取出url中的字符_python爬虫,解决大众点评字符库反爬机制的经验
刚开始写文章还希望大家可以喜欢,对于爬虫只是个人整理出的方法,爬虫大牛请嘴下留情。“”仅限学术交流,如有冒犯请联系作者删除“”话不多说,想分析天津地区餐饮行业的大致情况,要爬出(商铺名称,星级,评价条数,人均消费金额,菜系,商圈,团购活动等)。
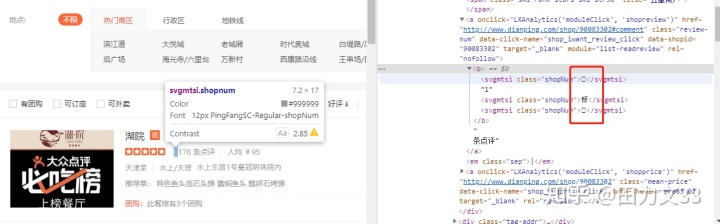
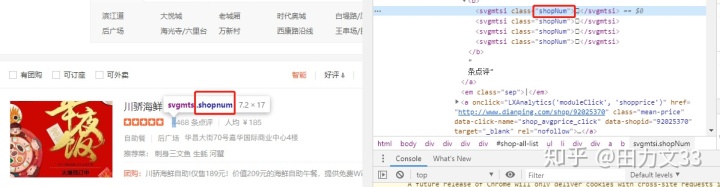
可是在爬虫时发现,这些数字都是以这类方框形式展示,再看源代码,以&#xXXXX这种形式展示,这是反爬机制中的字体库反爬,要把这些代码转化成前端看到的123或天津菜等数据。
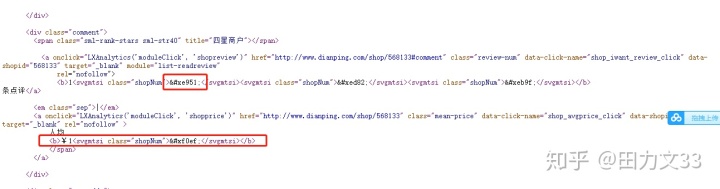
要把这些代码对应出真正的数字或汉字,需要把css内的woff字符库爬出来。获取的css链接类似如下:http://s3plus.sankuai.com/v1/mss_0a06a471f9514fc79c981b5466f56b91/svgtextcss/9a2072f4d3d2589da1b348aebb034c6c.css
在源代码中找到这样的内容,爬取下来
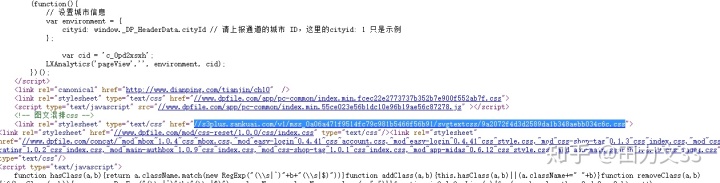
#爬取代码如下
pattern=re.compile(r'//s3plus..*?.css')
url=pattern.findall(html)
url1=''.join(url)
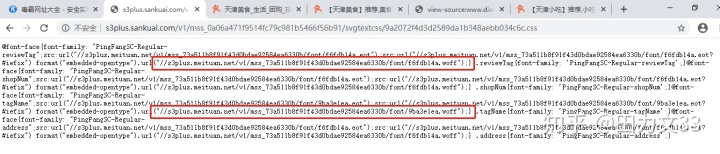
cssurl='http:'+url1css链接爬下来后打开看看,里面的内容,哇塞,这是什么神仙结构,可以看到里面有2种字符库。
但是css内的字体文件一直在变,光抓下来一次woff文件是不够的,既然这里实时变更,就要采取爬虫实时抓取css、下载woff。
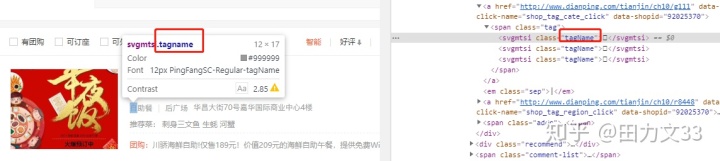
先把第一次爬取出来的css文件中的woff文件下载下来,上面截图看的出里面有2个woff文件,是否要把所有的woff文件都下载下来呢?这要看我们都需要爬取下来什么内容,(商铺名称,星级,评价条数,人均消费金额,菜系,商圈,团购活动)这些内容看他们的class标签,属于2类,shopNum,tagname,在css文件中能查到这2个标签,分别对应一个woff文件,也就是下载这2个woff文件即可。
 下载
下载
下载woff文件代码:
# 将css内对应shopNum,tagname标签的font-family内容爬取出来
def css_url(html):
pattern=re.compile(r'//s3plus..*?.css')
url=pattern.findall(html)
url1=''.join(url)
cssurl='http:'+url1
f=requests.get(cssurl)
f.encoding='utf-8'
f1=f.text
