写对比学习损失函数有感(关于速度差异、出现nan的情况)
出现nan的情况
1、比如 loss = sum(loss[i]) / count,这个时候就要小心分母,如果分母是0的话,loss就会变成nan。
2、使用交叉熵,因为有一个log函数,要注意内部。比如,-log(fenzi / fenmu),首先分母不能为0,第二分子也不能为0(否则log(0)一样会出问题),所以最好对分子分母都加一个很小的值,比如1e-8。
运行速度
使用time.perf_counter()来计时,因为time.time()得到的是以秒为单位的时间,在这里不合适。
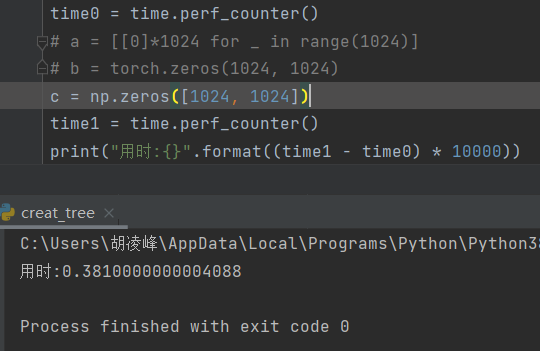
1、创建一个 1024*1024 的二维数组:
python列表:158

torch.zeros:131
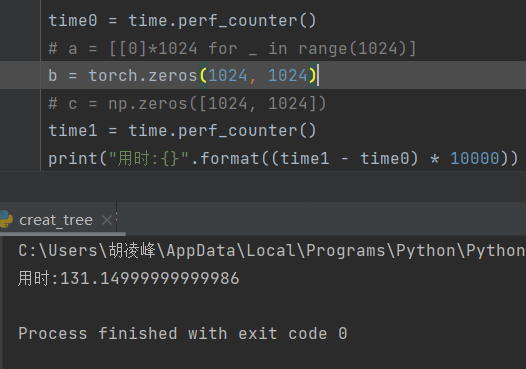
np.zeros:0.38
torch.zeros(1024, 1024).to(‘cuda’):55839
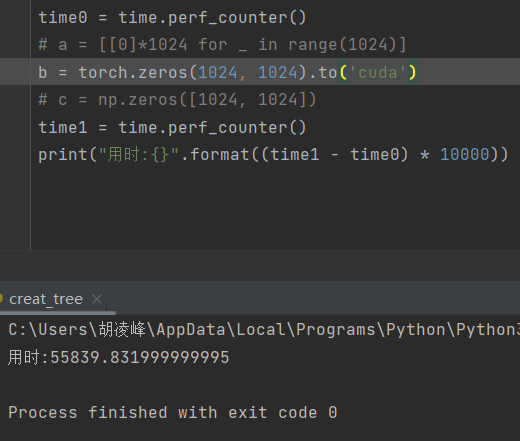
