Hive笔记
1. Hive 基本概念
1.1 什么是 Hive
1) hive 简介
Hive:由 Facebook 开源用于解决海量结构化日志的数据统计工具。
Hive 是基于 Hadoop 的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并 提供类 SQL 查询功能。
2) Hive 本质
将 HQL 转化成 MapReduce 程序
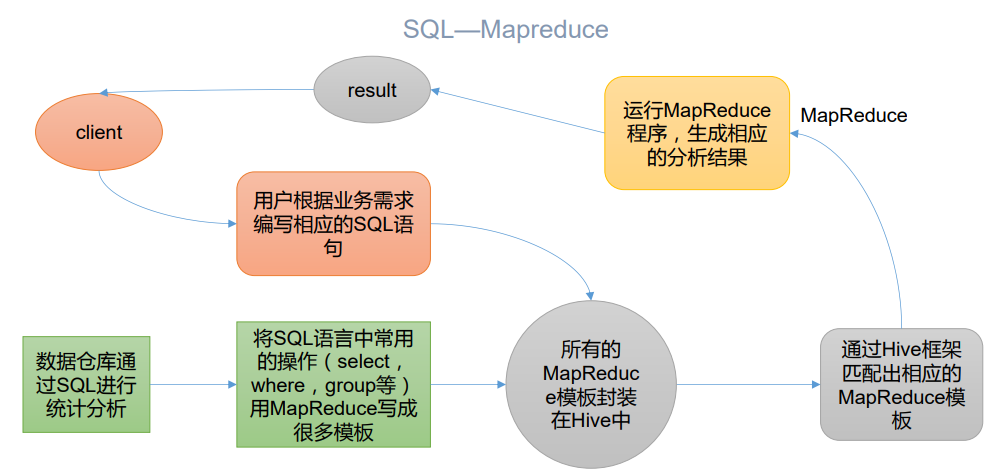
(1)Hive 处理的数据存储在 HDFS
(2)Hive 分析数据底层的实现是 MapReduce
(3)执行程序运行在 Yarn 上
1.2Hive 的优缺点
1.2.1 优点
(1)操作接口采用类 SQL 语法,提供快速开发的能力(简单、容易上手)。
(2)避免了去写 MapReduce,减少开发人员的学习成本。
(3)Hive 的执行延迟比较高,因此 Hive 常用于数据分析,对实时性要求不高的场合。
(4)Hive 优势在于处理大数据,对于处理小数据没有优势,因为 Hive 的执行延迟比较 高。
(5)Hive 支持用户自定义函数,用户可以根据自己的需求来实现自己的函数。
1.2.2 缺点
1)Hive 的 HQL 表达能力有限
(1)迭代式算法无法表达
(2)数据挖掘方面不擅长,由于 MapReduce 数据处理流程的限制,效率更高的算法却 无法实现。
2)Hive 的效率比较低
(1)Hive 自动生成的 MapReduce 作业,通常情况下不够智能化
(2)Hive 调优比较困难,粒度较粗
1.3 Hive 架构原理
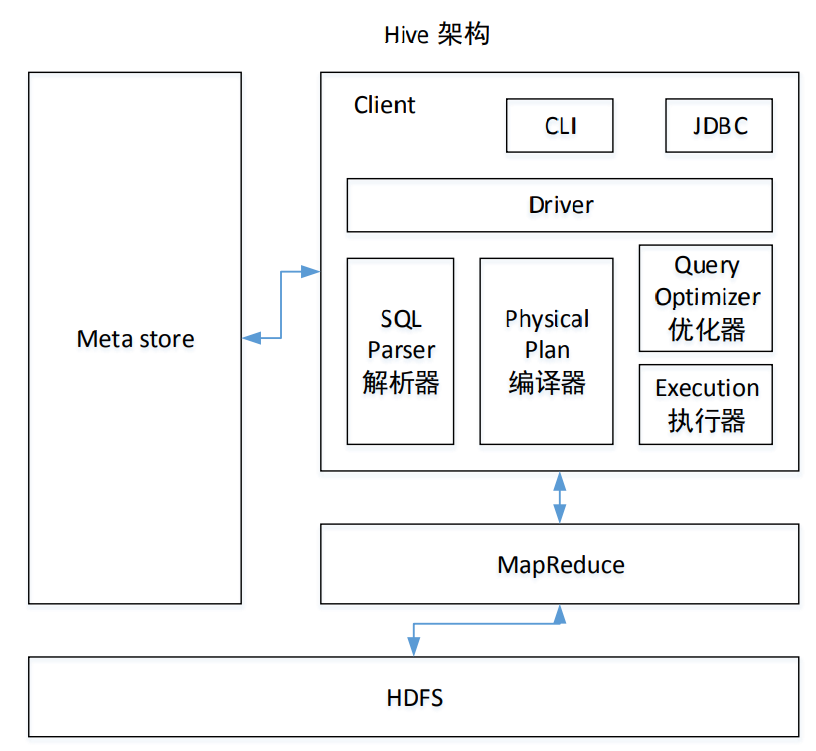
1)用户接口:Client
CLI(command-line interface)、JDBC/ODBC(jdbc 访问 hive)、WEBUI(浏览器访问 hive)
2)元数据:Metastore
元数据包括:表名、表所属的数据库(默认是 default)、表的拥有者、列/分区字段、 表的类型(是否是外部表)、表的数据所在目录等;
默认存储在自带的 derby 数据库中,推荐使用 MySQL 存储 Metastore
3)Hadoop
使用 HDFS 进行存储,使用 MapReduce 进行计算。
4)驱动器:Driver
(1)解析器(SQL Parser):将 SQL 字符串转换成抽象语法树 AST,这一步一般都用第 三方工具库完成,比如 antlr;对 AST 进行语法分析,比如表是否存在、字段是否存在、SQL 语义是否有误。
(2)编译器(Physical Plan):将 AST 编译生成逻辑执行计划。
(3)优化器(Query Optimizer):对逻辑执行计划进行优化。
(4)执行器(Execution):把逻辑执行计划转换成可以运行的物理计划。对于 Hive 来 说,就是 MR/Spark。
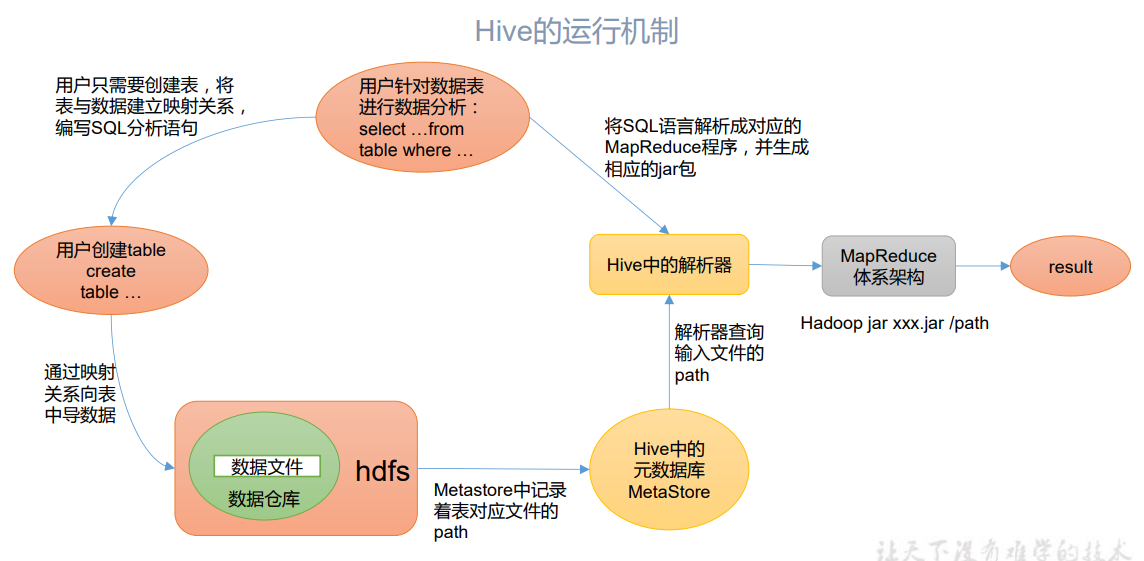
Hive 通过给用户提供的一系列交互接口,接收到用户的指令(SQL),使用自己的 Driver, 结合元数据(MetaStore),将这些指令翻译成 MapReduce,提交到 Hadoop 中执行,最后,将 执行返回的结果输出到用户交互接口。
1.4 Hive 和数据库比较
由于 Hive 采用了类似 SQL 的查询语言 HQL(Hive Query Language),因此很容易将 Hive 理 解为数据库。其实从结构上来看,Hive 和数据库除了拥有类似的查询语言,再无类似之处。 本文将从多个方面来阐述 Hive 和数据库的差异。数据库可以用在 Online 的应用中,但是 Hive 是为数据仓库而设计的,清楚这一点,有助于从应用角度理解 Hive 的特性。
1.4.1 查询语言
由于 SQL 被广泛的应用在数据仓库中,因此,专门针对 Hive 的特性设计了类 SQL 的查 询语言 HQL。熟悉 SQL 开发的开发者可以很方便的使用 Hive 进行开发。
1.4.2 数据更新
由于 Hive 是针对数据仓库应用设计的,而数据仓库的内容是读多写少的。因此,Hive 中 不建议对数据的改写,所有的数据都是在加载的时候确定好的。而数据库中的数据通常是需 要经常进行修改的,因此可以使用 INSERT INTO … VALUES 添加数据,使用 UPDATE … SET 修 改数据。
1.4.3 执行延迟
Hive 在查询数据的时候,由于没有索引,需要扫描整个表,因此延迟较高。另外一个导 致 Hive 执行延迟高的因素是 MapReduce 框架。由于 MapReduce 本身具有较高的延迟,因此 在利用 MapReduce 执行 Hive 查询时,也会有较高的延迟。相对的,数据库的执行延迟较低。 当然,这个低是有条件的,即数据规模较小,当数据规模大到超过数据库的处理能力的时候, Hive 的并行计算显然能体现出优势。
1.4.4 数据规模
由于 Hive 建立在集群上并可以利用 MapReduce 进行并行计算,因此可以支持很大规模 的数据;对应的,数据库可以支持的数据规模较小。
2. Hive 安装
2.1 Hive 安装地址
1)Hive 官网地址 http://hive.apache.org/
2)文档查看地址 https://cwiki.apache.org/confluence/display/Hive/GettingStarted
3)下载地址 http://archive.apache.org/dist/hive/
4)github 地址 https://github.com/apache/hive
2.2Hive 安装部署
2.2.1 安装 Hive
1)把 apache-hive-3.1.2-bin.tar.gz 上传到 linux 的/opt/software 目录下
2)解压 apache-hive-3.1.2-bin.tar.gz 到/opt/module/目录下面
[hhhyixin@hadoop102 software]$ tar -zxvf /opt/software/apache-hive-3.1.2-bin.tar.gz -C /opt/module/
3)修改 apache-hive-3.1.2-bin.tar.gz 的名称为 hive
[hhhyixin@hadoop102 module]$ mv apache-hive-3.1.2-bin/ hive
4)修改/etc/profile.d/my_env.sh,添加环境变量
[hhhyixin@hadoop102 software]$ sudo vim /etc/profile.d/my_env.sh
5)添加内容
#HIVE_HOME
export HIVE_HOME=/opt/module/hive
export PATH=$PATH:$HIVE_HOME/bin
别忘了source
[hhhyixin@hadoop102 hive]$ source /etc/profile.d/my_env.sh
6)解决日志 Jar 包冲突 (可弄可不弄)
[hhhyixin@hadoop102 software]$ mv $HIVE_HOME/lib/log4j-slf4j-impl2.10.0.jar $HIVE_HOME/lib/log4j-slf4j-impl-2.10.0.bak
7)初始化元数据库
[hhhyixin@hadoop102 hive]$ bin/schematool -dbType derby -initSchema
2.2.2 启动并使用 Hive
1)启动 Hive
[hhhyixin@hadoop102 hive]$ bin/hive
如果在启动中报错就进入到该系统的
[hhhyixin@hadoop103 ~]$cd /tmp/hhyixin/
在目录中打开hive.log日志文件来查看报错信息
2)使用 Hive
hive> show databases;
hive> show tables;
hive> create table test(id int);
hive> insert into test values(1);
hive> select * from test;
3)在 CRT 窗口中开启另一个窗口开启 Hive,在/tmp/atguigu 目录下监控 hive.log 文件
2.3MySQL 安装
1)检查当前系统是否安装过 MySQL
[hhhyixin@hadoop102 software]$ rpm -qa|grep mariadb mariadb-libs-5.5.68-1.el7.x86_64
//如果存在通过如下命令卸载
[hhhyixin@hadoop102 ~]$ sudo rpm -e --nodeps mariadb-libs
2)将 MySQL 安装包拷贝到/opt/software 目录下
3)解压 MySQL 安装包
[hhhyixin@hadoop102 software]# tar -xf mysql-5.7.28-1.el7.x86_64.rpm-bundle.tar

4)在安装目录下执行 rpm 安装
[hhhyixin@hadoop102 software]$
sudo rpm -ivh mysql-community-common-5.7.28-1.el7.x86_64.rpm
sudo rpm -ivh mysql-community-libs-5.7.28-1.el7.x86_64.rpm
sudo rpm -ivh mysql-community-libs-compat-5.7.28-1.el7.x86_64.rpm
sudo rpm -ivh mysql-community-client-5.7.28-1.el7.x86_64.rpm
sudo rpm -ivh mysql-community-server-5.7.28-1.el7.x86_64.rpm
如果出现依赖检测失败,则在每一行代码的后面加上 –force --nodeps
5)删除/etc/my.cnf 文件中 datadir 指向的目录下的所有内容,如果有内容的情况下:
查看 datadir 的值:
[mysqld]
datadir=/var/lib/mysql
删除/var/lib/mysql 目录下的所有内容:
[hhhyixin@hadoop102 mysql]# cd /var/lib/mysql
[hhhyixin@hadoop102 mysql]# sudo rm -rf ./* //注意执行命令的位置
6)初始化数据库
[hhhyixin@hadoop102 opt]$ sudo mysqld --initialize --user=mysql
7)查看临时生成的 root 用户的密码
[hhhyixin@hadoop102 opt]$ sudo cat /var/log/mysqld.log

8)启动 MySQL 服务
[hhhyixin@hadoop102 opt]$ sudo systemctl start mysqld
9)登录 MySQL 数据库
[hhhyixin@hadoop102 opt]$ mysql -uroot -p
Enter password: 输入临时生成的密码
10)必须先修改 root 用户的密码,否则执行其他的操作会报错
mysql> set password = password("新密码");
