【烈日炎炎战后端】JAVA基础(3.4万字)
JAVA基础(34587 字)
- 1. 如何理解面向对象?
- 2. Java和C++的区别?
- 3. Java面向对象的三大特性?
- 4. Java中重载和重写
- 5. Java 中的访问修饰符
- 6. Java的8种基本类型与封装类?
- 7. Java中“==”和equals的区别?
- 8. 为什么重写equals一定要重写hashcode?
- 9. Java中抽象类和接口的区别?
- 10. final finally finalize 区别及用法?
- 11. this和super的区别
- 13 泛型
- 14. 常用注解
- 15. JDK1.8中有哪些新特性?
- 16. Java对象的hashCode方法理解
- 17.Object o=new object()在中占用多少字节?
- 18. JDK, JRE 和JVM的区别
- 19. IO流?
- 20. 序列化和反序列化是什么?
- 【克隆】
- [1] 深克隆和浅克隆的区别?
- [2] 如何实现对象的克隆?
- [3] 数组的四种拷贝方式对比
- [4] 数组的四种拷贝方式实现
- 【static】
- [1] static关键词的原理?
- [2] Java中static关键词的作用?
- [3] 为什么静态成员和方法中不能用this和super关键字?
- 【异常处理】
- [1] try和catch
- [2] Error 和 Exception 的区别?
- [3] 运行时异常与受检异常有何异同?
- [4] throw 和 throws 的区别?
- [5] 常见的异常类有哪些?
- [补充]
- 【反射】
- [1] 为什么有反射机制?
- [2] 什么是反射机制?
- [3] 反射如何实现的?
- [4] 如何获取 Class 对象
- [5] 反射机制的作用
- [6] 反射相关的类
- [7] 反射的优缺点?
- 【代理】
- [1] 什么是代理模式?
- [2] 什么是静态代理?
- [3] 什么是动态代理?如何实现?
- [4] 静态代理和动态代理有什么区别?
- [5] 怎么实现动态代理?
- [6] 动态代理的应用
- [7] Spring如何实现AOP?
- [8] 静态代理和动态代理的区别
1. 如何理解面向对象?
参考链接:link1,link2
我认为可以从三个层面来解释:
第一个层面(基本概念):面向对象 ( Object Oriented ) 是将现实问题构建关系,然后抽象成 类 ( class ),给类定义属性和方法后,再将类实例化成 实例 ( instance ) ,通过访问实例的属性和调用方法来进行使用。
第二个层面(三大特性):三大特性:封装,继承,多态(重载和重写)。
第三个层面(设计模式):设计模式的六大原则可以更详细的去解释面向对象及其三大特性的规则。六大原则有:开闭原则,单一指责原则,里氏替换原则,依赖倒置原则,接口隔离原则,迪米特法则。
2. Java和C++的区别?
链接:https://www.nowcoder.com/discuss/406755
-
Java是解释型语言,所谓的解释型语言,就是源码会先经过一次编译,成为中间码,中间码再被解释器解释成机器码。对于Java而言,中间码就是字节码(.class),而解释器在JVM中内置了。
-
C++是编译型语言,所谓编译型语言,就是源码一次编译,直接在编译的过程中链接了,形成了机器码。
-
C++比Java执行速度快,但是Java可以利用JVM跨平台。
-
Java是纯面向对象的语言,所有代码(包括函数、变量)都必须在类中定义。而C++中还有面向过程的东西,比如是全局变量和全局函数。
-
C++中有指针,Java中没有,但是有引用。
-
C++支持多继承,Java中类都是单继承的。但是继承都有传递性,同时Java中的接口是多继承,类对接口的实现也是多实现。
-
C++中,开发需要自己去管理内存,但是Java中JVM有自己的GC机制,虽然有自己的GC机制,但是也会出现OOM和内存泄漏的问题。C++中有析构函数,Java中Object的finalize方法。
-
C++运算符可以重载,但是Java中不可以。同时C++中支持强制自动转型,Java中不行,会出现ClassCastException(类型不匹配)。
面向对象和面向过程有什么区别?
面向对象和面向过程最本质的区别在于考虑问题的出发点不同,面向过程是以事件流程为考虑问题的出发点,而面向对象则是以参与事件的角色(对象)为考虑问题的出发点,所以面向对象在处理问题时更加灵活。目前,面向过程的语言更多被用于处理底层业务,而面向对象编程则更多用于实现一些业务逻辑复杂的大型系统。
面向过程:摇(狗尾巴)
面向对象:狗.摇尾巴()面向过程是编年史。
面向对象是纪传史。
3. Java面向对象的三大特性?
三大特性:封装,继承,多态(重载和重写)
封装:把事物用类封装起来,保留特定的接口与外界联系,可减少耦合,隐藏细节;
继承:子类继承父类,子类可以拥有已知父类的行为和属性;通过继承创建的新类称为「子类」或「派生类」,被继承的类称为「基类」、「父类」或「超类」。
多态:多态性是允许你将父对象设置成为和一个或更多的他的子对象相等的技术,赋值之后,父对象就可以根据当前赋值给它的子对象的特性以不同的方式运作。简单说就是一句话:允许将子类类型的指针赋值给父类类型的指针。多态的本质就是一个程序中存在多个同名的不同方法,分为重载和重写。
【拓展】Java中实现多态的机制是什么?
多态就是指一个引用变量倒底会指向哪个类的实例对象,该引用变量发出的方法调用到底是哪个类中实现的方法,必须在由程序运行期间才能决定。因为在程序运行时才确定具体的类,这样,不用修改源程序代码,就可以让引用变量绑定到各种不同的类实现上,从而导致该引用调用的具体方法随之改变,即不修改程序代码就可以改变程序运行时所绑定的具体代码,让程序可以选择多个运行状态,这就是多态性。
特点:
- 指向子类的父类引用由于向上转型了,它只能访问父类中拥有的方法和属性,而对于子类中存在而父类中不存在的方法,该引用是不能使用的,尽管是重载该方法。
- 若子类重写了父类中的某些方法,在调用该些方法的时候,必定是使用子类中定义的这些方法(动态连接、动态调用)。
Java实现多态有三个必要条件:继承、重写、向上转型。
调用的优先级方法,该优先级为:this.show(O)、super.show(O)、this.show((super)O)super.show((super)O)。多态的实现原理
Java 里对象方法的调用是依靠类信息里的方法表实现的。总体而言,当调用对象某个方法时,JVM查找该对象类的方法表以确定该方法的直接引用地址,有了地址后才真正调用该方法。Overriding该方法,那么调用时会指向父类的方法。如果Overrding该方法,那么指向该类的代码区。但是超类会存有父类的方法表。
我们知道java程序运行时,类的相关信息放在方法区,在这些信息中有个叫方法表的区域,该表包含有该类型所定义的所有方法的信息和指向这些方法实际代码的指针。
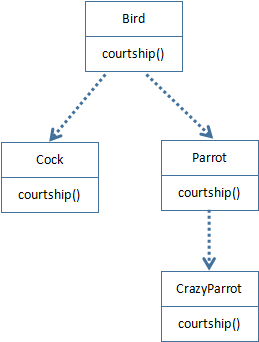
当Bird、Cock、Parrot和CrazyParrot这四个类被加载到 Java 虚拟机之方法区后,方法区中就包含了这四个类的信息,下图示例了各个类的方法表。
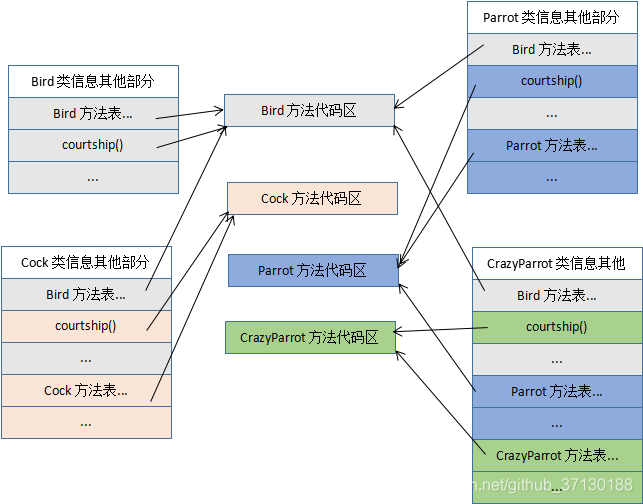
从图我们可以看到Cock、Parrot和CrazyParrot的类信息方法表包含了继承自Bird的方法。CrazyParrot的方法表包含了继承自Parrot的方法。此外各个类也有自己的方法。
注意看,方法表条目指向的具体方法代码区。对于多态Overriding的方法courtship(),虽然Cock、Parrot和CrazyParrot的方法表里的courtship()条目所在位置是属于继承自Bird方法表的部分,但指向不同的方法代码区了。
继承和多态有什么区别?
