机器学习模型1——线性回归和逻辑回归
前置知识
最大似然估计
最小二乘法
梯度下降算法
高斯分布
主要内容

注意:下面的w和θ指的都是自变量的斜率。
线性回归
利⽤回归⽅程(函数)对⼀个或多个⾃变量(特征值)和因变量(⽬标值)之间关系进⾏建模的⼀种分析⽅式。
目的:试图学的一个线性模型以尽可能准确低预测实值输出标记。
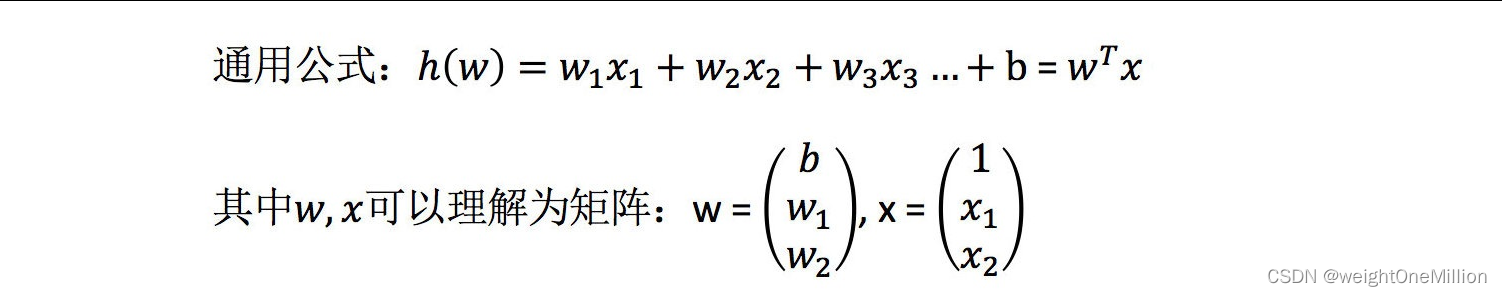
只有⼀个⾃变量的情况称为单变量回归,多于⼀个⾃变量情况的叫做多元回归。
根据已知的样本空间X,可以利用最小二乘法对线性回归方程中的w和b进行估计。
最小二乘法的形式:标函数(损失函数)=∑ (观测值 - 预测值)^2
线性回归的最小二乘法表示形式: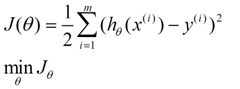
此处加上1/2是为了求导时消掉。
可以用正规方程(MLE+正规方程,最小二乘法的矩阵求解)或者梯度下降算法求解。
最小二乘法(利用MLE)求解

梯度下降求解

防止过拟合

线性回归API
经典的线性回归API
linear_model.LinearRegression(*[, ...]) Ordinary least squares Linear Regression(普通最小二乘线性回归).
linear_model.Ridge([alpha, fit_intercept, ...]) Linear least squares with l2 regularization.
linear_model.RidgeCV([alphas, ...]) Ridge regression with built-in cross-validation.
linear_model.SGDRegressor([loss, penalty, ...]) Linear model fitted by minimizing a regularized empirical loss with SGD.
