linux环境搭建
环境准备介绍
Oracle VM VirtualBox,虚机管理工具,免费好用,用过就知道
3台centos虚拟机,为后续搭建redis集群环境以及最简单的redis哨兵模式(一主二从,至少3台)
配置虚机网络
用centos7.ova导入VirtualBox,创建3台centos7虚拟机,内存跟cpu看自身笔记本硬件情况,需要注意的是,创建完成之后,这里的网络设置需要设置成桥接模式,如下
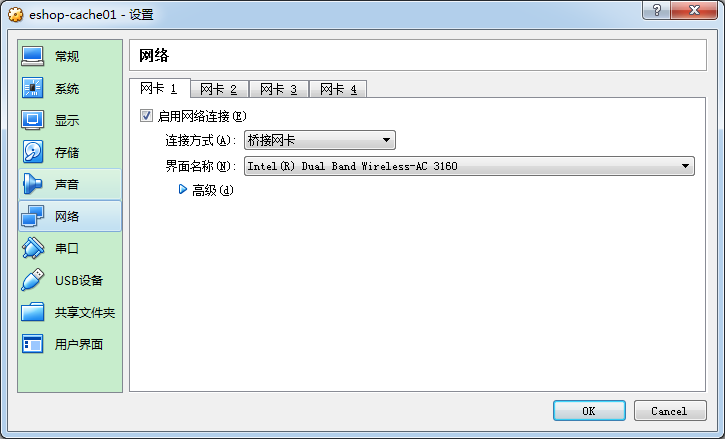
在创建完3台centos虚拟机后(这里使用的系统是centos7),将三台机子分别命名为eshop-cache01、eshop-cache02、eshop-cache03,方便称呼与后续管理(总比起三个ip地址为服务器名来的好吧)
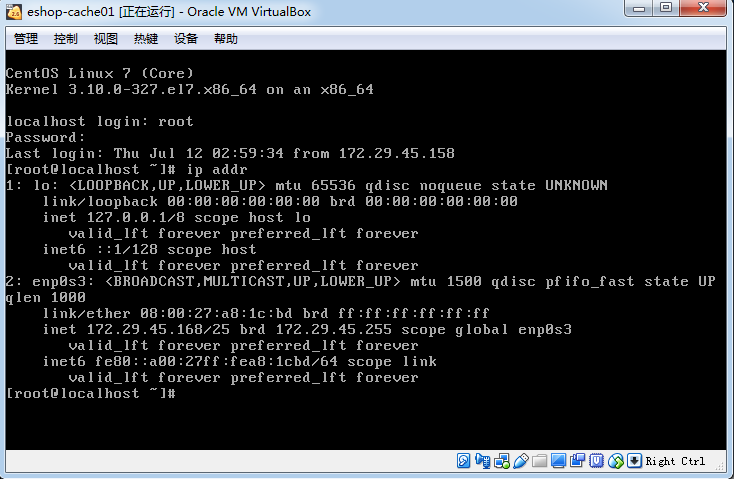
接下来配置下3台虚机的网络,先来看下eshop-cache01的网络
centos7的查看ip指令是ip addr,centos7以下是ifconfig
然后关闭防火墙,避免因为防火墙导致ssh工具连接不上
service iptables stop
service ip6tables stop
chkconfig iptables off
chkconfig ip6tables off 然后采用ssh工具连接,此处采用SecureCRT,使用SecureCRT登录上eshop-cache01之后,修改eshop-cache01的网络,将ip设置成静态ip并且设置网络随机子启动而主动连接(不采用动态地址导致地址更换频繁的浪费时间去纠正ip)
vi /etc/sysconfig/network-scripts/ifcfg-enp0s3 如下,修改的地方已用红框标注起来,首先修改ip分配方式为static,在文件末尾追加静态ip地址、子网掩码以及网关地址
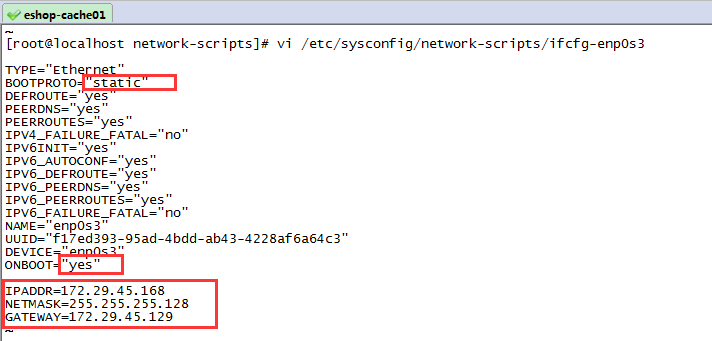
如下是我本地eshop-cache01的ifcfg-enp0s3文件内容
TYPE="Ethernet"
BOOTPROTO="static"
DEFROUTE="yes"
PEERDNS="yes"
PEERROUTES="yes"
IPV4_FAILURE_FATAL="no"
IPV6INIT="yes"
IPV6_AUTOCONF="yes"
IPV6_DEFROUTE="yes"
IPV6_PEERDNS="yes"
IPV6_PEERROUTES="yes"
IPV6_FAILURE_FATAL="no"
NAME="enp0s3"
UUID="f17ed393-95ad-4bdd-ab43-4228af6a64c3"
DEVICE="enp0s3"
ONBOOT="yes"
IPADDR=172.29.45.168
NETMASK=255.255.255.128
GATEWAY=172.29.45.129 ifcfg-enp0s3文件修改完之后,重启网络
service network restart
eshop-cache02与eshop-cache03如法炮制,最终配置完三台虚拟机的网络之后,三台虚拟机的ip地址如下
| 服务器 | ip |
|---|---|
| eshop-cache01 | 172.29.45.168 |
| eshop-cache02 | 172.29.45.170 |
| eshop-cache03 | 172.29.45.171 |
