Java中的数组以及八大排序算法
java中的数组
- 什么是数组
- 静态数组定义
- 数组访问
- 数组注意事项:
- 动态数组定义
- 元素默认的规则:
- 两种数组初始化注意事项:
- 数组的遍历
- 数组元素求和
- 数组求最值
- 随机排名
- 数组排序的技术
- 冒泡排序(交换)
- 快速排序(交换)
- 插入排序(插入)
- 希尔排序(插入)
- 选择排序(选择)
- 堆排序(选择)
- 归并排序
- 基数排序
- 数组搜索的技术
- 二分搜索
- 分块查找
- Java数组的内存图
- 数组使用常见的问题
什么是数组
- 数组就是用来存储一批同种类型数据的内存区域(可以理解成容器)
- 掌握重点:

静态数组定义
- 静态初始化数组:
定义数组的时候直接给数组赋值。 - 静态初始化数组的格式:
// 完整格式
数据类型[] 数组名 = new 数据类型[]{元素1,元素2,元素3...};
// 简化格式
数据类型[] 数组名 = {元素1,元素2,元素3,...};
package shuzu;
public class shuzu {
public static void main(String[] args) {
int[] ages = new int[]{12,24,36};
String[] name = {"小王","小瑞","小云"};
}
}
- 数组的基本原理:
首先内存中申请一个区域储存ages变量,后面把数据对象连续的储存在内存中对应有自己的内存地址,然后ages变量中存储数据对象中的首个元素的内存地址,这样通过内存地址就可以找到对应的元素。
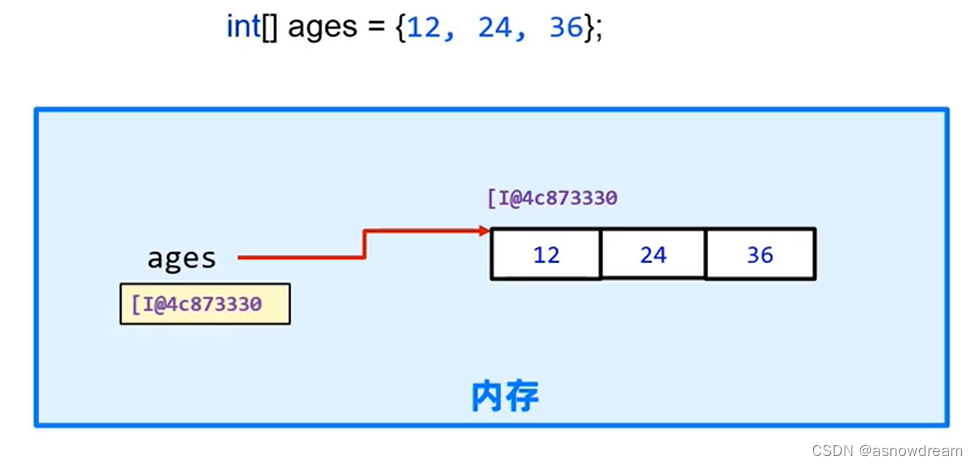
- 注意:数组变量名中存储的是数组在内存中的地址,数组是引用类型。
数组访问
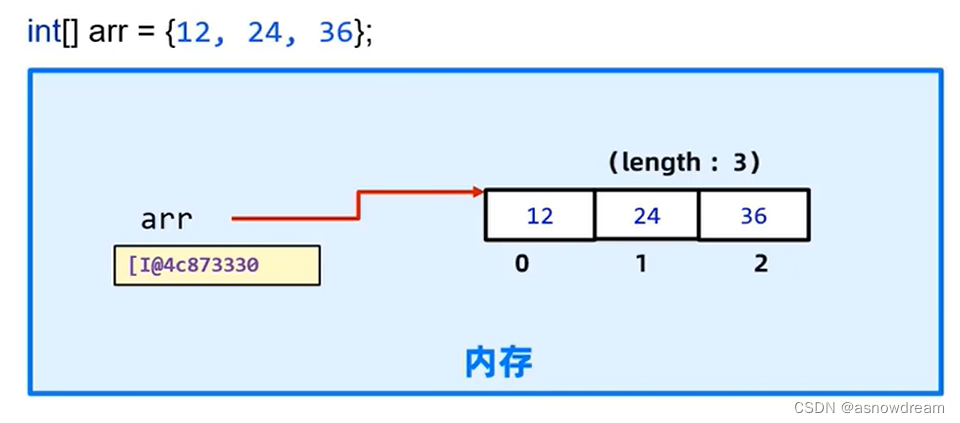
- 数组索引访问格式:
// 取值
数组名称[索引];
// 赋值
数组名称[索引]=相同类型值;
package shuzu;
public class shuzu {
public static void main(String[] args) {
int[] arr = {12,24,36};
// 取值
System.out.println(arr[0]); // 12
// 赋值
arr[0] = 100;
System.out.println(arr[0]); // 100
}
}
- 数组的长度属性访问格式:
数组名称.length;
package shuzu;
public class shuzu {
public static void main(String[] args) {
int[] arr = {12,24,36};
System.out.println(arr.length); // 3
}
}
数组注意事项:
- “数据类型[ ] 数组名”也可以写成“数据类型 数组名[ ]”。
package shuzu;
public class shuzu {
public static void main(String[] args) {
int[] arr = {12,24,36};
String name[] = {"小王","小瑞","小云"};
}
}
- 什么类型的数组存放什么类型的数据,否则报错。
- 数组一旦定义出来,程序执行的过程中、长度、类型就固定了。
动态数组定义
- 数组动态初始化:
定义数组的时候只确定元素的类型和数组的长度,之后再存入具体数据。 - 数组的动态初始化格式:
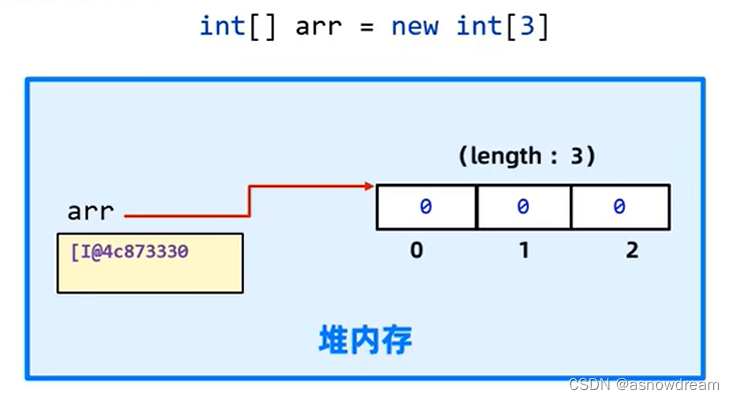
数据类型[] 数组名 = new 数据类型[长度];
package shuzu;
public class shuzu {
public static void main(String[] args) {
int[] arr = new int[3];
arr[0] = 521;
System.out.println(arr[0]); //521
System.out.println(arr[2]); //默认值为0
}
}
元素默认的规则:

package shuzu;
public class arrdem {
public static void main(String[] args) {
// 整型
int [] arr = new int[5];
System.out.println(arr[0]); // 0
// 字符型
char [] arr1 = new char[5];
System.out.println(arr1[0]); // 0
// 浮点型
double[] arr2 = new double[5];
System.out.println(arr2[0]); //0.0
// 布尔型
boolean[] arr3 = new boolean[5];
System.out.println(arr3[0]); //false
// 引用型
String[] arr4 = new String[5];
System.out.println(arr4[0]); // null
}
}
两种数组初始化注意事项:
- 动态初始化:只指定数组长度,后期赋值,适合开始知道数据数量,但是不确定具体元素值的业务场景。
- 静态初始化:开始就存入元素值,适合一开始就能确定元素值的业务场景。
- 两种格式的写法是独立的严,不可以混用。比如下面的错误写法:
int[] arrs = new int[3]{30,40,50};
数组的遍历
- 遍历:就是一个一个数据访问。
- 应用:搜索、数据统计等都需要用到遍历。
package shuzu;
public class bianli {
public static void main(String[] args) {
int[] ages = {20,30,40,50};
for (int i = 0; i <ages.length ; i++) {
System.out.print(ages[i]+"\t"); // 20 30 40 50
}
}
}
数组元素求和
- eg:某部门5名员工的销售额分别是:20、50、40、30.请计算出该部门的总销售额。
package shuzu;
public class bianli {
public static void main(String[] args) {
int sum = 0;
int[] ages = {20,50,40,30};
for (int i = 0; i <ages.length ; i++) {
sum += ages[i];
}
System.out.println("总销售额为:"+sum); //总销售额为:140
}
}
数组求最值
- eg:求最大营业额200,400,350,450,600,300,150.:
package shuzu;
public class bianli {
public static void main(String[] args) {
int[] ages = {200,400,350,450,600,300,150};
int min = ages[0];
int max = ages[0];
for (int i = 1; i <ages.length ; i++) {
if(min>=ages[i]){
min = ages[i];
}else if(max<=ages[i]){
max = ages[i];
}
}
System.out.println("最小值:"+min+" "+"最大值:"+max); // 最小值:150 最大值:600
}
}
随机排名
- eg:某公司开发部5名开发人员,进行项目演讲,现在采取随机排名后进行汇报,工号依次为22,33,35,13,88.