以普通最小线性回归为例,介绍sklearn线性回归API的使用。
普通的最小线性回归通过正规方程优化。
class sklearn.linear_model.LinearRegression(*, fit_intercept=True, normalize='deprecated', copy_X=True, n_jobs=None, positive=False)
参数:
- fit_intercept: bool, default=True
是否计算此模型的截距。如果设置为False,则计算中将不使用截距(即数据预计居中)。 - normalize: bool,default=False
当fit_intercept设置为False时,将忽略此参数。如果为True,回归系数X将在回归之前通过减去平均值并除以l2范数进行标准化。如果您希望标准化,请在对normalize=False的估计器调用fit之前使用StandardScaler。
不推荐使用,因为版本1.0:normalize在版本1.0中已被弃用,并将在1.2中删除。 - copy_X: bool,default=True
如果为True,将复制X;否则,它可能会被覆盖。 - n_jobs: int,default=无
用于计算的作业数。这只会在出现足够大的问题时提供加速,即如果第一个n_targets>1,第二个X是稀疏的,或者如果正值设置为True。除非在作业库中,否则无表示1。parallel_backend上下文-1表示使用所有处理器。 - positive: bool,default=False
设置为True时,强制系数为正值。仅密集阵列支持此选项。
属性:
- coef_: array of shape (n_features, ) or (n_targets, n_features)
线性回归问题的估计系数。如果在拟合期间传递多个目标(y 2D),这是一个2D形状数组(n_targets,n_features),而如果只传递一个目标,这是长度n_feetures的1D数组。 - rank_: int
矩阵X的秩。仅当X稠密时可用。 - singular_: array of shape (min(X, y),)
X的奇异值仅在X稠密时可用。 - intercept_: float or array of shape (n_targets,)
线性模型中的独立项。如果fit_intercept=False,则设置为0.0。 - n_features_in_: int
装配过程中看到的特征数量。版本0.24中的新增功能。 - feature_names_in_: ndarray of shape (n_features_in_,)
配合期间看到的特征名称。仅当X具有全部为字符串的要素名称时才定义。
通过SGD优化
sklearn.linear_model.SGDRegressor(loss="squared_loss", fit_intercept=True, learning_rate ='invscaling', eta0=0.01)
SGDRegressor类实现了随机梯度下降学习,它⽀持不同的loss函数和正则化惩罚项来拟合线性回归模型。
参数:
loss:损失类型
- loss=”squared_loss”: 普通最⼩⼆乘法
fit_intercept:是否计算偏置
learning_rate : string, optional
- 学习率填充
- 'constant': eta = eta0
- 'optimal': eta = 1.0 / (alpha * (t + t0)) [default]
- 'invscaling': eta = eta0 / pow(t, power_t)
- power_t=0.25:存在⽗类当中
- 对于⼀个常数值的学习率来说,可以使⽤learning_rate=’constant’ ,并使⽤eta0来指定学习率。
属性:
coef_:回归系数
intercept_:偏置
改进的线性回归——岭回归
sklearn.linear_model.Ridge(alpha=1.0, fit_intercept=True,solver="auto", normalize=False)
具有l2正则化的线性回归
alpha:正则化⼒度,也叫 λ
- λ取值:0~1 1~10 正则化⼒度越⼤,权重系数会越⼩
solver:会根据数据⾃动选择优化⽅法
- sag:如果数据集、特征都⽐较⼤,选择该随机梯度下降优化
normalize:数据是否进⾏标准化
- normalize=False:可以在fit之前调⽤preprocessing.StandardScaler标准化数据
Ridge.coef_:回归权重 Ridge.intercept_:回归偏置
Ridge⽅法相当于SGDRegressor(penalty='l2', loss="squared_loss"),只不过SGDRegressor实现了⼀个普通的随机 梯度下降学习,推荐使⽤Ridge(实现了SAG)
sklearn.linear_model.RidgeCV(_BaseRidgeCV, RegressorMixin)
具有l2正则化的线性回归,可以进⾏交叉验证
coef_:回归系数
逻辑回归----分类——二分类——》单位阶跃函数
如何利用线性模型进行分类任务?
将实值转换成0、1,利用对数几率函数(一种sigmod函数)替代单位阶跃函数求解0,1的值。
Logistic Regression 虽然被称为回归,但其实际上是分类模型,并常用于二分类。
引入sigmod函数: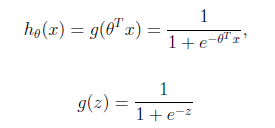

利用梯度下降法或者牛顿法可以更快的收敛,求极值。
逻辑回归API
线性分类器
linear_model.LogisticRegression([penalty, ...])Logistic Regression (aka logit, MaxEnt) classifier.
linear_model.LogisticRegressionCV(*[, Cs, ...])Logistic Regression CV (aka logit, MaxEnt) classifier.
linear_model.PassiveAggressiveClassifier(*)Passive Aggressive Classifier.
linear_model.Perceptron(*[, penalty, alpha, ...])Linear perceptron classifier.
linear_model.RidgeClassifier([alpha, ...])Classifier using Ridge regression.
linear_model.RidgeClassifierCV([alphas, ...])Ridge classifier with built-in cross-validation.
linear_model.SGDClassifier([loss, penalty, ...])Linear classifiers (SVM, logistic regression, etc.) with SGD training.
linear_model.SGDOneClassSVM([nu, ...])Solves linear One-Class SVM using Stochastic Gradient Descent.
以逻辑回归分类器为例。
class sklearn.linear_model.LogisticRegression(penalty='l2', *, dual=False, tol=0.0001, C=1.0, fit_intercept=True, intercept_scaling=1, class_weight=None, random_state=None, solver='lbfgs', max_iter=100, multi_class='auto', verbose=0, warm_start=False, n_jobs=None, l1_ratio=None)
Logistic回归(又名logit,MaxEnt)分类器。
在多类情况下,如果“multi_class”选项设置为“ovr”,则训练算法使用一对多(OvR)方案,如果“multi_class’”选项设置成“multinomial”,则使用交叉熵损失。(目前,“多项式”选项仅由“lbfgs”、“sag”、”saga“和”newton cg“解算器支持。)
此类使用“liblinear”库、“newton cg”、“sag”、“saga”和“lbfgs”解算器实现正则化逻辑回归。请注意,默认情况下应用正则化。它可以处理密集和稀疏输入。使用包含64位浮点的C顺序数组或CSR矩阵以获得最佳性能;任何其他输入格式都将被转换(和复制)。
“newton-cg”、“sag”和“lbfgs”解算器仅支持原始公式的L2正则化,或不支持正则化。“liblinear”解算器支持L1和L2正则化,仅对偶公式用于L2惩罚。弹性网正则化仅由“saga”解算器支持。
参数:
- penalty: {‘l1’, ‘l2’, ‘elasticnet’, ‘none’}, default=’l2’
规定处罚标准:
‘none’:不增加处罚;
“l2”:添加l2惩罚条款,这是默认选项;
“l1”:添加一个l1处罚条款;
“弹性网”:同时添加L1和L2处罚条款。
警告: 某些惩罚可能对某些solver不起作用。 - dual: bool, default=False
双重或原始配方。对偶公式仅使用liblinear解算器实现二级惩罚。当n_samples>n_features时,首选dual=False。 - tol: float, default=1e-4
停止标准公差。 - C: float,default=1.0
正则化强度的倒数;必须是正浮点数。与支持向量机类似,较小的值指定更强的正则化。 - fit_intercept: bool,default=True
指定是否应将常数(即偏差或截距)添加到决策函数中。 - intercept_scaling: float,default=1
仅当使用解算器“liblinear”和自身时才有用。fit_intercept设置为True。在这种情况下,x变为[x,self.intercept_scaling],即将一个常量值等于intercept_scaling的“合成”特征附加到实例向量。截距变为intercept_scaling*synthetic_feature_weight。
笔记与所有其他特征一样,合成特征权重也要服从l1/l2正则化。为了减少正则化对合成特征权重(从而对截距)的影响,必须增加intercept_scaling。 - class_weight: dict或“balanced”,default=None
与{class_label:weight}形式的类关联的权重。如果没有给出,所有课程都应该有一个权重。
“平衡”模式使用y值自动调整权重,权重与输入数据中的类频率成反比,即n_samples/(n_classes*np.bincount(y))。
请注意,如果指定了sample_weight,则这些权重将与sample_tweight(通过fit方法传递)相乘。 - random_state: int, RandomState instance, default=None
当solver==“sag”、“saga”或“liblinear”时使用,以洗牌数据。 - solver: {‘newton-cg’, ‘lbfgs’, ‘liblinear’, ‘sag’, ‘saga’}, default=’lbfgs’
优化问题中使用的算法。默认值为“lbfgs”。要选择解算器,您可能需要考虑以下方面:
对于小型数据集,“liblinear”是一个不错的选择,而“sag”和“saga”对于大型数据集更快;
对于多类问题,只有“newton-cg”、“sag”、“saga”和“lbfgs”处理多项式损失;
“liblinear”仅限于一对多方案。 - max_iter: int, default=100
解算器收敛所需的最大迭代次数。 - multi-class: {‘auto’,‘ovr’,‘multinomial’},default=‘auto’
如果选择的选项是“ovr”,则每个标签都适合一个二进制问题。对于“多项式”,最小损失是整个概率分布的多项式损失拟合,即使数据是二进制的当solver='liblinear’时,多项式’不可用。'如果数据是二进制的,或者如果解算器=“线性”,auto会选择“ovr”,否则会选择“多项式”。 - verbose: int, default=0
对于liblinear和lbfgs解算器,将verbose设置为任意正数表示详细性。 - warm_start: bool,default=False