修改host
在三台虚拟机的host中,添加三者的ip以及服务器域名,后续搭建集群时,可以通过域名去请求虚机,不去拷贝ip,不好记又容易乱
host文件内容如下
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
172.29.45.168 eshop-cache01
172.29.45.170 eshop-cache02
172.29.45.171 eshop-cache03配置虚机间ssh免密码登录
修改host文件完成后,在eshop-cache01可以用ssh指令去连接eshop-02,但是每次连接都要求输入密码,很不方便。有这样一个场景,就是eshop-cache01有个文件的配置与另外两台服务器的配置是一样,如果我们用SecureCRT去操作的话,需要将文件拷贝到本机,然后再在本机上传到另外两台,但是这样机器少还好,机器多就容易乱,我们可以用scp指令去拷贝文件到另外两台服务器,方便快捷,但是使用scp指令在服务器之间传文件也需要提供密码,也是个耗时的操作,所以这里有必要将三台虚机相互通讯配置免密登录。
#生成本机的公钥,过程中不断敲回车即可,ssh-keygen命令默认会将公钥放在/root/.ssh目录下
ssh-keygen -t rsa
#将公钥复制为authorized_keys文件,此时使用ssh连接本机就不需要输入密码了
cd /root/.ssh
cp id_rsa.pub authorized_keys
#使用ssh-copy-id -i hostname命令将本机的公钥拷贝到指定机器的authorized_keys文件中
ssh-copy-id -i eshop-cache02 然后eshop-cache02与eshop-cache03也如法炮制。
再提一个方法,就是这里我们只有3台服务器,但是如果再加几台,干这种工作也可能会让你干奔溃,所以有一个办法,就是在每个服务器上生成各自的公钥,然后使用ssh-copy-id -i eshop-cache01指令将其他服务器的authorized_keys集中复制到eshop-cache01,此时其他服务器的authorized_keys会在eshop-cache01中追加,最后将eshop-cache01的authorized_keys复制到其他的服务器

配置yum
yum clean all
yum makecache
yum install wget安装perl
#安装perl之前需要先安装gcc,如果确认自己的机子已经安装过gcc可以跳过该指令
yum install -y gcc
wget http://www.cpan.org/src/5.0/perl-5.16.1.tar.gz
tar -xzf perl-5.16.1.tar.gz
cd perl-5.16.1
./Configure -des -Dprefix=/usr/local/perl
make && make test && make install
perl -v 为什么要装perl?我们整个大型电商网站的系统,复杂。应用架构是java+nginx+lua,需要perl。
perl,是一个基础的编程语言的安装,tomcat,跑java web应用
安装单机版redis及其配置
安装redis
redis安装包:redis-3.2.8.tar.gz
tcl安装包:tcl8.6.1-src.tar.gz
#安装redis之前需要先安装tcl,否则在make的时候,会报错,安装不成功