继承是子类获得父类的成员,重写是继承后重新实现父类的方法,重载是在一个类里一系列参数不同名字相同的方法。多态则是为了避免在父类里大量重载引起代码臃肿且难于维护。
4. Java中重载和重写
重载(overloading):编译时多态, 在一个类里面,方法名字相同,而参数不同。返回类型可以相同也可以不同。
重写(Override):运行时多态,如果一个子类继承了一个父类,子类中拥有和父类相同方法名称,返回值,参数类型的话,就是重写,会执行子类中的方法。
重载:
public class 重载 {
public static void sayhello(int s){
System.out.println("这是int类型的参数");
}
public static void sayhello(char s){
System.out.println("这是char类型的参数");
}
public static void main(String[] args) {
sayhello(1);
sayhello('a');
}
}
重写:
class Animal{
public void move(){
System.out.println("动物可以移动");
}
}
class Dog extends Animal{
public void move(){
System.out.println("狗可以跑和走");
}
}
public class TestDog{
public static void main(String args[]){
Animal a = new Animal(); // Animal 对象
Animal b = new Dog(); // Dog 对象
a.move();// 执行 Animal 类的方法
b.move();//执行 Dog 类的方法
}
}
以上实例编译运行结果如下:
动物可以移动
狗可以跑和走
在上面的例子中可以看到,尽管 b 属于 Animal 类型,但是它运行的是 Dog 类的 move方法。这是由于在编译阶段,只是检查参数的引用类型。然而在运行时,Java 虚拟机(JVM)指定对象的类型并且运行该对象的方法。因此在上面的例子中,之所以能编译成功,是因为 Animal 类中存在 move 方法,然而运行时,运行的是特定对象的方法。
【拓展】多态的底层原理?
重载编译时多态和重写运行时多态的解释:link,link1,link2,link3
【拓展】Java中重载和重写的规则?
方法的重载规则
- 被重载的方法必须改变参数列表(参数个数或类型不一样);
- 被重载的方法可以改变返回类型;
- 被重载的方法可以改变访问修饰符;
- 被重载的方法可以声明新的或更广的检查异常;
- 方法能够在同一个类中或者在一个子类中被重载。
- 无法以返回值类型作为重载函数的区分标准。
方法的重写规则
-
参数列表必须完全与被重写方法的相同。
-
返回类型与被重写方法的返回类型可以不相同,但是必须是父类返回值的派生类(java5 及更早版本返回类型要一样,java7 及更高版本可以不同)。
父类返回值可能是复杂类型,如返回的是class A,那么重写返回值类型就要是class A或者是class A的子类
-
子类访问权限不能比父类中被重写的方法的访问权限更低。例如:如果父类的一个方法被声明为 public,那么在子类中重写该方法就不能声明为 protected。
-
父类的成员方法只能被它的子类重写。
-
声明为 final 的方法不能被重写。
-
声明为 static 的方法不能被重写,但是能够被再次声明。
-
子类和父类在同一个包中,那么子类可以重写父类所有方法,除了声明为 private 和 final 的方法。
-
子类和父类不在同一个包中,那么子类只能够重写父类的声明为 public 和 protected 的非 final 方法。
-
重写的方法能够抛出任何非强制异常,无论被重写的方法是否抛出异常。但是,重写的方法不能抛出新的强制性异常,或者比被重写方法声明的更广泛的强制性异常,反之则可以。
-
构造方法不能被重写。
-
如果不能继承一个方法,则不能重写这个方法。
为什么Java中子类重写方法的访问权限不能低于父类中权限? link
该问题依赖于里氏代换原则, 先记录下该原则的原理,里氏代换原则(Liskov Substitution Principle LSP)面向对象设计的基本原则之一。 里氏代换原则中说,任何基类可以出现的地方,子类一定可以出现。
重载重写规则对比
| 区别点 | 重载方法 | 重写方法 |
|---|---|---|
| 参数列表 | 必须修改 | 一定不能修改 |
| 返回类型 | 可以修改 | 一定不能修改 |
| 异常 | 可以修改 | 可以减少或删除,一定不能抛出新的或者更广的异常 |
| 访问 | 可以修改 | 一定不能做更严格的限制(可以降低限制) |
方法的重写(Overriding)和重载(Overloading)是java多态性的不同表现,重写是父类与子类之间多态性的一种表现,重载可以理解成多态的具体表现形式。
- (1)方法重载是一个类中定义了多个方法名相同,而他们的参数的数量不同或数量相同而类型和次序不同,则称为方法的重载(Overloading)。
- (2)方法重写是在子类存在方法与父类的方法的名字相同,而且参数的个数与类型一样,返回值也一样的方法,就称为重写(Overriding)。
- (3)方法重载是一个类的多态性表现,而方法重写是子类与父类的一种多态性表现。
5. Java 中的访问修饰符
Java中,可以使用访问控制符来保护对类、变量、方法和构造方法的访问。Java 支持 4 种不同的访问权限。
- public(公开) :任何位置都可见。使用对象:类、接口、变量、方法
- protected(受保护) : 对同一包内的类和所有子类可见。使用对象:变量、方法。 注意:不能修饰类(外部类)。
- default(默认) : 在同一包内可见,不使用任何修饰符。使用对象:类、接口、变量、方法。
- private(私有) : 在同一类内可见。使用对象:变量、方法。 注意:不能修饰类(外部类)
| 修饰符 | 当前类 | 同一包内 | 子孙类(同一包) | 子孙类(不同包) | 其他包 |
|---|---|---|---|---|---|
public | Y | Y | Y | Y | Y |
protected | Y | Y | Y | Y(说明) | N |
default | Y | Y | Y | N | N |
private | Y | N | N | N | N |
link
6. Java的8种基本类型与封装类?
整数类型:字节型(byte/8位)、短整型(short/16位)、整型(int/32位)、长整型(long/64位)
浮点类型:单精度型(float/32位)和双精度类型(double/64位)
字符类型:字符类型(char/16位)
布尔类型:布尔类型(boolean/1位),常量只有“真(true)”和“假(false)”这两个状态
一个字节为8位
Java中的封装类:
8种基本类型按照类型划分:byte,short,int,long,float,double,boolean,char。
8种基本类型的封装类:Byte,Short,Integer,Long,Float,Double,Boolean,Character.
- boolean类型占了单独使用是4个字节,在数组中又是1个字节
- 基本类型所占的存储空间是不变的。这种不变性也是Java具有可移植性的原因之一。
- 基本类型放在栈中,直接存储值。
- 所有数值类型都有正负号,没有无符号的数值类型。
为什么需要封装类?
