学习率和BatchSize对模型的影响
随机梯度下降算法的原理如下,
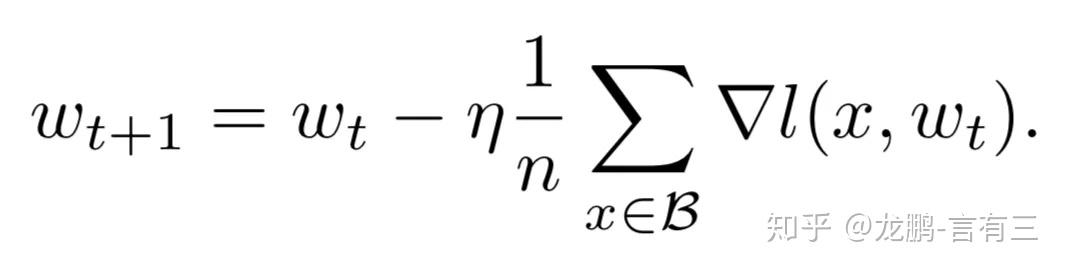
n是批量大小(batchsize),η是学习率(learning rate)。可知道除了梯度本身,这两个因子直接决定了模型的权重更新,从优化本身来看它们是影响模型性能收敛最重要的参数。
学习率直接影响模型的收敛状态,batchsize则影响模型的泛化性能,两者又是分子分母的直接关系,相互也可影响
毕设项目演示地址: 链接
毕业项目设计代做项目方向涵盖:
行为识别、OpenCV、场景文本识别、去雨、机器学习、风格迁移、视频目标检测、去模糊、显著性检测、剪枝、活体检测、人脸关键点检测、3D目标跟踪、视频修复、人脸表情识别、时序动作检测、图像检索、异常检测等
学习率如何调整
初始学习率大小对模型性能的影响
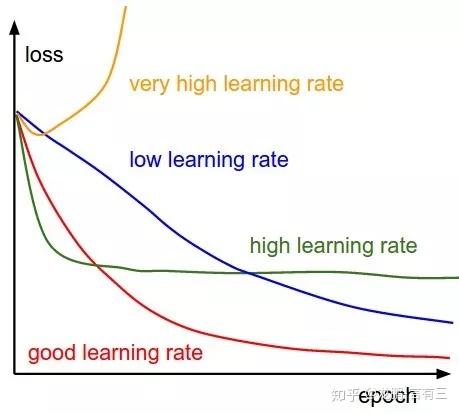
初始的学习率肯定是有一个最优值的,过大则导致模型不收敛,过小则导致模型收敛特别慢或者无法学习,下图展示了不同大小的学习率下模型收敛情况的可能性,图来自于cs231n。
通常可以采用最简单的**搜索法,即从小到大开始训练模型,然后记录损失的变化**,通常会记录到这样的曲线。
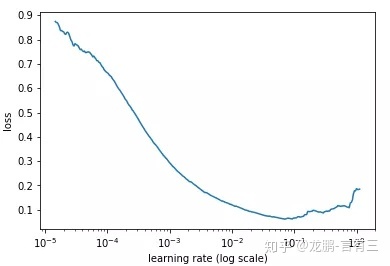
随着学习率的增加,损失会慢慢变小,而后增加,而最佳的学习率就可以从其中损失最小的区域选择。
