Python爬虫入狱小技巧

呀,来坐牢的是吧,坐牢是不可能坐牢的,骚年,下面就是方法,早上学,晚上进去
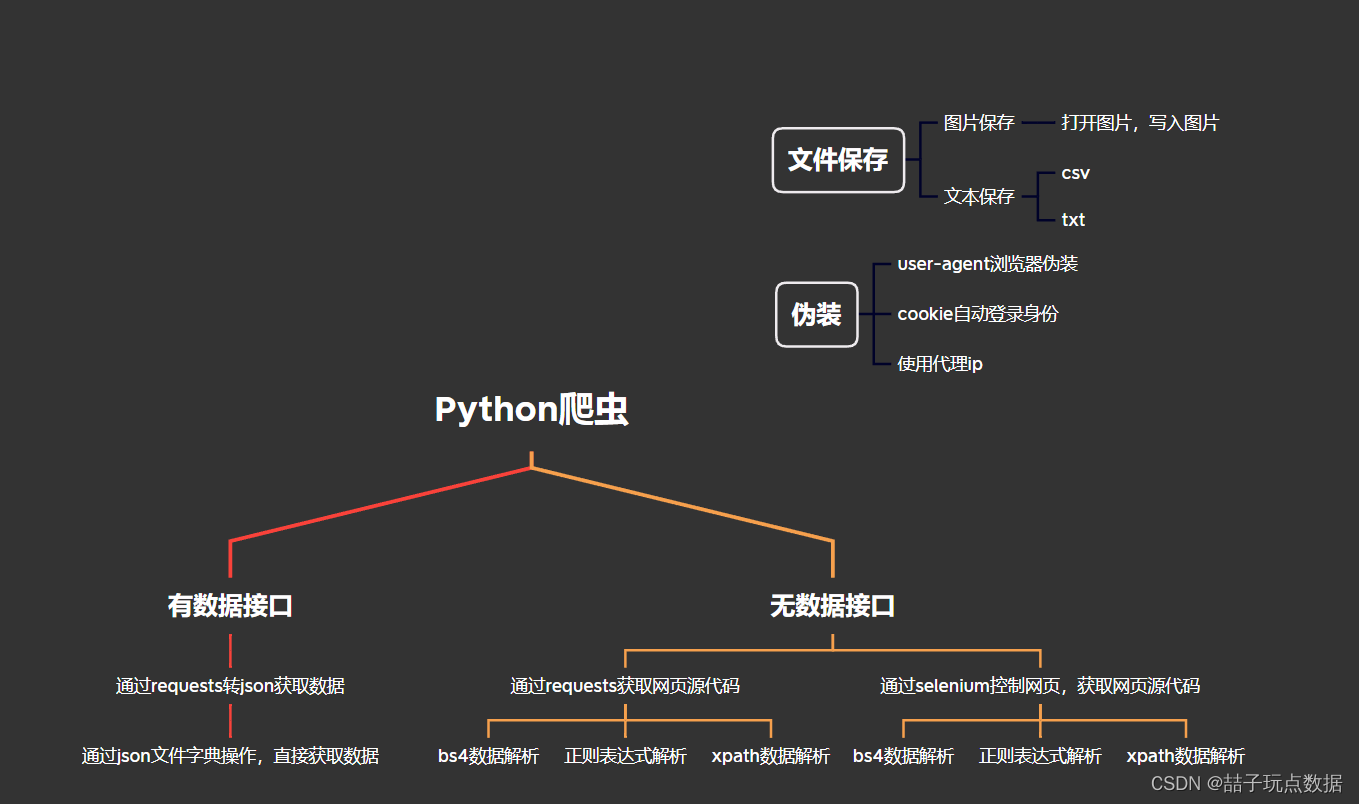
一、整体思路
爬虫一开始要把思路理清楚,即从网页源代码或者网页数据接口,获取需要的数据.大致思路如下
1.有数据接口,直接用requests获取json文件源代码,然后字典操作获取数据
2.没有数据集接口:
1)通过requests获取源代码,通过三大方法解析数据
2)通过selenium获取源代码,通过三大方法解析数据
3.伪装:
1)user-agent主要用于获取源代码时,网站防爬虫伪装浏览器
2)cookie主要用于账号登陆,伪装身份登录网站
3)代理ip用于访问网站被封ip后,用其他地址进入网站获取数据
4.文件保存:把文件长期保存,便于后期调用,搭建数据库
二、登录
1.user-agent:通过如图获取(图片敏感,删了):
进入网页
检查网页
点击network
All
刷新网页
选择网页的那个点
Headers
寻找user-agent
2.cookie获取:如图获取(图片敏感,删了):
进入网页
检查网页
点击network
All
选择网页的那个点
Headers
寻找cookie
3.代理ip使用:
1).requests:
headers = {xxx}
proxies = {'https': '代理ip'}
response = requests.get('网站地址', headers=headers, proxies=proxies)
2).selenium:
from selenium.webdriver import Chrome, ChromeOptions
# 1. 给浏览器添加配置
options = ChromeOptions()
#设置代理
options.add_argument('--proxy-server=http://171.83.191.223:4526')
b = Chrome(options=options)
b.get('网站')
三、有数据接口:
1.获取数据接口
在preview中观察比较像数据接口的点,选择最像字典,而且有数据的点
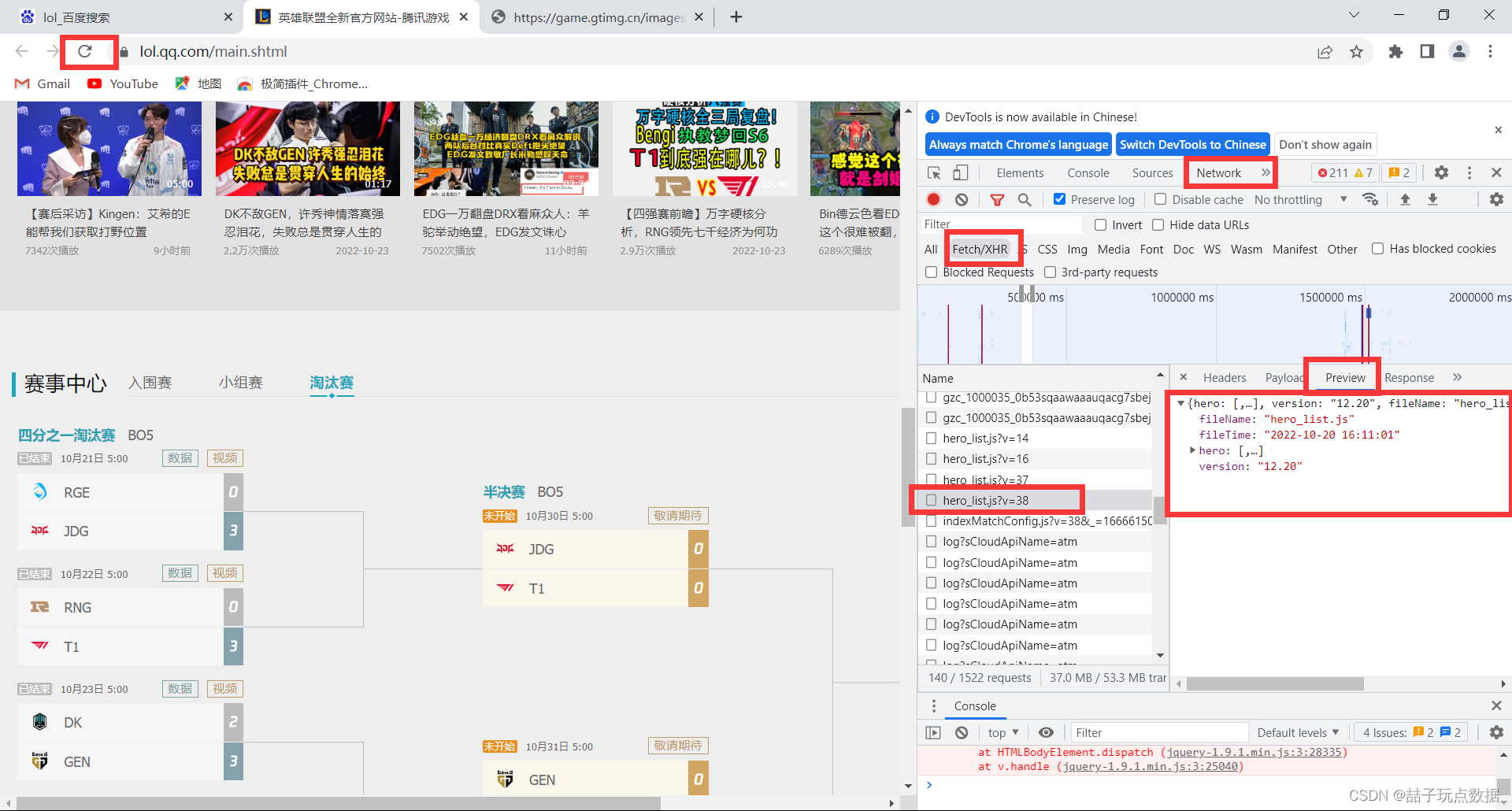
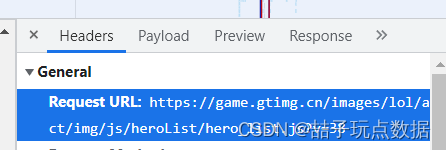
确定哪个是自己想要的数据接口后,点击他的Headers,然后获取Request URL
2.进入接口,转json解析
import requests
response = requests.get('数据接口')
# 接口数据转字典
result = response.json()
# 遍历获取的字典数据中newlist键下面title键的值
for x in result['newslist']:
print(x['title'])
四、无数据接口
1.requests
1)bs4数据解析
创建BeautifulSoup生成对象
import requests
from bs4 import BeautifulSoup
headers = {'user-agent': 'xxx'}
response = requests.get('网站', headers=headers)