wget http://downloads.sourceforge.net/tcl/tcl8.6.1-src.tar.gz
tar -xzvf tcl8.6.1-src.tar.gz
cd /usr/local/tcl8.6.1/unix/
./configure
make && make install
#使用redis-3.2.8.tar.gz(截止2017年4月的最新稳定版)
tar -zxvf redis-3.2.8.tar.gz
cd redis-3.2.8
make && make test && make install配置redis
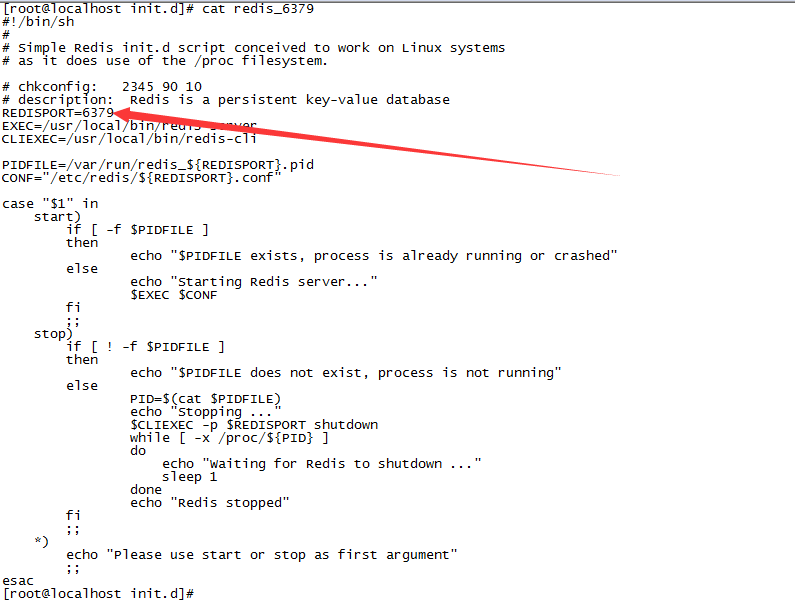
(1)redis安装目录的utils目录下,有个redis_init_script脚本
(2)将redis_init_script脚本拷贝到linux的/etc/init.d目录中,将redis_init_script重命名为redis_6379,6379是我们希望这个redis实例监听的端口号
cp /var/local/redis-3.2.8/utils/redis_init_script /etc/init.d/redis_6379(3)修改redis_6379脚本的第6行的REDISPORT,设置为相同的端口号(默认就是6379)
(4)创建两个目录:/etc/redis(存放redis的配置文件),/var/redis/6379(存放redis的持久化文件)
#/etc目录已经存在,直接创建redis目录
mkdir /etc/redis
#/var/redis的目录不存在,需要递归地创建目录加参数-p
mkdir -p /var/redis/6379(5)修改redis配置文件(默认在根目录下,redis.conf),拷贝到/etc/redis目录中,修改名称为6379.conf
cp /var/local/redis-3.2.8/redis.conf /etc/redis/6379.conf(6)修改redis.conf中的部分配置为生产环境
#让redis以daemon进程运行
daemonize yes
#设置redis的pid文件位置
pidfile /var/run/redis_6379.pid
#设置redis的监听端口号
port 6379
#设置持久化文件的存储位置
dir /var/redis/6379(7)启动redis
cd /etc/init.d
chmod 777 redis_6379
./redis_6379 start(8)确认redis进程是否启动
ps -ef | grep redis(9)让redis跟随系统启动自动启动
在redis_6379脚本中,最上面,在#!/bin/sh下,加入两行注释
# chkconfig: 2345 90 10
# description: Redis is a persistent key-value database 然后执行如下指令,让redis跟随系统启动自动启动
chkconfig redis_6379 on测试redis安装成功
#使用redis-cli指令连接eshop-cache01的redis服务器
redis-cli -h eshop-cache01 -p 6379
#连接成功,设置值
set mykey1 v1
#获取值
get mykey1
redis持久化
redis做持久化的意义在于故障恢复。