package shuzu;
import java.util.Random;
import java.util.Scanner;
public class eg3 {
public static void main(String[] args) {
int[] codes = new int[5];
Scanner sc = new Scanner(System.in);
for (int i = 0; i < codes.length; i++) {
System.out.println("请你输入第"+(i+1)+"个员工的工号:");
int code = sc.nextInt();
codes[i] = code;
}
// 随机交换
Random r = new Random();
for (int j = 0; j < codes.length; j++) {
int index = r.nextInt(codes.length);
int teap = codes[index];
codes[index] = codes[j];
codes[j] = teap;
}
for (int i = 0; i < codes.length; i++) {
System.out.print(codes[i]+"\t");
}
}
}
数组排序的技术
- 就是对数组中的元素,进行升序(由小到大)或者降序(由大到小)的排序。
冒泡排序(交换)
- 核心思想:
1、从第一个元素开始,比较相邻的两个元素。如果第一个比第二个大,则进行交换。
2、轮到下一组相邻元素,执行同样的比较操作,再找下一组,直到没有相邻元素可比较为止,此时最后的元素应是最大的数。
3、除了每次排序得到的最后一个元素,对剩余元素重复以上步骤,直到没有任何一对元素需要比较为止。
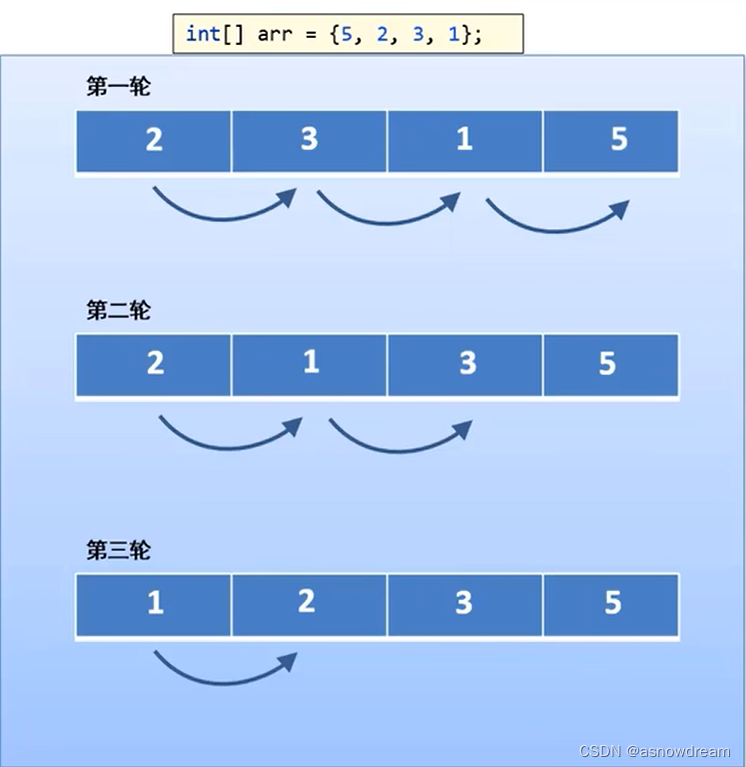
- 冒泡排序的分析与实现:
1.确定总共需要做几轮:数组的长度-1
2.每轮比较的次数:数组的长度-轮数

package shuzu;
public class maopaopaixu {
public static void main(String[] args) {
// 定义数组
int[] arr = {5,2,3,1};
// 定义有序变量
boolean flag = true;
// 定义一个循环控制比较了轮数
for (int i = 0; i < arr.length-1; i++) {
// 定义一个循环控制每轮比较的次数。
for (int j = 0; j < arr.length-i-1; j++) {
// 判断当前位置的元素是否大于后面元素,是否进行交换
if(arr[j] > arr[j+1]){
flag = false;
int temp = arr[j+1];
arr[j+1] = arr[j];
arr[j] = temp;
}
}
// 判断所给的数组是否有序
if(flag){
break;
}
}
for (int i = 0; i < arr.length ; i++) {
System.out.print(arr[i]+"\t"); // 1 2 3 5
}
}
}
快速排序(交换)
- 快速排序的思想:是一种基于分而治之的排序算法,其中:
1.通过从数组中选择一个中心元素将数组划分成两个子数组,在划分数组时,将比中心元素小的元素放在左子数组,将比中心元素大的元素放在右子数组。
2.左子数组和右子数组也使用相同的方法划分,这个过程一直持续到每个子数组都包含一个元素为止。
3.最后将元素组合在一起以形成排序的数组。 - 快速排序的分析与实现:
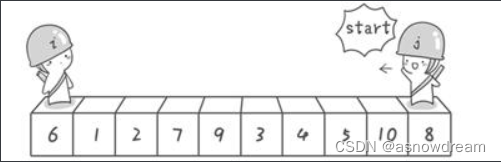
**步骤一:**分别从初始序列“6 1 2 7 9 3 4 5 10 8”两端开始“探测”。把6作为基准数,先从右往左找一个小于6的数,再从左往右找一个大于6的数,然后交换他们。这里可以用两个变量i和j,分别指向序列最左边和最右边。我们为这两个变量起个好听的名字“哨兵i”和“哨兵j”。刚开始的时候让哨兵i指向序列的最左边(即i=1),指向数字6。让哨兵j指向序列的最右边(即=10),指向数字。
**步骤二:**首先哨兵j开始出动。因为此处设置的基准数是最左边的数,所以需要让哨兵j先出动,这一点非常重要。哨兵j一步一步地向左挪动,直到找到一个小于6的数停下来。接下来哨兵i再一步一步向右挪动(即i++),直到找到一个数大于6的数停下来。最后哨兵j停在了数字5面前,哨兵i停在了数字7面前。
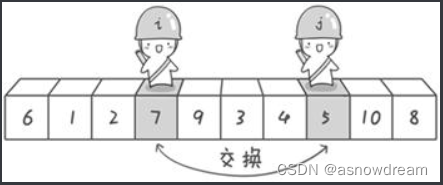
交换哨兵i和哨兵 j所指向的元素的值。交换之后的序列如下:
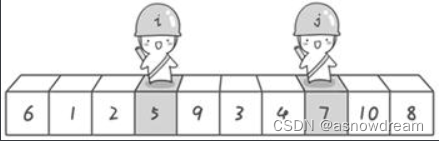
第一次交换结束。接下来开始哨兵j继续向左挪动,哨兵j发现小于6的数停在了4上,哨兵i也继续向右挪动的,哨兵i发现大于6的数停在了9上。
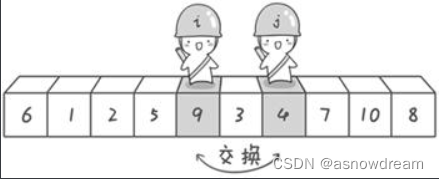
交换哨兵i和哨兵 j所指向的元素的值。交换之后的序列如下:
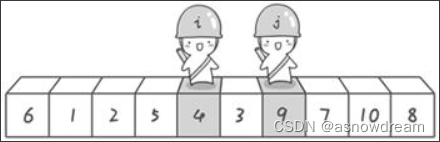
第二次交换结束,“探测”继续。哨兵j继续向左挪动,他发现了3(比基准数6要小,满足要求)之后又停了下来。哨兵i继续向右移动,糟啦!此时哨兵i和哨兵j相遇了,哨兵i和哨兵j都走到3面前。
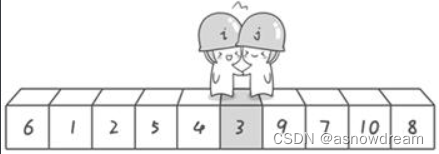
说明此时“探测”结束。将基准数6和3进行交换。
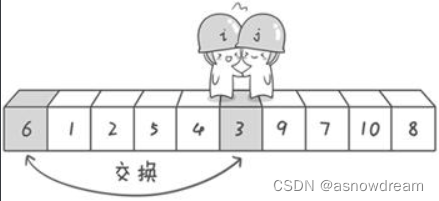
交换哨兵 j所指向的元素的值。交换之后的序列如下:
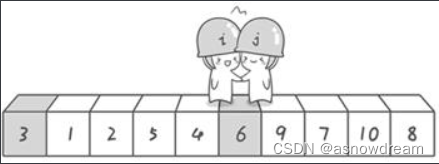
第一轮“探测”真正结束。此时以基准数6为分界点,6左边的数都小于等于6,6右边的数都大于等于6。回顾一下刚才的过程,其实哨兵j的使命就是要找小于基准数的数,而哨兵i的使命就是要找大于基准数的数,直到i和j碰头为止。
**步骤三:**现在基准数6已经归位,它正好处在序列的第6位。此时我们已经将原来的序列,以6为分界点拆分成了两个序列,左边的序列是“3 1 2 5 4”,右边的序列是“9 7 10 8”。接下来还需要分别处理这两个序列。因为6左边和右边的序列目前都还是很混乱的。不过不要紧,我们已经掌握了方法,接下来只要模拟刚才的方法分别处理6左边和右边的序列即可。现在先来处理6左边的序列现吧。
左边的序列是“3 1 2 5 4”。请将这个序列以3为基准数进行调整,使得3左边的数都小于等于3,3右边的数都大于等于3。调整完毕之后的序列的顺序是:2 1 3 5 4。
现在3已经归位。接下来需要处理3左边的序列“2 1”和右边的序列“5 4”。对序列“2 1”以2为基准数进行调整,处理完毕之后的序列为“1 2”,到此2已经归位。序列“1”只有一个数,也不需要进行任何处理。至此我们对序列“2 1”已全部处理完毕,得到序列是“1 2”。序列“5 4”的处理也仿照此方法,最后得到的序列是:1 2 3 4 5 6 9 7 10 8。
对于序列“9 7 10 8”也模拟刚才的过程,直到不可拆分出新的子序列为止。最终将会得到这样的序列如:1 2 3 4 5 6 7 8 9 10。
排序完全结束。快速排序的每一轮处理其实就是将这一轮的基准数归位,直到所有的数都归位为止,排序就结束了。下面的图来描述下整个算法的处理过程。
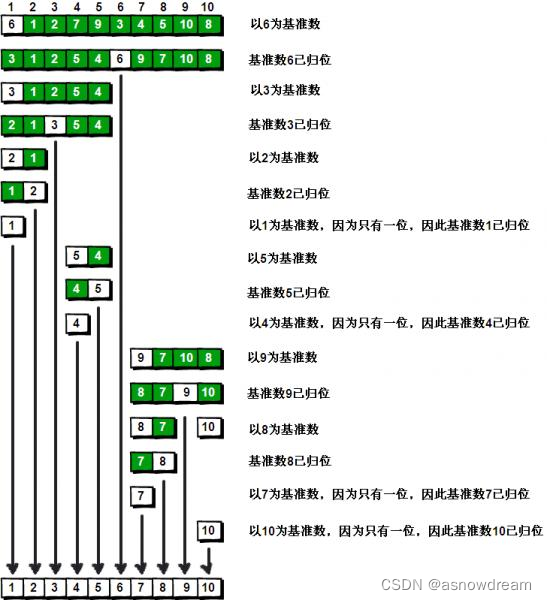
代码实现:
package shuzu;
import java.util.Arrays;
public class kuaisupaixu {
public static void quickSort(int[] arr,int low,int high){
int i,j,temp,t;
if(low>high){
return;
}
i=low;
j=high;
//temp就是基准位
temp = arr[low];
while (i<j) {
//先看右边,依次往左递减
while (temp<=arr[j]&&i<j) {
j--;
}
//再看左边,依次往右递增
while (temp>=arr[i]&&i<j) {
i++;
}
//如果满足条件则交换
if (i<j) {
t = arr[j];
arr[j] = arr[i];
arr[i] = t;
}
}
//最后将基准为与i和j相等位置的数字交换
arr[low] = arr[i];
arr[i] = temp;
//递归调用左半数组
quickSort(arr, low, j-1);
//递归调用右半数组
quickSort(arr, j+1, high);
}
public static void main(String[] args){
int[] arr = {6,1,2,7,9,3,4,5,10,8};
System.out.println("排序前:"+Arrays.toString(arr));
quickSort(arr, 0, arr.length-1);
System.out.println("排序后:"+ Arrays.toString(arr));
}
}
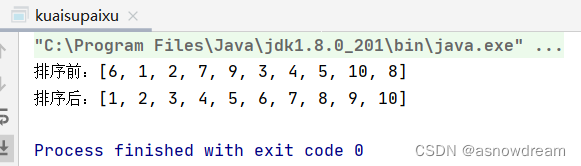
快速排序的面试题:
1、快速排序如何优化?
快速排序如果碰到有序数组,性能很差。因为以开头或末尾作为基准时,快速排序无法分成两份。换基准数等。
2、用快速排序找到数组中第k大的数?
