kafka原理看这一篇就够了
为何使用消息队列
- 异步。接口方式实现多个系统协作,如图A系统作为用户请求接收方,需要调用多个系统的接口,这些接口还有可能是在A系统里同步调用,所以最后的接口耗时是多个系统接口耗时的总和;mq方式则可以异步发送消息给mq,mq再发送给其他多个系统,多个系统并行且异步的接收消息。当然,mq方式实现有一个前提是用户的请求不需要立即返回请求结果,例如用户发送一个查询请求就不适合mq方式。mq方式多用于传递事件,如发送优惠券、秒杀等。
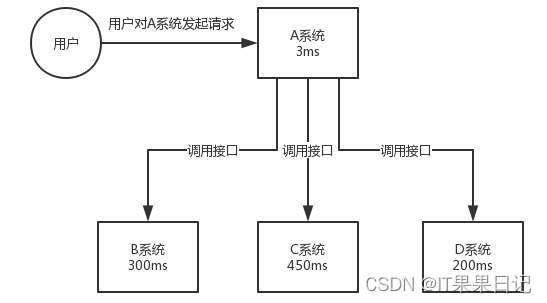
- 削峰。用户的请求大部分都集中在固定的时间段,而在晚间凌晨或者用户使用低峰期基本没什么请求。所以mq的削峰就是为了将高峰期的请求泄洪一部分到低峰期。
- 解耦。接口方式发送消息,发送者调用接口,接收者提供接口,此时发送者作为消息生产者(如图中的A系统)作为主动的一方需要适配上游的各个类型的接口,它们的传输协议、参数、返回值等可能都不一样,同时各个接收方还不能拒收消息,这些都会带来极大的工作量;mq方式发送消息,消息发送者变成了上游,现在只需要将统一格式的消息发送给mq,由mq来控制消息的存储、容灾以及消息是否送达等。消息接收者则遵守消息的统一格式即可,如果不想接收消息可以取消订阅。这样就达到了生产者和消费者之间的解耦效果。

kafka的总体架构
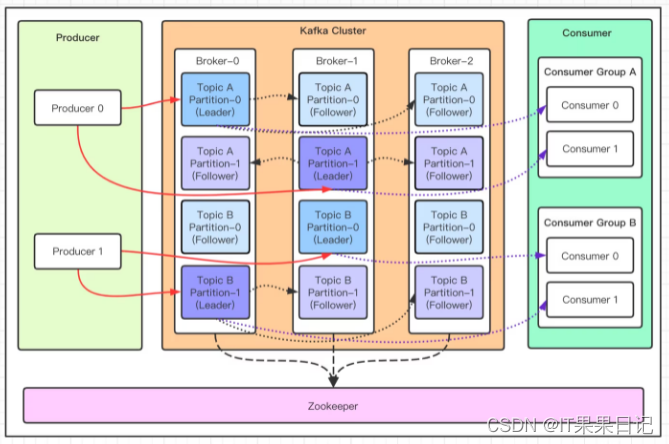
- Producer:消息的生产者,即消息的入口。
- Broker:kafka的一个实例,一台kafka服务器上会有一个或多个实例。多台kafka服务构成了kafka的集群。
- Topic:消息的主题,生产者按照主题发送消息,消费者按照主题接收消息,一个Broker可以有多个主题。
- Partition:Topic的分区,一个Topic可以有多个分区,分区越多可以并行处理消息的能力越强。同一个Topic上的不同分区消息是不重复的,Partition的本质是文件夹。
- Replication:Partition的副本,副本用来做数据备份。副本分为主分区副本(Leader)和从分区副本(Follower),它们不能同时出现在一个Broker上。主分区副本负责消息的接收并写入,从分区副本不接收生产者发来的消息,它的唯一职责就是从主分区副本同步过来消息。当主分区副本挂掉的时候,会在从分区副本中选出一个新的Leader作为主分区副本。kafka中一个Partition的最大副本数量是10个,且副本数量不能大于Broker的数量。