有经验的工程人员常常根据自己的经验进行选择,比如0.1,0.01等。
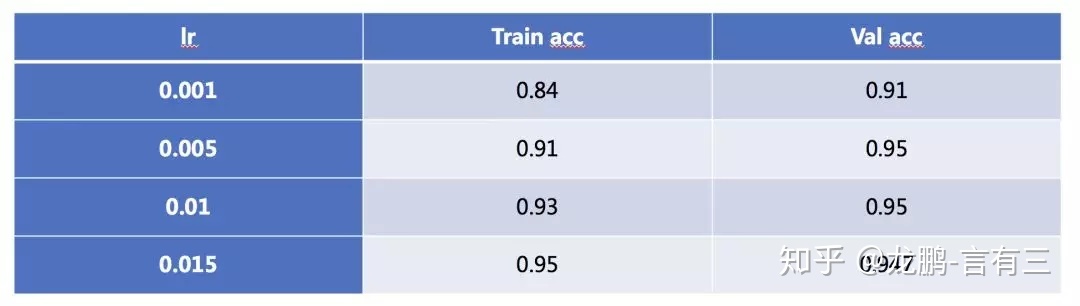
随着学习率的增加,模型也可能会从欠拟合过度到过拟合状态,在大型数据集上的表现尤其明显,笔者之前在Place365上使用DPN92层的模型进行过实验。随着学习率的增强,模型的训练精度增加,直到超过验证集。
不同的学习策略
Mutistep
一般使用Mutistep策略,搁几个epoch调整一次学习率的数量级。
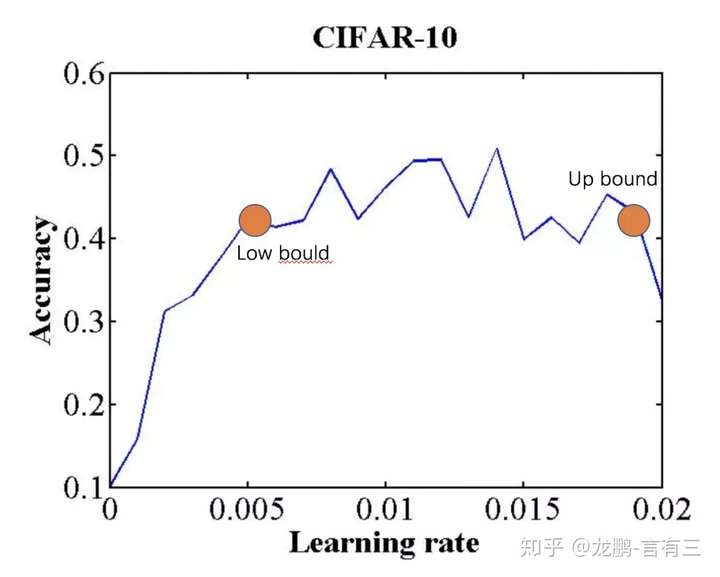
cyclical learning rate
实验证明通过设置上下界,让学习率在其中进行变化,可以在模型迭代的后期更有利于克服因为学习率不够而无法跳出鞍点的情况。
确定学习率上下界的方法则可以使用LR range test方法,即使用不同的学习率得到精度曲线,然后获得精度升高和下降的两个拐点,或者将精度最高点设置为上界,下界设置为它的1/3大小。
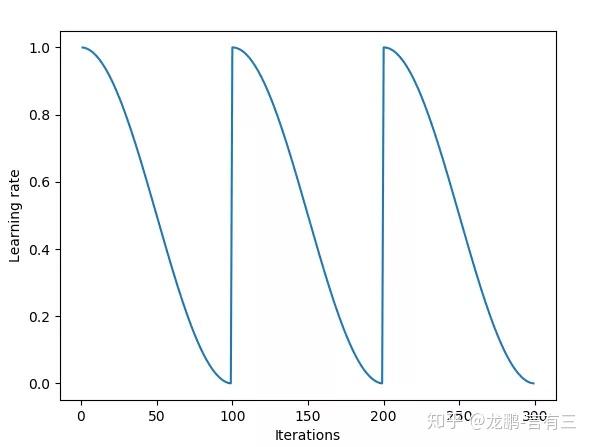
SGDR方法则是比cyclical learning rate变换更加平缓的周期性变化方法,如下图,效果与cyclical learning rate类似。
自适应学习率变换方法
也就是Adam,详情看《10_理清深度学习优化函数发展脉络.md》
Batchsize如何影响模型性能?