在降序排序中,基准数的下标是k-1时即为第k大的数,如果不是的话继续递归。如果基准数中不存在k-1,那么就在排序后的数组中输出arr[k-1]。
插入排序(插入)
- 插入排序的思想:
将一个记录插入到已经排好序的有序表中,从而一个新的、记录数增加1的有序表。在其实现过程使用双层循环,外层循环对除了第一个元素之外的所有元素,内层循环对当前元素前面有序表进行待插入位置查找,并进行移动。 - 插入排序的分析与实现:
步骤一: 从第二位置的6开始比较,比前面7小,交换位置。
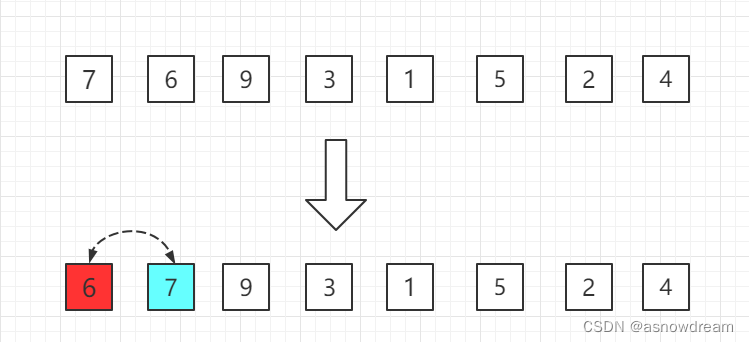
步骤二: 第三位置的9比前一位置的7大,无需交换位置。

步骤三: 第四个位置的3比前一位置的9小交换位置,依次往前比较。
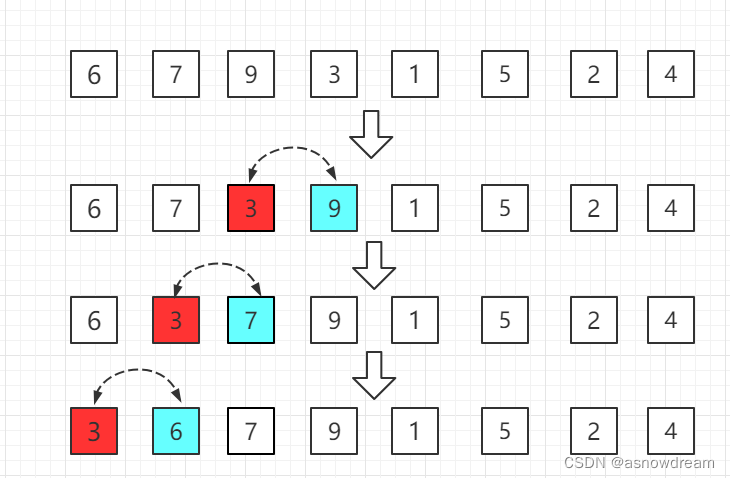
步骤四: 第五位置的1比前一位置的9小,交换位置,再依次往前比较。
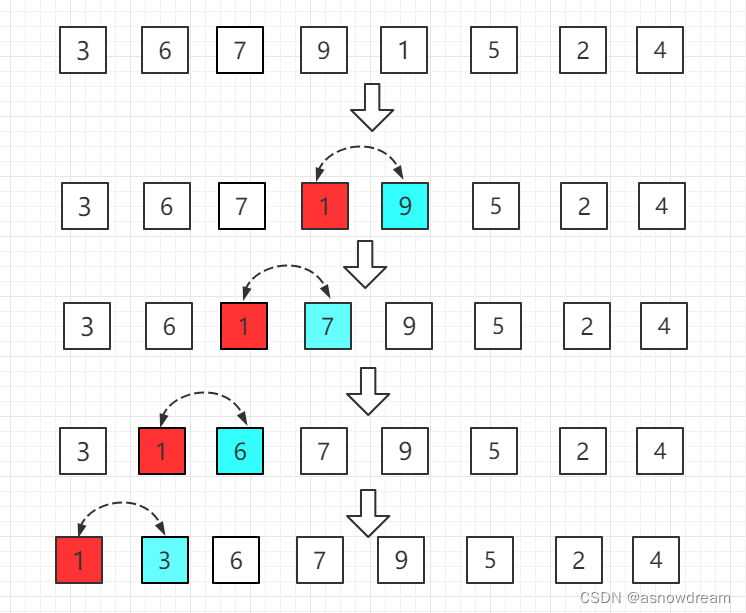
就这样依次比较7次就完成排序。
代码实现:
package shuzu;
public class charupaixu {
public static void InsertSort(int[] source) {
int i, j;
int insertNode;// 要插入的数据
// 从数组的第二个元素开始循环将数组中的元素插入
for (i = 1; i < source.length; i++) {
// 设置数组中的第2个元素为第一次循环要插入的数据
insertNode = source[i];
j = i - 1;
// 如果要插入的元素小于第j个元素,就将第j个元素向后移
while ((j >= 0) && insertNode < source[j]) {
source[j + 1] = source[j];
j--;
}
// 直到要插入的元素不小于第j个元素,将insertNote插入到数组中
source[j + 1] = insertNode;
System.out.print("第" + i + "趟排序:");
printArray(source);
}
}
private static void printArray(int[] source) {
for (int i = 0; i < source.length; i++) {
System.out.print("\t" + source[i]);
}
System.out.println();
}
public static void main(String[] args) {
int source[] = new int[] { 7, 6, 9, 3, 1, 5, 2, 4};
System.out.print("初始关键字:");
printArray(source);
System.out.println("");
InsertSort(source);
System.out.print("\n\n排序后结果:");
printArray(source);
}
}

希尔排序(插入)
- 希尔排序的思想: 希尔排序为了加快速度简单地改进了插入排序,希尔排序是把待排序数组按一定的数量分组,对每组使用直接插入排序算法排序;然后缩小数量继续分组排序,随着数量逐渐减少,每组包含的元素越来越多,当数量减至 1 时,整个数组恰被分成一组,排序便完成了。这个不断缩小的数量,就构成了一个增量序列,这里的数量称为增量。
- 希尔排序的分析与实现:
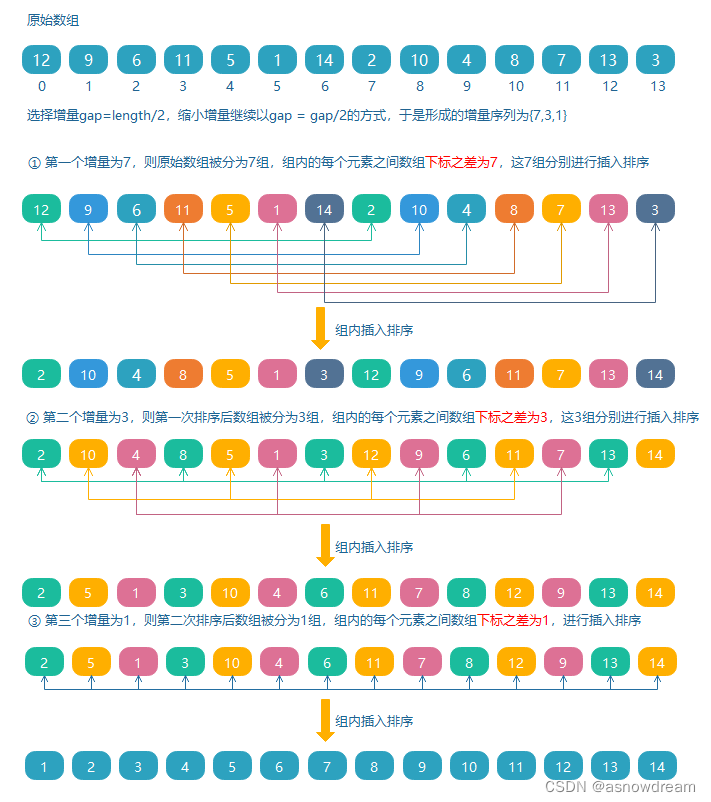
代码实现:
package shuzu;
import java.util.Arrays;
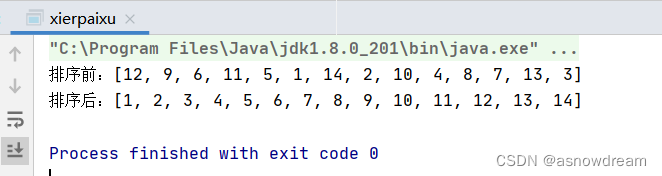
public class xierpaixu {
public static final int[] ARRAY = {12, 9, 6, 11, 5, 1, 14, 2, 10, 4, 8, 7, 13, 3};
public static int[] sort(int[] array) {
int len = array.length;
if (len < 2) {
return array;
}
//当前待排序数据,该数据之前的已被排序
int current;
//增量
int gap = len / 2;
while (gap > 0) {
for (int i = gap; i < len; i++) {
current = array[i];
//前面有序序列的索引
int index = i - gap;
