【MySQL】 B+ 树存储的原理
1. B 树 和 B+ 树
B Tree 模拟生成工具:https://www.cs.usfca.edu/~galles/visualization/BTree.html
B+Tree 模拟生成工具:
https://www.cs.usfca.edu/~galles/visualization/BPlusTree.html
- B 树 —— 1970年,R.Bayer和E.mccreight提出了一种适用于外查找的树,它是一种平衡的多叉树,称为B树(B-树、B_树)。其相对于普通的我们常见的树,具有如下特点:一个节点中可含有多个元素, 整个树有顺序,并且叶子节点都位于同一层。

- B+ 树 —— 就是 B 树的一个升级版,其和B树一样是一种平衡的多叉树,并且一个节点可含有多个元素且整个树有序。但是相对于 B 树,B+ 树的叶子节点有指针,并且非叶子节点上的元素都冗余了一份在叶子节点上
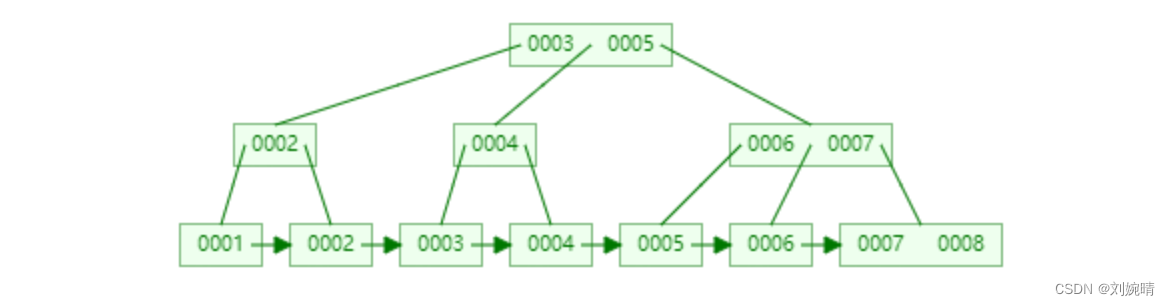
2. MySQL 的 B+ 树结构
2.1 必要概念
MySQL InnoDB 存储引擎中的 Page 页概念: 其含义是当Innodb向磁盘中取数据时,以页为单位去存和读,页的默认大小为 16 KB (对应操作系统中局部性原理)。—— 对应在存储结构中 page 就是 B+ 树中的节点。一个 Page 的结构 ( B+ 树中的节点)结构如下图所示:
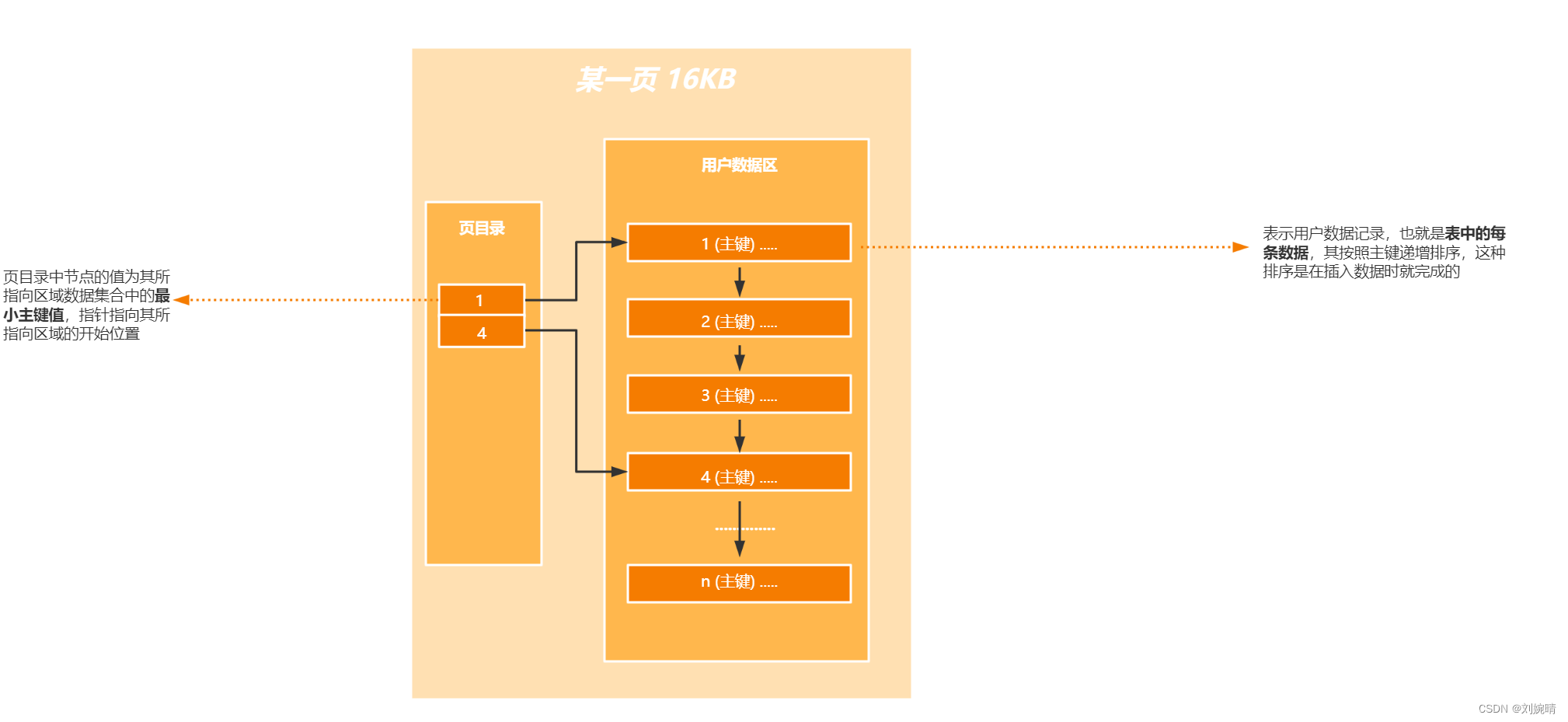
userRecord 用户记录的概念: page 页中含有 userRecord 用户记录,即当用户记录所占内存超过 16 KB 时,将其封装成页,放到磁盘中。
2.2 相关问题
在了解了 InnoDB 存储引擎中的页的概念后,让我们看一下相关的几个问题 ——
- 当我们插入数据时,存储引擎会按照主键升序排序 ,为什么要在插入时排序,这不是会影响插入的性能嘛?
1) 通过对主键排序能提高查询的效率,能提前结束查找表中不存在数据的查找 —— 使用链表的方式(插入效率高,但是查询效率低)
2)在对主键进行排序后,我们可以通过建立页目录的方式提升查找链表的数据的效率(这里的页目录类比一本书中的目录的作用)—— 在具体实现上,我们将数据进行分组,对应每个组建立一个目录项,对应每个目录项用每组最小的主键值标记 —— 这也是典型的空间换时间的思想
扩展: 因为页目录的存在和插入时会按照主键进行排序的存在,在插入数据时建议使用自增 id 原因 —— 如果不用自增 id, 可能需要进行页内数据的交换,这样会极大的影响插入数据的效率
—— 这也引出了 使用 UUID 的问题,一是无序导致的插入效率慢 ;二是其生成的 ID 很长,要占更多的空间