11)修改 mysql 库下的 user 表中的 root 用户允许任意 ip 连接
mysql> update mysql.user set host='%' where user='root';
mysql> flush privileges;
2.4 Hive 元数据配置到 MySQL
2.4.1 拷贝驱动
将 MySQL 的 JDBC 驱动拷贝到 Hive 的 lib 目录下
[hhhyixin@hadoop102 software]$ cp /opt/software/mysql-connector-java-5.1.37.jar $HIVE_HOME/lib
2.4.2 配置 Metastore 到 MySQL
1)在$HIVE_HOME/conf 目录下新建 hive-site.xml 文件
[hhhyixin@hadoop102 software]$ vim $HIVE_HOME/conf/hive-site.xml
添加如下内容
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- jdbc 连接的 URL -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop102:3306/metastore?useSSL=false</value>
</property>
<!-- jdbc 连接的 Driver-->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<!-- jdbc 连接的 username-->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<!-- jdbc 连接的 password -->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>000000</value>
</property>
<!-- Hive 元数据存储版本的验证 -->
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<!--元数据存储授权-->
<property>
<name>hive.metastore.event.db.notification.api.auth</name>
<value>false</value>
</property>
<!-- Hive 默认在 HDFS 的工作目录 -->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
</configuration>
2)登陆 MySQL
[hhhyixin@hadoop102 software]$ mysql -uroot -p000000
3)新建 Hive 元数据库
mysql> create database metastore;
mysql> quit;
4) 初始化 Hive 元数据库
[hhhyixin@hadoop102 software]$ schematool -initSchema -dbType mysql -verbose
当初始化时出现错误,应该删掉metastore库,再重新扩建一个,再初始化Hive元数据库。
2.4.3 再次启动 Hive
1)启动 Hive
[hhhyixin@hadoop102 hive]$ bin/hive
2)使用 Hive
hive> show databases;
hive> show tables;
hive> create table test (id int);
hive> insert into test values(1);
hive> select * from test;
3)在 CRT 窗口中开启另一个窗口开启 Hive
hive> show databases;
hive> show tables;
hive> select * from aa;
2.5 使用元数据服务的方式访问 Hive
1)在 hive-site.xml 文件中添加如下配置信息
<!-- 指定存储元数据要连接的地址 -->
<property>
<name>hive.metastore.uris</name>
<value>thrift://hadoop102:9083</value>
</property>
2)启动 metastore
[hhhyixin@hadoop102 hive]$ bin/hive --service metastore
2022-07-25 17:04:32: Starting Hive Metastore Server
注意: 启动后窗口不能再操作,需打开一个新的 shell 窗口做别的操作
启动之后ctrl+c关闭
3)启动 hive
[hhhyixin@hadoop102 hive]$ bin/hive
2.6 使用 JDBC 方式访问 Hive
1)在 hive-site.xml 文件中添加如下配置信息
<!-- 指定 hiveserver2 连接的 host -->
<property>
<name>hive.server2.thrift.bind.host</name>
<value>hadoop102</value>
</property>
<!-- 指定 hiveserver2 连接的端口号 -->
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property>
2)启动 hiveserver2
启动之前先打开元数据服务
[hhhyixin@hadoop102 hive]$ bin/hive --service hiveserver2
3)启动 beeline 客户端(需要多等待一会)
[hhhyixin@hadoop102 hive]$ bin/beeline -u jdbc:hive2://hadoop102:10000 -n hhhyixin
Error: Could not open client transport with JDBC Uri: jdbc:hive2://hadoop102:10000: Failed to open new session: java.lang.RuntimeException: org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.security.authorize.AuthorizationException): User: hhhyixin is not allowed to impersonate hhhyixin (state=08S01,code=0)
解决方法:
在 hadoop 文件 core-site.xml 中配置信息如下,重启Hadoop,再次启动 hiveserver2 和 beeline 即可
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
别忘了重新启动hadoop集群
4)看到如下界面
5)编写 hive 服务启动脚本(了解)
(1) 前台启动的方式导致需要打开多个 shell 窗口,可以使用如下方式后台方式启动
nohup: 放在命令开头,表示不挂起,也就是关闭终端进程也继续保持运行状态
/dev/null:是 Linux 文件系统中的一个文件,被称为黑洞,所有写入改文件的内容 都会被自动丢弃
2>&1 : 表示将错误重定向到标准输出上
&: 放在命令结尾,表示后台运行
一般会组合使用: nohup [xxx 命令操作]> file 2>&1 &,表示将 xxx 命令运行的结 果输出到 file 中,并保持命令启动的进程在后台运行。
如上命令不要求掌握。
[hhhyixin@hadoop202 hive]$ nohup hive --service metastore 2>&1 &
[hhhyixin@hadoop202 hive]$ nohup hive --service hiveserver2 2>&1 &
这两个命令可以把进程在后台运行,不需要新开窗口。(不太靠谱)
(2) 为了方便使用,可以直接编写脚本来管理服务的启动和关闭
[hhhyixin@hadoop102 bin]$ vim hiveservice.sh
#!/bin/bash
HIVE_LOG_DIR=$HIVE_HOME/logs
mkdir -p $HIVE_LOG_DIR
#检查进程是否运行正常,参数1为进程名,参数2为进程端口
function check_process()
{
pid=$(ps -ef 2>/dev/null | grep -v grep | grep -i $1 | awk '{print $2}')
ppid=$(netstat -nltp 2>/dev/null | grep $2 | awk '{print $7}' | cut -d '/' -f 1)
echo $pid
[[ "$pid" =~ "$ppid" ]] && [ "$ppid" ] && return 0 || return 1
}
function hive_start()
{
metapid=$(check_process HiveMetastore 9083)
cmd="nohup hive --service metastore >$HIVE_LOG_DIR/metastore.log 2>&1 &"
cmd=$cmd" sleep 4; hdfs dfsadmin -safemode wait >/dev/null 2>&1"
[ -z "$metapid" ] && eval $cmd || echo "Metastroe服务已启动"
server2pid=$(check_process HiveServer2 10000)
cmd="nohup hive --service hiveserver2 >$HIVE_LOG_DIR/hiveServer2.log 2>&1 &"
[ -z "$server2pid" ] && eval $cmd || echo "HiveServer2服务已启动"
}
function hive_stop()
{
metapid=$(check_process HiveMetastore 9083)
[ "$metapid" ] && kill $metapid || echo "Metastore服务未启动"
server2pid=$(check_process HiveServer2 10000)
[ "$server2pid" ] && kill $server2pid || echo "HiveServer2服务未启动"
}
case $1 in
"start")
hive_start
;;
"stop")
hive_stop
;;
"restart")
hive_stop
sleep 2
hive_start
;;
"status")
check_process HiveMetastore 9083 >/dev/null && echo "Metastore服务运行正常" || echo "Metastore服务运行异常"
check_process HiveServer2 10000 >/dev/null && echo "HiveServer2服务运行正常" || echo "HiveServer2服务运行异常"
;;
*)
echo Invalid Args!
