算法笔记:OPTICS 聚类
1 基本介绍
- OPTICS(Ordering points to identify the clustering structure)是一基于密度的聚类算法
- OPTICS算法是DBSCAN的改进版本
- 在DBCSAN算法中需要输入两个参数: ϵ 和 MinPts ,选择不同的参数会导致最终聚类的结果千差万别,因此DBCSAN对于输入参数过于敏感
- 机器学习笔记:DBSCAN_dbscan参数选取-CSDN博客
- OPTICS算法的提出就是为了帮助DBSCAN算法选择合适的参数,降低输入参数的敏感度
- OPTICS主要针对输入参数ϵ过敏感做的改进
- OPTICS和DBSCNA的输入参数一样( ϵ 和 MinPts ),虽然OPTICS算法中也需要两个输入参数,但该算法对 ϵ 输入不敏感(一般将 ϵ 固定为无穷大)【不太清楚为什么不直接不输入ε呢?】
- 同时该算法中并不显式的生成数据聚类,只是对数据集合中的对象进行排序,得到一个有序的对象列表
- 通过该有序列表,可以得到一个决策图
- 通过决策图可以不同 ϵ 参数的数据集中检测簇集,
- 即:先通过固定的 MinPts 和无穷大的 ϵ 得到有序列表,然后得到决策图,通过决策图可以知道当 ϵ 取特定值时(比如 ϵ=3 )数据的聚类情况。
- OPTICS算法是DBSCAN的改进版本
1.1 和DBSCAN相似的概念
- ε、minPts、核心点、边缘点、噪点、密度直达(直接密度可达)、密度可达、密度相连 这些概念可见“机器学习笔记:DBSCAN_dbscan参数选取-CSDN博客
1.2 OPTICS新的定义
1.2.1 核心距离
 换句话说,如果x不是核心点,那么cd(x)就没有意义
换句话说,如果x不是核心点,那么cd(x)就没有意义
1.2.2 可达距离

- 也是,如果x不是核心点,那么rd(y,x)没有意义
- 如果y在x的ε领域内,那么rd(y,x)=cd(x);如果在x的ε领域外,那么就是d(y,x)
1.3 算法思想
假设数据集为,OPTICS算法的目标是输出一个有序排列,以及每个元素的两个属性值:核心距离,可达距离。
1.3.1 OPTICS算法的数据结构

1.4 算法流程
- 输入:数据集
,领域参数ε(一般等于∞),MinPts
- 创建两个队列,有序队列O和结果队列R
- 有序队列用来存储核心对象及其该核心对象的密度直达对象,并按可达距离升序排列
- 理解为待处理的数据
- 结果队列用来存储样本点的输出次序
- 已经处理完的数据
- 有序队列用来存储核心对象及其该核心对象的密度直达对象,并按可达距离升序排列
- 如果D中所有点都处理完毕或者不存在核心点,则算法结束。否则:
- 选择一个未处理(即不在结果队列R中)且为核心对象的样本点 p
- 将 p 放入结果队列R中,并从X中删除 p
- 找到 X 中 p 的所有密度直达样本点 x,计算 x 到 p 的可达距离
- 如果 x 不在有序队列O 中,则将 x 以及可达距离放入 O 中
- 若 x 在O中,则如果 x 新的可达距离更小,则更新 x 的可达距离
- 最后对O中数据按可达距离从小到大重新排序。
- 如果有序队列O为空,则回到步骤2,否则:
- 取出O 中第一个样本点 y(即可达距离最小的样本点),放入 R 中
- 从 D 和 O 中删除 y
- 如果 y 不是核心对象,则重复步骤 3(即找 O 中剩余数据可达距离最小的样本点)
- 如果 y 是核心对象,则
- 找到 y 在 D 中的所有密度直达样本点
- 计算到 y 的可达距离
- 所有 y 的密度直达样本点更新到 O 中
- 对O中数据按可达距离从小到大重新排序。
- 重复步骤2、3,直到算法结束。
- 最终可以得到一个有序的输出结果,以及相应的可达距离。
1.5 举例