模型性能对batchsize虽然没有学习率那么敏感,但是在进一步提升模型性能时,batchsize就会成为一个非常关键的参数。
3.1 大的batchsize减少训练时间,提高稳定性
这是肯定的,同样的epoch数目,大的batchsize需要的batch数目减少了,所以可以减少训练时间(前提是batchsize大,lr也要大,确保一个epoch参数更新的总长度不变),目前已经有多篇公开论文在1小时内训练完ImageNet数据集。另一方面,大的batch size梯度的计算更加稳定,因为模型训练曲线会更加平滑。在微调的时候,大的batch size可能会取得更好的结果。
3.2 大的batchsize导致模型泛化能力下降
在一定范围内,增加batchsize有助于收敛的稳定性,但是随着batchsize的增加,模型的性能会下降,如下图,来自于文[5]。
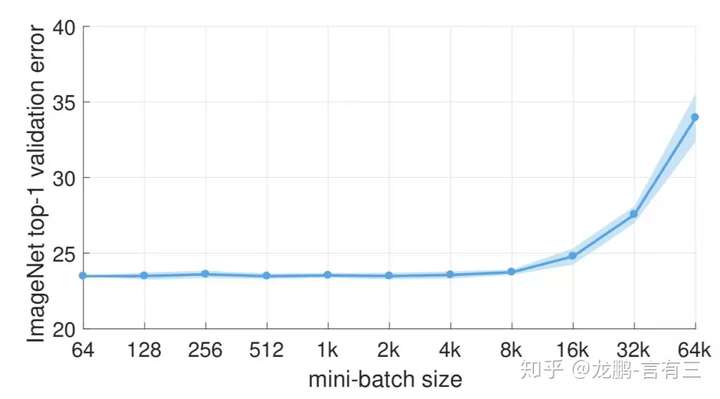
主要原因是小的batchsize带来的噪声有助于逃离局部最优。
3.3 小结
batchsize在变得很大(超过一个临界点)时,会降低模型的泛化能力。在此临界点之下,模型的性能变换随batch size通常没有学习率敏感。
学习率和BatchSize的关系
通常当我们增加batchsize为原来的N倍时,学习率应该增加为原来的N倍,因为要保证经过同样的样本后更新的权重相等,
- 如果增加了学习率,那么batch size最好也跟着增加,这样收敛更稳定。
- **尽量使用大的学习率,因为很多研究都表明更大的学习率有利于提高泛化能力。**如果真的要衰减,可以尝试其他办法,比如增加batch size,学习率对模型的收敛影响真的很大,慎重调整。
问题
10k样本用SGD,batchsize取1,100,10000哪个收敛最快?
100。
- 大的bs,一个epoch需要的iter次数就会变少,又一般有5次bs=1比1次bs=5的时间长,所以bs越大训练速度越快。
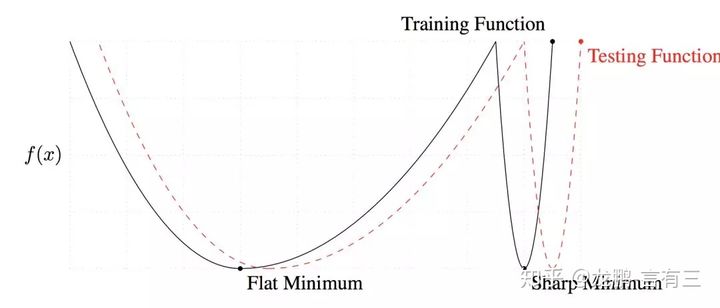
而且,bs越大,梯度更加稳定,loss曲线更加平滑。 - bs过大,导致模型泛化性下降,因为小bs更容易跳出局部最优点(sharp minimum)。一般bs不能超过8000。
因此,太大,太小都不好。
参考链接
【AI不惑境】学习率和batchsize如何影响模型的性能?