while (index >= 0 && current < array[index]) {
array[index + gap] = array[index];
//有序序列的下一个
index -= gap;
}
//插入
array[index + gap] = current;
}
//int相除取整
gap = gap / 2;
}
return array;
}
public static void print(int[] array) {
for (int i : array) {
System.out.print(i + " ");
}
System.out.println("");
}
public static void main(String[] args) {
System.out.println("排序前:"+ Arrays.toString(ARRAY));
System.out.println("排序后:"+ Arrays.toString(sort(ARRAY)));
}
}
选择排序(选择)
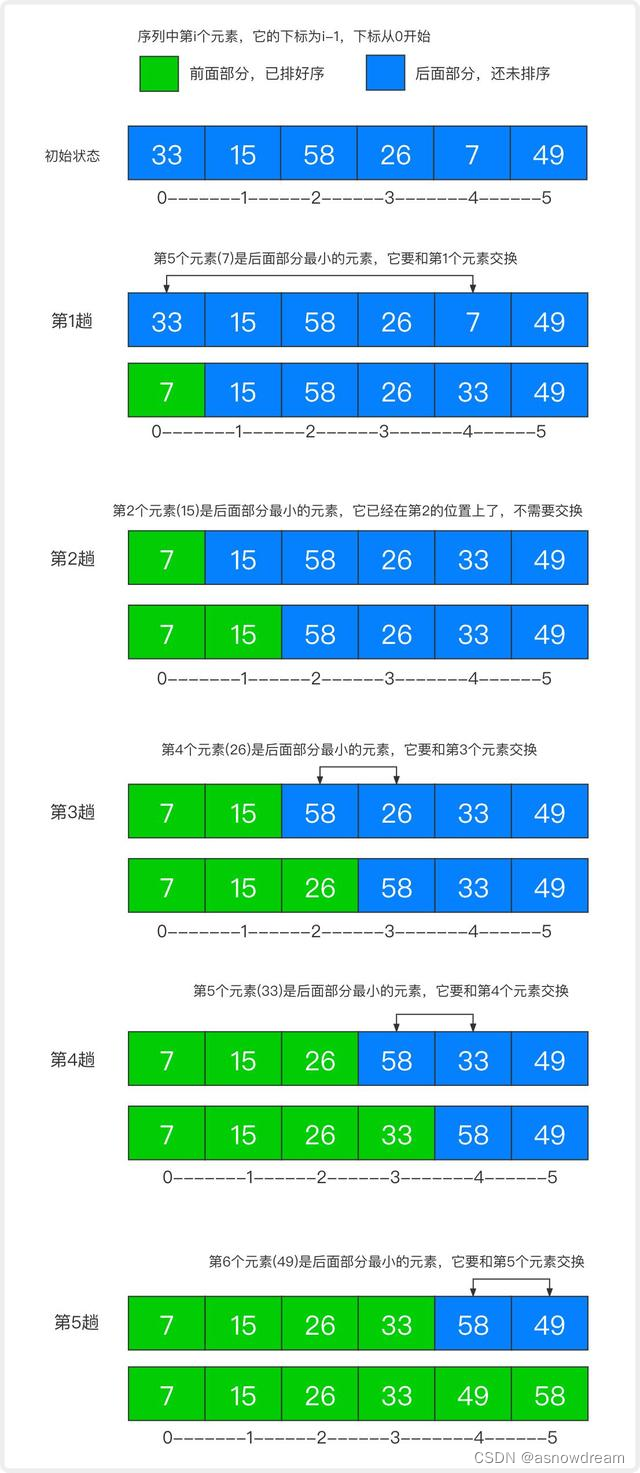
- 选择排序的思想:首先在未排序的序列中找到最小元素,存放到排序序列的起始位置,然后,再从剩余未排序元素中继续寻找最小元素,然后放到已排序序列的末尾。以此类推,直到所有元素均排序完毕,简单的说就是暴力实现,每一趟从未排序的区间找到一个最小元素,并放到第一位,直到全部区间有序为止。
- 选择排序的分析与实现:
步骤如下:
代码实现如下:
package shuzu;
public class xuanzepaixu {
public static void main(String[] args) {
int[] arr = {33,15,58,26,7,49};
// 选择排序的次数
for (int i = 0; i < arr.length-1; i++) {
// 创建保存最小变量
int min = arr[i];
// 创建保存最小变量的索引
int minindex = i;
// 筛选出没一趟的最小元素以及记录下最小元素的下标
for (int j = i+1; j < arr.length; j++) {
if(min > arr[j]){
min = arr[j];
minindex = j;
}
}
// 对每次选出的最小的值与当前值交换位置
if(i != minindex){
arr[minindex] = arr[i];
arr[i] = min;
}
}
// 遍历出排序后的数组
for (int i = 0; i < arr.length; i++) {
System.out.print(arr[i]+"\t"); // 7 15 26 33 49 58
}
}
}
堆排序(选择)
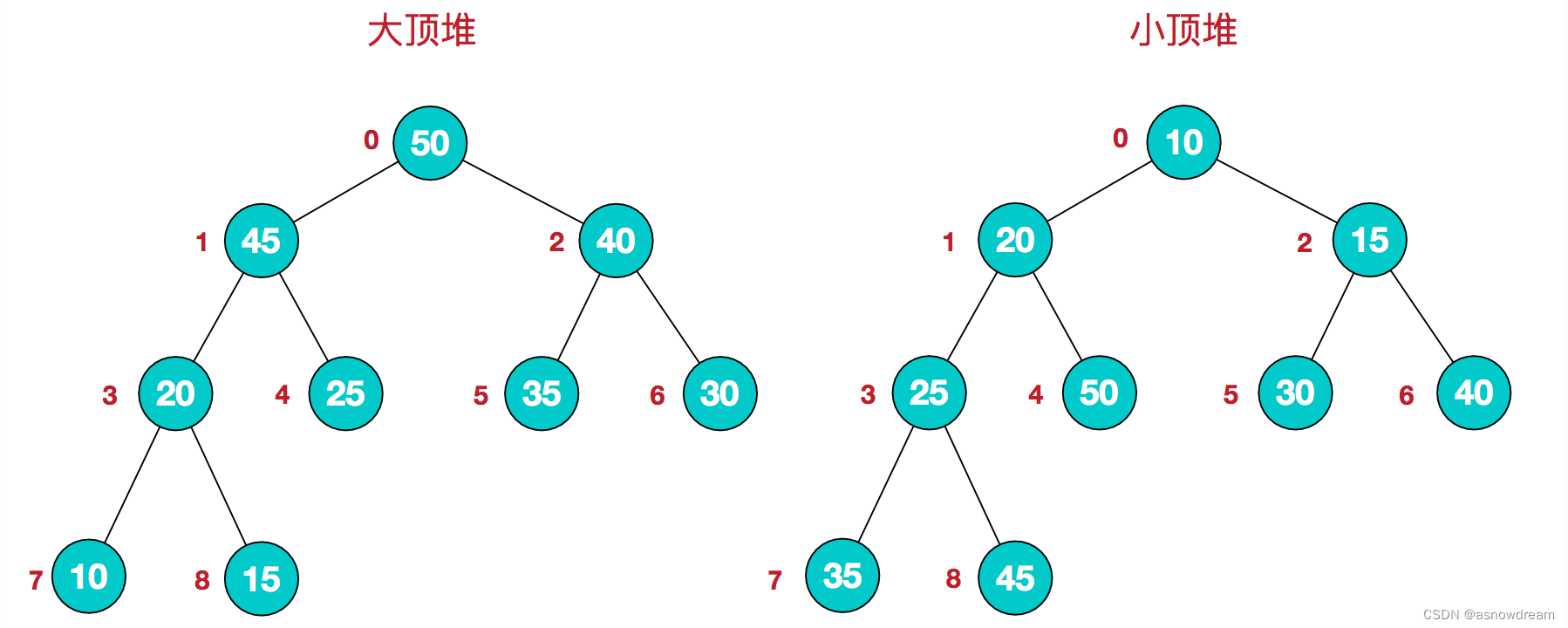
- 大顶堆和小顶堆的构成:对于任何一个数组都可以看成一颗完全二叉树,堆是具有以下性质的完全二叉树:每个结点的值都大于或等于其左右孩子结点的值,称为大顶堆。那么每个结点的值都小于或者等于其右孩子结点的值,称为小顶堆。如下图:
- 堆排序的基本思想:
1.先把将排序序列构造成一个大顶堆。
2.此时,整个序列的最大值就是堆顶的根结点。
3.将其与末尾元素进行交换,这时末尾就为最大值。
4.然后将剩余n-1个元素重新构造成一个堆,这样会得到n个元素的次小值,如此反复执行,最后就会得到一个有序序列。 - 堆排序的分析与实现:
由上面可以归纳堆排序的具体步骤::
步骤一: 构建初始堆,将 给定无序序列构造成一个大顶堆(一般升序采用大顶堆,降序采用小顶堆)。原始的数组[4,6,8,5,9]
1.假设给定无序列结构如下:arr[4,6,8,5,9]
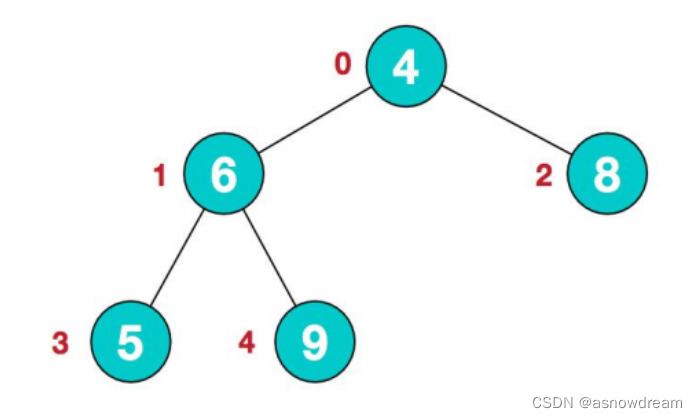
2.此时从最后一个非叶子结点开始(叶结点自然不用调整,第一个非叶子结点arr.length/2-1=5/2-1=1),从左至右,从下至上进行调整。arr[4,6,8,5,9] ——> arr[4,9,8,5,6]
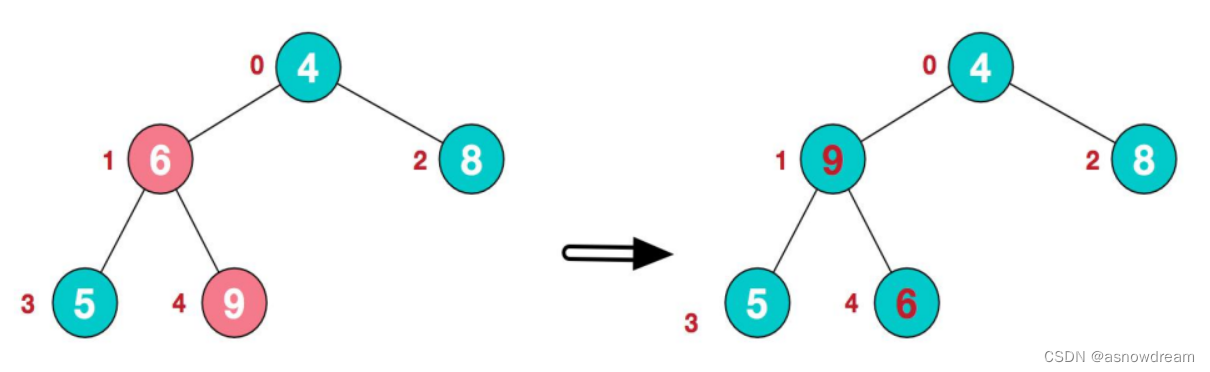
3.找到第二个非叶子节点4,由于[4,9,8]中9元素最大,4和9交换。arr[4,9,8,5,6]——>[9,4,8,5,6]
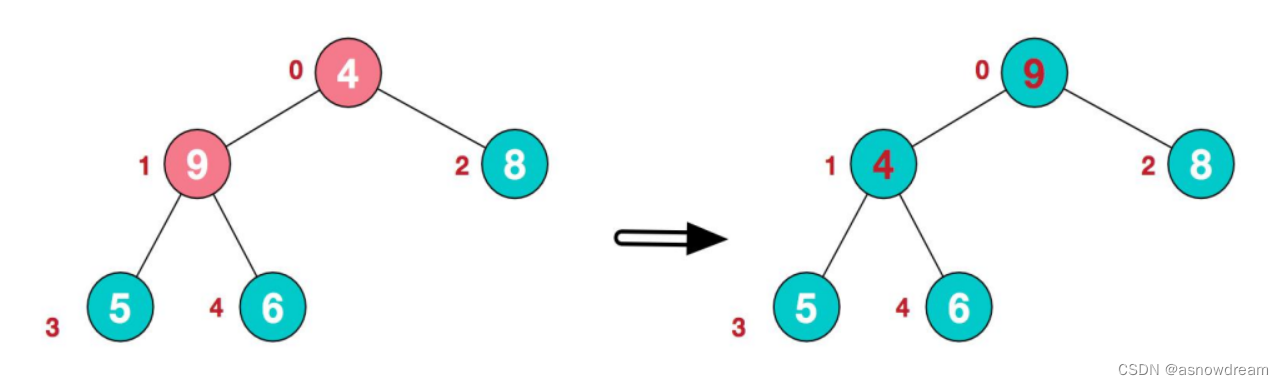
4.这时,交换导致了子根[4,5,6]结构混乱,继续调整,[4,5,6]中6最大,交换4和6。arr[9,4,8,5,6]——>arr[9,6,8,5,4]
这时,我们就将一个无序序列构造成了一个大顶堆。
步骤二: 将堆顶元素与末尾元素进行交换,使末尾元素最大。然后继续调整堆,再将堆顶元素与末尾元素交换,得到第二大元素。如此反复进行交换,重建,交换。
