what is BERT?
BERT
Introduction
Paper
参考博客
9781838821593_ColorImages.pdf (packt-cdn.com)
Bidirectional Encoder Representation from Transformer
来自Transformer的双向编码器表征
基于上下文(context-based)的嵌入模型。
那么基于上下文(context-based)和上下文无关(context-free)的区别是什么呢?
- He got bit by
python. Pythonis my favorite programming language.
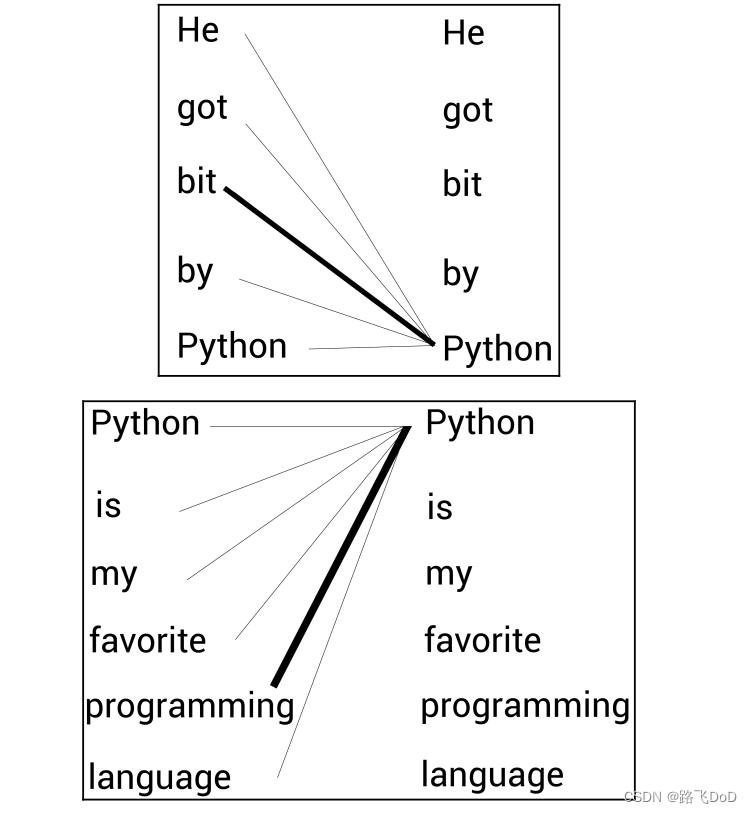
可以发现,同一个单词在不同句子的不同位置的含义可能是不同的,我们希望两个句子中的Python的词嵌入向量有不同的表征,那么就称是基于上下文(context-based)的。
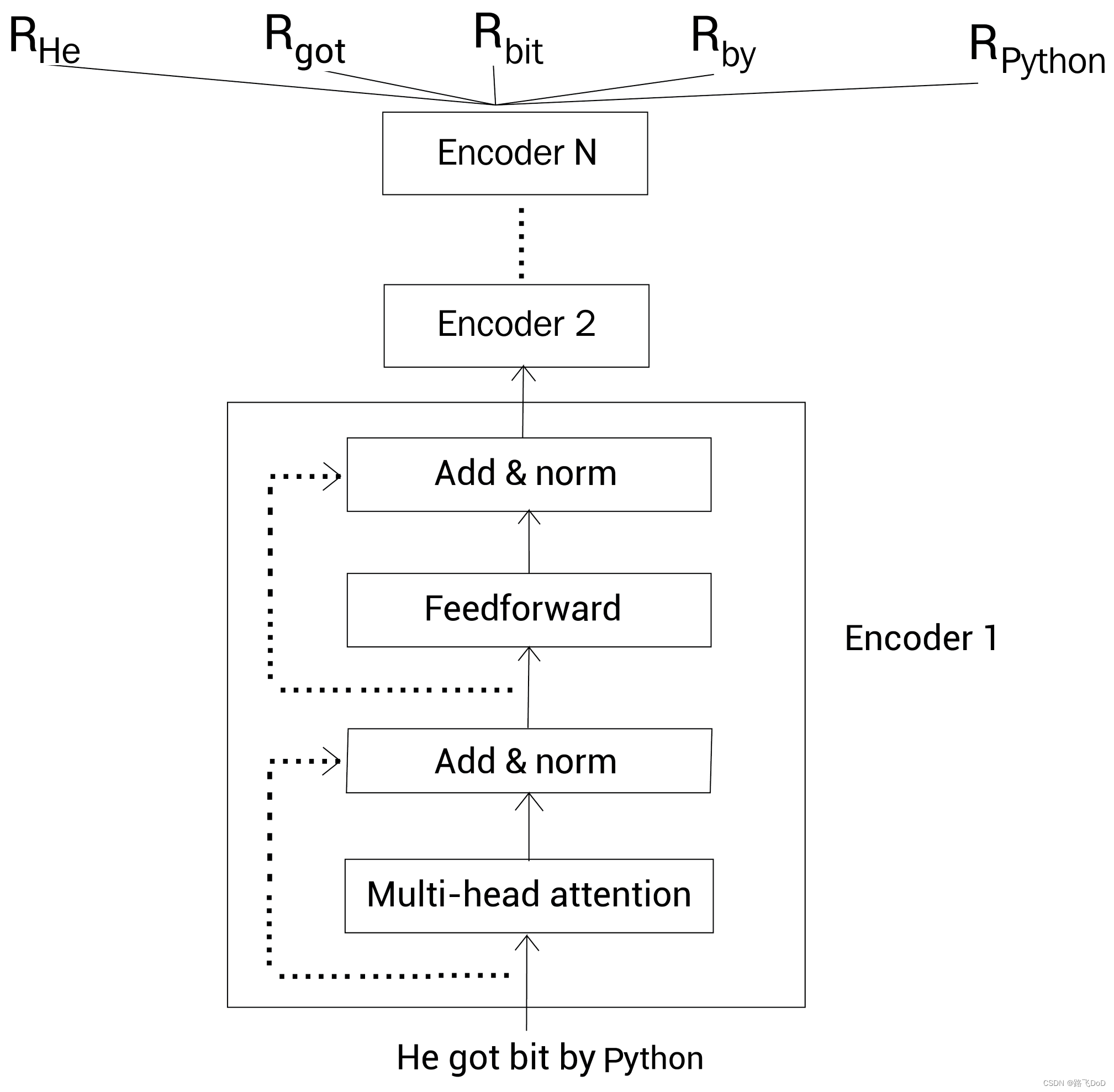
