详细介绍LinkedList
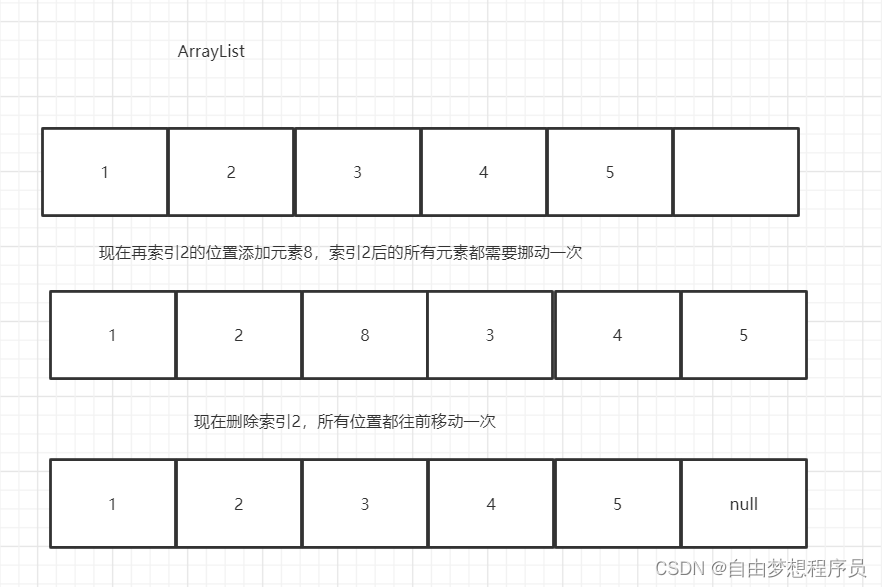
ArrayLIst引发的思考
- 优点:查询快
- 缺点:
1、增删慢,消耗CPU的的性能 - 情况一:指定索引位置上的添加
- 情况二:原数组位置不够了(这时候就需要扩容,而扩容则是原数组的1.5倍的长度)具体为何是1.5倍,可以期待下一篇文章,我将会详细解析ArrayList的源码、
2、比较浪费空间 - 有没有一种数据结构可以用多少空间就申请多少空间,并且又能够提高他的性能速度?
链表
- 链表的分类:单链表、双链表、循环链表
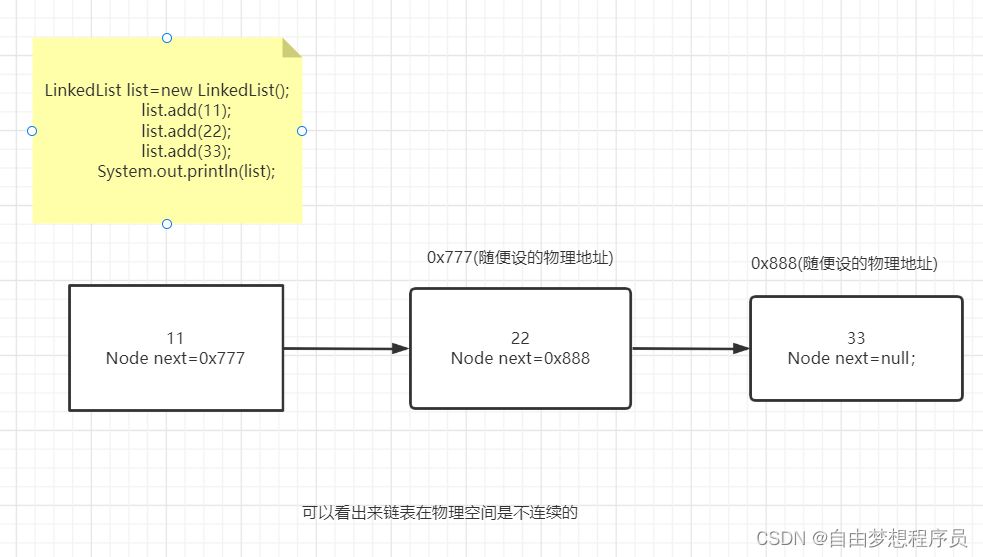
- 链表:由链将一个个元素连接起来,每一个元素称为Node节点
- Node节点;由两部分组成
- 数据值的变量
- Node next指向下一个节点的Node对象
- 链表的特点就是就是查询非常的慢(没有索引)但是增删非常的快
LinkedList list=new LinkedList();
list.add(11);
list.add(22);
list.add(33);
System.out.println(list);

自定义单向链表
刚开始入门的时候可以对着文章自己尝试做做,后面就自己就可以尝试对照LinkedList源码进行编写
- 创建LIst接口
package demo2.inter;
//将arrayList和LinkedList中共性方法进行抽取-》保证体系的完成
public interface List<E> {
int size();
boolean isEmpty();
boolean contains(E element);
void add(E element);
E get(int index);
E set(int index,E element);
void add(int index,E element);
E remove(int index);
int indexOf(E element);
void clear();
String toString();
}
- 创建抽象类AbstractList
package demo2.AbstractClass;
import demo2.inter.List;
//用于实现LinkedList和ArrayList中的那些共性方法
public abstract class AbstractList<E> implements List<E> {
protected int size;
@Override
public int size() {
return size;
}
//判断当前的集合是否有元素
@Override
public boolean isEmpty() {
return size==0;
}
//indexOf:寻找指定索引的元素,如果找到了就返回元素的索引,如果没找到就返回一个-1
@Override
public boolean contains(E element) {
return indexOf(element) !=-1;
}
}
- 创建LinkedList
package demo2.Linked;
import demo2.AbstractClass.AbstractList;
public class LinkedList<E> extends AbstractList<E> {
private Node first;
private static class Node<E> {
Node<E> next;
E element;
public Node(Node next,E element){
this.next=next;
this.element=element;
}
}
@Override
public void add(E element) {
//在末尾添加元素
//直接调用add(index,element)
//就把index设值为size就行了
add(size,element);
}
@Override
public E get(int index) {
//获取到指定位置链表的值
return node(index).element;
}
private Node<E> node(int index) {
Node x=first;
//index<0 && index>size就应该抛出异常
checkElementIndex(index);
for (int i = 0; i < index; i++) {
x=x.next;
}
return x;
}
private void checkElementIndex(int index) {
if (!isPositionIndex(index)) {
throw new IndexOutOfBoundsException("Index:" + index + ", Size:" + size);
}
}
private boolean isPositionIndex(int index) {
return index>=0 && index<=size;
}
private boolean isElementIndex(int index) {
//满足条件
return index>=0 && index<=size;
}
@Override
public E set(int index, E element) {
//将指定位置的值设置为element
//返回的是原来的链表位置的值
E oldElement = node(index).element;
node(index).element=element;
return oldElement;
}
//最复杂的一个方法
@Override
public void add(int index, E element) {
//在指定位置添加element元素
//判断位置是否合理
checkPositionIndex(index);
//考虑极端情况
if (index==0){
//最先开始first是空链表,也就是null
first=new Node(first,element);
