python读取的数据怎么变成数据框数据_利用python进行数据分析
数据分析的基本步骤包括:
1、提出问题
2、理解数据
3、清洗数据
4、构建模型
5、数据可视化
默认环境使用Anaconda软件,python3语言,win10系统
在这里使用朝阳医院18年销售数据作为案例

1、提出问题
假如我们要得到以下指标:
月均消费次数、月均消费金额、客单价、消费趋势
2、理解数据
2.1 安装一个读取excel文件的依赖包:xlrd(如非第一次操作,请跳过)
打开后输入命令:conda install xlrd
等待其结束就好
2.2 将数据信息导入jupyter目录(如非第一次操作,请跳过)

点击“Upload”找到对应文件上传即可
2.3读取数据
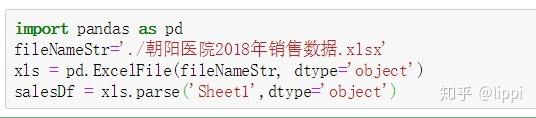
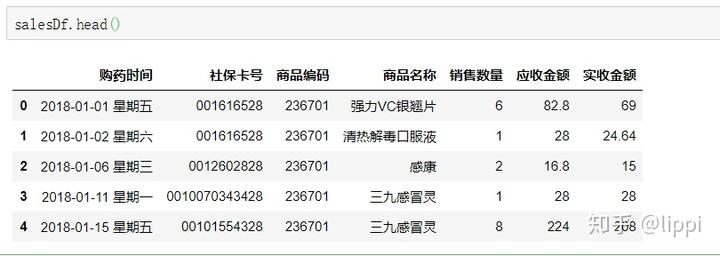
打印前五行:
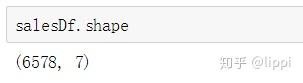
行数、列数:
查看列的数据类型:

3、数据清洗
数据清洗步骤包括:
1、选择子集
2、列名重命名
3、缺失数据处理
4、数据类型转换
5、数据排序
6、异常值处理
下面我们逐一来看
3.1 选择子集

注:根据实际应用场景判断是否有选择必要,本操作暂无必要,故跳过此步骤。
3.2 列名重命名
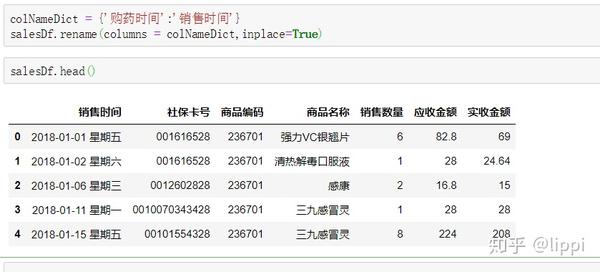
可以看到列名“购药时间”变成了“销售时间”。
inplace默认为False,数据框不变,创立一个新的改动后的数据框
inplace=True,则是对现有数据框进行改动
3.3 缺失数据的处理