在Transformer的Encoder中,我们的输入是完整的序列,自注意力机制允许模型在处理每个位置的输入时,考虑到输入序列中的所有其他位置。这意味着,对于每个输入位置,模型都能够同时关注左侧和右侧的上下文,而不仅仅是单向的左侧或右侧。这种特性使得Transformer的编码器天然具有双向建模的能力。
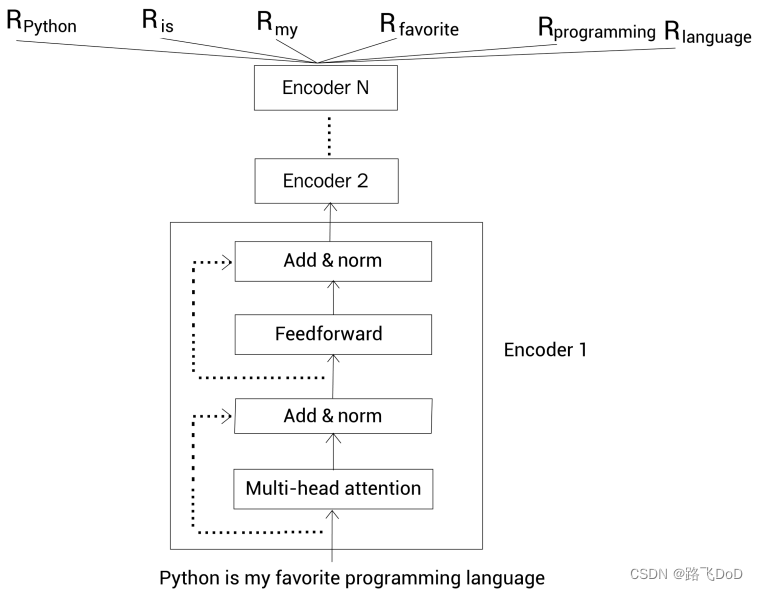
通过BERT,给定一个句子,我们就得到了句子中每个单词的上下文嵌入向量表示。
Model architecture
BERT的显著特点是在不同的下游任务中采用统一的架构。这意味着可以对同一个预训练模型进行微调,用于多种可能与模型训练时的任务不相似的最终任务,并能够达到接近SOTA的结果。
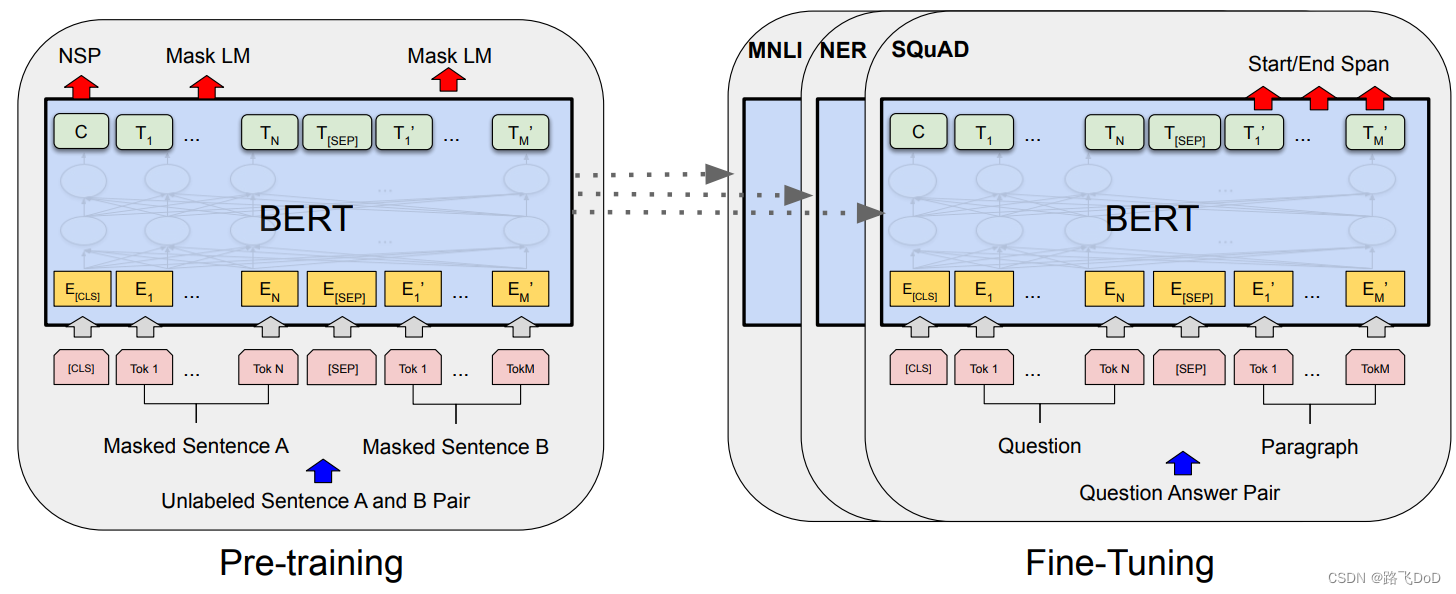
-
MNLI(Multi-Genre Natural Language Inference)
是一个大规模的、众包实现的蕴涵分类任务(Williams et al., 2018)。在这个任务中,给定一对句子,目标是预测第二个句子相对于第一个句子是蕴涵、矛盾还是中性的关系。任务的核心是判断两个句子之间的逻辑关系,即第一个句子是否蕴含了第二个句子,两个句子是否矛盾,或者它们之间是否没有明显的逻辑关系。这种任务通常用于评估模型在文本推断方面的性能,因为它涉及理解和推理句子之间的关系。