echo 'Usage: '$(basename $0)' start|stop|restart|status'
;;
esac
3)添加执行权限
[hhhyixin@hadoop102 bin]$ chmod u+x hiveservice.sh
4)启动 Hive 后台服务
[hhhyixin@hadoop102 bin]$ hiveservice.sh start
查看是否启动成功
[hhhyixin@hadoop102 bin]$ hiveservice.sh status
全部启动成功之后,启动beeline 客户端测试一下
[hhhyixin@hadoop102 bin]$ beeline -u jdbc:hive2://hadoop102:10000 -n hhhyixin
成功之后退出:!quit
2.7 Hive 常用交互命令
[hhhyixin@hadoop102 hive]$ bin/hive -help
-d,--define <key=value> Variable substitution to apply to Hive
commands. e.g. -d A=B or --define A=B
--database <databasename> Specify the database to use
-e <quoted-query-string> SQL from command line
-f <filename> SQL from files
-H,--help Print help information
--hiveconf <property=value> Use value for given property
--hivevar <key=value> Variable substitution to apply to Hive
commands. e.g. --hivevar A=B
-i <filename> Initialization SQL file
-S,--silent Silent mode in interactive shell
-v,--verbose Verbose mode (echo executed SQL to the
console)
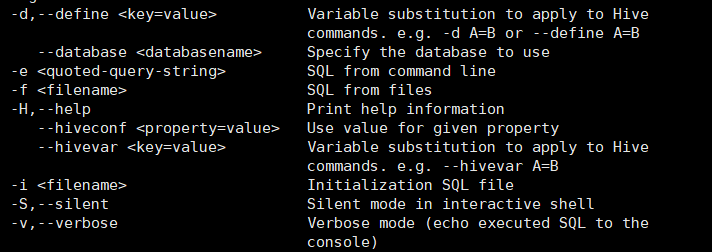
1)“-e”不进入 hive 的交互窗口执行 sql 语句
[hhhyixin@hadoop102 hive]$ bin/hive -e "select id from student;"
2)“-f”执行脚本中 sql 语句
(1)在/opt/module/hive/下创建 datas 目录并在 datas 目录下创建 hivef.sql 文件
[hhhyixin@hadoop102 datas]$ touch hivef.sql
(2)文件中写入正确的 sql 语句
select *from student;
(3)执行文件中的 sql 语句
[hhhyixin@hadoop102 hive]$ bin/hive -f /opt/module/hive/datas/hivef.sql
(4)执行文件中的 sql 语句并将结果写入文件中
[hhhyixin@hadoop102 hive]$ bin/hive -f /opt/module/hive/datas/hivef.sql >
/opt/module/datas/hive_result.txt
2.8 Hive 其他命令操作
1)退出 hive 窗口:
hive(default)>exit;
hive(default)>quit;
2)在 hive cli 命令窗口中如何查看 hdfs 文件系统
hive(default)>dfs -ls /;
3)查看在 hive 中输入的所有历史命令
(1)进入到当前用户的根目录 /root 或/home/hhhyixin
(2)查看. hivehistory 文件
[hhhyixin@hadoop102 ~]$ cat .hivehistory
2.9 Hive 常见属性配置
2.9.1 Hive 运行日志信息配置
1)Hive 的 log 默认存放在/tmp/hhhyixin/hive.log 目录下(当前用户名下)
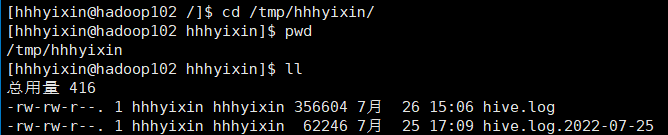
2)修改 hive 的 log 存放日志到/opt/module/hive/logs
(1)修改/opt/module/hive/conf/hive-log4j2.properties.template 文件名称为 hive-log4j2.properties
[hhhyixin@hadoop102 conf]$ mv hive-log4j2.properties.template hive-log4j2.properties
(2)在 hive-log4j2.properties 文件中修改 log 存放位置
hive.log.dir=/opt/module/hive/logs
2.9.2 打印 当前库 和 表头
在 hive-site.xml 中加入如下两个配置:
<!--打印当前库和表头-->
<property>
<name>hive.cli.print.header</name>
<value>true</value>
</property>
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
</property>
2.9.3 参数配置方式
1)查看当前所有的配置信息
hive>set;
2)参数的配置三种方式
(1)配置文件方式
默认配置文件:hive-default.xml
用户自定义配置文件:hive-site.xml
注意:用户自定义配置会覆盖默认配置。另外,Hive 也会读入 Hadoop 的配置,因为 Hive 是作为 Hadoop 的客户端启动的,Hive 的配置会覆盖 Hadoop 的配置。配置文件的设定对本 机启动的所有 Hive 进程都有效。
(2)命令行参数方式
启动 Hive 时,可以在命令行添加-hiveconf param=value 来设定参数。
例如:
[hhhyixin@hadoop103 hive]$ bin/hive -hiveconf mapred.reduce.tasks=10;
注意:仅对本次 hive 启动有效
查看参数设置:
hive (default)> set mapred.reduce.tasks;
(3)参数声明方式
可以在 HQL 中使用 SET 关键字设定参数
例如:
hive (default)> set mapred.reduce.tasks=100;
注意:仅对本次 hive 启动有效。
查看参数设置
hive (default)> set mapred.reduce.tasks;
上述三种设定方式的优先级依次递增。即配置文件<命令行参数<参数声明。注意某些系 统级的参数,例如 log4j 相关的设定,必须用前两种方式设定,因为那些参数的读取在会话 建立以前已经完成了。
3. Hive 数据类型
3.1 基本数据类型
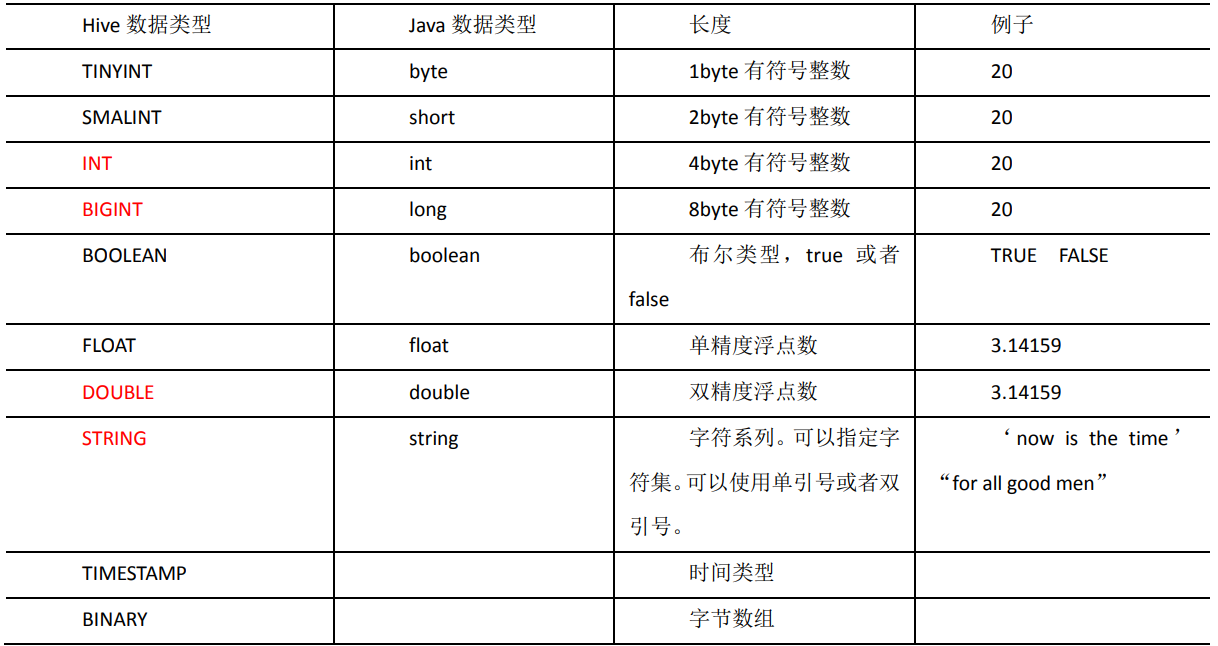
对于 Hive 的 String 类型相当于数据库的 varchar 类型,该类型是一个可变的字符串,不 过它不能声明其中最多能存储多少个字符,理论上它可以存储 2GB 的字符数。
3.2 集合数据类型
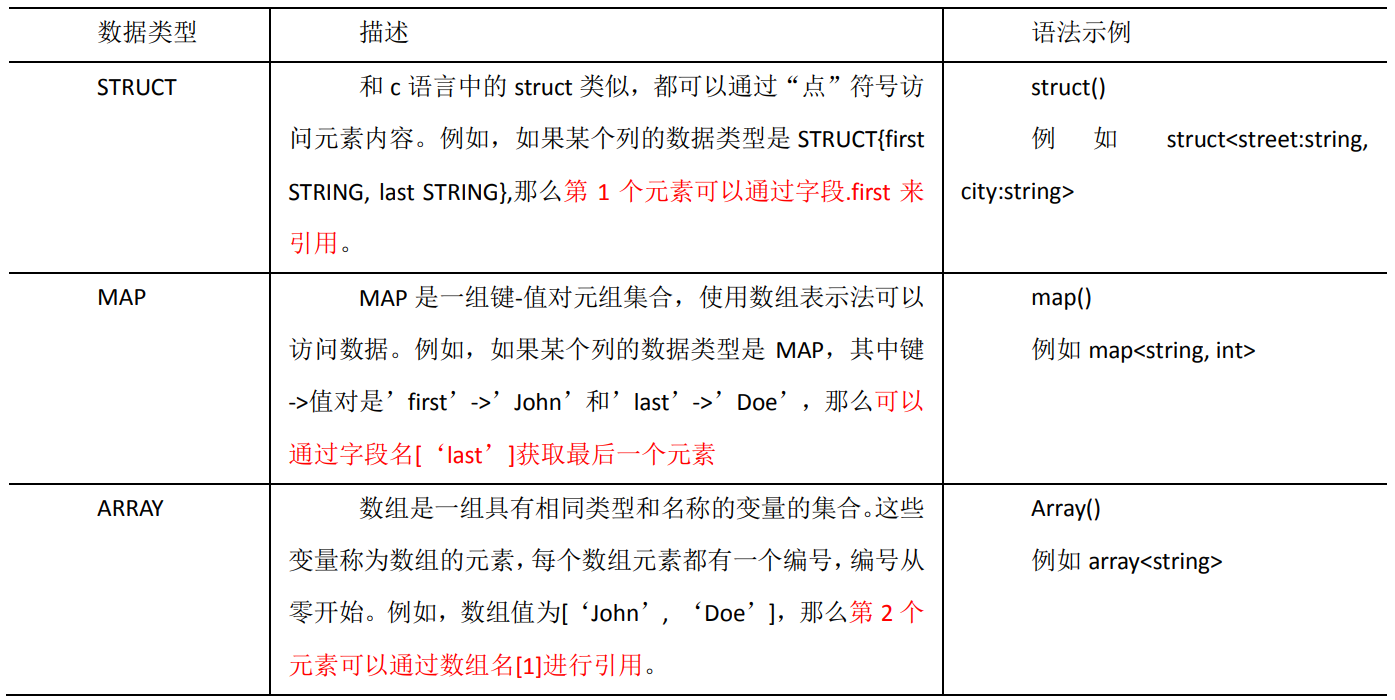
Hive 有三种复杂数据类型 ARRAY、MAP 和 STRUCT。ARRAY 和 MAP 与 Java 中的 Array 和 Map 类似,而 STRUCT 与 C 语言中的 Struct 类似,它封装了一个命名字段集合,复杂数据 类型允许任意层次的嵌套。
1)案例实操
(1)假设某表有如下一行,我们用 JSON 格式来表示其数据结构。在 Hive 下访问的格式为
{
"name": "songsong",
"friends": ["bingbing" , "lili"] , //列表 Array,
"children": { //键值 Map,
"xiao song": 18 ,
"xiaoxiao song": 19
}
"address": { //结构 Struct,
"street": "hui long guan",
"city": "beijing"
}
}
(2)基于上述数据结构,我们在 Hive 里创建对应的表,并导入数据。
创建本地测试文件 test.txt
songsong,bingbing_lili,xiao song:18_xiaoxiao song:19,hui long
guan_beijing
yangyang,caicai_susu,xiao yang:18_xiaoxiao yang:19,chao yang_beijing
注意:MAP,STRUCT 和 ARRAY 里的元素间关系都可以用同一个字符表示,这里用“_”。
(3)Hive 上创建测试表 test
create table test(
name string,
friends array<string>,
children map<string, int>,
address struct<street:string, city:string>
)
row format delimited fields terminated by ','
collection items terminated by '_'
map keys terminated by ':'
lines terminated by '\n';
| 字段 | 解释 |
|---|---|
| row format delimited fields terminated by ‘,’ | 列分隔符 |
| collection items terminated by ‘_’ | MAP STRUCT 和 ARRAY 的分隔符(数据分割符号) |
| map keys terminated by ‘:’ | MAP 中的 key 与 value 的分隔符 |
| ines terminated by ‘\n’; | 行分隔符 |
(4)导入文本数据到测试表
load data local inpath '/opt/module/hive/datas/test.txt' into table test;
(5)访问三种集合列里的数据,以下分别是 ARRAY,MAP,STRUCT 的访问方式