有这样的场景:你的电商项目部署了一个redis,作为cache缓存,当然也可以保存一些较为重要的数据,如果没有持久化的话,redis遇到灾难性故障的时候,就会丢失所有的数据,如果通过持久化将数据考一份儿在磁盘上去,然后定期比如说同步和备份到一些云存储服务上去,那么就可以保证数据不丢失全部,还是可以恢复一部分数据回来的。
如果不做持久化,当redis挂了,所有缓存数据丢失,所有请求都会去重查数据库,网站的吞吐量会立马下降,然后碰上高峰期,数据库就会被搞崩溃,然后网站就GG了。
所以,redis做持久化很有必要。
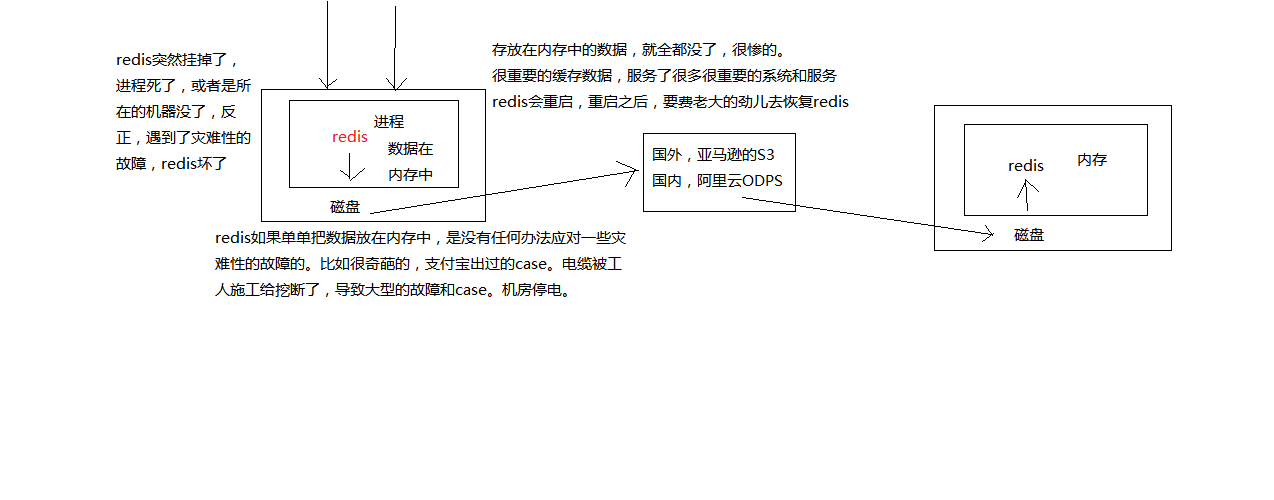
如果redis做了持久化,当redis挂了,服务器上的内存和磁盘上的数据都丢了,可以从云服务上拷贝回来之前的数据,放到指定的目录中,然后重新启动redis,redis就会自动根据持久化数据文件中的数据,去恢复内存中的数据,继续对外提供服务
redis的持久化有两种方式,RDB与AOF
如果我们想要redis仅仅作为纯内存的缓存来用,那么可以禁止RDB和AOF所有的持久化机制
RDB
RDB持久化机制,对redis中的数据执行周期性的持久化。
简单的说,RDB是比较简单粗暴,在配置开启RDB之后(redis默认开启),redis会根据配置的周期性时间将内存数据的快照保存到本地文件。
也即,RDB,就是一份数据文件,恢复的时候,直接加载到内存中即可。
所以,RDB非常适合做冷备,可以将这种完整的数据文件发送到一些远程的安全存储上去,比如说Amazon的S3云服务上去,在国内可以是阿里云的ODPS分布式存储上,以预定好的备份策略来定期备份redis中的数据。
RDB对redis对外提供的读写服务,影响非常小,可以让redis保持高性能,因为redis主进程只需要fork一个子进程,让子进程执行磁盘IO操作来进行RDB持久化即可。
但是RDB也不是完美的,RDB也有缺点:
(1)如果想要在redis故障时,尽可能少的丢失数据,那么RDB没有AOF好。一般来说,RDB数据快照文件,都是每隔5分钟,或者更长时间生成一次,这个时候就得接受一旦redis进程宕机,那么会丢失最近5分钟的数据
(2)RDB每次在fork子进程来执行RDB快照数据文件生成的时候,如果数据文件特别大,可能会导致对客户端提供的服务暂停数毫秒,或者甚至数秒
RDB持久化的工作流程
(1)redis根据配置自己尝试去生成rdb快照文件
(2)fork一个子进程出来
(3)子进程尝试将数据dump到临时的rdb快照文件中
(4)完成rdb快照文件的生成之后,就替换之前的旧的快照文件
RDB的配置及实验
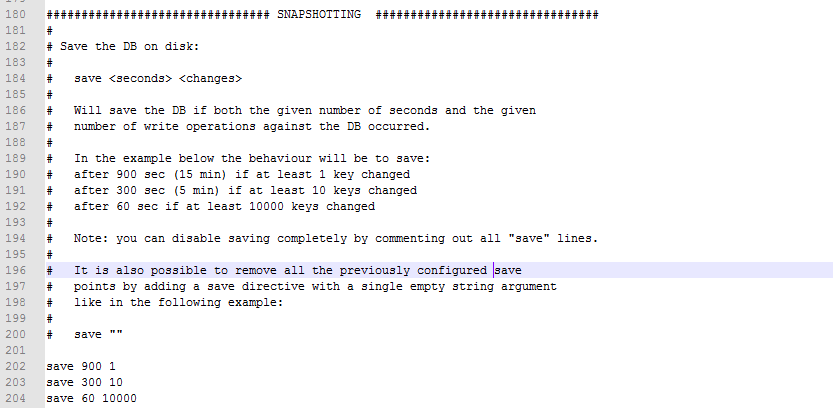
修改redis.conf文件,也就是/etc/redis/6379.conf,去配置持久化
#每隔60s,如果有超过1000个key发生了变更,那么就生成一个新的dump.rdb文件,就是当前redis内存中完整的数据快照,这个操作也被称之为snapshotting,快照
save 60 1000 也可以手动调用save或者bgsave命令,同步或异步执行rdb快照生成
save可以设置多个,就是多个snapshotting检查点,每到一个检查点,就会去check一下,是否有指定的key数量发生了变更,如果有,就生成一个新的dump.rdb文件
SHUTDOWN指令redis实验
默认配置不改的情况下,进行如下实验
#用redis-cli连接eshop-cache01的redis服务器
