从ChatGPT到Sora,来了解大模型训练中的存储
1 从chatGPT到Sora
2022年底,OpenAI推出人工智能聊天机器人ChatGPT,开启了大模型领域的“竞速跑”模式。2024年2月15日,随着视频生成模型Sora的横空出世,OpenAI再度掀起热潮。

Sora将视频生成内容拉到了一个全新的高度,逼真的视频效果刷新了社会对AI能力边界的认知。它的问世,就如同一枚深水炸弹,瞬间引爆全球科技圈。
不少业内人士直言,Sora的到来标志着一次质的飞跃。英国皇家工程院国际院士、欧洲科学院院士许彬(Pan Hui)在接受《每日经济新闻》记者采访时表示,“目前Sora在视频生成品质上面绝对是无可匹敌的。Sora生成的视频可以从小特写切大全景,变换不同的机位。”
2 大模型训练中的存储
清华大学舒继武团队分析了大模型训练的存储挑战,指出大模型训练的存储需求大,且具有独特的计算模式、访存模式、数据特征,这使得针对互联网、大数据等应用的传统存储技术在处理大模型训练任务时效率低下,且容错开销大;分别阐述了针对大模型训练的3类存储加速技术与2类存储容错技术;并进行了总结和展望。
2.1 大模型训练的存储挑战
大模型训练的存储容量需求高. 大模型不仅参数量庞大,在训练的每一步中还需要保存前向传播过程中产生的激活量和用于参数更新的优化器。
首先是模型参数(model parameters),大规模深度学习模型的参数量爆炸式增长,且这种趋
势仍在持续。
其次是激活(activation)量,根据反向传播算法,前向传播阶段产生的激活量需要被先保存,然后在反向传播时用于计算梯度信息,最后在梯度计算结束后被释放. 在大模型训练过程中,激活量所占的存储空间庞大. 根据研究发现,激活量在训练过程中的存储开销占总存储开销的 70%。
最后是优化器(optimizer)。 计算得到的梯度被传输到优化器中以更新得到新版本的模型参数。
此外,大模型训练过程中的容错需求高. 大模型训练会使用大量 GPU,这提高了故障的可能性。
传统支持大规模数据存储系统一方面未充分利用大模型训练中的计算模式、访存模式和数据特征,另一方面不适用于大模型数据更新数据量大、更新频繁的特点,严重影响大模型训练的效率:
1)传统的分布式存储技术不适用于大模型训练的计算模式:一方面,大模型训练常使用的 GPU具有计算资源和存储资源强耦合的特点,需要考虑计算任务与存储之间的依赖关系;另一方面,传统的分布式存储技术未利用大模型训练中各个任务间的数据依赖关系进行优化,可能导致相邻任务间的数据传输方案非最优。
