把原先搭建的集群环境给删除了,自己重新搭建了一次,将笔记整理在这里,方便自己以后查看
第一步:安装主节点spark1
第一个节点:centos虚拟机安装,全名spark1,用户名hadoop,密码123456 ,虚拟机名称spark1
第二步:配置yum源
需经常使用yum安装软件,使用国内网易源速度更快
[root@localhost ~]# mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.backup #备份CentOS-Base.repo.注意是在root用户下
[root@localhost ~]# vi /etc/yum.repos.d/CentOS-Base.repo #创建CentOS-Base.repo文件并根据对应版本添加保存文件内容
使用以下命令生成缓存
[root@localhost yum.repos.d]# yum clean all
[root@localhost yum.repos.d]# yum makecache
配置yum源https://lug.ustc.edu.cn/wiki/mirrors/help/centos
第三步:克隆两个从节点spark2、spark3
第二个节点:全名spark2 用户名hadoop
第三个节点:全名spark3 用户名hadoop
到这里就将spark1、spark2、spark3三个节点初步安装好了
第四步:网卡配置
查看网卡信息
[root@localhost ~]# ifconfig #spark1节点网卡名称是eth0
[root@localhost ~]# ifconfig #spark2节点网卡名称是eth1
[root@localhost ~]# ifconfig #spark3节点网卡名称是eth1
记录自动生成的网卡信息方便修改
spark1
inet addr:192.168.220.144 HWaddr:00:0C:29:01:07:7D
Bcast: 192.168.220.255 Mask: 255.255.255.0spark2
inet addr:192.168.220.145 HWaddr 00:0C:29:08:D6:45
Bcast:192.168.220.255 Mask: 255.255.255.0spark3:
inet addr:192.168.220.146 HWaddr 00:0C:29:6D:E1:EC
Bcast:192.168.220.255 Mask:255.255.255.0
- 修改配置
[root@localhost ~]# cd /etc/sysconfig/network-scripts #进入网卡配置信息目录
[root@localhost network-scripts]# ls #查看该目录下的文件,可以看到三个节点下都同一个文件ifcfg-eth0
[root@localhost network-scripts]# cat ifcfg-eth0 #查看默认网卡配置信息,三个节点一样
[root@localhost network-scripts]# mv ifcfg-eth0 ifcfg-eth1 #修改spark2、spark3节点该目录下的网卡配置文件名称为ifcfg-eth1
- spark1节点网卡配置
DEVICE="eth0"
BOOTPROTO="static" #这里将dhcp修改成了static
HWADDR="00:0C:29:01:07:7D"
IPV6INIT="yes"
NM_CONTROLLED="yes"
ONBOOT="yes"
TYPE="Ethernet"
UUID="6de4fbd4-af89-44ac-a477-61847c560758"
IPADDR=192.168.220.144 #新增
NETMASK=255.255.255.0 #新增
GATEWAY=192.168.220.2 #新增
DNS1=192.168.220.2 #新增
[root@localhost ~]# ping www.baidu.com #看能否ping通
- spark2节点网卡配置
DEVICE="eth1" #修改
BOOTPROTO="static" #修改
HWADDR="00:0C:29:08:D6:45" #修改
IPV6INIT="yes"
NM_CONTROLLED="yes"
ONBOOT="yes"
TYPE="Ethernet"
UUID="6de4fbd4-af89-44ac-a477-61847c560758"
IPADDR=192.168.220.145 #新增
NETMASK=255.255.255.0 #新增
GATEWAY=192.168.220.2 #新增
DNS1=192.168.220.2 #新增
- spark3节点网卡配置
DEVICE="eth1" #eth0修改成eth1
BOOTPROTO="static" #修改成static
HWADDR="00:0C:29:6D:E1:EC" #对应节点修改
IPV6INIT="yes"
NM_CONTROLLED="yes"
ONBOOT="yes"
TYPE="Ethernet"
UUID="6de4fbd4-af89-44ac-a477-61847c560758"
IPADDR=192.168.220.146 #新增
NETMASK=255.255.255.0 #新增
GATEWAY=192.168.220.2 #新增
DNS1=192.168.220.2 #新增
自己三个节点虽然全能连外网了了,但搞了很久,有待验证
第五步:修改主机名
[root@localhost ~]# vi /etc/sysconfig/network
NETWORKING=yes
HOSTNAME=spark1 #对应节点修改,其他两个节点分别修改成spark2和spark3
[root@localhost ~]# shutdown -r now #重启
第六步:修改hosts文件