html = response.text
soup = BeautifulSoup(html, 'lxml')
基于css选择器解析数据:获取标签 -> 获取标签内容和标签属性
1)获取标签
BeautifulSoup对象.select(css选择器) - 获取整个网页中css选择器选中的所有标签;返回一个列表,列表中元素是标签对象
BeautifulSoup对象.select_one(css选择器) - 获取整个网页中css选择器选中的第一个标签;返回一个标签对象
标签对象.select(css选择器) - 获取指定标签中css选择器选中的所有标签
标签对象.select_one(css选择器) - 获取指定标签中css选择器选中的第一个标签
2)获取标签内容和标签属性
标签对象.text - 获取标签内容
标签对象.attrs[属性名] - 获取指定标签中指定属性的值
例如下面提取
div_list = soup.select('.grid_view>li>.item')
print(div_list)
for div in div_list:
title = div.select_one('.title').text
comment = div.select('.star>span')[-1].text
score = div.select_one('.star>.rating_num').text
print(title, comment, score)
2)xpath数据解析
创建xpath数据生成对象
import requests
from lxml import etree
headers = {xxx}
response = requests.get('网站', headers=headers)
root = etree.HTML(response.text)
例如下面提取
all_div = root.xpath('//ol[@class="grid_view"]/li/div')
for x in all_div:
name = x.xpath('./div[@class="info"]/div[1]/a/span[1]/text()')[0]
score = x.xpath('./div[@class="info"]/div[2]/div/span[2]/text()')[0]
print(name, score)
2.selenium
1)bs4数据解析
创建BeautifulSoup生成对象
from selenium.webdriver import Chrome
from bs4 import BeautifulSoup
# 1.创建浏览器,打开网站
b = Chrome()
b.get('网站')
# 滚动操作
b.execute_script('window.scrollBy(0, 800)')
# 关闭图片加载
options.add_experimental_option("prefs", {"profile.managed_default_content_settings.images": 2})
# 取消测试环境
options.add_experimental_option('excludeSwitches', ['enable-automation'])
