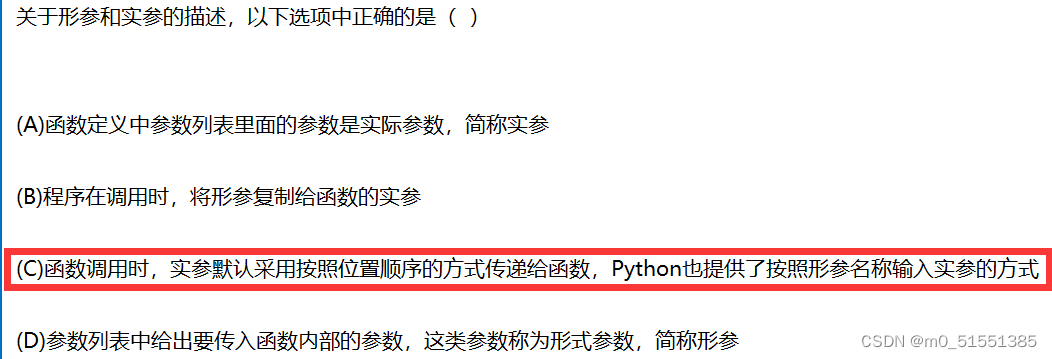
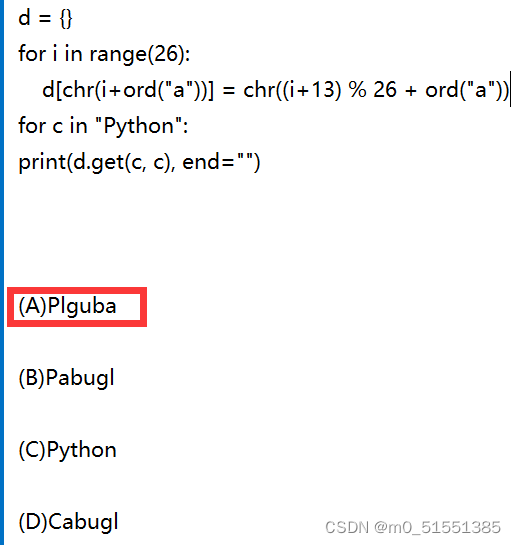
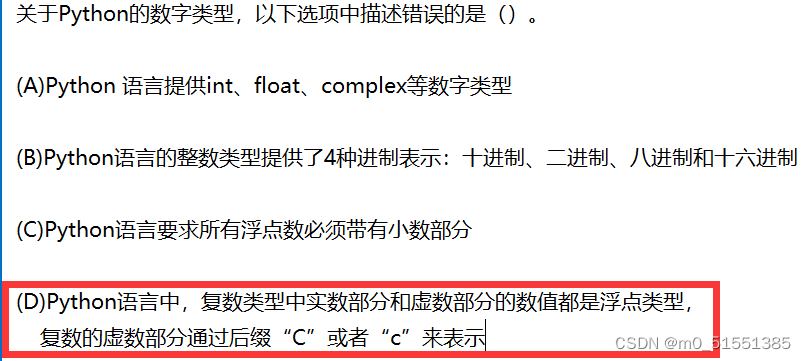
python——学校课程预习+复习
1、字典
- 大括号
{}代表字典。 - 没有下标操作
- 列表不能作为字典的键
一种数据结构,里面存的全是“键” 和 “值”,一个“键” 对应一个 “值”。每对“键”“值”用逗号隔开。“键”是索引(下标),值是数据。
字典的输出顺序和定义顺序不一样。