-
NER(Named Entity Recognition)
命名实体识别任务,涉及在文本中标注和识别具有特定类别(如人名、地名、组织名等)的实体。
-
SQuAD(Stanford Question Answering Dataset)
斯坦福问答数据集(SQuAD v1.1)是由10万个众包问答对(crowdsourced question/answer pairs)组成的集合(Rajpurkar等人,2016)。给定一个问题和包含答案的维基百科段落,任务是预测在段落中的答案文本跨度。在这个任务中,模型需要从给定的段落中找到与问题相匹配的答案文本,并输出答案的开始和结束位置。SQuAD数据集旨在评估问答系统的性能,要求模型能够理解问题并从相关文本中提取准确的答案。
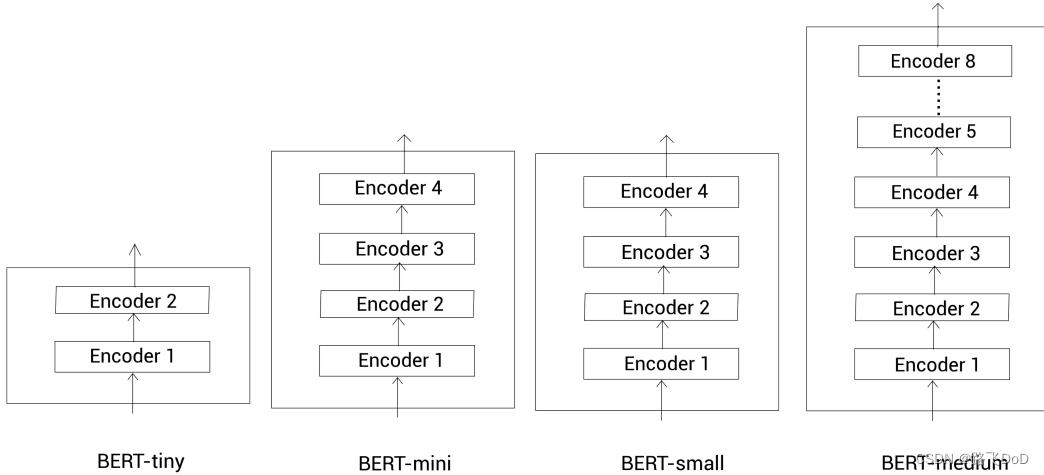
不同模型配置
L: Encoder数量;
A: 多头注意力数量;
H: 隐藏单元数。
BERT Base: L=12, H=768, A=12.