- Consumer:消息的消费者,即消息的出口。
- Consumer Group:多个消费者组成一个消费组,消费组之间可以重复消费消息。同一个消费组的某一个Partition不能同时被多个消费者消费。
- Zookeeper:kafka集群依赖Zookeeper保存集群的元信息,以保证kafka集群的可靠性。kafka从2.8版本以后使用其内部的Quorum控制器来代替Zookeeper。
生产者写数据
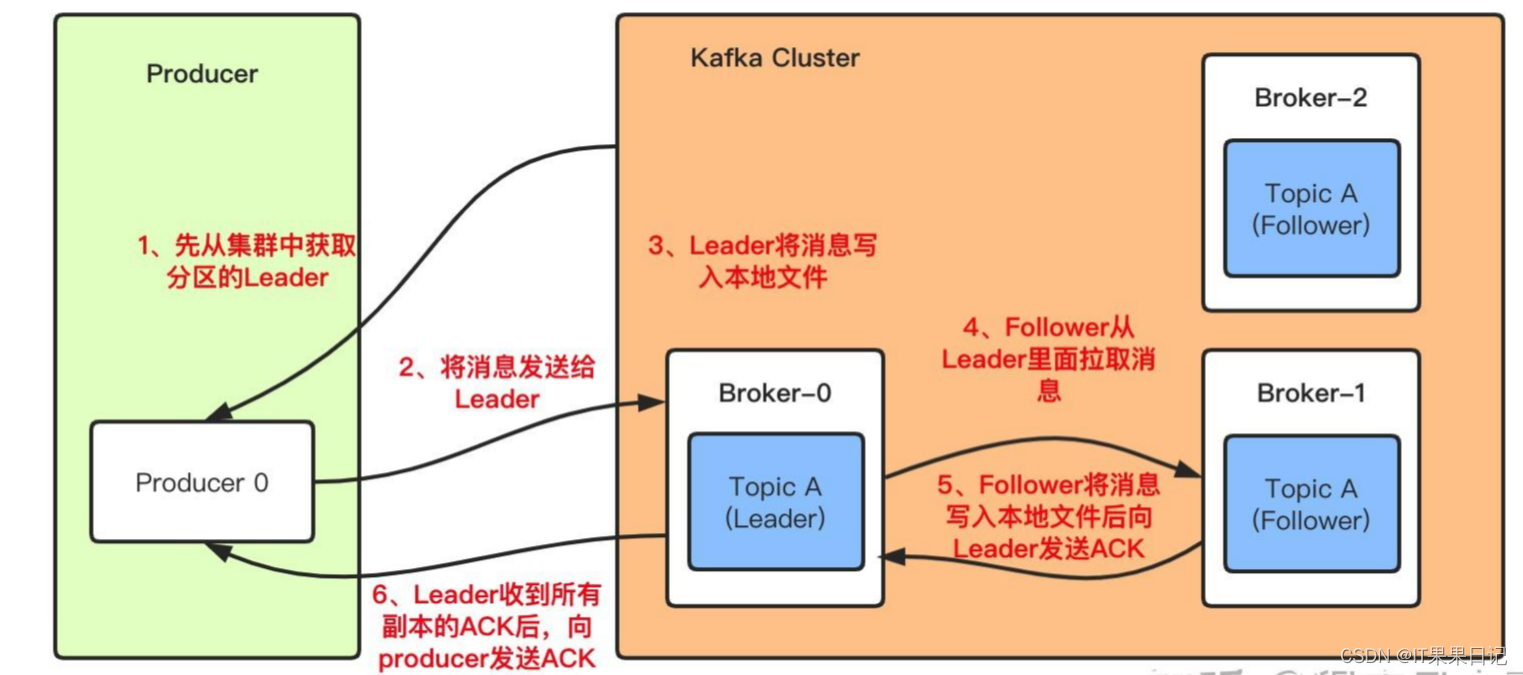
生产者发送消息给Leader分区副本,并顺序写入到磁盘文件,然后Follower分区副本从Leader分区副本poll消息以保证数据是最新的。kafka将消息写入哪个分区有几下几个原则:
- 生产者指定了分区,写入对应的分区
- 生产者没有指定分区,但设置了数据库的key,根据key的hash值算出一个分区
- 生产者既没有指定分区,也没有设置key,轮询出一个分区
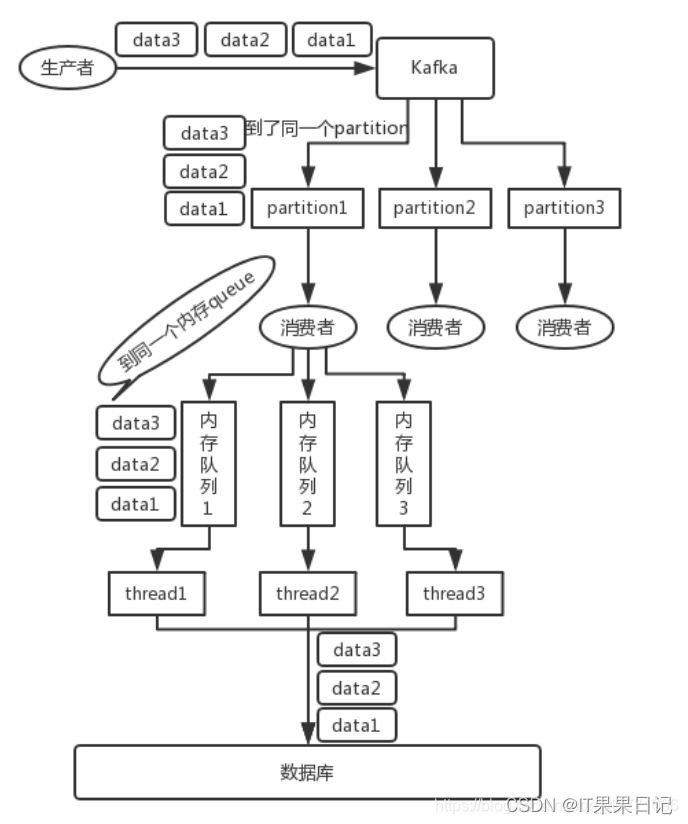
topic本质是一个目录,而topic又是由一些Partition Logs(分区日志)组成。消息采用hash取模的分区算法有序的写入到Partitionp Log上。
producer在将消息写入partition之前会先在内存中缓存,累计到一定量后(按数量、按时间间隔或按数据大小),再批量写入。

一般一条消息大概1~10kB,推荐不要超过1MB。
kafka默认数据保留7天时间。如果数据量大可以修改配置(log.retention.hours)将时间缩短。
消费者读数据
与生产者一样,消费者主动的从Leader分区副本拉取消息。每成功拉取一条partition的消息,partition的消息游标卡尺(offset)就会加1。

partition里的offset默认配置是从最新一条开始消费,也可以配置from beginning从0开始消费。
在同一个消费组里,消费者和partition的关系是1:1或者1:n,不能出现消费者与partition是n:1的情况,意思是同一个消费组里消费者数量要小于等于parition的数量。因为不这样做就会造成多个消费者共享一个offset,从而就不能保证一个partition内的消息的顺序性,也会造成消息被重复消费的安全问题,这是一种不稳定的重复消费。