[root@spark1 ~]# vi /etc/hosts ##其他两个节点也修改成以下这样.增加集群点名称和ip的映射关系
192.168.220.144 spark1
192.168.220.145 spark2
192.168.220.146 spark3第七步:检查配置(三个节点都检查)
- 确认主机名
[root@spark1 ~]# uname –n
spark1- 确认IP地址
[root@spark1 ~]# hostname --ip-address
192.168.220.144- 确认可以相互ping通
[root@spark1 ~]# ping spark1 -c 3
[root@spark1 ~]# ping spark2 -c 3
[root@spark1 ~]# ping spark3 -c 3第八步:建立集群间ssh无密码登陆
- ssh 无密码登陆本机(三个节点都需要)
[root@spark1 ~]# ssh spark1 #执行该命令将产生目录/root/.ssh。ssh-keygen命令默认会将公钥放在/root/.ssh目录下
[root@spark1 ~]# cd ~/.ssh #进入到该目录下
[root@spark1 .ssh]# ssh-keygen -t rsa #生成本机公钥。一直按回车键
[root@spark1 .ssh]# cat id_rsa.pub >> authorized_keys #加入授权。此时使用ssh连接本机就不需要输入密码了- 两两节点之间实现ssh无密码登陆
[root@spark1 ~]# ssh-copy-id -i spark2 #spark1 ssh无密码登陆spark2
[root@spark1 ~]# ssh-copy-id -i spark3 #spark1 ssh无密码登陆spark3
[root@spark2 .ssh]# ssh-copy-id -i spark1 #spark2 ssh无密码登陆spark1
[root@spark2 .ssh]# ssh-copy-id -i spark3 #spark2 ssh无密码登陆spark3
[root@spark3 .ssh]# ssh-copy-id -i spark1 #spark3 ssh无密码登陆spark1
[root@spark3 .ssh]# ssh-copy-id -i spark2 #spark3 ssh无密码登陆spark2
[root@spark2 ~]# exit #exit命令退出登陆第九步:jdk1.8安装
[root@spark1 ~]# mkdir /usr/java ##新建目录,将需要安装的软件都放入该目录
[root@spark1 java]# chmod u+x #增加权限 jdk-8u77-linux-x64.tar.gz
[root@spark1 java]# tar -zxvf #解压 jdk-8u77-linux-x64.tar.gz
[root@spark1 java]# mv jdk1.8.0_77 jdk1.8 #重命名
[root@spark1 java]# vi /etc/profile #三个节点都是这样配置
# environment variables
export JAVA_HOME=/usr/java/jdk1.8
export PATH=$PATH:$JAVA_HOME/bin
[root@spark1 ~]# source /etc/profile
[root@spark1 ~]# java -version
[root@spark1 usr]# scp -r java root@spark2:/usr/
[root@spark1 usr]# scp -r java root@spark3:/usr/
[root@spark2 ~]# source /etc/profile #配置完spark2节点的环境变量使其生效
[root@spark3 ~]# source /etc/profile #同上
[root@spark1 ~]# java -version #验证三个节点的java是否安装成功第十步:hadoop-2.6.0安装
[root@spark1 ~]# mkdir /usr/hadoop #将要安装hadoop上传到该目录
[root@spark1 hadoop]# chmod u+x hadoop-2.6.0.tar.gz #增加权限
[root@spark1 hadoop]# tar -zxvf hadoop-2.6.0.tar.gz #解压
[root@spark1 hadoop]# vi /etc/profile #配置环境变量
export HADOOP_HOME=/usr/hadoop/hadoop-2.6.0
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin
[root@spark1 hadoop]# source /etc/profile #是环境变量生效
[root@spark1 hadoop]# which hadoop
[root@spark1 hadoop-2.6.0]# mkdir tmp
[root@spark1 hadoop-2.6.0]# mkdir dfs
[root@spark1 dfs]# mkdir data
[root@spark1 dfs]# mkdir name
[root@spark1 hadoop-2.6.0]# cd etc/hadoop #进入该目录进行文件配置第十一步:文件配置
core-site.xml
[root@spark1 hadoop]# vi core-site.xml #增加以下内容
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/hadoop/hadoop-2.6.0/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://spark1:9000</value>