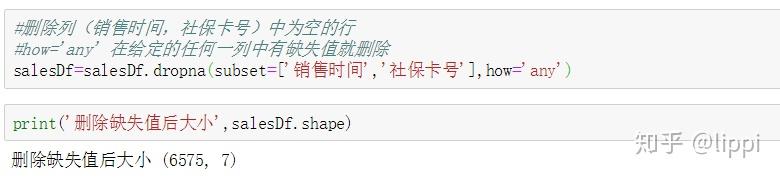
可以看到删除后数据变少了。
一般面对缺失数据的情况有两种解决的思路,一种是删除单条缺失数据,第二种是当缺失数据过多时,建模插值补充数据。根据实际业务场景,销售时间和社保卡号均不能为空,否则单条数据不能用来进行判断,因此删除单条销售时间或社保卡号为空的数据。
python数据缺失值有三种:
1、pandas函数中使用浮点值NaN(Not a Number)表示缺失数值。
2、pandas函数采用了R语言的编程管理,将缺失值称为NA(not available 不可用)
3、python内建的None值在对象数组中也被当做NA来处理。
综述,缺失值为:NaN、NA、None
常用过滤缺失数据的方法有两种:
1、pandas.isnull和布尔值索引手动过滤
2、dropna函数,在数据框上使用dropna,它会返回数据框中所有的非空数据和它的索引值。
这里使用第二种。
3.4 数据类型转换
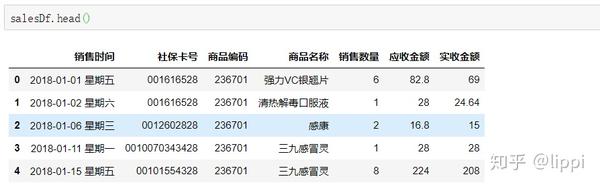
因为在导入数据框的时候,默认将所有数据的类型相同,但显然这并不符合现实情况。如图。
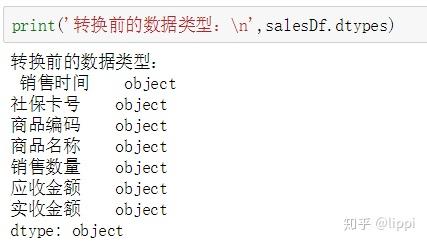
根据需要,这里对“销售数量”、“应收金额”、“实收金额”这三个列的数据转换类型。如图。
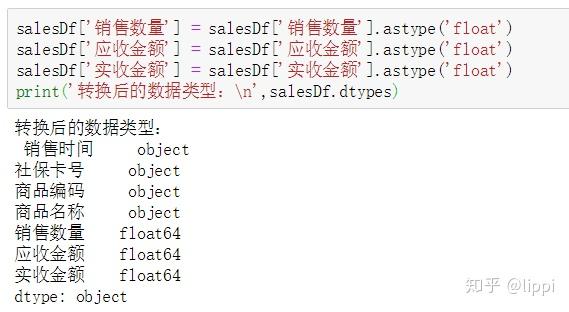
然后,对“销售时间”这列的数据进行处理。
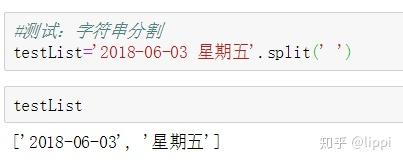
首先这里需要了解分割字符串的方法,通过空格将字符串分为两个部分。如图。
然后就可以取出想要的一部分的值。如图。

由于我们要对数据框中“销售时间”整个列进行处理,所以先要定义一个进行这样操作的函数。如图。

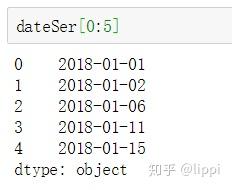
检查一下dateSer的值。如图。
确认无误之后,使用定义的函数进行操作。如图。
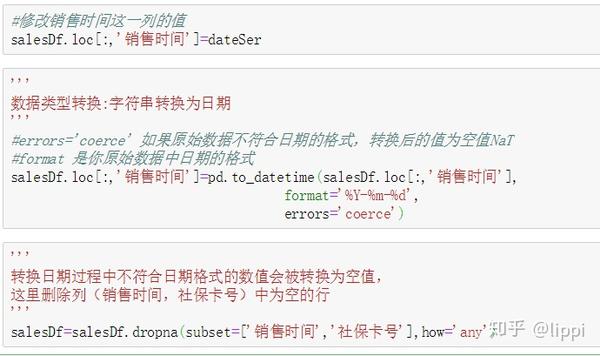
清洗过后,再次打印查看结果。
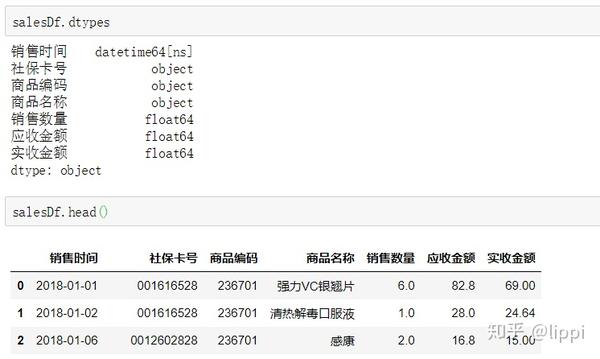
成功~
3.5 数据排序
by:按哪几列排序
ascending=True 表示升序排列,
ascending=True表示降序排列
na_position=True表示排序的时候,把空值放到前列,这样可以比较清晰的看到哪些地方有空值
根据实际业务场景,按销售日期进行升序排列。如图。
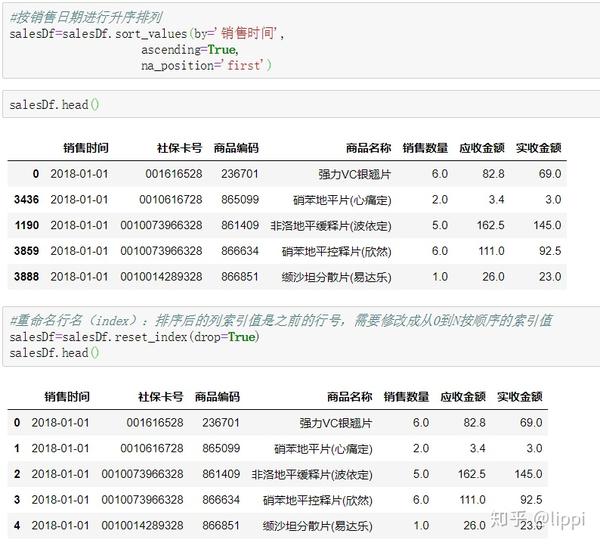
3.6 异常值处理
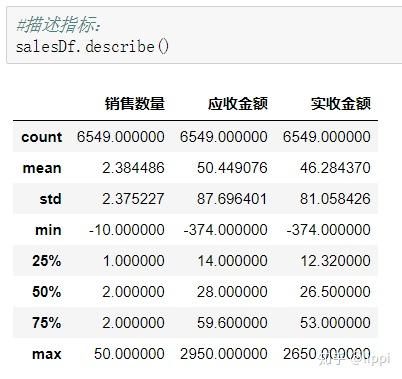
根据实际应用场景,销售数量肯定为正数,所有数据框内数据部分出现错误。现在要把错误数据找出来并删除。

