自然语言处理系列之:文本向量化
大纲
- 文本向量化常用算法介绍,word2vec及doc2vec
- 向量化方法的模型训练和使用
7.1 文本向量化概述
即将文本表示为一系列能表达文本语义的向量;
7.2 向量化算法word2vec
-
词袋(Bag of Word)模型:最早的以词语为基本处理单元的文本向量化方法;
-
词袋模型存在的问题:
- 维度灾难
- 无法保留词序信息
- 存在语义鸿沟问题
-
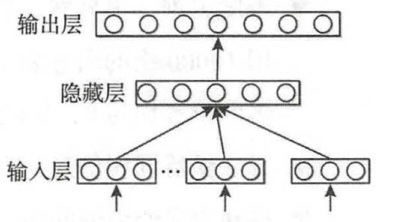
神经网络语言模型(NNLM)
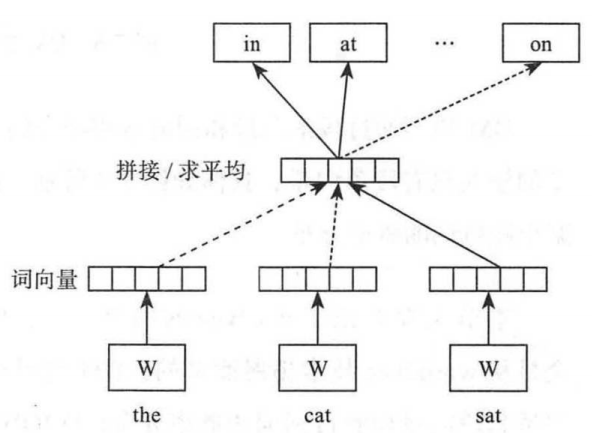
大致操作步骤:从语料库中收集一系列长度为 n n n的文本序列 w i − ( n − 1 ) , … , w i − 1 , w i w_{i-(n-1)},…,w_{i-1},w_i wi−(n−1),…,wi−1,wi,设这个长度为 n n n的文本序列组成的集合为 D D D,则NNML的目标函数定义为:
∑ D P ( w i ∣ w i − ( n − 1 ) , … , w i − 1 ) \sum _DP(w_i|w_{i-(n-1)},…,w_{i-1}) D∑P(wi∣wi−(n−1),…,wi−1)
即:在输入词序列为 w i − ( n − 1 ) , … , w i − 1 w_{i-(n-1)},…,w_{i-1} wi−(n−1),…,wi−1的情况下,计算目标词 w i w_i wi的概率;
在上述经典三层前馈神经网络结构中:为解决词袋模型数据稀疏问题,输入层的输入为低纬度的、紧密的词向量,将词序列 w i − ( n − 1 ) , … , w i − 1 w_{i-(n-1)},…,w_{i-1} wi−(n−1),…,wi−1中每个词向量按顺序进行拼接,即:
x = [ v ( w i − ( n − 1 ) ) ; … ; v ( w i − 2 ) ; v ( w i − 1 ) ] x=[v(w_{i-(n-1)});…;v(w_{i-2});v(w_{i-1})] x=[v(wi−(n−1));…;v(wi−2);v(wi−1)]
接下来, x x x经隐藏层得到 h h h,再将 h h h接入输入层从而得到最后的输出变量 y y y,其中:
h = t a n h ( b + H x ) h=tanh(b+Hx) h=tanh(b+Hx)
y = b + U h y=b+Uh y=b+Uh
其中 H H H是输入层到隐藏层的权重矩阵,维度为 ∣ h ∣ × ( n − 1 ) ∣ e ∣ |h|\times(n-1)|e| ∣h∣×(n−1)∣e∣; U U U是隐藏层到输出层的权重矩阵,维度为 ∣ V ∣ × ∣ h ∣ |V|\times |h| ∣V∣×∣h∣,其中 ∣ V ∣ |V| ∣V∣表示词表大小, b b b则是模型中的偏置项;为保证输出 y ( w ) y(w) y(w)的表示概率值,需对输出层进行归一化操作,一般是加入 s o f t m a x softmax softmax码数,将 y y y转化成对应概率值:
P ( w i ∣ w i − ( n − 1 ) … , w i − 1 ) = e x p ( y ( w i ) ) ∑ k = 1 ∣ V ∣ e x p ( y ( w k ) ) P(w_i|w_{i-(n-1)}…,w_{i-1})=\frac {exp(y(w_i))}{\sum _{k=1}^{|V|}exp(y(w_k))} P(wi∣wi−(n−1)…,wi−1)=∑k=1∣V∣exp(y(wk))exp(y(wi))
因为输出是在上下文词序列出现的情况下,下一个词的概率,所以语料库 D D D中最大化 y ( w i ) y(w_i) y(wi)即为 N N L M NNLM NNLM模型的目标函数:
∑ w i − ( n − 1 ) ; i i n D l o g P ( w i ∣ w i − ( n − 1 ) , … , w i − 1 ) \sum _{w_{i-(n-1);i in D}}log P(w_i|w_{i-(n-1)},…,w_{i-1}) wi−(n−1);iinD∑logP(wi∣wi−(n−1),…,wi−1)
一般使用随机梯度下降法对模型进行训练,对于每个 b a t c h batch batch,随机从语料库中抽取若干样本进行训练,其迭代公式为:
