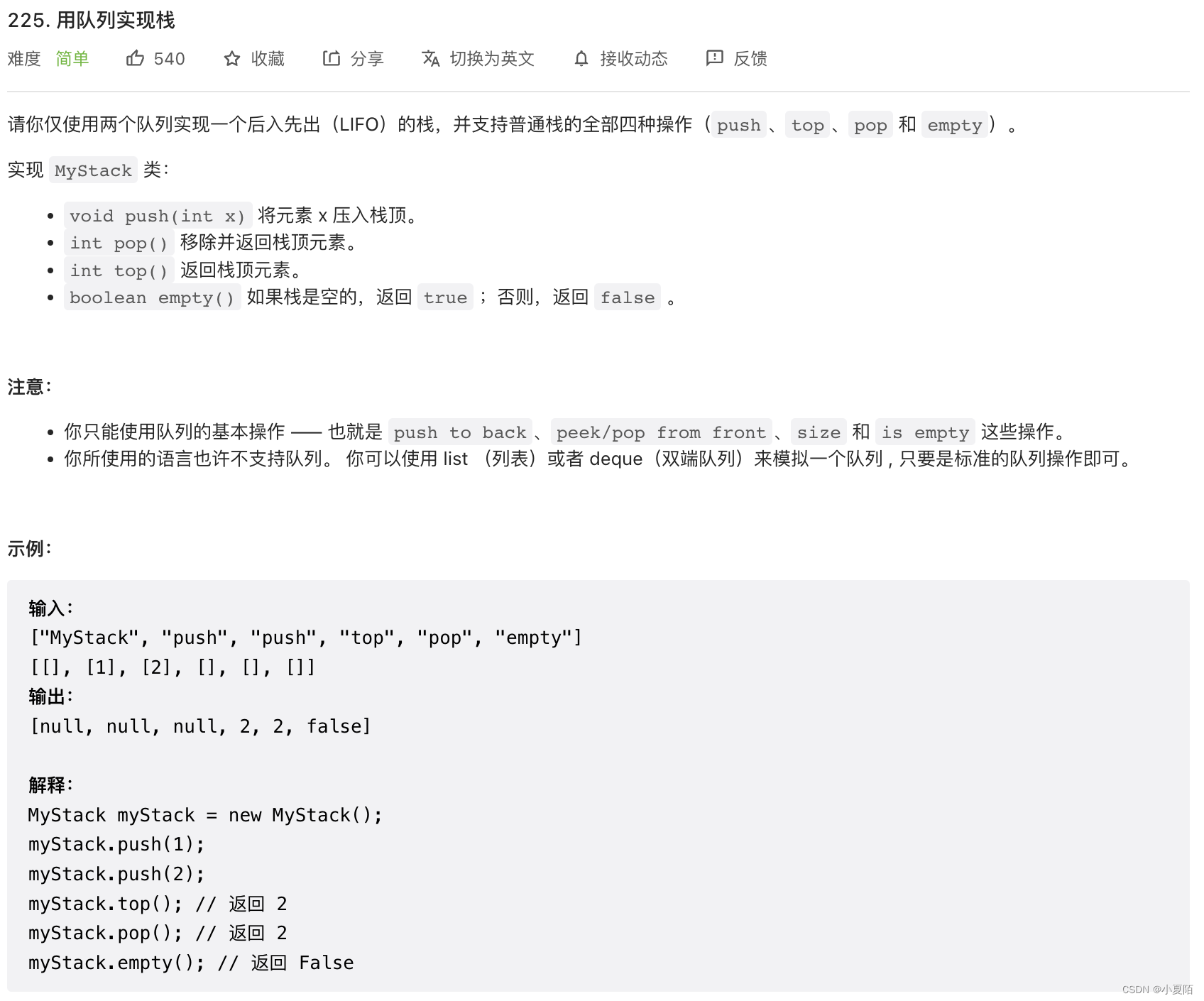
题目解析:用一个队列或两个队列都可以实现,一个队列的情况:每次删除栈顶,把除出栈值外,全部再次添加到队尾,再删除出栈值。两个队列情况:一个队列做备份用,每次添加新元素,都把除新元素外其它元素重添加入队尾。
代码如下:
/**
* 队列
*/
class MyStack {
private Queue<Integer> inQ; // 输入队列
private Queue<Integer> outQ; // 输出队列
public MyStack() {
inQ = new LinkedList<>();
outQ = new LinkedList<>();
}
public void push(int x) {
inQ.offer(x);
// 把outQ中元素全部转到inQ队列
while (!outQ.isEmpty()) {
inQ.offer(outQ.poll());
}
// 交换两队列
Queue temp = inQ;
inQ = outQ;
outQ = temp;
}
public int pop() {
return outQ.poll();
}
public int top() {
return outQ.peek();
}
public boolean empty() {
return outQ.isEmpty();
}
}
/**
* Your MyStack object will be instantiated and called as such:
* MyStack obj = new MyStack();
* obj.push(x);
* int param_2 = obj.pop();
* int param_3 = obj.top();
* boolean param_4 = obj.empty();
*/
232. 用栈实现队列

题目解析:用两个栈,相互导,可以实现队列。
代码如下:
/**
* 栈
*/
class MyQueue {
private Stack<Integer> inStack; // 输入栈
private Stack<Integer> outStack; // 输出栈
public MyQueue() {
inStack = new Stack<>();
outStack = new Stack<>();
}
public void push(int x) {
inStack.push(x);
}
public int pop(){
// 如果outStack栈为空,则将inStack栈全部弹出并压入b栈中,然后outStack.pop()
if (outStack.isEmpty()) {
while (!inStack.isEmpty()) {
outStack.push(inStack.pop());
}
}
return outStack.pop();
}
public int peek() {
if (outStack.isEmpty()) {
while (!inStack.isEmpty()) {