# 2. 获取网页源代码
html = b.page_source
# 3. 关闭浏览器
b.close()
soup = BeautifulSoup(html, 'lxml')
# 接下来就是与上面相同,用bs4解析
2)selenium按钮和输入操作
# 2.通过浏览器获取想要控制的标签
# b.find_element_by_id(id属性值) - 获取当前页面中id属性值为指定值的标签
# b.find_element_by_class_name(class属性值) - 获取当前页面中class属性值为指定值的第一个标签
# b.find_element_by_css_selector(css选择器) - 在当前页面中获取css选择器选中的第一个标签
# b.find_elements_by_class_name(class属性值) - 获取当前页面中所有class属性值为指定值的标签, 返回一个列表
# b.find_elements_by_css_selector(css选择器) - 在当前页面中获取css选择器选中的所有标签,返回一个列表
input_tag = b.find_element_by_id('key')
seckill = b.find_elements_by_class_name('navitems-lk')[2]
# 3. 操作标签
# 标签对象.click() - 点击指定标签
# seckill.click()
# 标签对象.send_keys(想要输入的内容) - 控制输入框输入指定内容
# input_tag.send_keys('电脑\n')
seckill.click()
3)xpath数据解析
创建xpath数据生成对象
import requests
from lxml import etree
headers = {xxx}
response = requests.get('网站', headers=headers)
root = etree.HTML(response.text)
五、文件保存
图片保存
import requests
x='https://ossweb-img.qq.com/images/clientpop/act/lol_1666321648_uploadnewsImg.jpg'
img_response = requests.get(x)
f = open(f'1.jpeg', 'wb')
f.write(img_response.content)
f.close()
文件夹建立
import os
if not os.path.exists('bad'):
os.mkdir('bad')
csv数据保存
import csv
f = csv.writer(open('files/students1.csv', 'w', encoding='utf-8',newline=''))
# 一次写一行
f.writerow(['姓名', '年龄', '性别', '电话'])
# 一次写入多行数据
writer1.writerows([
['小花', 20, '女', '120'],
['张三', 30, '男', '119']
])
txt保存
f = open('a.txt', 'w', encoding='utf-8')
f.write('你好!')
f.close()