一个看似纠结的MySQL标签需求的梳理
这是学习笔记的第 2145 篇文章

我们日常工作中总是会有一些看起来繁琐,吃力不讨好的事情,但是这些需求我们不能一概而论,为了落实规范而动用规范的大棒。
对我来说,我喜欢那种开放型的问题,比如看起来很繁琐无解,但是业务又迫切需要的事情。
比如业务同学今天提了一个问题:有一张表,数据量有600多万,而且数据实时的写入还挺多,记录的是一些工作的备注信息,比如客服同学接受了一个用户请求,然后会把这些信息记录下来,比如是关于哪个业务方向的,关于哪个游戏的等等,都当做一个字段信息存储起来。之前的管理是一种相对笼统的方式,在管理中会难以衡量和控制。 所以现在想使用类似标签的方式进行信息归类。
举个例子来说,客服同学之前处理了几个需求,假设记录的格式是这样的:
用户xxx咨询游戏A的登录问题。。。。。
用户xxx反馈游戏B的充值问题,反馈游戏C(可能错别字)的经验没有生效。。。
用户xxx反馈手机号登录游戏B(可能缩写)失败,而且充值有问题。。。
所以用户反馈的信息是没有严格的格式和规范,要对这些用户请求打上标签难度还是比较大的。
对一张600多万的大表进行业务整改,势必会有一些全流程的改变,首先业务同学给我们出了个难题,这个表的索引是比较多的,重建的过程远远超出了我们的预期,还好使用了pt-osc工具还算稳。
现在表的一个标签字段已经创建好了,就需要进行下一步的工作:打标签。
业务同学进行梳理和讨论,整理了大概12个种类的关键字,每个关键字会对应一个数字编码,也就是能够被识别业务标签。
array(
1 => '关键字1',
2 => '关键字2',
3 => '关键字3',
4 => '关键字4',
5 => '关键字5',
6 => '关键字6',
7 => '关键字7',
8 => '关键字8',
9 => '关键字9',
10 => '关键字10',
11 => '关键字11',
12 => '关键字12'
);
面对这么多的种类,难点来了,有些标签是有互斥关系的,有些是可能存在关键字重合的,比如“笔记本电脑”“台式电脑”这两个词是互斥的两种类型,而“笔记本”和“笔记本电脑”又是互斥的。
如果让业务部门去统计这么多的重合标签,估计会疯掉,因为按照一个粗略的计算,比如6个标签,4个重合的概率就是16+5+1=22种,如果是12类标签,那方案复杂度要高得多,至少得上百种。
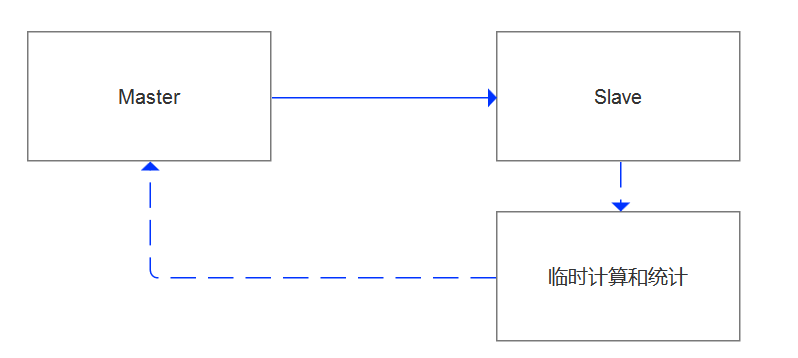
最关键的,哪怕这些都梳理出来,根据评估需要变更的数据有70万,怎么高效的把70万数据都发布到线上,这是一个值得思考的问题。 整体的思路是:
1)线上的关键字模糊匹配工作要放到从库来执行。
2)从库端不光进行数据过滤,还需要进行一些数据的统计分析,进行去重和过滤
3)在经过需求确认后,把变更语句按照主键条件发布到线上
对于标签的冲突关系梳理,我提出了改进的思路。
既然有12类标签,那么我们完全可以按照12个数据子集进行单独的关键字过滤,如果有一些标签是重合的,那么在12类标签过滤中势必会出现。
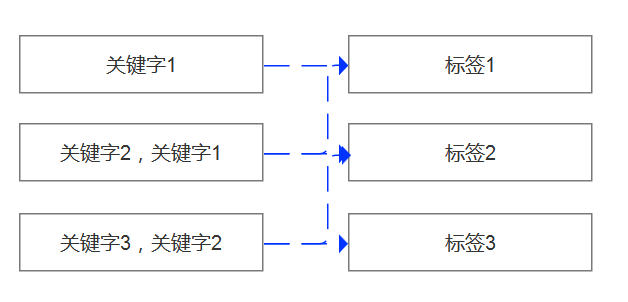
面对这种多对多的映射,我们可以完全统计出这些多标签的比例来,如果占比不到0.1%,那么这些单据我们完全可以通过人工来判别,这样一来,99%以上的数据都可以自动完成,人工只需要进行判断很少的单据,避免我们的需求从开始就进入本末倒置的状态。
所以我按照单号(order_id,tag_name,tag_id)来进行数据抽取,很快就得到了12个数据子集,我们假设为dataset1-dataset12
然后我们把这些自己的数据写入一个共同的集合dataset中。
select order_id,count(*)from dataset group by order_id having count(*)>1就可以得到多标签的单据了。
而经过初步的统计,这个数据量级确实是很低的,5个重合标签的单据都是个位数,99%以上的单据都是单标签。
所以这一层关系确定之后,我们就可以考虑进行线上的数据部署优化了,而这也正是DBA要做的专业的事情。
如果变更语句有30万,那么我们构造出30万条SQL语句是成本比较高的。
我们可以把dataset的结果导入线上环境中,创建索引(order_id,tag_id)
然后分批次变更,尽可能避免半连接操作,根据实践的效果来看,每一步基本都控制在毫秒级完成。
近期热文: