acwing算法基础模版分析
文章目录
- 前言:
- 基础算法
- 快排模版
- 归并排序
- 整数二分算法
- 浮点数二分算法
- 一维前缀和数组
- 二维前缀和数组
- 一维差分数组
- 二维差分数组
- 位运算
- 离散化
- 区间和并
- 未完待续.....
前言:
本博客借鉴acwing的模版分析
基础算法
快排模版
void quick_sort(int q[], int l, int r)
{
if (l >= r)return;
int i = l - 1, j = r + 1, x = q[(r + l) >> 1];
while (i < j)
{
do i++; while (q[i] < x);
do j--; while (q[j] > x);
if (i < j)swap(q[i], q[j]);
}
quick_sort(q, l, j), quick_sort(q, j + 1, r);
}
模版分析:
i = r -1, j = l + 1//这步相当于双指针,至于为什么要往两边移一格呢?
这是为了指针移动的时候第一次就到达边界并且判断,
还有就是交换后,重新循环必须得先移动指针i和j才行,故这样写简直完美!
do i++; while (q[i] < x);
do j- -; while (q[j] > x);
i是找到比x大的停止,j是找到比x小的停止
归并排序
int tmp[50010] = { 0 };//辅助数组大小根据题目大小而定
void merge_sort(vector<int>&q, int l, int r)//归并模版
{
if (l >= r)return;
int mid = (r + l) >> 1;
merge_sort(q, l, mid), merge_sort(q, mid + 1, r);//分治
int i = l, j = mid+1, k = 0;
while (i <= mid && j <= r)//和并到辅助数组
{
if (q[i] < q[j])tmp[k++] = q[i++];
else
tmp[k++] = q[j++];
}
while (i <= mid)tmp[k++] = q[i++];
while (j <= r)tmp[k++] = q[j++];
for (int i = l, k = 0; i <= r; i++, k++)q[i] = tmp[k];//将排好序的辅助数组拷贝到原数组中,注意起始位置和终点位置
}
整数二分算法
int bsearch_1(int q[],int l,int r,int x)
{
while (l<=r)
{
int mid = (l + r+1) >> 1;
if (q[mid] <= x)l = mid;//这是找数组中最左边的x
else r = mid - 1;
}
return l;
}
int bsearch_2(int q[], int l, int r, int x)
{
while (l <= r)
{
int mid = (l + r) >> 1;
if (q[mid] >= x)r = mid;//这是找数组中最右边的x
else r = mid + 1;
}
return l;
}
模版分析:
先分析这里的mid为什么有两种取法!
由该图可知,mid的取法可以有这两种,而这两种分别对应着分割数组的边界!!!
先看当if(q[mid]<=x) l=mid;那么x应该在蓝色区域,所以我们的l应该等于(L+R+1)/2,否则就是在绿色区域,所以就是r=mid-1,所以我们这的mid应该为(L+R+1)/2,同理:当if(q[mid]>=x),那么x应该是在绿色区域,那么r应该为(L+R)/2,否则l应该为mid+1
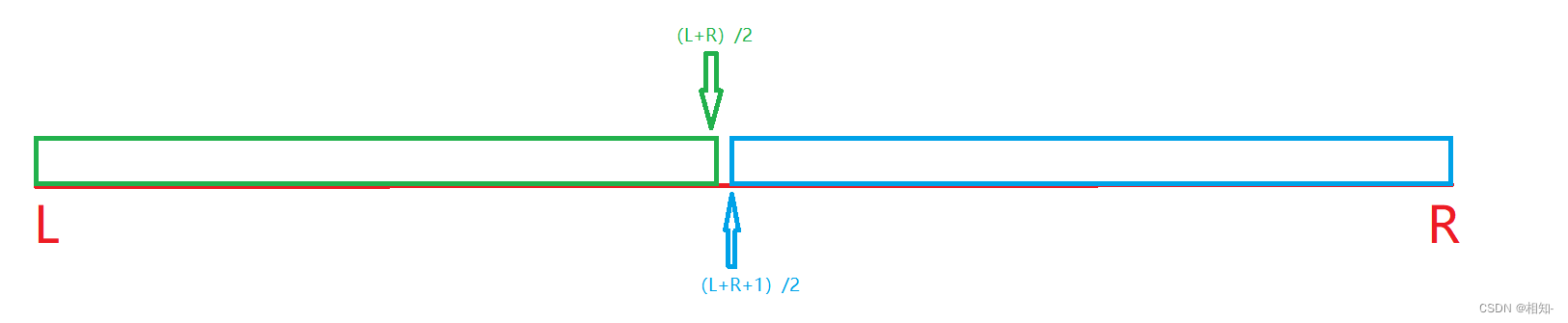
为什么说返回的位置是x在数组中的最左边或者最右边呢??
