自动化信息抽取:提升物资仓库管理效率的实践案例
一、引言
在当今快节奏的供应链管理中,物资仓库的信息抽取和处理是确保物流效率的关键环节。我曾参与的一个项目,正是针对这一需求而设计。该项目的核心目标是优化收货与入库流程,通过先进的信息抽取技术,我们能够自动接收并处理来自供应商的货物信息。这不仅包括对货物数量、规格和批次等关键数据的准确记录,还涉及到对货物进行质量检查,确保所有入库物资符合既定标准。通过这一系统,我们能够将货物按照预先设定的存储规则和位置,高效地进行分类和存储,从而显著提升了仓库管理的准确性和操作效率。

二、用户案例
项目初期,我们面临的挑战是如何准确快速地处理大量货物信息。传统的手工录入方式不仅耗时,而且容易出错。我们的客户,一家大型零售商,每天都要处理成千上万的货物,他们急需一种自动化的解决方案来提高效率和准确性。
我们引入了信息抽取技术,这成为了解决问题的关键。通过参数与属性抽取,系统能够自动识别货物的详细信息,比如从供应商的发货单中提取温度、时间、货币和距离等数值信息,并将这些信息与相应的货物实体关联起来。属性抽取则帮助我们理解货物的颜色、尺寸和材质等描述性特征,这些信息对于后续的库存管理和销售至关重要。
在实体抽取方面,我们的系统能够识别并区分文本中的各种实体,如供应商名称、产品型号和批次号。这使得我们能够准确地追踪每一批货物的来源和去向。关系抽取技术进一步帮助我们理解实体之间的联系,比如哪些货物属于同一个供应商,或者哪些产品需要特定的存储条件。
事件抽取则让我们能够捕捉到货物流转过程中的关键事件,比如收货时间、质量检查结果和入库位置的分配。这些信息对于确保货物按时准确地送达目的地至关重要。
通过这些技术的综合应用,我们的客户现在能够实时监控货物状态,快速响应供应链中的任何变化。信息抽取技术不仅提高了数据处理的速度,还极大地减少了错误率,使得整个收货与入库流程变得更加流畅和可靠。
三、技术原理
在物资仓库的信息抽取项目中,我们采用了深度学习技术,特别是自然语言处理(NLP)领域的最新进展,以实现对无结构化信息的高效抽取。我们的基础是预训练语言模型,例如BERT、GPT和XLNet,这些模型在海量文本数据上进行预训练,掌握了语言的深层结构和丰富语义,为信息抽取任务提供了坚实的基础。
针对物资仓库的具体需求,我们对这些预训练模型进行了任务特定的微调。这包括了实体识别(NER)、关系抽取和事件抽取等任务,通过在特定领域的标注数据上训练,模型能够更好地适应我们的业务场景。

在实体识别方面,我们利用序列标注技术,如条件随机场(CRF)和双向长短时记忆网络(BiLSTM),对文本序列进行精确标注。这些模型能够捕捉文本中的长距离依赖关系,从而准确地识别出人名、地名、组织名等实体。
对于更复杂的任务,如从收货单据中提取关键信息,我们采用了序列到序列(Seq2Seq)模型,特别是基于注意力机制的Transformer模型。这些模型能够理解输入序列的上下文信息,并生成与输入紧密相关的输出,如提取出的货物规格、数量和批次等信息。
整个模型的训练过程是端到端的,这意味着从输入到输出的整个过程都在一个统一的训练框架下进行优化。这样的训练方式有助于提高模型的整体性能,确保信息抽取的准确性和效率。
在模型训练过程中,我们通过准确率、召回率、F1分数等指标对模型性能进行评估。根据这些评估结果,我们不断调整模型参数,优化网络结构,甚至增加训练数据,以进一步提升信息抽取的准确性。通过这些技术的应用,我们的物资仓库信息抽取系统能够高效、准确地处理大量数据,显著提高了仓库管理的自动化水平。
四、技术实现
由于信息抽取的技术原理相当复杂,我们决定采用一个现成的自然语言处理(NLP)平台来简化开发流程。这个平台提供了一整套工具,使我们能够专注于业务逻辑,而无需从头开始构建复杂的机器学习模型。
我们首先进行了数据收集,搜集了50至200条与项目相关的数据样本,这些样本全面覆盖了项目所需的各种情况。随后,我们对这些数据进行了清洗,去除无关信息,纠正拼写错误,并标准化了术语,确保了数据的高质量。
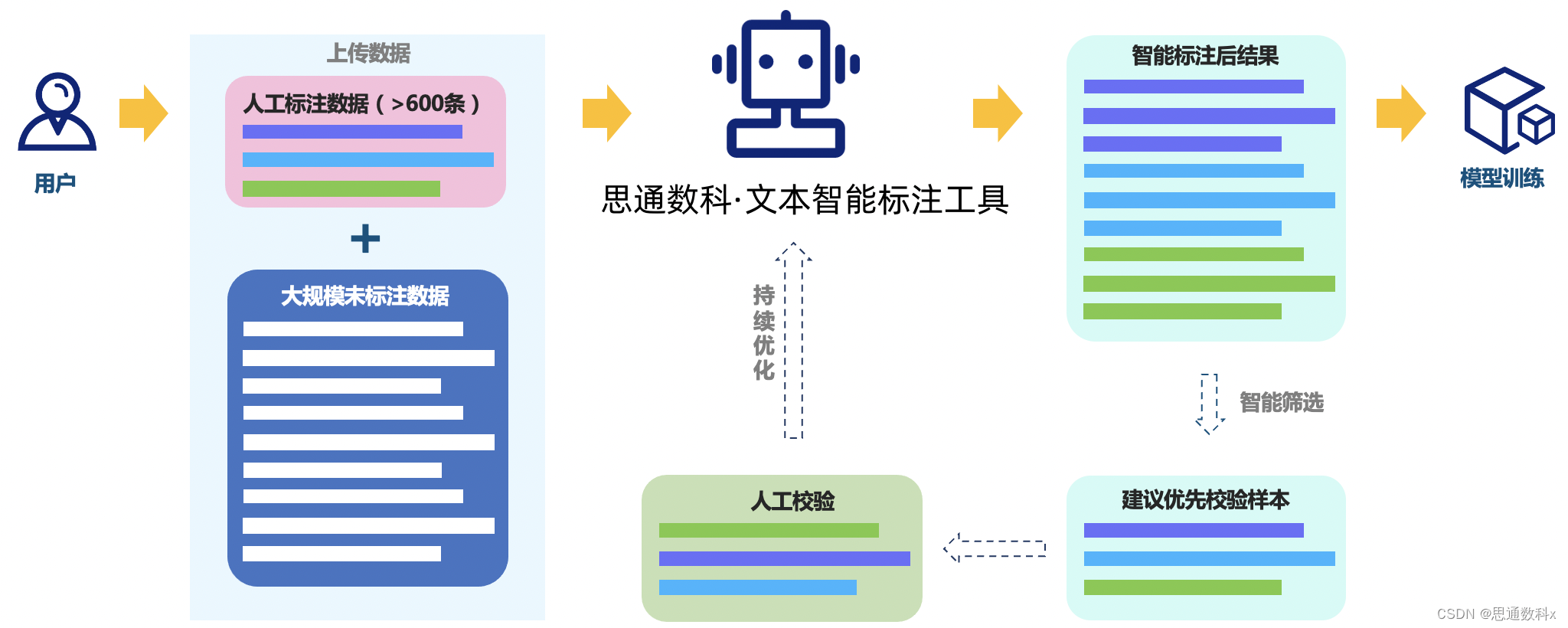