Total Parameters=110M!BERT Large: L=24, H=1024, A=16.
Total Parameters=340M!!
| L | H | |
|---|---|---|
| BERT-tiny | 2 | 128 |
| BERT-mini | 4 | 256 |
| BERT-small | 4 | 512 |
| BERT-medium | 8 | 512 |
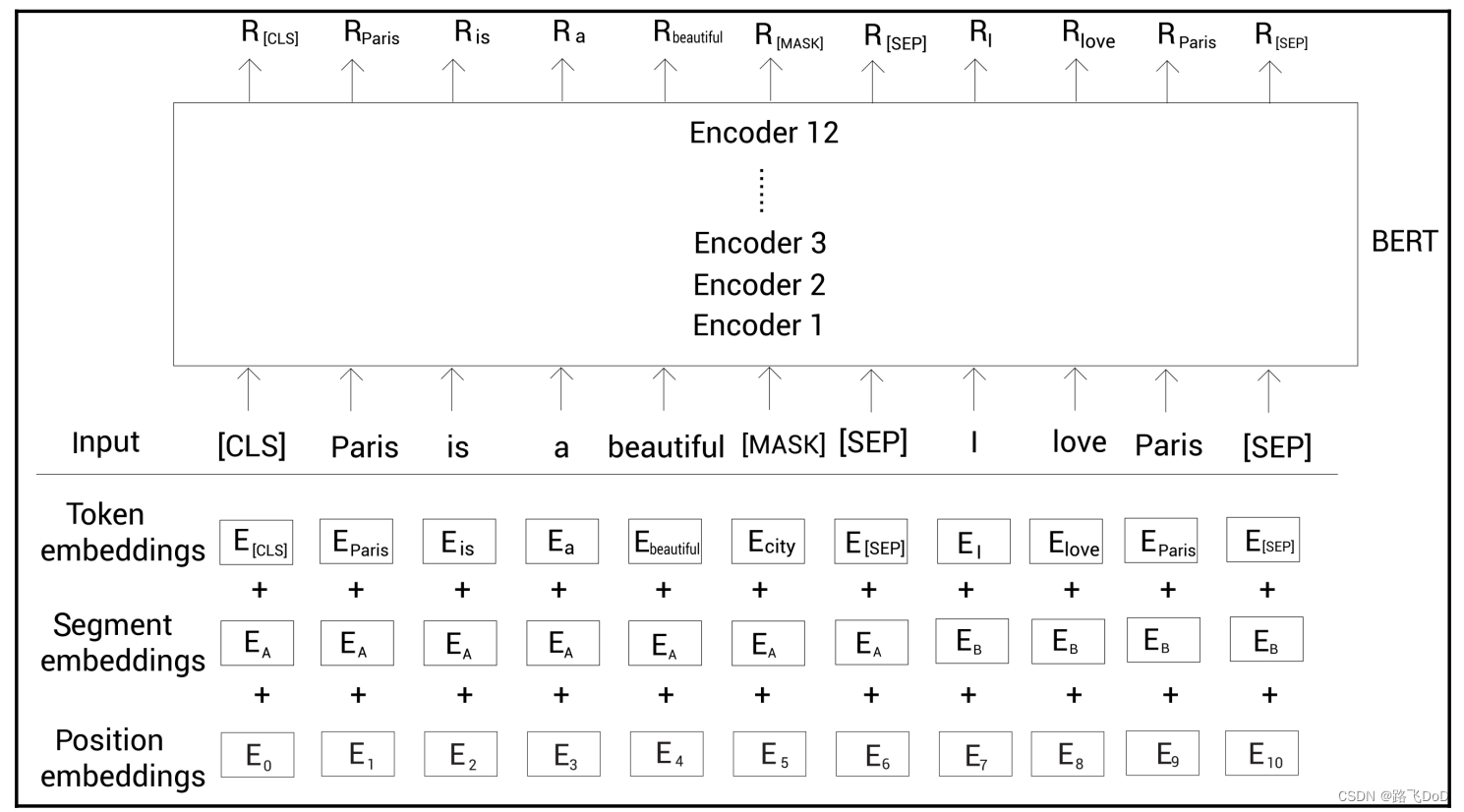
Input
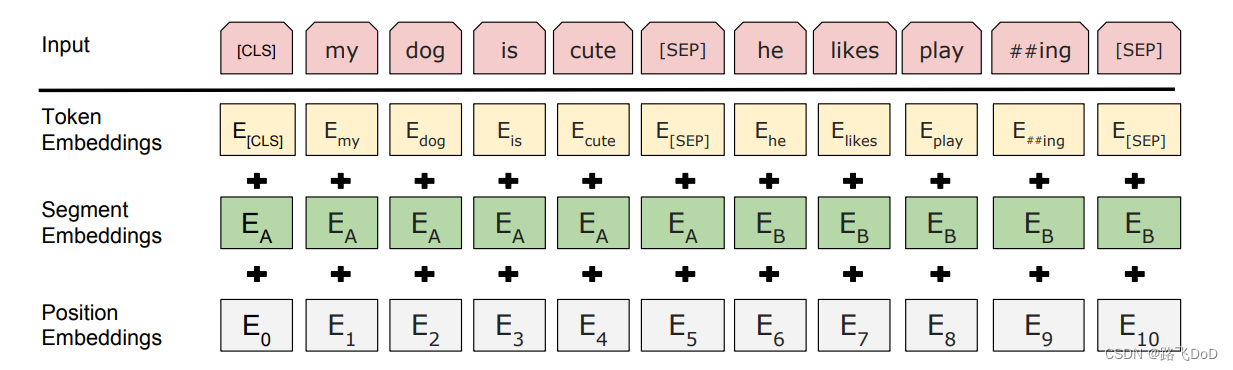
Token embedding——标记嵌入
标记嵌入是将文本中的每个单词或子词映射为实数向量的过程。在BERT中,采用了基于WordPiece的分词方式,将单词拆分成子词或子词块。

[CLS]–Classification
- [CLS] 标记位于每个输入序列的开头,表示“分类”或“汇总”标记。
[SEP]–Separator
- [SEP] 标记用于分隔两个句子,它在输入序列中标识两个独立的文本段。
Segment embedding——片段嵌入
片段嵌入是为了处理两个句子之间的关系。在涉及两个句子的输入情况下,为每个单词或子词分配一个片段标识符,以区分来自不同句子的信息。