shopnumfont=re.findall(r'@font-face{font-family: "PingFangSC-Regular-shopNum".*?shopNum{font-family: 'PingFangSC-Regular-shopNum';}',f1)
shopnum=''.join(shopnumfont)
tagnamefont=re.findall(r'@font-face{font-family: "PingFangSC-Regular-tagName".*?tagName{font-family: 'PingFangSC-Regular-tagName';}',f1)
tagname=''.join(tagnamefont)
return shopnum,tagname
# 将对应标签内的woff下载在本地
def unicode_dict(shopnum):
shopnumlist = re.findall(r'//s3plus.meituan.net/v1/w+/font/w+.woff',shopnum)
shopnumurl = "http:" + ''.join(shopnumlist)
response_shopnumwoff = requests.get(shopnumurl).content
fontname = shopnumurl[-13:-5]
h=open(fontname + '.woff', 'wb')
h.write(response_shopnumwoff)
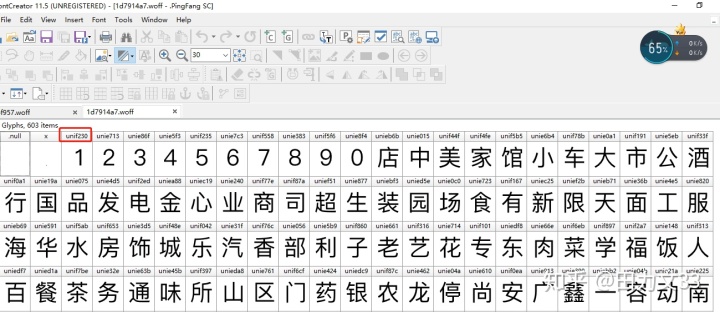
h.close()现在先以shopNum标签举例,举一反三tagname也就知道怎么处理了。下面就是关键,把爬取出来的一个woff文件做为基础字符库,通过FontCreator可以把编码对应的数字或汉字显示出来,下面是fontcreator打开woff文件后呈现出来的样子。
但要把这些编码和对应汉字转换成.xls或.txt还需要一个图像文字识别软件,推荐在线https://zhcn.109876543210.com/,把fontcreator中内容截图下来,用刚才的链接转换成.csv,直接把代码和对应的汉字都下载下来,方便直接生成字典(这是我的方法,可以根据自己的喜好来选择下载的形式),
这里的是不是unie045和很像?只要把前面3个字符更换成uni就可以了?测试一下是真的可以的。那把编码和汉字对应上,形成字典,再replace(’uni’,’&#x’)就能把网页上的&#xXXXX转换成汉字或数字了,就能爬取下来正确的内容了。
可这只能生成一个字典,前面说过css内的woff是不断变换的,每个woff文件下载下来相同数字对应的编码都不相同,如图,


不可能每个woff文件都这样生成一个字典,其他字符库要怎么找到编码对应的汉字或数字呢?这里需要用到TTFont,from fontTools.ttLib import TTFont,把woff文件存为xml,每个编码都会生成这样一个坐标系,虽然编码不同,但是后面的坐标系是相同的,对应生成的数字或汉字也是相同的,这是一个切入点~
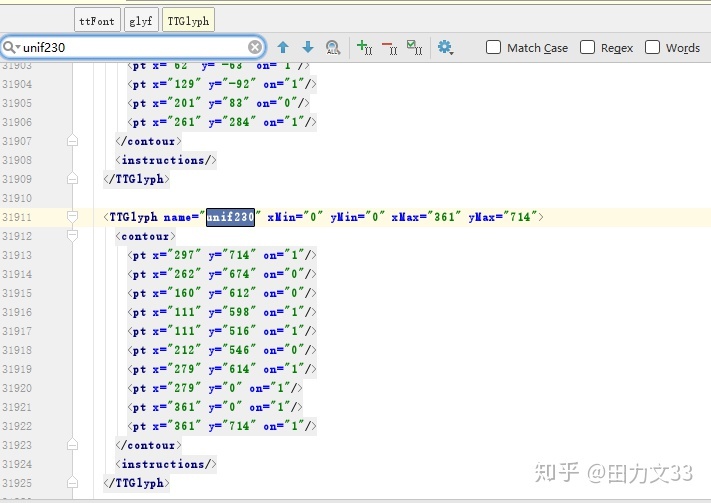
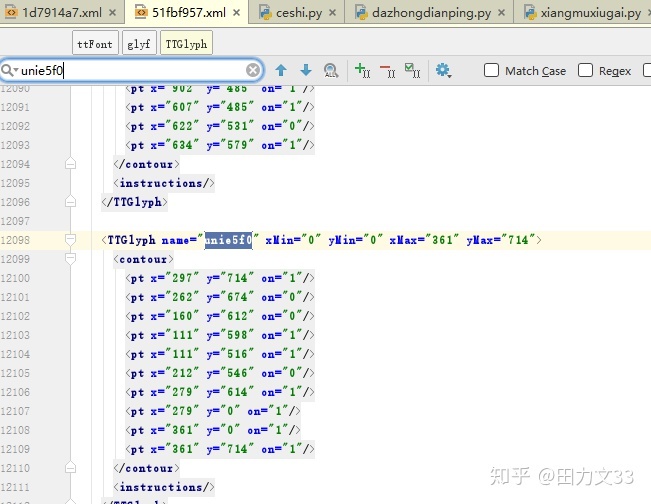