因为泛型类包括预定义的集合,使用的参数都是对象类型,无法直接使用基本数据类型,所以Java又提供了这些基本类型的封装类。
基本类型和对应的封装类由于本质的不同。具有一些区别:
1.基本类型只能按值传递,而封装类按引用传递。
2.基本类型会在栈中创建,而对于对象类型,对象在堆中创建,对象的引用在栈中创建,基本类型由于在栈中,效率会比较高,但是可能存在内存泄漏的问题
包装类的缓存:
Boolean:全部缓存
Byte:全部缓存
Character:<= 127 缓存
Short:-128 — 127 缓存
Long:-128 — 127 缓存
Integer:-128 — 127 缓存
Float:没有缓存
Doulbe:没有缓存
自动装箱与自动拆箱:link
7. Java中“==”和equals的区别?
- ==是基本运算符,可以对基本类型进行比较,比较的是对象的引用是否指向同一块内存地址。
- equals()是一个方法,它不可以可以对基本类型进行比较。见源码1,equals()默认的方法中也使用了==,比较的也是对象的地址。见源码2,只不过equals()是一个方法可以对其进行重写,像String、Date、Math、File、包装类等大部分类都重写了Object的equals()方法。重写后的equals()将每个值取出依次对比其内存地址,也可以把它理解为比较整体值是否相等。
重写hashCode遵循的五个条件
在改写equals方法时,也要遵守他们的通用约定(equals方法实现了等价关系):
\1. 自反性:x.equals(x) = true;
\2. 对称性:如果有x.equals(y) = true,那么一定有y.equals(x) = true;
\3. 传递性:对任意的x,y,z。如果有x.equals(y) = y.equals(z) = true,那么一定有x.equals(z)= true;
\4. 一致性:无论多少次调用,x.equals(y)总会返回相同的结果。
\5. 非空性(暂定):所有的对象都必须!=null;
上面的只是理论性的说法,更加具体的做法如下:
\1. 使用==操作符检查“实参是否为指向对象的一个引用”,如果是则返回true;
\2. 使用instanceof操作符检查“实参是否为正确的类型”,如果不是,则返回false;
\3. 将实参装换为正确的类型;
\4. 对于该类中的每一个关键域,检查实参中的域与当前对象中对应的域是否匹配。如果所有测试都成功,则返回true,否则返回false。
\5. 方法完成之后,确定equals方法的对称性,传递性,一致性。
如何使用?
在java虚拟机中,基本类型存储在方法区中的常量池中,同属性同地址,用==即可。但是对于new出来的对象它们存储在堆中,==仅能比较其地址首相等。无法比较真正意义上的相等,用重写的equals方法即可。
public boolean equals(Object obj) {
return (this == obj);
}
源码2. String类源码中重写的equals方法如下:
public boolean equals(Object anObject) {
// 1. 检查是否为同一个对象的引用,如果是直接返回 true;
if (this == anObject) {
return true;
}
/*2.判断anObject是否为String类的实例,如果不是直接返回false,如果是则取值比较大小。
注:instanceof 测试一个对象是否为一个类的实例
**/
if (anObject instanceof String) {
String anotherString = (String)anObject;
int n = value.length;
if (n == anotherString.value.length) {
char v1[] = value;
char v2[] = anotherString.value;
int i = 0;
while (n-- != 0) {
if (v1[i] != v2[i])
return false;
i++;
}
return true;
}
}
return false;
}
为什么会出现以下现象?
//1. 比较基本类型
int m=1;
int n=1;
// System.out.println(m.equals(n)); // 报错
System.out.println(m == n); // true
//System.out.println(m.hashCode()); // 报错
//System.out.println(n.hashcode()); // 报错
//2. 比较new出来的封装类型
Integer x = new Integer(1);
Integer y = new Integer(1);
System.out.println(x.equals(y)); // true
System.out.println(x == y); // false
//3. 比较非new封装类型 [-128, 127]
Integer x1 = 127;
Integer y1 = 127;
System.out.println(x1.equals(y1)); // true
System.out.println(x1 == y1); // true
//4. 比较非new封装类型非[-128, 127]
Integer x2 = 128;
Integer y2 = 128;
System.out.println(x2.equals(y2)); // true
System.out.println(x2 == y2); // false
//5. 比较非new字符串
String s1="abc";
String s2="abc";
System.out.println(s1==s2); // true
System.out.println(s1.equals(s2)); // true
//6. 比较new字符串
String str1 = new String("hello");
String str2 = new String("hello");
System.out.println(str1.equals(str2)); //true
System.out.println(str1==str2); //false
1. 比较基本类型
对于基本数据类型(byte,short,char,int,float,double,long,boolean)来说,他们是作为常量在方法区中的常量池里面以HashSet策略(HashSet中不允许有重复的元素)存储起来的。因此在常量池,一个常量只会对应一个地址。所以不管是再多的 1,其内存地址都为同一个。
2. 比较new出来的封装类型
new String(“hello”)会在堆内存中创建一个实例,开辟新的内存空间,故==为falsie。但是源码2中,String类源码中重写了equals方法,对单个值的进行比较。
3. 比较非new封装类型 [-128, 127]
4. 比较非new封装类型非[-128, 127]
对于两个非 new 生成的 Integer 对象进行比较时,如果两个变量的值在区间 [-128, 127] 之间,则比较结果为 true,否则为 false。Java 在编译 Integer i = 100 时,会编译成 Integer i = Integer.valueOf(100),而 Integer 类型的 valueOf 的源码如下所示:
public static Integer valueOf(int var0) {
return var0 >= -128 && var0 <= Integer.IntegerCache.high ? Integer.IntegerCache.cache[var0 + 128] : new Integer(var0);
}
从上面的代码中可以看出:Java 对于 [-128, 127] 之间的数会进行缓存,比如:Integer i = 127,会将 127 进行缓存,下次再写 Integer j = 127 的时候,就会直接从缓存中取出,而对于这个区间之外的数就需要 new 了。
5. 比较字符串
在Java执行时会维护一个String池(pool),对于一些可以共享的字符串对象,会先在String池中查找是否存在相同的String内容(字符相同),如果有就直接返回,不创建新对象。
6. 比较非new字符串常量
new String(“hello”)会在堆内存中创建一个实例,开辟新的内存空间,故==为falsie。但是,String类源码中重写了equals方法,对单个值的进行比较。
8. 为什么重写equals一定要重写hashcode?
link1,link2,link3,link4,link5,link6
主要是为了提升哈希表的性能。因为HashMap 集合类使用了 hashCode() 方法来计算对象在哈希表中应该存储的位置,如果不重写hashcode值一样的对象。因为new出来的对象即使值相同,存储地址必不相同。不重写 hashCode会导致为值相同的对象分别了两个存储空间,导致了空间浪费。因此要重写。
以下是关于hashcode的一些性质:
两个对象相等,hashcode一定相等
两个对象不等,hashcode不一定不等
hashcode相等,两个对象不一定相等
hashcode不等,两个对象一定不等
9. Java中抽象类和接口的区别?
link
从设计层面上看,抽象类提供了一种 IS-A 关系,需要满足里式替换原则,即子类对象必须能够替换掉所有父类对象。而接口更像是一种 LIKE-A 关系,它只是提供一种方法实现契约,并不要求接口和实现接口的类具有 IS-A 关系。接口反应能力,抽象类提供默认实现,方便子类实现接口。
(1)抽象类中可以定义构造函数,接口不能定义构造函数;
(2)接口可以被看作是抽象类的变体,接口中所有的方法都是抽象的(Java 1.8中可以定义default方法体)。
(3)从使用上来看,一个类可以实现多个接口,但是不能继承多个抽象类。
(4)接口的字段只能是 static 和 final 类型的,而抽象类的字段没有这种限制。
(5)接口的成员只能是 public 的,而抽象类的成员除了不能被private修饰,可以有多种访问权限。
共同点:抽象类和接口都不能被实例化
什么是抽象类?什么是抽象方法?
抽象类:抽象类就是不能使用new方法进行实例化的类,即没有具体实例对象的类,抽象类有点类似于“模板”的作用,目的是根据其格式来创建和修改新的类,对象不能由抽象类直接创建,只可以通过抽象类派生出新的子类,再由其子类来创建对象,当一个类被声明为抽象类时,要在这个类前面加上修饰符abstract,在抽象类中的成员方法可以包括一般方法和抽象方法
抽象方法:抽象方法就是以abstract修饰的方法,这种方法只声明返回的数据类型,方法名称和所需要的参数,没有方法体,也就是说抽象方法只需要声明而不需要事先,当一个方法为抽象方法时,意味着这个方法必须被子类的方法所重写,否则其子类的该方法仍然是abstract的,而这个子类也必须是抽象的,即声明为abstract。
原文链接:https://blog.csdn.net/dulijie/article/details/88256415
构造函数 ,是一种特殊的方法。主要用来在创建对象时初始化对象, 即为对象成员变量赋初始值,总与new运算符一起使用在创建对象的语句中。特别的一个类可以有多个构造函数 ,可根据其参数个数的不同或参数类型的不同来区分它们 即构造函数的重载。
为什么接口中的成员变量非得是public static final的呢?