我们单看if(q[mid]>=x)这一个条件就能懂了,就算q[mid]==x了,他还有往右缩小范围,所以只有当缩小到最后一个x的位置他就不往右缩小了,那么就只能往左缩小了,因为我们知道指针只能我那个中间缩小,是单调的!
浮点数二分算法
这个算法一般是用来求开方后的结果的!!
用一个例题来理解!
给你一个数字x,请你求根号x的结果,保留六位小数!
double bsearch_3(double l, double r,double x)//l是从0开始,r就是x的值
{
const double eps = 1e-6;
while (r - l > eps)
{
double mid = (l + r) / 2;
if (mid * mid >= x)r = mid;//这里不能用l代替x,因为l是会变的,x是固定的
else l = mid;
}
return l;
}
模版分析:
图解:
一维前缀和数组
举个例子你就知道什么叫前缀和了,已知原数组是a(下标从1开始,0位置数值为0),前缀和数组是s,s[i]=a[0]+a[1]+…+a[i]
,这就是前缀和!!!
前缀和的好处是当你频繁计算区间和时,支持O(1)复杂度计算!
for(int i = 1; i < size(); ++i)
s[i] = s[i - 1] + a[i];//a数组是原数组,s数组是前缀和数组
性质:
求[L,R]区间和=>s[R]-S[L-1]
二维前缀和数组
看图分析:
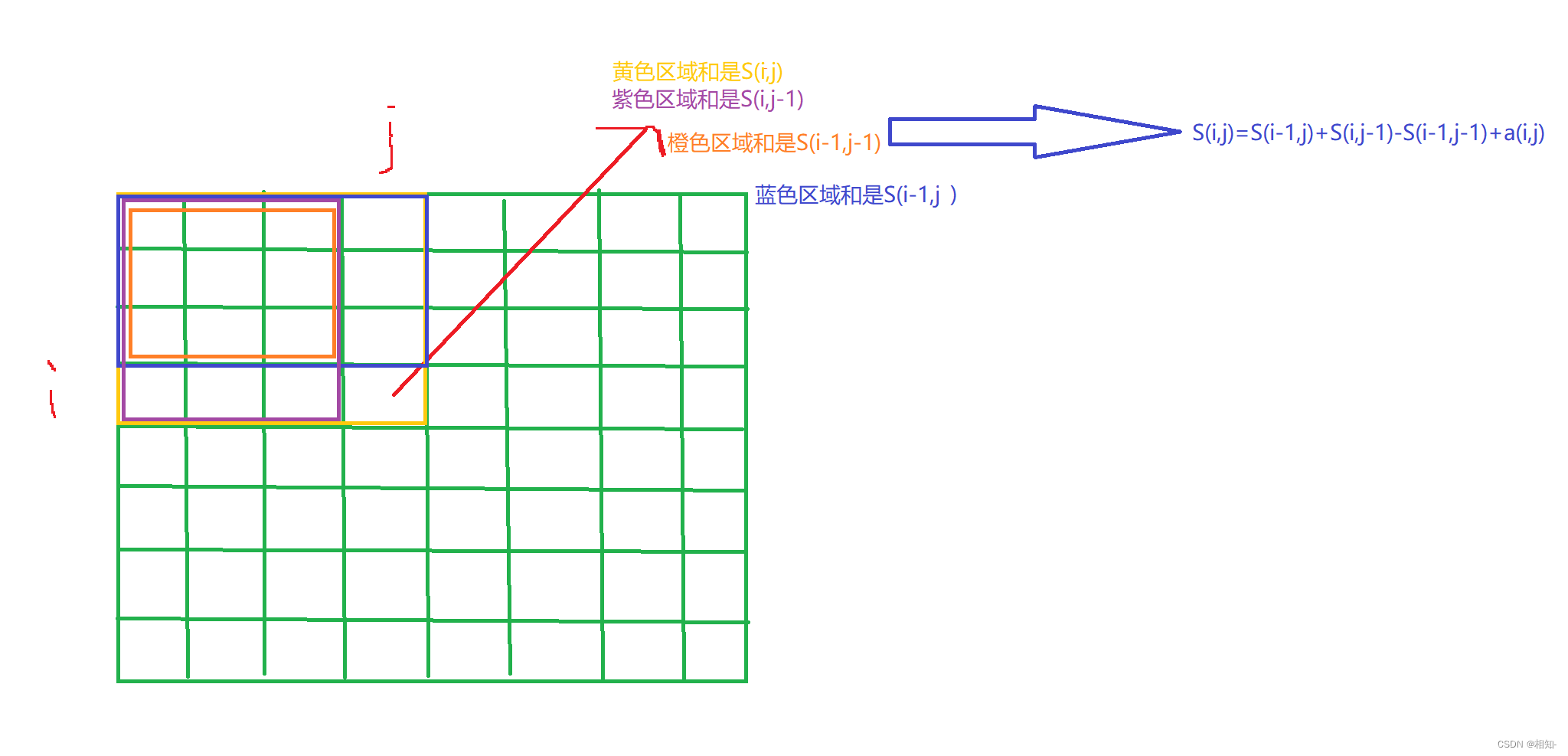
for(int i=1;i<a.size();++i)
for(int j=1;j<a[0].size();++j])
{
s[i][j]=s[i-1][j]+s[i][j-1]+s[i-1][j-1]+a[i][j];
}
性质:
求以(x1, y1)为左上角,(x2, y2)为右下角的子矩阵的和为: S[x2][y2]-S[x2][y1-1]-S[x1-1][y2]+S[x1][y1]
一维差分数组
举例说明什么是差分数组
原数组是a(下标从1开始,0位置数值为0),差分数组是b,
那么b[1]=a[1]-a[0],b[2]=a[2]-a[1], … ,b[i]=a[i]-a[i-1]
我们发现一个规律差分数组b的前缀和就是a数组
满足这样一个关系:
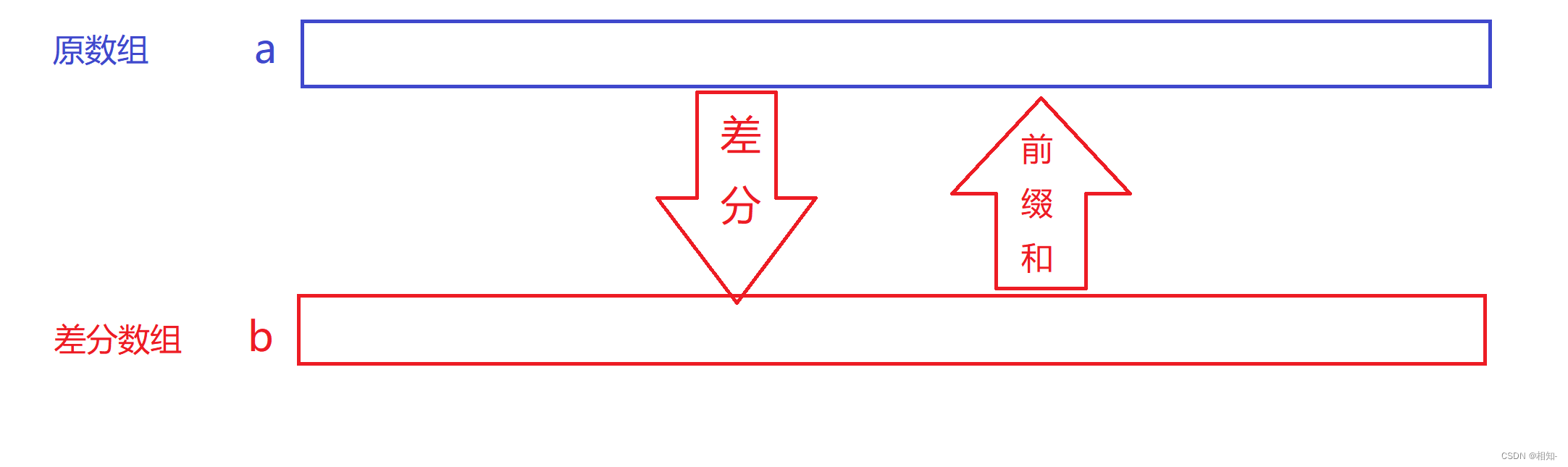
我们利用这个性质可以得出一个结论:
我们想在一个区间[L,R]都加上c,我们只需b[L]+=c,b[R+1]-=c;然后对b取前缀和得出所需要的结果!