hive (default)> select friends[1],children['xiao song'],address.city from
test
where name="songsong";
OK
_c0 _c1 city
lili 18 beijing
Time taken: 0.076 seconds, Fetched: 1 row(s)
3.3 类型转化
Hive 的原子数据类型是可以进行隐式转换的,类似于 Java 的类型转换,例如某表达式 使用 INT 类型,TINYINT 会自动转换为 INT 类型,但是 Hive 不会进行反向转化,例如,某表 达式使用 TINYINT 类型,INT 不会自动转换为 TINYINT 类型,它会返回错误,除非使用 CAST 操作。
1)隐式类型转换规则如下
(1)任何整数类型都可以隐式地转换为一个范围更广的类型,如 TINYINT 可以转换成 INT,INT 可以转换成 BIGINT。
(2)所有整数类型、FLOAT 和 STRING 类型都可以隐式地转换成 DOUBLE。
(3)TINYINT、SMALLINT、INT 都可以转换为 FLOAT。
(4)BOOLEAN 类型不可以转换为任何其它的类型。
2)可以使用 CAST 操作显示进行数据类型转换
例如 CAST(‘1’ AS INT)将把字符串’1’ 转换成整数 1;如果强制类型转换失败,如执行 CAST(‘X’ AS INT),表达式返回空值 NULL。
0: jdbc:hive2://hadoop102:10000> select '1'+2, cast('1'as int) + 2;
+------+------+--+
| _c0 | _c1 |
+------+------+--+
| 3.0 | 3 |
+------+------+--+
4. DDL 数据定义
4.1 创建数据库
CREATE DATABASE [IF NOT EXISTS] database_name
[COMMENT database_comment]
[LOCATION hdfs_path]
[WITH DBPROPERTIES (property_name=property_value, ...)];
1)创建一个数据库,数据库在 HDFS 上的默认存储路径是/user/hive/warehouse/*.db。
hive (default)> create database db_hive;
2)避免要创建的数据库已经存在错误,增加 if not exists 判断。(标准写法)
hive (default)> create database db_hive;
FAILED: Execution Error, return code 1 from
org.apache.hadoop.hive.ql.exec.DDLTask. Database db_hive already exists
hive (default)> create database if not exists db_hive;
3)创建一个数据库,指定数据库在 HDFS 上存放的位置
hive (default)> create database db_hive2 location '/db_hive2.db';
4.2 查询数据库
4.2.1 显示数据库
1)显示数据库
hive> show databases;
2)过滤显示查询的数据库
hive> show databases like 'db_hive*';
4.2.2 查看数据库详情
1)显示数据库信息
hive> desc database db_hive;
2)显示数据库详细信息,extended
hive> desc database extended db_hive;
4.2.3 切换当前数据库
hive (default)> use hive;
4.3 修改数据库
用户可以使用 ALTER DATABASE 命令为某个数据库的 DBPROPERTIES 设置键-值对属性值, 来描述这个数据库的属性信息。
hive (default)> alter database db_hive
set dbproperties('createtime'='20170830');
在 hive 中查看修改结果
hive> desc database extended db_hive;
4.4 删除数据库
1)删除空数据库
hive>drop database db_hive2;
2)如果删除的数据库不存在,最好采用 if exists 判断数据库是否存在
hive> drop database db_hive;
3)如果数据库不为空,可以采用 cascade 命令,强制删除
hive> drop database db_hive;
4.5 创建表
1)建表语法
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name
[(col_name data_type [COMMENT col_comment], ...)]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...)
[SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[ROW FORMAT row_format]
[STORED AS file_format]
[LOCATION hdfs_path]
[TBLPROPERTIES (property_name=property_value, ...)]
[AS select_statement]
2)字段解释说明
(1)CREATE TABLE 创建一个指定名字的表。如果相同名字的表已经存在,则抛出异常; 用户可以用 IF NOT EXISTS 选项来忽略这个异常。
(2)EXTERNAL 关键字可以让用户创建一个外部表,在建表的同时可以指定一个指向实 际数据的路径(LOCATION),在删除表的时候,内部表的元数据和数据会被一起删除,而外 部表只删除元数据,不删除数据。
(3)COMMENT:为表和列添加注释。
(4)PARTITIONED BY 创建分区表
(5)CLUSTERED BY 创建分桶表
(6)SORTED BY 不常用,对桶中的一个或多个列另外排序
(7)ROW FORMAT
DELIMITED [FIELDS TERMINATED BY char] [COLLECTION ITEMS TERMINATED BY char]
[MAP KEYS TERMINATED BY char] [LINES TERMINATED BY char]
| SERDE serde_name [WITH SERDEPROPERTIES (property_name=property_value,
property_name=property_value, ...)]
用户在建表的时候可以自定义 SerDe 或者使用自带的 SerDe。如果没有指定 ROW FORMAT 或者 ROW FORMAT DELIMITED,将会使用自带的 SerDe。在建表的时候,用户还需 要为表指定列,用户在指定表的列的同时也会指定自定义的 SerDe,Hive 通过 SerDe 确定表 的具体的列的数据。
SerDe 是 Serialize/Deserilize 的简称, hive 使用 Serde 进行行对象的序列与反序列化。
(8)STORED AS 指定存储文件类型
常用的存储文件类型:SEQUENCEFILE(二进制序列文件)、TEXTFILE(文本)、RCFILE(列 式存储格式文件)
如果文件数据是纯文本,可以使用STORED AS TEXTFILE。如果数据需要压缩,使用 STORED AS SEQUENCEFILE。
(9)LOCATION :指定表在 HDFS 上的存储位置。
(10)AS:后跟查询语句,根据查询结果创建表。
(11)LIKE 允许用户复制现有的表结构,但是不复制数据。
4.5.1 管理表
1)理论
默认创建的表都是所谓的管理表,有时也被称为内部表。因为这种表,Hive 会(或多或 少地)控制着数据的生命周期。Hive 默认情况下会将这些表的数据存储在由配置项 hive.metastore.warehouse.dir(例如,/user/hive/warehouse)所定义的目录的子目录下。
**当我们删除一个管理表时,Hive 也会删除这个表中数据。**管理表不适合和其他工具共享 数据。
4.5.2 外部表
1)理论
因为表是外部表,所以 Hive 并非认为其完全拥有这份数据。删除该表并不会删除掉这 份数据,不过描述表的元数据信息会被删除掉。
2)管理表和外部表的使用场景
每天将收集到的网站日志定期流入 HDFS 文本文件。在外部表(原始日志表)的基础上 做大量的统计分析,用到的中间表、结果表使用内部表存储,数据通过 SELECT+INSERT 进入内部表。
4.5.3 管理表与外部表的互相转换
(1)查询表的类型
hive (default)> desc formatted student2;
(2)修改内部表 student2 为外部表
alter table student2 set tblproperties('EXTERNAL'='TRUE');
(3)查询表的类型
hive (default)> desc formatted student2;
(4)修改外部表 student2 为内部表
alter table student2 set tblproperties('EXTERNAL'='FALSE');
(5)查询表的类型
hive (default)> desc formatted student2;
注意:(‘EXTERNAL’=‘TRUE’)和(‘EXTERNAL’=‘FALSE’)为固定写法,区分大小写!
4.6 修改表
4.6.1 重命名表
1)语法
ALTER TABLE table_name RENAME TO new_table_name
4.6.2 增加/修改/替换列信息
1)语法
(1)更新列
ALTER TABLE table_name CHANGE [COLUMN] col_old_name col_new_name
column_type [COMMENT col_comment] [FIRST|AFTER column_name]
(2)增加和替换列
ALTER TABLE table_name ADD|REPLACE COLUMNS (col_name data_type [COMMENT
col_comment], ...)