样本数据集为:D = {[1, 2], [2, 5], [8, 7], [3, 6], [8, 8], [7, 3], [4,5]}

假设eps = inf,min_samples=2,则数据集D在OPTICS算法上的执行步骤如下:
- 计算所有的核心对象和核心距离
- 因为 eps 为无穷大,则显然每个样本点都是核心对象
- 因为 min_samples=2,则每个核心对象的核心距离就是离自己最近样本点到自己的距离(样本点自身也是邻域元素之一)
-
索引 0 1 2 3 4 5 6 元素 (1, 2) (2, 5) (8, 7) (3, 6) (8, 8) (7, 3) (4, 5) 核心距离 3.16 1.41 1.0 1.41 1.0 3.61 1.41
- 随机在 D 中选择一个核心对象
- 假设选择 0 号元素,将 0 号元素放入 R 中,并从 D 中删除
- 因为 eps = inf,则其他所有样本点都是 0 号元素的密度直达对象
- 计算其他所有元素到 0 号元素的可达距离(计算所有元素到 0 号元素的欧氏距离)
- 按可达距离排序,添加到序列 O 中
- 此时D{1,2,3,4,5,6},R{0},O{1,6,3,5,2,4}
-
索引 0 1 2 3 4 5 6 核心对象 元素 (1, 2) (2, 5) (8, 7) (3, 6) (8, 8) (7, 3) (4, 5) 核心距离 3.16 1.41 1.0 1.41 1.0 3.61 1.41 第一次可达距离 -- 3.16 8.60 4.47 9.21 6.08 4.24 0
- 此时 O 中可达距离最小的元素是 1 号元素
- 取出 1 号元素放入 R ,并从 D 和 O 中删除
- 因为 1 号元素是核心对象,找到 1 号元素在 D 中的所有密度直达对象(剩余的所有样本点),并计算可达距离
- 同时更新 O
- 此时 D{2,3,4,5,6} R{0,1} O{3,6,5,2,4}
-
索引 0 1 2 3 4 5 6 核心对象 元素 (1, 2) (2, 5) (8, 7) (3, 6) (8, 8) (7, 3) (4, 5) 核心距离 3.16 1.41 1.0 1.41 1.0 3.61 1.41 第二次可达距离 -- -- 6.32 1.41 6.70 5.38 2.0 1
- 此时 O 中可达距离最小的元素是 3 号元素
- 取出 3 号元素放入 R ,并从 D 和 O 中删除
- 因为 3 号元素是核心对象,找到 3 号元素在 D 中的所有密度直达对象(剩余的所有样本点),并计算可达距离
- 同时更新 O
- 此时D{2,4,5,6} R{0,1,3} O{6,5,2,4}
-
索引 0 1 2 3 4 5 6 核心对象 元素 (1, 2) (2, 5) (8, 7) (3, 6) (8, 8) (7, 3) (4, 5) 核心距离 3.16 1.41 1.0 1.41 1.0 3.61 1.41 第三次可达距离 -- -- 5.09 -- 5.39 5.0 1.41 3
- 此时 O 中可达距离最小的元素是 6 号元素
- 取出 6 号元素放入 R ,并从 D 和 O 中删除
- 因为 6 号元素是核心对象,找到 6 号元素在 D 中的所有密度直达对象(剩余的所有样本点),并计算可达距离,同时更新 O
- 此时D{2,4,5},R{0,1,3,6},O(5,2,4}
-
索引 0 1 2 3 4 5 6 核心对象 元素 (1, 2) (2, 5) (8, 7) (3, 6) (8, 8) (7, 3) (4, 5) 核心距离 3.16 1.41 1.0 1.41 1.0 3.61 1.41 第四次可达距离 -- -- 4.47 -- 5.0 3.61 -- 6
- 此时 O 中可达距离最小的元素是 5 号元素
- 取出 5 号元素放入 R ,并从 D 和 O 中删除