redis-cli -h eshop-cache01 -p 6379
#查询所有key
keys *
#添加数据
set key1 v1
set key2 v2
set key3 v3
#查询所有key
keys *
#退出客户端
exit
#关闭eshop-cache01的redis服务器
redis-cli -h eshop-cache01 -p 6379 SHUTDOWN
#查看redis进程
ps -ef|grep redis
#找到启动脚本目录,重新启动
cd /etc/init.d/
./redis_6379 start
#用客户端连接重新查询数据
redis-cli -h eshop-cache01 -p 6379
keys *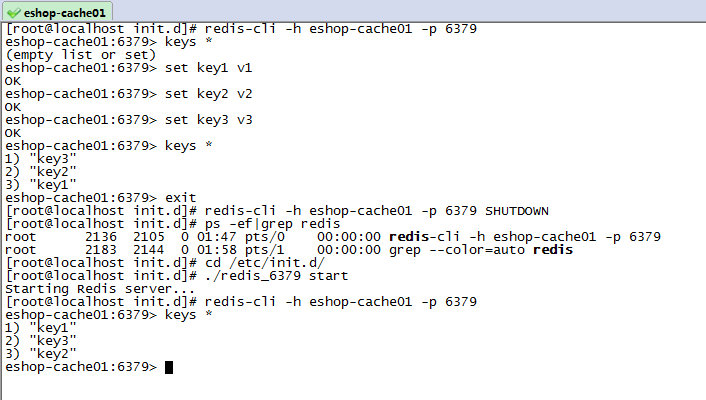
通过上述操作,我们可以知道,最后是可以查出数据的,理论上应该不能查到数据才对,因为默认的配置是1分钟有一万条数据更改、或5分钟有10条数据更改、或15分钟15分钟有一条数据更改,就生成dump.rdb文件

这是由于,当我们调用 redis-cli -h eshop-cache01 -p 6379 SHUTDOWN指令停掉redis时,其实是一种安全退出的模式,redis在退出的时候会将内存中的数据立即生成一份完整的rdb快照
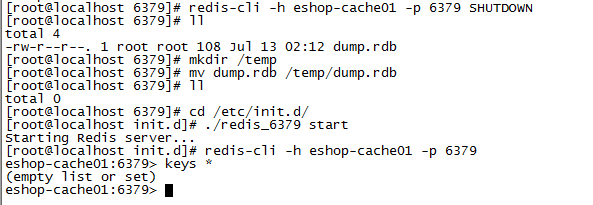
删除dump文件重启实验
如果我们此时把dump.rdb文件移动到一个别的地方,然后删除掉/var/redis/6379下的dump.rdb文件,重新启动redis服务器,再进行查询key就会发现数据不见了,因为rdb文件被我们删除了
kill进程重启实验
实验步骤也很简单,连接客户端添加键值对之后,退出客户端把redis服务进程给kill即可,实验结果如下,
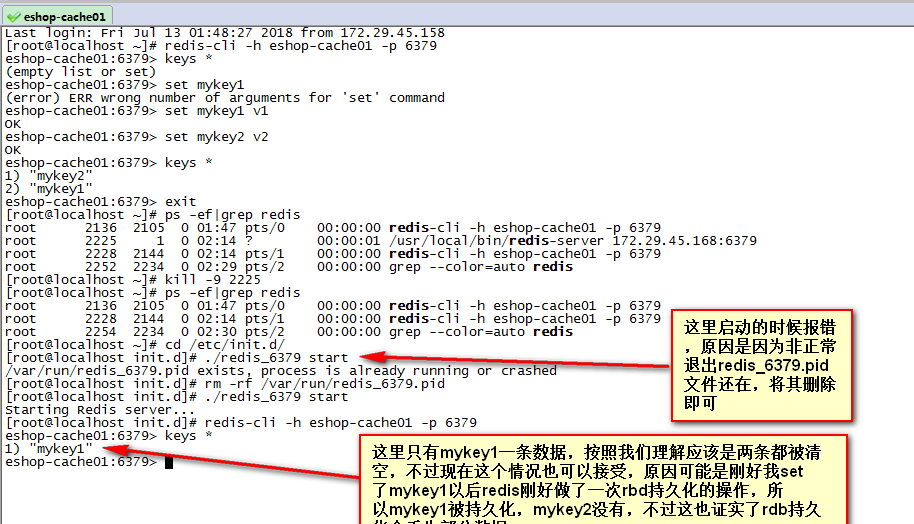
上面的实验也正好证实了,rdb持久化会丢失部分数据。
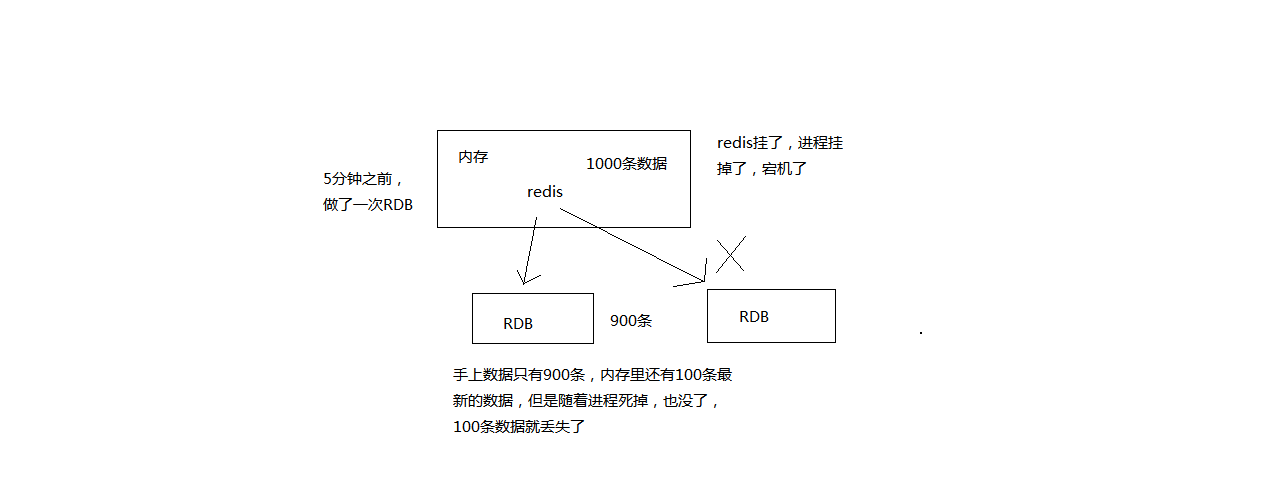
RDB恢复实验
恢复实验过程也很简单,就是将一份dump.rdb的文件拷贝到redis持久化的目录下,重启redis服务器即可,实际上一个实验也体现了RDB持久化的数据恢复,这里就不再演示了。
在实际的生产环境中,如果只做rdb持久化的情况下,最好是设置多个snapshotting检查点,如一个小时一次,以及2天一次,保证48小时内每个小时间隔的数据都做了备份(具体看自己系统的业务量而定),然后写个脚本将dump备份同步到云上去,当发生redis故障时,可以根据具体的情况恢复想要的数据。
AOF
AOF不像RDB流程那样简单直接fork一个子进程,保存内存中的数据快照,然后替换旧的dump文件。
如下,是RDB与AOF的流程对比图
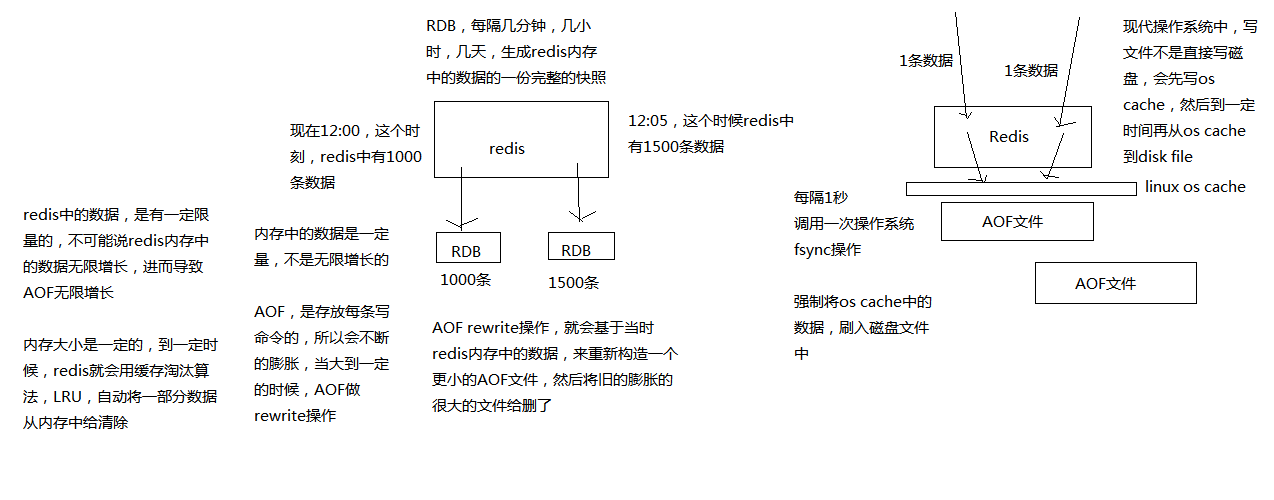
AOF机制对每条写入命令作为日志,以append-only的模式写入一个日志文件中,在redis重启的时候,可以通过回放AOF日志中的写入指令来重新构建整个数据集。
AOF开启后,redis每次接收到一条写命令,就会写入日志文件中,当然是先写入os cache的,然后每隔一定时间再fsync一下。
所以,相对来说,AOF的日志文件是人可以看懂的。
AOF持久化的工作流程
(1)AOF在接收到写命令之后,将指令写到os cache中
(2)根据配置os cache的更新策略,将os cache的指令写入到日志中,默认是1秒钟刷新一次os cache