为什么我们b[L]+=c,b[R+1]-=c只经过这个操作就可以在一个区间上加上c呢?
因为差分数组其实就是存的相邻原数组之间的差值d,我们要求原数组只不过是将这些d加起来而已,也就是前缀和(a[i]=d1+d2+d3+d4+d5+…+di),你在某一个d上加上c后,那么后面的a不都是加上c了吗,同理你在某一个d上减去c后,不就是都减去c了吗!!
我们用过这个原理可以直接构造出差分数组,我们假设原数组都是0,那么差分数组也都是0,我们输入一个a[i],就就相当于在差分数组的i位置加上a[i],输入完a数组后,差分数组也就构造完成了!
void insert(int l, int r, int c)
{
b[l] += c;
b[r + 1] -= c;
}
二维差分数组
有了一维差分的概念,二维差分我们看图应该可以理解!
我们假设在左上角(x1,y1),到右下角(x2,y2)这个区域加上c!
看图:

那么根据该图得到的公式为:
b[x1][y1]+=c,b[x2+1][y1]-=c,b[x1][y2+1]-=c,b[x2+1][y2+1]+=c
void insert(int x1, int y1,int x2,int y2 int c)
{
b[x1][y1] += c;
b[x1][y2 + 1] -= c;
b[x2 + 1][y1] -= c;
b[x1 + 1][y1 + 1] += c;
}
输入一个 nn 行 mm 列的整数矩阵,再输入 qq 个操作,每个操作包含五个整数 x1x1,y1y1,x2x2,y2y2,cc,其中 (x1,y1)(x1,y1) 和 (x2,y2)(x2,y2) 表示一个子矩阵的左上角坐标和右下角坐标。
每个操作都要将选中的子矩阵中的每个元素的值加上 cc。
请你将进行完所有操作后的矩阵输出。
Input
第一行包含整数 nn,mm,qq。
接下来 nn 行,每行包含 mm 个整数,表示整数矩阵。
接下来 qq 行,每行包含 55 个整数 x1x1,y1y1,x2x2,y2y2,cc,表示一个操作。
数据范围:
1≤n,m≤10001≤n,m≤1000,
1≤q≤1000001≤q≤100000,
1≤x1≤x2≤n1≤x1≤x2≤n,
1≤y1≤y2≤m1≤y1≤y2≤m,
−1000≤c≤1000−1000≤c≤1000,
−1000≤−1000≤矩阵内元素的值≤1000≤1000
Output
共 nn 行,每行 mm 个整数,表示所有操作进行完毕后的最终矩阵。
#include<iostream>
#include<stdio.h>
using namespace std;
const int N = 1010, M = 1010;
int a[N][M], b[N][M];
void insert(int x1, int y1, int x2, int y2, int c)//插入操作
{
b[x1][y1] += c;
b[x1][y2 + 1] -= c;
b[x2 + 1][y1] -= c;
b[x2+1][y2+1] += c;
}
int main()
{
int n, m, q;
cin >> n >> m >> q;
for (int i = 1; i <= n; i++)
for (int j = 1; j <= m; j++)
{