</property>hadoop-env.sh
[root@spark3 hadoop]# vi hadoop-env.sh
# The java implementation to use.
export JAVA_HOME=/usr/java/jdk1.8
hdfs-site.xml
[root@spark1 hadoop]# vi hdfs-site.xml
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>spark1:50090</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/hadoop/hadoop-2.6.0/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/hadoop/hadoop-2.6.0/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
mapred-site.xml
[root@spark1 hadoop]# mv mapred-site.xml.template mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>spark1:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>spark1:19888</value>
</property>yarn-site.xml
[root@spark1 hadoop]# vi yarn-site.xml
<property>
<name>yarn.resourcemanager.hostname</name>
<value>spark1</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
slaves
[root@spark1 hadoop]# vi slaves
spark1
spark2
spark3
将hadoop-2.6.0传到spark2和spark3节点
[root@spark1 hadoop]# scp -r /usr/hadoop root@spark2:/usr
[root@spark1 hadoop]# scp -r /usr/hadoop root@spark3:/usr
将配置文件/etc/profile传到spark2和spark3节点并执行source /etc/profile 命令使其生效
[root@spark1 ~]# scp /etc/profile root@spark2:/etc/
[root@spark1 ~]# scp /etc/profile root@spark3:/etc/
[hadoop@spark1 hadoop-2.6.0]$ ./bin/hadoop version #验证是否安装成功,安装成功会出现hadoop版本信息。有其他两个一样验证
关闭防火墙
[root@spark1 hadoop-2.6.0]# service iptables stop # 关闭防火墙服务,三个节点都关闭
[root@spark1 hadoop-2.6.0]# chkconfig iptables off # 禁止防火墙开机自启,就不用手动关闭了格式化
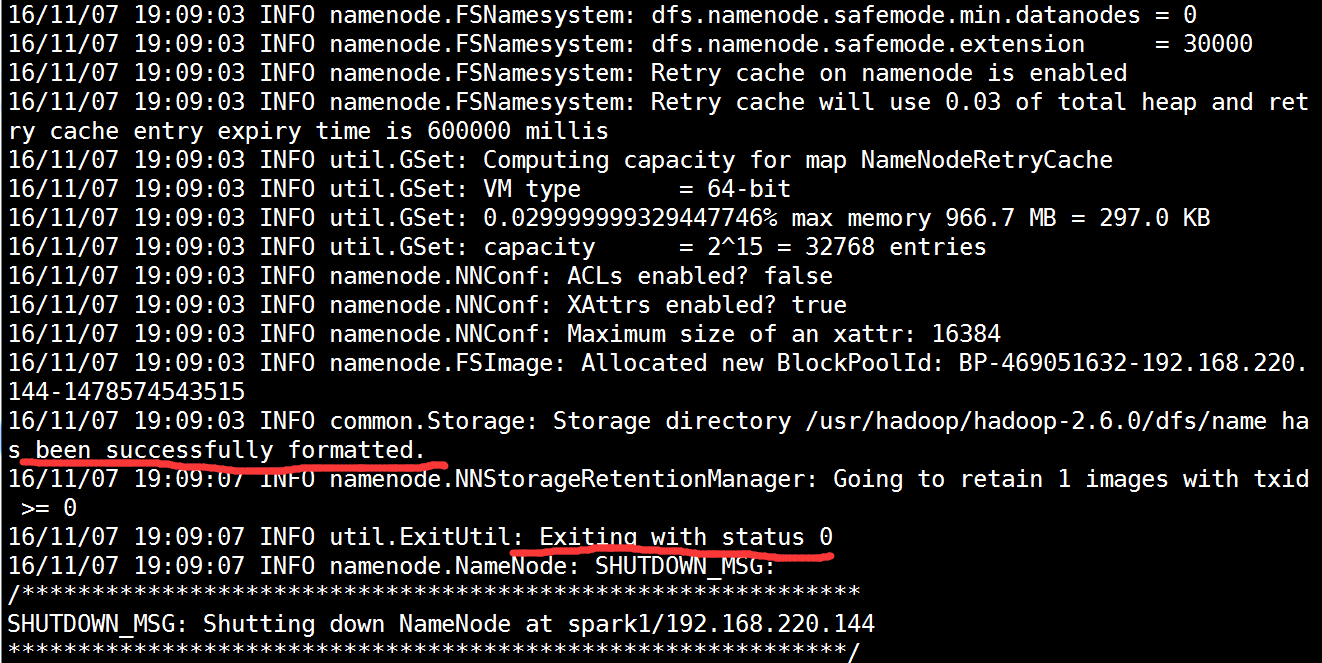
[root@spark1 hadoop-2.6.0]# hdfs namenode -format #格式化成功后如下图
启动hdfs集群
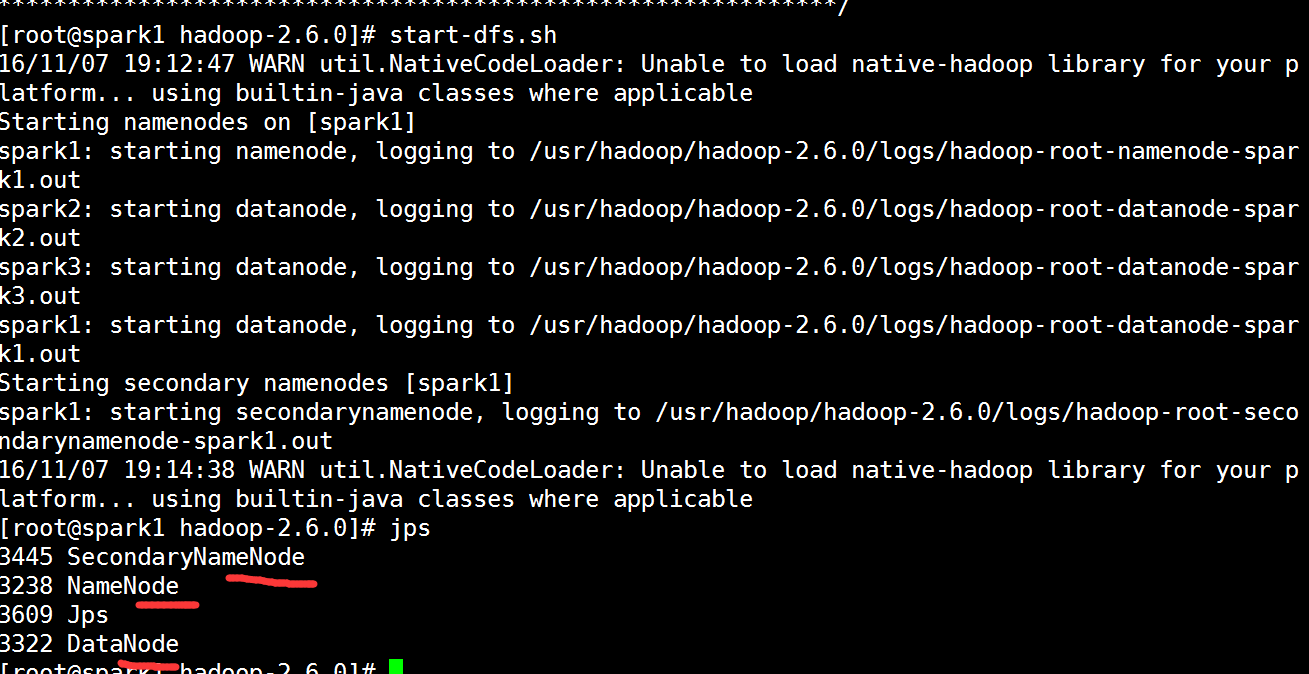