AOF的Rewrite流程
redis中的数据其实有限的,很多数据可能会自动过期,可能会被用户删除,可能会被redis用缓存清除的算法清理掉。redis中的数据会不断淘汰掉旧的,就一部分常用的数据会被自动保留在redis内存中,所以可能很多之前的已经被清理掉的数据,对应的写日志还停留在AOF中,AOF日志文件就一个,会不断的膨胀,到很大很大
所以AOF会自动在后台每隔一定时间做rewrite操作,比如日志里已经存放了针对100w数据的写日志了; redis内存只剩下10万; 基于内存中当前的10万数据构建一套最新的日志,到AOF中; 覆盖之前的老日志; 确保AOF日志文件不会过大,保持跟redis内存数据量一致
redis 2.4之前,还需要手动,开发一些脚本,crontab,通过BGREWRITEAOF命令去执行AOF rewrite,但是redis 2.4之后,会自动进行rewrite操作
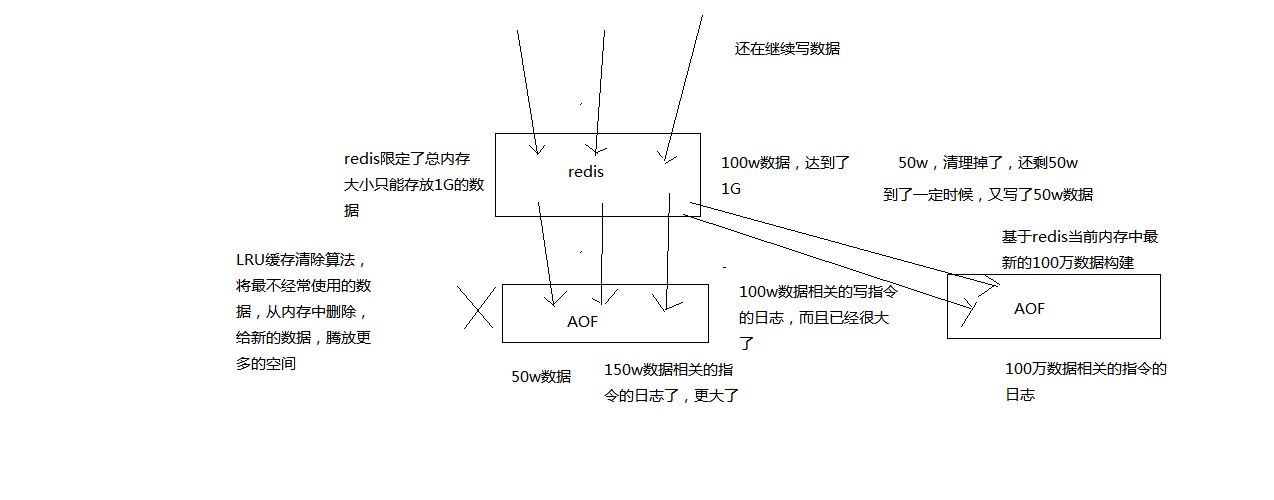
rewrite流程:
(1)redis fork一个子进程
(2)子进程基于当前内存中的数据,构建日志,开始往一个新的临时的AOF文件中写入日志
(3)redis主进程,接收到client新的写操作之后,在内存中写入日志,同时新的日志也继续写入旧的AOF文件
(4)子进程写完新的日志文件之后,redis主进程将内存中的新日志再次追加到新的AOF文件中
(5)用新的日志文件替换掉旧的日志文件
AOF的配置及实验
AOF持久化,默认是关闭的,默认是打开RDB持久化
appendonly yes,可以打开AOF持久化机制,在生产环境里面,一般来说AOF都是要打开的,除非你的系统业务随便丢个几分钟的数据也无所谓
如果AOF和RDB都开启了,redis重启的时候,也是优先通过AOF进行数据恢复的,因为AOF数据比较完整
AOF可以配置fsync策略,有三种策略可以选择:
always: 每次写入一条数据,立即将这个数据对应的写日志fsync到磁盘上去,性能非常非常差,吞吐量很低; 确保说redis里的数据一条都不丢,那就只能这样了
mysql -> 内存策略,大量磁盘,QPS到多少,一两k。QPS,每秒钟的请求数量
redis -> 内存,磁盘持久化,QPS到多少,单机,一般来说,上万QPS没问题
everysec: 每秒将os cache中的数据fsync到磁盘,这个最常用的,生产环境一般都这么配置,性能很高,QPS还是可以上万的
no: redis仅仅负责将数据写入os cache就撒手不管了,然后后面os自己会时不时有自己的策略将数据刷入磁盘,不可控了
修改AOF配置之后SHUTDOWN重启实验
实验步骤是先修改/etc/redis/6379.conf配置文件,开启AOF持久化,然后重启应用查看结果
#开启AOF持久化
appendonly yes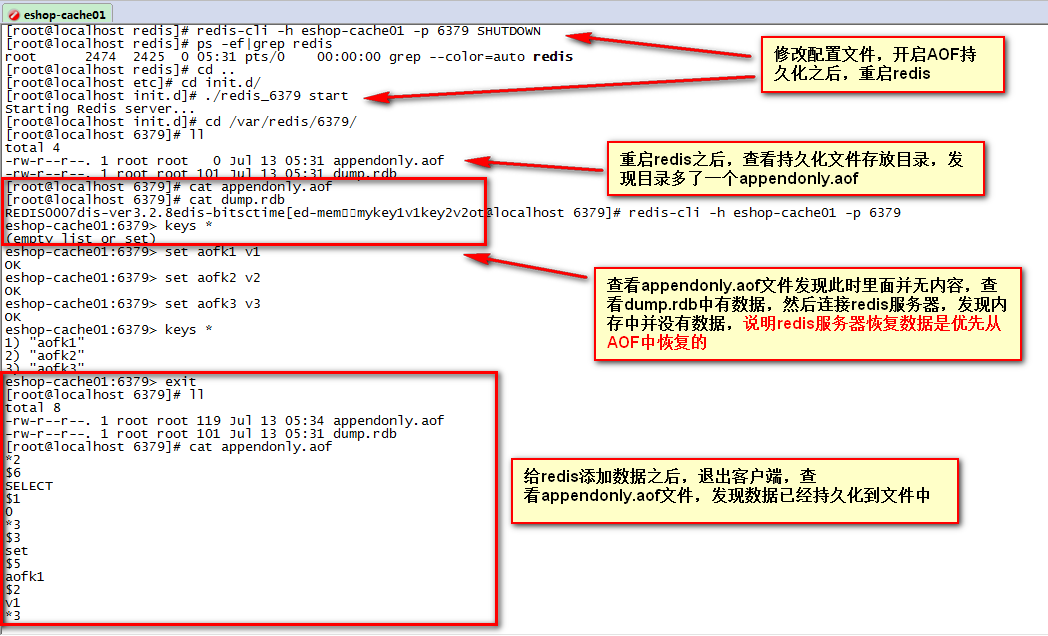
上图就是redis开启AOF持久化配置之后的测试结果,从上面的结果中,我们可以知道另外一个事情,就是如果同时开启RDB与AOF持久化时,优先从AOF中恢复,那么,如果开始你的redis是RDB备份的,现在需要添加开启AOF持久化,通过上面这种方式就显然是有问题的,原本系统的redis缓存数据全部丢失了,虽然还有dump.rdb文件,当发生数据变更,触发RDB持久化的周期备份,那么rdb的数据也没了!!也间接说明冷备很重要!冷备很重要!冷备很重要!