- 多页查找问题——在页数很多情况下,对每页的查找,不就又成了对链表的遍历嘛,那么MySQL 是如何设计提升多页查找的效率呢
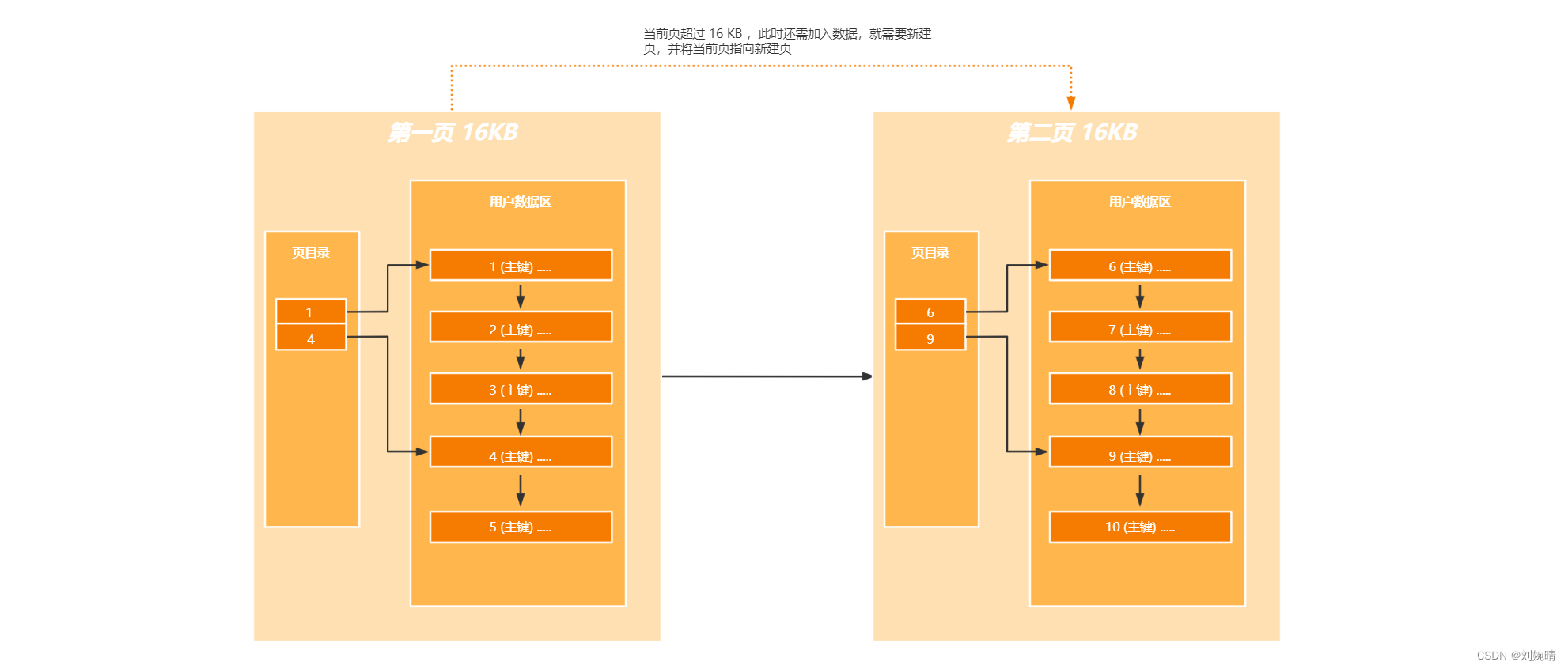
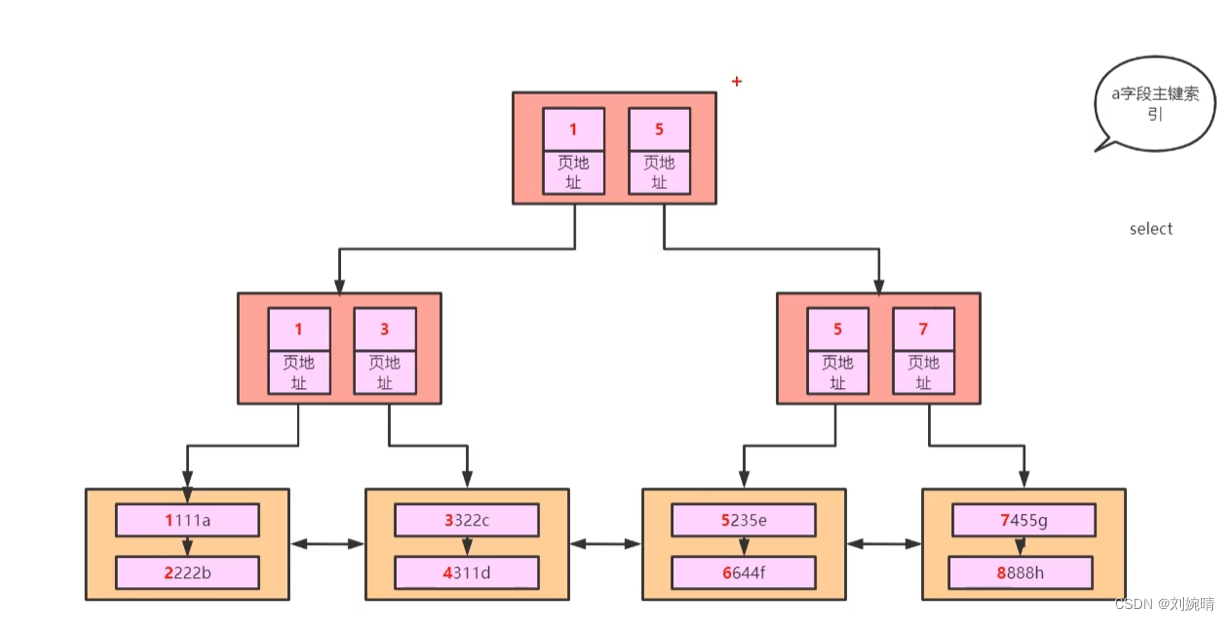
以上图为例子,执行 select * from tableName where id = 6
若是不进行优化,查找过程为:遍历页链表取出每页,对每页进行查找,这样的方式就又是对链表的遍历了,而链表就是一种插入效率高,查找效率低的数据结构,我们需要对这种方式进行优化。
优化方式: 和为用户数据建立目录页一页,我们为页页目录再建立一个目录页 ,在这个目录页的目录页中存放的是原目录页中的id最小值。这样我们再进行查找时,就可以通过目录页的目录页,快速找到我们要查找的数据所在的页范围,我们再去指定的页范围内进行查找就行了。
那么,一个完整的 B+ Tree 存储示例如下图所示:
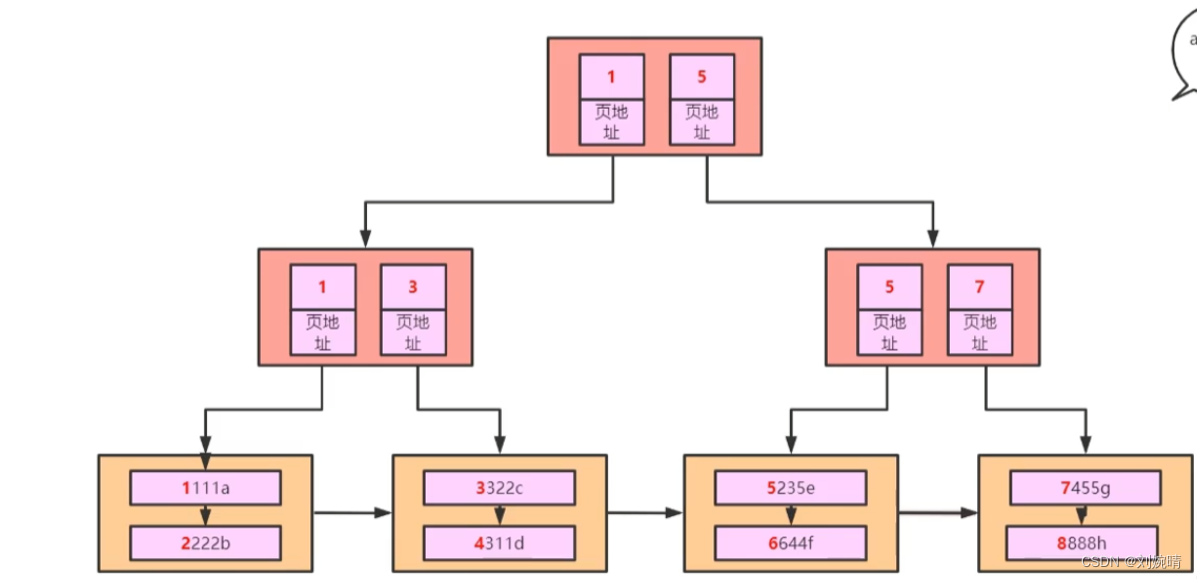
解释: 这是一个两层的 B+ Tree ,其共存放了 8 条用户数据,每个页含4条用户数据,共含三个页(两个用户数据页, 一个页目录目录页)
注: 当 B+ 树超过三层的话,就要考虑分库分表了,2 层的 B+ 树是比较好的
-