首先明白一个原理,就是接口的存在意义。接口就是为了实现多继承的抽象类,是一种高度抽象的模板、标准或者说协议。规定了什么东西该是这样,如果你继承了我这接口,就必须这样。比如USB接口,就是小方口,两根电源线和两根数据线,不能多不能少。
public: 使接口的实现类可以使用这个常量
static:static修饰就表示它属于类的,随的类的加载而存在的,如果是非static的话,就表示属于对象的,只有建立对象时才有它,而接口是不能建立对象的,所以接口的常量必须定义为static。
final:final修饰就是保证接口定义的常量不能被实现类去修改,如果没有final的话,
由子类随意去修改的话,接口建立这个常量就没有意义了。https://blog.csdn.net/u013682953/article/details/73699796
https://blog.csdn.net/piyongduo3393/article/details/85225294
10. final finally finalize 区别及用法?
(https://www.cnblogs.com/wisefulman/p/10584515.html)
final:可以用来修饰类、方法、变量,分别有不同的意义,final修饰的class代表不可以继承扩展,final的变量是不可以修改的,而final的方法也是不可以重写的(override)。
finally:则是Java保证重点代码一定要被执行的一种机制。我们可以使用try-finally或者try-catch-finally来进行类似关闭JDBC连接、保证unlock锁等动作。
finalize:是基础类java.lang.Object的一个方法,它的设计目的是保证对象在被垃圾收集前完成特定资源的回收。允许使用finalize()方法在垃圾收集器将对象从内存中清楚出去之前做必要的清理工作。finalize机制现在已经不推荐使用,并且在JDK 9开始被标记为deprecated。
链接:https://www.jianshu.com/p/afaf54b9632e
**final实现原理:**https://www.cnblogs.com/hexinwei1/p/10025840.html
对于final域,编译器和处理器要遵守两个重排序规则:
1.在构造函数内对一个final域的写入,与随后把这个被构造对象的引用赋值给一个引用变量,这两个操作之间不能重排序。(先写入final变量,后调用该对象引用)
**原因:**编译器会在final域的写之后,插入一个StoreStore屏障
2.初次读一个包含final域的对象的引用,与随后初次读这个final域,这两个操作之间不能重排序(先读对象的引用,后读final变量)
**原因:**编译器会在读final域操作的前面插入一个LoadLoad屏障
11. this和super的区别
https://www.cnblogs.com/newbie27/p/10437587.html
https://blog.csdn.net/lncsdn_123/article/details/79025525
this是自身的一个对象,代表对象本身,可以理解为:指向对象本身的一个指针;
super可以理解为是指向自己超(父)类对象的一个指针,而这个超类指的是离自己最近的一个父类。
13 泛型
https://segmentfault.com/a/1190000014120746
泛型:把类型明确的工作推迟到创建对象或调用方法之后,简单来说,你有一个类,在使用时内部类型暂不确定,给使用给一个占位符给代替,在使用的时候可以给确定其定义的类型。例如HashMap等集合类中就用到了泛型:
ArrayList<String> stringValues=new ArrayList<String>();
有了泛型以后:
- 代码更加简洁【不用强制转换】
- 程序更加健壮【只要编译时期没有警告,那么运行时期就不会出现ClassCastException异常】
- 可读性和稳定性【在编写集合的时候,就限定了类型】
https://www.jianshu.com/p/2bfbe041e6b7
泛型底层如何实现?Java的泛型是使用类型擦除来实现的,意味着当你在使用泛型时,任何具体的类型信息都被擦除了,你唯一知道的就是你在使用一个对象。
泛型用于编译阶段,编译后的字节码文件不包含泛型类型信息,因为虚拟机没有泛型类型对象,所有对象都属于普通类。例如定义
List<Object>或List<String>,在编译后都会变成List。定义一个泛型类型,会自动提供一个对应原始类型,类型变量会被擦除。如果没有限定类型就会替换为 Object,如果有限定类型就会替换为第一个限定类型,例如
<T extends A & B>会使用 A 类型替换 T。ava语言的泛型采用的是擦除法实现的伪泛型,泛型信息(类型变量、参数化类型)编译之后通通被除掉了。使用擦除法的好处就是实现简单、非常容易Backport,运行期也能够节省一些类型所占的内存空间。而擦除法的坏处就是,通过这种机制实现的泛型远不如真泛型灵活和强大。Java选取这种方法是一种折中,因为Java最开始的版本是不支持泛型的,为了兼容以前的库而不得不使用擦除法。
14. 常用注解
https://www.cnblogs.com/yanze/p/9481915.html
注解提升了java语言的表达能力,有效实现了应该用功能和底层功能的分离。
java内置注解
@Override
覆盖父类方法
@Deprecated(不赞成)
用于方法,表明方法已过期,不建议使用
@Suppvisewarning
忽略警告,例如当我们要使用已过时方法,有的编译器会出现警告,
@Suppvisewarning(“deprecation”)表示忽略此警告
元注解是自定义注解的注解,例如:
@Target:约束作用位置,值是 ElementType 枚举常量,包括 METHOD 方法、VARIABLE 变量、TYPE 类/接口、PARAMETER 方法参数、CONSTRUCTORS 构造方法和 LOACL_VARIABLE 局部变量等。
@Rentention:约束生命周期,值是 RetentionPolicy 枚举常量,包括 SOURCE 源码、CLASS 字节码和 RUNTIME 运行时。
@Documented:表明这个注解应该被 javadoc 记录。
15. JDK1.8中有哪些新特性?
link
- Lambda表达式:Lambda允许把函数作为一个方法的参数(函数作为参数传递到方法中)。
- 方法引用:方法引用提供了非常有用的语法,可以直接引用已有Java类或对象(实例)的方法或构造器。与lambda联合使用,方法引用可以使语言的构造更紧凑简洁,减少冗余代码。
- 默认方法:默认方法就是一个在接口里面有了一个实现的方法。
- 新工具:新的编译工具,如:Nashorn引擎 jjs、 类依赖分析器jdeps。
- Stream API:新添加的Stream API(java.util.stream) 把真正的函数式编程风格引入到Java中。
- Date Time API:加强对日期与时间的处理。
- Optional类:Optional 类已经成为 Java 8 类库的一部分,用来解决空指针异常。
- Nashorn,JavaScript引擎:JDK1.8提供了一个新的Nashorn javascript引擎,它允许我们在JVM上运行特定的javascript应用。
16. Java对象的hashCode方法理解
**概念:**Object类中有一个方法: public native int hashCode(); Java中的hashCode方法就是根据一定的规则将与对象相关的信息(比如对象的存储地址,对象的字段等)映射成一个数值,这个数值称作为散列值。
作用:
- 用于查找的快捷性。如HashMap,hashCode值用于散列来确定对象hash到哪个slot
- 减少equals方法的调用次数,从而提高程序效率。如在集合中两个对象相等判断时,先比较hashCode方法的值,相等再调用equals方法,所以在对象不相等时直接hashCode不等判断结束,减少equals方法的调用。当然也存在对象不相等但hashCide值相等的情况,如:
"wzd".hashCode()=="x[d".hashCode()
HashCode约定:
- 在程序执行期间,只要equals方法的比较操作用到的信息没有被修改,那么对这同一个对象调用多次,hashCode方法必须始终如一地返回同一个整数。
- 如果两个对象根据equals方法比较是相等的,那么调用两个对象的hashCode方法必须返回相同的整数结果。
- 如果两个对象根据equals方法比较是不等的,则hashCode方法不一定要返回不同的整数。但是,为不相等的对象生成不同hashCode可以提高hash的性能,减少冲突。
17.Object o=new object()在中占用多少字节?