回到上述问题,那如果出现这种场景,开始你的redis是RDB备份的,现在需要添加开启AOF持久化,那应该如何操作,才不会导致原有的数据丢失呢?
恢复到之前的场景,将6379.conf中的appendonly的配置项改为no
appendonly no
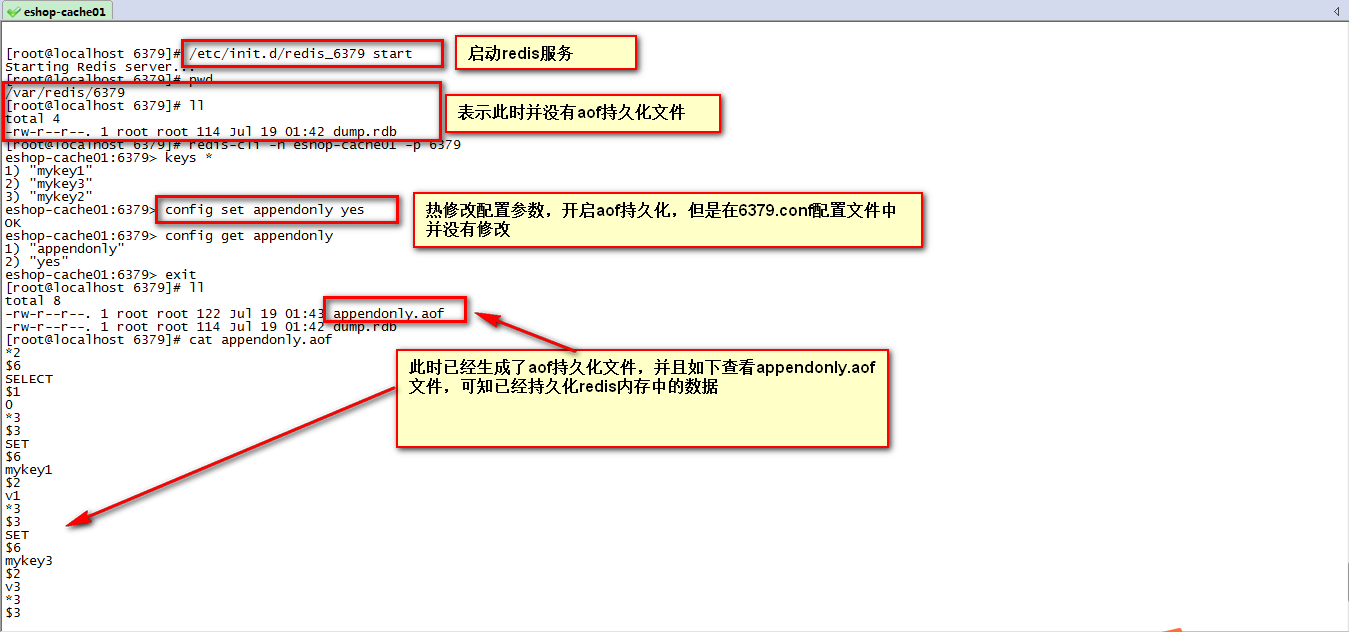
在已开启rdb的情况,正确开启aof持久化的做法如下,
#启动redis服务
/etc/init.d/redis_6379 start
Starting Redis server...