当设置为True时,重复使用前一个调用的解决方案作为初始化,否则,只需擦除前一个解决方案。不适用于liblinear解算器。请参阅术语表。 - n_jobs: int,default=None
如果multi_class=‘ovr’“,则在类上并行化时使用的CPU内核数。当解算器设置为“liblinear”时,无论是否指定了“multi_class”,都会忽略此参数。除非在作业库中,否则无表示1。parallel_backend上下文-1表示使用所有处理器。有关更多详细信息,请参阅词汇表。 - l1_ratio: float,默认值=无
弹性网混合参数,0<=l1_比率<=1。仅在惩罚=“弹性网”时使用。设置l1_tratio=0等同于使用pension=‘l2’,而设置l1_ltratio=1等同于使用fension=‘l1’。对于0<l1_tratio<1,惩罚是l1和L2的组合。
属性:
- classes_ndarray of shape (n_classes, )
分类器已知的类标签列表。 - coef_ndarray of shape (1, n_features) or (n_classes, n_features)
决策函数中的特征系数。
当给定的问题是二元时,coef的形状为(1,n特征)。特别是,当multi_class='multinomal’时,coef_对应结果1(True),-coef_对应成果0(False)。 - intercept_ndarray of shape (1,) or (n_classes,)
截距(也称为偏差)添加到决策函数中。
如果fit_intercept设置为False,则截距设置为零。当给定的问题是二进制时,intercept的形状为(1,)。特别是,当multi_class='multinomal’时,intercept_对应于结果1(True),-intercept_对应于结果0(False)。 - n_features_in_: int
装配过程中看到的特征数量。 - feature_names_in_: ndarray of shape (n_features_in_,)
配合期间看到的特征名称。仅当X具有全部为字符串的要素名称时才定义。 - n_iter_: ndarray of shape (n_classes,) or (1, )
所有类的实际迭代次数。如果是二进制或多项式,则只返回1个元素。对于liblinear解算器,只给出所有类的最大迭代次数。
方法
主要是训练fit、预测predict、打分score
decision_function(X)Predict confidence scores for samples.
densify()Convert coefficient matrix to dense array format.
fit(X, y[, sample_weight])Fit the model according to the given training data.
get_params([deep])Get parameters for this estimator.
predict(X)Predict class labels for samples in X.
predict_log_proba(X)Predict logarithm of probability estimates.
predict_proba(X)Probability estimates.
score(X, y[, sample_weight])Return the mean accuracy on the given test data and labels.
set_params(**params)Set the parameters of this estimator.
sparsify()Convert coefficient matrix to sparse format.
例子
>>> from sklearn.datasets import load_iris
>>> from sklearn.linear_model import LogisticRegression
>>> X, y = load_iris(return_X_y=True)
>>> clf = LogisticRegression(random_state=0).fit(X, y)
>>> clf.predict(X[:2, :])
array([0, 0])
>>> clf.predict_proba(X[:2, :])
array([[9.8...e-01, 1.8...e-02, 1.4...e-08],
[9.7...e-01, 2.8...e-02, ...e-08]])
>>> clf.score(X, y)
0.97...
逻辑回归的优缺点
1、优点
(1)适合分类场景
(2)计算代价不高,容易理解实现。
(3)不用事先假设数据分布,这样避免了假设分布不准确所带来的问题。
(4)不仅预测出类别,还可以得到近似概率预测。
(5)目标函数任意阶可导。
2、缺点
(1)容易欠拟合,分类精度不高。
(2)数据特征有缺失或者特征空间很大时表现效果并不好。
Softmax回归
这个还没学。

参考
1.https://www.bilibili.com/video/BV1Ca411M7KA?p=6&vd_source=c35b16b24807a6dbe33f5473659062ac
2.黑马机器学习
3.https://blog.csdn.net/qq_36330643/article/details/77649896