结论:如果用torch.zeros创建数组,还往cuda里放的话,速度会非常慢。最好用numpy,快好几个数量级。
2、给 1024*1024 的二维数组遍历赋值:
python自带数组:1800
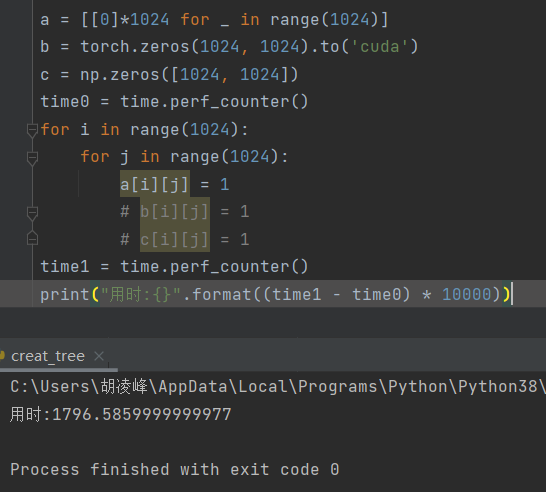
torch.tensor.to(‘cuda’):39400
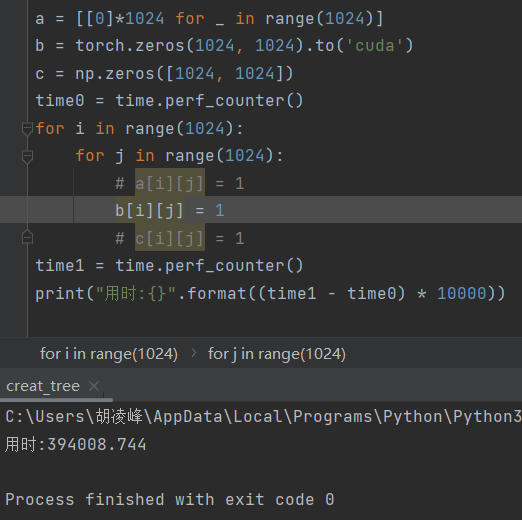
np.zeros:4700
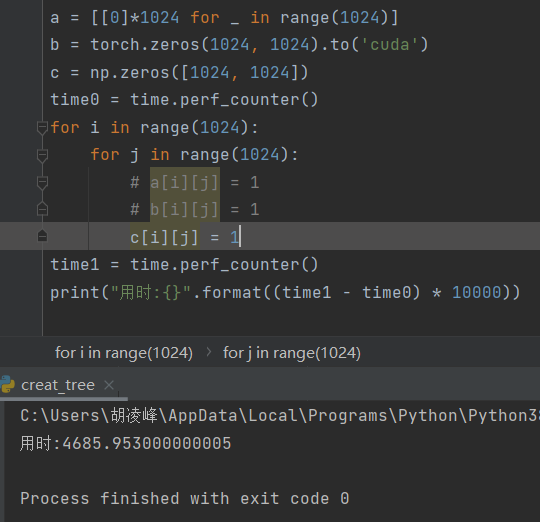
结论:在赋值方面np略逊于原生数组,但是没有数量级上的差距。tensor更不用说了,慢死人。
3、给 1024*1024 的二维数组遍历赋值,而且计算余弦相似度:
torch.tensor的数组,以及F.cos的相似度:774
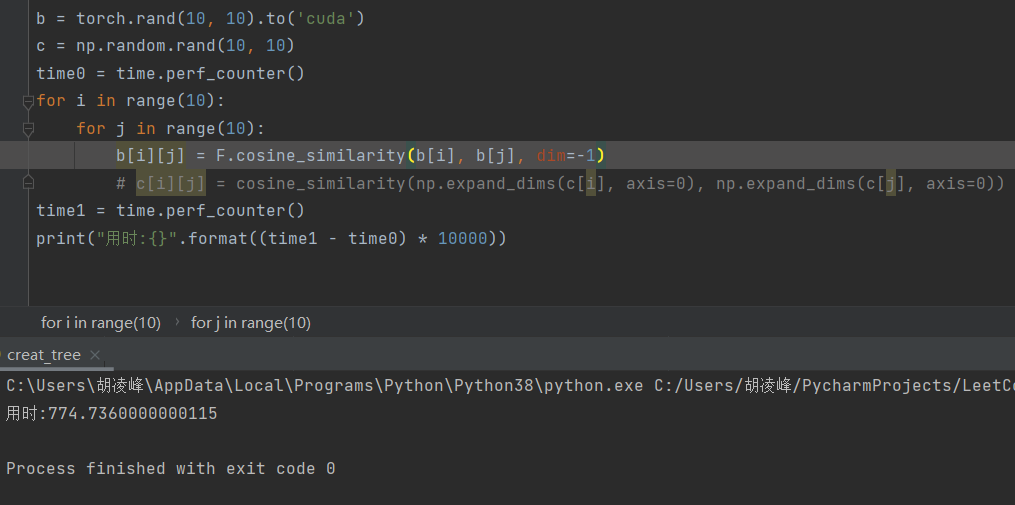
np的数组,以及np的相似度:686

我所用的转化一大堆转来转去的相似度:624
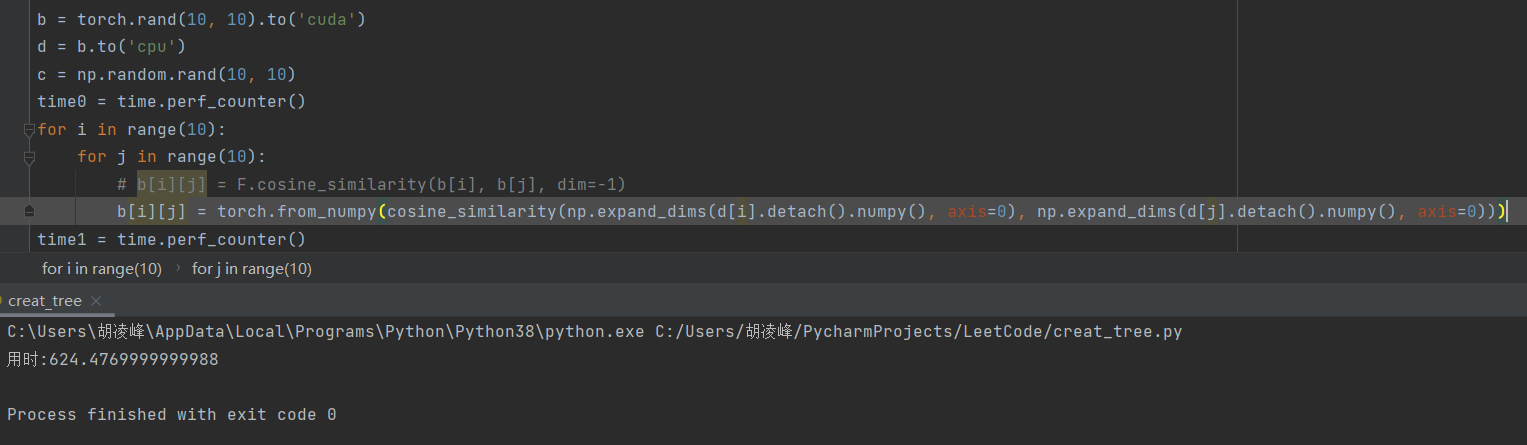
结论:计算相似度的话,几种方法都差不多。而且都不高。最耗时的,还是创建数组的过程。