https://blog.csdn.net/weixin_42864905/article/details/104966716
Klass Word 这里其实是虚拟机设计的一个oop-klass model模型,这里的OOP是指Ordinary Object Pointer(普通对象指针),看起来像个指针实际上是藏在指针里的对象。而 klass 则包含 元数据和方法信息,用来描述 Java 类。它在64位虚拟机开启压缩指针的环境下占用 32bits 空间。
Mark Word 是我们分析的重点,这里也会设计到锁的相关知识。Mark Word 在64位虚拟机环境下占用 64bits 空间。整个Mark Word的分配有几种情况:
-
未锁定(Normal): 哈希码(identity_hashcode)占用31bits,分代年龄(age)占用4 bits,偏向模式(biased_lock)占用1 bits,锁标记(lock)占用2 bits,剩余26bits 未使用(也就是全为0)
-
可偏向(Biased): 线程id 占54bits,epoch 占2 bits,分代年龄(age)占用4 bits,偏向模式(biased_lock)占用1 bits,锁标记(lock)占用2 bits,剩余 1bit 未使用。
-
轻量锁定(Lightweight Locked): 锁指针占用62bits,锁标记(lock)占用2 bits。
-
重量级锁定(Heavyweight Locked):锁指针占用62bits,锁标记(lock)占用2 bits。
-
GC 标记:标记位占2bits,其余为空(也就是填充0)
以上就是我们对Java对象头内存模型的解析,只要是Java对象,那么就肯定会包括对象头,也就是说这部分内存占用是避免不了的。所以,在笔者64位虚拟机,Jdk1.8(开启了指针压缩)的环境下,任何一个对象,啥也不做,只要声明一个类,那么它的内存占用就至少是96bits,也就是至少12字节。
内存对齐:4个字节,保证可以被8整除。内存对齐
想要知道为什么虚拟机要填充4个字节,我们需要了解什么是内存对齐?
我们程序员看内存是这样的:
上图表示一个坑一个萝卜的内存读取方式。但实际上 CPU 并不会以一个一个字节去读取和写入内存。相反 CPU 读取内存是一块一块读取的,块的大小可以为 2、4、6、8、16 字节等大小。块大小我们称其为内存访问粒度。如下图:
假设一个32位平台的 CPU,那它就会以4字节为粒度去读取内存块。那为什么需要内存对齐呢?主要有两个原因:
平台(移植性)原因:不是所有的硬件平台都能够访问任意地址上的任意数据。例如:特定的硬件平台只允许在特定地址获取特定类型的数据,否则会导致异常情况。
性能原因:若访问未对齐的内存,将会导致 CPU 进行两次内存访问,并且要花费额外的时钟周期来处理对齐及运算。而本身就对齐的内存仅需要一次访问就可以完成读取动作。
我用图例来说明 CPU 访问非内存对齐的过程:
在上图中,假设CPU 是一次读取4字节,在这个连续的8字节的内存空间中,如果我的数据没有对齐,存储的内存块在地址1,2,3,4中,那CPU的读取就会需要进行两次读取,另外还有额外的计算操作:
- CPU 首次读取未对齐地址的第一个内存块,读取 0-3 字节。并移除不需要的字节 0。
- CPU 再次读取未对齐地址的第二个内存块,读取 4-7 字节。并移除不需要的字节 5、6、7 字节。
- 合并 1-4 字节的数据。
- 合并后放入寄存器。
所以,没有进行内存对齐就会导致CPU进行额外的读取操作,并且需要额外的计算。如果做了内存对齐,CPU可以直接从地址0开始读取,一次就读取到想要的数据,不需要进行额外读取操作和运算操作,节省了运行时间。我们用了空间换时间,这就是为什么我们需要内存对齐。
回到Java空对象填充了4个字节的问题,因为原字节头是12字节,64位机器下,内存对齐的话还需要填充4个字节就是128位,也就是16字节。
数组:最小是24个字节 8+4+4+4+8
非空对象占用内存计算:TestNotNull的类占用空间是24字节,其中头部占用12字节,变量a是int类型,占用4字节,变量nullObject是引用,占用了4字节,最后填充了4个字节,总共是24个字节,与我们之前的预测一致。但是,因为我们实例化了NullObject,这个对象一会存在于内存中,所以我们还需要加上这个对象的内存占用16字节,那总共就是24bytes+16bytes=40bytes。我们图中最后的统计打印结果也是40字节,所以我们的分析正确。
18. JDK, JRE 和JVM的区别
https://www.cnblogs.com/xiaofeixiang/p/4085159.html
JDK(Java Development Kit)简单理解就是Java开发工具包,JRE(Java Runtime Enviroment)是Java的运行环境,JVM( java virtual machine)也就是常常听到Java虚拟机。JDK是面向开发者的,JRE是面向使用JAVA程序的用户。
Java 开发工具包 (JDK)
Java开发工具包是Java环境的核心组件,并提供编译、调试和运行一个Java程序所需的所有工具,可执行文件和二进制文件。JDK是一个平台特定的软件,有针对Windows,Mac和Unix系统的不同的安装包。可以说JDK是JRE的超集,它包含了JRE的Java编译器,调试器和核心类。目前JDK的版本号是1.7,也被称为Java 7。
Java虚拟机(JVM)
JVM是Java编程语言的核心。当我们运行一个程序时,JVM负责将字节码转换为特定机器代码。JVM也是平台特定的,并提供核心的Java方法,例如内存管理、垃圾回收和安全机制等。JVM 是可定制化的,我们可以通过Java 选项(java options)定制它,比如配置JVM 内存的上下界。JVM之所以被称为虚拟的是因为它提供了一个不依赖于底层操作系统和机器硬件的接口。这种独立于硬件和操作系统的特性正是Java程序可以一次编写多处执行的原因。
Java运行时环境(JRE)
JRE是JVM的实施实现,它提供了运行Java程序的平台。JRE包含了JVM、Java二进制文件和其它成功执行程序的类文件。JRE不包含任何像Java编译器、调试器之类的开发工具。如果你只是想要执行Java程序,你只需安装JRE即可,没有安装JDK的必要。
JDK, JRE 和JVM的区别
- JDK是用于开发的而JRE是用于运行Java程序的。
- JDK和JRE都包含了JVM,从而使得我们可以运行Java程序。
- JVM是Java编程语言的核心并且具有平台独立性。
即时编译器(JIT)
有时我们会听到JIT这个概念,并说它是JVM的一部分,这让我们很困惑。JIT是JVM的一部分,它可以在同一时间编译类似的字节码来优化将字节码转换为机器特定语言的过程相似的字节码,从而将优化字节码转换为机器特定语言的过程,这样减少转换过程所需要花费的时间。
19. IO流?
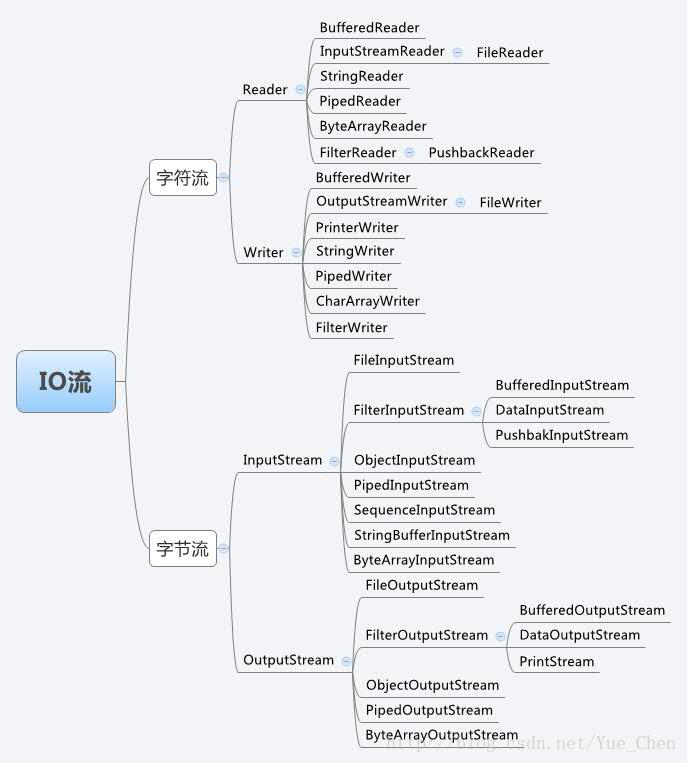
主要分为字符流和字节流,字符流一般用于文本文件,字节流一般用于图像或其他文件。
字符流包括了字符输入流 Reader 和字符输出流 Writer,字节流包括了字节输入流 InputStream 和字节输出流 OutputStream。字符流和字节流都有对应的缓冲流,字节流也可以包装为字符流,缓冲流带有一个 8KB 的缓冲数组,可以提高流的读写效率。除了缓冲流外还有过滤流 FilterReader、字符数组流 CharArrayReader、字节数组流 ByteArrayInputStream、文件流 FileInputStream 等。
20. 序列化和反序列化是什么?