outStack.push(inStack.pop());
}
}
return outStack.peek();
}
public boolean empty() {
return inStack.isEmpty() && outStack.isEmpty();
}
}
/**
* Your MyQueue object will be instantiated and called as such:
* MyQueue obj = new MyQueue();
* obj.push(x);
* int param_2 = obj.pop();
* int param_3 = obj.peek();
* boolean param_4 = obj.empty();
*/
284. 顶端迭代器

题目解析:最直观的做法是使用一个列表存储迭代器中的每个元素,然后按顺序遍历列表中的元素模拟迭代器。
代码如下:
/**
* 迭代器
*/
class PeekingIterator implements Iterator<Integer> {
private Iterator<Integer> iterator;
private Integer nextElement;
public PeekingIterator(Iterator<Integer> iterator) {
this.iterator = iterator;
nextElement = iterator.next();
}
public Integer peek() {
return nextElement;
}
@Override
public Integer next() {
Integer ret = nextElement;
nextElement = iterator.hasNext() ? iterator.next() : null;
return ret;
}
@Override
public boolean hasNext() {
return nextElement != null;
}
}
295. 数据流的中位数

题目解析:我们用两个优先队列 queMax 和 queMin 分别记录大于中位数的数和小于等于中位数的数。当累计添加的数的数量为奇数时,queMin 中的数的数量比 queMax 多一个,此时中位数为 queMin 的队头。当累计添加的数的数量为偶数时,两个优先队列中的数的数量相同,此时中位数为它们的队头的平均值。
代码如下:
/**
* 优先队列
*/
class MedianFinder {
PriorityQueue<Integer> queMin;
PriorityQueue<Integer> queMax;
public MedianFinder() {
queMin = new PriorityQueue<Integer>((a, b) -> (b - a));
queMax = new PriorityQueue<Integer>((a, b) -> (a - b));
}
public void addNum(int num) {