如果想要稳定的重复消费同一条消息,可以设置两个消费组。两个组内的消费者消费同一个partition时,offset是相互独立的。

消息的有序性
想要保证消息被消费的有序性,有以下两个方法:
- 一个topic只设置一个partition。缺点是消费组里只能有一个消费者消费,不适用高并发场景。
- producer将需要保证顺序的消息发送到同一个partition。两种方式指定:1、指定partition;2、不指定partition,根据key的hash值运算后得到partition。
消息的可靠性
kafka的数据是可持久化的写在Partition Log文件里。每个topic都可以设置副本数量。副本数量决定了有几个broker来存放写入的数据。
consumer和partition数量的关系是:partition数 >= 同一个消费组里的consumer数。因为一个partition只能被同一个消费组的一个consumer消费(但一个consumer可以消费多个partition)。这是为了消息在一个partition里的顺序读。
生产端消息可靠性
分区副本

所有的读写请求都发往leader副本所在的broker,follower副本不处理客户端请求,它唯一的任务就是从leader副本异步拉取消息。
Kafka默认的副本因子是3,即每个分区只有1个leader副本和2个follower副本。
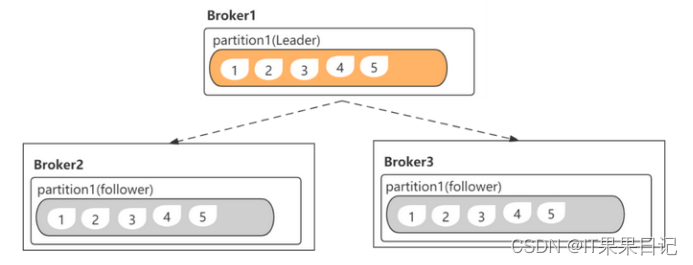
同步副本(In-sync replicas)
ISR同步副本机制是用来判断follower是否同步了leader的最新数据。
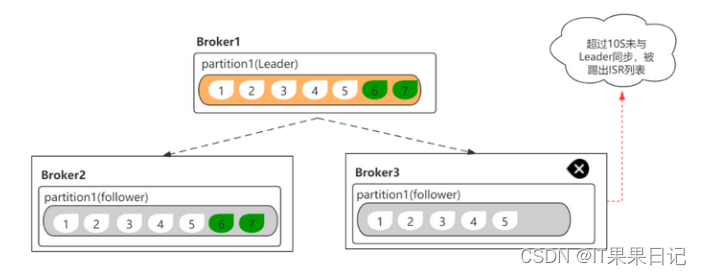
ISR列表保存了与leader已经同步的副本,leader自己是长期存在于ISR列表。当follower副本超过设定的时间间隔(replica.lag.time.max.ms)没有和leader同步,就会被踢出ISR列表,反之则不会被踢出。
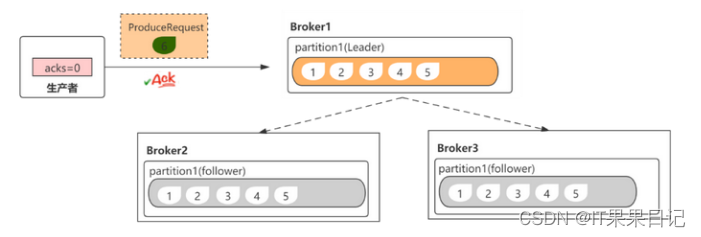
acks参数(生产者配置)
acks参数,表示有多少的分区副本收到消息,才能认为消息是写入成功的。
- acks=0。不需要副本收到消息,producer就能收到broker的响应。该模式吞吐量高,但安全性低,容易丢消息。
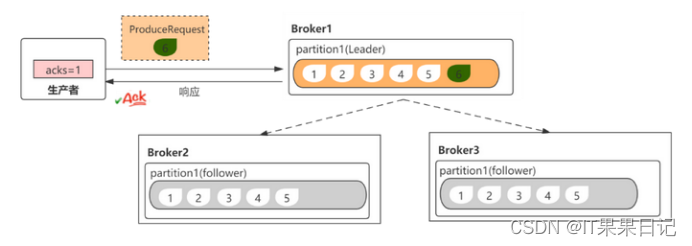