Java 对象 JVM 退出时会全部销毁,如果需要将对象及状态持久化,就要通过序列化实现,将内存中的对象保存在二进制流中,需要时再将二进制流反序列化为对象。对象序列化保存的是对象的状态,因此属于类属性的静态变量不会被序列化。
常见的序列化有三种:
-
Java 原生序列化
实现
Serializabale标记接口,Java 序列化保留了对象类的元数据(如类、成员变量、继承类信息)以及对象数据,兼容性最好,但不支持跨语言,性能一般。序列化和反序列化必须保持序列化 ID 的一致,一般使用private static final long serialVersionUID定义序列化 ID,如果不设置编译器会根据类的内部实现自动生成该值。如果是兼容升级不应该修改序列化 ID,防止出错,如果是不兼容升级则需要修改。 -
Hessian 序列化
Hessian 序列化是一种支持动态类型、跨语言、基于对象传输的网络协议。Java 对象序列化的二进制流可以被其它语言反序列化。Hessian 协议的特性:① 自描述序列化类型,不依赖外部描述文件,用一个字节表示常用基础类型,极大缩短二进制流。② 语言无关,支持脚本语言。③ 协议简单,比 Java 原生序列化高效。Hessian 会把复杂对象所有属性存储在一个 Map 中序列化,当父类和子类存在同名成员变量时会先序列化子类再序列化父类,因此子类值会被父类覆盖。
-
JSON 序列化
JSON 序列化就是将数据对象转换为 JSON 字符串,在序列化过程中抛弃了类型信息,所以反序列化时只有提供类型信息才能准确进行。相比前两种方式可读性更好,方便调试。
序列化通常会使用网络传输对象,而对象中往往有敏感数据,容易遭受攻击,Jackson 和 fastjson 等都出现过反序列化漏洞,因此不需要进行序列化的敏感属性传输时应加上 transient 关键字。transient 的作用就是把变量生命周期仅限于内存而不会写到磁盘里持久化,变量会被设为对应数据类型的零值。
【克隆】
[1] 深克隆和浅克隆的区别?
浅拷贝:浅克隆只是复制了对象的引用地址。是将原始对象中的数据型字段拷贝到新对象中去,将引用型字段的“引用”复制到新对象中去,不把“引用的对象”复制进去,所以原始对象和新对象引用同一对象,新对象中的引用型字段发生变化会导致原始对象中的对应字段也发生变化。
深拷贝:深拷贝是将对象及值复制过来,两个对象修改其中任意的值另一个值不会改变。是在引用方面不同,深拷贝就是创建一个新的和原始字段的内容相同的字段,是两个一样大的数据段,所以两者的引用是不同的,之后的新对象中的引用型字段发生改变,不会引起原始对象中的字段发生改变。
[2] 如何实现对象的克隆?
(1)实现 Cloneable 接口并重写 Object 类中的 clone() 方法;
(2)实现 Serializable 接口,通过对象的序列化和反序列化实现克隆,可以实现真正的深克隆。
[3] 数组的四种拷贝方式对比
https://blog.csdn.net/weixin_42220532/article/details/84200634
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cYrg2D7n-1596593286551)(X:\Users\xu\AppData\Roaming\Typora\typora-user-images\image-20200628205703300.png)]
对于基本数据类型来说可以理解为是深拷贝,对于引用类型来说是浅拷贝,它们拷贝的是引用,和被拷贝的引用指向同一个对象。
link1,link2
[4] 数组的四种拷贝方式实现
package 其他;
import java.util.Arrays;
public class 数组的四种拷贝方式 {
public static void main(String[] args) {
for_copy();
clone_copy();
arraycopy_copy();
ArrayscopyOf_copy();
}
/**
* for循环拷贝数组
*/
public static void for_copy() {
//一维数组的拷贝
int[] array1={1,2,3,4,5,6,7};
int[] array2=new int[array1.length];
for(int i = 0;i < array1.length;i++){
array2[i] = array1[i];
}
System.out.println(Arrays.toString(array2));
//二维数组的拷贝
int[][] array3= {{1,2,3},{4,5,6}};
int[][] array4 = new int[2][3];
for(int i = 0;i < array3.length;i++){
for(int j = 0;j < array3[i].length;j++){
array4[i][j] = array3[i][j];
}
}
System.out.println(Arrays.deepToString(array4));
}
/**
* clone拷贝数组
*/
public static void clone_copy() {
//一维数组的拷贝
int[] array1={1,2,3,5,9,8,7};
int[] array2=new int[array1.length];
array2=array1.clone();
System.out.println(Arrays.toString(array2));
//二维数组的拷贝
int[][] array3={{1,2,3,4},{5,6,7}};
int[][] array4=new int[2][];
for(int i = 0;i < array3.length;i++){
array4[i] = array3[i].clone();
}
for(int i=0;i<array3.length;i++){
System.out.print(Arrays.toString(array4[i]));
}
}
/**
* System.arraycopy拷贝数组
*/
public static void arraycopy_copy() {
//一维数组的拷贝
int[] array = {1,2,3,4,5};
int[] array2 = new int[array.length];
System.arraycopy(array, 0, array2, 0, array.length);//(被复制的数组,从几号下标开始复制,复制到哪个数组,复制到新数组第几号下标,复制长度)
System.out.println(Arrays.toString(array2));
//二维数组的拷贝
int[][] array1={{1,2,3,5,9},{2,3,36,5,7}};
int[][] array3=new int[2][5];
for(int i=0;i<array1.length;i++){
System.arraycopy(array1[i], 0, array3[i], 0, array1[i].length);
}
System.out.println(Arrays.deepToString(array3));
}
/**
* Arrays.copyOf拷贝数组
*/
public static void ArrayscopyOf_copy() {
//一维数组的拷贝
int[] array=new int[4];
System.out.println(Arrays.toString(array));
int[] array1 = new int[4];
array1 = Arrays.copyOf(array,array.length);//将数组array拷贝到数组brr,拷贝长度为array.length
System.out.println(Arrays.toString(array1));
//一维数组的拷贝
int[][] array2={{1,2,3,4},{2,6,7,5}};
int[][] array3=new int[2][4];
array3=Arrays.copyOf(array2, array2.length);
System.out.println(Arrays.deepToString(array3));
}
}
【static】
[1] static关键词的原理?

我们可以一句话来概括:方便在没有创建对象的情况下来进行调用,被他修饰的会在java虚拟机的方法区内,被static关键字修饰的不需要创建对象去调用,直接根据类名就可以去访问。静态变量存放在方法区中,并且是被所有线程所共享的。
[2] Java中static关键词的作用?