注:ADD 是代表新增一字段,字段位置在所有列后面(partition 列前),
REPLACE 则是表示替换表中所有字段。
4.7 删除表
hive (default)> drop table dept;
5. DML 数据操作
5.1 数据导入
5.1.1 向表中装载数据(Load)
1)语法
hive> load data [local] inpath '数据的 path' [overwrite] into table student [partition (partcol1=val1,…)];
(1)load data:表示加载数据
(2)local:表示从本地加载数据到 hive 表;否则从 HDFS 加载数据到 hive 表
(3)inpath:表示加载数据的路径
(4)overwrite:表示覆盖表中已有数据,否则表示追加
(5)into table:表示加载到哪张表
(6)student:表示具体的表
(7)partition:表示上传到指定分区
5.1.2 通过查询语句向表中插入数据(Insert)
基本模式插入(根据单张表查询结果)
hive (default)> insert overwrite table 表名
select 索引 from student where month='xxx';
insert into:以追加数据的方式插入到表或分区,原有数据不会删除
insert overwrite:会覆盖表中已存在的数据
注意:insert 不支持插入部分字段
多表(多分区)插入模式(根据多张表查询结果)
hive (default)> from student
insert overwrite table student partition(month='201707')
select id, name where month='201709'
insert overwrite table student partition(month='201706')
select id, name where month='201709';
从多个表中查找进行多行插入
5.1.3 查询语句中创建表并加载数据(As Select)
根据查询结果创建表(查询的结果会添加到新创建的表中)
create table if not exists student3
as select id, name from student;
将从student表查询出来的id, name创建一个新的student3表
5.1.4 创建表时通过 Location 指定加载数据路径
创建表,并指定在 hdfs 上的位置
hive (default)> create external table if not exists student5(
id int, name string
)
row format delimited fields terminated by '\t'
location '/student;
扩建一个student5表,将student中的id、name属性加载。
5.1.5 Import 数据到指定 Hive 表中
注意:先用 export 导出后,再将数据导入。
hive (default)> import table student2
from '/user/hive/warehouse/export/student';
将student中表的数据导入到student2表中。
5.2 数据导出
5.2.1 Insert 导出
1)将查询的结果导出到本地
hive (default)> insert overwrite local directory
'/opt/module/hive/data/export/student'
select * from student;
将student表中的数据导出到本地。
2)将查询的结果格式化导出到本地
hive(default)>insert overwrite local directory
'/opt/module/hive/data/export/student1'
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
select * from student;
3)将查询的结果导出到 HDFS 上(没有 local)
hive (default)> insert overwrite directory '/user/atguigu/student2'
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
select * from student;
5.2.2 Hadoop 命令导出到本地
hive (default)> dfs -get /user/hive/warehouse/student/student.txt /opt/module/data/export/student3.txt;
5.2.3 Hive Shell 命令导出
基本语法:(hive -f/-e 执行语句或者脚本 > file)
[hhhyixin@hadoop102 hive]$ bin/hive -e 'select * from default.student;' >
/opt/module/hive/data/export/student4.txt;
5.2.4 Export 导出到 HDFS 上
(defahiveult)> export table default.student to '/user/hive/warehouse/export/student';
export 和 import 主要用于两个 Hadoop 平台集群之间 Hive 表迁移。
5.2.5 清除表中数据(Truncate)
注意:Truncate 只能删除管理表,不能删除外部表中数据
hive (default)> truncate table student;
6. 查询
查询语句语法:
SELECT [ALL | DISTINCT] select_expr, select_expr, ...
FROM table_reference
[WHERE where_condition]
[GROUP BY col_list]
[ORDER BY col_list]
[CLUSTER BY col_list
| [DISTRIBUTE BY col_list] [SORT BY col_list]
]
[LIMIT number]
6.1 基本查询(Select…From)
6.1.1 全表和特定列查询
0)数据准备
(0)原始数据
dept:
10 ACCOUNTING 1700
20 RESEARCH 1800
30 SALES 1900
40 OPERATIONS 1700
emp:
7369 SMITH CLERK 7902 1980-12-17 800.00 20
7499 ALLEN SALESMAN 7698 1981-2-20 1600.00 300.00 30
7521 WARD SALESMAN 7698 1981-2-22 1250.00 500.00 30
7566 JONES MANAGER 7839 1981-4-2 2975.00 20
7654 MARTIN SALESMAN 7698 1981-9-28 1250.00 1400.00 30
7698 BLAKE MANAGER 7839 1981-5-1 2850.00 30
7782 CLARK MANAGER 7839 1981-6-9 2450.00 10
7788 SCOTT ANALYST 7566 1987-4-19 3000.00 20
7839 KING PRESIDENT 1981-11-17 5000.00 10
7844 TURNER SALESMAN 7698 1981-9-8 1500.00 0.00 30
7876 ADAMS CLERK 7788 1987-5-23 1100.00 20
7900 JAMES CLERK 7698 1981-12-3 950.00 30
7902 FORD ANALYST 7566 1981-12-3 3000.00 20
7934 MILLER CLERK 7782 1982-1-23 1300.00 10
(1)创建部门表
create table if not exists dept(
deptno int,
dname string,
loc int
)
row format delimited fields terminated by '\t';
(2)创建员工表
create table if not exists emp(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal double,
comm double,
deptno int)
row format delimited fields terminated by '\t';
(3)导入数据
load data local inpath '/opt/module/datas/dept.txt' into table dept;
load data local inpath '/opt/module/datas/emp.txt' into table emp;
1)全表查询
hive (default)> select * from emp;
hive (default)> select empno,ename,job,mgr,hiredate,sal,comm,deptno from emp ;
2)选择特定列查询
hive (default)> select empno, ename from emp;
注意:
(1)SQL 语言大小写不敏感。
(2)SQL 可以写在一行或者多行
(3)关键字不能被缩写也不能分行
(4)各子句一般要分行写。
(5)使用缩进提高语句的可读性。
6.1.2 列别名
查询名称和部门
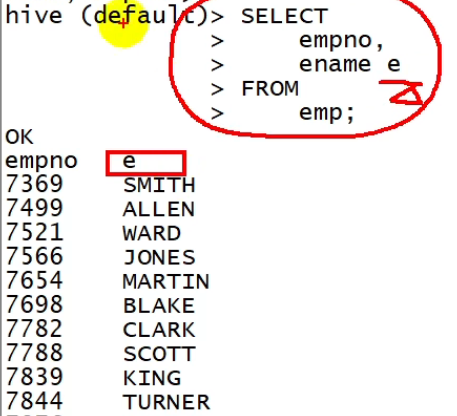
hive (default)> select
>empno,
>ename AS e
>from emp;
6.1.7 比较运算符(Between/In/ Is Null)
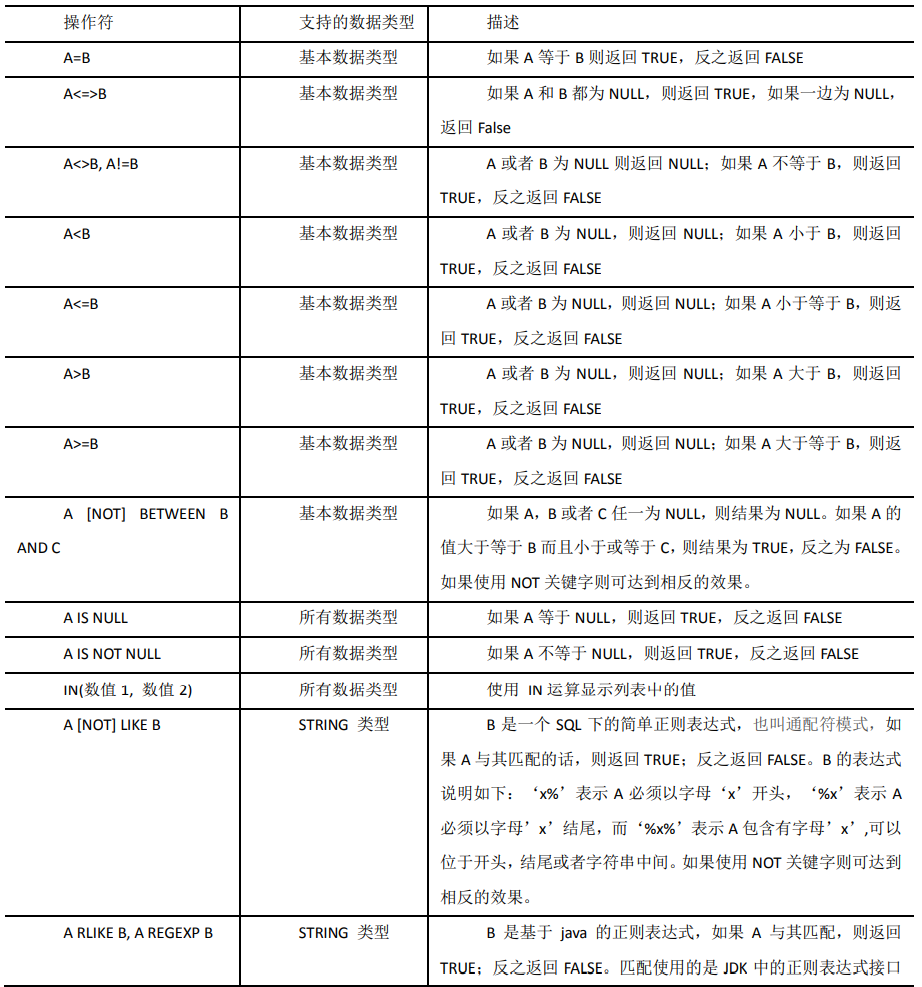
1)下面表中描述了谓词操作符,这些操作符同样可以用于 JOIN…ON 和 HAVING 语句中。

6.1.8 Like 和 RLike
1)使用 LIKE 运算选择类似的值
2)选择条件可以包含字符或数字:
% 代表零个或多个字符(任意个字符)。
_ 代表一个字符。
3)RLIKE 子句
RLIKE 子句是 Hive 中这个功能的一个扩展,其可以通过 Java 的正则表达式这个更强大 的语言来指定匹配条件。
4)案例实操
(1)查找名字以 A 开头的员工信息
hive (default)> select * from emp where ename LIKE 'A%';
(2)查找名字中第二个字母为 A 的员工信息
hive (default)> select * from emp where ename LIKE '_A%';
(3)查找名字中带有 A 的员工信息
hive (default)> select * from emp where ename RLIKE '[A]';
6.1.9 逻辑运算符(And/Or/Not)

1)案例实操
(1)查询薪水大于 1000,部门是 30
hive (default)> select * from emp where sal>1000 and deptno=30;
(2)查询薪水大于 1000,或者部门是 30
hive (default)> select * from emp where sal>1000 or deptno=30;
(3)查询除了 20 部门和 30 部门以外的员工信息
hive (default)> select * from emp where deptno not IN(30, 20);
6.2 分组
6.2.1 Group By 语句
GROUP BY 语句通常会和聚合函数一起使用,按照一个或者多个列队结果进行分组,然 后对每个组执行聚合操作。
1)案例实操:
(1)计算 emp 表每个部门的平均工资
hive (default)> select t.deptno, avg(t.sal) avg_sal from emp t group by t.deptno;
(2)计算 emp 每个部门中每个岗位的最高薪水
hive (default)> select t.deptno, t.job, max(t.sal) max_sal from emp t group by t.deptno, t.job;
6.2.2 Having 语句
1)having 与 where 不同点
(1)where 后面不能写分组函数,而 having 后面可以使用分组函数。
(2)having 只用于 group by 分组统计语句。
2)案例实操
(1)求每个部门的平均薪水大于 2000 的部门
求每个部门的平均工资
hive (default)> select deptno, avg(sal) from emp group by deptno;
求每个部门的平均薪水大于 2000 的部门
hive (default)> select deptno, avg(sal) avg_sal from emp group by deptno having avg_sal > 2000;
6.3 Join 语句
6.3.1 等值 Join
Hive 支持通常的 SQL JOIN 语句。
1)案例实操
(1)根据员工表和部门表中的部门编号相等,查询员工编号、员工名称和部门名称;
hive (default)> select e.empno, e.ename, d.deptno, d.dname
from emp e
join dept d on e.deptno = d.deptno;
6.3.2 表的别名
合并员工表和部门表
hive (default)> select e.empno, e.ename, d.deptno
from emp e
join dept d on e.deptno = d.deptno;
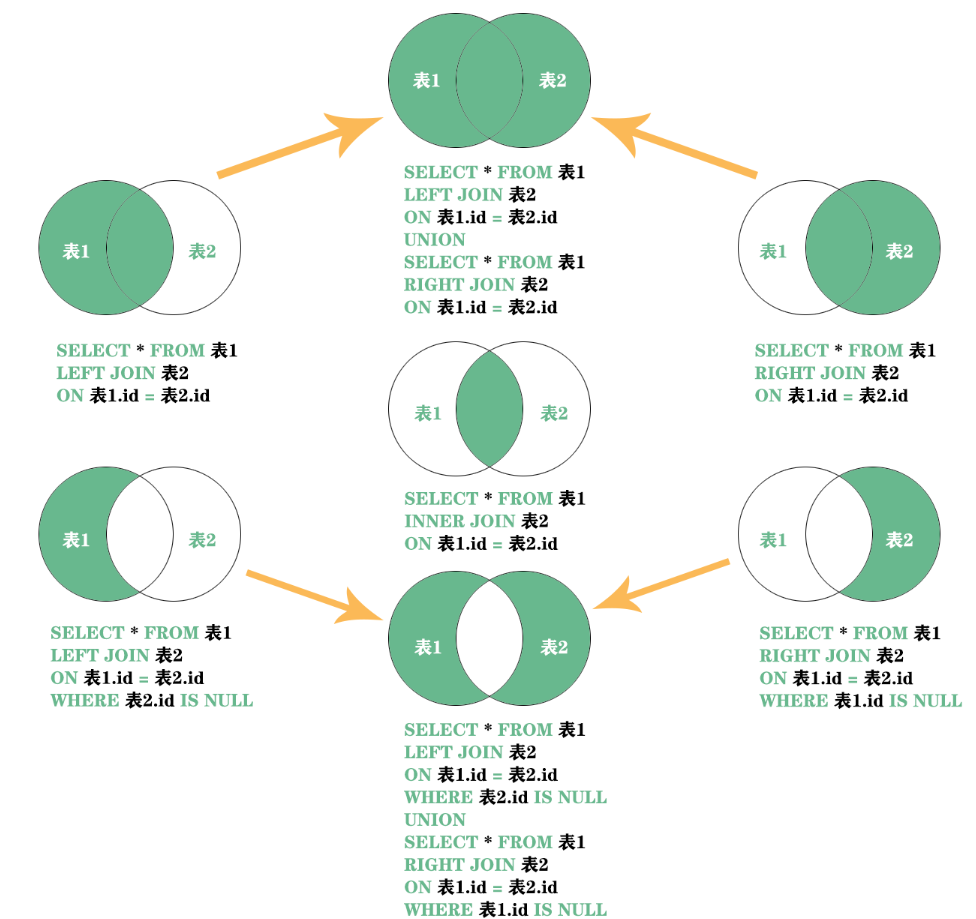
6.3.2.5join的七种结果
6.3.3 内连接
内连接:只有进行连接的两个表中都存在与连接条件相匹配的数据才会被保留下来。
hive (default)> select e.empno, e.ename, d.deptno
from emp e
join dept d on e.deptno = d.deptno;
6.3.4 左外连接
左外连接:JOIN 操作符左边表中符合 WHERE 子句的所有记录将会被返回。
hive (default)> select e.empno, e.ename, d.deptno