- acks=1(默认)。只要leader副本接收到了消息并写入到磁盘,producer就能收到broker的响应。需要注意的是这种模式依然会有丢消息的安全问题。例如,当leader副本收到消息以后还没来得及同步副本到follower就宕机了,此时producer已经收到了成功的响应,但follower变为新的leader时还未将最新的那条消息同步过来。
- acks=all(或-1)。只有ISR列表里的所有分区副本都收到消息,producer才能收到broker的响应。该模式延迟最高。
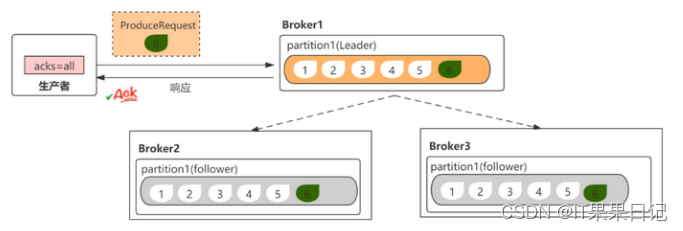
acks=all模式下,有一个最小副本配置(min.insync.replicas)。该配置默认值是1,只在acks=all时生效。该参数控制消息最少被多少个副本写入才算成功写入。即ISR列表的副本最小数量。因为ISR列表始终要有leader副本,所以如果该配置默认是1,实际上是起不到副本作用的,所以该配置最好配置为大于1的数。
当leader副本宕机时,acks=all模式下,会在ISR列表中选举一个新的broker作为leader。
- 增大min.insync.replicas。可以增加数据的可靠性。
- 减小min.insync.replicas。可以增加系统的可用性。
消费端消息可靠性
要想实现消费端的消息可靠性,必须抓住两点:
- 保证消息到达的状态(offset)和本地事务的状态保持一致。
- 保证消费的幂等性。
要想保证消费端消息的可靠性,首先必须保证提交offset和提交本地事务要么一起成功,要么一起失败。我们以自动提交offset和手动提交offset分别举例说明。
- 自动提交offset。消息到达消费客户端,不论本地事务是否提交成功,offset都会自动提交。一旦本地事务提交失败,就会造成消息丢失的问题。
- 手动提交offset。有三种方法:
- 第一种方式是消费端KafkaListener不配置本地事务,业务代码执行完后数据入库,最后再提交offset,即使offset提交失败,只要保证业务代码的幂等性,消息重复消费也可以接受。
- 第二种方式是消费端KafkaListener配置本地事务,将offset的值写道数据库里和业务数据一起提交,这样就将业务数据和offset做了绑定关系,在消费一开始就根据业务id和offset判断消息是否消费过,如果没有消费过才执行业务代码。