(1)静态变量:又称为类变量,也就是说这个变量属于类的,类所有的实例都共享静态变量,可以直接通过类名来访问它。静态变量在内存中只存在一份;
(2)静态方法:可以直接通过类名来进行调用。静态方法在类加载的时候就存在了,它不依赖于任何实例。所以静态方法必须有实现,也就是说它不能是抽象方法。只能访问所属类的静态字段和静态方法(因为非静态方法是随着对象实例化才有的,调用它可能会出现错误),方法中不能有 this 和 super 关键字;
main 方法就是静态方法
(3)静态内部类:static关键字修饰类,普通类是不允许声明为静态的,只有内部类才可以。非静态内部类依赖于外部类的实例,而静态内部类不需要。静态内部类不能访问外部类的非静态的变量和方法;
(4)静态语句块:静态语句块在类初始化时运行一次;
初始化顺序:静态变量和静态语句块优先于实例变量和普通语句块,静态变量和静态语句块的初始化顺序取决于它们在代码中的顺序。
https://baijiahao.baidu.com/s?id=1636927461989417537&wfr=spider&for=pc
https://www.cnblogs.com/w-wfy/p/7118494.html
[3] 为什么静态成员和方法中不能用this和super关键字?
-
因为this代表的是调用这个函数的对象的引用,而静态方法是属于类的,不属于对象,静态方法成功加载后,对象还不一定存在
-
super的用法跟this类似,this代表对本类对象的引用,指向本类已经创建的对象;而super代表对父类对象的引用,指向父类对象;
2.静态优先于对象存在; -
因为静态优先于对象存在,所以方法被静态修饰之后方法先存在,而方法里面要用到super指向的父类对象,但是所需的父类引用对象晚于该方法出现,也就是super所指向的对象没有,当然就会出错。
【异常处理】
[1] try和catch
https://blog.csdn.net/qq_34427165/article/details/83929470
[2] Error 和 Exception 的区别?
Error 类和 Exception 类的父类都是 Throwable 类。主要区别如下:
Error 类: 一般是指与虚拟机相关的问题,如:系统崩溃、虚拟机错误、内存空间不足、方法调用栈溢出等。这类错误将会导致应用程序中断,仅靠程序本身无法恢复和预防;
Exception 类:分为运行时异常和受检查的异常。
[3] 运行时异常与受检异常有何异同?
运行时异常:如:空指针异常、指定的类找不到、数组越界、方法传递参数错误、数据类型转换错误。可以编译通过,但是一运行就停止了,程序不会自己处理;
受检查异常:要么用 try … catch… 捕获,要么用 throws 声明抛出,交给父类处理。
[4] throw 和 throws 的区别?
(1)throw:在方法体内部,表示抛出异常,由方法体内部的语句处理;throw 是具体向外抛出异常的动作,所以它抛出的是一个异常实例;
(2)throws:在方法声明后面,表示如果抛出异常,由该方法的调用者来进行异常的处理;表示出现异常的可能性,并不一定会发生这种异常。
[5] 常见的异常类有哪些?
NullPointerException:当应用程序试图访问空对象时,则抛出该异常。
SQLException:提供关于数据库访问错误或其他错误信息的异常。
IndexOutOfBoundsException:指示某排序索引(例如对数组、字符串或向量的排序)超出范围时抛出。
FileNotFoundException:当试图打开指定路径名表示的文件失败时,抛出此异常。
IOException:当发生某种 I/O 异常时,抛出此异常。此类是失败或中断的 I/O 操作生成的异常的通用类。
ClassCastException:当试图将对象强制转换为不是实例的子类时,抛出该异常。
IllegalArgumentException:抛出的异常表明向方法传递了一个不合法或不正确的参数。
[补充]
所有异常都是 Throwable 的子类,分为 Error 和 Exception。
Error 是 Java 运行时系统的内部错误和资源耗尽错误,例如 StackOverFlowError 和 OutOfMemoryError,这种异常程序无法处理。
Exception 分为受检异常和非受检异常,受检异常需要在代码中显式处理,否则会编译出错,非受检异常是运行时异常,继承自 RuntimeException。
受检异常:① 无能为力型,如字段超长导致的 SQLException。② 力所能及型,如未授权异常 UnAuthorizedException,程序可跳转权限申请页面。常见受检异常还有 FileNotFoundException、ClassNotFoundException、IOException等。
非受检异常:① 可预测异常,例如 IndexOutOfBoundsException、NullPointerException、ClassCastException 等,这类异常应该提前处理。② 需捕捉异常,例如进行 RPC 调用时的远程服务超时,这类异常客户端必须显式处理。③ 可透出异常,指框架或系统产生的且会自行处理的异常,例如 Spring 的 NoSuchRequestHandingMethodException,Spring 会自动完成异常处理,将异常自动映射到合适的状态码。
【反射】
[1] 为什么有反射机制?
程序运行时,允许改变程序结构或变量类型,这种语言称为动态语言,像是python。JAVA的反射机制就是为了实现这种功能。
[2] 什么是反射机制?
反射机制是指在一个类在运行中,对于任意一个类,都能够知道这个类的所有属性和方法,且都能够调用它的任意一个方法和属性。即动态获取信息和动态调用对象方法的功能称为反射机制。
[3] 反射如何实现的?
每个类都有一个 Class 对象,包含了与类有关的信息。当编译一个新类时,会产生一个同名的 .class 文件,该文件内容保存着 Class 对象。类加载相当于 Class 对象的加载。
[4] 如何获取 Class 对象
① 类名.class 。②对象的 getClass方法。③ Class.forName(类的全限定名)。
(1)通过类名称.class来获取Class类对象:
Class c = int.class;
Class c = int[ ].class;
Class c = String.class
(2)通过**对象.getClass( )**方法来获取Class类对象:
Class c = obj.getClass( );
(3)通过类名称加载类Class.forName( ),只要有类名称就可以得到Class:
Class c = Class.forName(“cn.ywq.Demo”);
[5] 反射机制的作用
- 在运行时判断任意一个对象所属的类
- 在运行时构造一个类的对象
- 在运行时判断任意一个类所具有的成员变量和方法
- 在运行时调用任意一个对象的方法,生成动态代(dai)理
[6] 反射相关的类
反射可以提供运行时的类信息,并且这个类可以在运行时才加载进来,甚至在编译时期该类的 .class 不存在也可以加载进来。Class 和 java.lang.reflect 一起对反射提供了支持,java.lang.reflect 类库主要包含了以下三个类:
(1)Field :可以使用 get() 和 set() 方法读取和修改 Field 对象关联的字段;
(2)Method :可以使用 invoke() 方法调用与 Method 对象关联的方法;
(3)Constructor :可以用 Constructor 创建新的对象。
[7] 反射的优缺点?
**优点:**运行期类型的判断,class.forName() 动态加载类,提高代码的灵活度;
**缺点:**尽管反射非常强大,但也不能滥用。如果一个功能可以不用反射完成,那么最好就不用。在我们使用反射技术时,下面几条内容应该牢记于心。
(1)性能开销 :反射涉及了动态类型的解析,所以 JVM 无法对这些代码进行优化。因此,反射操作的效率要比那些非反射操作低得多。我们应该避免在经常被执行的代码或对性能要求很高的程序中使用反射。
(2)安全限制 :使用反射技术要求程序必须在一个没有安全限制的环境中运行。如果一个程序必须在有安全限制的环境中运行,如 Applet,那么这就是个问题了。
(3)内部暴露:由于反射允许代码执行一些在正常情况下不被允许的操作(比如:访问私有的属性和方法),所以使用反射可能会导致意料之外的副作用,这可能导致代码功能失调并破坏可移植性。反射代码破坏了抽象性,因此当平台发生改变的时候,代码的行为就有可能也随着变化。
(4) 破坏了封装性以及泛型约束
【代理】
link
[1] 什么是代理模式?