from emp e left
join dept d on e.deptno = d.deptno;
6.3.5 右外连接
右外连接:JOIN 操作符右边表中符合 WHERE 子句的所有记录将会被返回。
hive (default)> select e.empno, e.ename, d.deptno
from emp e right
join dept d on e.deptno = d.deptno;
6.3.6 满外连接
满外连接:将会返回所有表中符合 WHERE 语句条件的所有记录。如果任一表的指定字 段没有符合条件的值的话,那么就使用 NULL 值替代。
hive (default)> select e.empno, e.ename, d.deptno
from emp e full
join dept d on e.deptno = d.deptno;
6.3.7 多表连接
注意:连接 n 个表,至少需要 n-1 个连接条件。例如:连接三个表,至少需要两个连接 条件。
数据准备
1700 Beijing
1800 London
1900 Tokyo
1)创建位置表
create table if not exists location(
loc int,
loc_name string
)
row format delimited fields terminated by '\t';
2)导入数据
hive (default)> load data local inpath '/opt/module/datas/location.txt'
into table location;
3)多表连接查询
hive (default)>SELECT e.ename, d.dname, l.loc_name
FROM emp e
JOIN dept d ON d.deptno = e.deptno
JOIN location l ON d.loc = l.loc;
大多数情况下,Hive 会对每对 JOIN 连接对象启动一个 MapReduce 任务。本例中会首先 启动一个 MapReduce job 对表 e 和表 d 进行连接操作,然后会再启动一个 MapReduce job 将 第一个 MapReduce job 的输出和表 l;进行连接操作。
注意:为什么不是表 d 和表 l 先进行连接操作呢?这是因为 Hive 总是按照从左到右的 顺序执行的。
优化:当对 3 个或者更多表进行 join 连接时,如果每个 on 子句都使用相同的连接键的 话,那么只会产生一个 MapReduce job。
6.3.8 笛卡尔积
1)笛卡尔集会在下面条件下产生
(1)省略连接条件
(2)连接条件无效
(3)所有表中的所有行互相连接
2)案例实操
hive (default)> select empno, dname from emp, dept;
6.4 排序
6.4.1 全局排序(Order By)
Order By:全局排序,只有一个 Reducer
1)使用 ORDER BY 子句排序
ASC(ascend): 升序(默认)
DESC(descend): 降序
2)ORDER BY 子句在 SELECT 语句的结尾
3)案例实操
(1)查询员工信息按工资升序排列
hive (default)> select * from emp order by sal;
(2)查询员工信息按工资降序排列
hive (default)> select * from emp order by sal desc;
6.4.2 按照别名排序
按照员工薪水的 2 倍排序
hive (default)> select ename, sal*2 twosal from emp order by twosal;
6.4.3 多个列排序
按照部门和工资升序排序
hive (default)> select ename, deptno, sal from emp order by deptno, sal;
6.4.4 每个 Reduce 内部排序(Sort By)
**Sort By**:对于大规模的数据集 order by 的效率非常低。在很多情况下,并不需要全局排序,此时可以使用 sort by。
Sort by 为每个 reducer 产生一个排序文件。每个 Reducer 内部进行排序,对全局结果集 来说不是排序。
1)设置 reduce 个数
hive (default)> set mapreduce.job.reduces=3;
2)查看设置 reduce 个数
hive (default)> set mapreduce.job.reduces;
3)根据部门编号降序查看员工信息
hive (default)> select * from emp sort by deptno desc;
4)将查询结果导入到文件中(按照部门编号降序排序)
hive (default)> insert overwrite local directory
'/opt/module/data/sortby-result'
select * from emp sort by deptno desc;
6.4.5 分区(Distribute By)
Distribute By: 在有些情况下,我们需要控制某个特定行应该到哪个 reducer,通常是为 了进行后续的聚集操作。distribute by 子句可以做这件事。distribute by 类似 MR 中 partition (自定义分区),进行分区,结合 sort by 使用。
对于 distribute by 进行测试,一定要分配多 reduce 进行处理,否则无法看到 distribute by 的效果。
1)案例实操:
(1)先按照部门编号分区,再按照员工编号降序排序。
hive (default)> set mapreduce.job.reduces=3;
hive (default)> insert overwrite local directory
'/opt/module/data/distribute-result'
select * from emp distribute by deptno sort by empno desc;
distribute by 的分区规则是根据分区字段的 hash 码与 reduce 的个数进行模除后, 余数相同的分到一个区。
Hive 要求 DISTRIBUTE BY 语句要写在 SORT BY 语句之前。
6.4.6 Cluster By
当 distribute by 和 sorts by 字段相同时,可以使用 cluster by 方式。
cluster by 除了具有 distribute by 的功能外还兼具 sort by 的功能。但是排序只能是升序 排序,不能指定排序规则为 ASC 或者 DESC。
(1)以下两种写法等价
hive (default)> select * from emp cluster by deptno;
hive (default)> select * from emp distribute by deptno sort by deptno;
**注意**:按照部门编号分区,不一定就是固定死的数值,可以是 20 号和 30 号部门分到一 个分区里面去。
7. 分区表和分桶表
7.1 分区表
分区表实际上就是对应一个 HDFS 文件系统上的**独立的文件夹**,该文件夹下是该分区所有的数据文件。**Hive 中的分区就是分目录**,把一个大的数据集根据业务需要分割成小的数据 集。在查询时通过 WHERE 子句中的表达式选择查询所需要的指定的分区,这样的查询效率 会提高很多。
7.1.1 分区表基本操作
创建分区表语法
hive (default)> create table dept_partition(
deptno int, dname string, loc string
)
partitioned by (day string)
row format delimited fields terminated by '\t';
查询分区表中数据
单分区查询
hive (default)> select * from dept_partition where day='20200401';
多分区联合查询
hive (default)> select * from dept_partition where day='20200401'
union
select * from dept_partition where day='20200402'
union
select * from dept_partition where day='20200403';
hive (default)> select * from dept_partition
where day='20200401' orday='20200402' or day='20200403';
增加分区
创建单个分区
hive (default)> alter table dept_partition add partition(day='20200404');
同时创建多个分区
hive (default)> alter table dept_partition
add partition(day='20200405') partition(day='20200406');
删除分区
删除单个分区
hive (default)> alter table dept_partition drop partition (day='20200406');
同时删除多个分区
hive (default)> alter table dept_partition
drop partition (day='20200404'), partition(day='20200405');
查看分区表有多少分区
hive> show partitions dept_partition;
查看分区表结构
hive> desc formatted dept_partition;
7.1.2 二级分区
1)创建二级分区表
hive (default)> create table dept_partition2(
deptno int, dname string, loc string
)
partitioned by (day string, hour string)
row format delimited fields terminated by '\t';
2)正常的加载数据
(1)加载数据到二级分区表中
hive (default)> load data local inpath '/opt/module/hive/datas/dept_20200401.log'
into table dept_partition2 partition(day='20200401', hour='12');
(2)查询分区数据
hive (default)> select * from dept_partition2 where day='20200401' and hour='12';
3)把数据直接上传到分区目录上,让分区表和数据产生关联的三种方式
(1)方式一:上传数据后修复
上传数据
hive (default)> dfs -mkdir -p
/user/hive/warehouse/mydb.db/dept_partition2/day=20200401/hour=13;
hive (default)> dfs -put /opt/module/datas/dept_20200401.log
/user/hive/warehouse/mydb.db/dept_partition2/day=20200401/hour=13;
查询数据(查询不到刚上传的数据)
hive (default)> select * from dept_partition2 where day='20200401' and hour='13';
执行修复命令
hive> msck repair table dept_partition2;
再次查询数据
hive (default)> select * from dept_partition2 where day='20200401' and hour='13';
(2)方式二:上传数据后添加分区
上传数据
hive (default)> dfs -mkdir -p
/user/hive/warehouse/mydb.db/dept_partition2/day=20200401/hour=14;
hive (default)> dfs -put /opt/module/hive/datas/dept_20200401.log
/user/hive/warehouse/mydb.db/dept_partition2/day=20200401/hour=14;
执行添加分区
hive (default)> alter table dept_partition2 add partition(day='201709',hour='14');
查询数据
hive (default)> select * from dept_partition2 where day='20200401' and hour='14';
(3)方式三:创建文件夹后 load 数据到分区
创建目录
hive (default)> dfs -mkdir -p
/user/hive/warehouse/mydb.db/dept_partition2/day=20200401/hour=15;
上传数据
hive (default)> load data local inpath
'/opt/module/hive/datas/dept_20200401.log' into table
dept_partition2 partition(day='20200401',hour='15');
查询数据
hive (default)> select * from dept_partition2
where day='20200401' and hour='15';
7.1.3 动态分区调整
关系型数据库中,对分区表 Insert 数据时候,数据库自动会根据分区字段的值,将数据插入到相应的分区中,Hive 中也提供了类似的机制,即动态分区(Dynamic Partition),只不过, 使用 Hive 的动态分区,需要进行相应的配置。
1)开启动态分区参数设置
(1)开启动态分区功能(默认 true,开启)
hive.exec.dynamic.partition=true
(2)设置为非严格模式(动态分区的模式,默认 strict,表示必须指定至少一个分区为 静态分区,nonstrict 模式表示允许所有的分区字段都可以使用动态分区。)
hive.exec.dynamic.partition.mode=nonstrict
