【博客484】alertmanager-----告警处理源码剖析
alertmanager-----告警处理源码剖析
alertmanager整体处理流程
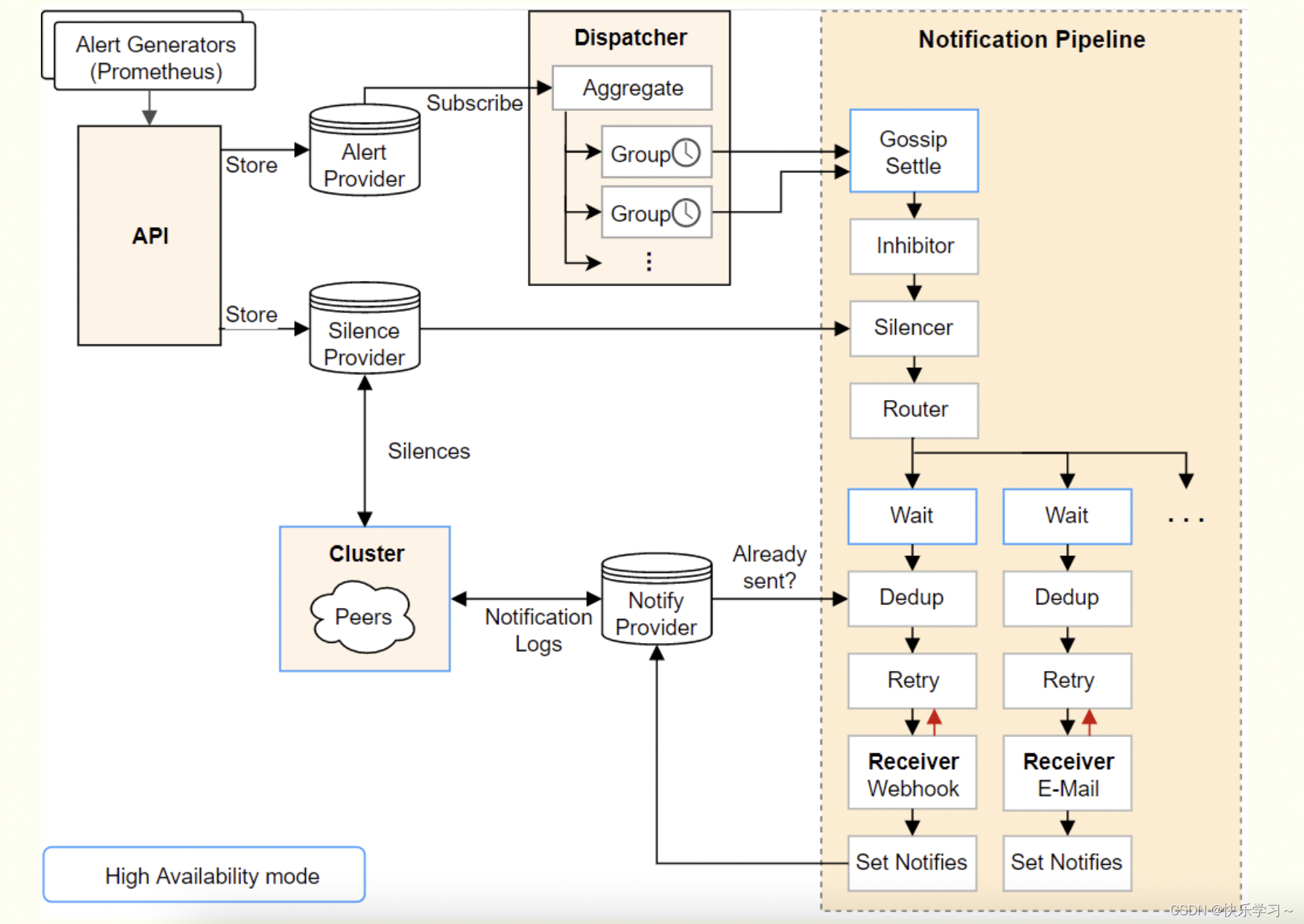
本文重点讲Dedup(去重)和Wait(等待同步)
Dedup:保证一条告警在正常情况下只会由集群内的一个节点发出,不会重复发送
Wait:保证了正常情况下,在集群有节点发送告警后,在同步给其它节点的期间,其它节点又把告警重复发了一次
Wait(等待同步)
WaitStage
顾名思义,WaitStage表示向其他实例发送Notification Log的时间间隔,只是单纯的时间等待。
官方源码解释:
clusterWait returns a function that inspects the current peer state and returns
a duration of one base timeout for each peer with a higher ID than ourselves.