Position embedding ——位置嵌入
位置嵌入是为了引入序列中的顺序信息,每个输入位置都会被分配一个表示其相对位置的向量。
位置嵌入通过使用预定义的位置编码(通常是固定的正弦和余弦函数)来表示输入序列中每个位置的信息。这些位置嵌入与对应的标记嵌入相加,以提供关于标记在序列中位置的信息。
位置嵌入的目标是帮助模型理解输入文本的顺序信息,这对于捕捉上下文和语境非常重要。

最终表示
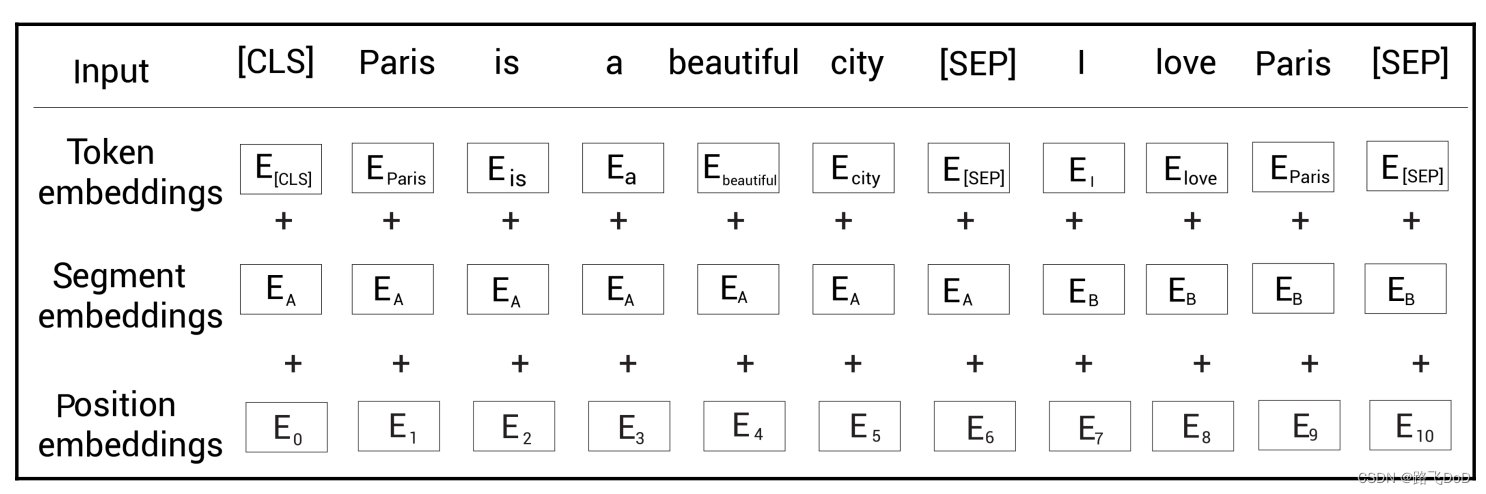
Pre-training
BERT模型的预训练基于两个任务:
- Masked LM
- Next Sentence Prediction(NSP)
语言建模划分如下:
- 自回归
- 在自回归语言模型中,模型的目标是预测序列中的下一个元素,给定其之前的元素。
- 单向的
- 自编码
- 自编码语言模型通过学习将输入数据重新生成为自身,强制模型通过中间表示(编码)来捕捉数据的重要特征。
- 双向的
Masked LM (MLM)
屏蔽语言建模:从输入文本中随机选择一些单词,并将它们屏蔽(用特殊的标记替代),然后让模型预测这些被屏蔽的单词。
In Autumn the ______ fall from the trees.