θ : θ + α ∂ l o g P ( w i ∣ w i − ( n − 1 ) , … , w i − 1 ) ∂ θ \theta:\theta+\alpha \frac{\partial logP(w_i|w_{i-(n-1)},…,w_{i-1})}{\partial \theta} θ:θ+α∂θ∂logP(wi∣wi−(n−1),…,wi−1)
α \alpha α为学习率, θ \theta θ包括模型中设计所有参数,包括 N N L M NNLM NNLM模型中的权重、偏置以及输入词向量;
-
C&W模型
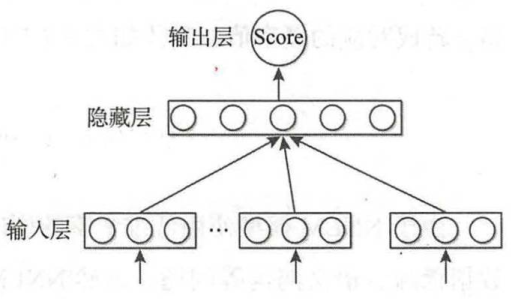
KaTeX parse error: Expected 'EOF', got '&' at position 2: C&̲W模型未采用语言模型的方式求解词语上下文的条件概率,而是直接对 n n n元短语打分,其核心机理为:若 n n n元短语在语料中出现过,则模型给该短语打一个高分,若未出现的短语,则赋予一个较低评分,其目标函数为:
∑ ( w , c ) ∈ D ∑ w ‘ ∈ V m a x ( 0 , 1 − s c o r e ( w , c ) + s c o r e ( w ‘ , c ) ) \sum _{(w,c)\in D} \sum_{w^` \in V}max(0,1-score(w,c)+score(w^`,c)) (w,c)∈D∑w‘∈V∑max(0,1−score(w,c)+score(w‘,c))
( w , c ) (w,c) (w,c)是从语料中抽取的 n n n元短语,为保证上下文词数一致性 n n n应该为奇数, w w w是目标词, c c c表示目标词上下文语境, w ‘ w^` w‘是词典中随机抽取的词;
-
CBOW模型
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VjU5ejcY-1604644465522)(https://i.loli.net/2019/08/31/iyZ941D68EKNgrU.png)]
根据上下文来预测当前词语的概率,使用文本中间词作为目标词,同时去除隐藏层从而提升运算速率,其输入层激吻语义上下文的表示;
对目标词的条件概率公式如下:
P ( w ∣ c ) = e x p ( e ‘ ( w ) T x ) ∑ w ‘ ∈ V e x p ( e ‘ ( w ‘ ) T x ) P(w|c)=\frac {exp(e^`(w)^Tx)}{\sum _{w^` \in V} exp(e^`(w^`)^Tx)} P(w∣c)=∑w‘∈Vexp(e‘(w‘)Tx)exp(e‘(w)Tx)
其目标函数类似于 N N L M NNLM NNLM模型,为最大化式:
∑ ( w , c ) ∈ D l o g P ( w , c ) \sum _{(w,c)\in D}logP(w,c) (w,c)∈D∑logP(w,c)
-
Skim-gram模型
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-tTiS5qFA-1604644465523)(https://i.loli.net/2019/08/31/UNFVnfweLiOtHI5.png)]
根据当前词语来预测上下文概率,从目标词 w w w的上下文中选择一个词,然后将其词向量组成上下文的表示,模型目标函数为:
m a x ( ∑ ( w , c ) ∈ D ∑ w j ∈ c l o g P ( w ∣ w j ) ) max(\sum_{(w,c)\in D} \sum _{w_j \in c}log P(w|w_j)) max((w,c)∈D∑wj∈c∑logP(w∣wj))
7.3 向量化算法doc2vec/str2vec
doc2vec包括DM(Distributed Memory)和DBOW(Distributed Bag of Words),DM模型视图预测给定上下文(不仅包含单词,还包含相应段落)求某单词出现的概率,而DBOW则在仅给定段落向量的情况下预测段落中一组随机单词的概率。总体而言,doc2vec是word2vec的升级,doc2vec不仅提取了文本的语义信息,还提取了文本的语序信息;