[root@spark1 hadoop-2.6.0]# start-dfs.sh #启动hdfs集群
是否启动成功
spark1:namenode、datanode、secondarynamenode
spark2:datanode
spark3:datanode
[root@spark1 hadoop-2.6.0]# stop-dfs.sh #停止
启动yarn计算平台
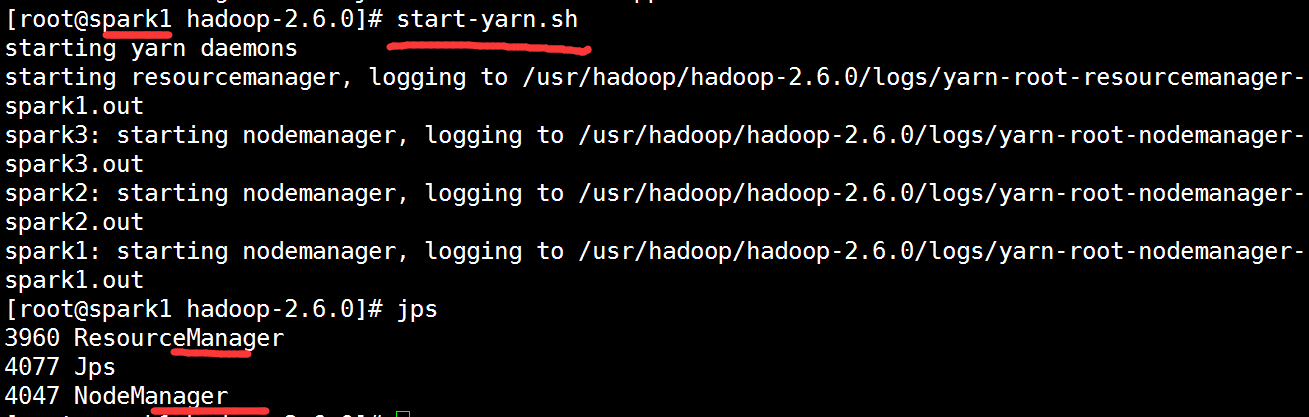
[root@spark1 hadoop-2.6.0]# start-yarn.sh #启动yarn计算平台
是否启动成功
spark1:resourcemanager、nodemanager
spark2:nodemanager
spark3:nodemanager
[root@spark1 hadoop-2.6.0]# stop-yarn.sh #停止
可以两个一起启动