2)传统的异构存储技术对大模型训练中的访存模式不感知,未利用这些访存模式设计数据的预取和传输策略,因而无法达到训练的最佳性能。
3)传统的存储缩减技术不适用于大模型训练中的数据特征,大模型数据稠密度高,难以通过传统的压缩方法缓解存储压力。
4)传统的存储容错技术在大模型训练场景下容错开销大,大模型训练中的数据量庞大,并且数据更新频繁。
2.2 向大模型的存储加速技术
在存储性能方面,现有工作提出了针对大模训练的存储加速技术. 这些技术可以总结为 3 类:基
于大模型计算模式的分布式显存管理技术、大模型训练访存感知的异构存储技术和大模型数据缩减技术。
2.2.1 基于大模型计算模式的分布式显存管理技术
大模型训练中的计算模式可以分为层间并行和层内并行。这 2 种计算模式对应不同的任务划分方式和任务依赖关系. 其中,层间并行以张量为粒度将模型划分到多张 GPU 上,单个计算任务仅依赖于负责计算相邻张量的任务;层内并行则是以张量的某一维度为粒度,将单个张量的计算拆分到多张 GPU 上,单个计算任务依赖于多个负责计算相邻张量分片的任务。
(1)基于模型层间并行的分布式显存管理技术
模型层间分片方式是以张量为粒度,将模型数据划分成多个小片,并分布式地存储到多张 GPU 中,此类工作在训练过程中传输的数据类型可以分为2 类:模型数据和激活量. 在传输模型数据的工作中,每张 GPU 负责所有模型分片的训练;在训练前,所需的模型数据被传输到负责计算的 GPU 显存中;训练结束后,GPU 将释放不由此 GPU 存储的模型分片所占的显存空间. 在传输激活量的工作中,每张 GPU 仅负责训练显存中存储的模型分片,并传输相邻分片的激活量。
ZeRO-DP是微软提出的大模型训练系统,它采用数据并行的方式对模型进行训练. 为满足模型训练过程中对存储空间的需求,ZeRO-DP 采用层间分片的方式存储模型,并训练过程中采用在 GPU 间传输模型数据的方案。
GPipe是谷歌提出的基于流水线并行的模型训练框架. 它首先使用一个样本中所有子样本进行前向传播,接着对所有子样本进行反向传播,最后根据此样本训练得到的梯度进行参数更新. 由于前向传播和反向传播的顺序不同,并且需要在使用一个样本完成训练后暂停模型训练以对参数进行更新,GPipe 产生了较多的计算空闲时间(即气泡)。