只要通过一个字符库的xml找到坐标系和汉字、数字对应的关系,新爬下来的字符库转换成xml后,遍历他的坐标系和已知字符库的坐标系对上了,就把已知字符库的汉字或数字赋值给新的字符库,完成!
上代码:
newfont = TTFont(fontname + '.woff')
newfont.saveXML(fontname + '.xml')
basefont = TTFont('1d7914a7.woff')
unicodedict = {"unie046": "跟", "unif305": "块", "unif230": "1", "unie713": "2", "unie86f": "3", "unie5f3": "4",
"unif235": "5", "unie7c3": "6", "unif558": "7", "unie383": "8", "unif5f6": "9", "unie8f4": "0",
"unieb6b": "店", "unie015": "中", "unif44f": "美", "unif4fe": "家", "unif5b5": "馆", "unie6b4": "小",
"unif78b": "车", "unie0a1": "大", "unif191": "市", "unie5eb": "公", "unif33f": "酒",
"unif0a1": "行", "unie19a": "国", "unie075": "品", "unie4d5": "发", "unif2ed": "电", "uniea88": "金",
"uniec19": "心", "unie240": "业", "unif77e": "商", "unif87a": "司", "unief51": "超", "unie877": "生",
"uniebf3": "装", "unied5e": "园", "unie0c0": "场", "unie723": "食", "unif167": "有", "uniec25": "新",
"unief2b": "限", "unieb71": "天", "unie36b": "面", "unie4e5": "工", "unie820": "服",
"unieb69": "海", "unie591": "华", "unif5ab": "水", "unif653": "房", "unie3d5": "饰", "unif48e": "城",
"unif042": "乐", "unie31f": "汽", "unif76c": "香", "unie056": "部", "unie5b9": "利", "unif860": "子",
"unie661": "老", "unif316": "艺", "unie714": "花", "unif101": "专", "uniedf8": "东", "unie66e": "肉",
"unif6eb": "菜", "unif897": "学", "unif2a7": "福", "unie148": "饭", "unif313": "人",
"uniedf7": "百", "unied1a": "餐", "unif7be": "茶", "unie32e": "务", "unie63b": "通", "unie45b": "味",