[root@spark1 hadoop-2.6.0]# start-all.sh #两个一起启动
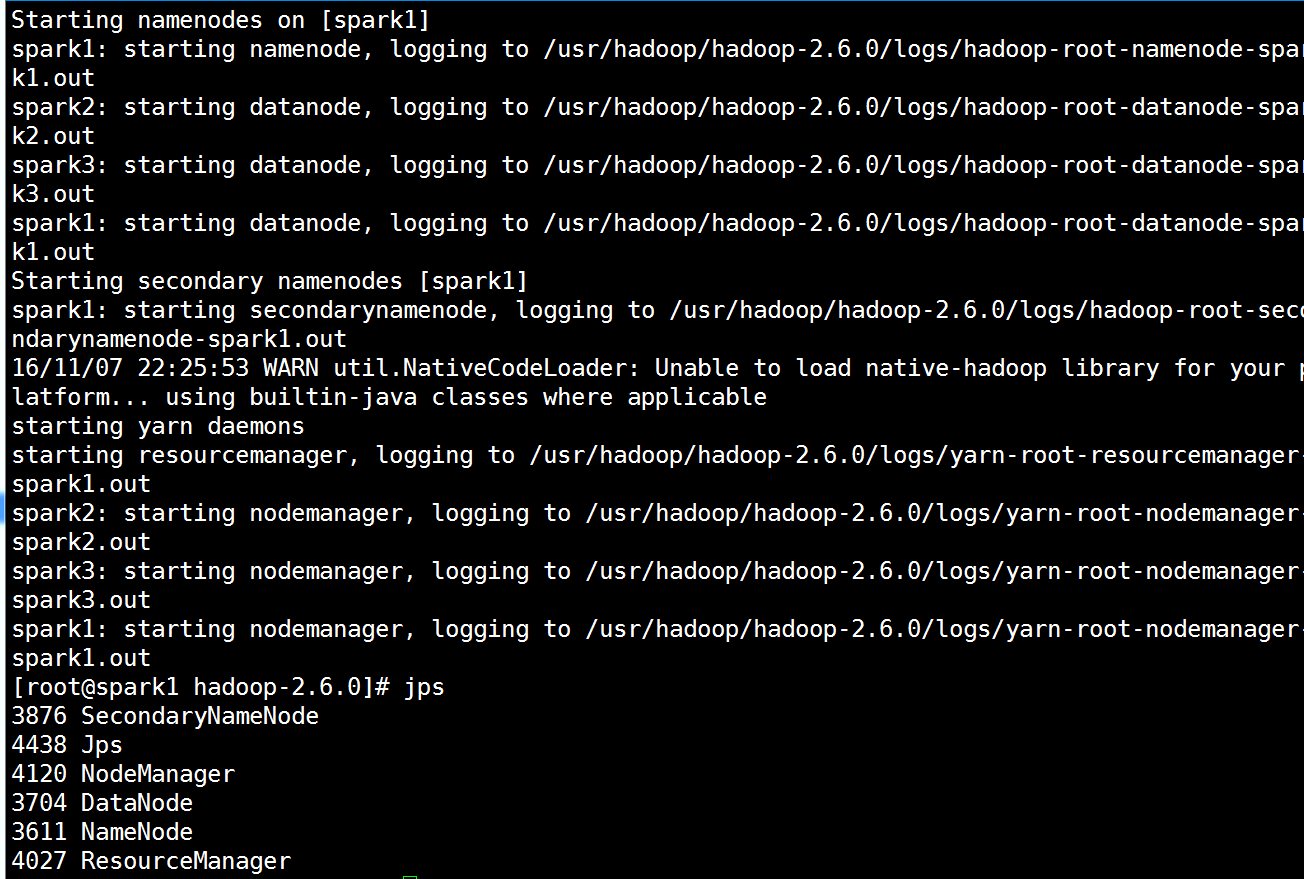
检验
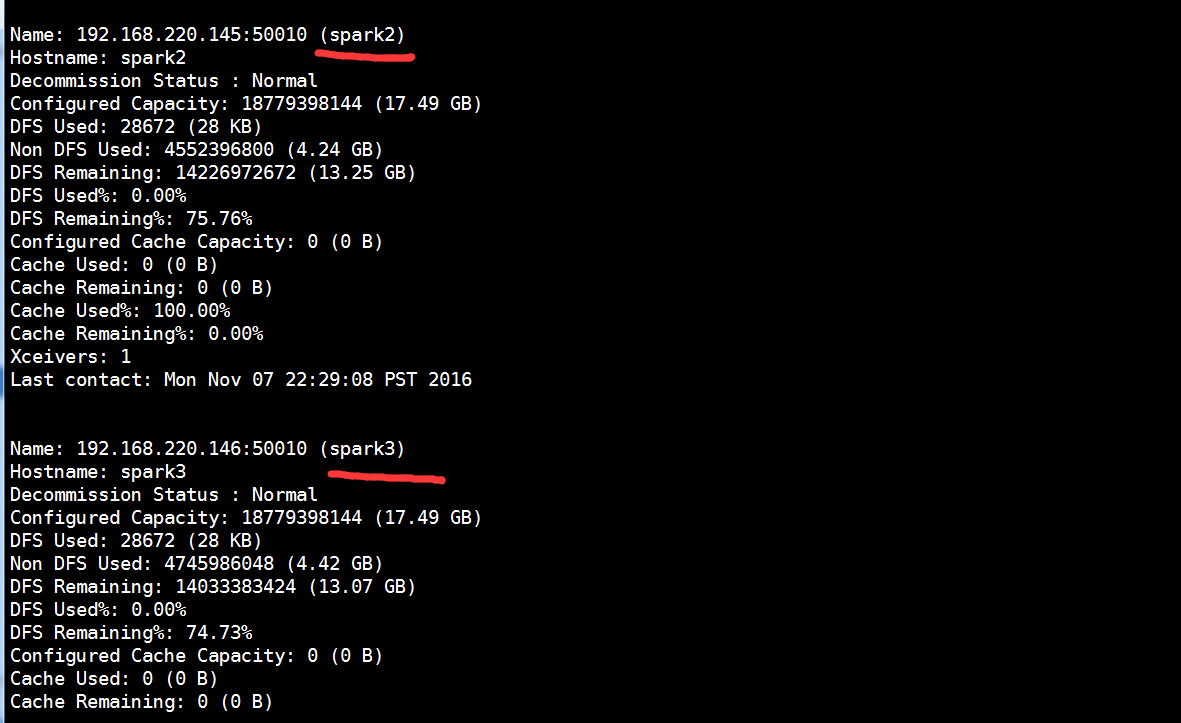
[root@spark1 hadoop-2.6.0]# hdfs dfsadmin -report # 查看Datanode是否启动成功
注意:如果 Live datanodes 不为 0 ,则说明集群启动成功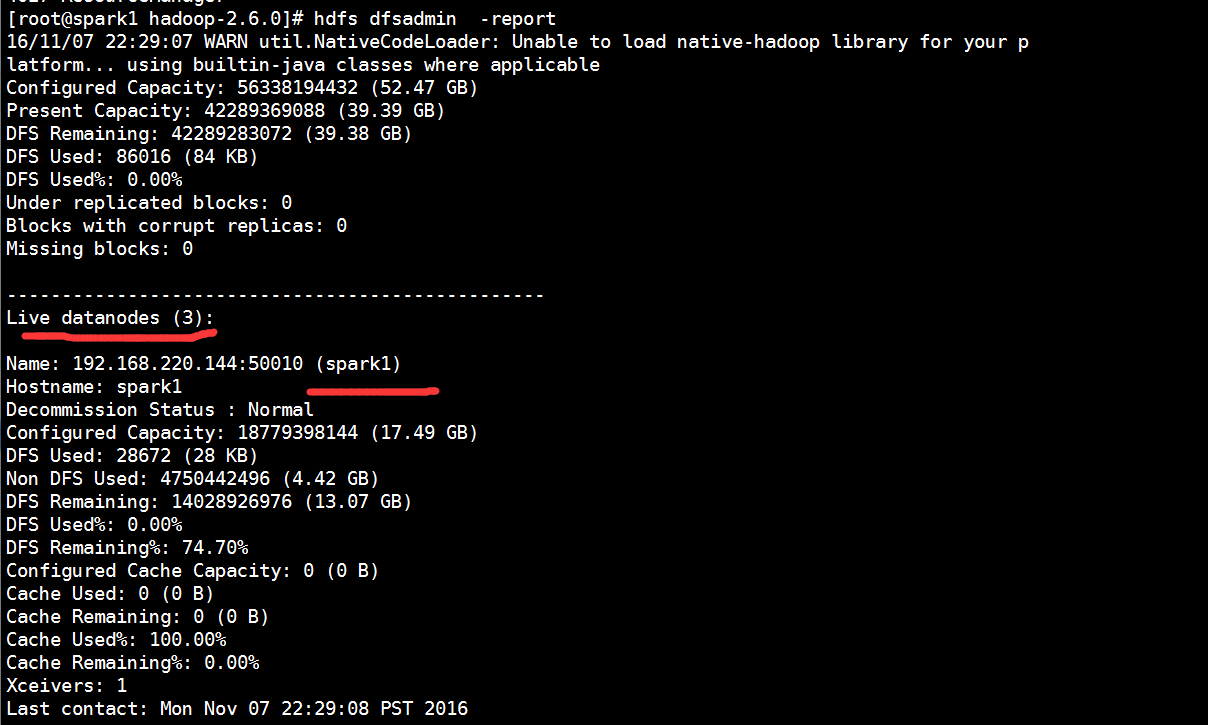
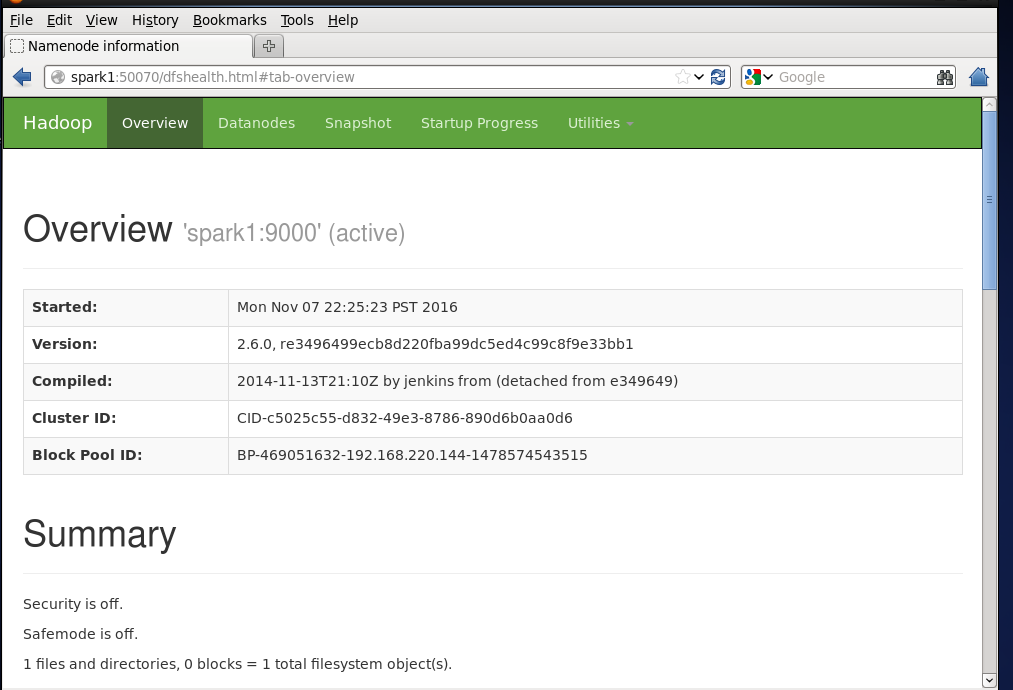
可通过50070端口验证集群是否启动成功:http://spark1:50070/
可通过8088端口验证计算平台是否启动成功:http://spark1:8088/