- 第三种方式是前两种方式的结合,这种方式不需要将offset入库。该方法在消费端KafkaListener配置本地事务,先执行业务代码最后执行offset提交,这样业务代码失败就不会执行提交offset的代码;而如果是最后提交offset失败,本地事务也会回滚。
在实际的运用中,考虑到数据库事务相对性能较差,可以把本地事务和offset的绑定关系用缓存来保存。
kafka优化
kafka削峰的几种方法:
- 增加分区。增加分区数可以提高消息并行处理的能力。当然也会增加集群的维护成本,需要权衡。
- 使用消费组。使用消费组可以让多个消费者并行消费一个partition的消息,因为每个消费组在同一个partition的offset不是共享的。但是为了避免重复消费消息,需要为不同消费组上的多个消费者指定所消费消息的key。
- 增加副本数。可以提高kafka的吞吐量,提升kafka的可靠性和容错性。
此外,修改一些kafka配置参数也能达到一定的优化效果。例如,
- 为了减少每次发送/拉取消息的次数,可以提高消息发送/拉取的消息数量/数据大小的阈值,或者增加时间间隔。减少消息发送/拉取的次数意味着一次发送/拉取的量比较大,所以还要注意提高会话超时、拉取超时的时间间隔,以免触发rebalance。
- 减小并行度(concurrency)。当concurrency=3时,就会有4*3=12个Consumer线程,12个Listener线程。减小concurrency可以减少客户端线程数量。
kafka和rocketmq
目前消息队列用的比较多的就是kafka和rocketmq了。我们可以比较一下这两种消息队列的优缺点。
- 适用场景
topic较多时推荐使用rocketmq;topic少时kafka性能更佳。因为kafka一个topic一个partition文件,rocketmq是多个topic一个文件。
kafka适合日志处理、大数据领域;rocketmq适合业务处理。
- 性能
kafka的tps在百万条/秒;rocketmq大约10万条/秒。
- 可靠性
kafka异步刷盘,异步副本;recketmq异步/同步刷盘,异步/同步副本。
- 支持队列数量
kafka单机最大支持64个队列/分区,增加分区性能降低严重;rocketmq单机最大支持5w队列,性能稳定。
- 消息顺序性
kafka在同一个partition下支持消息顺序性,但如果一台broker宕机会打乱顺序;rocketmq支持消息顺序性,一台broker宕机消息会发送失败,但顺序性依然可以保证。