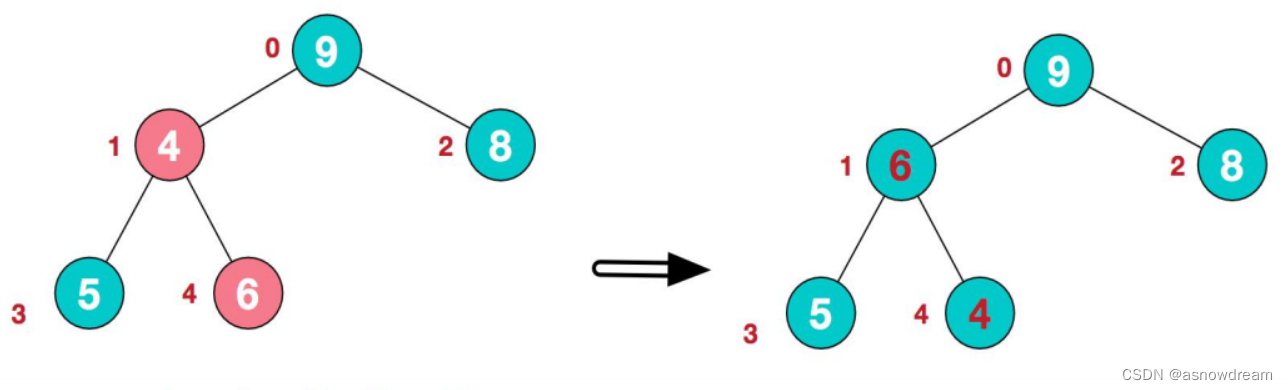
1.将堆顶元素9和末尾元素4进行交换。arr[9,6,8,5,4]——>arr[4,6,8,5,9]
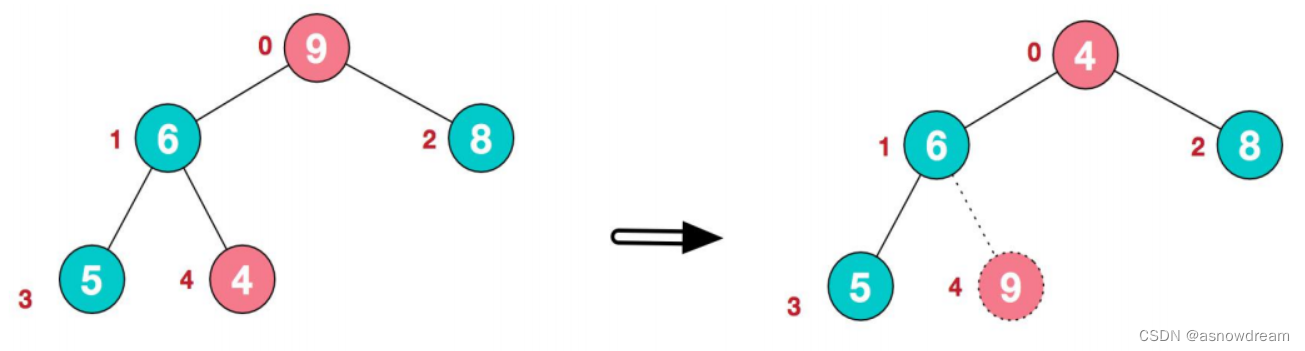
2.重新调整结构,使其继续满足堆定义。arr[4,6,8,5,9]——>arr[8,6,4,5,9]
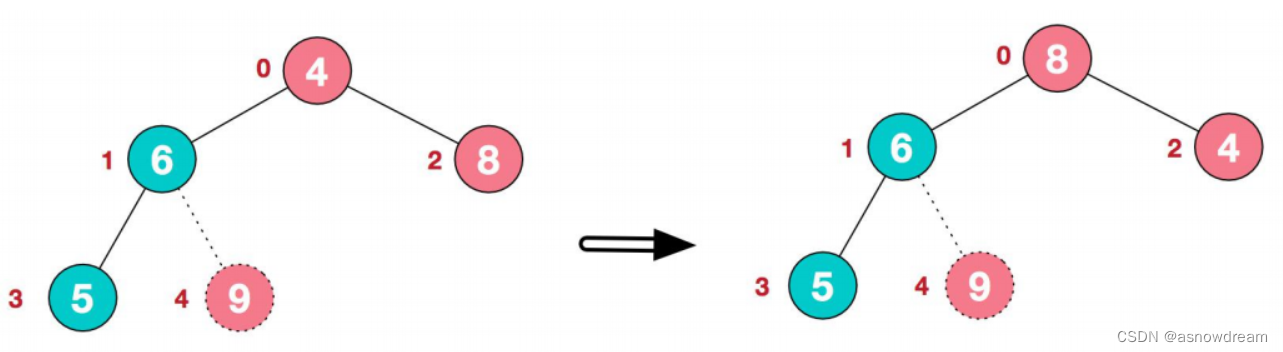
3.再将堆顶元素8与末尾元素5进行交换,得到第二大元素8。arr[8,6,4,5,9]——>arr[5,6,4,8,9]
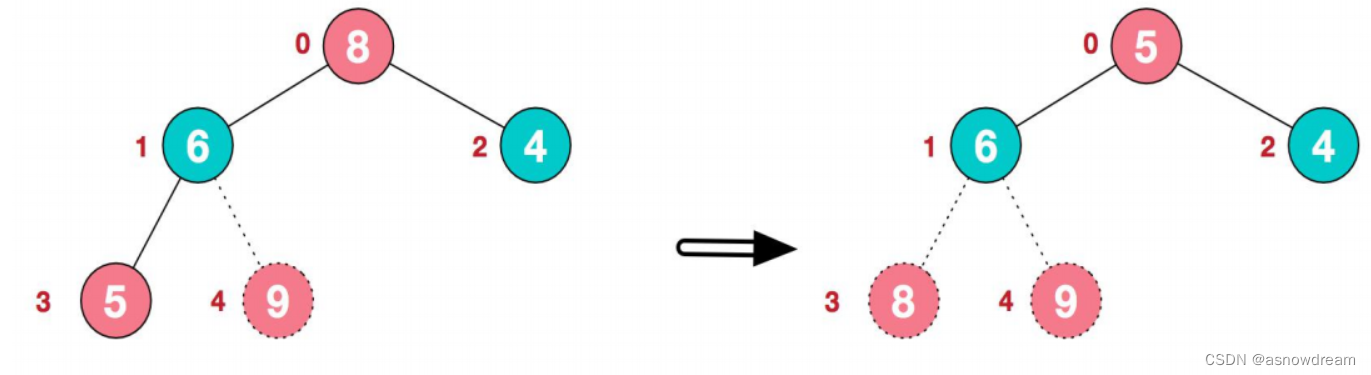
4.后续过程,继续进行调整,交换,如此反复进行,最终使得整个序列有序。arr[4,5,6,8,9]
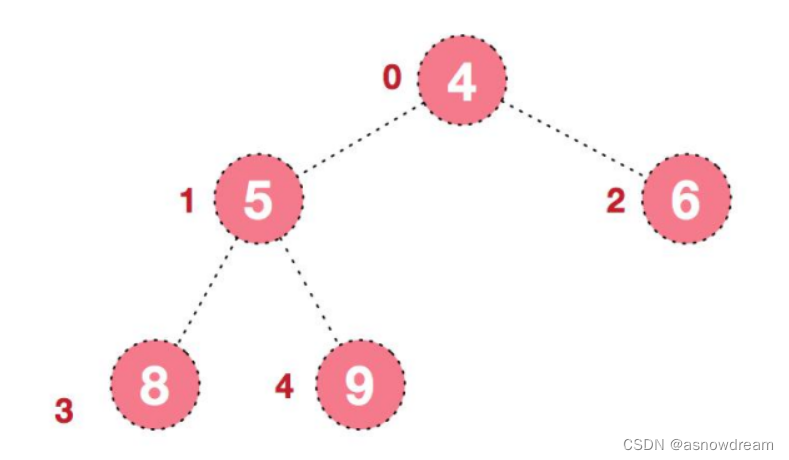
简单的理解堆排序的基本思路:
1.将无序序列构建成一个堆,根据升序降序需求选择大顶堆或小顶堆;
2.将堆顶元素与末尾元素交换,将最大元素“沉”到数组末端;
3.重新调整结构,使其满足堆定义,然后继续交换堆顶元素与当前末尾元素,反复执行调整+交换步骤,直到整个序列有序。
代码实现如下:
package shuzu;
import java.util.Arrays;
public class duipaixu {
public static void main(String []args){
int []arr = {4,6,8,5,9};
System.out.println("排序前:"+Arrays.toString(arr));
sort(arr);
System.out.println("排序前:"+Arrays.toString(arr));
}
public static void sort(int []arr){
//1.构建大顶堆
for(int i=arr.length/2-1;i>=0;i--){
//从第一个非叶子结点从下至上,从右至左调整结构
adjustHeap(arr,i,arr.length);
}
//2.调整堆结构+交换堆顶元素与末尾元素
for(int j=arr.length-1;j>0;j--){
swap(arr,0,j);//将堆顶元素与末尾元素进行交换
adjustHeap(arr,0,j);//重新对堆进行调整
}
}
/**
* 调整大顶堆(仅是调整过程,建立在大顶堆已构建的基础上)
*/
public static void adjustHeap(int []arr,int i,int length){
int temp = arr[i];//先取出当前元素i
for(int k=i*2+1;k<length;k=k*2+1){//从i结点的左子结点开始,也就是2i+1处开始
if(k+1<length && arr[k]<arr[k+1]){//如果左子结点小于右子结点,k指向右子结点
k++;
}
if(arr[k] >temp){//如果子节点大于父节点,将子节点值赋给父节点(不用进行交换)
arr[i] = arr[k];
i = k;
}else{
break;
}
}
arr[i] = temp;//将temp值放到最终的位置
}
public static void swap(int []arr,int a ,int b){
int temp=arr[a];
arr[a] = arr[b];
arr[b] = temp;
}
}
排序结果:
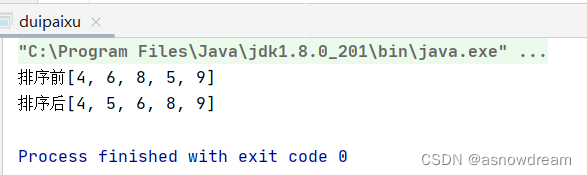
归并排序
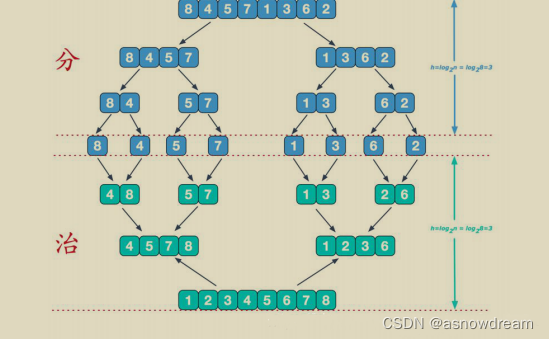
- 归并排序的思想: 利用归并的思想实现的排序方法,该算法采用经典的分治策略(分治法将问题分成一些小的问题然后递归求解,而治的阶段则将分的阶段得到的各答案"修补"在一起,即分而治之),先将待排序的数组不断拆分,直到拆分到区间里 只剩下一个元素的时候。不能再拆分的时候。这个时候我们再想办法合并两个有序的数组,得到长度更长的有序数组,当前合并好的有序数组为下一轮得到更长的有序数组做好了准备。一层一层的合并回去,直到整个数组有序。
- 归并排序的归纳与实现:
步骤一:
步骤二:
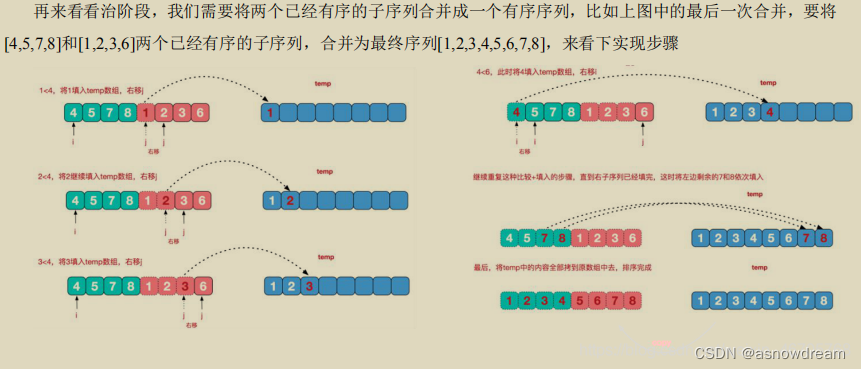
代码实现:
package shuzu;
import java.util.Arrays;
public class guibingpaixu {
public static void main(String[] args) {