- 因为 5 号元素是核心对象,找到 5 号元素在 D 中的所有密度直达对象(剩余的所有样本点),并计算可达距离,同时更新 O。
- 注意本次计算的4号元素到5号元素的可达距离是5.10,大于5.0,因此不更新4号元素的可达距离
- 此时D{2,4}R{0,1,3,6,5} O(2,4)
-
索引 0 1 2 3 4 5 6 核心对象 元素 (1, 2) (2, 5) (8, 7) (3, 6) (8, 8) (7, 3) (4, 5) 核心距离 3.16 1.41 1.0 1.41 1.0 3.61 1.41 第五次可达距离 -- -- 4.12 -- 5.0
(5.10)
-- -- 5
- 此时 O 中可达距离最小的元素是 2 号元素
- 取出 2 号元素放入 R ,并从 D 和 O 中删除
- 因为 2 号元素是核心对象,找到 2 号元素在 D 中的所有密度直达对象,并计算可达距离,同时更新 O
-
索引 0 1 2 3 4 5 6 核心对象 元素 (1, 2) (2, 5) (8, 7) (3, 6) (8, 8) (7, 3) (4, 5) 核心距离 3.16 1.41 1.0 1.41 1.0 3.61 1.41 第六次可达距离 -- -- -- -- 1.0 -- -- 2
所以最后的R:(0,1,3,6,5,2,4) ,对应的可达距离为:{∞,3.16,1.41,1.41,3.61,4.12,1.0}
按照最终的输出顺序绘制可达距离图
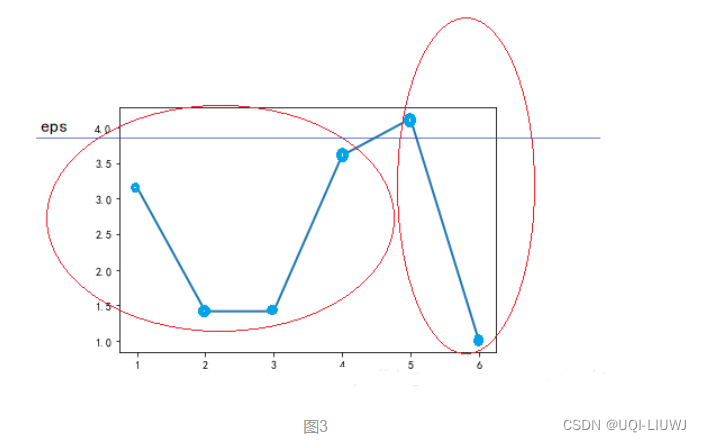
- 可以发现,可达距离呈现两个波谷,也即表现为两个簇,波谷越深,表示簇越紧密
- 只需要在两个波谷之间取一个合适的 eps 分隔值(图中蓝色的直线),使用 DBSCAN 算法就会聚类为两个簇。
- 即第一个簇的元素为:0、1、3、6、5;第二个簇的元素为:2、4。
1.4 和DBSCAN的异同
- OPTICS算法与DBSCAN算法有许多相似之处,可以被视为DBSCAN的一种泛化,它将eps要求从单一值放宽到值范围
- DBSCAN和OPTICS之间的关键区别在于,OPTICS算法构建了一个可达性图,为每个样本分配了一个可达性距离和在集群排序属性中的位置
- 这两个属性在模型拟合时被赋值,并用于确定集群成员资格
1.5 可达性距离
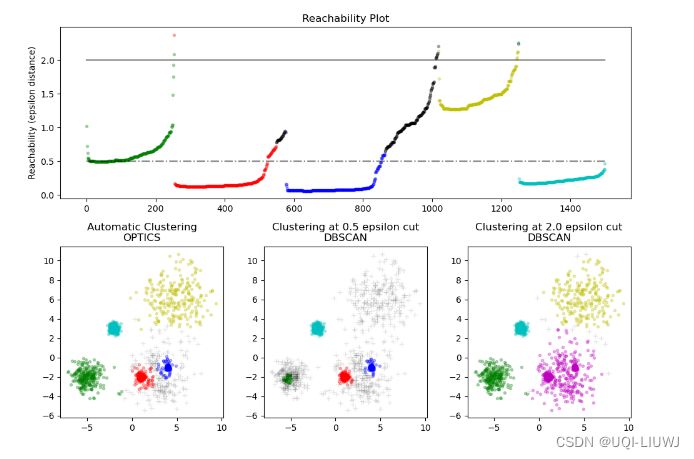
- OPTICS生成的可达性距离允许在单个数据集中提取可变密度的集群
- 结合可达性距离和数据集排序产生了一个可达性图,其中点密度在Y轴上表示,点的排序使得附近的点相邻
- 平行于x轴“切割”可达性图产生了类似DBSCAN的结果:
- 所有在“切割”线以上的点被分类为噪声
- 每当从左到右阅读时出现间断时,就标志着一个新的集群
- OPTICS的默认集群提取方法是查看图中的陡峭斜坡以找到集群,可以使用xi参数定义什么算作陡峭斜坡
1.6 计算复杂度
- 空间索引树用于避免计算完整的距离矩阵,并允许在大量样本集上有效地使用内存
- 对于大型数据集,可以通过HDBSCAN获得类似(但不完全相同)的结果。
- HDBSCAN实现是多线程的,并且比OPTICS具有更好的算法运行时间复杂性,但以较差的内存扩展为代价
2 sklearn.cluster.OPTICS
class sklearn.cluster.OPTICS(*, min_samples=5, max_eps=inf, metric='minkowski', p=2, metric_params=None, cluster_method='xi', eps=None, xi=0.05, predecessor_correction=True, min_cluster_size=None, algorithm='auto', leaf_size=30, memory=None, n_jobs=None)2.1 主要参数