PipeDream是英伟达公司提出的基于流水线并行的模型训练模式,它在流水线中将前向传播和反向传播交替进行(1 forward 1 backward,1F1B),解决了 GPipe 中的气泡问题. 在 PipeDream 中,某一子样本完成前向传播传播后会立即开始此子样本的反向传播. 当 PipeDream 启动并稳定后,流水线中将不存在气泡。但是, PipeDream 中需要存放多个版本的参数,增加了额外的存储开销。
(2)基于模型层内并行的分布式显存管理技术
张量并行采用模型层内分片的策略,该策略以张量的某一维度为粒度对模型进行切分,并将切分
得到的分片存储在多张 GPU 中. 相比于模型的层间分片以层为粒度存储数据,模型的层内分片将某一层的数据以更细的粒度拆分. 因此,模型的层内分片可将单层的数据存储到更多 GPU 中,从而支持单层数据量更大的模型。
根据是否切分输入的张量和张量存放的方式,张量并行分为 4 种不同的模式. 其中每种张量并行的存储开销和通信开销的对比如表所示。
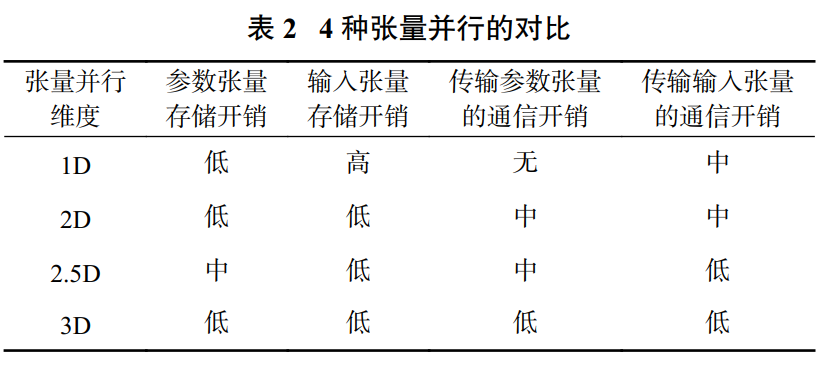
Megatron是由英伟达公司提出的一种基于Transformer 结构的大模型训练框架,它使用了 1D 张量并行策略。
2.2.2 大模型训练访存感知的异构存储技术
若仅使用 GPU 显存存储模型数据,需要更大规模的 GPU 集群以满足更大规模模型训练时的存储需求。
除 GPU 显存外,训练服务器中包含有各种异构的存储资源,如 DRAM 和 SSD。 模型参数、优化器数据和训练产生的中间结果可以被存储到这些异构存储资源中,以提高模型训练的规模。
但是,异构存储系统的数据移动开销高. 虽然GPU 内的存储资源的读写带宽高,以匹配其计算资源的性能,但与外部存储资源之间的互联带宽低. 这导致数据在 GPU 与外部设备间的搬移开销大。
现有工作利用大模型训练中访存模式可预测的特性,减少使用异构存储介质带来的数据移动开销.在指定样本批大小等其他模型训练的超参数后,大模型训练中的每一个操作的计算开销和存储开销的变化相对固定. 并且大模型的模型结构固定,这使得每一个计算操作的顺序也随之固定. 因此,根据训练第一个样本批时获得的每个操作的访存时刻和访存大小信息,可以预测后续模型训练过程中的访存模式。
(1)基于 DRAM 的异构存储技术
相比于 GPU 显存,DRAM 的容量更大,因此,可以将模型数据或者训练的中间结果卸载到 DRAM 中,并在计算前按需将卸载数据上传到 GPU 显存之中,以支持更大规模的模型训练。
vDNN是首个提出使用 DRAM 扩充显存以支持更大规模模型训练的工作。