BERT规定,对于给定的输入序列,我们随机屏蔽15%的单词。
举个例子,假设我们屏蔽单词city,然后用[MASK]标记替换这个单词,结果为:
tokens = [ [CLS], Paris, is, a beautiful, [MASK], [SEP], I, love, Paris, [SEP] ]
然而,在大多数下游任务中,微调阶段通常不涉及对被屏蔽令牌的直接预测。这种差异可能导致预训练和微调之间的不一致性,因为在预训练过程中模型被要求执行一项任务,而在微调过程中模型需要适应不同的任务。
为了缓解这种不匹配问题,在训练中,大约有15%的单词被屏蔽,但并非所有被屏蔽的单词都被[MASK]标记替换。
BERT采用了微妙的屏蔽方式,对于这些15%的要屏蔽的单词,我们将会做下面的事情:
-
80%的概率,我们用
[MASK]标记替换该标记:tokens = [ [CLS], Paris, is, a beautiful, [MASK], [SEP], I, love, Paris, [SEP] ] -
10%的概率,我们用一个随机标记(单词)替换该标记:
随机标记引入了更多的噪声,增加模型的数据多样性、降低模型对具体标记的依赖性。
tokens = [ [CLS], Paris, is, a beautiful, love, [SEP], I, love, Paris, [SEP] ] -
剩下10%的概率,我们不做任何替换:
tokens = [ [CLS], Paris, is, a beautiful, city, [SEP], I, love, Paris, [SEP] ]\
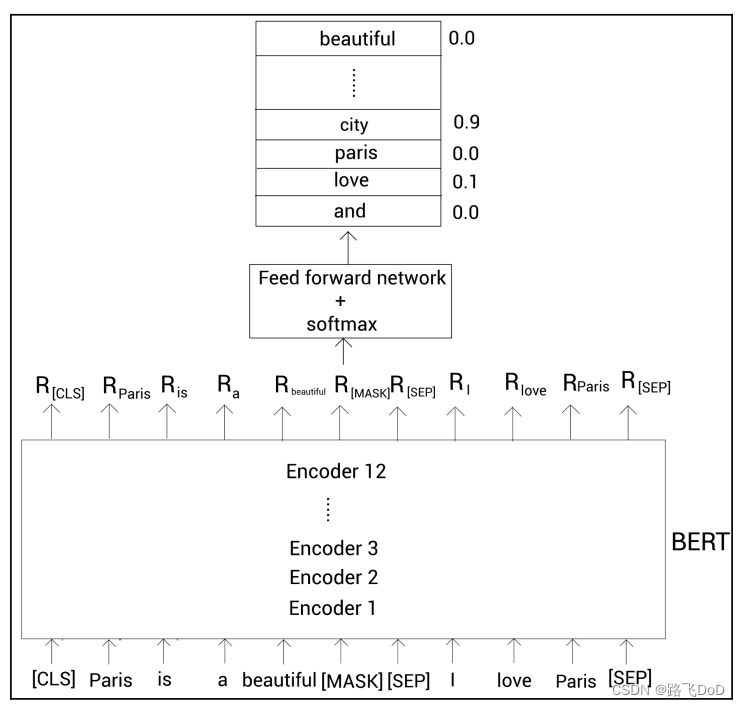
为了预测屏蔽的标记,我们将BERT返回的屏蔽的单词表示 R [MASK] R_{\text{[MASK]}} R[MASK] 喂给一个带有softmax激活函数的前馈神经网络。然后该网络输出词表中每个单词属于该屏蔽的单词的概率。
屏蔽语言建模也被称为**完形填空(cloze)**任务。我们已经知道了如何使用屏蔽语言建模任务训练BERT模型。而屏蔽输入标记时,我们也可以使用一个有点不同的方法,叫作全词屏蔽(whole word masking,WWM)。