scanf("%d", &a[i][j]);
}
for (int i = 1; i <= n; i++)
for (int j = 1; j <= m; j++)
{
insert(i, j, i, j, a[i][j]);//构造差分数组
}
while (q--)
{
int x1, y1, x2, y2, c;
cin >> x1 >> y1 >> x2 >> y2 >> c;
insert(x1, y1, x2, y2, c);
}
for (int i = 1; i <= n; i++)
for (int j = 1; j <= m; j++)
{
b[i][j] += b[i - 1][j] + b[i][j - 1] - b[i - 1][j - 1];//求前缀和
}
for (int i = 1; i <= n; i++)
{
for (int j = 1; j <= m; j++)
printf("%d ", b[i][j]);
puts("");
}
return 0;
}
位运算
求n的第k位数字: n >> k & 1
返回n的最后一位1:lowbit(n) = n & -n
离散化
离散化就是一种哈希思想,对于一些连续的数据,其实也是映射的,比如数组中的数据,他是连续的,他是通过下边映射到对应的数据的,但是对于一些不连续的数据呢??? 那我们怎么办呢?如果通过数组下边映射存储的话,对应那些范围跨度小一点的还行,对应那些跨度非常大或者出现用负数映射的怎么办呢?我们可以用过一个离散化数组来存储映射的下标,然后用一个普通数组来存储对应的数据,但是我们怎么存呢?怎么通过离散化映射找到我们对应的数据呢? 我们这里先说说怎么存储吧,我们先将离散化数组排序,去重,然后通过find(二分查找)找到对应的下标,然后在普通数组中在该下标存储其数据! 所以我们想查找某个映射的数据,我们可以先find映射的下标,通过下标去查询数据!可能文字看不懂,我画个图帮助你理解!!!
a是val数组,alls是key数组,alls先将key排序,去重,然后通过其在数组中的下标,去a中对应的下标存储对应的val
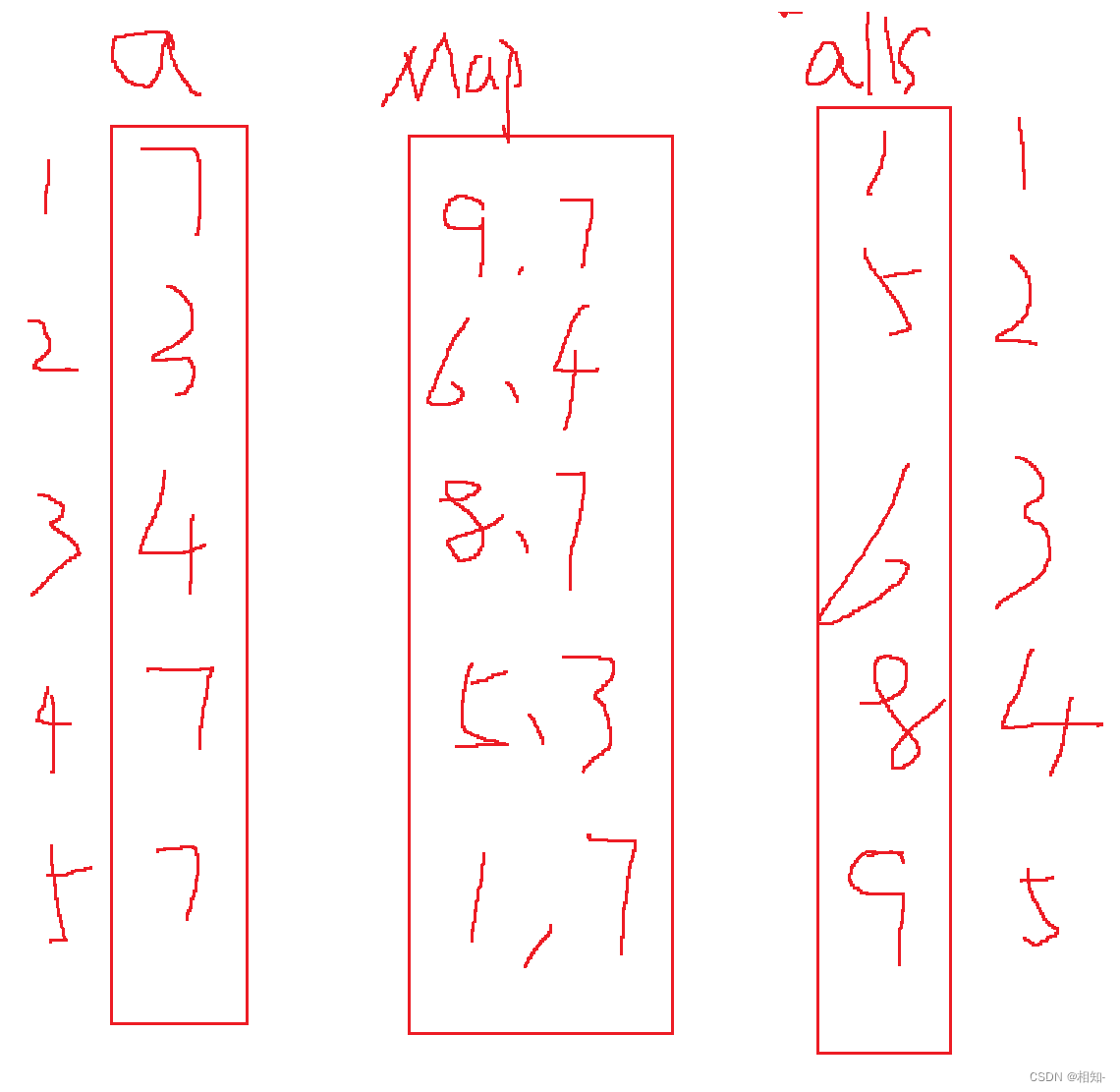
看一道离散化经典题目:

#include<iostream>
#include<vector>
#include <algorithm>
using namespace std;
typedef pair<int, int> PII;
const int N = 300010;
int a[N], s[N];
vector<int> alls;//离散化数组
vector<PII> add, query;//add是插入的x,c集合数组,query是询问结果区间的集合
int find(int x)//二分查找
{
int l = 0, r = alls.size() - 1;
int mid = (l + r) >> 1;
while (l < r)
{
mid = (l + r) >> 1;
if (alls[mid] >= x) r = mid;
else l = mid + 1;
}
return l + 1;
}
int main()
{
int n, m;
cin >> n >> m;
while (n--)
{
int x, c;
cin >> x >> c;