即:clusterWait 返回一个检查当前对等体状态的函数并返回对于 ID 比我们自己高的每个对等点,
一个基本超时的持续时间。
// Exec implements the Stage interface.
func (ws *WaitStage) Exec(ctx context.Context, _ log.Logger, alerts ...*types.Alert) (context.Context, []*types.Alert, error) {
select {
case <-time.After(ws.wait()):
case <-ctx.Done():
return ctx, nil, ctx.Err()
}
return ctx, alerts, nil
}
// clusterWait returns a function that inspects the current peer state and returns
// a duration of one base timeout for each peer with a higher ID than ourselves.
func clusterWait(p *cluster.Peer, timeout time.Duration) func() time.Duration {
return func() time.Duration {
return time.Duration(p.Position()) * timeout
}
}
// Position returns the position of the peer in the cluster.
func (p *Peer) Position() int {
all := p.mlist.Members()
sort.Slice(all, func(i, j int) bool {
return all[i].Name < all[j].Name
})
k := 0
for _, n := range all {
if n.Name == p.Self().Name {
break
}
k++
}
return k
}
解析:
各个实例发送Notification Log的时长并不一样,它与p.Position()的返回值有关,timeout默认是15s。
p.Position()返回的是当前的alertmanager实例的编号,每个alertmanager等待的时间:
编号 * timeout(默认是15s)
Dedup(去重)
对startsAt和endsAt的处理
startsAt和endsAt这两个字段,这两个字段分别表示告警的起始时间和终止时间,不过两个字段都是可选的。当AlertManager收到告警实例之后,会分以下几类情况对这两个字段进行处理:
1、两者都存在:不做处理
2、两者都未指定:startsAt指定为当前时间,endsAt为当前时间加上告警持续时间,默认为5分钟
3、只指定startsAt:endsAt指定为当前时间加上默认的告警持续时间
4、只指定endsAt:将startsAt设置为endsAt
即:如果 endsAt 没有提供,则自动等于 startsAt + resolve_timeout(默认 5m)
AlertManager一般以当前时间和告警实例的endsAt字段进行比较用以判断告警的状态:
* 若当前时间位于endsAt之前,则表示告警仍然处于触发状态(firing)
* 若当前时间位于endsAt之后,则表示告警已经消除(resolved)
为什么一直触发的告警不会触发恢复,而触发的告警一旦采集不到,尽管仍是触发的,也会触发恢复
如果告警一直 Firing,那么 Prometheus 会在 resend_delay 的间隔重复发送,而 startsAt 保持不变, endsAt 跟着 ValidUntil 变,这也就是为啥一直firing的规则不会被认为恢复,而不发firting则会认为恢复。
因为一直firing的告警消息中, endsAt 跟着 ValidUntil 变,一直在后延。而如果没收到,就会导致alertmanger那边在过了告警的endAt时间后,没收到恢复或者新firing,则认为恢复
注意:Alertmanager 里必须有 Inactive 消息所对应的告警,否则是会被忽略的。换句话说如果一个告警在 Alertmanager 里已经解除了,再发同样的 Inactive 消息,Alertmanager 是不会发给 webhook 的。
Prometheus 需要 持续 地将 Firing 告警发送给 Alertmanager,遇到以下一种情况,Alertmanager 会认为告警已经解决,发送一个 resolved:
* Prometheus 发送了 Inactive 的消息给 Alertmanager,即 endsAt=当前时间
* Prometheus 在上一次消息的 endsAt 之前,一直没有发送任何消息给 Alertmanager