SwapAdvisor 从张量的角度对 DNN 模型中计算和存储进行建模,以支持模型训练中各种不同类型的模型数据的卸载;并采用遗传算法搜索卸载和预取的近似最优方案。
ZeRO-Offload[30] 是首个利用异构存储方案的分布式训练框架. ZeRO-Offload 采用与 ZeRO-DP 类似的训练流程,但是将模型数据和参数更新的过程卸载到 DRAM 和 CPU 中。
Mobius是清华大学于 2023 年提出的基于消费级 GPU 服务器的大模型训练系统。Mobius提出了基于流水线并行的异构存储训练策略。
(2)基于 SSD 的异构存储技术
随着模型规模的增长,模型数据量和中间结果到达了 TB 量级. 现有工作尝试将模型数据和中间变量卸载到 SSD 以支持更大规模的模型的训练. 相较于 DRAM,SSD 的容量更大、价格与能耗更低,可以支持更大规模的模型训练,但 SSD 的读写带宽低,给模型训练带来了新的挑战。
FlashNeuron将模型参数卸载到 SSD 中. 为最小化卸载带来的开销,FlashNeuron 设计了离线的卸载选择策略,并提出了 GPU 直访 SSD 的数据传输方案。
ZeRO-Infinity将模型数据存储在 SSD 中,它沿用了 ZeRO 训练模式,同时也是使用了 ZeRO-Offload中的 CPU 更新参数的策略。
2.2.3 大模型数据缩减技术
传统的数据缩减技术往往通过压缩的方式减少存储开销, 但是大模型的数据稠密[难以被压缩。
现有工作根据大模型数据特征,从 2 方面对大模型训练中的数据进行缩减:增加计算量和牺牲模型精度. 具体地,激活量检查点与重算算法(checkpoint andrecomputation)通过增加计算量减少了所需存储的激活量数据;混合精度与量化通过牺牲模型精度以减低模型数据和中间变量的大小。
3.4 总结
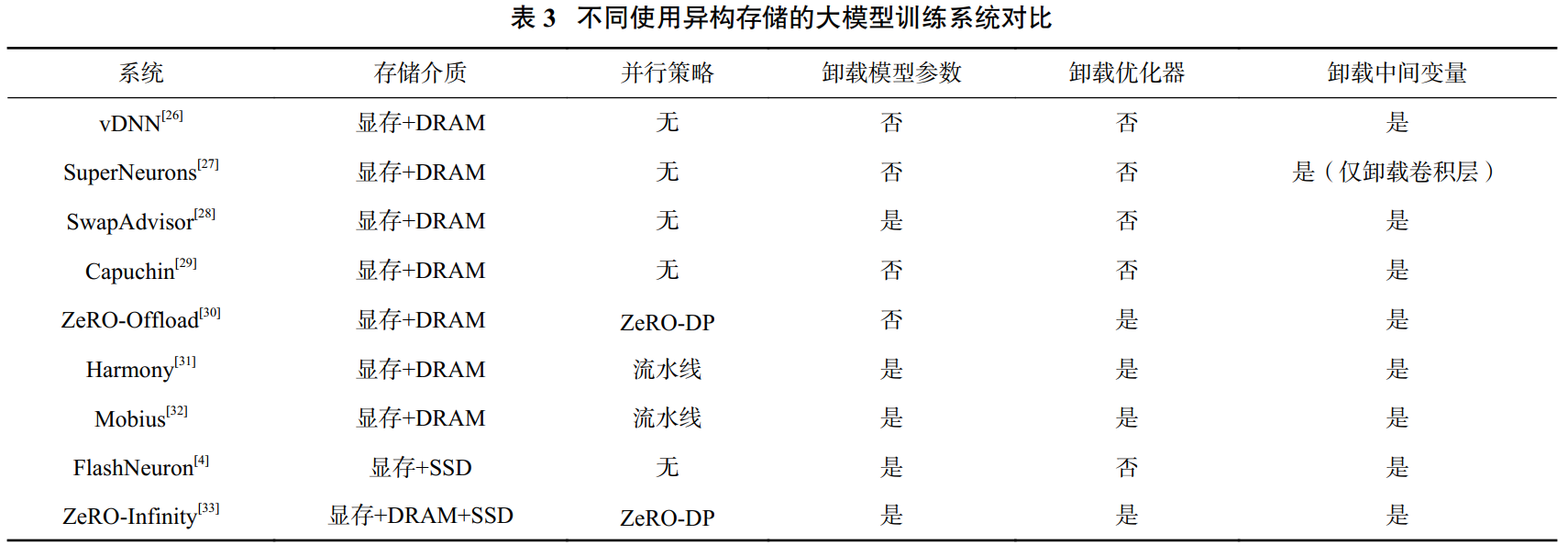
下表所示的各类存储技术在单步训练中所需的存显存容量、通信开销以及引入的额外计算开销各有差异。

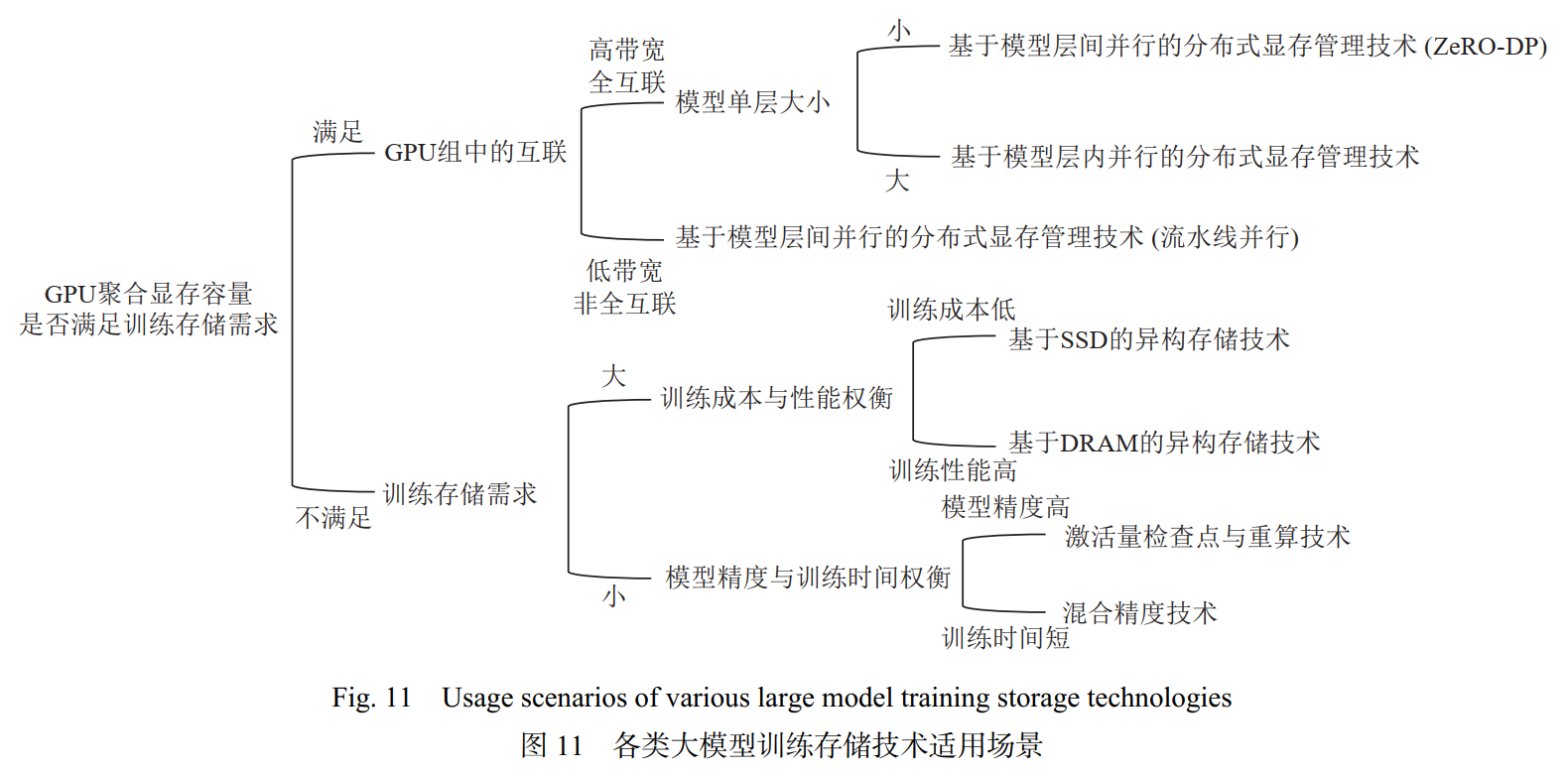
下图展示了根据算法性能需求和所用硬件条件选择最合适的存储技术的流程. 在实际训练过程中,可能会混合采用多种不同的存储技术. 例如,在GPU集群中,通过高带宽的NVLink互联的GPU组使用基于层内并行的分布式显存管理技术;通过带宽较低的PCIe互联的GPU组使用流水线并行的方式。
2.3 面向大模型的存储容错技术