"unif397": "所", "unieda8": "H1", "unie761": "区", "unif6cf": "门", "unie424": "药", "uniedc9": "银",
"unif87c": "农", "unie462": "龙", "unie04a": "停", "unie610": "尚", "unif0ea": "安", "unie913": "广",
"unie399": "鑫", "uniebb2": "—", "unie04b": "容", "unie21a": "动", "unie225": "南",
"unif024": "具", "unif165": "源", "unie259": "兴", "uniecb3": "鲜", "unie4a3": "记", "unif109": "时",
"unif4ed": "机", "unie5c7": "烤", "unif276": "文", "unie538": "康", "unied4c": "信", "uniedca": "果",
"unif1d5": "阳", "unif6f9": "理", "unie83a": "锅", "unif7e1": "宝", "unif094": "达", "unif18e": "地",
....... } # 太长了做缩略,全部代码后面会附上。
newfont_glyphNames=newfont.getGlyphNames()[1:-1]
basefont_glyphNames=basefont.getGlyphNames()[1:-1]
temp={}
a=len(unicodedict)
for i in range(0,a):
for j in range(0,a):
if newfont['glyf'][newfont_glyphNames[i]]==basefont['glyf'][basefont_glyphNames[j]]:
temp[newfont_glyphNames[i].replace('uni','&#x').lower()]=unicodedict[basefont_glyphNames[j]]
else:
pass
return temp通过上面几步,基本上就可以把爬取下来的字段对应出正常的汉字或数字了,再保存到mysql中,结果如下。
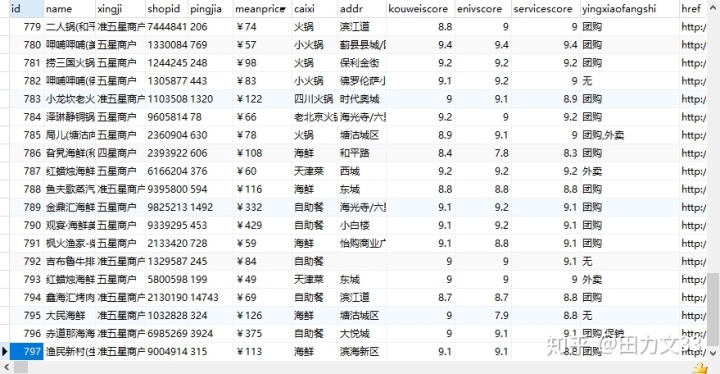
整理思路:
1、 爬取出css链接,从css内解析出shopNum,tagname标签的woof文件
2、 将下载下来的一个woff文件做为基础,用fontcreator和诚华OCR,将编码对应的汉字和数字整理成字典。
3、 将已知的字符库用TTFont存为xml,用getGlyphNames()和if条件语句判断新下载的字符库和已知字符库是否有相同的坐标系,有的话将字典内的值赋给新的字符库的编码,用replace(‘uni’,‘&#x’)将Unicode编码转换为网页上的编码,形成新的字典。
4、 通过以上方式生成2类字典,shopNum字典和tagname字典。
5、 将爬取出来的&#xXXXX这个格式的内容,区分匹配哪类字典,再将字典的值赋给对应的编码,形成最终的前端显示的文字或数字。