}else {
//获得index-1的节点,也称为前节点
//然后在获取index的节点,使它作为我们要创建的节点一个节点
Node pre = node(index - 1);
Node next = node(index);
pre.next = new Node(next, element);
//做完后发现报了index=-1的错误,说明我们没有考虑到极端情况
//也就是index=0的时候,index-1就是-1
//然后抛出异常
}
size++;
}
private void checkPositionIndex(int index) {
if (!isElementIndex(index)) {
throw new IndexOutOfBoundsException("Index:" + index + ", Size:" + size);
}
}
@Override
public E remove(int index) {
checkElementIndex(index);
//删除指定位置的元素并返回
Node<E> pre = node(index);
Node node=pre.next;
pre.next=node.next;
node.next=null;
E element = (E) node.element;
size--;
return element;
}
@Override
public int indexOf(E element) {
//返回指定元素的第一次出现的索引index
int index=0;
//这里也可以思考下为什么要分element是否为null的情况
if(element==null){
for (Node<E> x=first;x!=null;x=x.next){
if (x.element==element){
return index;
}
index++;
}
}else{
for (Node<E> x=first;x!=null;x=x.next){
//大家可以思考为啥不是x.element.equals(element)
//答:这是避免因为x.element值为null的情况
//如果x.element是null,那么equals方法就会报错
//这也是平时需要注意的点
if (element.equals(x.element)){
return index;
}
index++;
}
}
//如果未找到返回-1
return -1;
}
@Override
public void clear() {
//gc回收器会自动回收不需要的对象
first=null;
size=0;
}
public String toString(){
/*
这里之所以选择StringBuilder数据结构,原因如下
1、动态字符串,所以排除String数据结构
2、StringBuffer几乎所有的方法都使用synchronized实现了同步,线程比较安全,在多线程系统中可以保证数据同步,但是效率比较低
而StringBuilder 没有实现同步,线程不安全,在多线程系统中不能使用 StringBuilder,但是效率比较高。
*/
StringBuilder sb=new StringBuilder();
if (size==0){
return "[]";
}
sb.append("[");
for (Node i=first;i!=null;i=i.next){
sb.append(i.element);
if (i.next==null){
return sb.append("]").toString();
}
sb.append(",");
}
return sb.toString();
}
}
双链表
双链表简单来说有两个指针的链表,一个指向头,一个指向尾
双链表的遍历可能优于单链表
package demo2.Linked;
import demo2.AbstractClass.AbstractList;
public class LinkedList2<E> extends AbstractList<E> {
private Node first;
private Node last;
private static class Node<E> {
Node<E> pre;
Node<E> next;
E element;
public Node(Node pre,Node next,E element){
this.pre=pre;
this.next=next;
this.element=element;
}
}
@Override
public void add(E element) {
//在末尾添加元素
//直接调用add(index,element)
//就把index设值为size就行了
add(size,element);
}
@Override
public E get(int index) {
//获取到指定位置链表的值
return node(index).element;
}
private Node<E> node(int index) {
Node x=first;
//index<0 && index>size就应该抛出异常
checkElementIndex(index);
//先去判断index使=是靠近头还是尾
//如果是靠近头就从头开始找
//如果靠近尾就从尾开始找
if (index<size/2){
//从第一个节点开始遍历
for (int i=0;i<index;i++){
x=x.next;
}
return x;
}else {
//从尾节点开始查找
for (int i=size-1;i>index;i--){
x=x.pre;
}
return x;
}
}
private void checkElementIndex(int index) {
if (!isPositionIndex(index)) {
throw new IndexOutOfBoundsException("Index:" + index + ", Size:" + size);
}
}