int[] arr = {8, 4, 5, 7, 1, 3, 6, 2};
int[] temp = new int[arr.length];
System.out.println("排序前:"+Arrays.toString(arr));
diao(arr, 0, arr.length - 1, temp);
System.out.println("排序后:"+Arrays.toString(arr));
}
public static void diao(int[] arr, int left, int right, int[] temp) {
if (left >= right) {//如果左大于等于右 说明到合并方法时只剩下一部分了,没有对比 自然不能发生比较排序
return;
}
int mid = (left + right) / 2;//中间索引
diao(arr, left, mid, temp);//左递归分
diao(arr, mid + 1, right, temp);//右递归分解
mergeSort(arr, left, mid, right, temp);//分解完 两部分比较 排序插入数组
}
public static void mergeSort(int[] arr, int left, int mid, int right, int[] temp) {
int i = left;//记录左部分开头
int j = mid + 1;//右部分开头 同时也是左部分结束
int index = 0;//辅助下标
while (i <= mid && j <= right) {//如果左右开头部分 没到各自结尾 就继续合并 直到一部分处理完毕
//如果左边小于右边 将左边添加到temp
//同时 index++ i++
if (arr[i] <= arr[j]) {
temp[index] = arr[i];
index++;
i++;
} else {//反之 index++ j++
temp[index] = arr[j];
index++;
j++;
}
}
//当 两部分有一个处理完毕 剩下一个 将剩下部分的数字 全部填入temp
while (i <= mid) {
temp[index] = arr[i];
index++;
i++;
}
while (j <= right) {
temp[index] = arr[j];
index++;
j++;
}
//将temp数组部分拷贝到 arr
//注意不是 temp全部拷贝 而是没次调用合方法中 比较的两个部分的数字 拷贝
//第一次合并 tempLeft = 0 , right = 1 // tempLeft = 2 right = 3 // tL=0 ri=3
//最后一次 tempLeft = 0 right = 7
index = 0;
int arrIndex=left;
while (arrIndex <= right) {
arr[arrIndex] = temp[index++];
arrIndex++;
}
}
}
基数排序
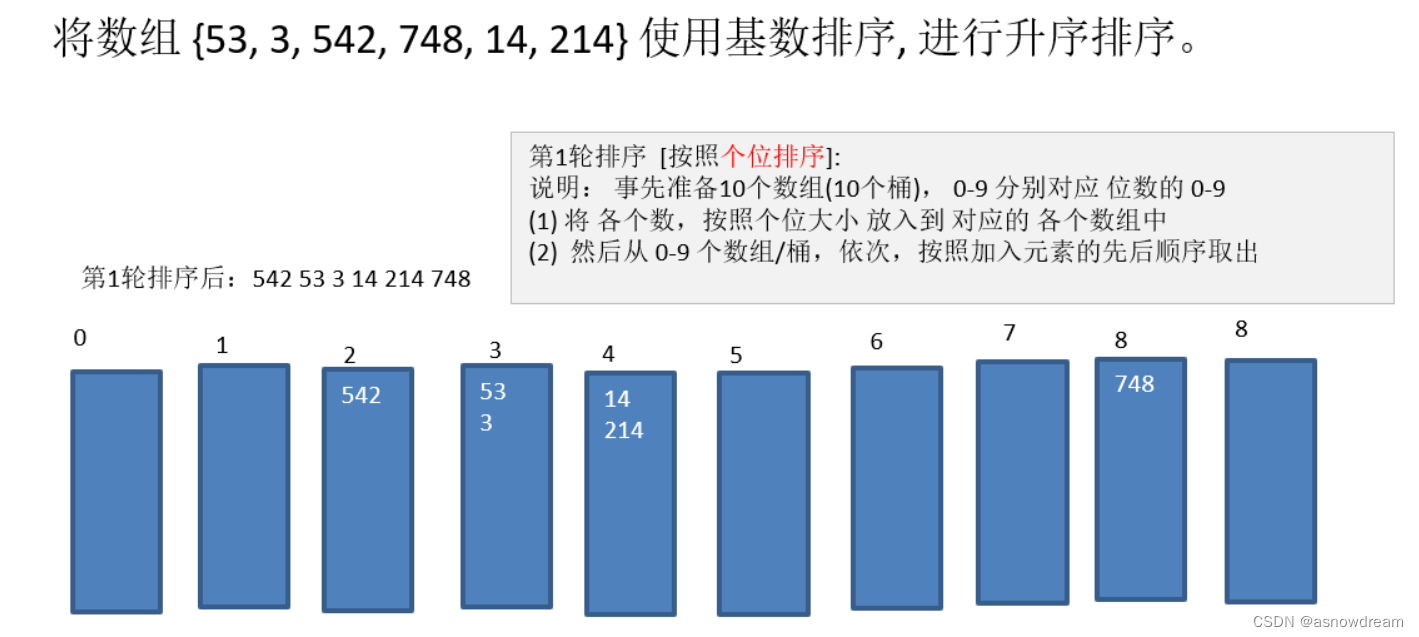
- 基数排序的思想: 属于”分配式排序“,它通过元素的各个位的值,将元素放置对应的”桶“中基数排序属于稳定性排序,效率高,但是过多的元素会出现虚拟机运行内存的不足,简单的说就是把元素统一为同样长度的数组长度元素较短的数面前补0,比如(1 15 336 看成 001 015 336)然后从最低位开始,以此进行排序。
- 基数排序的归纳与实现:
步骤一:
步骤二:
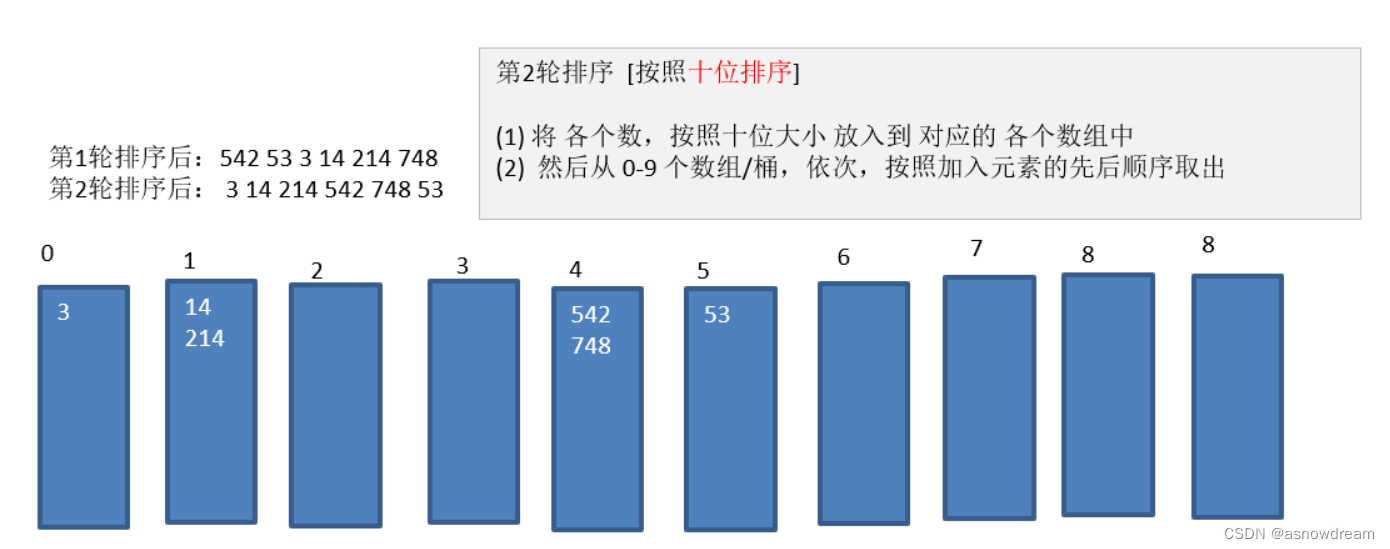
步骤三:
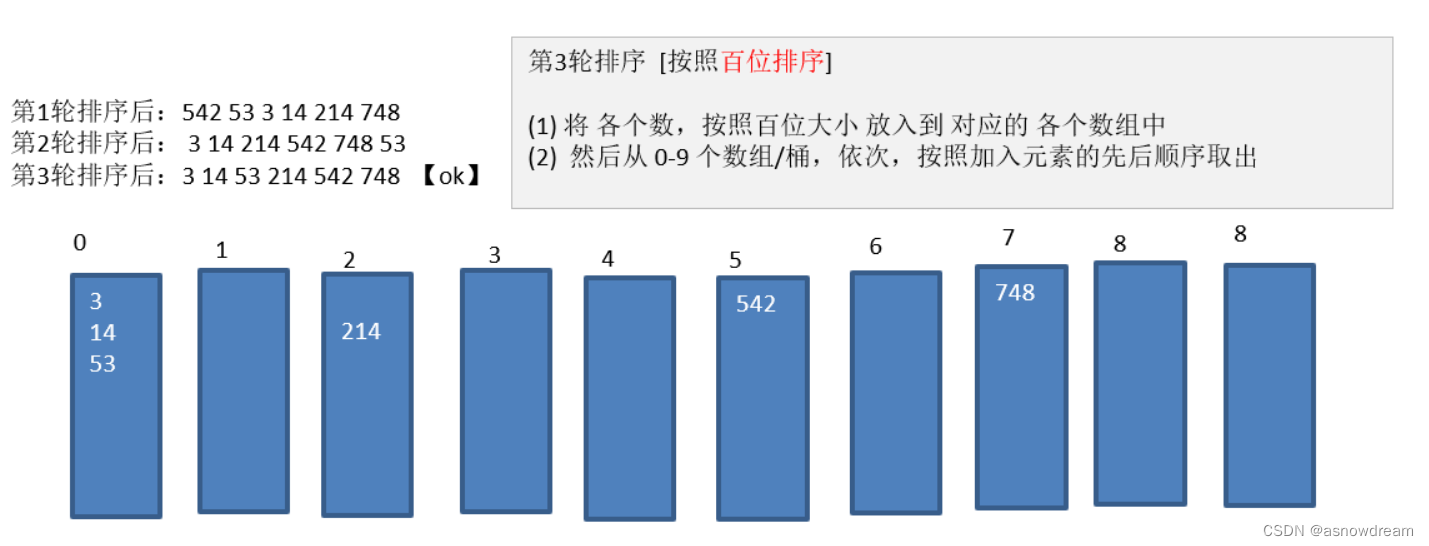
代码实现:
package shuzu;
import java.util.Arrays;
public class jishupaixu {
public static void main(String[] args) {
int[] arr = new int[]{53,3,542,748,14,214}; //定义一个数组
int coun = 0;
int max = 0;
for (int k : arr) { //得到这些数里面最大数的长度
if ((k + "").length() > max) {
max = (k + "").length();
}
}
for (int x = 0; x < max; x++) {
int[][] temp = new int[10][arr.length];
int[] tempcount = new int[10];