| min_samples | int > 1 或介于0和1之间的浮点数,默认为5 点被视为核心点时,邻域中的样本数量 如果是浮点数,表示样本数量的一部分 |
| max_eps | 两个样本被视为彼此邻域的最大距离。 np.inf的默认值将识别所有规模的聚类; 降低max_eps将导致更短的运行时间 |
| metric | str或可调用,默认为'minkowski' 用于距离计算的度量。可以使用 来自scikit-learn:['cityblock', 'cosine', 'euclidean', 'l1', 'l2', 'manhattan'] 来自scipy.spatial.distance:['braycurtis', 'canberra', 'chebyshev', 'correlation', 'dice', 'hamming', 'jaccard', 'kulsinski', 'mahalanobis', 'minkowski', 'rogerstanimoto', 'russellrao', 'seuclidean', 'sokalmichener', 'sokalsneath', 'sqeuclidean', 'yule'] |
| p | 闵可夫斯基度量的参数 |
| xi | float在0和1之间,默认为0.05 确定可达性图中构成聚类边界的最小陡度。 例如,可达性图中的向上点被定义为一个点与其后继的比率最多为1-xi。 仅在cluster_method='xi'时使用 |
| min_cluster_size | int > 1 或介于0和1之间的浮点数,默认为None OPTICS聚类中的最小样本数量,表示为绝对数量或样本数量的一部分(至少为2)。如果为None,则使用min_samples的值。 仅在cluster_method='xi'时使用。 |
| algorithm | {'auto', 'ball_tree', 'kd_tree', 'brute'},默认为'auto' 用于计算最近邻居的算法: 'ball_tree'将使用BallTree。 'kd_tree'将使用KDTree。 'brute'将使用蛮力搜索。 'auto'(默认)将尝试根据传递给fit方法的值决定最合适的算法。 |
| leaf_size | 传递给BallTree或KDTree的叶子大小。这会影响构建和查询的速度,以及存储树所需的内存。最佳值取决于问题的性质。 |
| cluster_method | str,默认为'xi' 使用计算的可达性和排序提取聚类的方法。可能的值是“xi”和“dbscan” |
2.2. 举例
from sklearn.cluster import OPTICS
import numpy as npX = np.array([[1, 2], [1, 4], [1, 0],[10, 2], [10, 4], [10, 0]])op=OPTICS(min_samples=2).fit(X)op.labels_
#array([0, 0, 0, 1, 1, 1])op.ordering_
#array([0, 1, 2, 3, 4, 5])
#按聚类顺序排列的样本索引列表op.reachability_
#array([inf, 2., 2., 9., 2., 2.])
#按对象顺序索引的每个样本的可达距离op.core_distances_
#array([inf, 2., 2., 9., 2., 2.])
#每个样本成为核心点的核心距离
#永远不会成为核心的点的距离为无穷大。参考内容:机器学习笔记(十一)聚类算法OPTICS原理和实践_optics聚类_大白兔黑又黑的博客-CSDN博客
(4)聚类算法之OPTICS算法 - 知乎 (zhihu.com)