2 层 B+ 树能存多少条数据,3 层 B+ 树能存多少条数据?
2 层 B+ 树 ——
假设我们的主键是 int 类型,占 4 个字节,而指针占 6 个字节,一个页可以放下 16 KB 的数据,那么存放页目录的目录的页中一共可以放下 (16KB / 10字节)个页目录,也就是说我们最多可以有 (16KB / 10字节)个数据页。那么假设我们的一条数据为 1 KB,总共可以有 —— (16KB / 10字节) * (16 KB / 1 KB)条数据 (页数 * 每个页可以存放的数据条数)
3 层 B+ 树 ——
3层的 B+Tree 就是为目录页的目录页再设置一个目录页,计算方法类似,这里不过多介绍
3. InnoDB 中的 B+ 树索引查找问题
3.1 索引查找问题
B+ 树是主键索引,叶子节点为数据库中的数据,上面的页为索引 —— 也可以叫聚集索引(聚簇索引, 即索引和数据在一起)
在查找时,使用在从上往下的找法,通过主键查找(= > < 都可以,支持范围查找) —— 为了更加好的支持范围查找,其在最底层叶子节点的数据处使用用双向指针
那要是不能走索引呢,即不通过主键找 的情况 —— 在这种情况,只能进行全表扫描,也就是从链表头扫描到链表尾
尾注:所有的不自信,所有的痛苦,所有的失望,都是因为技术不够强,我热爱我所学的,不后悔走上这条路,我也一定会坚持走下去,与君共勉