GPU 故障数量随着 GPU 集群规模的增大而提高. GPU 的频繁故障一方面会导致训练得到的参数丢失;另一方由于大模型训练中各 GPU 间的数据存在依赖关系,单 GPU 的故障会扩散到整个 GPU 集群中. 有 2 类主要的工作解决大模型训练故障的问题:参数检查点和冗余计算. 本节将具体介绍这 2 类不同的大模型训练容错技术。
(1)参数检查点
参数检查点技术以设定的频率将训练得到的参数信息存储到持久化的存储介质中,以对 GPU 故障进行容错. 在 GPU 故障后,参数检查点技术利用最新且完整的参数进行恢复。
(2)冗余计算
参数检查点技术需要大容量的持久化存储设备以保存检查点信息. 并且在恢复阶段,参数检查点需要从持久化介质中读取之前版本的参数,这导致恢复开销高. 有工作利用冗余计算的方式,在多张 GPU 中重复计算相同版本的参数,以对模型训练数据容错。
2.4 亟需解决的问题
随着模型规模的急剧增加和硬件设备的发展,大模型训练中仍存在着一些存储问题亟需解决:
大模型训练的存储成本. 一方面,为充分利用硬件的计算资源,训练需要使用读写带宽更高的存储介质,如HBM. 而这些存储介质的单位比特的价格高昂. 另一方面,随着模型规模的不断攀升,训练所需的存储空间也随之增长,因此需要更大容量的存储介质,这增加了训练过程中用于存储设备的成本.
大模型训练的绿色存储. 大模型训练能耗大,导致大量碳排放,从而影响全球环境. 从存储角度谈,大模型训练需要使用数量庞大的高带宽存储介质满足大模型训练中的存储需求,这些存储介质相较于读写带宽较低的SSD和HDD能耗高. 并且大模型训练中数据读写频繁,进一步提高了存储能耗。
3 未来
在智算时代下,大模型带来了巨大的挑战和机会,需要更大的数据量级和存储计算的能力,可以预见在未来几年,存储计算技术会不断提升。比如:
(1)多级存储加速技术;
(2)数据编排加速技术;
(3)存算一体技术;
(4)近数据计算技术;
(5)存内计算技术;
……
4 参考资料
[01] https://baijiahao.baidu.com/s?id=1791661612117319817
[02] 冯杨洋, 汪庆, 谢旻晖, 舒继武. 从BERT到ChatGPT:大模型训练中的存储挑战与技术发展[J]. 计算机研究与发展. DOI: 10.7544/issn1000-1239.202330554
[03] https://www.bilibili.com/read/cv26765514/
[04]《金融AI存力报告:大模型时代金融行业如何破解先进存力之困?》