()代表元组
python 中的字符串,元组都是不可变类型,无法更改元素的值
元组有下标操作
[]代表列表
列表也有下标操作
2、eval()函数
去掉字符串的两个引号,将其解释为一个变量。有三个参数
eval(expression, globals=None, locals=None)
- expression:待计算的字符串表达式
- globals:该部分必须是字典!有了这个参数,eval函数的作用域会被限定在这个参数里
- locals:功能和globals类型,不过当参数冲突时,会执行locals处的参数
a=10;
print(eval("a+1"))
打印11
a=10;
g={'a':4}
print(eval("a+1",g))
打印5
指定了globals,所以在expression部分的作用域就是globals指定的字典范围内。所以此时外面的a=10被屏蔽,取用字典中的值
a=10
b=20
c=30
g={'a':6,'b':8}
t={'b':100,'c':10}
print(eval('a+b+c',g,t))
打印116
当globals和locals中都有参数b时取locals中的值。所以a=6,b=100,c=10
3、input()
执行该函数时,接收屏幕输入,传给=左边的值。
该函数总是返回一个字符串,即便输入的是个数字。
input("请输入东西:")
如果里面有字符串,会输出他
如何同时输入多个?用split()分隔,split()里的内容就是分隔符(默认以空格分隔)
input().split(',')
这样就是以逗号分隔。
4、间隔取数 [::n]
不管间隔n是多少,都先取第一个元素,然后隔n个再取
5、python如何实现循环递减(循环变量从大到小)
5.1 while循环
>>> i=10
>>> while i>0:
print(i,end=" ")
i-=1
10 9 8 7 6 5 4 3 2 1
5.2 利用range中的步长
range三个参数的意义:
range(start, stop, step);
实现:
for i in range(10,0,-1):
print(i,end=" ")
输出:
10 9 8 7 6 5 4 3 2 1
5.3 利用reserve函数反转
for i in reversed(range(1,10+1)):
print(i,end=" ")
6、for循环
for i in range(n):
##
7、输出不换行
print("要输出的内容",end="")
8、想输出算出来的小数的所有位的话就直接print,不要整format
9、用format输出整数
print("{:.2f}{:.2f}{}".format(float, float, float, int))
大括号里什么都不写就是输出原本类型和位数,不加任何限制
10、两个除号连在一起//
就是相除的结果自动取整数。
11、oct() bin()
oct():求出括号内数字的8进制形式,结果以0o开头
bin():求出括号内数字的2进制形式,结果以0b开头
12、complex()函数
Python输出虚数时,自动加上小括号 ()
class complex([real[, imag]])
real是实部,imag是虚部,产生一个字符串,且自带括号
print(complex(10.99))
print(complex(1, 2))
结果:
(10.99+0j)
(1+2j)
13、round()函数
四舍五入
round(number, num_digits)
number 是需要四舍五入的数
num_digits 是保留的位数
如果只有一个参数,就是保留0位,结果是整数。
14、format

实例:
a = "Python"
b = "A Superlanguage"
print("{:->10}:{:-<19}".format(a, b))
输出:
----Python:A Superlanguage----
{:->10}:这个大括号里的内容总长度为10,是右对齐(从右往左写),左边写不满用 - 补位
有时候大括号里的冒号前面会有数字,这个数字是后面参数填入的顺序,如下面的例子:
print("{1}的值为{0:.6f}".format(3.1415926, "Π"))
输出:
Π的值为3.141593
15、upper函数
把字符串中的小写字母转大写字母
16、count函数
str.count( sub, start= 0, end=len(string) )
start 是查找的起始位置
end 是查找的结束位置
在str串中查找sub串出现的次数,结果是一个整数。
17、isnumeric函数
str.isnumeric()
字符串只由数字组成返回true,否则返回false
18、argmax 和 argmin函数
对于一维数组来说,返回数组中最大值的下标。
当一组中同时出现几个最大值时,返回第一个最大值的索引值。
argmin反之。
19、np.random.randint() 和 random.randint()
它俩的区别看这篇博客就够了
所有生成随机数,有这篇博客就够了

还要额外记住这两个,上面的博客没有
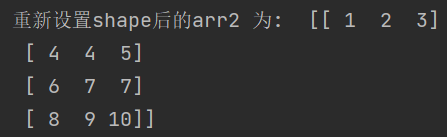
20、shape
- 可以重新设置多维数组的行和列

输出:
21、append生成多维数组
import numpy as np
a=[]
for i in range(5):
a.append([])
for j in range(5):
a[i].append(i)
append:在数组末尾追加元素
22、transpose转置矩阵
a = np.transpose(a)
23、用户输入填充字典
d = {}
for i in range(1, 6):
name = input()
mark = input()
d[name] = mark
search = input()
print("{} {}".format(search, d[search]))
24、用户输入填充列表
n = eval(input())
l = []
for i in range(0, n):
l.append(eval(input()))
25、文件操作
f = open("car_data.txt",encoding="gbk")
content = f.readlines() 读取所有行,并返回一个列表
for temp in content: temp就是文件的每一行的内容
# ...........
# ...........
f.close() 一定要记得关闭文件
使用open打开文件,第一个参数是文件路径,第二个参数是编码方式。
注意,readlines()是读取所有行,而且 返回的是一个列表。
所以下面的temp是列表中的每一个元素。
26、正则表达式 re库
1)findall(pattern, string)
findall有两个参数,他能在第二个参数表示的串中 找到所有的第一个参数,并一一存入结果字符串列表中,结果列表中元素的个数取决于第二个参数里有多少个第一个参数。
若第一个参数有的部分被()括起来了,那么匹配的时候仍然正常匹配,但是取结果的时候只保留小括号里面的内容。
若第一个参数里面有|,那么|前后表示的串都可以匹配成功。
2).
在正则表达式中,一个.可以匹配任意一个字符。
3)[a-z]
中括号括起来的部分表示一个字符,什么样的字符呢?就是中括号范围内的任意一个字符。