全词屏蔽(WWM)
考虑句子Let us start pretraining the model。
1、在使用该分词器之后,我们得到下面的标记:
tokens = [let, us, start, pre, ##train, ##ing, the, model]
2、然后增加[CLS]和[SEP]标记:
tokens = [[CLS], let, us, start, pre, ##train, ##ing, the, model, [SEP]]
3、接着随机屏蔽15%的单词。假设屏蔽后的结果为:
tokens = [[CLS], [MASK], us, start, pre, [MASK], ##ing, the, model, [SEP]]
4、从上面可知,我们屏蔽了单词let和##train。其中##train是单词pretraining的一个子词。**在全词屏蔽模型中,如果子词被屏蔽了,然后我们屏蔽与该子词对应单词的所有子词。**因此,我们的标记变成了下面的样子:
tokens = [[CLS], [MASK], us, start, [MASK], [MASK], [MASK], the, model, [SEP]]
5、注意我们也需要保持我们的屏蔽概率为15%。所以,当屏蔽子词对应的所有单词后,如果超过了15%的屏蔽率,我们可以取消屏蔽其他单词。如下所示,我们取消屏蔽单词let来控制屏蔽率:
tokens = [[CLS], let, us, start, [MASK], [MASK], [MASK], the, model, [SEP]]
下一句预测(NSP)
在BERT的预训练中,语言模型(LM)并不直接捕捉两个句子之间的关系,而这在许多下游任务中是相关的,比如问答(QA)和自然语言推理(NLI)。为了教导模型理解句子之间的关系,BERT采用了二元分类的下一句预测(NSP)任务。
模型被要求判断两个输入句子是否在原始文本中是相邻的,即后一个句子是否是前一个句子的下一句。
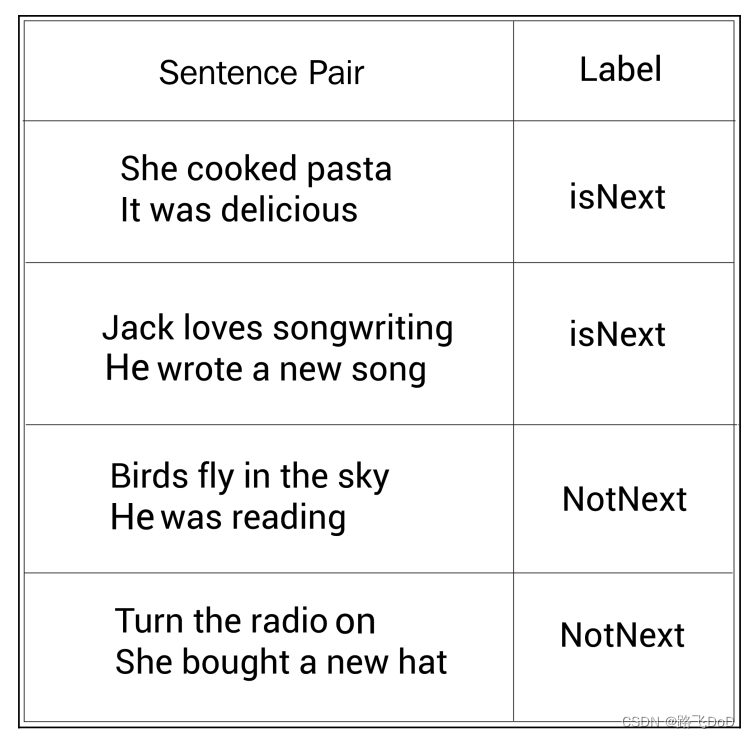
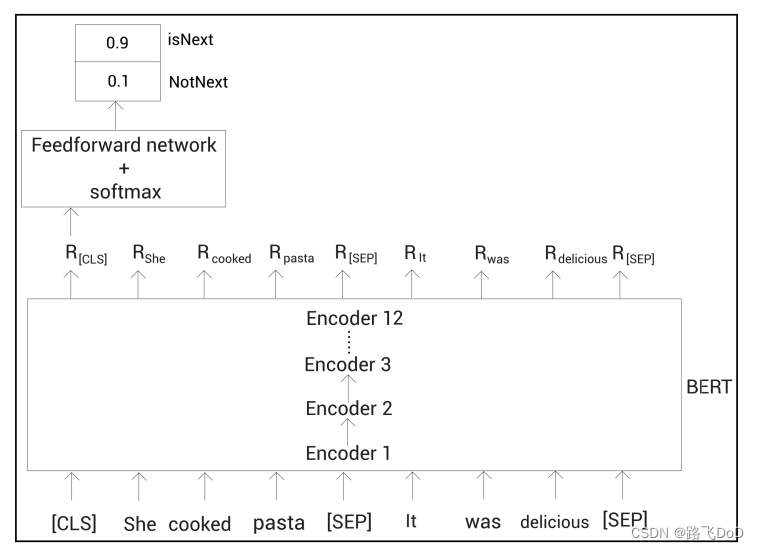
考虑下面两个句子:
Sentence A: She cooked pasta.