(3)在所有执行 MR 的节点上,最大一共可以创建多少个动态分区。默认 1000
hive.exec.max.dynamic.partitions=1000
(4)在每个执行 MR 的节点上,最大可以创建多少个动态分区。该参数需要根据实际 的数据来设定。比如:源数据中包含了一年的数据,即 day 字段有 365 个值,那么该参数就 需要设置成大于 365,如果使用默认值 100,则会报错。
hive.exec.max.dynamic.partitions.pernode=100
(5)整个 MR Job 中,最大可以创建多少个 HDFS 文件。默认 100000
hive.exec.max.created.files=100000
(6)当有空分区生成时,是否抛出异常。一般不需要设置。默认 false
hive.error.on.empty.partition=false
2)案例实操
将 dept 表中的数据按照地区(loc 字段),插入到目标表 dept_partition 的相应 分区中。
(1)创建目标分区表
hive (default)> create table dept_partition_dy(id int, name string)
partitioned by (loc int)
row format delimited fields terminated by '\t';
(2)设置动态分区
set hive.exec.dynamic.partition.mode = nonstrict;
hive (default)> insert into table dept_partition_dy partition(loc)
select deptno, dname, loc from dept;
(3)查看目标分区表的分区情况
hive (default)> show partitions dept_partition;
7.2 分桶表
分区提供一个隔离数据和优化查询的便利方式。不过,并非所有的数据集都可形成合理 的分区。对于一张表或者分区,Hive 可以进一步组织成桶,也就是更为细粒度的数据范围 划分。
分桶是将数据集分解成更容易管理的若干部分的另一个技术。
分区针对的是数据的存储路径;分桶针对的是数据文件。
1)先创建分桶表
(1)数据准备
1001 ss1
1002 ss2
1003 ss3
1004 ss4
1005 ss5
1006 ss6
1007 ss7
1008 ss8
1009 ss9
1010 ss10
1011 ss11
1012 ss12
1013 ss13
1014 ss14
1015 ss15
1016 ss16
(2)创建分桶表
create table stu_buck(id int, name string)
clustered by(id)
into 4 buckets
row format delimited fields terminated by '\t';
(3)查看表结构
hive (default)> desc formatted stu_buck;
(4)导入数据到分桶表中,load 的方式
hive (default)> load data inpath '/student.txt' into table stu_buck;
(5)查看创建的分桶表中是否分成 4 个桶
在hadoop102:9870中查看数据时否分成四份
(6)查询分桶的数据
hive(default)> select * from stu_buck;
(7)分桶规则:
根据结果可知:Hive 的分桶采用对分桶字段的值进行哈希,然后除以桶的个数求余的方 式决定该条记录存放在哪个桶当中
2)分桶表操作需要注意的事项:
(1)reduce 的个数设置为-1,让 Job 自行决定需要用多少个 reduce 或者将 reduce 的个 数设置为大于等于分桶表的桶数
(2)从 hdfs 中 load 数据到分桶表中,避免本地文件找不到问题
(3)不要使用本地模式
3)insert 方式将数据导入分桶表
hive(default)>insert into table stu_buck select * from student_insert;
7.3 抽样查询
对于非常大的数据集,有时用户需要使用的是一个具有代表性的查询结果而不是全部结 果。Hive 可以通过对表进行抽样来满足这个需求。
语法: TABLESAMPLE(BUCKET x OUT OF y)
查询表 stu_buck 中的数据。
hive (default)> select * from stu_buck tablesample(bucket 1 out of 4 on id);
注意:x 的值必须小于等于 y 的值,否则
FAILED: SemanticException [Error 10061]: Numerator should not be bigger than denominator in sample clause for table stu_buck
8. 函数
8.1 系统内置函数
1)查看系统自带的函数
hive> show functions;
2)显示自带的函数的用法
hive> desc function upper;
3)详细显示自带的函数的用法
hive> desc function extended upper;
8.2 常用内置函数
8.2.1 空字段赋值
函数说明
NVL:给值为 NULL 的数据赋值,它的格式是 NVL( value,default_value)。它的功能是如 果 value 为 NULL,则 NVL 函数返回 default_value 的值,否则返回 value 的值,如果两个参数 都为 NULL ,则返回 NULL。
8.2.2 case when then else end
1)数据准备

2)需求
求出不同部门男女各多少人。结果如下:
dept_Id 男 女
A 2 1
B 1 2
3)创建本地 emp_sex.txt,导入数据
[hhhyixin@hadoop102 datas]$ vi emp_sex.txt
悟空 A 男
大海 A 男
宋宋 B 男
凤姐 A 女
婷姐 B 女
婷婷 B 女
4)创建 hive 表并导入数据
create table emp_sex(
name string,
dept_id string,
sex string)
row format delimited fields terminated by "\t";
load data local inpath '/opt/module/hive/data/emp_sex.txt' into table
emp_sex;
5)按需求查询数据
select
dept_id,
sum(case sex when '男' then 1 else 0 end) male_count,
sum(case sex when '女' then 1 else 0 end) female_count
from emp_sex
group by dept_id;
8.2.3 行转列
1)相关函数说明
CONCAT(string A/col, string B/col…):返回输入字符串连接后的结果,支持任意个输入字 符串;
CONCAT_WS(separator, str1, str2,…):它是一个特殊形式的 CONCAT()。第一个参数剩余参 数间的分隔符。分隔符可以是与剩余参数一样的字符串。如果分隔符是 NULL,返回值也将 为 NULL。这个函数会跳过分隔符参数后的任何 NULL 和空字符串。分隔符将被加到被连接 的字符串之间;
注意: CONCAT_WS must be "string or array
COLLECT_SET(col):函数只接受基本数据类型,它的主要作用是将某字段的值进行去重 汇总,产生 Array 类型字段。
2)数据准备
| name | constellation | blood_type |
|---|---|---|
| 孙悟空 | 白羊座 | A |
| 大海 | 射手座 | A |
| 宋宋 | 白羊座 | B |
| 猪八戒 | 白羊座 | A |
| 凤姐 | 射手座 | A |
| 苍老师 | 白羊座 | B |
3)需求
把星座和血型一样的人归类到一起。结果如下:
射手座,A 大海|凤姐
白羊座,A 孙悟空|猪八戒
白羊座,B 宋宋|苍老师
4)创建本地 constellation.txt,导入数据
[hhhyixin@hadoop102 datas]$ vim person_info.txt
孙悟空 白羊座 A
大海 射手座 A
宋宋 白羊座 B
猪八戒 白羊座 A
凤姐 射手座 A
苍老师 白羊座 B
5)创建 hive 表并导入数据
create table person_info(
name string,
constellation string,
blood_type string)
row format delimited fields terminated by "\t";
load data local inpath "/opt/module/hive/data/person_info.txt" into table
person_info;
6)按需求查询数据
SELECT
t1.c_b,
CONCAT_WS("|",collect_set(t1.name))
FROM (
SELECT
NAME,
CONCAT_WS(',',constellation,blood_type) c_b
FROM person_info
)t1
GROUP BY t1.c_b
8.2.4 列转行
1)函数说明
EXPLODE(col):将 hive 一列中复杂的 Array 或者 Map 结构拆分成多行。
LATERAL VIEW
用法:LATERAL VIEW udtf(expression) tableAlias AS columnAlias
解释:用于和 split, explode 等 UDTF 一起使用,它能够将一列数据拆成多行数据,在此 基础上可以对拆分后的数据进行聚合。
2)数据准备

3)需求
将电影分类中的数组数据展开。结果如下:
《疑犯追踪》 悬疑
《疑犯追踪》 动作
《疑犯追踪》 科幻
《疑犯追踪》 剧情
《Lie to me》 悬疑
《Lie to me》 警匪
《Lie to me》 动作
《Lie to me》 心理
《Lie to me》 剧情
《战狼 2》 战争
《战狼 2》 动作
《战狼 2》 灾难
4)创建本地 movie.txt,导入数据
[hhhyixin@hadoop102 datas]$ vi movie_info.txt
《疑犯追踪》 悬疑,动作,科幻,剧情
《Lie to me》悬疑,警匪,动作,心理,剧情
《战狼 2》 战争,动作,灾难
5)创建 hive 表并导入数据
create table movie_info(
movie string,
category string)
row format delimited fields terminated by "\t";
load data local inpath "/opt/module/data/movie.txt" into table movie_info;
6)按需求查询数据
SELECT
movie,
category_name
FROM
movie_info
lateral VIEW
explode(split(category,",")) movie_info_tmp AS category_name;
8.2.5 窗口函数(开窗函数)
1)相关函数说明
OVER():指定分析函数工作的数据窗口大小,这个数据窗口大小可能会随着行的变而变化。
| 函数 | 作用 |
|---|---|
| CURRENT ROW | 当前行 |
| n PRECEDING | 往前 n 行数据 |
| n FOLLOWING | 往后 n 行数据 |
| UNBOUNDED | 起点 |
| UNBOUNDED PRECEDING | 表示从前面的起点 |
| UNBOUNDED FOLLOWING | 表示到后面的终点 |
| LAG(col,n,default_val) | 往前第 n 行数据 |
| LEAD(col,n, default_val) | 往后第 n 行数据 |
| NTILE(n) | 把有序窗口的行分发到指定数据的组中,各个组有编号,编号从 1 开始,对 于每一行,NTILE 返回此行所属的组的编号。注意:n 必须为 int 类型。 |
2)数据准备:name,orderdate,cost
jack,2017-01-01,10
tony,2017-01-02,15
jack,2017-02-03,23
tony,2017-01-04,29
jack,2017-01-05,46
jack,2017-04-06,42
tony,2017-01-07,50
jack,2017-01-08,55
mart,2017-04-08,62
mart,2017-04-09,68
neil,2017-05-10,12
mart,2017-04-11,75
neil,2017-06-12,80
mart,2017-04-13,94
3)需求
(1)查询在 2017 年 4 月份购买过的顾客及总人数
(2)查询顾客的购买明细及月购买总额
(3)上述的场景, 将每个顾客的 cost 按照日期进行累加
(4)查询每个顾客上次的购买时间
(5)查询前 20%时间的订单信息
4)创建本地 business.txt,导入数据
[hhhyixin@hadoop102 datas]$ vi business.txt
5)创建 hive 表并导入数据
create table business(
name string,
orderdate string,
cost int
) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
load data local inpath "/opt/module/data/business.txt" into table business;
6)按需求查询数据
(1) 查询在 2017 年 4 月份购买过的顾客及总人数
select name,count(*) over ()
from business
where substring(orderdate,1,7) = '2017-04'group by name;
(2) 查询顾客的购买明细及月购买总额
select name,orderdate,cost,sum(cost) over(partition by month(orderdate)) from business;
(3) 将每个顾客的 cost 按照日期进行累加
select name,orderdate,cost,
sum(cost) over() as sample1,--所有行相加