这时候再来看一下指标描述情况。如图。
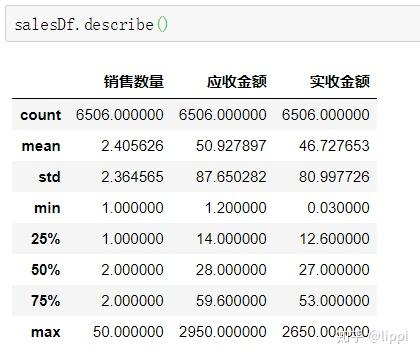
看不出异常了。
到这里数据清洗结束。
4、构建模型
我们先把之前提出的问题拿过来,并逐一处理。
1、月均消费次数
2、月均消费金额
3、客单价
4、消费趋势
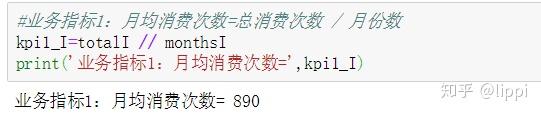
4.1 月均消费次数
月均消费次数 = 总消费次数 / 月份数
获取总消费次数和月份数两个值。如图。
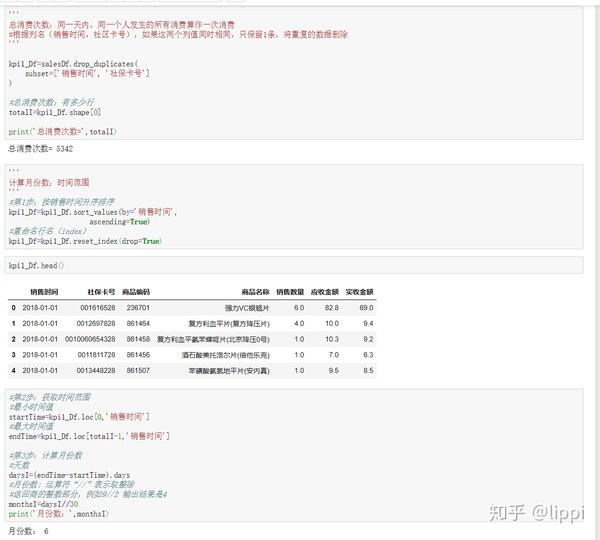
结论:
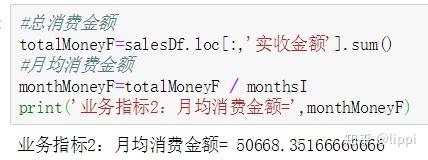
4.2 月均消费金额
月均消费金额 = 总消费金额 / 月份数
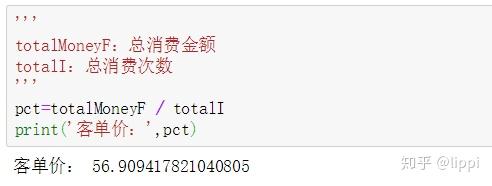
4.3 客单价
客单价=总消费金额 / 总消费次数
4.4 消费趋势
数据可视化方面呢,未完待续hh