代理是一种设计模式,它的核心思想,是将对目标的访问转移到代理对象上。这样做的好处就是,目标对象在不改变代码的情况下,可以通过代理对象加一些额外的功能。这是一种编程思想,在不改变原有代码的情况下,通过代理增加一些扩展功能。
代理过程如图所示,用户访问代理对象,代理对象通过访问目标对象,来达到用户访问目标对象的目的
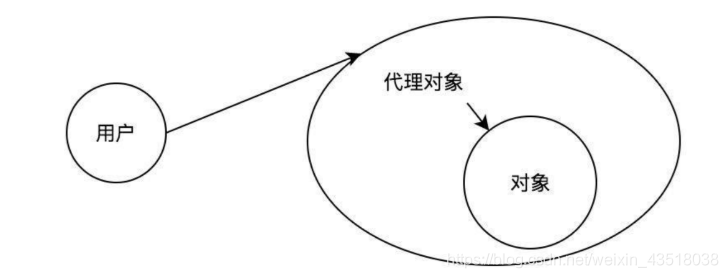
代理模式包含一下三个角色:
- ISubject:接口对象,该接口是对象和它的代理共用的接口。
- TargetSubject:目标对象,是实现抽象主题接口的类。
- Proxy:代理角色,内部含有对目标对象TargetSubject的引用,从而可以操作真实对象。代理对象提供与目标对象相同的接口,以便在任何时刻都能代替目标对象。同时,代理对象可以在执行目标对象操作时,附加其他的操作,相当于对真实对象进行封装。
常见的代理模式分为静态代理和动态代理,动态代理在Java中的实现分为JDK动态代理和cglib代理。
[2] 什么是静态代理?
1,2,3,4
静态代理:由程序员创建或工具生成代理类的源码,再编译代理类,即代理类和委托类的关系再程序运行前就已经存在。
[3] 什么是动态代理?如何实现?
动态代理:在运行期间使用动态生成字节码形式,动态创建代理类。使用的工具有 jdkproxy、cglibproxy 等。
动态代理的实现方式是借助java.lang.Reflect.Proxy进行反射实现的,其步骤如下:
a、编写一个委托类接口,对应的静态代理的Subject接口
b、编写一个委托类接口的实现类,对应的是静态代理的RealSubject
c、创建动态代理类方法调用处理程序,实现InvocationHandler接口,并重写invoke方法
d、在测试类中生成动态代理对象
链接:https://www.jianshu.com/p/85d181d7d09a
[4] 静态代理和动态代理有什么区别?
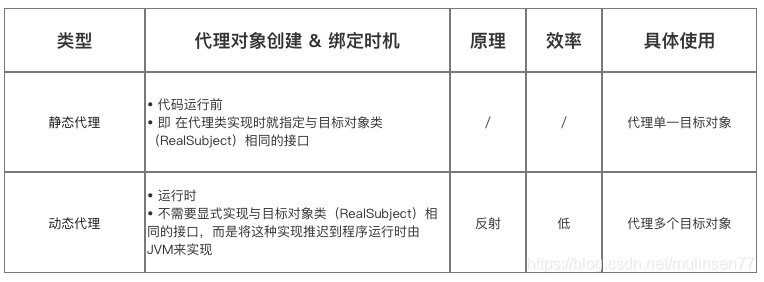
动态代理的应用:Spring 的 AOP 、加事务、加权限、加日志。
[5] 怎么实现动态代理?
https://cloud.tencent.com/developer/article/1009203
Jdk动态对象
Jdk的动态代理由Proxy这个类来生成,注意该方法是在Proxy类中是静态方法,且接收的三个参数依次为:
ClassLoader loader,:指定当前目标对象使用类加载器,获取加载器的方法是固定的Class<?>[] interfaces,:目标对象实现的接口的类型,使用泛型方式确认类型InvocationHandler h😗*事件处理,**执行目标对象的方法时,会触发事件处理器的方法,会把当前执行目标对象的方法作为参数传入
CGLib动态代理
CGLib采用了非常底层的字节码技术,其原理是通过字节码技术为一个类创建子类,并在子类中采用方法拦截的技术拦截所有父类方法的调用,顺势织入横切逻辑。
上面的静态代理和动态代理模式都是要求目标对象是实现一个接口的目标对象,但是有时候目标对象只是一个单独的对象,并没有实现任何的接口,这个时候就可以使用以目标对象子类的方式类实现代理,这种方法就叫做:Cglib代理
也叫作子类代理,它是在内存中构建一个子类对象从而实现对目标对象功能的扩展.
- JDK的动态代理有一个限制,就是使用动态代理的对象必须实现一个或多个接口,如果想代理没有实现接口的类,就可以使用Cglib实现.
- Cglib是一个强大的高性能的代码生成包,它可以在运行期扩展java类与实现java接口.它广泛的被许多AOP的框架使用,例如Spring AOP和synaop,为他们提供方法的interception(拦截)
- Cglib包的底层是通过使用一个小而块的字节码处理框架ASM来转换字节码并生成新的类.不鼓励直接使用ASM,因为它要求你必须对JVM内部结构包括class文件的格式和指令集都很熟悉.
https://cloud.tencent.com/developer/article/1524189
Cglib子类代理实现方法:
1.需要引入cglib的jar文件,但是Spring的核心包中已经包括了Cglib功能,所以直接引入pring-core-3.2.5.jar即可.
2.引入功能包后,就可以在内存中动态构建子类
3.代理的类不能为final,否则报错
4.目标对象的方法如果为final/static,那么就不会被拦截,即不会执行目标对象额外的业务方法.
Jdk动态对象和CGLib动态代理区别
Jdk SDK面向的是一组接口,他为这些接口创建了一个实现类。cglib代理面对的是一个具体类,搭配创建了一个新类,继承了该类重写了该方法。
[6] 动态代理的应用
链接:https://www.zhihu.com/question/40536038/answer/676236311
动态代理在代码界可是有非常重要的意义,我们开发用到的许多框架都使用到了这个概念。我所知道的就有:Spring AOP、Hibernate、Struts 使用到了动态代理。
- Spring AOP。Spring 最重要的一个特性是 AOP(Aspect Oriented Programming 面向切面编程),利用 Spring AOP 可以快速地实现权限校验、安全校验等公用操作。而 Spring AOP 的原理则是通过动态代理实现的,默认情况下 Spring AOP 会采用 Java 动态代理实现,而当该类没有对应接口时才会使用 CGLib 动态代理实现。
- Hibernate。Hibernate 是一个常用的 ORM 层框架,在获取数据时常用的操作有:get() 和 load() 方法,它们的区别是:get() 方法会直接获取数据,而 load() 方法则会延迟加载,等到用户真的去取数据的时候才利用代理类去读数据库。
- Struts。Struts 现在虽然因为其太多 bug 已经被抛弃,但是曾经用过 Struts 的人都知道 Struts 中的拦截器。拦截器有非常强的 AOP 特性,仔细了解之后你会发现 Struts 拦截器其实也是用动态代理实现的。
[7] Spring如何实现AOP?
https://cloud.tencent.com/developer/article/1524189
- AnnotationAwareAspectJAutoProxyCreator是AOP核心处理类
- AnnotationAwareAspectJAutoProxyCreator实现了BeanProcessor,其中postProcessAfterInitialization是核心方法。
- 核心实现分为2步 getAdvicesAndAdvisorsForBean获取当前bean匹配的增强器 createProxy为当前bean创建代理
- getAdvicesAndAdvisorsForBean核心逻辑如下 a. 找所有增强器,也就是所有@Aspect注解的Bean b. 找匹配的增强器,也就是根据@Before,@After等注解上的表达式,与当前bean进行匹配,暴露匹配上的。 c. 对匹配的增强器进行扩展和排序,就是按照@Order或者PriorityOrdered的getOrder的数据值进行排序,越小的越靠前。
- createProxy有2种创建方法,JDK代理或CGLIB a. 如果设置了proxyTargetClass=true,一定是CGLIB代理 b. 如果proxyTargetClass=false,目标对象实现了接口,走JDK代理 c. 如果没有实现接口,走CGLIB代理
[8] 静态代理和动态代理的区别
很明显的是:
- 静态代理需要自己写代理类–>代理类需要实现与目标对象相同的接口
- 而动态代理不需要自己编写代理类—>(是动态生成的)
使用静态代理时:
- 如果目标对象的接口有很多方法的话,那我们还是得一一实现,这样就会比较麻烦
使用动态代理时:
- 代理对象的生成,是利用JDKAPI,动态地在内存中构建代理对象(需要我们指定创建 代理对象/目标对象 实现的接口的类型),并且会默认实现接口的全部方法。
链接:https://www.zhihu.com/question/40536038/answer/685995295