[root@localhost 6379]# pwd
/var/redis/6379
[root@localhost 6379]# ll
total 4
-rw-r--r--. 1 root root 114 Jul 19 01:42 dump.rdb
#客户端连接redis服务
[root@localhost 6379]# redis-cli -h eshop-cache01 -p 6379
eshop-cache01:6379> keys *
1) "mykey1"
2) "mykey3"
3) "mykey2"
#热修改配置参数,将appendonly设置为yes,但此时6379.conf配置文件并没有修改appendonly项
eshop-cache01:6379> config set appendonly yes
OK
eshop-cache01:6379> config get appendonly
1) "appendonly"
2) "yes" 在查看到aof持久化文件有数据后,可以将服务停掉,然后修改6379.conf配置文件,将appendonly改为yes,然后重启服务
总结
RDB持久化机制的优点
(1)RDB会生成多个数据文件,每个数据文件都代表了某一个时刻中redis的数据,这种多个数据文件的方式,非常适合做冷备,可以将这种完整的数据文件发送到一些远程的安全存储上去,比如说Amazon的S3云服务上去,在国内可以是阿里云的ODPS分布式存储上,以预定好的备份策略来定期备份redis中的数据
RDB也可以做冷备,生成多个文件,每个文件都代表了某一个时刻的完整的数据快照
AOF也可以做冷备,只有一个文件,但是你可以,每隔一定时间,去copy一份这个文件出来
RDB做冷备,优势在哪儿呢?由redis去控制固定时长生成快照文件的事情,比较方便; AOF,还需要自己写一些脚本去做这个事情,各种定时
RDB数据做冷备,在最坏的情况下,提供数据恢复的时候,速度比AOF快
(2)RDB对redis对外提供的读写服务,影响非常小,可以让redis保持高性能,因为redis主进程只需要fork一个子进程,让子进程执行磁盘IO操作来进行RDB持久化即可
RDB,每次写,都是直接写redis内存,只是在一定的时候,才会将数据写入磁盘中
AOF,每次都是要写文件的,虽然可以快速写入os cache中,但是还是有一定的时间开销的,速度肯定比RDB略慢一些
(3)相对于AOF持久化机制来说,直接基于RDB数据文件来重启和恢复redis进程,更加快速
AOF,存放的指令日志,做数据恢复的时候,其实是要回放和执行所有的指令日志,来恢复出来内存中的所有数据的
RDB,就是一份数据文件,恢复的时候,直接加载到内存中即可
结合上述优点,RDB特别适合做冷备份,冷备
RDB持久化机制的缺点
(1)如果想要在redis故障时,尽可能少的丢失数据,那么RDB没有AOF好。一般来说,RDB数据快照文件,都是每隔5分钟,或者更长时间生成一次,这个时候就得接受一旦redis进程宕机,那么会丢失最近5分钟的数据
这个问题,也是rdb最大的缺点,就是不适合做第一优先的恢复方案,如果你依赖RDB做第一优先恢复方案,会导致数据丢失的比较多
(2)RDB每次在fork子进程来执行RDB快照数据文件生成的时候,如果数据文件特别大,可能会导致对客户端提供的服务暂停数毫秒,或者甚至数秒
一般不要让RDB的间隔太长,否则每次生成的RDB文件太大了,对redis本身的性能可能会有影响的
AOF持久化机制的优点
(1)AOF可以更好的保护数据不丢失,一般AOF会每隔1秒,通过一个后台线程执行一次fsync操作,最多丢失1秒钟的数据
每隔1秒,就执行一次fsync操作,保证os cache中的数据写入磁盘中
redis进程挂了,最多丢掉1秒钟的数据
(2)AOF日志文件以append-only模式写入,所以没有任何磁盘寻址的开销,写入性能非常高,而且文件不容易破损,即使文件尾部破损,也很容易修复
(3)AOF日志文件即使过大的时候,出现后台重写操作,也不会影响客户端的读写。因为在rewrite log的时候,会对其中的指导进行压缩,创建出一份需要恢复数据的最小日志出来。再创建新日志文件的时候,老的日志文件还是照常写入。当新的merge后的日志文件ready的时候,再交换新老日志文件即可。
(4)AOF日志文件的命令通过非常可读的方式进行记录,这个特性非常适合做灾难性的误删除的紧急恢复。比如某人不小心用flushall命令清空了所有数据,只要这个时候后台rewrite还没有发生,那么就可以立即拷贝AOF文件,将最后一条flushall命令给删了,然后再将该AOF文件放回去,就可以通过恢复机制,自动恢复所有数据
AOF持久化机制的缺点
(1)对于同一份数据来说,AOF日志文件通常比RDB数据快照文件更大
(2)AOF开启后,支持的写QPS会比RDB支持的写QPS低,因为AOF一般会配置成每秒fsync一次日志文件,当然,每秒一次fsync,性能也还是很高的
如果你要保证一条数据都不丢,也是可以的,AOF的fsync设置成没写入一条数据,fsync一次,那就完蛋了,redis的QPS大降
(3)以前AOF发生过bug,就是通过AOF记录的日志,进行数据恢复的时候,没有恢复一模一样的数据出来。所以说,类似AOF这种较为复杂的基于命令日志/merge/回放的方式,比基于RDB每次持久化一份完整的数据快照文件的方式,更加脆弱一些,容易有bug。不过AOF就是为了避免rewrite过程导致的bug,因此每次rewrite并不是基于旧的指令日志进行merge的,而是基于当时内存中的数据进行指令的重新构建,这样健壮性会好很多。
(4)唯一的比较大的缺点,其实就是做数据恢复的时候,会比较慢,还有做冷备,定期的备份,不太方便,可能要自己手写复杂的脚本去做,做冷备不太合适
RDB和AOF到底该如何选择
(1)不要仅仅使用RDB,因为那样会导致你丢失很多数据
(2)也不要仅仅使用AOF,因为那样有两个问题,第一,你通过AOF做冷备,没有RDB做冷备,来的恢复速度更快; 第二,RDB每次简单粗暴生成数据快照,更加健壮,可以避免AOF这种复杂的备份和恢复机制的bug
(3)综合使用AOF和RDB两种持久化机制,用AOF来保证数据不丢失,作为数据恢复的第一选择; 用RDB来做不同程度的冷备,在AOF文件都丢失或损坏不可用的时候,还可以使用RDB来进行快速的数据恢复
AOF和RDB同时工作
(1)如果RDB在执行snapshotting操作,那么redis不会执行AOF rewrite; 如果redis再执行AOF rewrite,那么就不会执行RDB snapshotting
(2)如果RDB在执行snapshotting,此时用户执行BGREWRITEAOF命令,那么等RDB快照生成之后,才会去执行AOF rewrite
(3)同时有RDB snapshot文件和AOF日志文件,那么redis重启的时候,会优先使用AOF进行数据恢复,因为其中的日志更完整