sum(cost) over(partition by name) as sample2,--按 name 分组,组内数据相加
sum(cost) over(partition by name order by orderdate) as sample3,--按 name
分组,组内数据累加
sum(cost) over(partition by name order by orderdate rows between
UNBOUNDED PRECEDING and current row ) as sample4 ,--和 sample3 一样,由起点到
当前行的聚合
sum(cost) over(partition by name order by orderdate rows between 1
PRECEDING and current row) as sample5, --当前行和前面一行做聚合
sum(cost) over(partition by name order by orderdate rows between 1
PRECEDING AND 1 FOLLOWING ) as sample6,--当前行和前边一行及后面一行
sum(cost) over(partition by name order by orderdate rows between current
row and UNBOUNDED FOLLOWING ) as sample7 --当前行及后面所有行
from business;
rows 必须跟在 order by 子句之后,对排序的结果进行限制,使用固定的行数来限制分 区中的数据行数量
(4) 查看顾客上次的购买时间
select name,orderdate,cost,
lag(orderdate,1,'1900-01-01') over(partition by name order by orderdate )
as time1, lag(orderdate,2) over (partition by name order by orderdate) as time2 from business;
(5) 查询前 20%时间的订单信息
select * from (
select name,orderdate,cost, ntile(5) over(order by orderdate) sorted
from business
) t
where sorted = 1;
8.2.6 Rank
1)函数说明
RANK() 排序相同时会重复,总数不会变
DENSE_RANK() 排序相同时会重复,总数会减少
ROW_NUMBER() 会根据顺序计算
2)数据准备
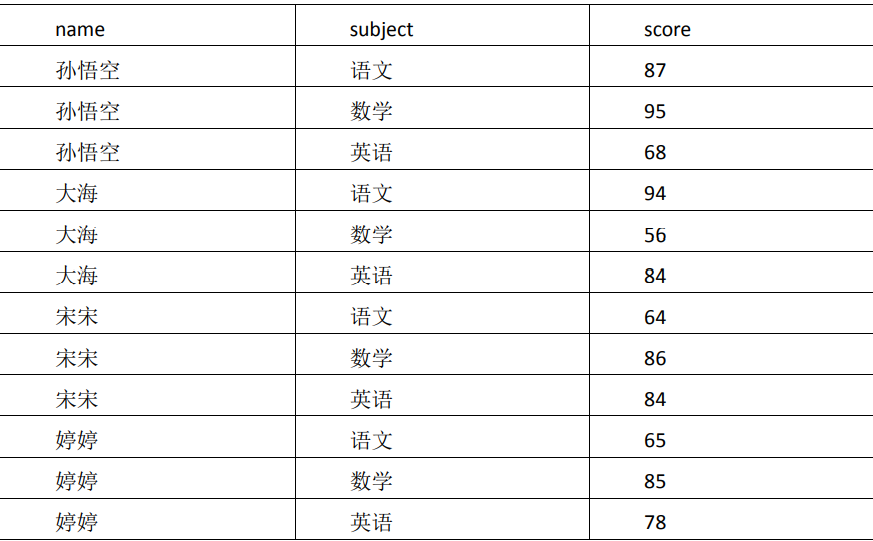
3)需求
计算每门学科成绩排名。
4)创建本地 score.txt,导入数据
[hhhyixin@hadoop102 datas]$ vi score.txt
5)创建 hive 表并导入数据
create table score(
name string,
subject string,
score int)
row format delimited fields terminated by "\t";
load data local inpath '/opt/module/data/score.txt' into table score;
6)按需求查询数据
select name,
subject,
score,
rank() over(partition by subject order by score desc) rp,
dense_rank() over(partition by subject order by score desc) drp,
row_number() over(partition by subject order by score desc) rmp
from score;
name subject score rp drp rmp
孙悟空 数学 95 1 1 1
宋宋 数学 86 2 2 2
婷婷 数学 85 3 3 3
大海 数学 56 4 4 4
宋宋 英语 84 1 1 1
大海 英语 84 1 1 2
婷婷 英语 78 3 2 3
孙悟空 英语 68 4 3 4
大海 语文 94 1 1 1
孙悟空 语文 87 2 2 2
婷婷 语文 65 3 3 3
宋宋 语文 64 4 4 4
8.2.7 其他常用函数
8.3 自定义函数
1)Hive 自带了一些函数,比如:max/min 等,但是数量有限,自己可以通过自定义 UDF 来 方便的扩展。
2)当 Hive 提供的内置函数无法满足你的业务处理需要时,此时就可以考虑使用用户自定义函数(UDF:user-defined function)。
3)根据用户自定义函数类别分为以下三种:
(1)UDF(User-Defined-Function) 一进一出
(2)UDAF(User-Defined Aggregation Function)
聚集函数,多进一出 类似于:count/max/min
(3)UDTF(User-Defined Table-Generating Functions)
一进多出 如 lateral view explode()
4)官方文档地址
https://cwiki.apache.org/confluence/display/Hive/HivePlugins
5)编程步骤:
(1)继承 Hive 提供的类
org.apache.hadoop.hive.ql.udf.generic.GenericUDF
org.apache.hadoop.hive.ql.udf.generic.GenericUDTF;
(2)实现类中的抽象方法
(3)在 hive 的命令行窗口创建函数
添加 jar
add jar linux_jar_path
创建 function
create [temporary] function [dbname.]function_name AS class_name;
(4)在 hive 的命令行窗口删除函数
drop [temporary] function [if exists] [dbname.]function_name;
8.4 自定义 UDF 函数
0)需求:
自定义一个 UDF 实现计算给定字符串的长度,例如:
hive(default)> select my_len("abcd");
4
1)创建一个 Maven 工程 Hive
2)导入依赖
<dependencies>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>3.1.2</version>
</dependency>
</dependencies>
3)创建一个类
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.exec.UDFArgumentLengthException;
import org.apache.hadoop.hive.ql.exec.UDFArgumentTypeException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDF;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import
org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectIn
spectorFactory;
/**
* 自定义 UDF 函数,需要继承 GenericUDF 类
* 需求: 计算指定字符串的长度
*/
public class MyStringLength extends GenericUDF {
/**
*
* @param arguments 输入参数类型的鉴别器对象
* @return 返回值类型的鉴别器对象
* @throws UDFArgumentException
*/
@Override
public ObjectInspector initialize(ObjectInspector[] arguments) throws
UDFArgumentException {
// 判断输入参数的个数
if(arguments.length !=1){
throw new UDFArgumentLengthException("Input Args Length
Error!!!");
}
// 判断输入参数的类型
if(!arguments[0].getCategory().equals(ObjectInspector.Category.PRIMITIVE)
){
throw new UDFArgumentTypeException(0,"Input Args Type
Error!!!");
}
//函数本身返回值为 int,需要返回 int 类型的鉴别器对象
return PrimitiveObjectInspectorFactory.javaIntObjectInspector;
}
/**
* 函数的逻辑处理
* @param arguments 输入的参数
* @return 返回值
* @throws HiveException
*/
@Override
public Object evaluate(DeferredObject[] arguments) throws
HiveException {
if(arguments[0].get() == null){
return 0;
}
return arguments[0].get().toString().length();
}
@Override
public String getDisplayString(String[] children) {
return "";
}
}
4)打成 jar 包上传到服务器/opt/module/data/myudf.jar
5)将 jar 包添加到 hive 的 classpath
hive (default)> add jar /opt/module/data/myudf.jar;
6)创建临时函数与开发好的 java class 关联
hive (default)> create temporary function my_len as "com.atguigu.hive.MyStringLength";
7)即可在 hql 中使用自定义的函数
hive (default)> select ename,my_len(ename) ename_len from emp;
8.5 自定义 UDTF 函数
0)需求
自定义一个 UDTF 实现将一个任意分割符的字符串切割成独立的单词,例如:
hive(default)> select myudtf("hello,world,hadoop,hive", ",");
hello
world
hadoop
hive
1)代码实现
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDTF;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import
org.apache.hadoop.hive.serde2.objectinspector.ObjectInspectorFactory;
import
org.apache.hadoop.hive.serde2.objectinspector.StructObjectInspector;
import
org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectIn
spectorFactory;
import java.util.ArrayList;
import java.util.List;
public class MyUDTF extends GenericUDTF {
private ArrayList<String> outList = new ArrayList<>();
@Override
public StructObjectInspector initialize(StructObjectInspector argOIs)
throws UDFArgumentException {
//1.定义输出数据的列名和类型
List<String> fieldNames = new ArrayList<>();
List<ObjectInspector> fieldOIs = new ArrayList<>();
//2.添加输出数据的列名和类型
fieldNames.add("lineToWord");
fieldOIs.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);
return
ObjectInspectorFactory.getStandardStructObjectInspector(fieldNames,
fieldOIs);
}
@Override
public void process(Object[] args) throws HiveException {
//1.获取原始数据
String arg = args[0].toString();
//2.获取数据传入的第二个参数,此处为分隔符
String splitKey = args[1].toString();
//3.将原始数据按照传入的分隔符进行切分
String[] fields = arg.split(splitKey);
//4.遍历切分后的结果,并写出
for (String field : fields) {
//集合为复用的,首先清空集合
outList.clear();
//将每一个单词添加至集合
outList.add(field);
//将集合内容写出
forward(outList);
}
}
@Override
public void close() throws HiveException {
}
}
2)打成 jar 包上传到服务器/opt/module/hive/data/myudtf.jar
3)将 jar 包添加到 hive 的 classpath 下
hive (default)> add jar /opt/module/hive/data/myudtf.jar;
4)创建临时函数与开发好的 java class 关联
hive (default)> create temporary function myudtf as "com.hhhyixin.hive.MyUDTF";
5)使用自定义的函数
hive (default)> select myudtf("hello,world,hadoop,hive",",");