Sentence B: It was delicious.
这两个句子中, B B B就是 A A A的下一句,所以我们标记这对句子为isNext。
然后看另外两个句子:
Sentence A: Turn the radio on.
Sentence B: She bought a new hat.
显然 B B B不是 A A A的下一句,所以我们标记这个句子对为notNext。
在NSP任务中,我们模型的目标是预测句子对属于isNext还是notNext。
那么NSP任务有什么用?通过运行NSP任务,我们的模型可以理解两个句子之间的关系,这会有利于很多下游任务,像问答和文本生成。
如何训练?
对于isNext类别,我们从某篇文档中抽取任意相连的句子,然后将它们标记为isNext;对于notNext类别,我们从一篇文档中取一个句子,然后另一个句子随机的从所有文档中取,标记为notNext。同时我们需要保证数据集中50%的句子对属于isNext,剩下50%的句子对属于notNext。
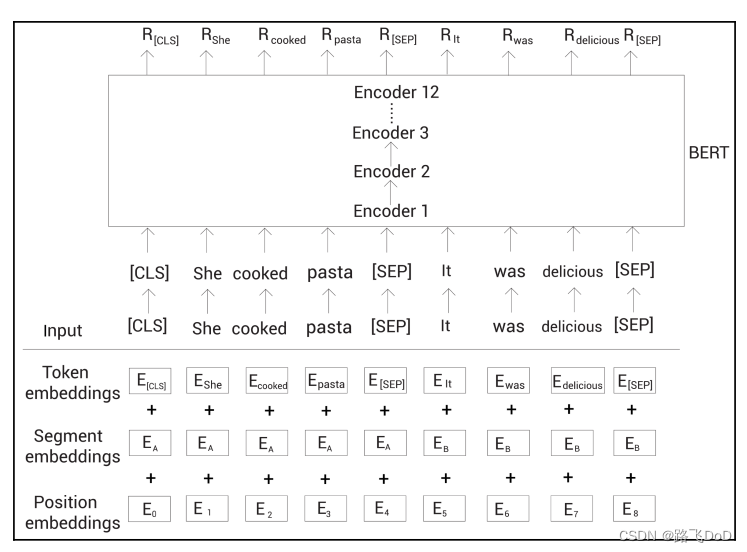
[CLS]标记保存了所有标记的聚合表示,将 R [ C L S ] R_{[CLS]} R[CLS]喂给一个带有softmax函数的全连接网络,返回我们输入的句子对对应isNext和notNext的概率。
ouput
-
pooler output
in: [CLS]
用于分类/回归任务
-
sequence output
序列任务
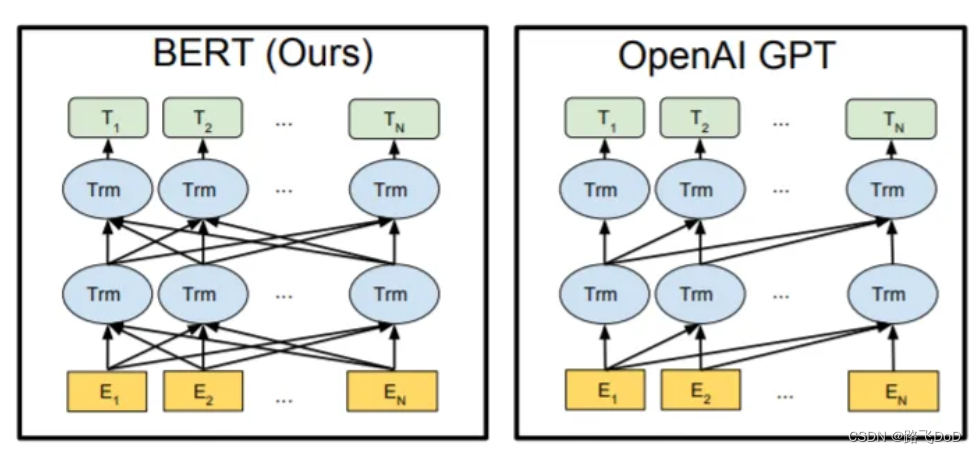
GPT — 远房表亲
- BERT:双向 预训练语言模型 + fine-tuning(微调)
- GPT:自回归 预训练语言模型 + Prompting(指示/提示)
如前所述,BERT 将 Transformer 的编码器部分堆叠为其构建块。同时,GPT 使用 Transformer 的解码器部分作为其构建块。