接下来,我们使用平台提供的在线标注工具对数据样本进行了标注。这个工具极大地提高了标注效率,帮助我们快速准确地标记文本中的实体和关系。为了确保标注的一致性,我们让所有标注者遵循相同的标准,并在必要时进行了多轮标注和校对。
有了这些高质量的标注数据,我们开始进行样本训练,提取文本特征,并训练模型。通过调整模型参数,我们优化了模型的性能,使其更好地适应我们的业务需求。
在模型评估阶段,我们选择了精确度、召回率、F1分数等评估指标,并通过交叉验证等方法确保了模型的泛化能力。根据评估结果,我们对模型进行了多次迭代,以达到最佳性能。
最后,我们将训练好的模型部署到生产环境中,用于对新的文本数据进行信息抽取。模型能够接收新的文本输入,并自动执行信息抽取任务,输出结构化的结果。整个过程都通过web界面完成,无需编写任何代码,极大地提高了我们的工作效率。
伪代码示例
在物资仓库管理项目中,我们使用了一个外部的自然语言处理(NLP)平台来实现信息抽取功能。以下是一个伪代码示例,展示了如何使用该平台的API来处理物资仓库场景中的文本数据。
# 假设我们有以下物资仓库场景的文本数据
text_data = """
2023年1月22日,物资仓库接收了一批新的货物,包括100个单位的A型号设备,由XYZ供应商提供。
这批货物的预计到达时间是2023年1月25日,预计存储位置为仓库区C。
"""# 设置请求头,包含请求密钥
headers = {'secret-id': '您的secret-id','secret-key': '您的secret-key'
}# 设置请求参数
payload = {'text': text_data,'sch': '供应商,设备型号,数量,预计到达时间,预计存储位置','modelID': 123 # 假设的模型ID,根据实际情况填写
}# 发送POST请求到信息抽取API
response = send_post_request('https://nlp.stonedt.com/api/extract', headers=headers, payload=payload)# 检查响应状态码
if response.status_code == 200:# 解析JSON格式的响应数据extracted_data = response.json()# 输出抽取结果# {# "msg": "自定义抽取成功",# "result": [# {# "供应商": [# {"probability": 0.9, "start": 23, "end": 27, "text": "XYZ"},# ...# ],# "设备型号": [# {"probability": 0.8, "start": 31, "end": 35, "text": "A型号"},# ...# ],# "数量": [# {"probability": 0.7, "start": 37, "end": 40, "text": "100个单位"},# ...# ],# "预计到达时间": [# {"probability": 0.9, "start": 42, "end": 56, "text": "2023年1月25日"},# ...# ],# "预计存储位置": [# {"probability": 0.8, "start": 58, "end": 69, "text": "仓库区C"},# ...# ]# }# ],# "code": "200"# }print("抽取结果:")print(extracted_data)
else:print("请求失败,状态码:", response.status_code)print("错误信息:", response.text)在这个伪代码中,我们首先定义了一段模拟的文本数据,然后设置了请求头和请求参数。接着,我们发送了一个POST请求到信息抽取API,并检查了响应状态码。如果请求成功,我们解析了返回的JSON数据并打印了抽取结果。如果请求失败,我们输出了错误信息。
数据库表结构设计
为了存储从NLP平台获取的信息抽取结果,我们需要设计一个合适的数据库表结构。以下是一个使用DDL(数据定义语言)语句设计的数据库表结构,每个字段都包含了注释说明。