add.push_back({ x,c });//将插入的x,c放到add中,这就是map映射关系
alls.push_back(x);//插入key
}
while (m--)
{
int l, r;
cin >> l >> r;
query.push_back({ l,r });
alls.push_back(l);//插入key
alls.push_back(r);//插入key
}
sort(alls.begin(), alls.end());//排序
alls.erase(unique(alls.begin(), alls.end()), alls.end());//去重
for (auto& e : add)
{
int x = find(e.first);//得到key在数组中的下标
a[x] += e.second;通过该下标去存储对应的val
}
for (int i = 1; i <= alls.size(); ++i)
s[i] = s[i - 1] + a[i];//求前缀和数组
for (auto& q : query)
{
int l = find(q.first), r = find(q.second);
cout << s[r] - s[l - 1] << endl;
}
return 0;
}
区间和并

分析:
先将区间排序,这个应该容易想的,区间之间的关系无非就相交,不相交,包含,这三种关系,可以先用两个指针st,ed指向前一个区间的两边,然后去更新他,当有区间交集的时候,就将当前区间和前一个区间合并,这里就是将指针ed移动而已,当没有交集就加入到新区间数组中去,以此类推!!要注意的是,我们遍历第一个区间的时候,我们可以将st,ed指向一个更小的区间(并不存在)
#include<iostream>
#include<vector>
#include <algorithm>
using namespace std;
typedef pair<int, int> PII;
vector<PII> segs;
vector<PII> tmp;
void merge(vector<PII>& segs)
{
sort(segs.begin(), segs.end());//将所以的区间排序
int st = -2e9, ed = -2e9;//先设置一个无穷小区间,在题目范围外的
for (auto& seg : segs)
{
if (ed < seg.first)//没有交集时
{
if (ed != -2e9)tmp.push_back({ st,ed });//如果不是无穷小区间就将前一个区间加入到新区间集合中
st = seg.first;//然后指针指向新区间
ed = seg.second;
}
else
ed = max(ed, seg.second);//如果有交集,就更新ed
}
if (ed != -2e9)tmp.push_back({ st,ed });//这是防止只有一个区间
}
int main()
{
int n;
cin >> n;
while (n--)
{
int l, r;
cin >> l >> r;
segs.push_back({ l,r });
}
merge(segs);
cout<<tmp.size();
return 0;
}