int n = (int) Math.pow(10, x);
for (int k : arr) {
int number = (((k / n) % 10));
temp[number][tempcount[number]] = k; //temp[number]默认值为0
tempcount[number]++;
}
int result = 0;
for (int i = 0; i < tempcount.length; i++) {
for (int j = 0; j < tempcount[i]; j++) {
arr[result] = temp[i][j];
result++;
}
}
coun++;
System.out.println("第"+Integer.toString(coun)+"次排序:"+Arrays.toString(arr));
}
}
}

数组搜索的技术
二分搜索
- 二分法查找的是想: 二分法查找又称折半查找是一种效率高的查找算法,将数列按有序化(递增货递减)排列,查找过程中采用跳跃的方式查找,即先以有序序列的中点位置为比较的对象,如果要查找的元素值要小于该中点元素,则将查找的元素缩小为左半部分,否则为右半部分,通过一次比较,将查找的区间缩小为一半。二分查找先行条件就是要保持元素有序。
- 二分法的归纳与实现:
图文归纳:

代码实现:
package shuzu;
public class erfensousuo {
public static void main(String[] args) {
// TODO Auto-generated method stub
// 测试,数组(有序,以升序序列为例。这里是园友留言,提示纠正的。)
int arr[] = {10,14,21,38,45,50,37,53,81,87,99};
BinaryFind bf = new BinaryFind();
bf.find(0, arr.length - 1, 50, arr);
}
}
// 定义一个二分查找的类
class BinaryFind {
public void find(int leftIndex, int rightIndex, int val, int arr[]) {
// 首先找到中间的数,这里不用担心。/代表取整。 //(之前的错误,被园友纠正:Java中,除不尽会自动取整)
int midIndex = (rightIndex + leftIndex) / 2;
int midVal = arr[midIndex];
if (rightIndex >= leftIndex) {
// 如果要找的数比midVal大
if (midVal > val) {
// 在arr数组的左边找
find(leftIndex, midIndex - 1, val, arr);
} else if (midVal < val) {
// 在arr数组的右边找
find(midIndex + 1, rightIndex, val, arr);
} else if (midVal ==val) {
System.out.println("找到"+val+"下标为:" + midIndex); // 找到50的下标为:5
}
}
}
}
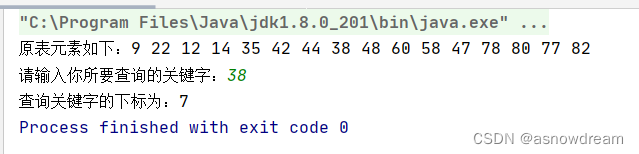
分块查找
- 分块查找的思想: 首先查找索引表,因为索引表是有序的表,所以可以采用二分法或者顺序查找,以确定待查记录在哪一块;然后在已确定的块中进行顺序查找(因为内无序,只能用顺序查找)。如果在块中找到该记录则查询成功,否则查找失败。
- 分块查找的归纳与实现:
归纳:
1.首先确定待查记录所在的块(子表)
2.然后在块中进行顺序查找确定记录的最终位置
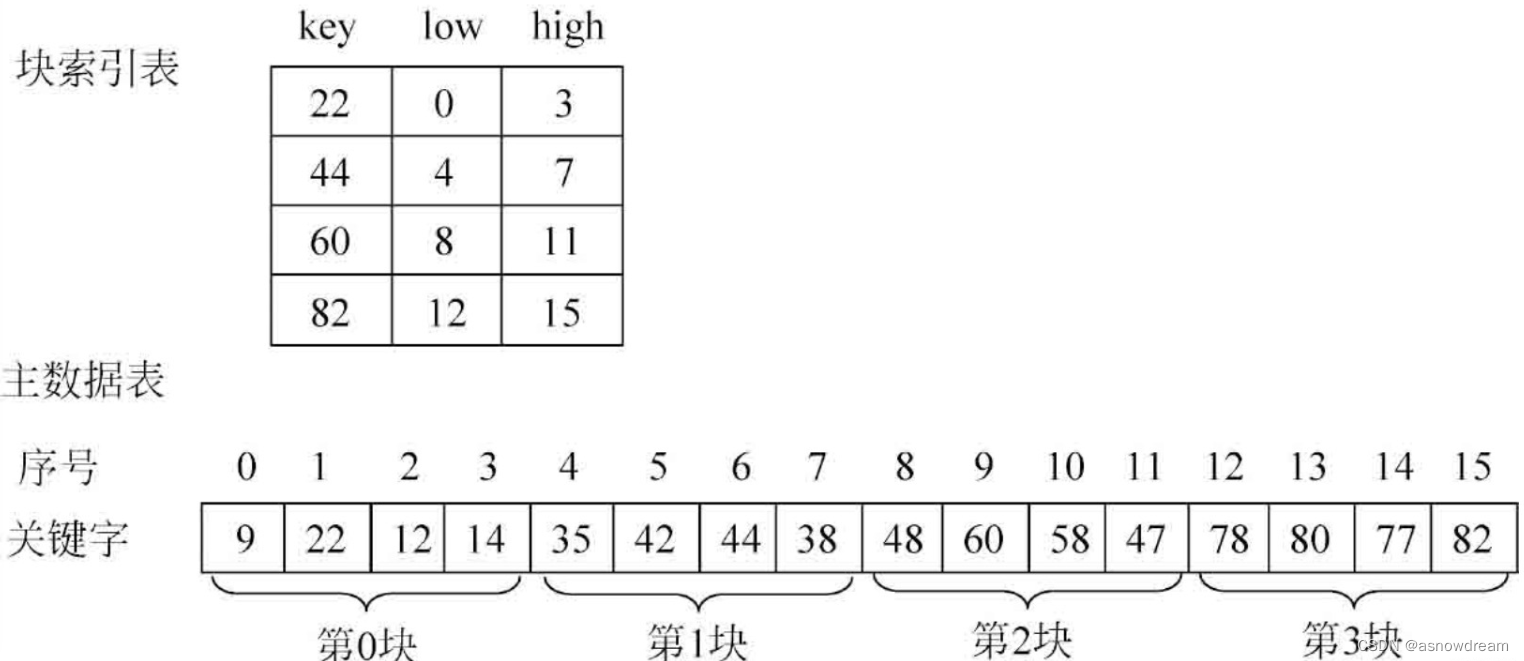
假如查找记录38;
1.先将key依次与索引表中各个最大的关键字进行比较,因为22<38<44则关键字为38的记录若存在则必定在第二块(子表)中。
2.然后从第二个块的qishi下标之间使用顺序查找key的具体位置,最终查找成功返回其下标:7,若查找失败就返回失败标识:-1。
代码实现:
package shuzu;
import java.util.Scanner;
public class fenkuaichaxun {
public static void main(String[] args) {
Scanner input=new Scanner(System.in);
//原表
int a[]={9,22,12,14,35,42,44,38,48,60,58,47,78,80,77,82};
//分块获得对应的索引表,这里是一个以索引结点为元素的对象数组