private boolean isPositionIndex(int index) {
return index>=0 && index<=size;
}
private boolean isElementIndex(int index) {
//满足条件
return index>=0 && index<=size;
}
@Override
public E set(int index, E element) {
//将指定位置的值设置为element
//返回的是原来的链表位置的值
E oldElement = node(index).element;
node(index).element=element;
return oldElement;
}
//最复杂的一个方法
@Override
public void add(int index, E element) {
//在指定位置添加element元素
//判断位置是否合理
checkPositionIndex(index);
if (index==size){
//1、添加到末尾
//2.没有元素的时候
linkLast(element);
}else{
//添加到头部
linkBefore(index,element);
}
size++;
}
//头插法
private void linkBefore(int index, E element) {
/**
* 1、获得指定的node
* 2、前一个节点的获取
* 3、构建新的node->完成指向关系
* 4、改变1、2的指向
*/
Node<E> next = node(index);
Node pre=next.pre;
Node node=new Node(pre,next,element);
next.pre=node;
if (pre==null){
first=node;
}else {
pre.next=node;
}
}
//尾插法
private void linkLast(E element) {
/**
* 1、拿到last节点
* 2、构建node完成它的指向关系
* 3、将原来的last节点的next修改为新构建出来的node
* 4、将原来的last进行修改
*/
Node<E> oldLast=last;
Node newLast=new Node(oldLast,null,element);
last=newLast;
if (oldLast==null){
first=newLast;
}else {
oldLast.next=newLast;
}
size++;
}
private void checkPositionIndex(int index) {
if (!isElementIndex(index)) {
throw new IndexOutOfBoundsException("Index:" + index + ", Size:" + size);
}
}
@Override
public E remove(int index) {
/**
* 1、获得要删除的元素Node
* 2、获得前一个节点
* 3、获得后一个节点
* 4、需要改变前一个节点的next
* 5、改变后一个节点pre
*/
checkElementIndex(index);
Node<E> node = node(index);
Node pre=node.pre;
Node next=node.next;
E element = node.element;
if (pre==null) {
next.pre=null;
first=next;
}else if (next==null){
pre.next=null;
last=pre;
}else {
pre.next=next;
next.pre=pre;
}
size--;
return element;
}
@Override
public int indexOf(E element) {
//返回指定元素的第一次出现的索引index
int index=0;
//这里也可以思考下为什么要分element是否为null的情况
if(element==null){
for (Node<E> x=first;x!=null;x=x.next){
if (x.element==element){
return index;
}
index++;
}
}else{
for (Node<E> x=first;x!=null;x=x.next){
//大家可以思考为啥不是x.element.equals(element)
//答:这是避免因为x.element值为null的情况
//如果x.element是null,那么equals方法就会报错
//这也是平时需要注意的点
if (element.equals(x.element)){
return index;
}
index++;
}
}
//如果未找到返回-1
return -1;
}
@Override
public void clear() {
//gc回收器会自动回收不需要的对象
first=null;
size=0;
last=null;
}
public String toString(){
/*
这里之所以选择StringBuilder数据结构,原因如下
1、动态字符串,所以排除String数据结构
2、StringBuffer几乎所有的方法都使用synchronized实现了同步,线程比较安全,在多线程系统中可以保证数据同步,但是效率比较低
而StringBuilder 没有实现同步,线程不安全,在多线程系统中不能使用 StringBuilder,但是效率比较高。
*/
StringBuilder sb=new StringBuilder();
if (size==0){
return "[]";
}
sb.append("[");
for (Node i=first;i!=null;i=i.next){
sb.append(i.element);
if (i.next==null){
return sb.append("]").toString();
}
sb.append(",");
}
return sb.toString();
}
}