if (queMin.isEmpty() || num <= queMin.peek()) {
queMin.offer(num);
if (queMax.size() + 1 < queMin.size()) {
queMax.offer(queMin.poll());
}
} else {
queMax.offer(num);
if (queMax.size() > queMin.size()) {
queMin.offer(queMax.poll());
}
}
}
public double findMedian() {
if (queMin.size() > queMax.size()) {
return queMin.peek();
}
return (queMin.peek() + queMax.peek()) / 2.0;
}
}
297. 二叉树的序列化与反序列化
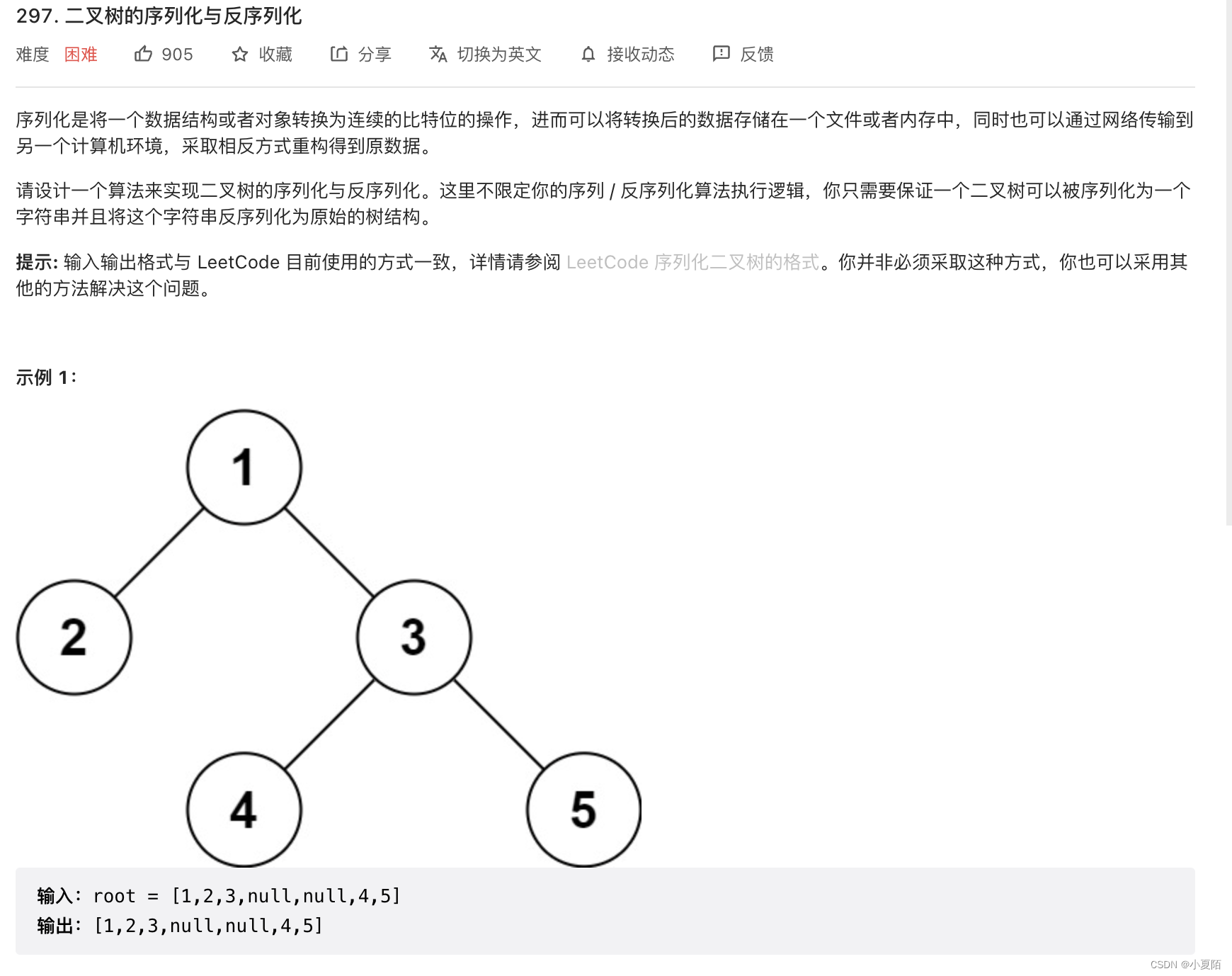
题目解析:二叉树的序列化本质上是对其值进行编码,更重要的是对其结构进行编码。可以遍历树来完成上述任务。
代码如下:
/**
* 深度优先搜索
*/
public class Codec {
public String serialize(TreeNode root) {
return rserialize(root, "");
}
public TreeNode deserialize(String data) {
String[] dataArray = data.split(",");
List<String> dataList = new LinkedList<String>(Arrays.asList(dataArray));
return rdeserialize(dataList);
}
public String rserialize(TreeNode root, String str) {
if (root == null) {
str += "None,";
} else {
str += str.valueOf(root.val) + ",";
str = rserialize(root.left, str);
str = rserialize(root.right, str);
}
return str;
}
public TreeNode rdeserialize(List<String> dataList) {
if (dataList.get(0).equals("None")) {
dataList.remove(0);
return null;
}
TreeNode root = new TreeNode(Integer.valueOf(dataList.get(0)));
dataList.remove(0);
root.left = rdeserialize(dataList);
root.right = rdeserialize(dataList);
return root;
}
}
回到首页
刷 leetcode 500+ 题的一些感受