举例:
[Aa] 表示一个字符,这个字符可以是 A ,或 a
[a-z] 表示一个字符,可以是a-z之间的任意字符
4)x*
x*可以匹配任意个数的 只由 x 构成的字符。
举例:
?* 可以匹配:空,?,??,???......????????????????????
也就是任意个数的 ?
5)\d
匹配任意一个数字
6)\d+
至少有一个数字
+表示至少有一个前面所代表的字符,不能是空
7)\d{x}
匹配x个数字。
\d{x, x+n}
匹配x到x+n之间个数的数字,若既能匹配到x ,也能匹配到x+n之间的某一个,则取最大
8)\w
匹配任意一个字母。等价于[a-zA-z]
9)注意:下面这张表里e和c老搞混

27、argmax和argmin
这两个函数分别返回列表中最大值/最小值的下标
28、文件操作
r只读,r+可读写,不能创建
w新建只写,w+新建读写,二者都会将文件内容清零
a:附加写方式打开,不可读;a+: 附加读写方式打开
+的作用是:在原功能基础上增加同时读写功能
29、注释
注释会被python解释器过滤掉
注释可以辅助程序调试
30、jieba.lcut的三种模式
(1)精确模式语法:jieba.lcut(字符串, cut_all=False),默认时为cut_all=False,表示为精确模型。精确模式是把文章词语精确的分开,并且不存在冗余词语,切分后词语总词数与文章总词数相同。
(2)全模式语法:jeba.lcut(字符串,cut_all=True),其中cut_all=True表示采用全模型进行分词。全模式会把文章中有可能的词语都扫描出来,有冗余,即在文本中从不同的角度分词,变成不同的词语。
(3)搜索引擎模式:jieba.lcut_for_search(字符串)在精确模式的基础上,对长词语再次切分。
31、divmod函数
divmod(a,b)方法返回的是a//b(商)以及a%b(余数),返回结果类型为tuple
32、在一行上写多条Python语句使用符号 ;
33、seek函数
seek函数表示将光标移到文件的哪个位置。
seek(offset,whence=0)
offset:偏移量,偏移移动的字节数whence:要从哪个位置开始偏移;0代表从文件开头开始算起,1代表从当前位置开始算起,2代表从文件末尾算起。
seek(0); 表示把光标移动到文件头,只有一个参数的时候,该参数代表 whence
34、lower和upper函数
分别是把一个字符串转换成小写和大写,使用方法如下:
string.lower()
35、ord 和 chr函数
ord函数:返回传入字符的ASCll数值
chr函数:返回传入ASCII码的字符值
字典的get方法:
dict.get(key, default=None)
返回字典中键key所对应的值。第二个参数只有在字典中不存在键key时才有用,此时,键key对应的值就是default。
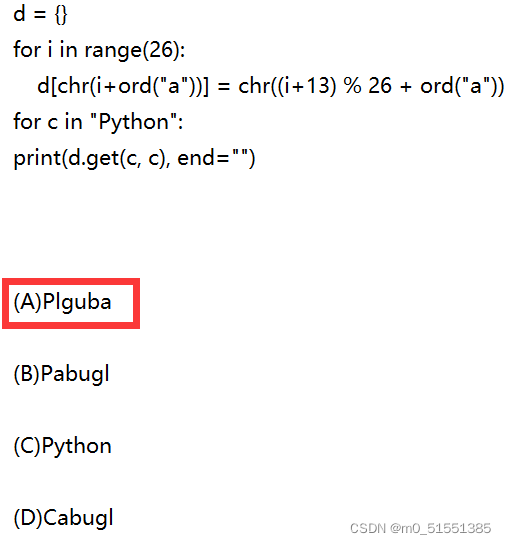
36、index函数
str1.index(str2, beg=0, end=len(string))]
检测字符串中是否包含子字符串str,如果指定beg(开始) 和end(结束)范围,则检查是否包含在指定范围内。并返回第一次出现的下标。
str1也可以是一个列表,str2也可以只是个数字。
37、isinstance函数
isinstance(object, classinfo) 判断 object 的类型是否是 classinfo,返回 True 或 False
例题:

使用
writelines函数将一个字符串列表写入文件,默认列表中的元素间没有任何分隔








e后面必须跟一个数字,所以上式中+8整体是一个数字8,+代表正号,而不是加号。而5.67e+8j.real整体是一个虚数,该虚数只有虚部没有实部,虚部是5.67e+8。
Python中使用j或J表示虚部。












默认参数可以不按顺序提供





scv是一种通用的电子表格和数据库导入导出格式。里面的每行数据以,分隔





不允许同一个键出现两次。如果同一个键被赋值两次,后一个值会被记住