BlockTable [] arr={
new BlockTable(22,0,3),//最大关键字为22 起始下标为0,3的块
new BlockTable(44,4,7),
new BlockTable(60,8,11),
new BlockTable(82,12,15)
};
//打印原表
System.out.print("原表元素如下:");
for (int i = 0; i < a.length; i++) {
System.out.print(a[i]+" ");
}
System.out.println();
//待查关键字
System.out.print("请输入你所要查询的关键字:");
int key=input.nextInt();
//调用分块查找算法,并输出查找的结果
int result=BlockSearch(a,arr,key);
System.out.print("查询关键字的下标为:"+result);
}
private static int BlockSearch(int a[],BlockTable[] arr,int key){
int left=0,right=arr.length-1;
//利用折半查找法查找元素所在的块
while(left<=right){
int mid=(right-left)/2+left;
if(arr[mid].key>=key){
right=mid-1;
}else{
left=mid+1;
}
}
//循环结束,元素所在的块为right+1 取对应左区间下标作为循环的开始点
int i=arr[right+1].low;
//在块内进行顺序查找确定记录的最终位置
while(i<=arr[right+1].high&&a[i]!=key){
i++;
}
//如果下标在块的范围之内,说明查找成功,佛否则失败
if(i<=arr[right+1].high){
return i;
}else{
return -1;
}
}
}
//索引表结点
class BlockTable{
int key;
int low;
int high;
BlockTable(int key,int low,int high){
this.key=key;
this.low=low;
this.high=high;
}
}
Java数组的内存图
-
java内存分配,数组内存图
Java内存分配介绍:
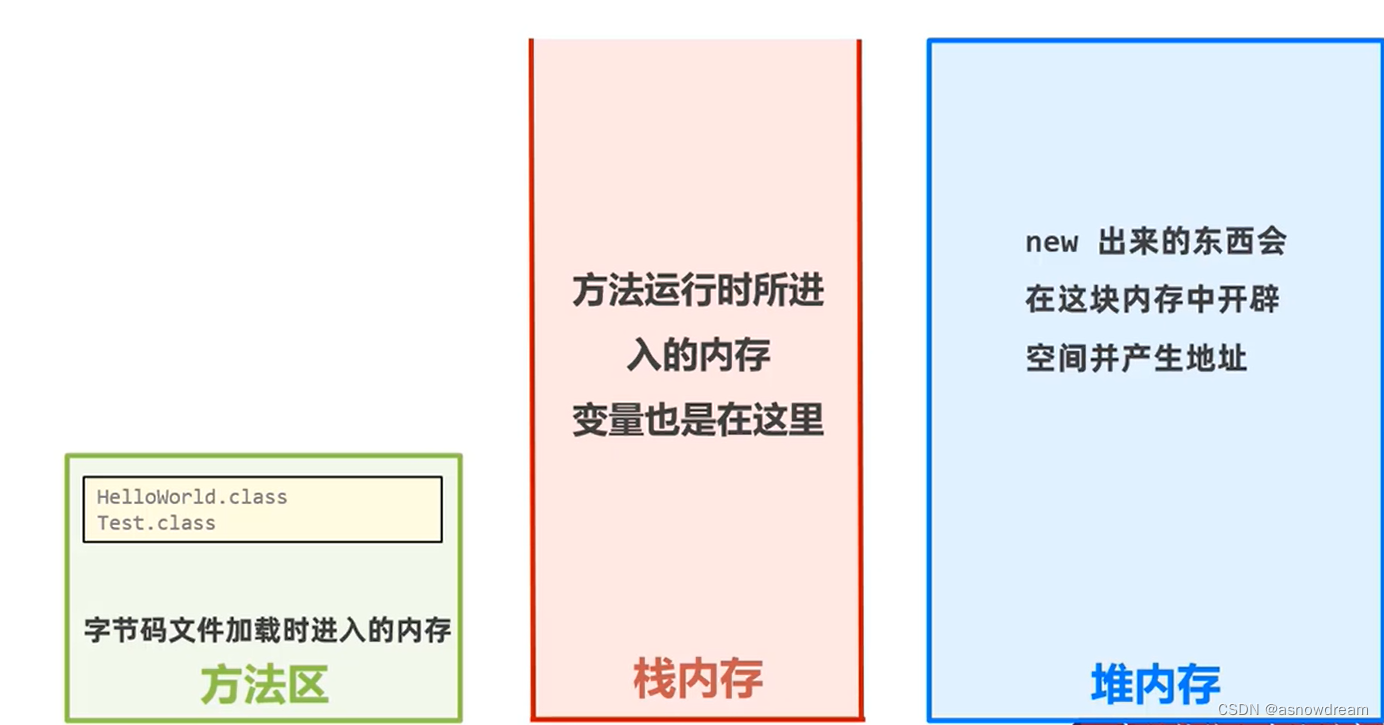
1.栈:主要方法运行是进入,以及变量。
2.堆:new出来的东西(对象)在这里开辟空间并产生地址。
3.方法区:字节码文件加载时进入
4.本地方法栈:Java虚拟机栈用于管理Java方法的调用,而本地方法栈用于管理本地方法的调用
5.寄存器:用于保存机器的运行状态,与微处理器中的某些专用寄存器类似。
下面通过具体代码运行讲述一下之间的过程:
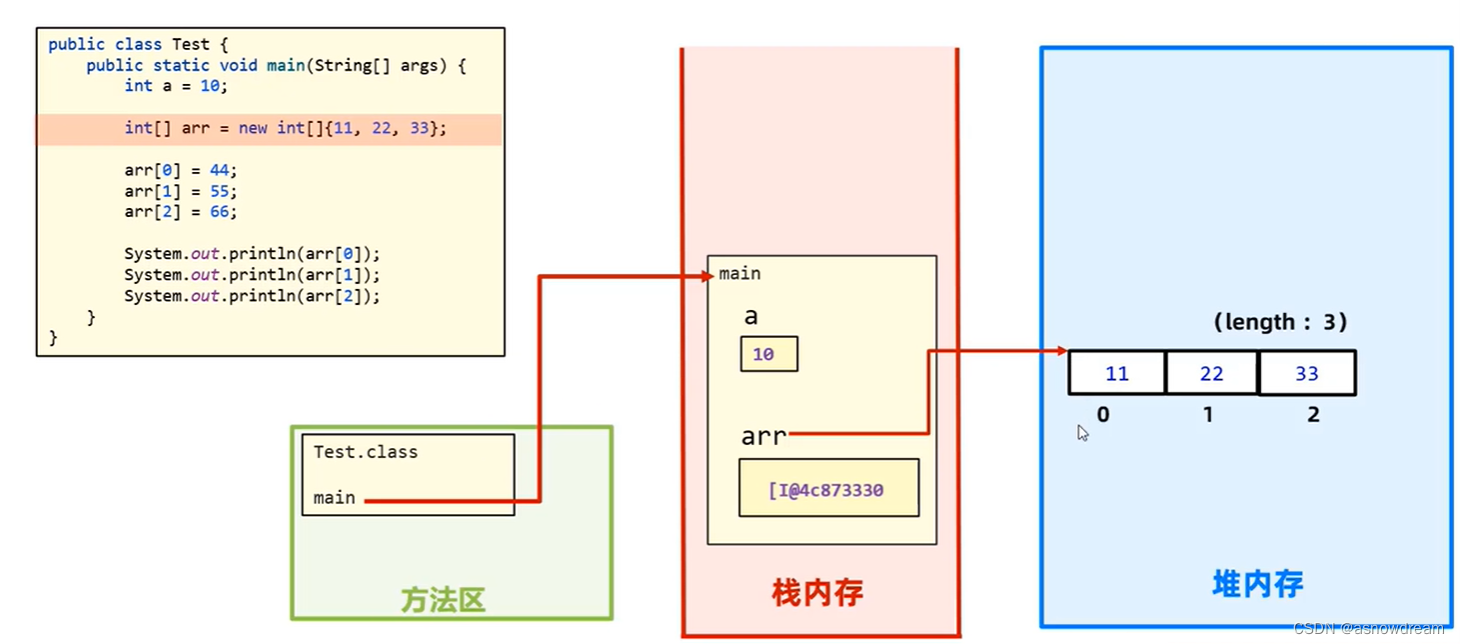
首先编译代码成class文件和main方法加载到方法区里面,然后把main方法提取到栈里面来运行,执行第一行代码的时候在栈内存中开辟一块区域a里面存储10,执行第二行代码的时候在栈内存中开辟一片区域arr,用于存储在堆内存中的数组内存地址,arr属于引用类型。在new一个对象的时候就会在堆内存中开辟一个连续的数组空间,存储数组元素,并且把数组所在空间的内存地址赋值给栈内存中的arr。
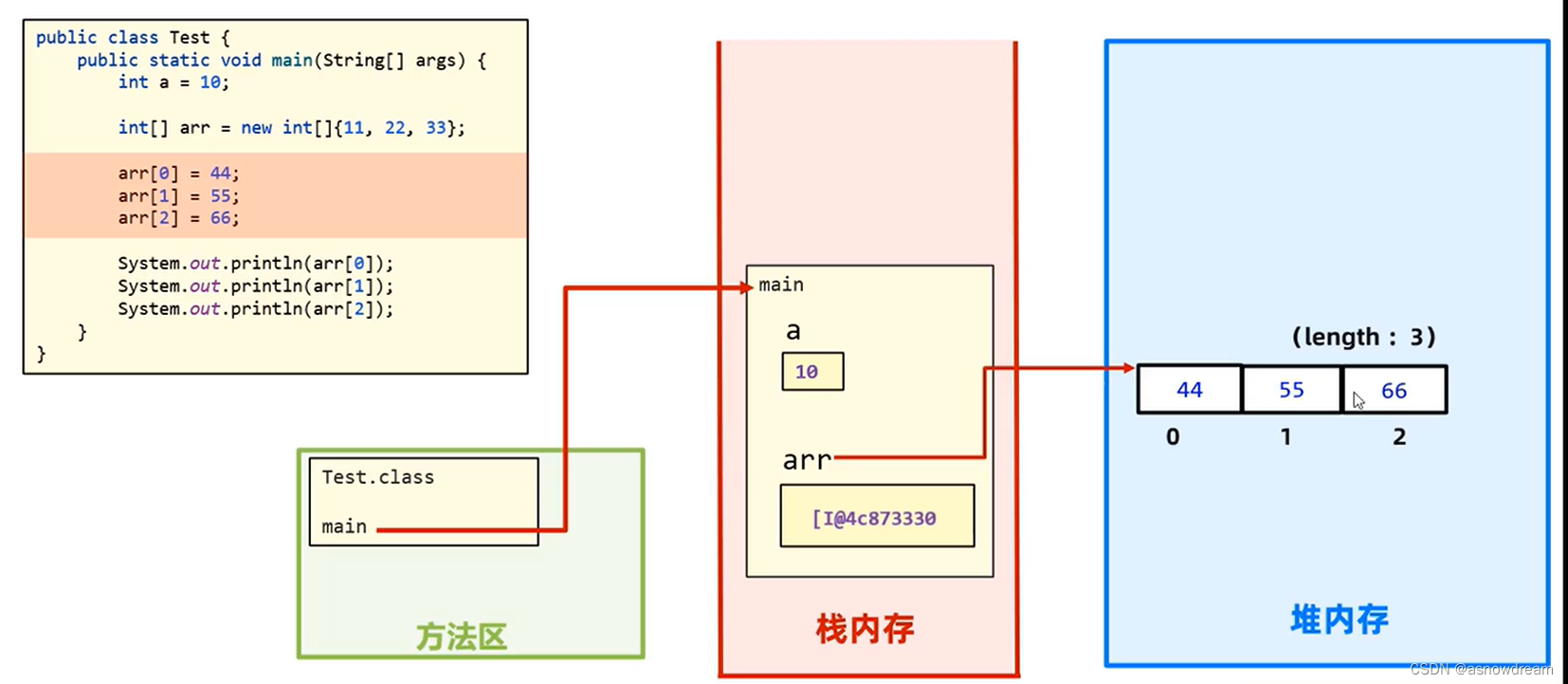
执行这个语句的时候就会根据内存地址以及数组下标把堆内存中列表对应位置上的数据进行修改。
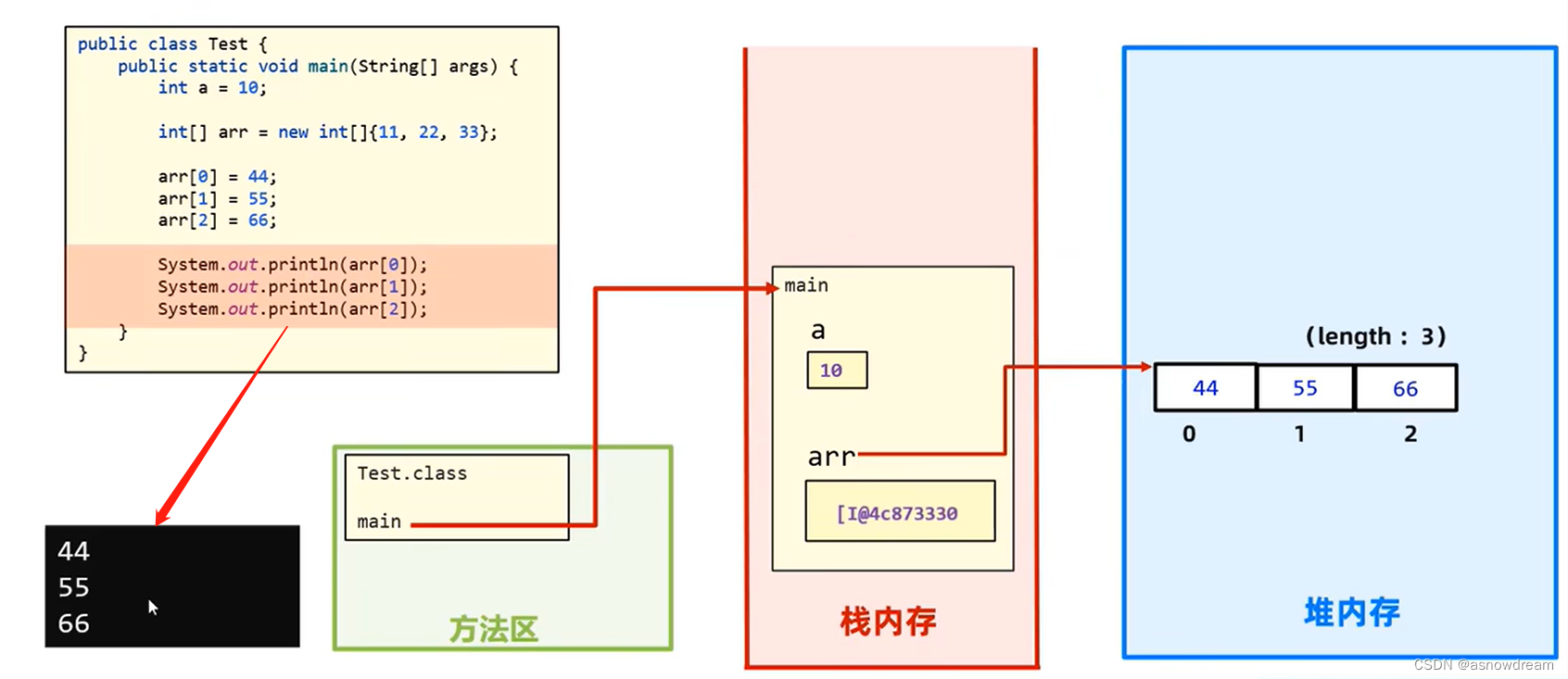
然后根据相同的索引方式把堆内存列表中的值进行输出操作。 -
两个变量指向同一个数组
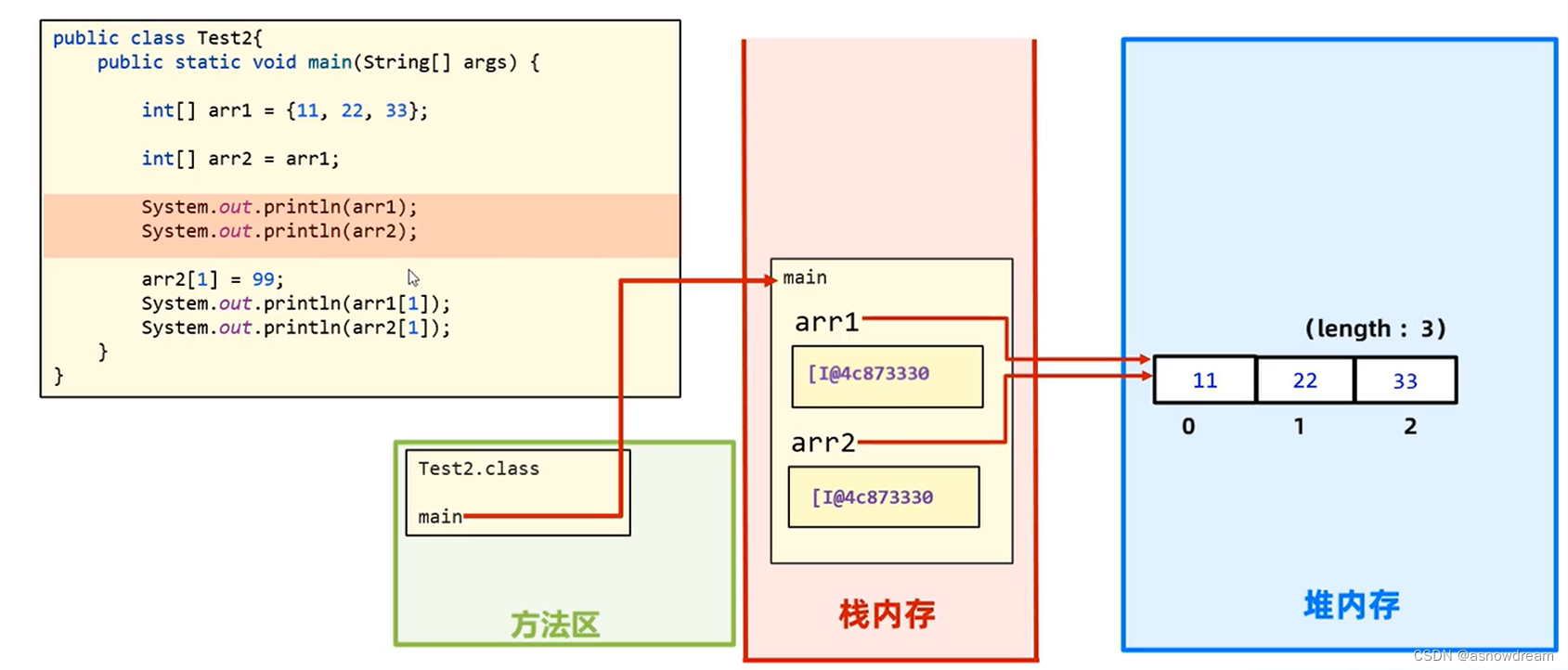
通过这个实例就会理解这个过程,前面的操作都是一样的,在把数组地址arr1赋值给新的空间的时候,arr2中存储的是也是内存地址,同时指向同一个数组。经过输出发现两个空间里面的内存地址是一样的。
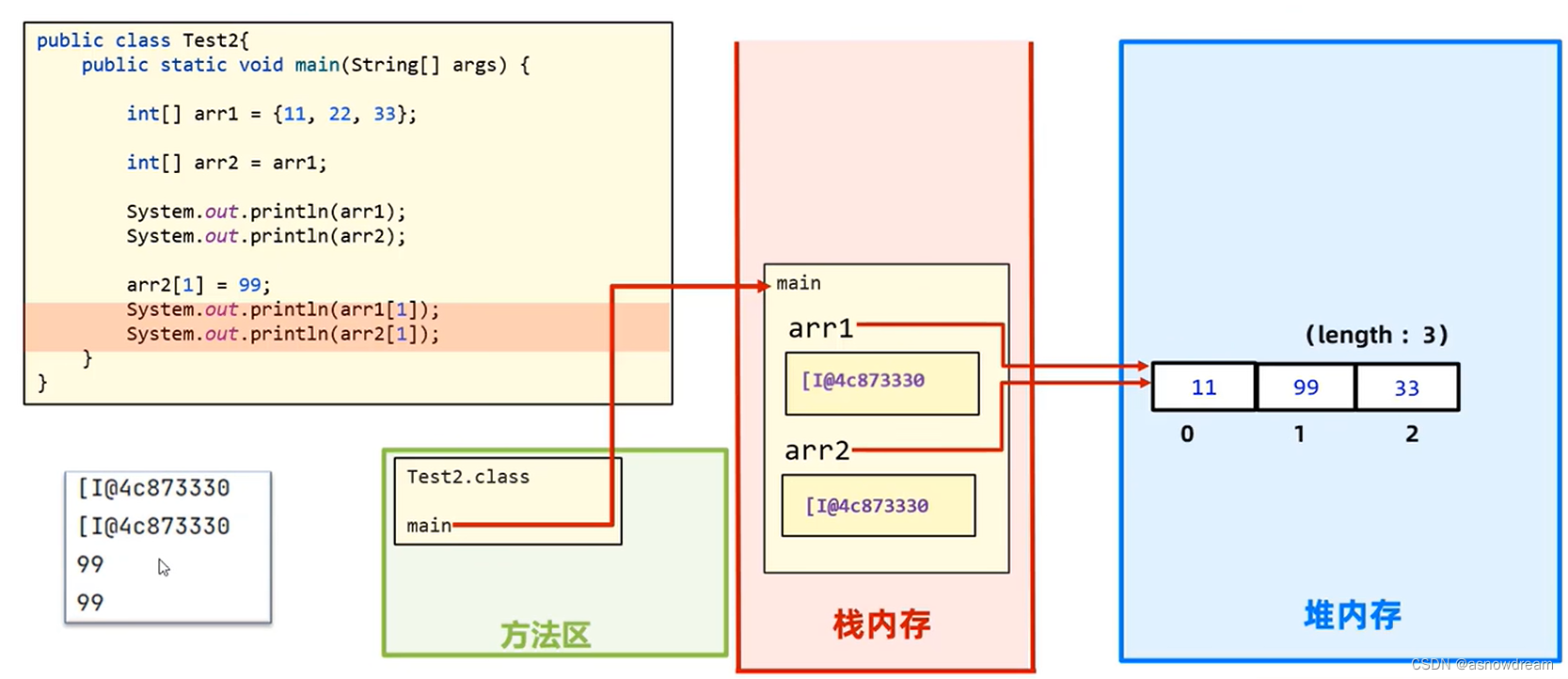
然后不论通过那个空间地址和数组下标对数组进行修改,最后打印输出的值是一样的,因为两个空间修改的是同一个数组,查询也是查询的同一个数组。
数组使用常见的问题
- 问题一: 如果访问的元素位置超过最大索引,执行时会出现ArrayindexOutOfBoundsException(数组索引越界异常)
- 问题二: 如果数组变量中没有存储数组的地址,而是忙null,在访问数组信息时会出现NuLLpointerException(空指针异常)