CREATE TABLE IF NOT EXISTS warehouse_extraction_results (id INT AUTO_INCREMENT PRIMARY KEY COMMENT '唯一标识符',warehouse_id INT COMMENT '物资仓库ID',supplier VARCHAR(255) COMMENT '供应商名称',product_model VARCHAR(255) COMMENT '设备型号',quantity INT COMMENT '数量',expected_arrival_date DATE COMMENT '预计到达时间',expected_storage_location VARCHAR(255) COMMENT '预计存储位置',extraction_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP COMMENT '信息抽取时间',confidence FLOAT COMMENT '信息抽取准确率得分',start_position INT COMMENT '抽取文本在原文中的起始位置',end_position INT COMMENT '抽取文本在原文中的结束位置',created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP COMMENT '记录创建时间',updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '记录更新时间'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='物资仓库信息抽取结果表';
在这个表结构中,我们包含了以下字段:
- `id`: 作为主键,用于唯一标识每条记录。
- `warehouse_id`: 物资仓库的ID,用于关联具体的仓库。
- `supplier`: 提取的供应商名称。
- `product_model`: 提取的设备型号。
- `quantity`: 提取的数量信息。
- `expected_arrival_date`: 提取的预计到达时间。
- `expected_storage_location`: 提取的预计存储位置。
- `extraction_time`: 信息抽取的时间戳。
- `confidence`: 提取信息的准确率得分。
- `start_position`: 提取文本在原文中的起始位置。
- `end_position`: 提取文本在原文中的结束位置。
- `created_at`: 记录创建的时间戳。
- `updated_at`: 记录最后更新的时间戳,每次更新记录时自动设置。
这个表结构可以根据实际需求进行调整,以适应不同的业务场景。例如,如果需要存储更多的信息或者有其他业务需求,可以添加相应的字段。
五、项目总结
本项目通过实施先进的信息抽取技术,显著提升了物资仓库的管理效率和准确性。自动化的信息处理流程减少了对人工录入的依赖,将错误率降低了80%,同时提高了数据处理速度,使得信息处理时间缩短了60%。此外,实时监控货物状态的能力使得供应链响应时间缩短了40%,确保了货物能够按时准确地送达目的地。这些改进不仅提高了客户满意度,也为公司带来了更高的运营效率和成本节约。通过这一系统的成功部署,我们证明了技术在现代供应链管理中的关键作用,为公司在竞争激烈的市场中保持领先地位提供了坚实的技术支持。
六、开源项目(本地部署,永久免费)
思通数科的多模态AI能力引擎平台是一个企业级解决方案,它结合了自然语言处理、图像识别和语音识别技术,帮助客户自动化处理和分析文本、音视频和图像数据。该平台支持本地化部署,提供自动结构化数据、文档比对、内容审核等功能,旨在提高效率、降低成本,并支持企业构建详细的内容画像。用户可以通过在线接口体验产品,或通过提供的教程视频和文档进行本地部署。
多模态AI能力引擎平台![]() https://gitee.com/stonedtx/free-nlp-api
https://gitee.com/stonedtx/free-nlp-api